Hai, Habr, dalam artikel ini saya akan berbicara tentang perpustakaan menyalakan , dengan mana Anda dapat dengan mudah melatih dan menguji jaringan saraf menggunakan kerangka kerja PyTorch.
Dengan penyalaan, Anda dapat menulis siklus untuk melatih jaringan hanya dalam beberapa baris, menambahkan perhitungan metrik standar dari kotak, menyimpan model, dll. Nah, bagi mereka yang telah pindah dari TF ke PyTorch, kita dapat mengatakan bahwa perpustakaan yang menyala adalah Keras untuk PyTorch.
Artikel ini akan memeriksa secara rinci contoh pelatihan jaringan saraf untuk tugas klasifikasi menggunakan ignite.

Tambahkan lebih banyak api ke PyTorch
Saya tidak akan membuang waktu berbicara tentang betapa kerennya kerangka PyTorch. Siapa pun yang telah menggunakannya memahami apa yang saya tulis. Tetapi, dengan semua kelebihannya, masih rendah dalam hal siklus penulisan untuk pelatihan, pengujian, pengujian jaringan saraf.
Jika kita melihat contoh resmi menggunakan kerangka PyTorch, kita akan melihat setidaknya dua siklus iterasi oleh zaman dan oleh batch pelatihan yang diatur dalam kode pelatihan grid:
for epoch in range(1, epochs + 1): for batch_idx, (data, target) in enumerate(train_loader):
Gagasan utama dari perpustakaan yang menyala adalah untuk memfaktorkan loop ini ke dalam satu kelas, sementara memungkinkan pengguna untuk berinteraksi dengan loop ini menggunakan event handler.
Akibatnya, dalam kasus tugas pembelajaran dalam standar, kita dapat menyimpan banyak pada jumlah baris kode. Lebih sedikit baris - lebih sedikit kesalahan!
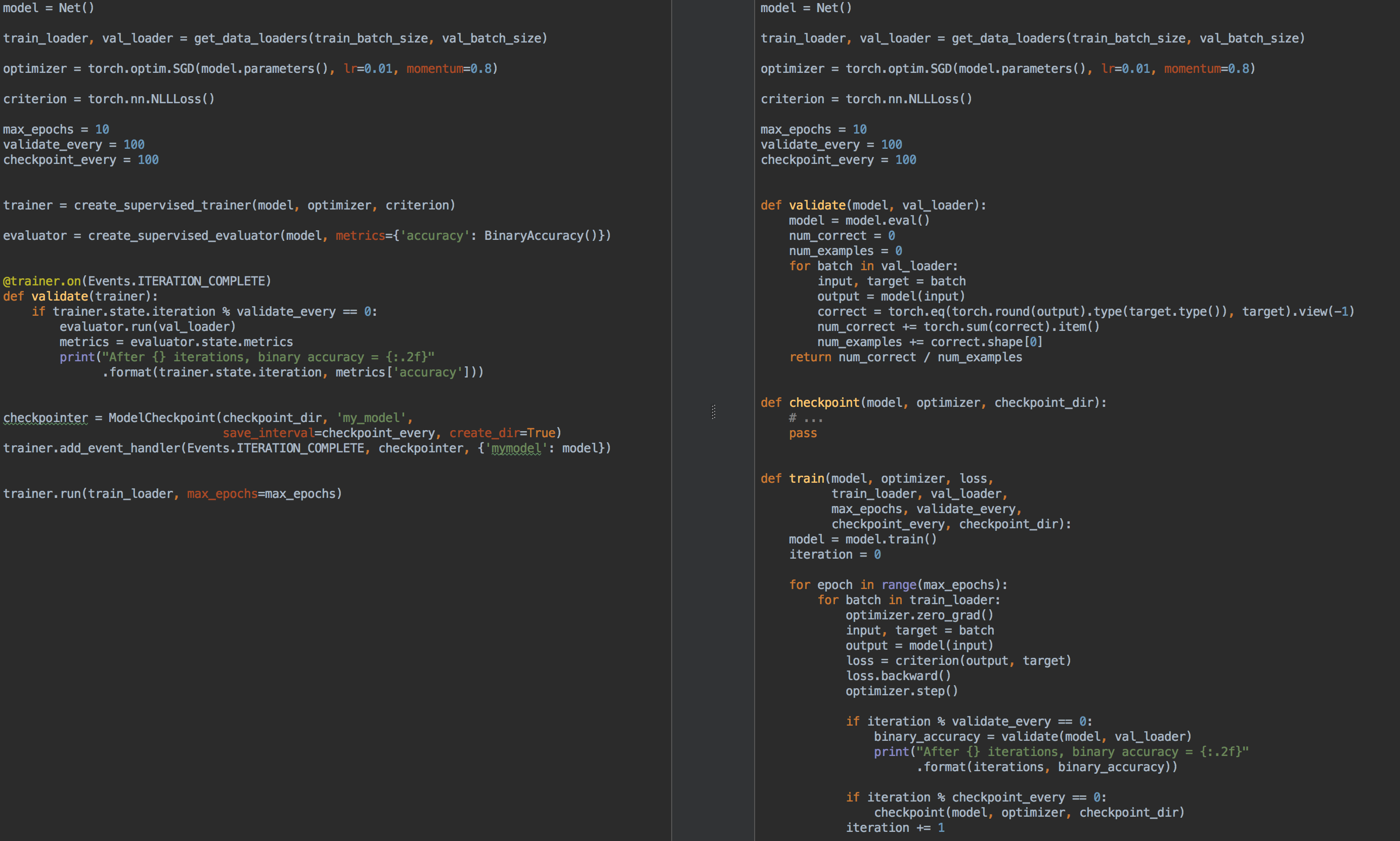
