Pada 22 September, kami mengadakan mitap non-standar pertama kami untuk pengembang sistem yang sarat muatan. Itu sangat keren, banyak umpan balik positif pada laporan dan karena itu memutuskan tidak hanya untuk mengunggahnya, tetapi juga untuk mendekripsi Habr. Hari ini kami menerbitkan pidato oleh Ivan Bubnov, DevOps dari BIT.GAMES. Dia berbicara tentang implementasi layanan penemuan Konsul dalam proyek beban tinggi yang sudah berjalan untuk kemungkinan penskalaan cepat dan kegagalan layanan negara. Dan juga tentang mengatur namespace yang fleksibel untuk aplikasi backend dan jebakan. Sekarang sepatah kata untuk Ivan.Saya mengelola infrastruktur produksi di studio BIT.GAMES dan menceritakan kisah pengenalan konsul dari Hashicorp dalam proyek kami "Guild of Heroes" - RPG fantasi dengan pvp asinkron untuk perangkat seluler. Tersedia di Google Play, App Store, Samsung, Amazon. DAU sekitar 100.000, online dari 10 hingga 13 ribu. Kami membuat game di Unity, jadi kami menulis klien di C # dan menggunakan bahasa skrip BHL kami sendiri untuk logika game. Kami menulis bagian server di Golang (beralih dari PHP). Berikutnya adalah arsitektur skematik proyek kami.
 Bahkan, ada lebih banyak layanan, hanya ada dasar-dasar logika permainan.
Bahkan, ada lebih banyak layanan, hanya ada dasar-dasar logika permainan.Jadi apa yang kita miliki. Dari layanan tanpa kewarganegaraan, ini adalah:
- nginx, yang kami gunakan sebagai Frontend dan Load Balancers dan mendistribusikan klien ke backend kami berdasarkan koefisien berat;
- gamed - backends, aplikasi yang dikompilasi dari Go. Ini adalah poros utama dari arsitektur kami, mereka melakukan bagian terbesar dari pekerjaan dan berkomunikasi dengan semua layanan backend lainnya.
Dari layanan Stateful, yang utama kami miliki adalah:
- Redis, yang kami gunakan untuk menyimpan informasi terbaru (kami juga menggunakannya untuk mengatur obrolan dalam game dan menyimpan notifikasi untuk pemain kami);
- Percona Server untuk Mysql adalah tempat penyimpanan informasi yang persisten (mungkin yang terbesar dan paling lambat dalam arsitektur apa pun). Kami menggunakan garpu MySQL dan di sini kami akan membicarakannya lebih detail hari ini.
Selama proses desain, kami (seperti orang lain) berharap bahwa proyek ini akan berhasil dan menyediakan mekanisme sharding. Ini terdiri dari dua entitas database MAINDB dan pecahan itu sendiri.

MAINDB adalah sejenis daftar isi - ini menyimpan informasi tentang data pecahan tertentu tentang kemajuan pemain yang disimpan. Dengan demikian, rangkaian pengambilan informasi lengkap terlihat seperti ini: klien mengakses frontend, yang pada gilirannya mendistribusikannya kembali ke salah satu backend, backend menuju MAINDB, melokalisasi pecahan pemain, dan kemudian memilih data langsung dari beling itu sendiri.
Tetapi ketika kami merancang, kami bukan proyek besar, jadi kami memutuskan untuk membuat pecahan pecahan hanya secara nominal. Mereka semua berada di server fisik yang sama dan kemungkinan besar partisi database dalam server yang sama.
Untuk cadangan, kami menggunakan replikasi slave master klasik. Itu bukan solusi yang sangat baik (saya akan mengatakan mengapa sedikit kemudian), tetapi kelemahan utama dari arsitektur itu adalah bahwa semua backend kita tahu tentang layanan backend lain secara eksklusif oleh alamat IP. Dan jika terjadi kecelakaan konyol lain di pusat data dari jenis "
maaf, teknisi kami menekan kabel pada server Anda sementara melayani yang lain dan kami membutuhkan waktu yang sangat lama untuk mencari tahu mengapa server Anda tidak terhubung " diperlukan gerakan besar dari kami. Pertama, ini adalah pembangunan kembali dan pra-instalasi backend dari server cadangan IP untuk tempat yang gagal. Kedua, setelah kejadian itu, perlu untuk mengembalikan tuan kita dari cadangan dari cadangan, karena ia dalam keadaan tidak konsisten dan membawanya ke keadaan terkoordinasi menggunakan replikasi yang sama. Kemudian kami kembali memasang backend dan mengisi ulang. Semua ini, tentu saja, menyebabkan downtime.
Ada saatnya ketika direktur teknis kami (yang sangat saya ucapkan terima kasih) berkata: "Teman-teman, hentikan penderitaan, kita perlu mengubah sesuatu, mari mencari jalan keluar." Pertama-tama, kami ingin mencapai proses penskalaan dan migrasi yang sederhana, mudah dipahami, dan paling penting - dikelola dari satu tempat ke tempat lain jika diperlukan. Selain itu, kami ingin mencapai ketersediaan tinggi dengan mengotomatiskan failover.
