Beberapa bulan yang lalu, di salah satu retrospektif, kami memutuskan untuk mencoba membaca bersama.
Format kami:
- Pilih buku.
- Kami menentukan bagian yang perlu dibaca dalam seminggu. Pilih volume kecil.
- Pada hari Jumat, kami mendiskusikan apa yang kami baca.
- Kami membaca selama jam non-kerja, membahas selama jam kerja.
- Setelah menyelesaikan buku, kami bersama-sama memilih yang berikut.
Apa yang memberi:
- Motivasi membaca dan membaca.
- Pengembangan keterampilan (termasuk untuk masa depan).
- Penyelarasan pola pikir dan terminologi dalam sebuah tim.
- Tumbuhnya kepercayaan.
- Alasan lain untuk berbicara.
Salah satu buku terbaru yang kita baca adalah
Merancang Aplikasi Intensif Data . Ya, buku yang sama dengan babi. Dan semua orang sangat menyukai buku ini sehingga saya memutuskan untuk memeriksanya di sini sehingga lebih banyak orang membacanya.
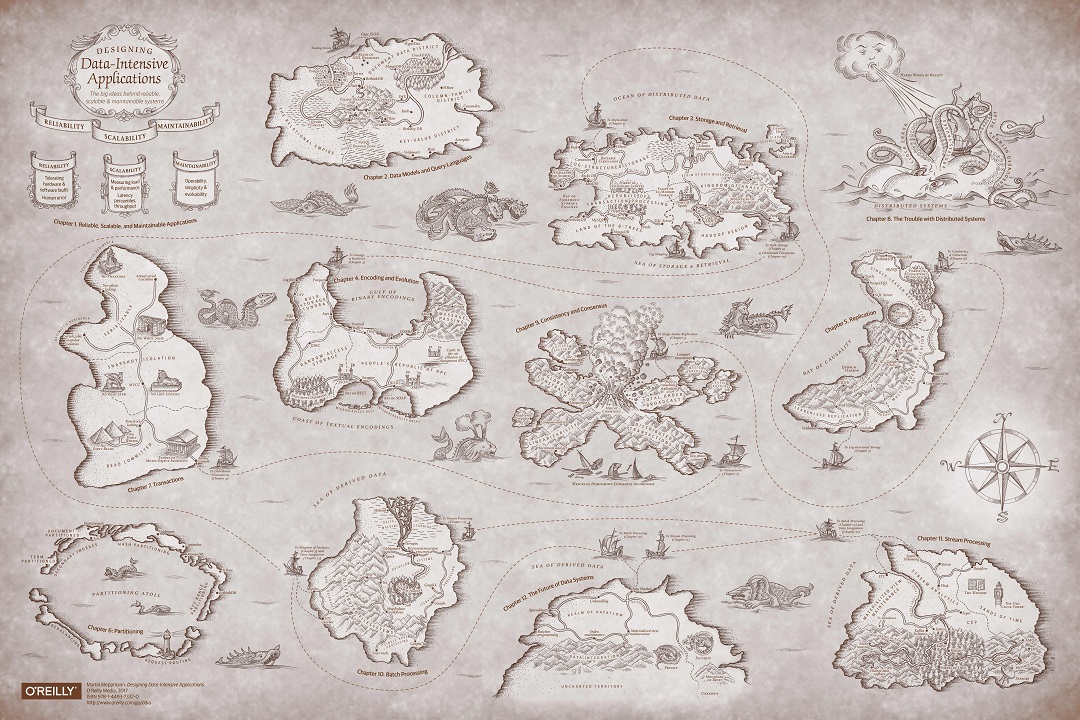 Peta dalam kualitas asli
Peta dalam kualitas asliAda terjemahan buku ini ke dalam bahasa Rusia dari Penerbit Peter. Tapi kami membaca dalam bahasa aslinya, jadi saya tidak berjanji bahwa terjemahan dari ketentuan akan cocok. Selain itu, kami sengaja tidak menerjemahkan bagian dari ketentuan.
Bagian awal buku ini dikhususkan untuk dasar-dasar sistem pemrosesan data.
Bab pertama menunjukkan bahwa sifat penting dari sistem tersebut adalah keandalan, skalabilitas, dan kemudahan perawatan.
Bab kedua menjelaskan berbagai model data. DBMS relasional dan berorientasi dokumen yang biasa, serta basis data grafik dan kolom yang kurang dikenal dijelaskan.
Bab-bab pertama up to date, menetapkan ruang lingkup buku. Di banyak tempat di bawah ini, penulis merujuk pada bab-bab pertama. Dalam keadilan, kita dapat mengatakan bahwa buku ini penuh dengan referensi silang.
Apa yang mengejutkan dari bab pertama adalah jumlah sumber (ada bibliografi setelah setiap bab). Tautan ke banyak artikel (baik blog maupun ilmiah) dan buku disusun dengan cermat di semua bab. Jumlah sumber untuk beberapa bab melebihi seratus.
Bab ketiga dimulai dengan kode sumber dari penyimpanan nilai kunci paling sederhana:
Ini bahkan akan berhasil, sangat bagus dalam menulis, tetapi, tentu saja, bukan tanpa masalah membaca.
