Laporan ini oleh Alexey Milovidov, Kepala tim pengembangan ClickHouse, adalah tinjauan umum dari beberapa sistem basis data yang terkenal. Beberapa dari mereka sudah ketinggalan zaman, beberapa telah menghentikan perkembangan mereka dan ditinggalkan. Alexey menarik perhatian pada solusi arsitektur yang menarik dalam contoh-contoh yang tercantum, memahami nasib mereka dan menjelaskan persyaratan apa yang harus dipenuhi oleh proyek sumber terbuka Anda.
- Laporan saya akan tentang basis data. Izinkan saya bertanya kepada Anda, peta metro mana yang ditampilkan pada slide ini? Semua garis berjalan satu arah.
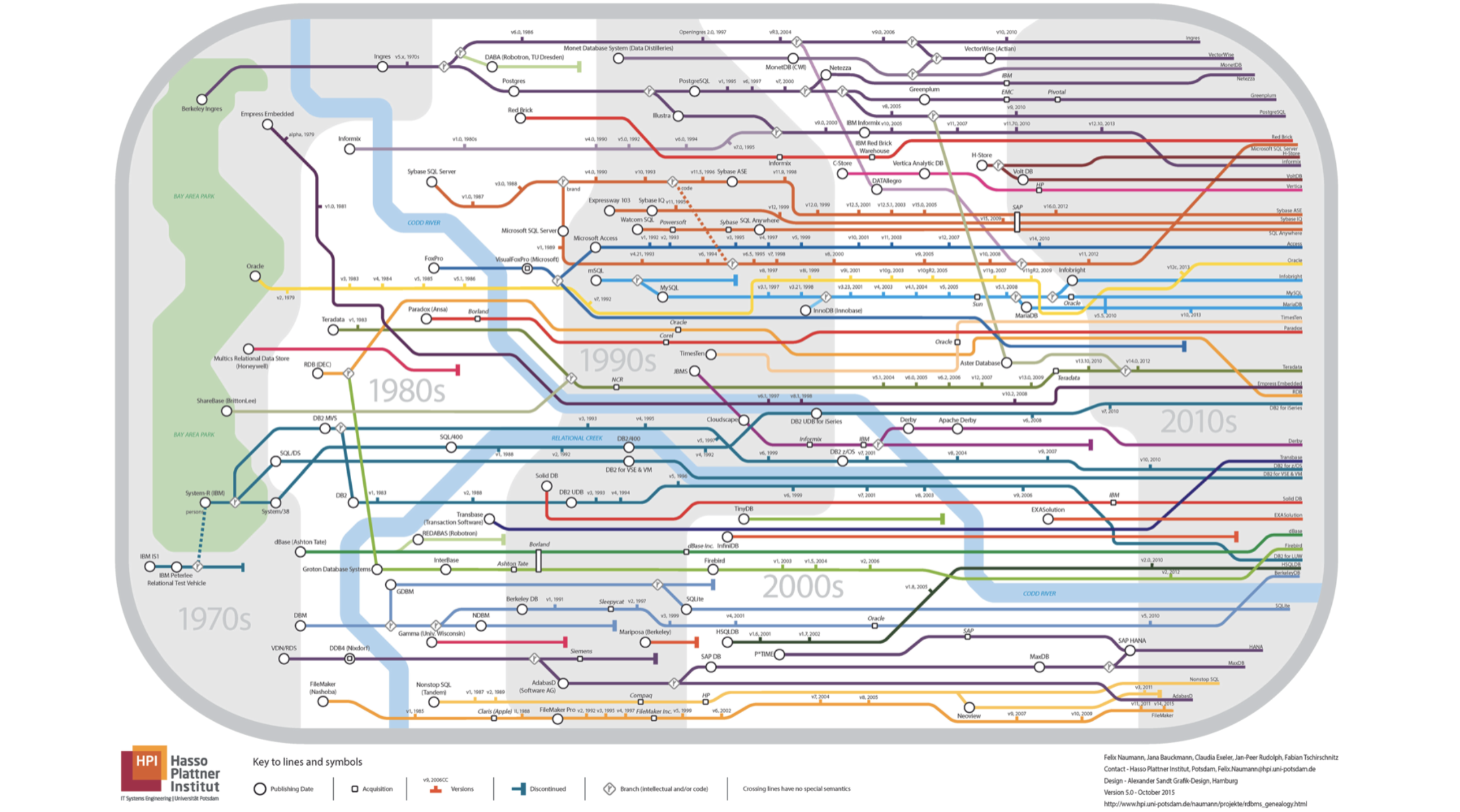
Semuanya salah, itu tidak di bawah tanah sama sekali, itu adalah silsilah dari basis data relasional. Jika Anda melihat lebih dekat, Anda akan melihat bahwa sungai itu adalah Sungai
Kodda .
Saya tidak akan membicarakannya. Apa yang bisa lebih membosankan daripada berbicara tentang MySQL, PostgreSQL atau sesuatu seperti itu? Sebagai gantinya, saya akan berbicara tentang membuat basis data.

