Edisi pertama rilis CTP dari SQL Server 2019 disajikan pada 24 September, dan izinkan saya mengatakan bahwa ini penuh dengan segala macam perbaikan dan fitur baru (banyak di antaranya dapat ditemukan dalam formulir pratinjau dalam database Azure SQL). Saya memiliki kesempatan luar biasa untuk mengetahui hal ini sedikit lebih awal, yang memungkinkan saya untuk memperluas pemahaman saya tentang perubahan, bahkan secara dangkal. Anda juga dapat membaca
publikasi terbaru dari tim SQL Server dan
dokumentasi yang diperbarui .
Tanpa merinci lebih lanjut, saya akan membahas fitur-fitur kernel baru berikut: kinerja, pemecahan masalah, keamanan, ketersediaan, dan pengembangan. Saat ini, saya memiliki sedikit lebih banyak detail daripada yang lain, dan beberapa di antaranya sudah siap untuk dipublikasikan. Saya akan kembali ke bagian ini, juga ke banyak artikel dan dokumentasi lainnya, dan menerbitkannya. Saya segera memberi tahu Anda bahwa ini bukan ulasan yang komprehensif, tetapi hanya sebagian dari fungsi yang saya berhasil “sentuh”, hingga CTP 2.0. Masih banyak yang harus dibicarakan.
Performa
Variabel Tabel: Bangunan Rencana Tertunda
Variabel tabel memiliki reputasi yang tidak terlalu baik, sebagian besar di bidang estimasi biaya. Secara default, SQL Server mengasumsikan bahwa variabel tabel hanya bisa berisi satu baris, yang terkadang mengarah ke pilihan paket yang tidak memadai ketika variabel akan berisi baris berkali-kali lebih banyak. OPSI (RECOMPILE) biasanya digunakan sebagai solusi, tetapi ini membutuhkan perubahan kode dan boros dalam kaitannya dengan sumber daya untuk melakukan pembangunan kembali setiap waktu, sementara jumlah garis paling sering sama. Untuk meniru pembangunan kembali,
bendera jejak 2453 diperkenalkan, tetapi juga membutuhkan peluncuran dengan bendera, dan hanya berfungsi ketika perubahan signifikan dalam garis terjadi.
Pada tingkat kompatibilitas 150, konstruksi ditunda dilakukan jika variabel tabel hadir dan rencana kueri tidak dibangun sampai variabel tabel diisi satu kali. Biaya akan diestimasi berdasarkan hasil penggunaan variabel tabel pertama, tanpa perubahan lebih lanjut. Ini adalah kompromi antara pembangunan kembali konstan untuk mendapatkan biaya yang tepat, dan tidak adanya pembangunan kembali dengan biaya konstan 1. Jika jumlah baris tetap relatif konstan, maka ini adalah indikator yang baik (dan bahkan lebih baik jika jumlahnya melebihi 1), tetapi mungkin kurang menguntungkan jika ada variasi besar dalam jumlah baris.
Saya mempresentasikan analisis yang lebih dalam dalam artikel
Tabular Variables baru-baru ini
: Build Tertunda dalam SQL Server , dan Brent Ozar juga membicarakan hal ini dalam artikel
Fast Tabular Variables (Dan Masalah Analisis Parameter Baru) .
Umpan Balik Alokasi Memori dalam Mode String
SQL Server 2017 memiliki umpan balik alokasi memori batch, yang dijelaskan secara rinci di
sini . Pada dasarnya, untuk alokasi memori apa pun yang terkait dengan paket kueri yang menyertakan pernyataan mode kumpulan, SQL Server akan mengevaluasi memori yang digunakan oleh kueri dan membandingkannya dengan memori yang diminta. Jika memori yang diminta terlalu kecil atau terlalu banyak, yang akan menyebabkan pengeringan dalam tempdb atau pemborosan memori, maka pada awal berikutnya memori yang dialokasikan untuk rencana kueri yang sesuai akan disesuaikan. Perilaku ini akan mengurangi volume yang dialokasikan dan memperluas konkurensi, atau meningkatkannya, untuk meningkatkan kinerja.
