Teman, selamat sore.
Ada pemahaman yang jelas bahwa sebagian besar proyek ICO pada dasarnya adalah aset tidak berwujud. Proyek ICO bukan mobil Mercedes-Benz - ia mengendarai mobil terlepas dari siapa yang menyukainya atau tidak. Dan pengaruh utama pada ICO diberikan oleh suasana hati orang - baik sikap terhadap pendiri / pendiri ICO dan proyek itu sendiri.
Akan lebih baik entah bagaimana mengukur sikap orang-orang terhadap pendiri ICO dan / atau proyek ICO. Yang sudah dilakukan. Laporannya di bawah.
Hasilnya adalah alat untuk mengumpulkan suasana hati positif / negatif dari Internet, khususnya dari Twitter.
Lingkungan saya adalah Windows 10 x64, menggunakan bahasa Python 3 di editor Spyder di Anaconda 5.1.0, koneksi jaringan kabel.
Pengumpulan data
Saya akan mendapatkan mood dari posting Twitter. Pertama, saya akan mencari tahu apa yang dilakukan pendiri ICO sekarang dan seberapa positif mereka menanggapi hal ini dengan contoh sepasang kepribadian terkenal.
Saya akan menggunakan perpustakaan python tweepy. Untuk bekerja dengan Twitter, Anda harus mendaftar sebagai pengembang di dalamnya, lihat twitter / . Dapatkan kriteria akses Twitter.
Kode tersebut adalah sebagai berikut:
import tweepy API_KEY = "vvvvEXQWhuF1fhAqAtoXRrrrr" API_SECRET = "vvvv30kspvqiezyPc26JafhRjRiZH3K12SGNgT0Ndsqu17rrrr" ACCESS_TOKEN = "vvvv712098-WBn6rZR4lXsnZCwcuU0aOsRkENSGpw2lppArrrr" ACCESS_TOKEN_SECRET = "vvvvlG7APRc5yGiWY5xFKfIGpqkHnXAvuwwVzMwyyrrrr" auth = tweepy.OAuthHandler(API_KEY, API_SECRET) auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) api = tweepy.API(auth)
Sekarang kita dapat membuka API Twitter dan mendapatkan sesuatu darinya, atau sebaliknya mempostingnya. Hal itu dilakukan pada awal Agustus. Anda perlu mendapatkan tweet untuk menemukan proyek pendiri saat ini. Dicari seperti ini:
import pandas as pd searchstring = searchinfo+' -filter:retweets' results = pd.DataFrame() coursor = tweepy.Cursor(api.search, q=searchstring, since="2018-07-07", lang="en", count = 500) for tweet in coursor.items(): my_series = pd.Series([str(tweet.id), tweet.created_at, tweet.text, tweet.retweeted], index=['id', 'title', 'text', 'retweeted']) result = pd.DataFrame(my_series).transpose() results = results.append(result, ignore_index = True) results.to_excel('results.xlsx')
Dalam searchinfo, kami mengganti nama yang diperlukan dan meneruskan. Hasilnya disimpan ke results.xlsx unggul.
Kreatif
Lalu saya memutuskan untuk membuat kreatif. Kita perlu menemukan proyek pendiri. Nama proyek adalah nama yang tepat dan dikapitalisasi. Misalkan ini juga tampaknya benar bahwa dengan huruf kapital di setiap tweet akan ditulis: 1) nama pendiri, 2) nama proyeknya, 3) kata pertama dari tweet dan 4) kata-kata asing. Kata 1 dan 2 akan sering ditemukan di tweet, dan 3 dan 4 jarang, dalam frekuensi kita 3 dan 4 dan disingkirkan. Ya, ternyata juga tautannya sering muncul dalam tweet, 5) kami juga akan menghapusnya.
Ternyata seperti ini:
import re import nltk nltk.download('stopwords') from nltk.corpus import stopwords from nltk.stem.porter import PorterStemmer corpus = [] for i in range(0, len(results.index)): review1 = [] mystr = results['text'][i]
Analisis Data Kreatif
Dalam variabel nama kita memiliki kata-kata, dan dalam variabel X - tempat di mana mereka disebutkan. "Matikan" tabel X - dapatkan jumlah referensi. Kami menghapus kata-kata yang jarang disebutkan. Simpan ke Excel. Dan di Excel kami membuat bagan batang yang indah dengan informasi tentang seberapa sering kata mana yang disebutkan dalam kueri mana.