Perakitan manual. Sistem yang hampir tidak diketahui siapa pun. Mereka dirancang oleh satu orang atau sudah lama ditinggalkan.

Contoh pertama adalah EventQL. Tolong angkat tangan Anda jika Anda pernah mendengar tentang sistem ini. Bukan satu orang, kecuali mereka yang bekerja di Yandex dan sudah mendengarkan laporan saya. Jadi, tidak sia-sia saya memasukkan sistem ini dalam ulasan saya.

Ini adalah mesin basis data kolom terdistribusi yang dirancang untuk pemrosesan acara dan analitik. Ini melakukan query SQL yang sangat cepat, open source sejak 26 Juli 2016, ditulis dalam C ++, ZooKeeper digunakan untuk koordinasi, tidak ada dependensi selain itu. Itu mengingatkan saya pada sesuatu. Sistem kami yang luar biasa, semua orang sudah tahu namanya. EventQL adalah sesuatu seperti ClickHouse, tetapi lebih baik. Terdistribusi, paralel masif, berorientasi kolom, skala ke petabyte, permintaan rentang cepat - semuanya jelas, kami memiliki semuanya. Hampir dukungan penuh untuk SQL 2009, menyisipkan waktu nyata dan pembaruan, distribusi data otomatis di seluruh cluster, dan bahkan bahasa ChartSQL untuk menggambarkan grafik. Luar biasa! Inilah yang kami janjikan kepada semua orang dan apa yang tidak kami miliki.
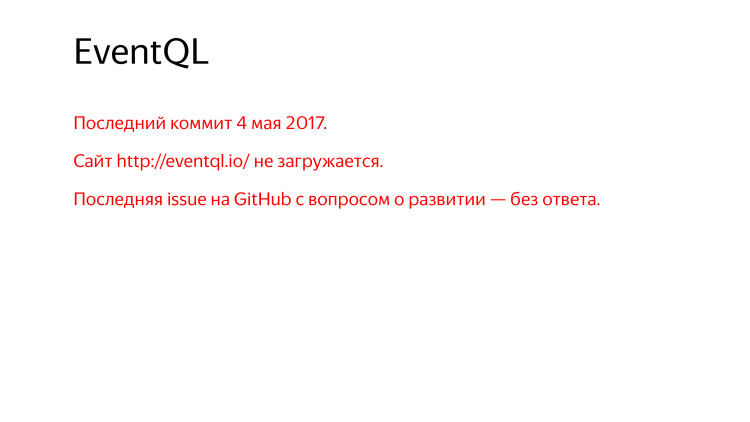
Namun demikian, komit terakhir hampir setahun yang lalu, ada situs yang tidak memuat, Anda harus menonton melalui web.archive.org.
Tanyakan pada GitHub - apa rencana pengembangan Anda, apa yang akan terjadi selanjutnya? Tidak ada yang menjawab.
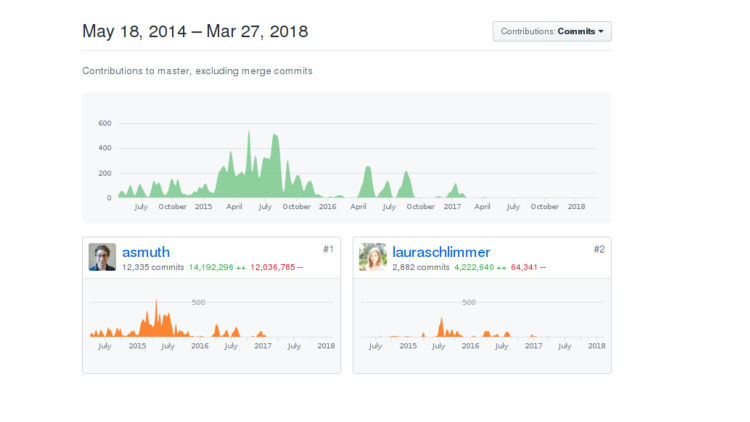
Sistem ini memiliki dua pengembang. Satu adalah pengembang backend, yang kedua adalah frontend. Saya tidak akan menunjukkan siapa di antara mereka yang, mungkin, akan menebak sendiri. Dibuat oleh DeepCortex. Namanya sepertinya akrab, tetapi ada banyak perusahaan dengan kata Deep dan kata Cortex. DeepCortex adalah perusahaan yang tidak dikenal dari Berlin. Sistem ini telah dikembangkan sejak 2014, dikembangkan secara internal untuk waktu yang lama, kemudian dirilis ke sumber terbuka dan ditinggalkan setahun kemudian.

