Penafian: Saya tidak mempertimbangkan algoritma dan API apa pun untuk bekerja dengan pengenalan suara dan ucapan. Artikel ini adalah tentang masalah audio dan cara menyelesaikannya dengan Go.

phono adalah kerangka kerja aplikasi untuk bekerja dengan suara. Fungsi utamanya adalah membuat konveyor dari berbagai teknologi yang akan memproses suara untukmu dalam cara yang Anda butuhkan.
Apa hubungannya conveyor dengan itu, selain dari teknologi yang berbeda, dan mengapa kerangka kerja lain? Sekarang mari kita cari tahu.
Dari mana suara itu berasal?
Pada 2018, suara telah menjadi cara standar manusia berinteraksi dengan teknologi. Sebagian besar raksasa TI telah menciptakan asisten suara mereka sendiri atau sedang melakukannya sekarang. Kontrol suara sudah ada di sebagian besar sistem operasi, dan pesan suara adalah fitur khas dari setiap messenger. Di dunia, sekitar seribu startup bekerja pada pemrosesan bahasa alami dan sekitar dua ratus pada pengenalan suara.
Dengan musik, kisah serupa. Ini diputar dari perangkat apa pun, dan rekaman suara tersedia untuk semua orang yang memiliki komputer. Perangkat lunak musik dikembangkan oleh ratusan perusahaan dan ribuan penggemar di seluruh dunia.
Jika Anda harus bekerja dengan suara, maka kondisi berikut seharusnya terdengar familier:
- Audio harus diperoleh dari file, perangkat, jaringan, dll.
- Audio harus diproses : tambahkan efek, transcode, analisis, dll.
- Audio harus ditransfer ke file, perangkat, jaringan, dll.
- Data ditransmisikan dalam buffer kecil.
Ternyata pipa biasa - ada aliran data yang melewati beberapa tahap pemrosesan.
Solusi
Untuk kejelasan, mari kita ambil tugas dari kehidupan nyata. Misalnya, Anda perlu mengonversi suara ke teks:
- Kami merekam audio dari perangkat
- Hapus kebisingan
- Menyamakan
- Lewati sinyal ke API pengenalan suara
Seperti tugas lainnya, tugas ini memiliki beberapa solusi.
Dahi
Hardcore saja pengendara sepeda programmer. Kami merekam suara secara langsung melalui driver kartu suara, menulis pengurangan noise cerdas dan equalizer multi-band. Ini sangat menarik, tetapi Anda bisa melupakan tugas asli Anda selama beberapa bulan.
Panjang dan sangat sulit.
Normal
Alternatifnya adalah menggunakan API yang ada. Anda dapat merekam audio menggunakan ASIO, CoreAudio, PortAudio, ALSA dan lainnya. Ada juga beberapa jenis plugin untuk diproses: AAX, VST2, VST3, AU.
Pilihan yang luas tidak berarti Anda dapat menggunakan semuanya sekaligus. Biasanya, pembatasan berikut berlaku:
- Sistem operasi Tidak semua API tersedia di semua sistem operasi. Misalnya, AU adalah teknologi OS X asli dan hanya tersedia di sana.
- Bahasa pemrograman Kebanyakan pustaka audio ditulis dalam C atau C ++. Pada tahun 1996, Steinberg merilis versi pertama VST SDK, masih standar plugin paling populer. Setelah 20 tahun, tidak perlu lagi menulis dalam C / C ++: untuk VST ada pembungkus di Jawa, Python, C #, Rust, dan siapa yang tahu apa lagi. Meskipun bahasanya tetap menjadi batasan, sekarang bahkan suara diproses dalam JavaScript.
- Fungsional Jika tugasnya sederhana dan mudah, tidak perlu menulis aplikasi baru. FFmpeg yang sama dapat melakukan banyak hal.
Dalam situasi ini, kompleksitasnya tergantung pada pilihan Anda. Dalam kasus terburuk, Anda harus berurusan dengan beberapa perpustakaan. Dan jika Anda tidak beruntung sama sekali, dengan abstraksi yang kompleks dan antarmuka yang sangat berbeda.
Apa hasilnya?
Anda harus memilih antara sangat kompleks dan kompleks :
- baik berurusan dengan beberapa API tingkat rendah untuk menulis sepeda Anda
- baik berurusan dengan beberapa API dan mencoba berteman dengan mereka
Tidak peduli metode mana yang dipilih, tugas selalu turun ke conveyor. Teknologi yang digunakan dapat bervariasi, tetapi esensinya sama. Masalahnya adalah itu lagi, alih-alih menyelesaikan masalah nyata, Anda harus menulis sepeda ban berjalan.