Misalnya, untuk perbandingan, di sebelah kiri adalah kode untuk pelatihan dan validasi model menggunakan ignite , dan di sebelah kanan adalah PyTorch murni:
Jadi sekali lagi, untuk apa menyalakan api ?
- Anda tidak perlu lagi menulis untuk setiap loop tugas
for epoch in range(n_epochs) dan for batch in data_loader . - memungkinkan Anda membuat kode faktorisasi yang lebih baik
- memungkinkan Anda menghitung metrik dasar di luar kotak
- menyediakan "roti" seperti
- menyimpan model terbaru dan terbaik (juga pengoptimal dan penjadwal tingkat pembelajaran) selama pelatihan,
- berhenti belajar awal
- dll.
- mudah diintegrasikan dengan alat visualisasi: tensorboardX, visdom, ...
Dalam arti, seperti yang telah disebutkan, perpustakaan yang menyala dapat dibandingkan dengan semua Keras terkenal dan API-nya untuk pelatihan dan pengujian jaringan. Juga, perpustakaan menyalakan pada pandangan pertama sangat mirip dengan perpustakaan tnt , karena pada awalnya kedua perpustakaan memiliki tujuan yang sama dan memiliki ide yang sama untuk implementasinya.
Jadi, nyalakan:
pip install pytorch-ignite
atau
conda install ignite -c pytorch
Selanjutnya, dengan contoh spesifik, kami akan membiasakan diri dengan API pustaka api .
Tugas klasifikasi dengan menyalakan
Pada bagian artikel ini, kami akan mempertimbangkan contoh sekolah melatih jaringan saraf untuk masalah klasifikasi menggunakan perpustakaan nyala .
Jadi, mari kita ambil dataset sederhana dengan gambar buah-buahan dengan kaggle . Tugasnya adalah untuk mengasosiasikan kelas yang sesuai dengan masing-masing gambar buah.