Bintang super ICO kami adalah Le Minh Tam dan Mike Novogratz. Bagan:
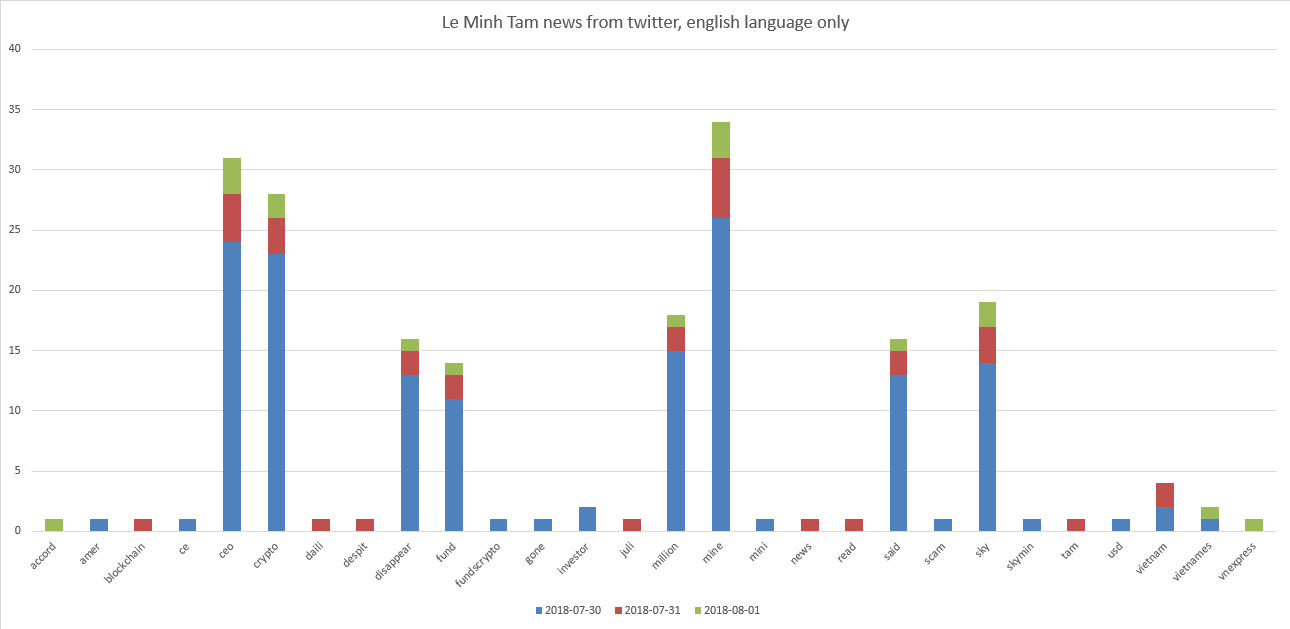
Dapat dilihat bahwa Le Minh Tam terkait dengan "ceo, crypto, mine, sky". Dan sedikit "menghilang, dana, juta".
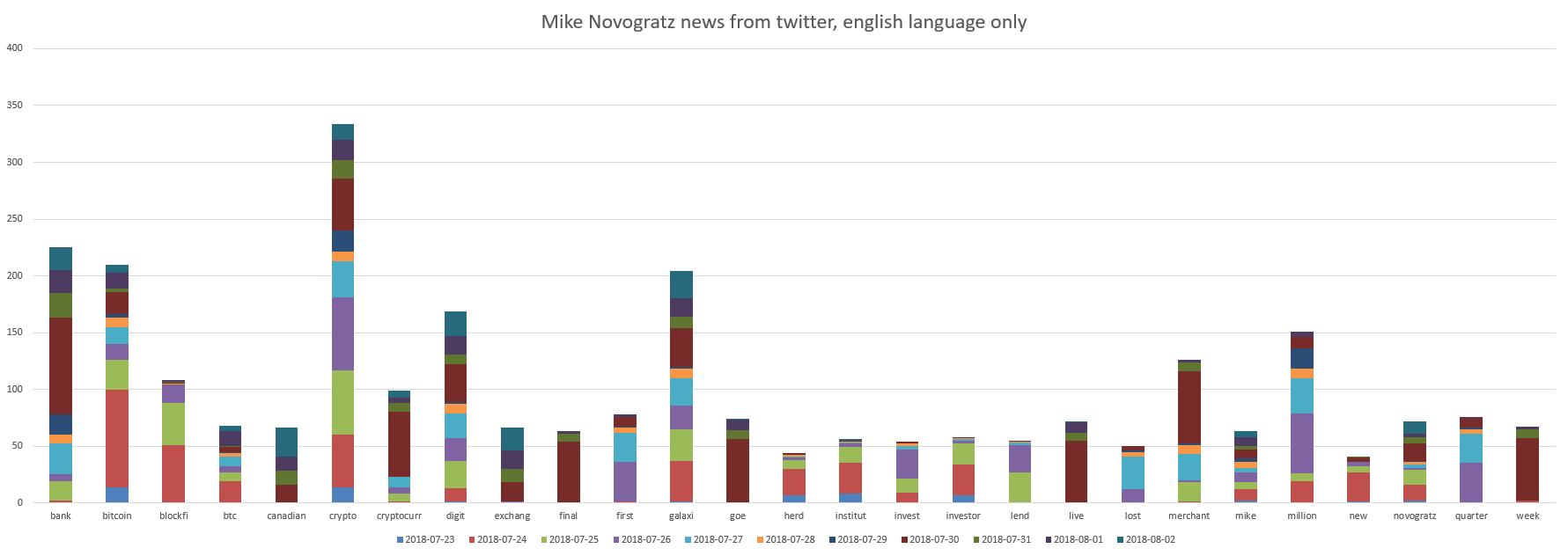
Dapat dilihat bahwa Mike Novogratz terkait dengan "bank, bitcoin, crypto, digit, galaxy".
