Halo semuanya!
Hari ini saya akan memberi tahu Anda bagaimana kami di
hh.ru mempertimbangkan statistik manual tentang eksperimen. Kami akan melihat dari mana data berasal, bagaimana kami memprosesnya, dan apa jebakan yang kami temui. Pada artikel ini saya akan membagikan arsitektur dan pendekatan umum, akan ada minimum skrip dan kode nyata. Audiens utama adalah analis pemula yang tertarik pada struktur infrastruktur analisis data di hh.ru. Jika topik ini menarik - tulis di komentar, kita dapat mempelajari kode di artikel berikut.
Anda dapat membaca tentang bagaimana metrik otomatis untuk percobaan A / B dipertimbangkan dalam
artikel kami yang
lain .

Data apa yang kami analisis dan dari mana mereka berasal
Kami menganalisis log akses dan log kustom apa pun yang kami tulis sendiri.
95.108.213.12 - - [13 / Agustus / 2018: 04: 00: 02 +0300] 200 "GET / perusahaan / 2574971 HTTP / 1.1" 12012 "-" "Mozilla / 5.0 (kompatibel; YandexBot / 3.0; + http: / /yandex.com/bots) "" - "" gardabani.headhunter.ge "" 0,063 "-" "1534122002.858" - "" 192.168.2.38:1500 "" [0,064] "{15341220027959c8c01c51a6e01b682f} 200 https 1 -" - "- - [35827] [0,000 0]
178.23.230.16 - - [13 / Agustus / 2018: 04: 00: 02 +0300] 200 "GET / lowongan / 24266672 HTTP / 1.1" 24229 " hh.ru/vacancy/24007186?query=bmw " "Mozilla / 5.0 ( Macintosh; Intel Mac OS X 10_10_5) AppleWebKit / 603.3.8 (KHTML, seperti Gecko) Versi / 10.1.2 Safari / 603.3.8 "-" "hh.ru" "0,210" "last_visit = 1534111115966 :: 1534121915966; hhrole = anonim; daerah = 1; tmr_detect = 0% 7C1534121918520; total_searches = 3; unique_banner_user = 1534121429.273825242076558 "" 1534122002.859 "" - "" 192.168.2.239:1500 "" [0,208] "{1534122002649b7eef2e901d8c9c0469} 200 https 1 -" - "- [0]
Dalam arsitektur kami, setiap layanan menulis log secara lokal, dan kemudian melalui log client-server yang ditulis sendiri (termasuk log akses nginx) dikumpulkan pada repositori pusat (selanjutnya dicatat). Pengembang memiliki akses ke mesin ini dan secara manual dapat mencatat log jika perlu. Tetapi bagaimana, dalam waktu yang wajar, dapat melahap beberapa ratus gigabytes kayu gelondongan? Tentu saja, tuangkan ke dalam hadoop!
Dari mana data berasal dari hadoop?
Hadoop tidak hanya menyimpan log layanan, tetapi juga mengunggah basis data prod. Setiap hari di hadoop kami mengunggah beberapa tabel yang diperlukan untuk analitik.
Log layanan masuk ke hadoop dalam tiga cara.
- Jalan menuju dahi - cron diluncurkan dari penyimpanan log di malam hari, dan rsync mengunggah log mentah ke hdfs.
- Caranya modis - log dari layanan dituangkan tidak hanya ke penyimpanan umum, tetapi juga di kafka, di mana flume membacanya, melakukan preprocessing dan menyimpannya dalam hdfs.
- Jalannya kuno - pada hari-hari sebelum kafka, kami menulis layanan kami sendiri, yang membaca log mentah dari penyimpanan, membuatnya dari preprocessing, dan mengunggahnya ke hdfs.
Mari kita pertimbangkan setiap pendekatan secara lebih rinci.
Jalur dahi
Cron menjalankan skrip bash biasa.
Seperti yang kita ingat, dalam repositori log semua log dalam bentuk file biasa, struktur folder kira-kira sebagai berikut: /logging/java/2018/08/10/{service_nameasure/*.log
Hadoop menyimpan file-nya dalam kira-kira struktur folder yang sama hdfs-raw / banner-versi / tahun = 2018 / bulan = 08 / hari = 10
tahun, bulan, hari kami gunakan sebagai partisi.
Jadi, kita hanya perlu membentuk jalur yang benar (baris 3-4), dan kemudian pilih semua log yang diperlukan (baris 6) dan gunakan rsync untuk mengisinya ke hadoop (baris 8).
Keuntungan dari pendekatan ini:- Perkembangan cepat
- Semuanya transparan dan jelas.