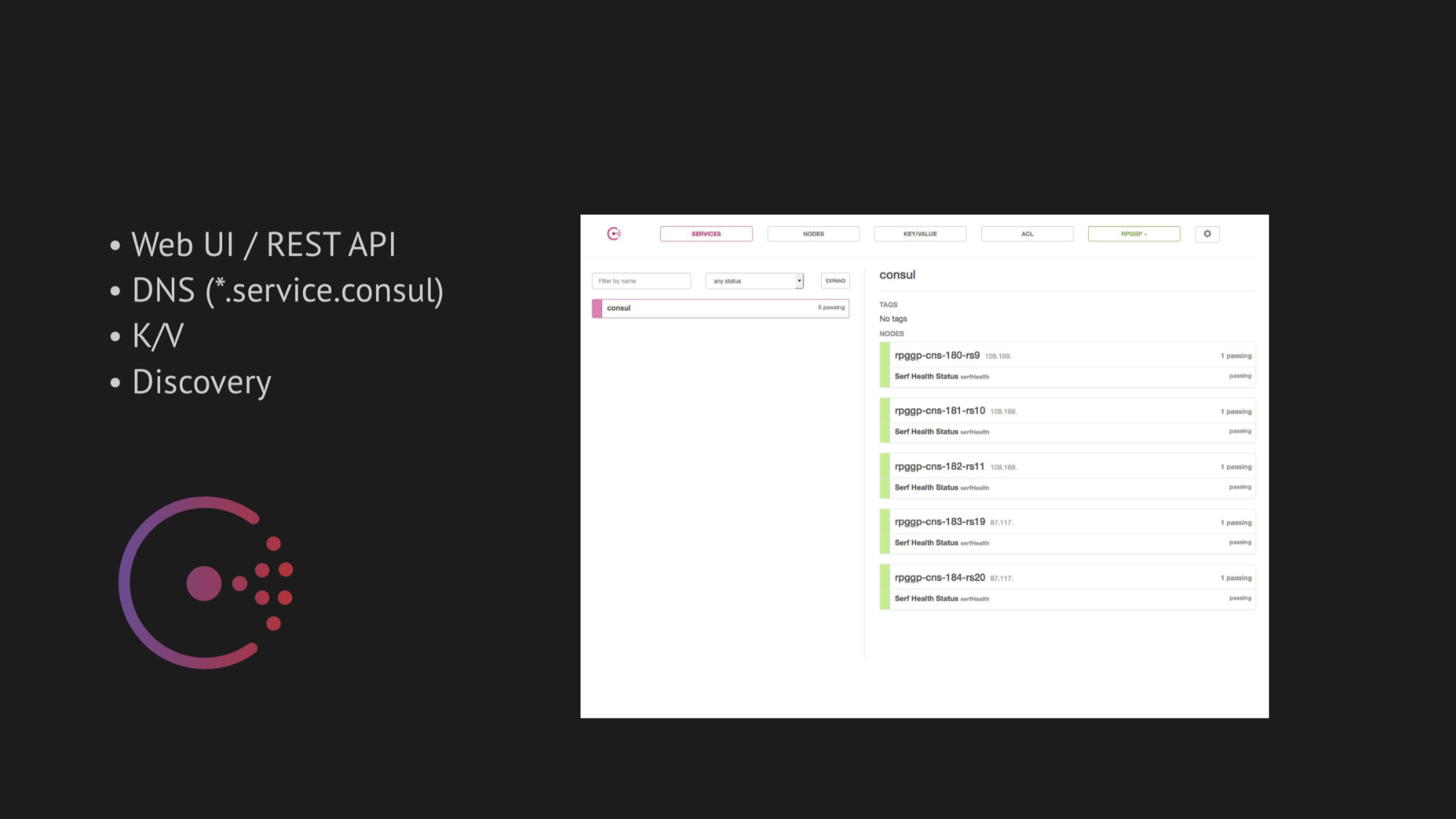
Sumbu sentral dari penelitian kami telah menjadi Konsul dari Hashicorp. Pertama, kami dinasihati, dan kedua, kami sangat tertarik dengan kesederhanaan, keramahan, dan tumpukan teknologi yang luar biasa dalam satu kotak: layanan penemuan dengan pemeriksaan kesehatan, penyimpanan bernilai-kunci dan hal terpenting yang ingin kami gunakan adalah DNS yang memutuskan kepada kami alamat dari domain service.consul.
Consul juga menyediakan UI Web dan REST API yang hebat untuk mengelola semua ini.
Adapun ketersediaan tinggi, kami memilih dua utilitas untuk failover otomatis:
- MHA untuk MySQL
- Redis-sentinel

Dalam kasus MHA untuk MySQL, kami menuangkan agen ke dalam node dengan basis data, dan mereka memantau keadaan mereka. Ada batas waktu tertentu dengan kegagalan master, setelah itu berhenti budak dibuat untuk menjaga konsistensi dan master cadangan kami dari master yang muncul dalam keadaan tidak konsisten tidak mengambil data. Dan kami menambahkan web hook ke agen-agen ini, yang terdaftar di sana IP baru cadangan master di Consul sendiri, setelah itu masuk ke penerbitan DNS.
Dengan Redis-sentinel, semuanya bahkan lebih sederhana. Karena dia sendiri melakukan bagian terbesar dari pekerjaan, semua yang tersisa untuk kita lakukan adalah untuk memperhitungkan dalam pemeriksaan kesehatan bahwa Redis-sentinel harus dilakukan secara eksklusif pada node master.
Awalnya semuanya bekerja dengan sempurna, seperti jam. Kami tidak punya masalah di bangku tes. Tapi itu layak pindah ke lingkungan alami transfer data dari pusat data yang dimuat, mengingat beberapa OOM-kill (ini kehabisan memori, di mana proses tersebut dibunuh oleh inti sistem) dan mengembalikan layanan atau hal-hal yang lebih canggih yang mempengaruhi ketersediaan layanan - bagaimana kita segera mendapatkan risiko serius positif palsu atau tidak ada respons yang terjamin sama sekali (jika Anda mencoba untuk memutar beberapa cek dalam upaya untuk melarikan diri dari positif palsu).

Pertama-tama, semuanya tergantung pada kesulitan menulis pemeriksaan kesehatan yang benar. Tampaknya tugasnya cukup sepele - periksa apakah layanan ini berjalan di server dan port pingani Anda. Tetapi, seperti yang diperlihatkan oleh praktik selanjutnya, menulis cek kesehatan ketika mengimplementasikan Konsul adalah proses yang sangat rumit dan memakan waktu. Karena begitu banyak faktor yang mempengaruhi ketersediaan layanan Anda di pusat data tidak dapat diramalkan - mereka terdeteksi hanya setelah waktu tertentu.
Selain itu, pusat data bukanlah struktur statis tempat Anda dibanjiri dan berfungsi sebagaimana mestinya. Tetapi kami, sayangnya (atau untungnya), baru mengetahui hal ini nanti, tetapi untuk saat ini kami terinspirasi dan penuh keyakinan bahwa kami akan mengimplementasikan segala sesuatu pada produksi.

Mengenai penskalaan, saya akan katakan secara singkat: kami mencoba menemukan sepeda yang sudah jadi, tetapi semuanya dirancang untuk arsitektur tertentu. Dan, seperti dalam kasus Jetpants, kami tidak dapat memenuhi persyaratan yang dikenakannya pada arsitektur penyimpanan informasi yang persisten.
Karena itu, kami memikirkan tentang skrip kami sendiri yang mengikat dan menunda pertanyaan ini. Kami memutuskan untuk bertindak secara konsisten dan mulai dengan penerapan Konsul.

Konsul adalah desentralisasi, cluster terdistribusi yang beroperasi berdasarkan protokol gosip dan algoritma konsensus Raft.