Sekarang kita mendapatkan perilaku yang sama untuk kueri dalam mode string, di bawah tingkat kompatibilitas 150. Jika kueri dipaksa untuk menggabungkan data ke disk, maka untuk peluncuran selanjutnya memori yang dialokasikan akan meningkat. Jika setelah selesai setengah permintaan memori diperlukan daripada yang dialokasikan, maka untuk permintaan selanjutnya akan disesuaikan ke bawah. Bretn Ozar menjelaskan hal ini lebih terinci dalam artikelnya
Alokasi Memori Bersyarat .
Mode batch untuk penyimpanan baris demi baris
Dimulai dengan SQL Server 2012, tabel kueri dengan indeks kolom telah mendapat manfaat dari peningkatan kinerja mode batch. Peningkatan kinerja disebabkan oleh prosesor kueri yang melakukan pemrosesan batch dan bukan dari segi baris. Garis juga diproses oleh inti penyimpanan dalam paket, yang menghindari pernyataan pertukaran mata uang. Paul White (
@SQL_Kiwi ) mengingatkan saya bahwa jika Anda menggunakan tabel kosong dengan penyimpanan kolom untuk memungkinkan operasi mode batch, maka baris yang diproses akan dikumpulkan ke dalam paket dengan pernyataan yang tidak terlihat. Namun, penopang ini dapat meniadakan perbaikan yang diterima dari pemrosesan batch. Beberapa informasi tentang ini ada di
jawaban Stack Exchange .
Pada tingkat kompatibilitas 150, SQL Server 2019 akan secara otomatis memilih mode batch sebagai jalan tengah dalam kasus-kasus tertentu, bahkan ketika tidak ada indeks kolom. Anda mungkin berpikir mengapa tidak membuat indeks kolom dan topi saja? Atau terus menggunakan kruk yang disebutkan di atas? Pendekatan ini juga diperluas ke objek tradisional dengan penyimpanan baris, karena indeks kolom, karena beberapa alasan, tidak selalu mungkin, termasuk batasan fungsional (misalnya, pemicu), overhead selama operasi pembaruan atau penghapusan yang sangat dimuat, dan kurangnya dukungan dari produsen pihak ketiga. Dan tidak ada hal baik yang bisa diharapkan dari tongkat itu.
Saya membuat tabel yang sangat sederhana dengan 10 juta baris dan satu indeks berkerumun pada kolom integer dan menjalankan kueri ini:
SELECT sa5, sa2, SUM(i1), SUM(i2), COUNT(*) FROM dbo.FactTable WHERE i1 > 100000 GROUP BY sa5, sa2 ORDER BY sa5, sa2;
Rencana tersebut dengan jelas menunjukkan pencarian indeks dan konkurensi, tetapi tidak sepatah kata pun tentang indeks kolom (seperti yang
ditunjukkan oleh SentryOne Plan Explorer ):
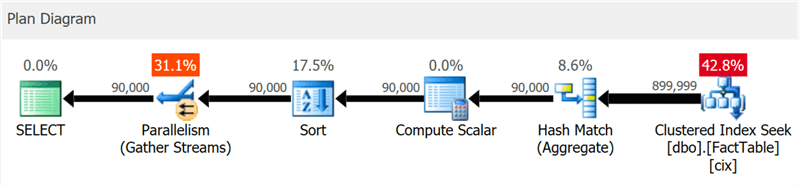
Tetapi jika Anda menggali sedikit lebih dalam, Anda dapat melihat bahwa hampir semua operator dieksekusi dalam mode batch, bahkan penyortiran dan perhitungan skalar:

Anda dapat menonaktifkan fitur ini dengan tetap pada tingkat kompatibilitas yang lebih rendah dengan mengubah konfigurasi database atau dengan menggunakan prompt DISALLOW_BATCH_MODE dalam kueri:
SELECT … OPTION (USE HINT ('DISALLOW_BATCH_MODE'));
Dalam hal ini, operator pertukaran tambahan muncul, semua operator dieksekusi dalam mode baris demi baris, dan waktu eksekusi kueri hampir tiga kali lipat.

Untuk tingkat tertentu, Anda bisa melihat ini dalam diagram, tetapi dalam pohon detail rencana Anda juga bisa melihat pengaruh kondisi pemilihan yang tidak dapat mengecualikan baris sampai penyortiran terjadi:

Pilihan mode batch tidak selalu merupakan langkah yang baik - heuristik yang termasuk dalam algoritma pengambilan keputusan memperhitungkan jumlah garis, jenis operator yang diusulkan dan manfaat yang diharapkan dari mode batch.