Dan segera, opsi untuk meningkatkan kinerja ditawarkan. Menjelaskan indeks hash, SSTable, b-tree, dan LSM-tree. Semua ini dijelaskan di jari, tetapi ditunjukkan bagaimana struktur ini atau itu digunakan dalam database yang sudah dikenal.
Fokus pada latihan adalah ciri khas lain dari buku ini. Kebanyakan contoh dan resep sangat praktis sehingga saya menemukan hampir semua yang relevan.
Bab keempat menjelaskan pengodean: dari JSON dan XML biasa ke Protobuf dan AVRO. Kami tidak selalu memilih format secara sadar, biasanya dipaksakan oleh satu atau lain teknologi secara keseluruhan. Tapi itu keren untuk memahami cara kerjanya di dalam, apa kekuatan dan kelemahan format.
Penulis tidak secara khusus menggunakan istilah serialisasi, karena istilah ini memiliki satu makna lagi dalam database.
Isi bab-bab ini jauh lebih kaya daripada presentasi singkat saya. Bagian pertama juga menjelaskan perbedaan antara OLTP dan OLAP, bagaimana pencarian teks lengkap dan pencarian di database kolom, REST, dan broker pesan diatur.
Bagian kedua dari buku ini berbicara tentang sistem pemrosesan data terdistribusi. Hampir semua sistem modern yang lebih atau kurang dimuat memiliki beberapa replika atau subsistem (layanan mikro).
Ketika kami pertama kali mulai berlatih membaca bersama, kami hanya mendiskusikan catatan, tempat menarik, dan pemikiran kami. Pada titik tertentu, kami menyadari bahwa kami tidak memiliki cukup percakapan, setelah diskusi semuanya cepat dilupakan. Kemudian kami memutuskan untuk memperkuat latihan kami dan menambahkan isian peta pikiran. Inovasi baru saja buku ini. Mulai dari bagian kedua, kami mulai mempertahankan peta pikiran untuk setiap bab. Karena itu, lebih jauh setiap bab akan ada dengan peta pikiran kita. Kami menggunakan coggle.it
Bab kelima menjelaskan replikasi.
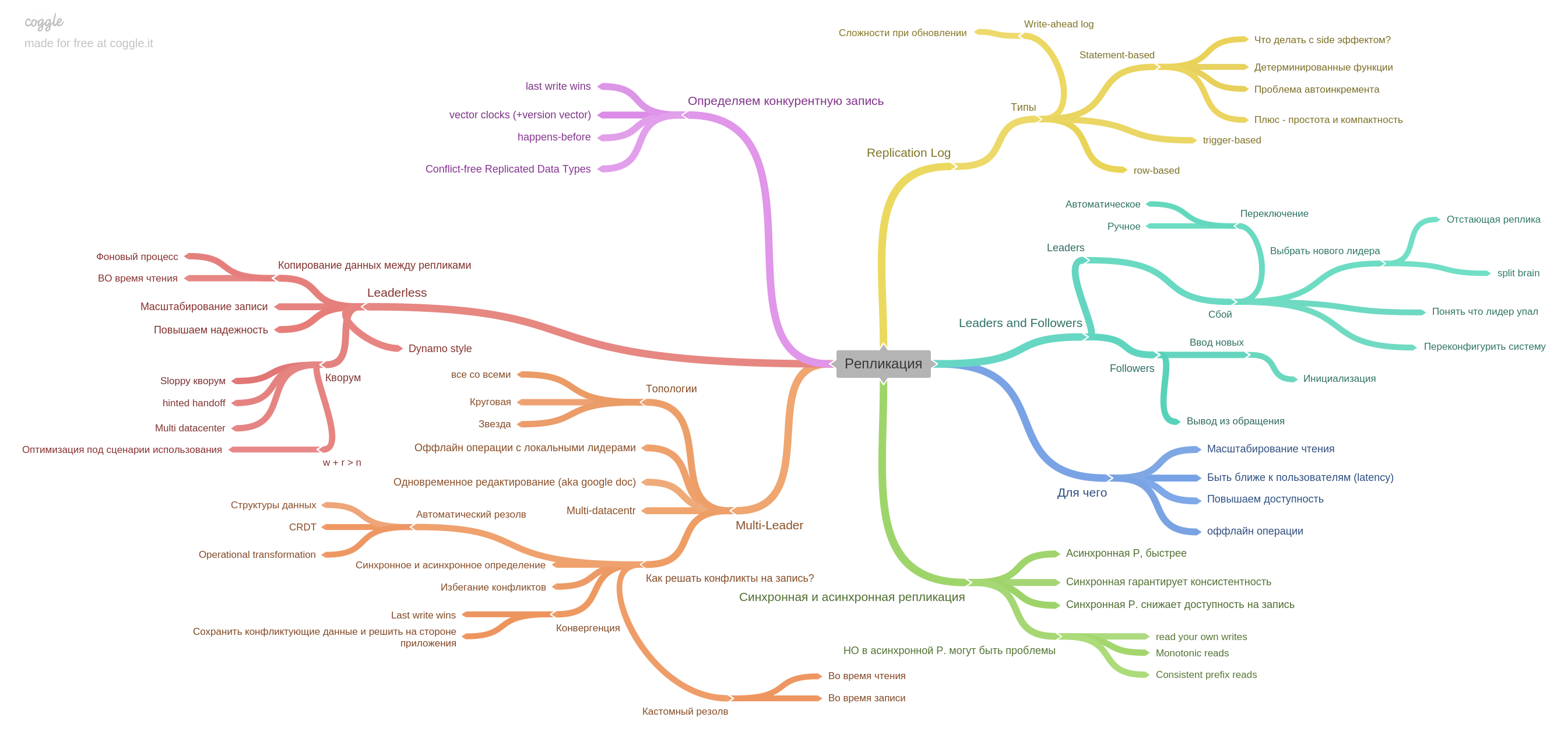
Di sini dikumpulkan semua informasi dasar tentang replika: master tunggal, multimaster, log replikasi, dan cara hidup dengan catatan kompetitif dalam sistem tanpa pemimpin.