Itu terlihat seperti ini: mereka melemparkannya ke udara dan berpikir, tiba-tiba seseorang akan memperhatikannya atau dia akan terbang ke suatu tempat. Sayangnya tidak.
Kerugian lain adalah lisensi AGPL, yang relatif tidak nyaman. Bahkan jika itu tidak menimbulkan batasan serius bagi perusahaan Anda untuk digunakan, itu masih sering ditakuti, departemen hukum mungkin memiliki beberapa poin yang menentangnya.
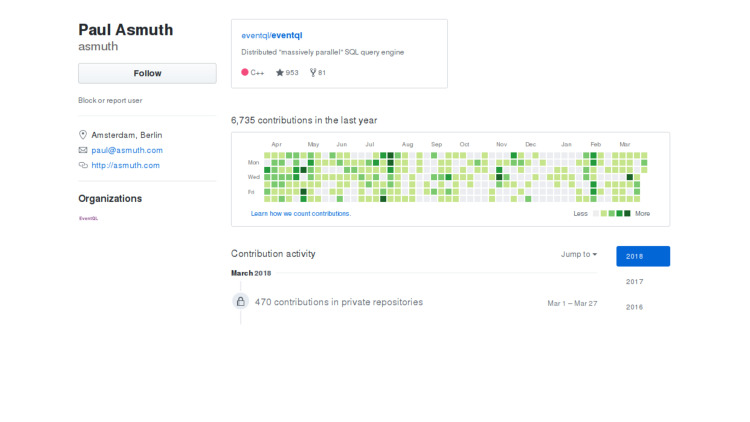
Saya mulai mencari apa yang terjadi, mengapa itu tidak dikembangkan. Saya melihat akun pengembang, pada prinsipnya semuanya baik-baik saja, orang itu hidup, terus berkomitmen, namun, semua komitmen untuk repositori pribadi. Tidak jelas apa yang terjadi.

Entah orang tersebut pindah ke perusahaan lain dan kehilangan minat untuk mendukung, atau prioritas perusahaan berubah, atau keadaan kehidupan tertentu. Mungkin perusahaan itu sendiri tidak merasa sangat buruk, dan open source dibuat untuk berjaga-jaga. Atau hanya lelah. Saya tidak tahu jawaban pastinya. Jika ada yang tahu, tolong beri tahu saya.