Kami memiliki equorum independen dari lima server (lima untuk menghindari situasi otak terpisah). Untuk setiap node, kami menumpahkan agen Konsul dalam mode agen dan menumpahkan semua pemeriksaan kesehatan (mis. Tidak ada sehingga kami mengunggah satu pemeriksaan kesehatan ke server tertentu dan lainnya ke server tertentu). Healthcheck ditulis sehingga mereka hanya lulus jika ada layanan.
Kami juga menggunakan utilitas lain sehingga kami tidak perlu mempelajari backend kami untuk menyelesaikan alamat dari domain tertentu pada port non-standar. Kami menggunakan Dnsmasq - ini menyediakan kemampuan untuk sepenuhnya menyelesaikan alamat pada node cluster yang kami butuhkan (yang di dunia nyata, jadi, tidak ada, tetapi ada secara eksklusif di dalam cluster). Kami menyiapkan skrip otomatis untuk mengisi Ansible, mengunggah semuanya ke produksi, menyetel namespace, memastikan semuanya selesai. Dan, sambil menggerakkan jari mereka, mengisi ulang backend kami, yang diakses bukan oleh alamat IP, tetapi dengan nama-nama ini dari server.consul domain.
Semuanya dimulai pertama kali, sukacita kami tidak mengenal batas. Tetapi masih terlalu dini untuk bersukacita, karena dalam satu jam kami memperhatikan bahwa pada semua simpul di mana backend kami berada, indikator rata-rata beban meningkat dari 0,7 menjadi 1,0, yang merupakan indikator yang agak gemuk.
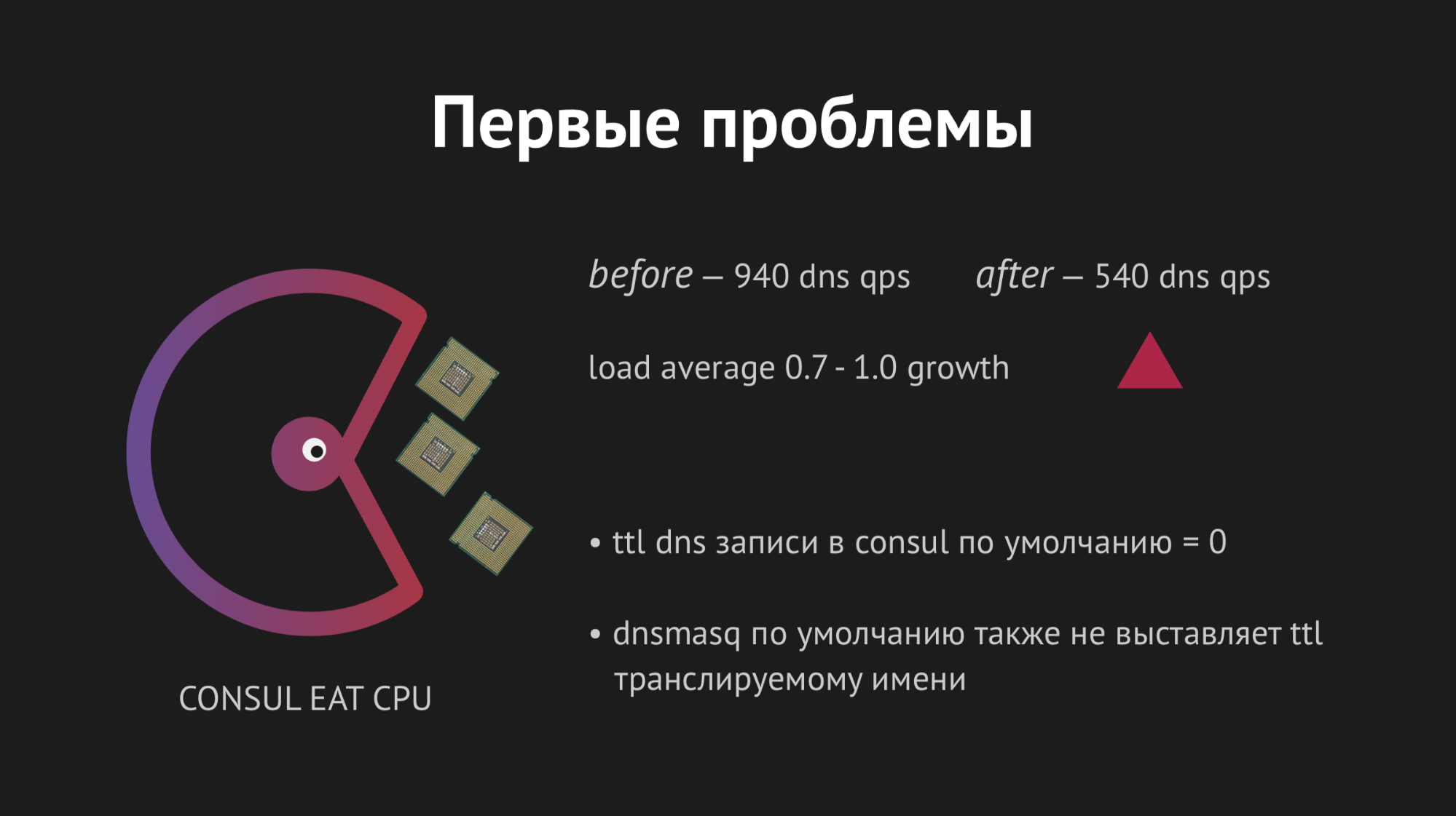
Saya naik ke server untuk melihat apa yang terjadi dan menjadi jelas bahwa CPU memakan Konsul. Di sini kita mulai mencari tahu, mulai perdukunan dengan strace (sebuah utilitas untuk sistem unix yang memungkinkan Anda untuk melacak syscall mana proses sedang berjalan), membuang statistik Dnsmasq untuk memahami apa yang terjadi pada node ini, dan ternyata kami melewatkan poin yang sangat penting. Saat merencanakan integrasi, kami melewatkan cache data DNS dan ternyata backend kami menarik Dnsmasq untuk setiap gerakannya, dan itu, pada gilirannya, beralih ke Konsul dan semua ini menghasilkan 940 kueri DNS per detik yang sakit-sakitan.
Jalan keluarnya tampak jelas - putar saja ttl dan semuanya akan menjadi lebih baik. Tetapi di sini tidak mungkin menjadi fanatik, karena kami ingin menerapkan struktur ini untuk mendapatkan namespace dinamis yang mudah dikendalikan dan cepat berubah (oleh karena itu, kami tidak dapat menetapkan, misalnya, 20 menit). Kami memutar ttl ke nilai optimal maksimum bagi kami, kami berhasil mengurangi tingkat permintaan per detik menjadi 540, tetapi ini tidak mempengaruhi indikator konsumsi CPU.
