 Enam bulan lalu, kami menyelesaikan migrasi semua layanan tanpa kewarganegaraan kami ke kubernetes. Sekilas, tugasnya cukup sederhana: Anda perlu menggunakan cluster, menulis spesifikasi aplikasi dan menjalankannya. Karena obsesi untuk memastikan stabilitas dalam pekerjaan layanan kami, saya harus segera mulai memahami cara kerja k8 dan menguji berbagai skenario kegagalan. Sebagian besar pertanyaan yang saya miliki tentang segala sesuatu yang berkaitan dengan jaringan. Salah satu masalah yang licin adalah pengoperasian Layanan di kubernetes.
Enam bulan lalu, kami menyelesaikan migrasi semua layanan tanpa kewarganegaraan kami ke kubernetes. Sekilas, tugasnya cukup sederhana: Anda perlu menggunakan cluster, menulis spesifikasi aplikasi dan menjalankannya. Karena obsesi untuk memastikan stabilitas dalam pekerjaan layanan kami, saya harus segera mulai memahami cara kerja k8 dan menguji berbagai skenario kegagalan. Sebagian besar pertanyaan yang saya miliki tentang segala sesuatu yang berkaitan dengan jaringan. Salah satu masalah yang licin adalah pengoperasian Layanan di kubernetes.
Dokumentasi memberi tahu kami:
- jalankan aplikasi
- mengatur sampel liveness / kesiapan
- buat layanan
- maka semuanya akan bekerja: load balancing, failover, dll.
Namun dalam praktiknya, semuanya agak lebih rumit. Mari kita lihat bagaimana cara kerjanya.
Sedikit teori
Lebih jauh, maksud saya bahwa pembaca sudah terbiasa dengan perangkat kubernetes dan terminologinya, kita hanya ingat apa layanan itu.
Layanan adalah inti dari k8s, yang menggambarkan seperangkat perapian dan metode untuk mengaksesnya.
Misalnya, kami meluncurkan aplikasi kami:
apiVersion: apps/v1 kind: Deployment metadata: name: webapp spec: selector: matchLabels: app: webapp replicas: 2 template: metadata: labels: app: webapp spec: containers: - name: webapp image: defaultxz/webapp command: ["/webapp", "0.0.0.0:80"] ports: - containerPort: 80 readinessProbe: httpGet: {path: /, port: 80} initialDelaySeconds: 1 periodSeconds: 1
$ kubectl get pods -l app=webapp NAME READY STATUS RESTARTS AGE webapp-5d5d96f786-b2jxb 1/1 Running 0 3h webapp-5d5d96f786-rt6j7 1/1 Running 0 3h
Sekarang, untuk mengaksesnya, kita harus membuat layanan di mana kita menentukan saluran mana yang ingin kita akses (pemilih) dan di port mana:
kind: Service apiVersion: v1 metadata: name: webapp spec: selector: app: webapp ports: - protocol: TCP port: 80 targetPort: 80
$ kubectl get svc webapp NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE webapp ClusterIP 10.97.149.77 <none> 80/TCP 1d
Sekarang kita dapat mengakses layanan kami dari mesin apa pun di kluster:
curl -i http://10.97.149.77 HTTP/1.1 200 OK Date: Mon, 24 Sep 2018 11:55:14 GMT Content-Length: 2 Content-Type: text/plain; charset=utf-8
Bagaimana cara kerjanya?