Bab keenam menjelaskan tentang partisi (alias sharding dan banyak istilah lainnya).
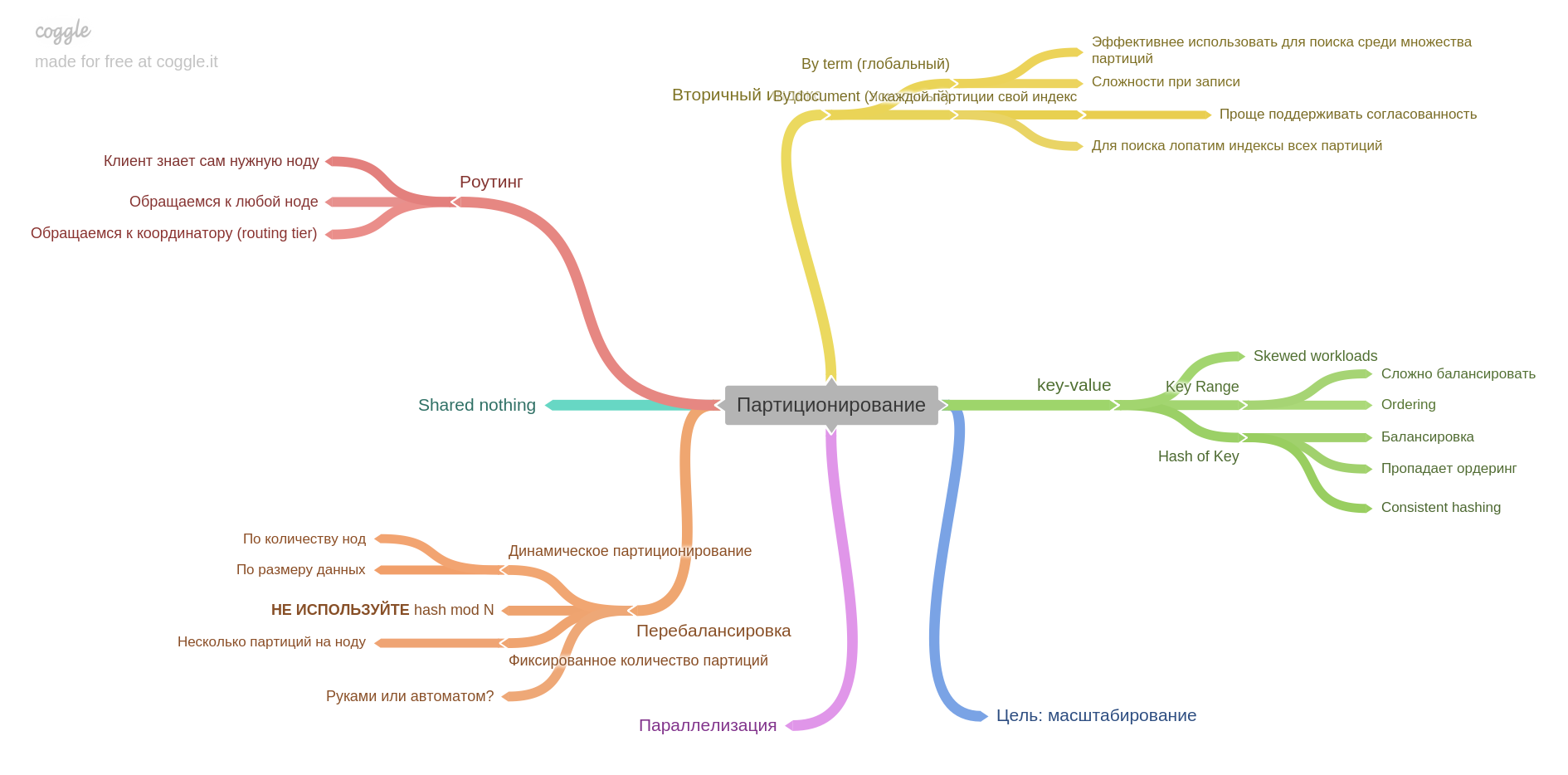
Anda akan belajar cara memecah data menjadi pecahan, masalah apa yang bisa dipecahkan dan mana yang harus didapatkan, cara membuat indeks dan menyeimbangkan data.