Namun semua ini dilakukan tidak sia-sia. Pertama-tama, ChartSQL untuk deskripsi deklaratif dari grafik. Sekarang sesuatu yang serupa digunakan dalam sistem visualisasi data Tabix untuk ClickHouse. EventQL memiliki blog, namun saat ini tidak tersedia, Anda harus melihat melalui web.archive.org, ada file .txt. Sistem ini diterapkan dengan sangat kompeten, dan jika Anda tertarik, Anda dapat membaca kode dan melihat solusi arsitektur yang menarik.
Itu saja tentang dia untuk saat ini. Dan sistem selanjutnya memenangkan semua orang, yang akan saya pertimbangkan, karena ia memiliki nama terbaik, paling enak. Sistem Alenka.
Saya ingin menambahkan foto kemasan cokelat, tetapi saya khawatir akan ada masalah hak cipta. Apa itu Alenka?

Ini adalah DBMS analitik yang mengeksekusi query pada akselerator grafis. Openors, lisensi Apache 2, 1103 bintang, ditulis dalam CUDA, C ++ kecil, satu pengembang dari Minsk. Bahkan ada driver JDBC. Pembuka sejak 2012. Namun, sejak 2016, sistem untuk beberapa alasan tidak berkembang lagi.

Ini adalah proyek pribadi, bukan milik perusahaan, tetapi benar-benar proyek satu orang. Ini adalah prototipe penelitian untuk mengeksplorasi kemungkinan cara cepat memproses data pada GPU. Ada tes menarik dari Mark Litvinchik, jika tertarik, Anda bisa melihat di blog. Mungkin, banyak yang sudah melihat tesnya di sana bahwa ClickHouse adalah yang tercepat.

Saya tidak punya jawaban mengapa sistem ini ditinggalkan, hanya tebakan saja. Sekarang seseorang bekerja untuk nVidia, mungkin ini hanya kebetulan.

Ini adalah contoh yang bagus, karena meningkatkan minat, cakrawala, Anda dapat melihat dan memahami bagaimana Anda bisa melakukannya, bagaimana sistem dapat bekerja pada GPU.
Tetapi jika Anda tertarik dengan topik ini, ada banyak pilihan lain. Misalnya, sistem MapD.
Siapa yang mendengar tentang MapD? Tersinggung. Ini adalah startup yang berani, juga mengembangkan basis data GPU. Baru-baru ini dirilis dalam sumber terbuka di bawah lisensi Apache 2. Saya tidak tahu untuk apa itu, baik atau sebaliknya. Startup ini sangat sukses sehingga ditata dalam open source atau sebaliknya, akan segera ditutup.
Ada PGStorm. Jika Anda semua berpengalaman dalam PostgreSQL, maka Anda harus mendengar tentang PGStorm. Juga open source, dikembangkan oleh satu orang. Dari sistem tertutup, ada BrytlytDB, Kinetica, dan perusahaan Rusia Polymatic, yang membuat sistem Business Intelligence. Analisis, visualisasi dan semua itu. Dan untuk pemrosesan data, bisa juga menggunakan akselerator grafis, mungkin menarik untuk dilihat.

Apakah mungkin melakukan sesuatu yang lebih keren daripada GPU? Misalnya, ada sistem yang memproses data pada FPGA. Ini Kickfire. Dia memberikan solusinya dalam bentuk besi dengan perangkat lunak segera. Benar, perusahaan telah lama tutup, solusi ini cukup mahal dan tidak dapat bersaing dengan kabinet lain ketika beberapa vendor membawa kabinet ini kepada Anda, dan semuanya bekerja secara ajaib.
Selanjutnya, ada prosesor yang berisi instruksi untuk mempercepat SQL - SQL di Silicon dalam model prosesor SPARC baru. Tapi Anda tidak perlu berpikir bahwa Anda menulis bergabung di Assembler, itu tidak ada di sana. Ada instruksi sederhana yang melakukan dekompresi menggunakan beberapa algoritma sederhana dan sedikit penyaringan. Pada prinsipnya, ia tidak hanya bisa mempercepat SQL. Sebagai contoh, prosesor Intel memiliki seperangkat instruksi SSE 4.2 untuk memproses string. Ketika muncul sekitar tahun 2008, situs web Intel memiliki artikel berjudul “Menggunakan Instruksi Prosesor Intel Baru untuk Memproses Pemrosesan XML”. Hampir sama di sini. Instruksi yang berguna untuk mempercepat basis data juga dapat digunakan.
Opsi lain yang sangat menarik adalah mentransfer tugas memfilter data sebagian ke SSD. Sekarang SSD telah menjadi sangat kuat, ini adalah komputer kecil dengan controller, dan pada dasarnya Anda dapat mengunggah kode Anda ke dalamnya jika Anda benar-benar mencobanya. Data Anda akan dibaca dari SSD, tetapi akan segera difilter dan hanya mentransfer data yang diperlukan ke program Anda. Sangat keren, tetapi semua ini masih dalam tahap penelitian. Berikut ini adalah artikel di VLDB, baca.
Selanjutnya, ViyaDB tertentu.