Tapi ada jalan keluar.
phono

phono diciptakan untuk memecahkan masalah umum - untuk " menerima, memproses dan mengirimkan " suara. Untuk melakukan ini, ia menggunakan pipa sebagai abstraksi yang paling alami. Ada artikel di blog Go resmi yang menjelaskan pola saluran pipa. Gagasan utama dari pipeline adalah bahwa ada beberapa tahapan pemrosesan data yang bekerja secara independen satu sama lain dan bertukar data melalui saluran. Apa yang kamu butuhkan
Kenapa pergi?
Pertama, sebagian besar program audio dan perpustakaan ditulis dalam bahasa C, dan Go sering disebut sebagai penggantinya. Selain itu, ada cgo dan beberapa pengikat untuk perpustakaan audio yang ada. Anda dapat mengambil dan menggunakan.
Kedua, menurut pendapat pribadi saya, Go adalah bahasa yang baik. Saya tidak akan masuk terlalu dalam, tapi saya akan perhatikan multithreading -nya. Saluran dan gorutin sangat menyederhanakan implementasi conveyor.
Abstraksi
Jantung phono adalah jenis pipe.Pipe . Dialah yang mengimplementasikan pipa. Seperti dalam contoh dari blog , ada tiga jenis tahapan:
pipe.Pump (pompa bahasa Inggris) - menerima suara, hanya saluran keluaranpipe.Processor (prosesor bahasa Inggris) - saluran pemrosesan , input dan output suarapipe.Sink ( pipe.Sink Inggris) - transmisi suara, saluran input saja
Di dalam pipe.Pipe data dilewatkan dalam buffer. Aturan yang digunakan untuk membangun saluran pipa:
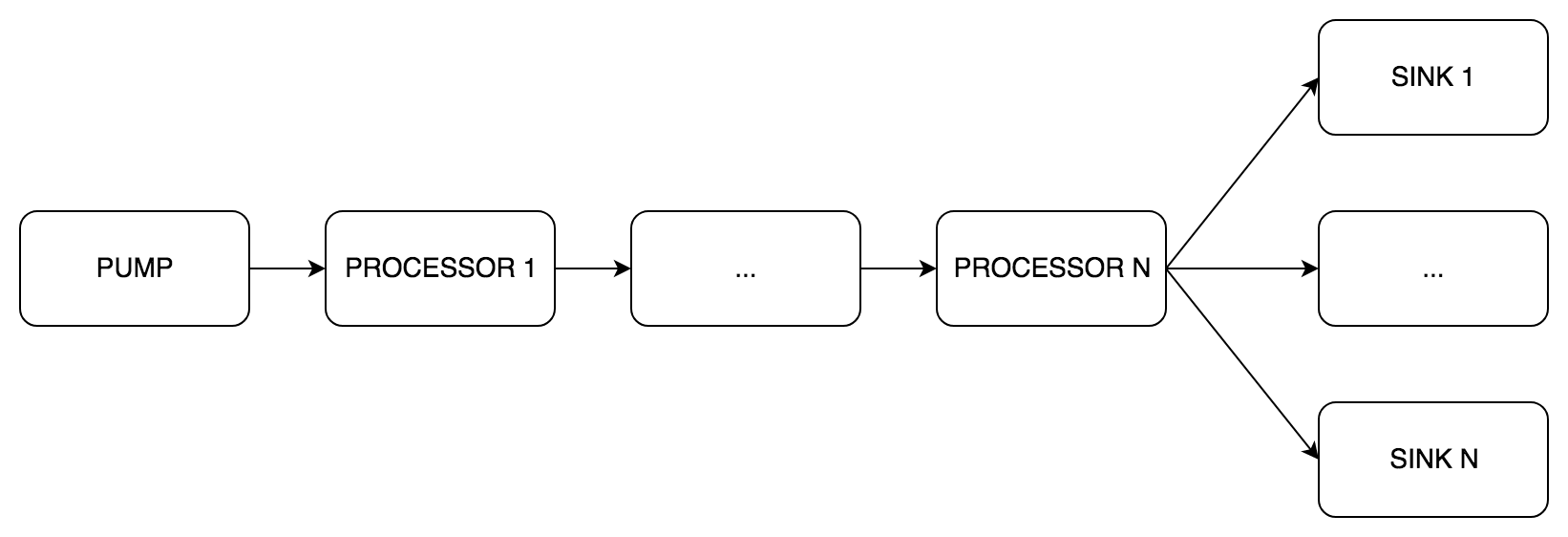
- Satu
pipe.Pump - Beberapa
pipe.Processor ditempatkan berurutan satu demi satu - Satu atau lebih
pipe.Sink ditempatkan secara paralel - Semua
pipe.Pipe Komponen pipe.Pipe harus memiliki yang sama:
- Ukuran Buffer (Pesan)
- Tingkat pengambilan sampel
- Jumlah saluran
Konfigurasi minimum adalah Pump dan satu Sink, sisanya opsional.