Data dari X dapat dituangkan ke dalam jaringan saraf dan dapat belajar menentukan apa saja, tetapi Anda dapat:
Analisis data
Lalu kita berhenti main-main menjadi kreatif dan mulai menggunakan pustaka TextBlob python. Perpustakaan adalah keajaiban betapa baiknya.
Orang pintar mengatakan bahwa dia bisa:
- Sorot frasa
- lakukan penandaan bagian
- menganalisis suasana hati (ini berguna bagi kami di bawah),
- lakukan klasifikasi (naif bayes, decision tree),
- terjemahkan dan tentukan bahasa menggunakan Google Translate,
- lakukan tokenization (pisahkan teks menjadi kata-kata dan kalimat),
- mengidentifikasi frekuensi kata dan frasa,
- lakukan parsing
- mendeteksi n-gram
- jangan \ mengungkapkan infleksi \ deklinasi \ konjugasi kata-kata (pluralisasi dan singularisasi) dan lemmatization,
- ejaan yang benar.
Perpustakaan memungkinkan Anda untuk menambah model atau bahasa baru melalui ekstensi dan memiliki integrasi WordNet. Singkatnya, NLP adalah keajaiban anak .
Kami menyimpan hasil pencarian ke file results.xlsx di atas. Unduh dan lalui dengan TextBlob library untuk tujuan penilaian suasana hati:
from textblob import TextBlob results = pd.read_excel('results.xlsx') polarity = 0 for i in range(0, len(results.index)): polarity += TextBlob(results['text'][i]).sentiment.polarity print(polarity/i)
Hebat! Beberapa baris kode dan hasil yang bagus.
Ikhtisar Hasil
Ternyata pada awal Agustus 2018, tweet yang ditemukan pada permintaan "Le Minh Tam" menunjukkan sesuatu yang secara negatif tercermin dalam tweet dengan peringkat rata-rata semua tweet dikurangi 0,13 . Jika kita menonton tweet itu sendiri, maka kita akan melihat misalnya “CEO Crypto Mining Dikatakan Menghilang Dengan Dana $ 35 Juta Perusahaan Crypto, CEO Sky Mining, Le Minh Tam memiliki ...”.
Dan teman Mike Novogratz melakukan sesuatu yang secara positif tercermin dalam tweet dengan nilai rata-rata semua tweet plus 0,03 . Anda dapat menafsirkannya sehingga semuanya bergerak maju dengan tenang.
Rencana serangan
Untuk keperluan penilaian ICO, ada baiknya memonitor informasi tentang pendiri ICO dan ICO itu sendiri dari beberapa sumber. Sebagai contoh:
Rencanakan untuk memantau satu ICO:
- Buat daftar nama-nama pendiri ICO dan ICO itu sendiri,
- Kami membuat daftar sumber daya untuk pemantauan,
- Kami membuat robot yang mengumpulkan data untuk setiap baris dari 1 - untuk setiap sumber daya dari 2, contoh di atas,
- Kami membuat robot yang mengevaluasi setiap 3, contoh di atas,
- Simpan hasil 4 (dan 3),
- Ulangi langkah 3-5 setiap jam, secara otomatis, hasil penilaian dapat diposting / dikirim / disimpan di suatu tempat,
- Kami secara otomatis memantau lompatan dalam penilaian di paragraf 6. Jika ada lompatan dalam penilaian di paragraf 6, ini adalah kesempatan untuk melakukan studi tambahan tentang apa yang terjadi secara ahli. Dan menimbulkan kepanikan, atau sebaliknya bersukacita.
Ya, kira-kira seperti itu.
NB Nah, atau beli informasi ini, misalnya di sini thomsonreuters