Kemudian kami memutuskan untuk keluar dengan cara yang rumit, menggunakan file host kustom.
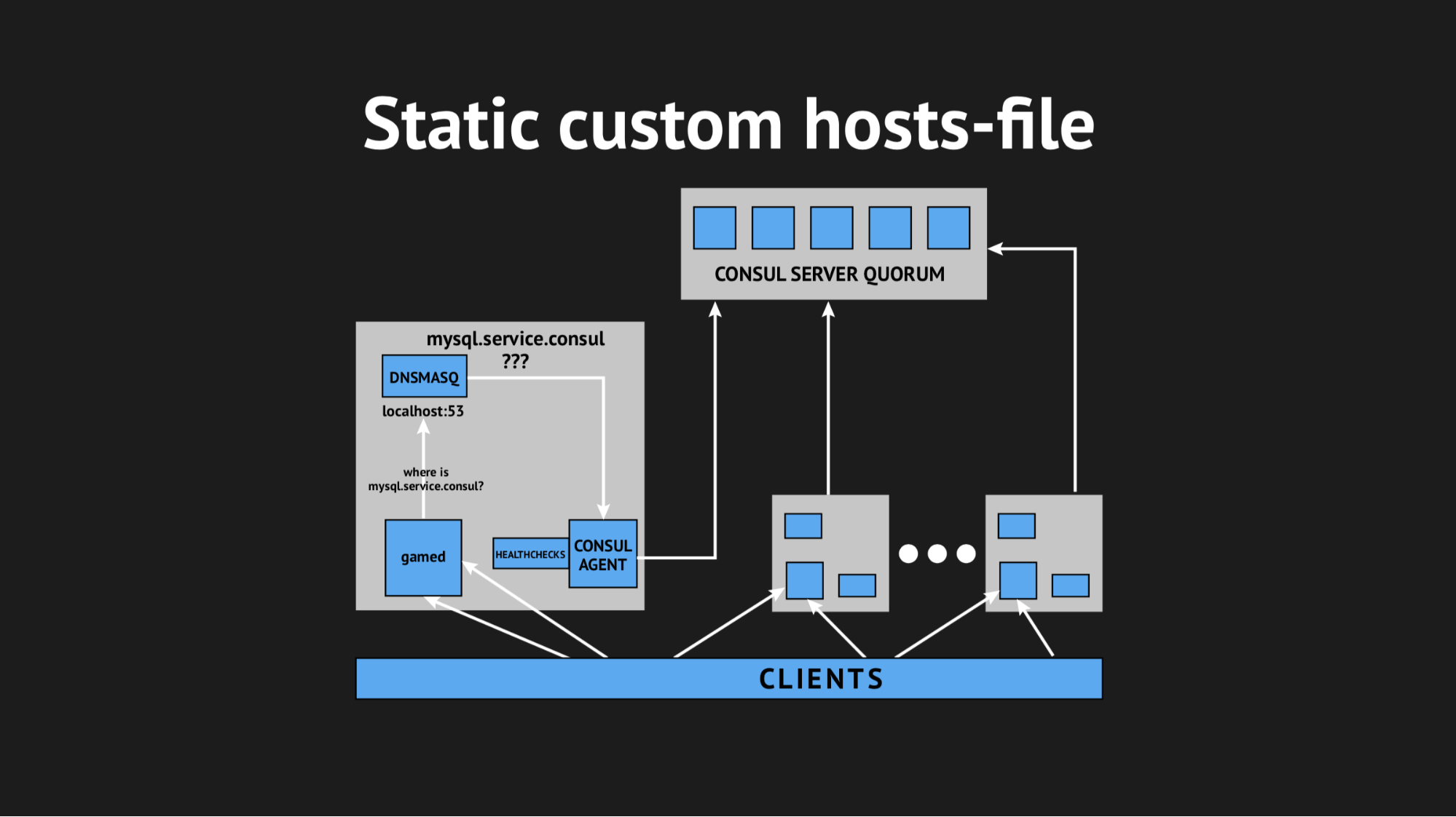
Sangat baik bahwa kami memiliki segalanya untuk ini: sistem template yang sangat baik dari Consul, yang, berdasarkan keadaan cluster dan skrip template, menghasilkan file dalam bentuk apa pun, konfigurasi apa pun yang Anda inginkan. Selain itu, Dnsmasq memiliki parameter konfigurasi addn-hosts yang memungkinkan Anda untuk menggunakan file host non-sistem sebagai file host tambahan yang sama.