APPROX_COUNT_DISTINCT
Fungsi agregat baru ini dimaksudkan untuk skenario pergudangan data dan setara dengan COUNT (DISTINCT ()). Namun, alih-alih melakukan penyortiran yang mahal untuk menentukan kuantitas aktual, fungsi baru bergantung pada statistik untuk mendapatkan data yang relatif akurat. Anda perlu memahami bahwa kesalahan terletak pada 2% dari jumlah yang tepat, dan dalam 97% kasus yang merupakan norma untuk analisis tingkat tinggi, ini adalah nilai yang ditampilkan pada indikator atau digunakan untuk perkiraan cepat.
Pada sistem saya, saya membuat tabel dengan kolom bilangan bulat yang menyertakan nilai unik dalam kisaran 100 hingga 1.000.000, dan kolom baris, dengan nilai unik di kisaran 100 hingga 100.000. Tidak memiliki indeks kecuali kunci primer yang dikelompokkan di awal kolom bilangan bulat. Berikut adalah hasil dari mengeksekusi COUNT (DISTINCT ()) dan APPROX_COUNT_DISTINCT () pada kolom-kolom ini, yang darinya Anda dapat melihat sedikit perbedaan (tetapi selalu dalam 2%):
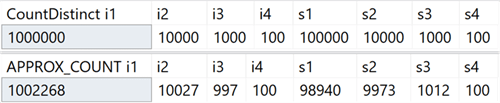
Gain sangat besar jika ada keterbatasan memori, yang berlaku untuk kebanyakan dari kita. Jika Anda melihat paket kueri, dalam kasus khusus ini, Anda dapat melihat perbedaan besar dalam konsumsi memori oleh operator pencocokan hash:

Perhatikan bahwa Anda biasanya hanya akan melihat peningkatan kinerja yang signifikan jika Anda sudah terikat memori. Di sistem saya, eksekusi berlangsung sedikit lebih lama karena utilisasi CPU yang tinggi dari fitur baru:

Mungkin perbedaannya akan lebih signifikan jika saya memiliki tabel yang lebih besar, lebih sedikit memori yang tersedia untuk SQL Server, konkurensi lebih tinggi, atau kombinasi di atas.
Kiat untuk menggunakan tingkat kompatibilitas dalam kueri
Apakah Anda memiliki permintaan khusus yang berfungsi lebih baik di bawah tingkat kompatibilitas tertentu, berbeda dari database saat ini? Ini sekarang dimungkinkan berkat petunjuk permintaan baru yang mendukung enam tingkat kompatibilitas yang berbeda dan lima model berbeda untuk memperkirakan jumlah elemen. Berikut ini adalah tingkat kompatibilitas yang tersedia, contoh sintaks, dan model tingkat kompatibilitas yang digunakan dalam setiap kasus. Lihat bagaimana ini memengaruhi peringkat, bahkan untuk tampilan sistem:

Singkatnya: tidak perlu lagi mengingat flag jejak, atau bertanya-tanya apakah Anda perlu khawatir tentang apakah tambalan TF 4199 untuk optimizer kueri didistribusikan, atau dibatalkan oleh beberapa paket layanan lainnya. Perhatikan bahwa tips tambahan ini baru-baru ini ditambahkan untuk SQL Server 2017 dalam pembaruan kumulatif # 10 (lihat
blog Pedro Lopez untuk detailnya). Anda dapat melihat semua petunjuk yang tersedia dengan perintah berikut:
SELECT name FROM sys.dm_exec_valid_use_hints;
Tapi jangan lupa bahwa petunjuk adalah ukuran yang luar biasa, mereka sering cocok untuk keluar dari situasi yang sulit, tetapi jangan direncanakan untuk digunakan dalam jangka panjang, karena perilaku mereka dapat berubah dengan pembaruan berikutnya.
Pemecahan masalah
Profil default sederhana
Memahami peningkatan ini membutuhkan beberapa hal untuk diingat. SQL Server 2014 memperkenalkan tampilan DMV sys.dm_exec_query_profiles, yang memungkinkan pengguna yang menjalankan kueri untuk mengumpulkan informasi diagnostik tentang semua pernyataan di semua bagian kueri. Informasi yang dikumpulkan menjadi tersedia setelah penyelesaian kueri dan memungkinkan Anda untuk menentukan operator mana yang benar-benar menghabiskan sumber daya utama dan mengapa. Setiap pengguna yang tidak memenuhi permintaan spesifik dapat menerima data ini untuk sesi apa pun di mana pernyataan STATISTIK XML atau STATISTIK PROFIL disertakan, atau untuk semua sesi, menggunakan acara extended_post_execution_showplan, meskipun acara ini, khususnya, dapat memengaruhi kinerja secara keseluruhan.