Sebelum menggunakan ignite , mari kita tentukan komponen utama:
Aliran data
- melatih pemuat pengumpul sampel,
train_loader - checkout pengunduh batch,
val_loader
Model:
- ambil kotak squeezeNet kecil dari
torchvision
Algoritma Optimasi:
Fungsi kerugian:
Kode from pathlib import Path import numpy as np import torch from torch.utils.data import Dataset, DataLoader from torch.utils.data.dataset import Subset from torchvision.datasets import ImageFolder from torchvision.transforms import Compose, RandomResizedCrop, RandomVerticalFlip, RandomHorizontalFlip from torchvision.transforms import ColorJitter, ToTensor, Normalize FRUIT360_PATH = Path(".").resolve().parent / "input" / "fruits-360_dataset" / "fruits-360" device = "cuda" train_transform = Compose([ RandomHorizontalFlip(), RandomResizedCrop(size=32), ColorJitter(brightness=0.12), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) val_transform = Compose([ RandomResizedCrop(size=32), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) batch_size = 128 num_workers = 8 train_dataset = ImageFolder((FRUIT360_PATH /"Training").as_posix(), transform=train_transform, target_transform=None) val_dataset = ImageFolder((FRUIT360_PATH /"Test").as_posix(), transform=val_transform, target_transform=None) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
import torch.nn as nn from torchvision.models.squeezenet import squeezenet1_1 model = squeezenet1_1(pretrained=False, num_classes=81) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device)
import torch.nn as nn from torch.optim import SGD optimizer = SGD(model.parameters(), lr=0.01, momentum=0.5) criterion = nn.CrossEntropyLoss()
Jadi sekarang saatnya untuk menjalankan penyalaan :
from ignite.engine import Engine, _prepare_batch def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item() trainer = Engine(process_function)
Mari kita lihat apa arti kode ini.
Mesin Engine
Kelas ignite.engine.Engine adalah framework library, dan objek dari class ini adalah trainer :
trainer = Engine(process_function)
Ini didefinisikan dengan fungsi fungsi input proses untuk memproses satu batch dan berfungsi untuk menerapkan pass untuk sampel pelatihan. Di dalam kelas ignite.engine.Engine , hal berikut terjadi:
while epoch < max_epochs:
Kembali ke fungsi process_function :
def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item()
Kita melihat bahwa di dalam fungsi kita, seperti biasa dalam hal pelatihan model, menghitung prediksi y_pred , menghitung fungsi loss , loss dan gradien. Yang terakhir memungkinkan Anda untuk memperbarui bobot model: optimizer.step() .
Secara umum, tidak ada batasan pada kode fungsi process_function . Kami hanya mencatat bahwa dibutuhkan dua argumen sebagai input: objek Engine (dalam kasus kami, trainer ) dan kumpulan dari pemuat data. Oleh karena itu, misalnya, untuk menguji jaringan saraf, kita dapat mendefinisikan objek lain dari kelas ignite.engine.Engine , di mana fungsi input hanya menghitung prediksi, dan mengimplementasikan lulus melalui sampel uji sekali. Baca tentang itu nanti.
Jadi, kode di atas hanya mendefinisikan objek yang diperlukan tanpa memulai pelatihan. Pada dasarnya, dalam contoh minimal, Anda dapat memanggil metode:
trainer.run(train_loader, max_epochs=10)
dan kode ini cukup untuk "diam-diam" (tanpa derivasi hasil antara) melatih model.
Sebuah catatanPerhatikan juga bahwa untuk tugas-tugas jenis ini perpustakaan memiliki metode yang mudah untuk membuat objek trainer :
from ignite.engine import create_supervised_trainer trainer = create_supervised_trainer(model, optimizer, criterion, device)
Tentu saja, dalam praktiknya, contoh di atas tidak terlalu menarik, jadi mari kita tambahkan opsi berikut untuk "pelatih":
- tampilan nilai fungsi kerugian setiap 50 iterasi
- mulai perhitungan metrik pada set pelatihan dengan model tetap
- mulai perhitungan metrik pada sampel uji setelah setiap era
- menyimpan parameter model setelah setiap era
- pelestarian tiga model terbaik
- perubahan kecepatan belajar tergantung pada zaman (penjadwalan tingkat pembelajaran)
- pelatihan penghentian dini (early-stopping)
Acara dan Penangan Acara
Untuk menambahkan opsi di atas untuk "pelatih", perpustakaan menyalakan menyediakan sistem acara dan peluncuran penangan acara kustom. Dengan demikian, pengguna dapat mengontrol objek kelas Engine pada setiap tahap:
- mesin memulai / menyelesaikan peluncuran
- era dimulai / berakhir
- iterasi batch dimulai / berakhir
dan jalankan kode Anda di setiap acara.