Mari kita lihat beberapa contoh.
Sederhana
Tugas: memutar file wav.
Mari kita bawa ke formulir " terima, proses, transfer ":
- Dapatkan audio dari file wav
- Transfer audio ke perangkat portaudio

Audio dibaca dan segera diputar.
Kode package example import ( "github.com/dudk/phono" "github.com/dudk/phono/pipe" "github.com/dudk/phono/portaudio" "github.com/dudk/phono/wav" )
Pertama, kita membuat elemen-elemen dari pipeline masa depan: wav.Pump dan portaudio.Sink dan berikan mereka ke pipe.New constructor baru. Fungsi p.Do(pipe.actionFn) error memulai pipa dan menunggu sampai selesai.
Lebih keras
Tugas: pisahkan file wav menjadi sampel, buat lagu dari mereka, simpan hasilnya dan putar secara bersamaan.
Trek adalah urutan sampel, dan sampel adalah segmen kecil audio. Untuk memotong audio, Anda harus terlebih dahulu memuatnya ke dalam memori. Untuk melakukan ini, gunakan jenis phono/asset . asset.Asset dari paket phono/asset . Kami membagi tugas menjadi langkah-langkah standar:
- Dapatkan audio dari file wav
- Transfer audio ke memori
Sekarang kami membuat sampel dengan tangan kami, menambahkannya ke trek dan menyelesaikan tugas:
- Dapatkan audio dari trek
- Transfer audio ke
- file wav
- perangkat portaudio
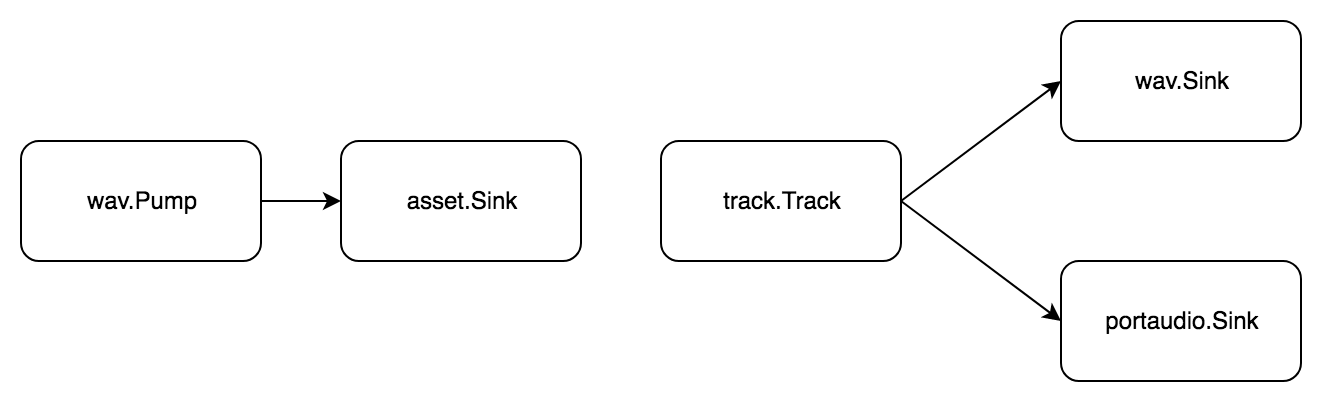
Sekali lagi, tanpa tahap pemrosesan, tetapi dua pipa!
Kode package example import ( "github.com/dudk/phono" "github.com/dudk/phono/asset" "github.com/dudk/phono/pipe" "github.com/dudk/phono/portaudio" "github.com/dudk/phono/track" "github.com/dudk/phono/wav" )
Dibandingkan dengan contoh sebelumnya, ada dua pipe.Pipe . Yang pertama mentransfer data ke memori sehingga Anda dapat memotong sampel. Yang kedua memiliki dua penerima di akhir: wav.Sink dan portaudio.Sink . Dengan skema ini, suara direkam secara bersamaan dalam file wav dan diputar.