Itu dibuka hanya sebulan yang lalu. "Basis data analitik untuk data yang tidak disortir." Mengapa "tidak disortir" dimasukkan ke dalam nama, tidak jelas mengapa penekanan semacam itu harus dilakukan. Apa, di basis data lain hanya dengan yang diurutkan yang dapat Anda gunakan?
Semuanya baik-baik saja, kode sumber pada GitHub, lisensi Apache 2.0, ditulis dalam C ++ paling modern, semuanya baik-baik saja. Satu pengembang, tetapi tidak ada.

Yang paling saya sukai, di mana Anda bisa mengambil contoh, adalah persiapan peluncuran yang luar biasa. Karena itu, saya terkejut bahwa tidak ada yang mendengar. Ada situs yang luar biasa, ada dokumentasi, ada artikel tentang Habré, ada artikel di Medium, LinkedIn, Hacker News. Jadi apa Apakah semua ini sia-sia? Anda belum melihat semua ini. Di sini mereka berkata, Habr bukan kue. Yah, mungkin, tapi hal yang hebat.
Seperti apa sistem ini?

Data dalam RAM, sistem bekerja dengan data agregat. Pra-agregasi sedang berlangsung. Sistem untuk permintaan analitik. Ada beberapa dukungan SQL awal, tetapi baru mulai dikembangkan, awalnya pertanyaan harus ditulis dalam beberapa jenis JSON. Dari fitur-fitur menarik, Anda memberikan permintaan, dan menulis kode untuk C ++ ke permintaan Anda sendiri, kode ini dihasilkan, dikompilasi, dimuat secara dinamis, dan memproses data Anda. Bagaimana permintaan Anda akan diproses seoptimal mungkin. Kode khusus C ++ khusus ditulis untuk permintaan Anda. Ada penskalaan, dan Konsul digunakan untuk koordinasi. Ini juga merupakan nilai tambah, seperti yang Anda tahu, ini lebih keren daripada ZooKeeper. Atau tidak. Saya tidak yakin, tapi sepertinya ya.
Beberapa tempat dari mana sistem ini berasal agak kontradiktif. Saya penggemar berbagai teknologi, dan saya tidak ingin memarahi siapa pun. Ini hanya pendapat saya, mungkin saya salah.
Premisnya adalah agar dapat secara konstan merekam data baru ke dalam sistem, termasuk secara retroaktif, satu jam yang lalu, sehari yang lalu, peristiwa seminggu yang lalu. Dan pada saat yang sama segera menjalankan kueri analitik pada data ini.

Penulis mengklaim bahwa untuk ini sistem harus dalam memori. Ini tidak benar. Jika Anda tertarik mengapa, Anda dapat membaca artikel "Evolusi struktur data di Yandex.Metrica". Satu orang di ruangan itu sedang membaca.
Tidak perlu menyimpan data dalam RAM. Saya tidak akan mengatakan apa yang perlu dilakukan dan sistem apa yang harus diinstal jika Anda tertarik untuk menyelesaikan masalah ini.