Bab ketujuh : transaksi.
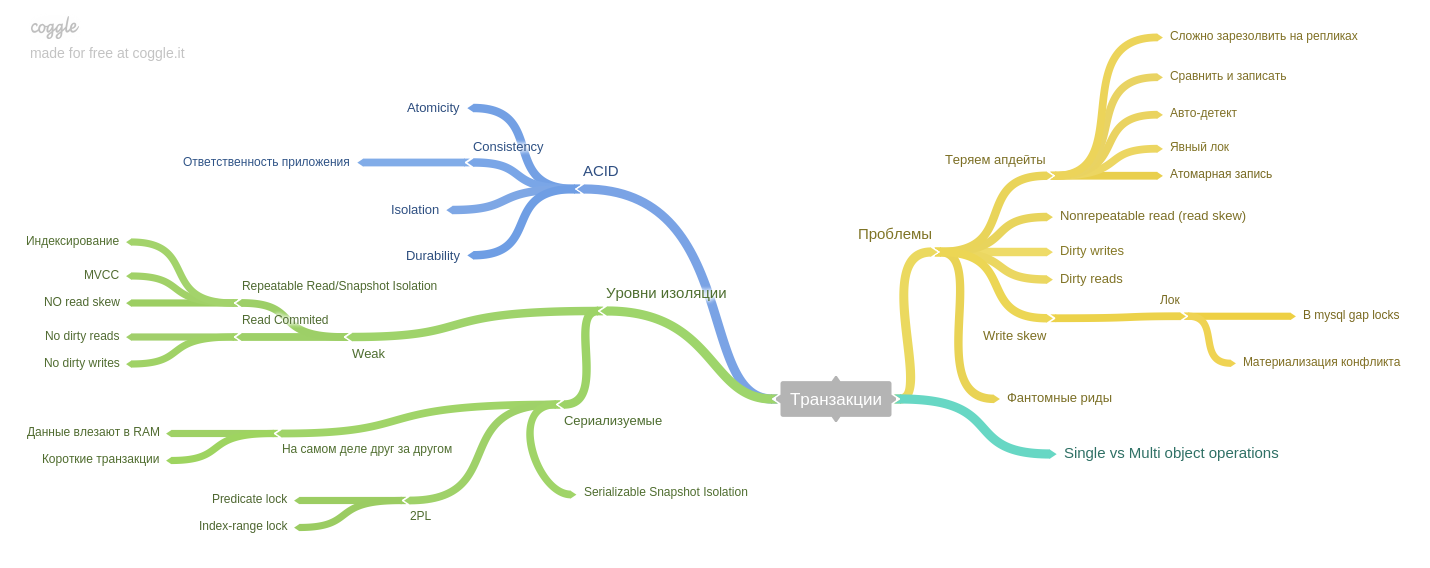
Fenomena (baca miring, tulis miring, membaca hantu, dll) dijelaskan dan bagaimana tingkat isolasi database gaya ACID membantu untuk menghindari masalah.
Bab kedelapan: tentang masalah khusus untuk sistem terdistribusi.
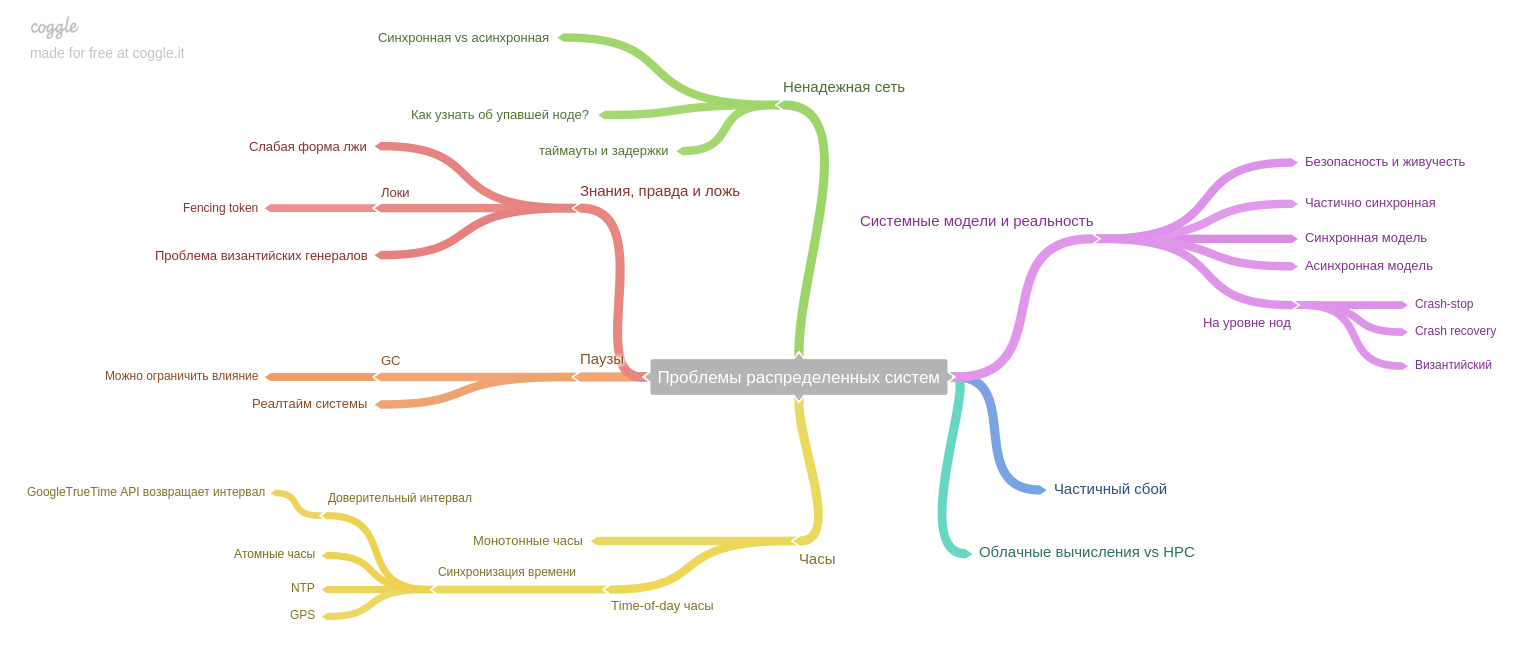
Penulis menekankan ide penting: jika sebelumnya sistem bekerja pada satu mesin, dan jika terjadi kegagalan seluruh sistem berhenti bekerja (dan menerima data baru). Dengan demikian, data setelah kegagalan tetap dalam keadaan konsisten, tetapi hari ini, di era replika dan layanan mikro, hanya