Di Management Studio 2016, fungsionalitas telah ditambahkan yang memungkinkan Anda untuk menampilkan aliran data yang melewati rencana kueri secara real time berdasarkan informasi yang dikumpulkan dari DMV, yang membuatnya bahkan lebih kuat untuk pemecahan masalah. Plan Explorer juga menawarkan kemampuan untuk memvisualisasikan data yang melewati kueri, baik dalam waktu nyata maupun dalam mode pemutaran.
Dimulai dengan SQL Server 2016 Paket Layanan 1 (SP1), Anda juga dapat mengaktifkan versi ringan pengumpulan data ini untuk semua sesi menggunakan jejak jejak 7412 atau properti query_thread_profile canggih, yang memungkinkan Anda untuk segera mendapatkan informasi terbaru tentang sesi apa pun, tanpa perlu apa pun termasuk di dalamnya secara eksplisit (khususnya, hal-hal yang mempengaruhi kinerja). Ini dijelaskan lebih rinci di
blog Pedro Lopez .
Di SQL Server 2019, fitur ini diaktifkan secara default, jadi Anda tidak perlu menjalankan sesi dengan peristiwa yang diperluas atau menggunakan tanda jejak dan pernyataan STATISTIK dalam kueri apa pun. Lihat saja data dari DMV kapan saja untuk semua sesi bersamaan. Namun dimungkinkan untuk menonaktifkan mode ini menggunakan LIGHTWEIGHT_QUERY_PROFILING, namun, sintaks ini tidak berfungsi di CTP 2.0 dan akan diperbaiki dalam edisi mendatang.
Statistik indeks kolom yang dikelompokkan sekarang tersedia dalam database yang dikloning
Dalam versi SQL Server saat ini, ketika kloning database, hanya statistik objek asli dari indeks kolom berkerumun digunakan, tidak termasuk pembaruan yang dibuat ke tabel setelah pembuatannya. Jika Anda menggunakan klon untuk mengonfigurasi kueri dan pengujian kinerja lainnya, yang didasarkan pada peringkat daya, maka contoh ini mungkin tidak berfungsi. Parikshit Savyani menjelaskan batasan
dalam publikasi ini dan memberikan solusi sementara - sebelum membuat klon, Anda perlu membuat skrip yang mengeksekusi DBCC SHOW_STATISTICS ... DENGAN STATS_STREAM untuk setiap objek. Itu mahal dan, tentu saja, mudah melupakannya.
Di SQL Server 2019, statistik yang diperbarui ini akan secara otomatis tersedia di klon, sehingga Anda dapat menguji berbagai skenario kueri dan mendapatkan rencana obyektif berdasarkan statistik nyata, tanpa menjalankan STATS_STREAM secara manual untuk semua tabel.
Prakiraan kompresi untuk penyimpanan kolom
Dalam versi saat ini, prosedur sys.sp_estimate_data_compression_savings memiliki pemeriksaan berikut:
if (@data_compression not in ('NONE', 'ROW', 'PAGE'))
Ini berarti Anda dapat memeriksa kompresi baris atau halaman (atau melihat hasil penghapusan kompresi saat ini). Di SQL Server 2019, pemeriksaan ini sekarang terlihat seperti ini:
if (@data_compression not in ('NONE', 'ROW', 'PAGE', 'COLUMNSTORE', 'COLUMNSTORE_ARCHIVE'))
Ini adalah berita bagus karena memungkinkan Anda untuk memperkirakan secara kasar dampak menambahkan indeks kolom ke tabel yang tidak memilikinya, atau mengonversi tabel atau partisi ke format penyimpanan kolom yang lebih terkompresi, tanpa harus mengembalikan tabel ke sistem lain. Saya memiliki tabel dengan 10 juta baris, di mana saya melakukan prosedur tersimpan dengan masing-masing dari lima parameter:
EXEC sys.sp_estimate_data_compression_savings @schema_name = N'dbo', @object_name = N'FactTable', @index_id = NULL, @partition_number = NULL, @data_compression = N'NONE';
Hasil:

Seperti jenis kompresi lainnya, akurasi sepenuhnya tergantung pada baris yang tersedia dan keterwakilan data lainnya. Namun, ini adalah cara yang cukup ampuh untuk mendapatkan hasil yang dapat diprediksi tanpa banyak kesulitan.