Apa yang kami lakukan, sekali lagi menyiapkan skrip dalam Ansible, mengunggahnya ke produksi dan mulai terlihat seperti ini:
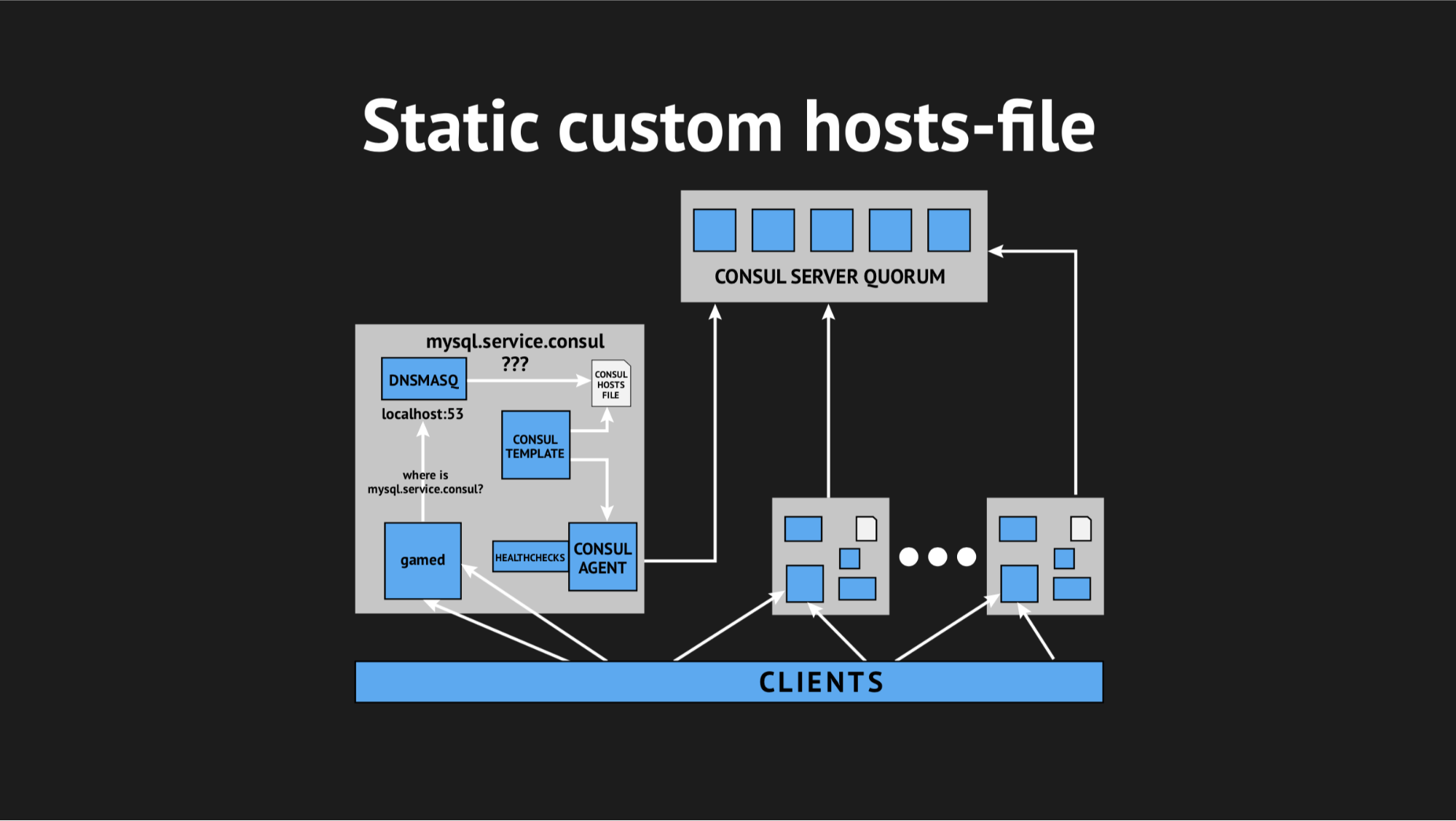
Ada elemen tambahan dan file statis pada disk, yang cukup cepat dibuat ulang. Sekarang rantai tampak cukup sederhana: gamed beralih ke Dnsmasq, dan pada gilirannya (alih-alih menarik agen Consula, yang akan bertanya pada server di mana kita memiliki simpul ini atau itu) hanya melihat file. Ini memecahkan masalah dengan konsumsi CPU oleh Konsul.
Sekarang semuanya mulai terlihat seperti yang kami rencanakan - benar-benar transparan untuk produksi kami, praktis tanpa memakan sumber daya.
Kami cukup tersiksa pada hari itu dan dengan cemas kami pulang. Mereka tidak takut sia-sia, karena pada malam hari peringatan dari pemantauan membangunkan saya dan memberi tahu saya bahwa kami memiliki kesalahan yang berskala besar (walaupun jangka pendek).
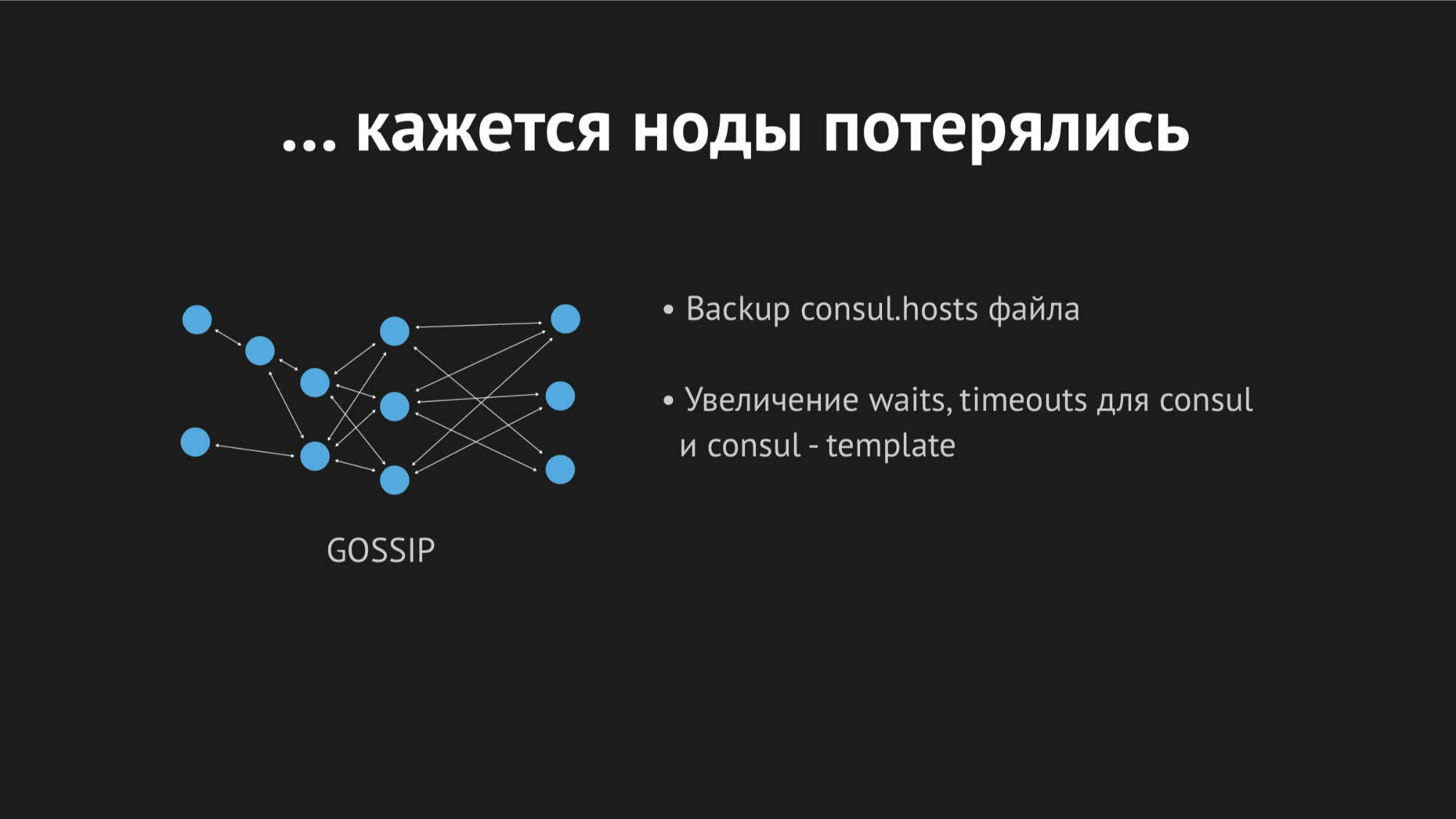
Berhubungan dengan log di pagi hari, saya melihat bahwa semua kesalahan adalah dari jenis host yang tidak diketahui sama. Tidak jelas mengapa Dnsmasq tidak dapat menggunakan satu atau layanan lain dari file - sepertinya tidak ada sama sekali. Untuk mencoba memahami apa yang sedang terjadi, saya menambahkan metrik khusus untuk membuat ulang file - sekarang saya tahu persis waktu kapan akan dibuat ulang. Selain itu, template Konsul itu sendiri memiliki opsi cadangan yang sangat baik, yaitu Anda dapat melihat status file regenerasi sebelumnya.