sebagian dari sistem yang dimatikan. Dengan demikian, kami menghadapi masalah baru: memastikan konsistensi data dalam kondisi kegagalan parsial, masalah terus-menerus dengan jaringan yang tidak dapat diandalkan, dll.
Bab kesembilan menjelaskan koherensi dan konsensus dan memperkenalkan konsep penting: linierabilitas. Saya ingat kepala itu keras dan pas di kepala saya)
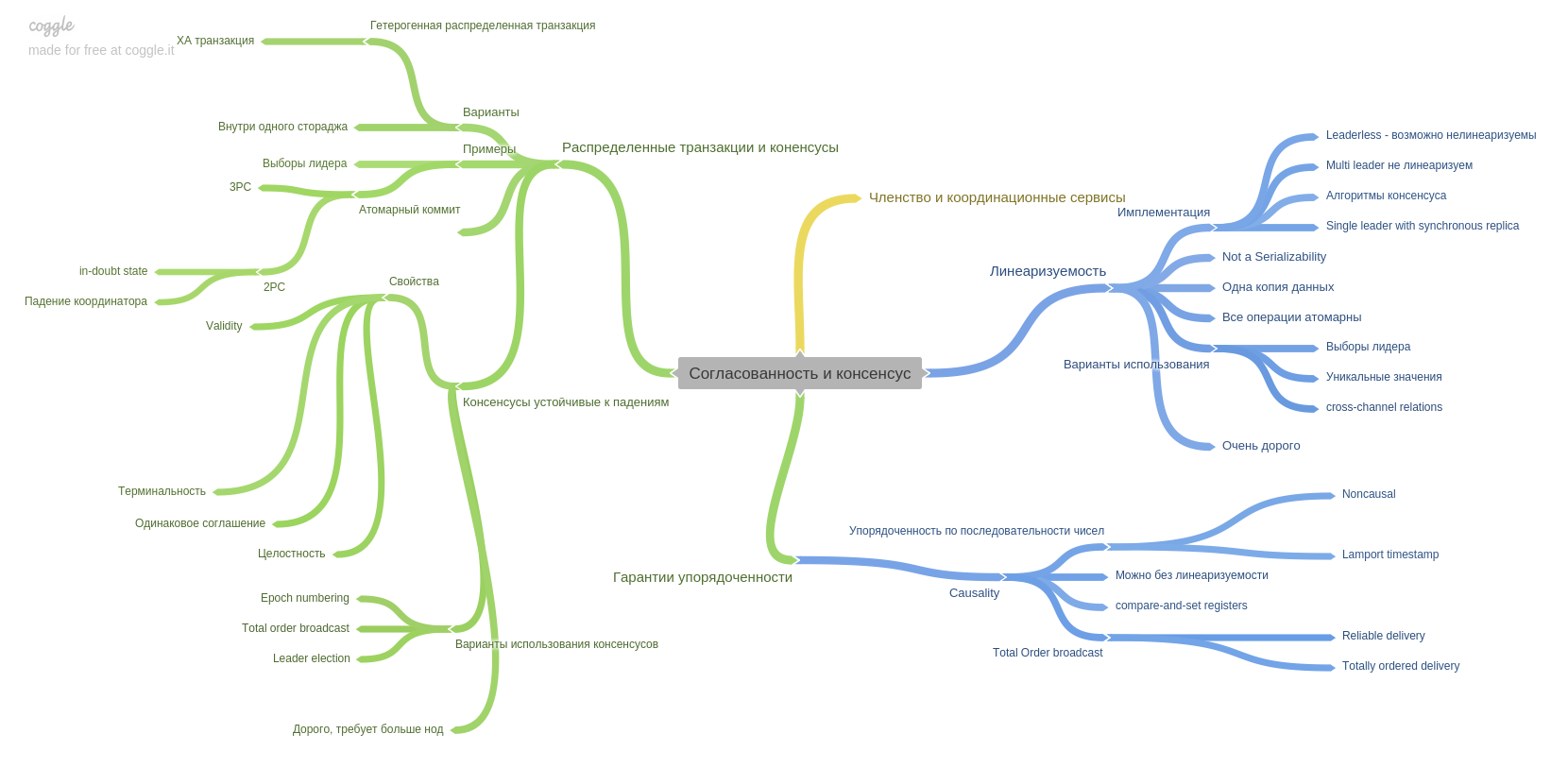
Bab ini juga menjelaskan teknik komit dua fase dan titik lemahnya. Juga dalam bab ini Anda akan membaca tentang jaminan ketertiban. Bagaimana dan apa yang dapat diberikan sistem modern kepada Anda.