Fitur baru untuk mendapatkan info halaman
Untuk waktu yang lama, PAGE DBCC dan DBCC IND digunakan untuk mengumpulkan informasi tentang halaman yang berisi bagian, indeks, atau tabel. Tetapi mereka tidak berdokumen dan tidak didukung, dan mungkin membosankan untuk mengotomatisasi solusi tugas yang terkait dengan beberapa indeks atau halaman.
Kemudian, fungsi administrasi dinamis (DMF) sys.dm_db_database_page_allocations muncul, yang mengembalikan set yang mewakili semua halaman di objek yang ditentukan. Masih tidak terdokumentasi dan memiliki kekurangan yang dapat menjadi masalah nyata pada tabel besar: bahkan untuk mendapatkan informasi tentang satu halaman, ia harus membaca seluruh struktur, yang bisa sangat mahal.
Di SQL Server 2019, DMF lain telah muncul - sys.dm_db_page_info. Ini pada dasarnya mengembalikan semua informasi halaman, tanpa overhead distribusi DMF. Namun, untuk menggunakan fungsi dalam build saat ini, Anda perlu mengetahui jumlah halaman yang Anda cari sebelumnya. Mungkin langkah ini diambil dengan sengaja, karena ini adalah satu-satunya cara untuk memastikan kinerja. Jadi, jika Anda mencoba mengidentifikasi semua halaman dalam indeks atau tabel, maka Anda masih perlu menggunakan distribusi DMF. Pada artikel selanjutnya saya akan menjelaskan pertanyaan ini secara lebih rinci.
Keamanan
Enkripsi permanen menggunakan lingkungan yang aman (kantong)
Saat ini, enkripsi permanen melindungi data sensitif selama transmisi dan dalam memori dengan enkripsi / dekripsi pada setiap akhir proses. Sayangnya, ini sering mengarah pada batasan serius ketika bekerja dengan data, seperti ketidakmampuan untuk melakukan perhitungan dan pemfilteran, sehingga Anda harus mentransfer seluruh data yang ditetapkan ke sisi klien untuk melakukan, katakanlah, pencarian rentang.
Lingkungan aman (enklosur) adalah area memori yang dilindungi di mana perhitungan dan penyaringan tersebut dapat didelegasikan (Windows menggunakan
keamanan berbasis virtualisasi ) - data tetap dienkripsi dalam kernel, tetapi dapat dengan aman didekripsi atau dienkripsi dalam lingkungan yang aman. Anda hanya perlu menambahkan parameter ENCLAVE_COMPUTATIONS ke kunci utama menggunakan SSMS, misalnya, dengan mencentang kotak "Izinkan perhitungan dalam lingkungan yang aman":
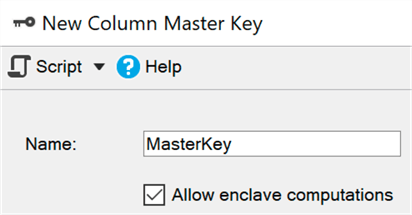
Sekarang Anda dapat mengenkripsi data hampir secara instan, dibandingkan dengan metode lama (di mana wizard, cmdlet Set-SqlColumnEncyption atau aplikasi Anda, harus sepenuhnya mendapatkan seluruh set dari database, mengenkripsi, dan mengirimkannya kembali):
ALTER TABLE dbo.Patients ALTER COLUMN SSN char(9)
Saya pikir bahwa bagi banyak organisasi peningkatan ini akan menjadi berita utama, tetapi dalam CTP saat ini beberapa subsistem ini masih diperbaiki, oleh karena itu mereka dimatikan secara default, tetapi di
sini Anda dapat melihat cara menyalakannya.
Manajemen Sertifikat di Manajer Konfigurasi
Mengelola sertifikat SSL dan TLS selalu menyusahkan, dan banyak orang terpaksa melakukan pekerjaan yang membosankan dengan membuat skrip mereka sendiri untuk menggunakan dan mempertahankan sertifikat perusahaan mereka. Manajer konfigurasi yang diperbarui untuk SQL Server 2019 akan membantu Anda dengan cepat melihat dan memverifikasi sertifikat dari setiap contoh, menemukan sertifikat yang segera kedaluwarsa, dan menyinkronkan penyebaran sertifikat di semua replikasi dalam grup ketersediaan atau semua node dalam instance cluster failover.