Lebih keras
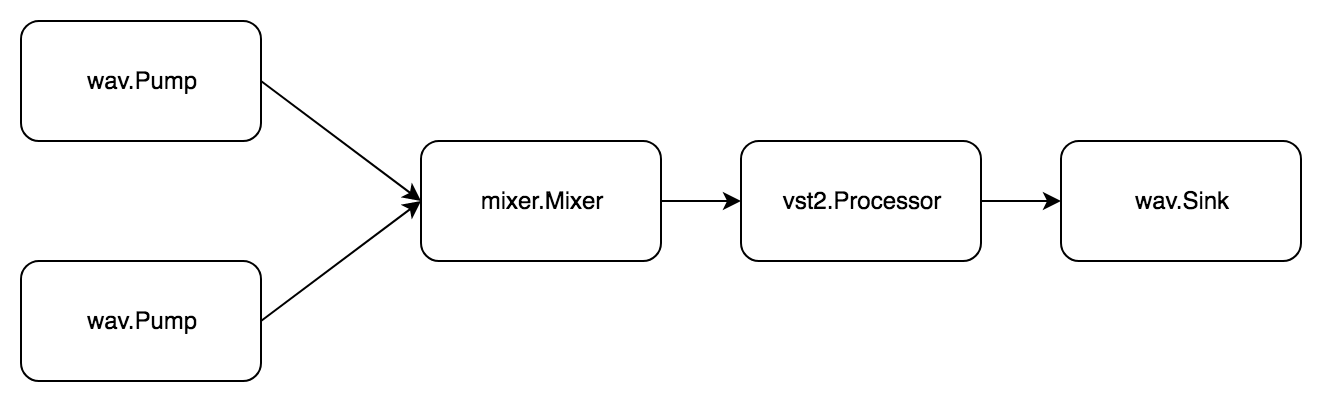
Tugas: membaca dua file wav, mencampur, memproses vst2 plugin dan menyimpan ke file wav baru.
Ada mixer.Mixer sederhana. mixer.Mixer dalam paket phono/mixer . Itu dapat mengirimkan sinyal dari beberapa sumber dan mendapatkan satu campuran. Untuk melakukan ini, ia secara bersamaan mengimplementasikan pipe.Sink . pipe.Sink dan pipe.Sink .
Sekali lagi, tugas terdiri dari dua subtugas. Yang pertama terlihat seperti ini:
- Dapatkan file audio wav
- Transfer audio ke mixer
Kedua:
- Dapatkan audio dari mixer.
- Memproses plugin audio
- Transfer audio ke file wav
Kode package example import ( "github.com/dudk/phono" "github.com/dudk/phono/mixer" "github.com/dudk/phono/pipe" "github.com/dudk/phono/vst2" "github.com/dudk/phono/wav" vst2sdk "github.com/dudk/vst2" )
Sudah ada tiga pipe.Pipe . pipe.Pipe , semua saling berhubungan melalui mixer. Untuk memulai, gunakan fungsi p.Begin(pipe.actionFn) (pipe.State, error) . Tidak seperti p.Do(pipe.actionFn) error , itu tidak memblokir panggilan, tetapi hanya mengembalikan keadaan yang kemudian bisa ditunggu dengan p.Wait(pipe.State) error .
Apa selanjutnya
Saya ingin phono menjadi kerangka kerja aplikasi yang paling nyaman. Jika Anda memiliki masalah dengan suara, Anda tidak perlu memahami API yang rumit dan menghabiskan waktu mempelajari standar. Yang diperlukan hanyalah membangun konveyor dari elemen yang sesuai dan menjalankannya.
Selama setengah tahun, paket-paket berikut difilmkan:
phono/wav - baca / tulis file wavphono/vst2 - binding tidak lengkap dari VST2 SDK, sementara Anda hanya dapat membuka plugin dan memanggil metode-metodenya, tetapi tidak semua strukturphono/mixer - mixer, menambahkan sinyal N, tanpa keseimbangan dan volumephono/asset - buffer samplingphono/track - pembacaan berurutan sampel (layering broken)phono/portaudio - pemutaran sinyal saat percobaan
Selain daftar ini, ada tumpukan ide dan ide baru yang terus tumbuh, termasuk:
- Hitung mundur
- Variabel pada pipa terbang
- Pompa HTTP / wastafel
- Parameter Otomatis
- Resampling prosesor
- Saldo dan volume mixer
- Pompa waktu nyata
- Pompa tersinkronisasi untuk banyak trek
- Vst2 penuh
Dalam artikel berikut saya akan menganalisis:
pipe.Pipe siklus hidup - karena struktur yang kompleks, pipe.Pipe dikendalikan oleh atom akhir- cara menulis tahap-tahap pipa Anda
Ini adalah proyek open-source pertama saya, jadi saya akan berterima kasih atas bantuan dan rekomendasi. Sama-sama
Referensi