Bagian ketiga dari buku ini dikhususkan untuk data turunan (tidak ada terjemahan yang ditetapkan). Akibatnya, penulis menyuarakan gagasan bahwa semua indeks, tabel, tampilan terwujud hanya merupakan cache di atas log. Hanya log yang berisi data yang paling relevan, yang lainnya terlambat dan digunakan untuk kenyamanan.
Bab kesepuluh.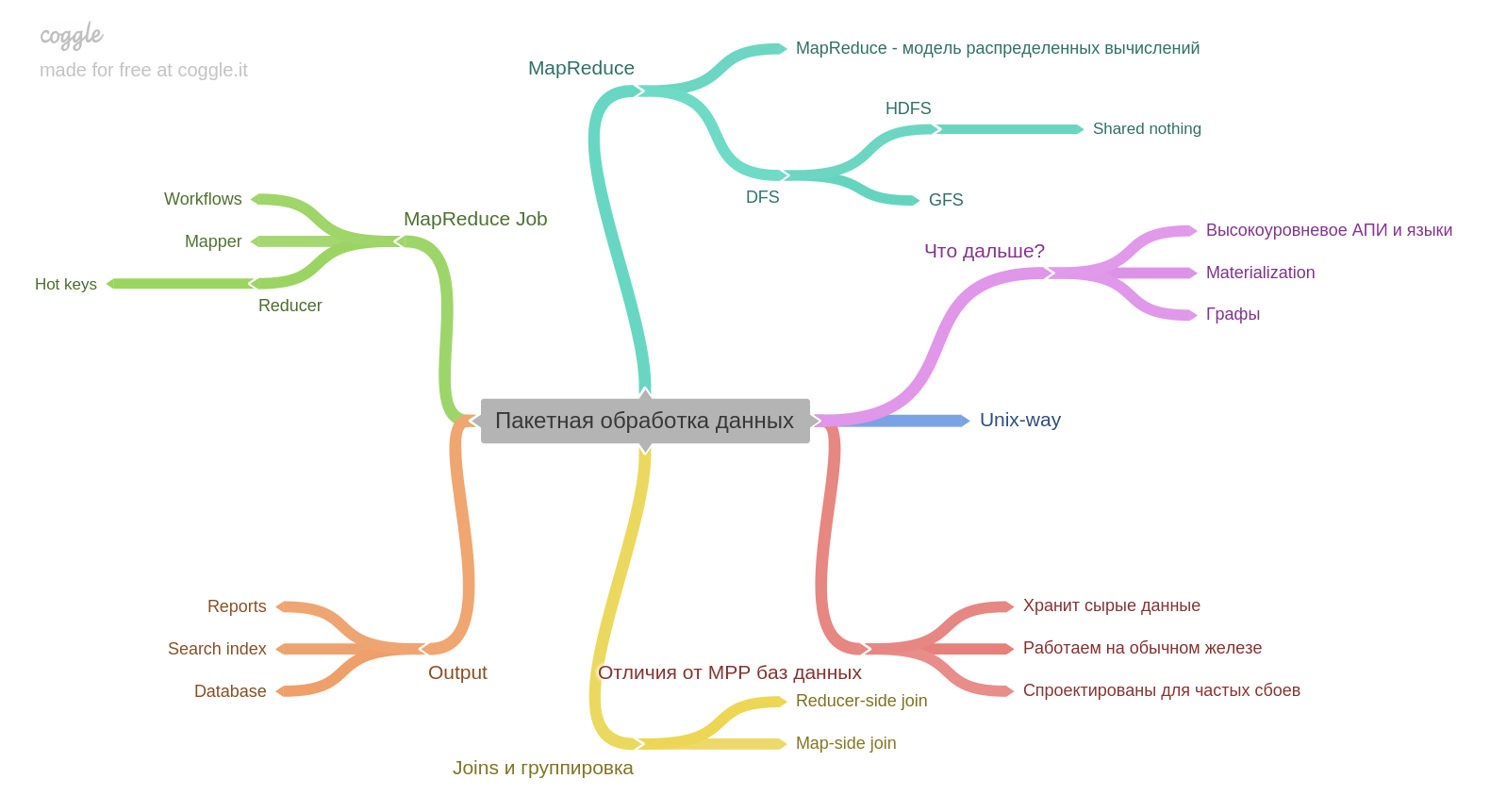
Jika Anda memiliki pengalaman dengan Hadoop atau MapReduce, mungkin Anda akan belajar sedikit hal baru. Tetapi saya tidak bekerja dan itu sangat menarik. Poin penting bagi saya - hasil pemrosesan batch itu sendiri dapat menjadi dasar untuk database lain.