Saya belum mencoba semua operasi ini, tetapi mereka harus bekerja untuk versi SQL Server sebelumnya jika manajemen berasal dari SQL Server 2019 Configuration Manager.
Klasifikasi dan audit data bawaan
Tim pengembangan SQL Server telah menambahkan kemampuan untuk mengklasifikasikan data dalam SSMS 17.5, yang memungkinkan Anda untuk mengidentifikasi kolom apa pun yang mungkin berisi informasi sensitif atau bertentangan dengan berbagai standar (HIPAA, SOX, PCI, dan GDPR, tentu saja). Panduan menggunakan algoritme yang menawarkan kolom yang seharusnya menyebabkan masalah, tetapi Anda dapat menyesuaikan kalimatnya dengan menghapus kolom ini dari daftar, atau menambahkan milik Anda. Untuk menyimpan klasifikasi, digunakan properti canggih; Laporan SSMS bawaan menggunakan informasi yang sama untuk menampilkan datanya. Di luar laporan, sifat-sifat ini tidak begitu jelas.
SQL Server 2019 memperkenalkan pernyataan baru untuk metadata ini, yang sudah tersedia di Azure SQL Database, dan disebut ADD SENSITIVITY CLASSIFICATION. Ini memungkinkan Anda untuk melakukan hal yang sama seperti wizard di SSMS, tetapi informasi tersebut tidak lagi disimpan di properti yang diperluas, dan setiap akses ke data ini secara otomatis ditampilkan dalam audit sebagai kolom XML baru data_sensitivity_information. Ini berisi semua jenis informasi yang terpengaruh selama audit.
Sebagai contoh cepat, misalkan saya punya meja untuk kontraktor eksternal:
CREATE TABLE dbo.Contractors ( FirstName sysname, LastName sysname, SSN char(9), HourlyRate decimal(6,2) );
Melihat struktur seperti itu, menjadi jelas bahwa keempat kolom berpotensi rentan terhadap kebocoran, atau hanya dapat diakses oleh lingkaran orang yang terbatas. Di sini Anda dapat bertahan dengan izin, tetapi setidaknya Anda harus fokus padanya. Dengan demikian, kita dapat mengklasifikasikan kolom ini dengan cara yang berbeda:
ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.FirstName, dbo.Contractors.LastName WITH (LABEL = 'Confidential – GDPR', INFORMATION_TYPE = 'Personal Info'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.SSN WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'National ID'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.HourlyRate WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'Financial');
Sekarang, alih-alih melihat sys.extended_properties, Anda dapat melihatnya di sys.sensitivity_classifications:

Dan jika kita melakukan sampling audit (atau DML) untuk tabel ini, kita tidak perlu secara khusus mengubah apa pun; setelah membuat klasifikasi,
SELECT * akan mencatat dalam audit log, catatan dari jenis informasi ini dalam kolom baru data_sensitivity_information:
<sensitivity_attributes> <sensitivity_attribute label="Confidential - GDPR" information_type="Personal Info" /> <sensitivity_attribute label="Highly Confidential" information_type="National ID" /> <sensitivity_attribute label="Highly Confidential" information_type="Financial" /> </sensitivity_attributes>
Tentu saja, ini tidak menyelesaikan semua masalah kepatuhan dengan standar, tetapi dapat memberikan keuntungan nyata. Menggunakan wizard untuk secara otomatis mengidentifikasi kolom dan menerjemahkan panggilan properti sp_addextendedproperty menjadi perintah ADD SENSITIVITY CLASSIFICATION dapat sangat menyederhanakan tugas memenuhi standar. Nanti, saya akan menulis artikel terpisah tentang ini.
Anda juga dapat mengotomatiskan pembuatan (atau memperbarui) izin berdasarkan label pada metadata - pembuatan skrip SQL dinamis yang melarang akses ke semua kolom rahasia (GDPR), yang akan memungkinkan Anda untuk mengelola pengguna, grup, atau peranb. Saya akan mengerjakan masalah ini di masa mendatang.