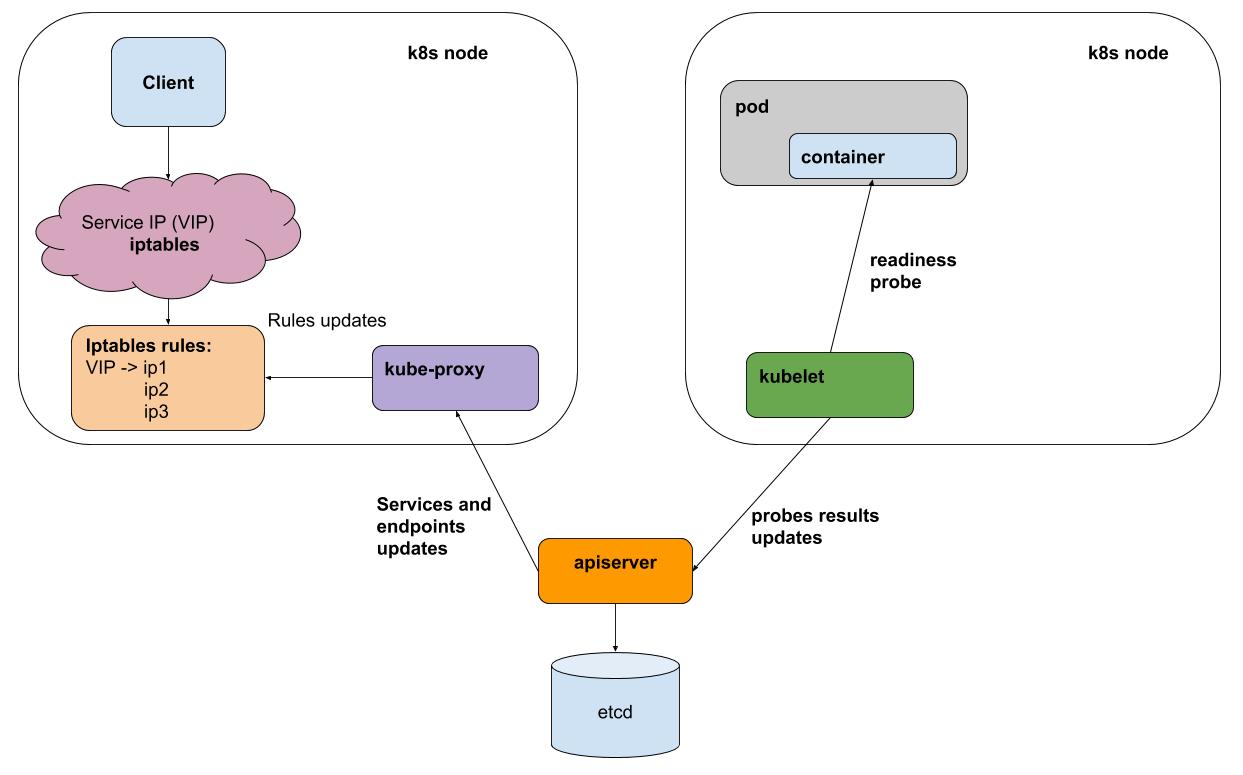
Sangat disederhanakan:
- Anda sudah kubectl menerapkan spesifikasi Penerapan
- keajaiban terjadi, rinciannya tidak penting dalam konteks ini
- sebagai hasilnya, simpul-simpul aplikasi yang berfungsi ternyata ada pada beberapa simpul
- sekali setiap interval kubelet (agen k8s pada setiap node) melakukan sampel liness / readiness dari semua pod yang berjalan pada node-nya, ia mengirimkan hasilnya ke apiserver (antarmuka ke otak k8s)
- kube-proxy pada setiap node menerima pemberitahuan dari apiserver tentang semua perubahan dalam layanan dan perapian yang berpartisipasi dalam layanan
- kube-proxy mencerminkan semua perubahan dalam konfigurasi subsistem yang mendasarinya (iptables, ipvs)
Untuk mempermudah, pertimbangkan metode proxy default - iptables. Di iptables, kami memiliki untuk ip virtual kami 10.97.149.77:
-A KUBE-SERVICES -d 10.97.149.77/32 -p tcp -m comment --comment "default/webapp: cluster IP" -m tcp --dport 80 -j KUBE-SVC-BL7FHTIPVYJBLWZN
lalu lintas menuju ke rantai KUBE-SVC-BL7FHTIPVYJBLWZN , di mana ia didistribusikan di antara 2 rantai lainnya
-A KUBE-SVC-BL7FHTIPVYJBLWZN -m comment --comment "default/webapp:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-UPKHDYQWGW4MVMBS -A KUBE-SVC-BL7FHTIPVYJBLWZN -m comment --comment "default/webapp:" -j KUBE-SEP-FFCBJRUPEN3YPZQT
ini adalah pod kami:
-A KUBE-SEP-UPKHDYQWGW4MVMBS -p tcp -m comment --comment "default/webapp:" -m tcp -j DNAT --to-destination 10.244.0.10:80 -A KUBE-SEP-FFCBJRUPEN3YPZQT -p tcp -m comment --comment "default/webapp:" -m tcp -j DNAT --to-destination 10.244.0.11:80
Menguji kegagalan salah satu perapian
Aplikasi pengujian webapp saya dapat beralih ke mode "ruam kesalahan", untuk ini Anda perlu menarik URL "/ err".