Bab 11. Streaming pemrosesan data.
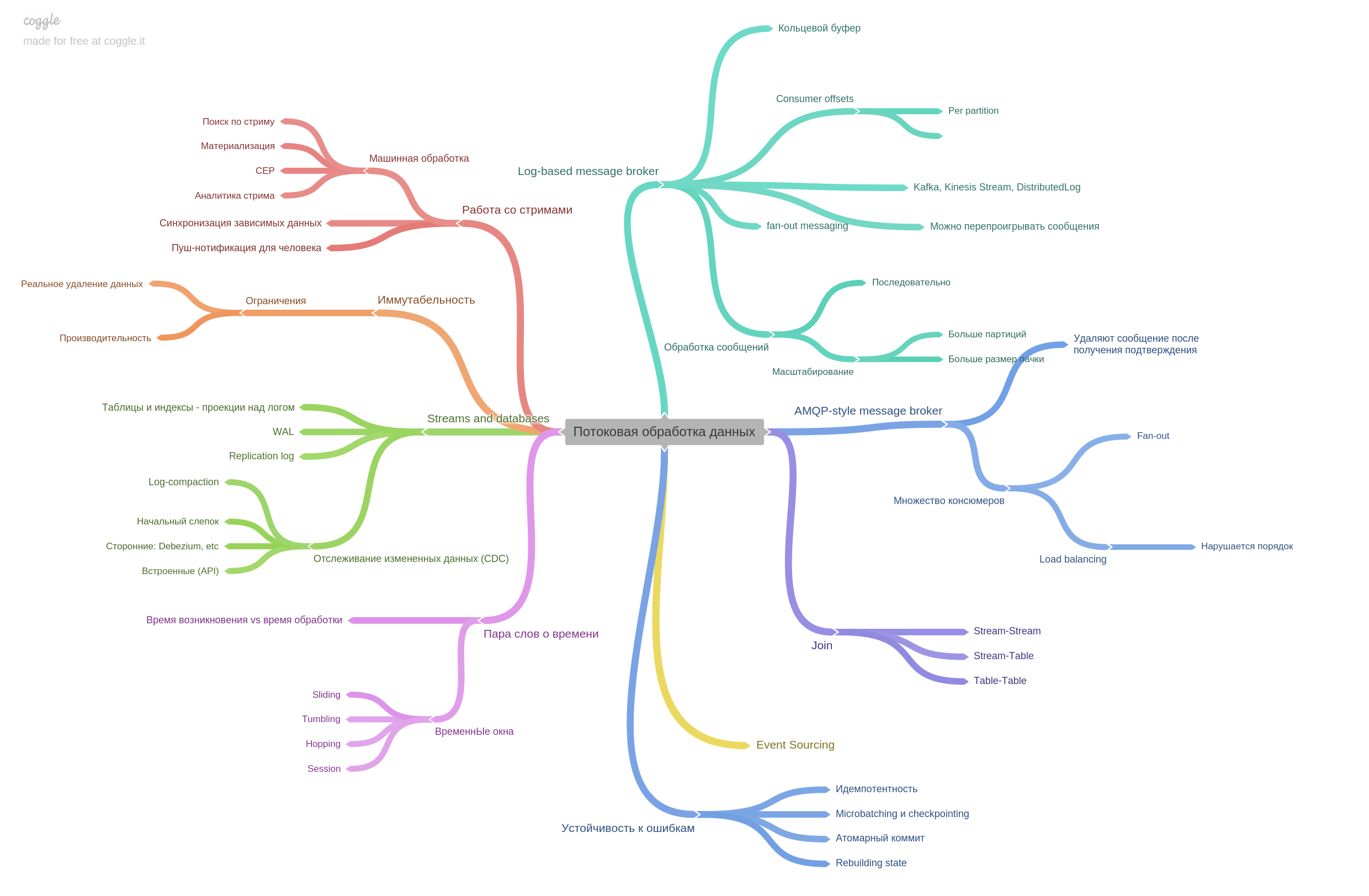
Pialang pesan dijelaskan dan bagaimana gaya AMPQ berbeda dari berbasis log. Bahkan, bab ini berisi banyak informasi lainnya. Sangat menarik untuk dibaca.