Pada siang hari, insiden itu berulang beberapa kali dan menjadi jelas bahwa pada suatu titik waktu (walaupun sifatnya sporadis, tidak sistematis), file host tanpa layanan spesifik apa pun akan dibuat ulang. Ternyata di pusat data tertentu (saya tidak akan melakukan anti-periklanan) ada jaringan yang agak tidak stabil - karena jaringan yang terputus-putus, kami benar-benar tidak dapat diprediksi berhenti melewati pemeriksaan kesehatan, atau bahkan simpul jatuh dari gugus. Itu terlihat seperti ini:
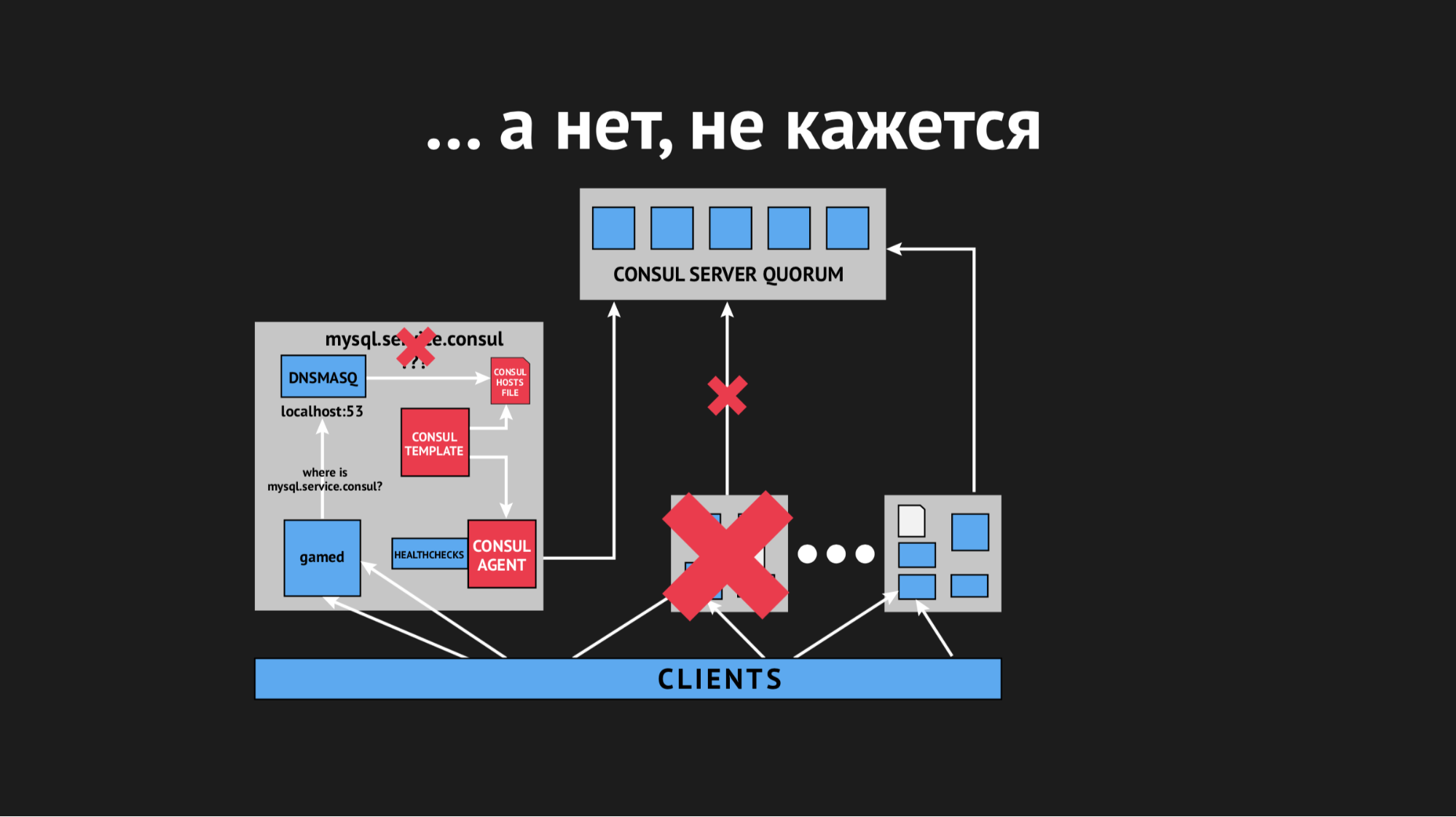
Node keluar dari cluster, agen Konsul segera diberitahu tentang hal ini, dan template Konsul segera membuat ulang file host tanpa layanan yang kami butuhkan. Ini umumnya tidak dapat diterima, karena masalahnya konyol: jika layanan tidak tersedia selama beberapa detik, siapkan waktu tunggu dan ulang (mereka tidak terhubung satu kali, tetapi yang kedua kali ternyata). Tapi kami memprovokasi struktur baru di penjual ketika layanan menghilang begitu saja dari pandangan dan tidak ada cara untuk terhubung dengannya.
Kami mulai berpikir tentang apa yang harus dilakukan dan memutar parameter batas waktu dalam Konsul, setelah itu diidentifikasi setelah berapa banyak node jatuh. Kami berhasil memecahkan masalah ini dengan indikator yang cukup kecil, node berhenti rontok, tetapi ini tidak membantu dengan pemeriksaan kesehatan.
Kami mulai berpikir untuk memilih parameter yang berbeda untuk pemeriksaan kesehatan, mencoba untuk entah bagaimana memahami kapan dan bagaimana ini terjadi. Tetapi karena kenyataan bahwa semuanya terjadi secara sporadis dan tidak terduga, kami tidak dapat melakukannya.