Ketersediaan
Pembuatan indeks terbarukan waktu-nyata
Dalam SQL Server 2017, menjadi mungkin untuk menunda dan melanjutkan membangun kembali indeks secara real time, yang dapat sangat berguna jika Anda perlu mengubah jumlah prosesor yang digunakan, melanjutkan dari saat penskorsan setelah kegagalan, atau hanya menjembatani kesenjangan antara jendela layanan. Saya berbicara tentang fitur ini di
artikel sebelumnya .
Di SQL Server 2019, Anda dapat menggunakan sintaks yang sama untuk membuat indeks real-time, jeda dan lanjutkan, dan juga untuk membatasi waktu eksekusi (mengatur waktu jeda):
CREATE INDEX foo ON dbo.bar(blat) WITH (ONLINE = ON, RESUMABLE = ON, MAX_DURATION = 10 MINUTES);
Jika kueri ini bekerja terlalu lama, maka Anda dapat menjeda ALTER INDEX di sesi lain (bahkan jika indeks belum ada secara fisik):
ALTER INDEX foo ON dbo.bar PAUSE;
Dalam bangunan saat ini, tingkat paralelisme selama pembaruan tidak dapat dikurangi, seperti halnya dengan pembangunan kembali. Saat mencoba mengurangi DOP:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 2);
Kami mendapatkan yang berikut ini:
Msg 10666, Level 16, State 1, Line 3 Cannot resume index build as required DOP 4 (DOP operation was started with) is not available. Please ensure sufficient DOP is available or abort existing index operation and try again. The statement has been terminated.
Bahkan, jika Anda mencoba melakukan ini, dan kemudian menjalankan perintah tanpa parameter tambahan, Anda akan mendapatkan kesalahan yang sama, setidaknya pada build saat ini. Saya pikir upaya pembaruan direkam di suatu tempat dan sistem ingin menggunakannya lagi. Untuk melanjutkan, Anda harus menentukan nilai DOP yang benar (atau lebih tinggi):
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 4);
Untuk memperjelas: Anda dapat meningkatkan DOP saat melanjutkan pembuatan indeks yang dijeda, tetapi tidak menurunkannya.
Manfaat tambahan dari semua ini adalah Anda dapat mengonfigurasi pembuatan dan / atau pembaruan indeks secara real time sebagai mode default menggunakan klausa ELEVATE_ONLINE dan ELEVATE_RESUMABLE untuk database baru.
Pembuatan / pembangunan kembali real-time dari indeks kolom berkerumun
Selain pembuatan indeks yang dapat diperbarui, kami juga mendapatkan kesempatan untuk membuat atau membangun kembali indeks kolom yang dikelompokkan secara real time. Ini adalah perubahan signifikan, yang memungkinkan Anda untuk tidak lagi menghabiskan waktu jendela layanan untuk pemeliharaan indeks tersebut atau (untuk kepastian yang lebih besar) untuk mengkonversi indeks dari baris-bijaksana ke kolom-bijaksana:
CREATE TABLE dbo.splunge ( id int NOT NULL ); GO CREATE UNIQUE CLUSTERED INDEX PK_Splunge ON dbo.splunge(id); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (DROP_EXISTING = ON, ONLINE = ON);
Satu peringatan: jika indeks cluster tradisional yang ada dibuat secara real time, maka konversinya ke indeks kolom cluster juga hanya dimungkinkan dalam mode ini. Jika itu adalah bagian dari kunci utama, bawaan atau tidak ... CREATE TABLE dbo.splunge ( id int NOT NULL CONSTRAINT PK_Splunge PRIMARY KEY CLUSTERED (id) ); GO
Kami mendapatkan kesalahan berikut: Msg 1907, Level 16 Cannot recreate index 'PK_Splunge'. The new index definition does not match the constraint being enforced by the existing index.