Bab terakhir adalah tentang masa depan. Apa yang diharapkan, apa yang dipikirkan oleh para peneliti dan insinyur.
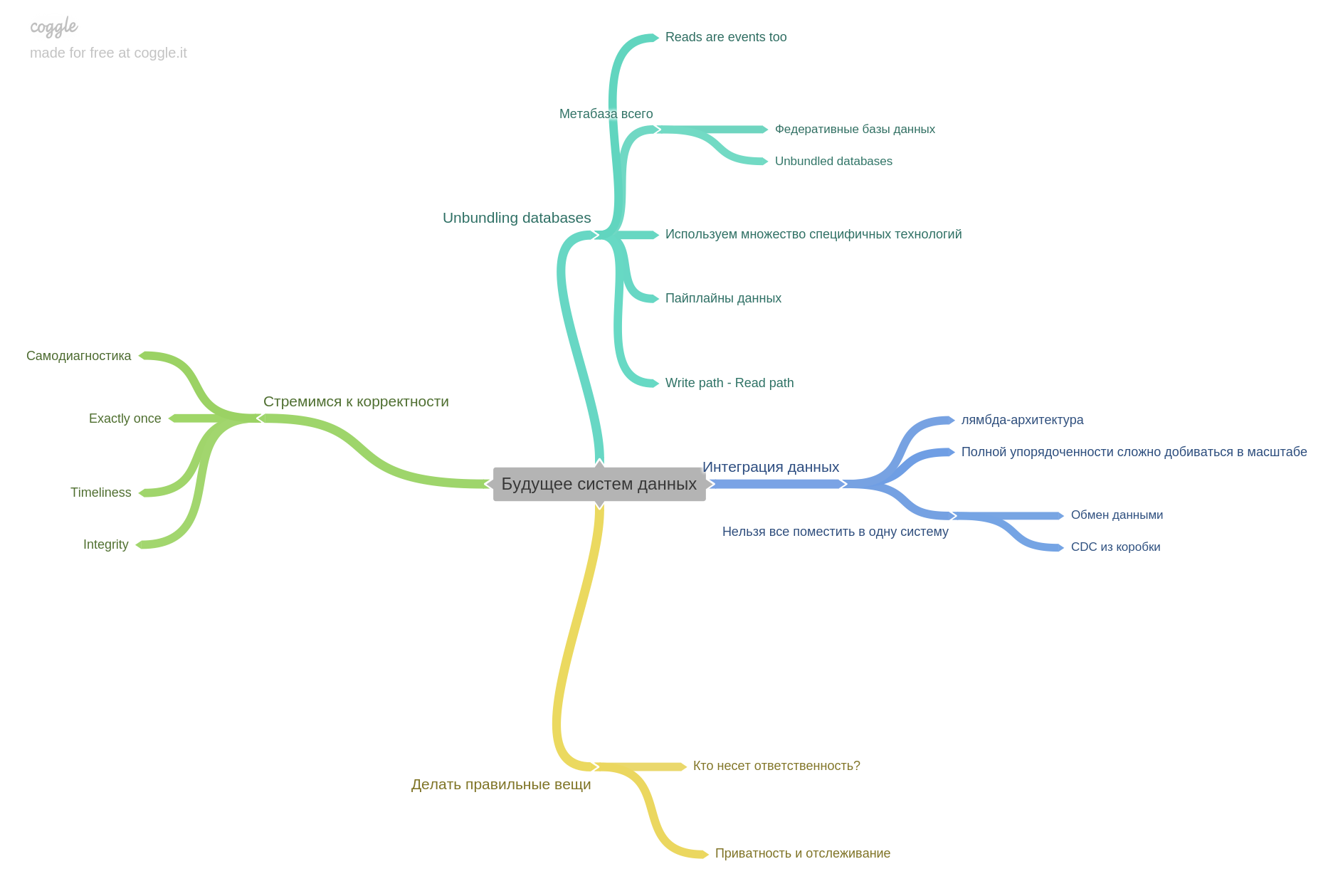
Ini menyimpulkan ulasan saya. Penting untuk dipahami bahwa saya hanya membuat sebagian dari tesis untuk setiap bab. Buku ini memiliki konten yang sangat padat sehingga tidak mungkin untuk secara singkat, tetapi menceritakan kembali sepenuhnya.
Secara pribadi, saya pikir buku ini adalah teknis terbaik dalam beberapa tahun terakhir. Saya sangat merekomendasikan membacanya. Dan tidak hanya membaca, tetapi bekerja keras. Ikuti tautan dari daftar pustaka, mainkan dengan DBMSs yang sebenarnya.
Setelah membaca buku ini, Anda dapat dengan mudah menjawab banyak pertanyaan dalam wawancara basis data teknis. Tapi ini bukan intinya. Anda akan menjadi lebih keren sebagai pengembang, Anda akan mengetahui struktur internal, kekuatan dan kelemahan dari berbagai database dan berpikir tentang masalah sistem terdistribusi.
Saya siap membahas dalam komentar baik buku itu sendiri maupun praktik membaca bersama.
Baca buku!