Cons:Cara yang modis
Karena kami mengunggah log ke repositori dengan skrip yang ditulis sendiri, masuk akal untuk mengacaukan kemampuan untuk mengunggahnya tidak hanya ke server, tetapi juga ke kafka.
Pro- Log online (log in hadoop muncul saat Anda mengisi kafka)
- Anda dapat melakukan pra-pemrosesan
- Itu menahan beban dengan baik dan Anda dapat mengunggah log besar
Cons- Pengaturan lebih keras
- Saya harus menulis kode
- Lebih banyak bagian dari proses casting
- Pemantauan dan analisis insiden yang lebih rumit
Cara kuno
Ini berbeda dari mode hanya dengan tidak adanya kafka. Oleh karena itu, ia mewarisi semua kelemahan dan hanya beberapa keunggulan dari pendekatan sebelumnya. Layanan terpisah (pengunggah ustats) di java secara berkala membaca file yang diperlukan, memprosesnya terlebih dahulu dan mengunggahnya ke hadoop.
Pro- Anda dapat melakukan pra-pemrosesan
Cons- Pengaturan lebih keras
- Saya harus menulis kode
Dan data masuk ke hadoop dan siap untuk analisis. Mari kita berhenti sedikit dan mengingat apa hadoop itu dan mengapa ratusan gigabyte dapat dikonsumsi jauh lebih cepat daripada grep biasa.
Hadoop
Hadoop adalah gudang data terdistribusi. Data tidak terletak pada server terpisah, tetapi didistribusikan di antara beberapa mesin, dan juga disimpan bukan dalam satu contoh, tetapi dalam beberapa - ini dilakukan untuk memastikan keandalan. Dasar dari kecepatan pemrosesan data terletak pada perubahan dalam pendekatan dibandingkan dengan database konvensional.
Dalam kasus database biasa, kami mengekstrak data darinya dan mengirimkannya ke klien, yang melakukan semacam analisis dan mengembalikan hasilnya kepada analis. Jadi, untuk menghitung lebih cepat, kita perlu memiliki banyak pelanggan dan memparalelkan permintaan (misalnya, untuk membagi data dengan bulan - dan setiap klien dapat membaca data untuk bulannya).
Dalam hadoop, yang terjadi adalah sebaliknya. Kami mengirim kode (persis apa yang ingin kami hitung) ke data, dan kode ini dieksekusi di cluster. Seperti yang kita ketahui, data terletak pada banyak mesin, sehingga setiap mesin hanya mengeksekusi kode pada datanya dan mengembalikan hasilnya ke klien.
Banyak yang mungkin pernah mendengar tentang
pengurangan peta , tetapi menulis kode untuk analisis tidak terlalu mudah dan cepat, sementara menulis dalam SQL jauh lebih sederhana. Oleh karena itu, muncul layanan yang dapat mengubah SQL menjadi pengurangan-peta secara transparan bagi pengguna, dan analis mungkin tidak curiga bagaimana permintaannya benar-benar dipertimbangkan.
Di hh.ru kami menggunakan sarang dan presto untuk ini. Hive adalah yang pertama, tetapi kami secara bertahap bergerak ke presto, karena itu jauh lebih cepat untuk permintaan kami. Sebagai GUI, kami menggunakan rona dan zeppelin.
Lebih mudah bagi saya untuk mempertimbangkan analitik dalam python dalam jupyter, ini memungkinkan kita untuk membacanya dengan satu klik dan mendapatkan tabel excel yang diformat dengan benar pada output, yang menghemat banyak waktu. Tulis di komentar, topik ini menarik ke artikel terpisah.
Mari kita kembali ke analitik itu sendiri.
Bagaimana memahami apa yang ingin kita pertimbangkan?
Manajer produk datang dengan tugas menghitung hasil percobaan
Kami mengirimkan email buletin di mana kami mengirim lowongan yang sesuai untuk pemohon (apakah semua orang menyukai surat seperti itu?). Kami memutuskan untuk mengubah desain surat itu sedikit dan ingin memahami apakah itu menjadi lebih baik. Untuk ini kami akan mempertimbangkan:
- jumlah transisi ke lowongan dari surat;
- umpan balik setelah transisi
Biarkan saya mengingatkan Anda bahwa yang kita miliki hanyalah log akses dan database. Kami perlu merumuskan metrik kami dalam hal klik tautan.
Jumlah transisi ke lowongan dari surat
Transisi adalah permintaan GET ke
hh.ru/vacancy/26646861 . Untuk memahami dari mana asal transisi, kami menambahkan tag utm dari formulir? Utm_source = email_campaign_123. Untuk permintaan GET di log akses akan ada informasi tentang parameter, dan kami hanya dapat memfilter transisi dari milis kami.