Kemudian kami pergi ke template Konsul dan memutuskan untuk membuat batas waktu untuk itu, setelah itu bereaksi terhadap perubahan status gugus. Sekali lagi, tidak mungkin menjadi fanatik, karena kita bisa sampai pada situasi di mana hasilnya tidak akan lebih baik daripada DNS klasik, ketika kita membidik yang sama sekali berbeda.
Dan sekali lagi direktur teknis kami datang ke penyelamatan dan berkata: "Guys, mari kita coba untuk melepaskan semua interaktivitas ini, kita semua dalam produksi dan tidak ada waktu untuk penelitian, kita perlu menyelesaikan masalah ini. Mari manfaatkan hal-hal sederhana dan mudah dimengerti. ” Jadi kami sampai pada konsep menggunakan penyimpanan kunci-nilai sebagai sumber untuk menghasilkan file host.
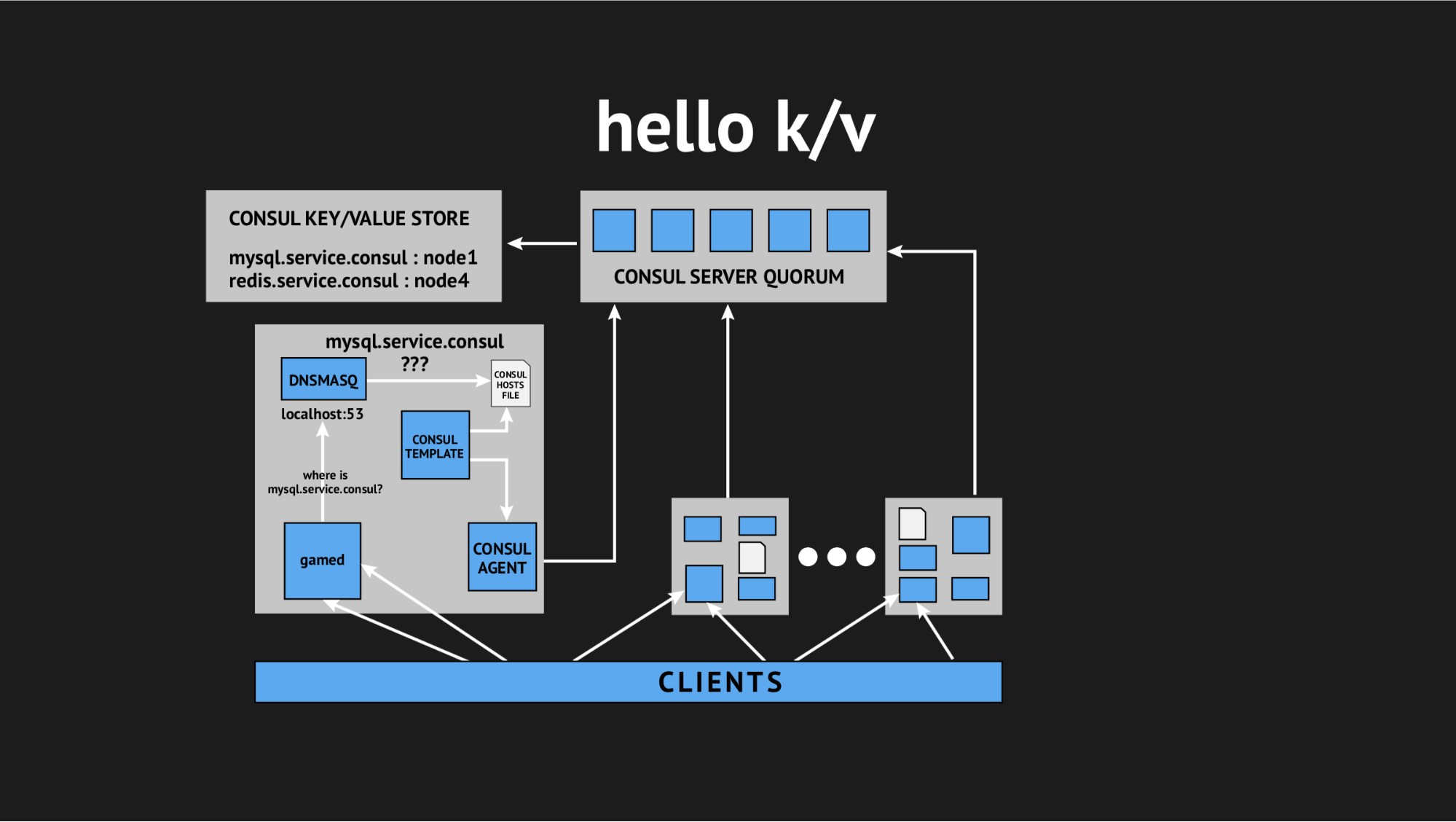
Seperti apa tampilannya: kami menolak semua pemeriksaan kesehatan dinamis, menulis ulang skrip templat kami sehingga menghasilkan file berdasarkan data yang direkam dalam penyimpanan nilai kunci. Di penyimpanan nilai-kunci, kami menggambarkan seluruh infrastruktur kami dalam bentuk nama kunci (ini adalah nama layanan yang kami butuhkan) dan nilai kunci (ini adalah nama dari simpul dalam gugus). Yaitu jika node ada di cluster, maka kita dengan mudah mendapatkan alamat IP-nya dan menuliskannya ke file hosts.
Kami menguji semuanya, mengisinya dalam produksi, dan itu menjadi peluru perak dalam situasi tertentu. Sekali lagi, kami cukup tersiksa sepanjang hari pulang, tetapi kembali sudah beristirahat, didorong, karena masalah ini tidak terulang dan tidak terulang selama setahun terakhir. Dari mana saya pribadi menyimpulkan bahwa ini adalah keputusan yang tepat (khusus untuk kami).
Jadi Kami akhirnya mendapatkan apa yang kami inginkan dan mengatur namespace dinamis untuk backend kami. Lebih lanjut kami berupaya memastikan ketersediaan tinggi.

Tetapi kenyataannya adalah bahwa cukup takut pada integrasi Konsul dan karena masalah yang kami temui, kami berpikir dan memutuskan bahwa menerapkan auto-failover bukanlah solusi yang baik, karena sekali lagi kita mengambil risiko kesalahan positif atau kegagalan. Proses ini buram dan tidak terkendali.