Apa yang bisa kamu pelajari? Solusi arsitektur yang menarik adalah pembuatan kode dalam C ++. Jika Anda tertarik dengan topik ini, Anda dapat memperhatikan proyek penelitian seperti DBToaster. EPFL Institute Research, tersedia di GitHub, Apache 2.0. Scala code, Anda memberikan kueri SQL di sana, kode ini menghasilkan sumber C ++ untuk Anda, yang akan membaca dan memproses data dari suatu tempat dengan cara yang paling optimal. Mungkin, tapi tidak yakin.

Ini hanya satu pendekatan untuk pembuatan kode, untuk pemrosesan permintaan. Ada pendekatan yang bahkan lebih populer - pembuatan kode LLVM. Intinya adalah bahwa program Anda, seolah-olah, secara dinamis menulis kode di Assembler. Yah, tidak juga, di LLVM. Ada MemSQL sebagai contoh. Ini awalnya merupakan basis data OLTP, tetapi juga cocok untuk analitik. Tertutup, eksklusif, C ++ awalnya digunakan di sana untuk pembuatan kode. Kemudian mereka beralih ke LLVM. Mengapa Anda menulis kode C ++, Anda harus mengompilasinya, dan butuh lima detik untuk melakukannya. Dan yah, jika permintaan Anda kurang lebih sama, Anda dapat membuat kode satu kali. Tetapi ketika datang ke analytics, Anda memiliki permintaan ad hoc di sana, dan sangat mungkin bahwa setiap kali mereka tidak hanya berbeda, tetapi bahkan memiliki struktur yang berbeda. Jika pembuatan kode pada LLVM, dibutuhkan milidetik atau puluhan milidetik, berbeda, terkadang lebih.
Contoh lain adalah Impala. Juga menggunakan LLVM. Tetapi jika kita berbicara tentang ClickHouse, ada juga pembuatan kode di sana, tetapi terutama ClickHouse bergantung pada pemrosesan permintaan vektor. Seorang juru bahasa, tetapi bekerja pada array, sehingga bekerja sangat cepat, seperti sistem seperti kdb +.
Contoh menarik lainnya. Logo terbaik dalam ulasan saya.

Sistem manajemen basis data sumber terbuka pertama dan satu-satunya yang dirancang khusus untuk pergudangan data dan intelijen bisnis. Tersedia di GitHub, lisensi Apache 2. Dulu ada GPL, tetapi sudah diubah dan dilakukan dengan benar. Itu ditulis dalam Java. Komit terakhir enam tahun lalu. Awalnya, sistem ini dikembangkan oleh organisasi nirlaba Eigenbase, tujuan organisasi adalah mengembangkan kerangka kerja, basis kode yang dapat diperluas secara maksimal untuk basis data yang tidak hanya OLTP, tetapi misalnya, satu untuk analitik, LucidDB sendiri, dan StreamBase lainnya untuk memproses data streaming.

Apa yang terjadi enam tahun lalu? Arsitektur yang bagus, basis kode yang dapat diperluas dengan baik, lebih dari satu pengembang. Dokumentasi hebat. Tidak ada yang memuat sekarang, tetapi Anda dapat melihatnya melalui WebArchive. Dukungan SQL yang luar biasa.

Tapi ada yang salah. Idenya bagus, tetapi ini dilakukan oleh organisasi nirlaba untuk beberapa sumbangan, dan beberapa startup di dekatnya. Untuk beberapa alasan, semuanya bengkok. Mereka tidak dapat menemukan pembiayaan, tidak ada penggemar, dan semua startup ini ditutup sejak lama.
Tapi tidak sesederhana itu. Semua ini tidak sia-sia.

Ada kerangka kerja semacam itu - Apache Calcite. Ini semacam frontend untuk database SQL. Ia dapat mengurai kueri, menganalisis, melakukan semua jenis transformasi optimasi, menyusun rencana eksekusi kueri, dan menyediakan driver JDBC yang sudah jadi.
Bayangkan Anda tiba-tiba terbangun, suasana hati Anda baik, dan Anda memutuskan untuk mengembangkan DBMS relasional Anda. Anda tidak pernah tahu, itu terjadi. Sekarang Anda dapat mengambil Apache Calcite, Anda hanya perlu menambahkan penyimpanan data, membaca data, memproses query, replikasi, toleransi kesalahan, sharding, semuanya sederhana. Apache Calcite didasarkan pada basis kode LucidDB, yang merupakan sistem canggih sehingga mereka mengambil seluruh frontend dari sana, yang sekarang digunakan dalam bentuk yang sedikit diadaptasi di hampir semua Apache, Hive, Drill, Samza, produk Storm, dan bahkan MapD, terlepas dari kenyataan bahwa itu ditulis dalam C ++, entah bagaimana menghubungkan kode ini di Jawa.