Jumlah respons setelah transisi
Di sini kita dapat dengan mudah menghitung jumlah respons terhadap lowongan dari buletin, tetapi kemudian statistiknya akan salah, karena responsnya dapat dipengaruhi oleh hal lain, kecuali untuk surat kami, misalnya, iklan di ClickMe dibeli untuk lowongan, dan karenanya jumlah respons sangat dewasa.
Kami memiliki dua opsi untuk bagaimana merumuskan jumlah respons:
- Tanggapannya adalah POST di hh.ru/applicant/vacancy_response/popup?vacancy_id=26646861 , yang memiliki perujuk hh.ru/vacancy/26646861?utm_source=email_campaign_123 .
- Nuansa dari pendekatan ini adalah bahwa jika pengguna beralih ke lowongan, dan kemudian berjalan di sekitar situs sedikit dan kemudian menanggapi lowongan, maka kami tidak akan menghitungnya.
- Kita dapat mengingat id pengguna yang beralih ke hh.ru/vacancy/26646861 , dan menghitung jumlah ulasan untuk lowongan pada siang hari berdasarkan database.
Pilihan pendekatan ditentukan oleh persyaratan bisnis, biasanya opsi pertama sudah cukup, tetapi semuanya tergantung pada apa yang menunggu manajer produk.
Perangkap yang mungkin terjadi
- Tidak semua data ada di hadoop, Anda perlu menambahkan data dari database prod. Misalnya, dalam log biasanya hanya id, dan jika Anda memerlukan nama - maka itu ada di database. Terkadang Anda perlu mencari pengguna dengan resume_id, dan ini juga disimpan dalam database. Untuk melakukan ini, kami membongkar sebagian dari database di hadoop sehingga bergabung lebih mudah.
- Data mungkin berupa kurva. Ini umumnya merupakan bencana bagi hadoop dan cara kami memuat data ke dalamnya. Bergantung pada data, nilai kosong dapat menjadi nol, Tidak ada, tidak ada, string kosong, dll. Anda harus berhati-hati dalam setiap kasus, karena data benar-benar berbeda, dimuat dengan cara yang berbeda dan untuk tujuan yang berbeda.
- Hitungan panjang untuk seluruh periode. Misalnya, kita perlu menghitung transisi dan tanggapan kita untuk bulan itu. Ini sekitar 3 terabyte log. Bahkan hadoop akan mengambil ini untuk beberapa waktu. Biasanya menulis permintaan kerja 100% pertama kali cukup sulit, jadi kami menulisnya dengan coba-coba. Setiap waktu untuk menunggu 20 menit adalah waktu yang sangat lama. Cara untuk memecahkan:
- Men-debug permintaan pada log dalam 1 hari. Karena kami telah mempartisi data dalam hadoop, cukup cepat untuk menghitung sesuatu untuk log 1 hari.
- Unggah log yang diperlukan ke tabel sementara. Sebagai aturan, kami memahami url apa yang kami minati, dan kami dapat membuat tabel sementara untuk log dari url ini.
Secara pribadi, opsi pertama lebih nyaman bagi saya, tetapi, kadang-kadang, saya perlu membuat tabel sementara, tergantung pada situasinya. - Distorsi dalam metrik akhir
- Lebih baik menyaring log. Anda perlu memperhatikan, misalnya, pada kode respons, redirect, dll. Lebih baik lebih sedikit data, tetapi lebih akurat, yang Anda yakin.
- Langkah perantara sesedikit mungkin dalam metrik. Misalnya, beralih ke lowongan adalah satu langkah (MENDAPATKAN permintaan untuk / lowongan / 123). Responsnya adalah dua (transisi ke lowongan + POST). Semakin pendek rantai, semakin sedikit kesalahan dan lebih akurat metriknya. Kadang-kadang terjadi bahwa data antara transisi hilang dan umumnya tidak mungkin untuk menghitung sesuatu. Untuk mengatasi masalah ini, kita perlu memikirkan apa yang akan kita pertimbangkan dan bagaimana sebelum mengembangkan percobaan. Log terpisah Anda dari acara yang diperlukan sangat membantu. Kita dapat merekam peristiwa yang diperlukan, dan dengan demikian rantai peristiwa akan lebih akurat, dan penghitungan lebih mudah.
- Bot dapat menghasilkan banyak transisi. Anda perlu memahami ke mana bot dapat pergi (misalnya, pada halaman di mana otorisasi tidak diperlukan, mereka seharusnya tidak), dan memfilter data ini.