Oleh karena itu, kami menempuh jalan yang lebih sederhana (atau kompleks): kami memutuskan untuk meninggalkan kegagalan dengan hati nurani administrator yang bertugas, tetapi memberinya alat tambahan lain. Kami telah mengganti replikasi master slave dengan replikasi master master dalam mode Baca saja. Ini menghilangkan sejumlah besar sakit kepala dalam proses failover'ov - ketika Anda mendapatkan panduan, yang perlu Anda lakukan adalah mengubah nilai dalam penyimpanan k / v menggunakan UI Web atau perintah dalam API dan sebelum itu, mode Baca saja master cadangan.
Setelah insiden selesai, master kontak dan secara otomatis datang ke keadaan terkoordinasi tanpa tindakan yang tidak perlu. Kami berhenti pada opsi ini dan menggunakannya seperti sebelumnya - bagi kami itu senyaman mungkin, dan yang paling penting sesederhana mungkin, sejernih dan terkontrol.
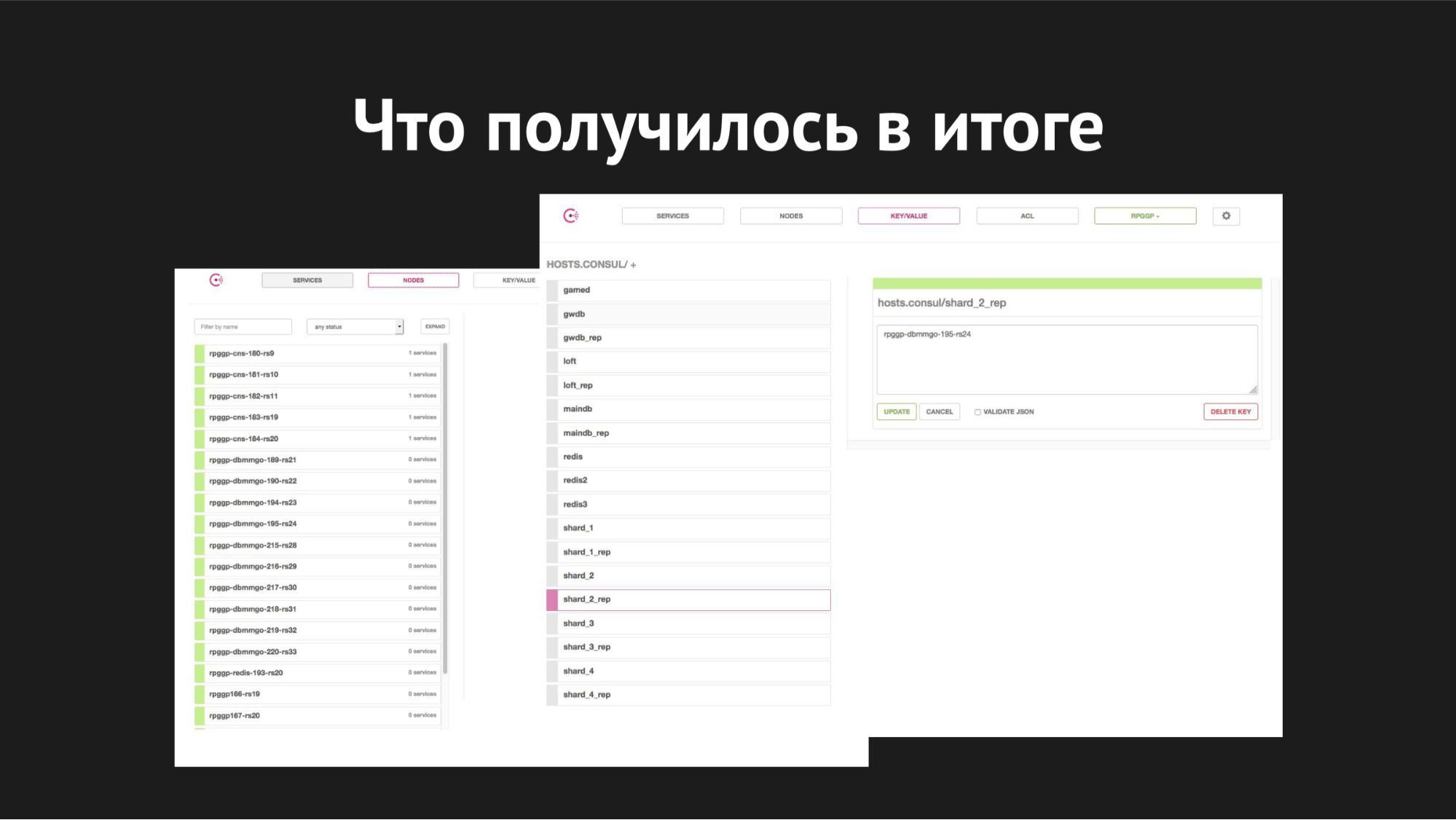 Antarmuka Web Konsul
Antarmuka Web KonsulDi sebelah kanan adalah penyimpanan k / v dan layanan kami terlihat, yang kami gunakan dalam gamed; nilai adalah nama simpul.
Sedangkan untuk penskalaan, kami mulai menerapkannya ketika pecahan sudah penuh di satu server, basis bertambah, menjadi lambat, jumlah pemain meningkat, kami bertukar dan kami memiliki tugas mendistribusikan semua pecahan ke server kami yang berbeda.

Bagaimana kelihatannya: menggunakan utilitas XtraBackup, kami memulihkan cadangan kami pada sepasang server baru, setelah itu master baru digantung dengan seorang budak pada yang lama. Itu datang ke keadaan yang konsisten, kami mengubah nilai kunci dalam k / v-storage dari nama node master lama ke nama node master baru. Kemudian (ketika kami percaya bahwa semuanya berjalan dengan benar dan semua bermain dengan pilihan mereka, pembaruan, sisipan pergi ke master baru), kami hanya harus membunuh replikasi dan membuat drop database yang didambakan pada produksi, karena kita semua suka melakukan dengan database yang tidak perlu.

Jadi pecahan kami hancur. 40 , backend' ( , — ).

failover', — 20 40 . .
— , , - , .
-, , , , - , , , .
- , , ; — , , , .
k/v — ?K/v- Consul- - , http- RESTful API Web UI.
, - , , .
, Redis?, - .
-, backend. -, backend', — . Yaitu , MAINDB , . . - , .
- , inmemory key-value -.
?MySQL — Percona server.
? Maria, MHA for MySQL, Galera.Galera. - « » Galera , . , .
, — , , - , , , .
Pixonic DevGAMM Talks