Hasil dari ab -c 50 -n 20.000 di tengah-tengah tes menarik "/ err" pada salah satu perapian:
Complete requests: 20000 Failed requests: 3719
Intinya di sini bukanlah jumlah kesalahan spesifik (jumlah mereka akan bervariasi tergantung pada beban), tetapi itu adalah. Secara umum, kami melemparkan "buruk" di bawah keseimbangan, tetapi pada saat beralih klien layanan menerima kesalahan. Penyebab kesalahan cukup mudah untuk dijelaskan: tes kesiapan dilakukan kubelet sekali per detik + bahkan waktu yang singkat untuk menyebarkan informasi yang di bawah tidak menanggapi tes.
Akankah backend IPVS untuk proxy kubus (percobaan) membantu?
Tidak juga! Ini memecahkan masalah optimasi proxy, menawarkan algoritma penyeimbang kustom, tetapi tidak memecahkan masalah pemrosesan kegagalan.
Bagaimana menjadi
Masalah ini hanya bisa diselesaikan oleh penyeimbang yang bisa mencoba lagi (coba lagi). Dengan kata lain, untuk http kita membutuhkan penyeimbang L7. Penyeimbang seperti itu untuk kubernet sudah digunakan penuh baik dalam bentuk masuknya (tersirat sebagai titik dalam perpindahan ke cluster, tetapi pada umumnya ia melakukan persis apa yang dibutuhkannya), atau sebagai implementasi dari lapisan terpisah - sebuah service mesh, misalnya, istio .
Dalam produksi kami, kami belum mulai menggunakan ingress atau service mesh karena kerumitan tambahan. Abstraksi semacam itu, menurut pendapat saya, membantu dalam kasus di mana Anda perlu sering mengkonfigurasi sejumlah besar layanan. Tetapi pada saat yang sama Anda "membayar" pengendalian dan infrastruktur sederhana. Anda akan menghabiskan waktu ekstra untuk mencari tahu cara mengatur rertai dan waktu tunggu untuk layanan tertentu.
Bagaimana kita
Kami menggunakan layanan k8 tanpa kepala. Layanan tersebut tidak memiliki ip virtual dan, karenanya, proxy-kubus dan iptables tidak terlibat dalam pekerjaan mereka. Untuk setiap layanan seperti itu, Anda bisa mendapatkan daftar perapian langsung baik melalui DNS atau melalui API.
Untuk aplikasi yang berinteraksi dengan layanan lain, kami membuat wadah sespan dengan utusan . Evoy secara berkala menerima daftar pod terbaru untuk semua layanan yang diperlukan melalui DNS, dan yang paling penting, ia dapat melakukan upaya berulang-ulang untuk menanyakan pod lain jika terjadi kesalahan. Anda bisa menjalankannya sebagai DaemonSet pada setiap node, tetapi kemudian jika instance ini gagal, semua aplikasi yang menggunakannya akan berhenti bekerja. Karena konsumsi sumber daya oleh proksi ini cukup kecil, kami memutuskan untuk menggunakannya dalam varian wadah sespan.
Ini pada dasarnya persis apa yang dilakukan istio, tetapi dalam kasus kami keseimbangan telah bergeser ke kesederhanaan (tidak perlu belajar istio, mengalami bug). Mungkin keseimbangan ini akan berubah, dan kami akan mulai menggunakan sesuatu seperti istio.
Kami di okmeter.io kubernetes jelas-jelas berakar, dan kami percaya pada distribusinya lebih lanjut. Dukungan untuk memantau k8 di layanan kami sedang dalam perjalanan, tetap disini!