- Benjolan besar - misalnya, dalam salah satu grup mungkin ada satu pelamar, yang menghasilkan 50% dari semua tanggapan. Akan ada kecenderungan statistik, data tersebut juga perlu disaring.
- Sulit untuk merumuskan apa yang harus dipertimbangkan dalam hal log akses. Ini membantu pengetahuan tentang basis kode, pengalaman, dan alat pengembang krom. Kami membaca deskripsi metrik dari produk, mengulanginya dengan tangan kami di situs dan melihat transisi apa yang dihasilkan.
Akhirnya, mari kita bicara tentang bagaimana hasil perhitungan akan terlihat.
Hasil perhitungan
Dalam contoh kami, ada 2 grup dan 2 metrik yang membentuk corong.
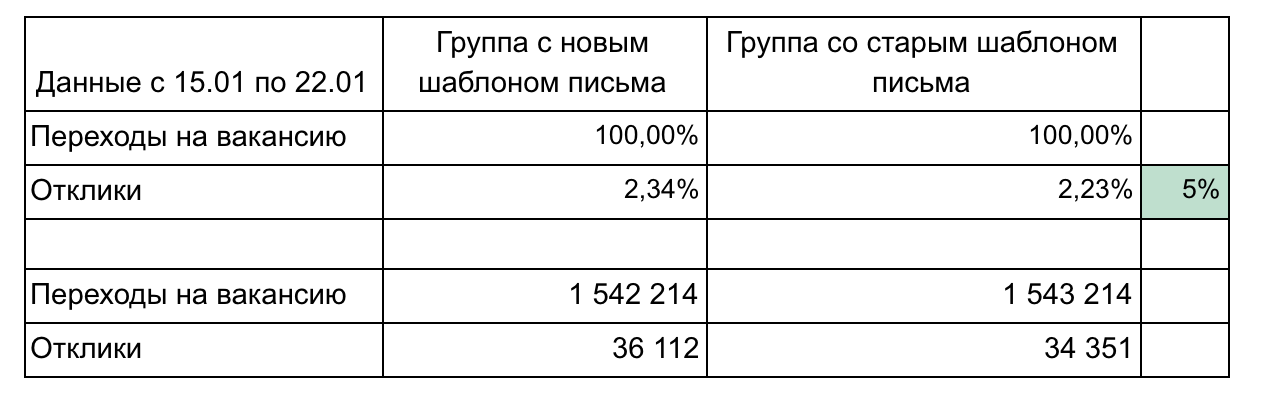
Rekomendasi untuk melaporkan hasil:
- Jangan membebani terlalu banyak komponen sampai diperlukan. Sederhana dan lebih kecil lebih baik (misalnya, di sini kami dapat menampilkan setiap lowongan secara terpisah atau mengklik menurut hari). Fokus pada satu hal.
- Detail mungkin diperlukan selama hasil demo, jadi pikirkan pertanyaan apa yang mungkin Anda tanyakan dan siapkan detailnya. (Dalam contoh kami, perincian dapat sesuai dengan kecepatan transisi setelah mengirim email - 1 hari, 3 hari, seminggu, mengelompokkan lowongan berdasarkan area profesional)
- Ingatlah tentang signifikansi statistik. Misalnya, perubahan 1% dengan 100 klik dan 15 klik tidak signifikan dan dapat dilakukan secara acak. Gunakan kalkulator
- Otomatiskan sebanyak mungkin, karena Anda harus menghitung beberapa kali. Biasanya di tengah eksperimen seseorang sudah ingin memahami bagaimana keadaannya. Setelah percobaan, pertanyaan dapat muncul dan Anda harus mengklarifikasi sesuatu. Dengan demikian, akan perlu untuk menghitung 3-4 kali, dan jika setiap perhitungan adalah urutan 10 pertanyaan dan kemudian menyalin secara manual untuk unggul, itu akan menyakitkan dan menghabiskan banyak waktu. Belajar python, itu akan menghemat banyak waktu.
- Gunakan representasi grafis dari hasil saat diperlukan. Alat sarang dan zeppelin bawaan memungkinkan Anda membuat grafik sederhana di luar kotak.
Penting untuk mempertimbangkan berbagai metrik cukup sering, karena kami mengeluarkan hampir setiap tugas sebagai bagian dari percobaan A / B. Tidak ada yang rumit dalam perhitungan, setelah 2-3 percobaan pemahaman muncul tentang bagaimana melakukan ini. Ingatlah bahwa log akses menyimpan banyak informasi berguna yang dapat menghemat uang perusahaan, membantu Anda mempromosikan ide Anda dan membuktikan opsi perubahan mana yang lebih baik. Yang utama adalah bisa mendapatkan informasi ini.