Semua sistem yang menarik ini menggunakan Apache Calcite.
Sistem selanjutnya adalah InfiniDB. Dari nama-nama ini pusing.

Ada Calpont, awalnya InfiniDB sistem berpemilik, dan sedemikian rupa sehingga manajer penjualan menghubungi perusahaan kami dan menjual kami sistem ini. Sangat menarik untuk berpartisipasi dalam ini. Mereka mengatakan bahwa DBMS analitis, hebat, lebih cepat dari Hadoop, berorientasi kolom, tentu saja, semua pertanyaan akan bekerja dengan cepat. Tapi kemudian mereka tidak memiliki cluster, sistem tidak skala. Saya mengatakan bahwa tidak ada cluster - kami tidak dapat membeli. Saya melihat, setelah setengah tahun versi InfiniDB 4.0 dirilis, kami menambahkan integrasi dengan Hadoop, scaling, semuanya baik-baik saja.
Enam bulan telah berlalu, dan kode sumber tersedia dalam sumber terbuka. Saya kemudian berpikir apa yang saya duduki, mengembangkan sesuatu, kita harus menerimanya, ada sesuatu yang siap.
Mereka mulai melihat bagaimana beradaptasi, menggunakan. Setahun kemudian, perusahaan bangkrut. Tetapi kode sumber tersedia.
Ini disebut open-source post-mortem. Dan itu bagus. Jika beberapa perusahaan tidak merasa sangat baik, maka perlu setidaknya beberapa peninggalan tetap ada, sehingga yang lain dapat menggunakannya.

Semuanya sia-sia. Berdasarkan sumber InfiniDB, MariaDB sekarang memiliki mesin tabel yang disebut ColumnStore. Sebenarnya, ini adalah InfiniDB. Perusahaan tidak ada lagi, orang-orang sekarang bekerja di tempat lain, tetapi warisan tetap ada, dan ini luar biasa. Semua orang tahu tentang MariaDB. Jika Anda menggunakannya, dan Anda perlu mempercepat mesin analisis berorientasi kolom dengan cepat, Anda dapat menggunakan ColumnStore. Secara rahasia, saya akan mengatakan ini bukan solusi terbaik. Jika Anda membutuhkan solusi terbaik, maka Anda tahu ke mana harus pergi dan apa yang harus digunakan.
Sistem lain dengan kata Infini dalam namanya. Mereka memiliki logo yang aneh, garis ini sepertinya dibengkokkan. Dan font lain yang tidak bisa dimengerti, untuk beberapa alasan tidak ada antialiasing, seolah-olah dilukis dalam Paint. Dan semua hurufnya besar, mungkin untuk mengintimidasi pesaing.

Saya seorang penggemar semua jenis teknologi, sangat menghormati semua jenis solusi menarik. Saya tidak bercanda, tidak perlu berpikir.
Seperti apa sistem ini? Ini bukan lagi sistem analitis, ini OLTP. Sistem untuk memproses transaksi pada skala ekstrim. Ada sebuah situs, kelebihan dari sistem ini adalah situs tersebut memuat. Karena ketika saya melihat semua yang lain, saya terbiasa dengan kenyataan bahwa akan ada parkir domain atau yang lainnya. Sumber tersedia. Sekarang GPL. Dulu AGPL, tapi untungnya, penulis cepat mengubahnya. Ditulis dalam C ++, lebih dari satu pengembang, diposting ke open source pada November 2013, dan sudah ditinggalkan pada Januari 2014. Satu setengah bulan. Mengapa Apa gunanya Kenapa melakukan ini?