Anda harus terlebih dahulu menghapus kendala untuk mengubahnya menjadi indeks kolom berkerumun, tetapi kedua operasi ini dapat dilakukan secara real time: ALTER TABLE dbo.splunge DROP CONSTRAINT PK_Splunge WITH (ONLINE = ON); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (ONLINE = ON);
Ini berfungsi, tetapi tabel besar cenderung memakan waktu lebih lama daripada jika kunci primer diimplementasikan sebagai indeks cluster unik. Saya tidak bisa mengatakan dengan pasti apakah ini adalah pembatasan yang disengaja atau hanya batasan CTP saat ini.Mengarahkan koneksi replikasi dari server sekunder ke primer
Fungsi ini memungkinkan Anda untuk mengkonfigurasi pengalihan tanpa mendengarkan, sehingga Anda dapat mengalihkan koneksi ke server utama, bahkan jika sekunder ditentukan secara langsung dalam string koneksi. Fungsi ini dapat digunakan ketika teknologi pengelompokan tidak mendukung mendengarkan, saat menggunakan AGs tanpa sebuah klaster, atau ketika ada skema pengalihan yang kompleks dalam skenario dengan beberapa subnet. Ini akan mencegah koneksi dari, misalnya, mencoba menulis operasi untuk replikasi dalam mode read-only (dan kegagalan, masing-masing).Pengembangan
Fitur tambahan dari grafik
Hubungan grafik sekarang mendukung pernyataan MERGE untuk node atau tabel batas menggunakan predikat MERGE; Sekarang satu operator dapat memperbarui tepi yang ada atau memasukkan yang baru. Pembatasan tepi baru memungkinkan Anda menentukan simpul mana yang dapat disambungkan tepi.Utf-8
SQL Server 2012 menambahkan dukungan untuk UTF-16 dan karakter tambahan dengan mengatur penyortiran dengan menentukan nama dengan akhiran _SC, seperti Latin1_General_100_CI_AI_SC, untuk menggunakan kolom Unicode (nchar / nvarchar). Di SQL Server 2017, Anda dapat mengimpor dan mengekspor data UTF-8 dari dan ke kolom ini menggunakan alat seperti BCP dan BULK INSERT .Di SQL Server 2019, ada opsi susunan baru untuk mendukung retensi paksa data UTF-8 dalam bentuk aslinya. Jadi, Anda dapat dengan mudah membuat kolom char atau varchar dan menyimpan data UTF-8 dengan benar menggunakan susunan baru dengan akhiran _SC_UTF8, seperti Latin1_General_100_CI_AI_SC_UTF8. Ini dapat membantu meningkatkan kompatibilitas dengan aplikasi eksternal dan DBMS, tanpa biaya pemrosesan dan penyimpanan nvarchar.Telur paskah saya temukan
Sejauh yang saya ingat, pengguna SQL Server mengeluh tentang pesan kesalahan yang tidak jelas ini: Msg 8152 String or binary data would be truncated.
Di CTP builds yang saya uji, ada pesan kesalahan yang menarik yang tidak ada sebelumnya: Msg 2628 String or binary data would be truncated in table '%.*ls', column '%.*ls'. Truncated value: '%.*ls'
Saya tidak berpikir hal lain diperlukan di sini; ini merupakan peningkatan besar (meskipun sangat terlambat), dan berjanji untuk membuat banyak orang bahagia. Namun, fungsi ini tidak akan tersedia di CTP 2.0; Saya hanya memberi Anda kesempatan untuk melihat sedikit ke depan. Brent Ozar mendaftar semua pesan baru yang ia temukan di CTP saat ini dan membumbui mereka dengan beberapa komentar bermanfaat di artikel sys.messages- nya : menemukan fitur tambahan .Kesimpulan
SQL Server 2019 menawarkan fitur tambahan yang bagus yang akan membantu meningkatkan pekerjaan dengan platform basis data relasional favorit Anda, dan ada sejumlah perubahan yang belum saya bicarakan. Memori hemat energi, pengelompokan untuk layanan pembelajaran mesin, replikasi dan transaksi terdistribusi di Linux, Kubernetes, konektor untuk Oracle / Teradata / MongoDB, replikasi AG sinkron telah meningkat untuk mendukung Java (implementasi yang mirip dengan Python / R) dan, yang sama pentingnya, lompatan baru, berjudul Big Data Cluster. Untuk menggunakan beberapa fitur ini, Anda harus mendaftar menggunakan formulir EAP ini .Buku mendatang Bob Ward, Pro SQL Server di Linux - Termasuk Penempatan Berbasis Kontainer dengan Docker dan Kubernetes, dapat memberikan beberapa petunjuk tentang sejumlah hal lain yang akan segera hadir. Dan publikasi ini oleh Brent Ozar berbicara tentang kemungkinan perbaikan yang akan datang untuk fungsi skalar yang ditentukan pengguna.Tetapi bahkan dalam CTP publik pertama ini ada sesuatu yang signifikan bagi hampir semua orang, dan saya mendorong Anda untuk mencobanya sendiri!