Database OLTP dengan dukungan SQL awal, proyek pribadi, tidak ada perusahaan di belakangnya. Penulis sendiri di Hackers News mengatakan bahwa ia memposting di sumber terbuka dengan harapan menarik penggemar yang akan mengerjakan produk ini.

Harapan ini selalu menemui kegagalan. Anda punya ide, Anda hebat, Anda seorang penggila. Jadi, Anda harus melakukan ide ini. Tidak mungkin orang lain terinspirasi oleh ini. Atau Anda harus bekerja keras untuk menginspirasi seseorang. Jadi sulit untuk berharap bahwa entah dari mana di sisi lain dunia seseorang akan muncul yang akan mulai menambahkan kode orang lain di GitHub.
Kedua, mungkin hanya meremehkan kompleksitas. Pengembangan DBMS bukan petualangan selama 20 menit. Itu sulit, panjang, mahal.
Ini adalah kasus yang sangat menarik, banyak yang telah mendengar RethinkDB. Contoh ini bukan basis analitis, bukan OLTP, tetapi yang berorientasi pada dokumen.

Sistem ini telah mengubah konsepnya berkali-kali. Dipikirkan kembali. Katakanlah pada tahun 2011 ditulis bahwa ini adalah mesin MySQL, yang seratus kali lebih cepat pada SSD, seperti yang ditulis di situs web resmi. Kemudian dikatakan bahwa ini adalah sistem dengan protokol memcached, juga dioptimalkan untuk SSD. Dan setelah beberapa saat, itu adalah basis data untuk aplikasi waktu nyata. Yaitu, untuk berlangganan data dan menerima pembaruan secara langsung dalam waktu nyata. Katakanlah semua jenis obrolan interaktif, game online. Upaya menemukan ceruk. -, JSON. MongoDB. . MongoDB , ? MongoDB . , , «PostgreSQL ».
? — . . , .
RethinkDB? , RAFT. , , , . JSON, - LINQ . ReQL, ++, , ++.

. . , , , , . , , . 20938 GitHub. - .

, , , , , . Mengapa ?

, 2009 , , , . , , 2016 . , , , . , , RethinkDB, , , The Linux Foundation. AGPL Apache 2, . , — .

, , , , , , . , .
, , . , - , , , , .
. , , . , XML 15 .
- , 2000-, . , XML . - - , . , .

, Sedna. XML , . , . , . , Sedna, , , , . , .
2013, , . XML , , .
— .
— , , . garret.ru, , . , . , , , . .

. 2014 — IMCS, PostgreSQL, . PostgreSQL, SQL, , . select, . -, . , , , . , . , , , - . , .
, - ? .

, , ? , — . : , - , . , . .
— . , , . , , .
— . , -. - , — , , , -.
, , , .
— , ? , - .
, , . . , , , .
— - - . -, KPHP.
— . , , , .

, , : , , , ? — . , . , . ? : , .
. , , . , .
. , - , , multimodel DB, , , OLTP, , , , . , ? , , - . - -, , , , . , .
Dukungan perusahaan induk yang dapat diandalkan. Tidak ada komentar. Bukan lisensi yang membatasi, sehingga perusahaan lain tidak menakut-nakuti departemen hukum, orang-orang ini takut akan segalanya. Manfaat sistem Anda harus berasal dari alasan mendasar. Katakanlah, jika Anda memiliki database untuk pemrosesan XML, ini entah bagaimana tidak terlalu baik. Mungkin tidak ada orang lain yang perlu menyimpan data dalam XML. Dan jika Anda memiliki basis data berorientasi dokumen, itu yang lain. Semua orang perlu menyimpan dokumen, dan tidak peduli apa tepatnya. Selain itu, dukungan untuk pengembangan masyarakat sangat penting untuk sumber terbuka yang baik. Ini berarti Anda tidak hanya perlu menahan permintaan tarik. Ini berarti - Anda perlu orang untuk merasa bahwa Anda, Anda ada, menjawab pertanyaan, produk sedang berkembang. Inilah yang akan menjadikan open source yang bagus dan hidup. Itu saja, terima kasih.