Menampilkan nilai fungsi kerugian
Untuk melakukan ini, cukup tentukan fungsi di mana output akan ditampilkan di layar, dan tambahkan ke "trainer":
from ignite.engine import Events log_interval = 50 @trainer.on(Events.ITERATION_COMPLETED) def log_training_loss(engine): iteration = (engine.state.iteration - 1) % len(train_loader) + 1 if iteration % log_interval == 0: print("Epoch[{}] Iteration[{}/{}] Loss: {:.4f}" .format(engine.state.epoch, iteration, len(train_loader), engine.state.output))
Sebenarnya ada dua cara untuk menambahkan event handler: melalui add_event_handler , atau melalui dekorator on . Hal yang sama seperti di atas dapat dilakukan seperti ini:
from ignite.engine import Events log_interval = 50 def log_training_loss(engine):
Perhatikan bahwa argumen apa pun dapat diteruskan ke fungsi penanganan acara. Secara umum, fungsi seperti itu akan terlihat seperti ini:
def custom_handler(engine, *args, **kwargs): pass trainer.add_event_handler(Events.ITERATION_COMPLETED, custom_handler, *args, **kwargs)
Jadi, mari kita mulai pelatihan di satu era dan lihat apa yang terjadi:
output = trainer.run(train_loader, max_epochs=1)
Epoch[1] Iteration[50/322] Loss: 4.3459 Epoch[1] Iteration[100/322] Loss: 4.2801 Epoch[1] Iteration[150/322] Loss: 4.2294 Epoch[1] Iteration[200/322] Loss: 4.1467 Epoch[1] Iteration[250/322] Loss: 3.8607 Epoch[1] Iteration[300/322] Loss: 3.6688
Tidak buruk! Mari kita melangkah lebih jauh.
Mulai perhitungan metrik pada pelatihan dan sampel uji
Mari kita hitung metrik berikut: akurasi rata-rata, kelengkapan rata-rata setelah setiap era pada bagian pelatihan dan seluruh sampel uji. Perhatikan bahwa kami akan menghitung metrik pada bagian sampel pelatihan setelah setiap era pelatihan, dan bukan selama pelatihan. Dengan demikian, pengukuran efisiensi akan lebih akurat karena model tidak berubah selama perhitungan.
Jadi, kami mendefinisikan metrik:
from ignite.metrics import Loss, CategoricalAccuracy, Precision, Recall metrics = { 'avg_loss': Loss(criterion), 'avg_accuracy': CategoricalAccuracy(), 'avg_precision': Precision(average=True), 'avg_recall': Recall(average=True) }
Selanjutnya, kita akan membuat dua mesin untuk mengevaluasi model menggunakan ignite.engine.create_supervised_evaluator :
from ignite.engine import create_supervised_evaluator
Kami membuat dua mesin untuk lebih melampirkan penangan acara tambahan ke salah satunya ( val_evaluator ) untuk menyimpan model dan berhenti belajar lebih awal (tentang semua ini di bawah).
Mari kita juga melihat lebih dekat bagaimana mesin untuk mengevaluasi model didefinisikan, yaitu, bagaimana fungsi fungsi input proses didefinisikan untuk memproses satu batch:
def create_supervised_evaluator(model, metrics={}, device=None): if device: model.to(device) def _inference(engine, batch): model.eval() with torch.no_grad(): x, y = _prepare_batch(batch, device=device) y_pred = model(x) return y_pred, y engine = Engine(_inference) for name, metric in metrics.items(): metric.attach(engine, name) return engine
Kami melanjutkan lebih jauh. Biarkan kami secara acak memilih bagian dari sampel pelatihan yang akan kami hitung metriknya:
import numpy as np from torch.utils.data.dataset import Subset indices = np.arange(len(train_dataset)) random_indices = np.random.permutation(indices)[:len(val_dataset)] train_subset = Subset(train_dataset, indices=random_indices) train_eval_loader = DataLoader(train_subset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device)
Selanjutnya, mari kita tentukan pada titik mana dalam pelatihan kita akan memulai perhitungan metrik dan akan ditampilkan ke layar:
@trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_offline_train_metrics(engine): epoch = engine.state.epoch print("Compute train metrics...") metrics = train_evaluator.run(train_eval_loader).metrics print("Training Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall'])) @trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_val_metrics(engine): epoch = engine.state.epoch print("Compute validation metrics...") metrics = val_evaluator.run(val_loader).metrics print("Validation Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall']))
Kamu bisa lari!
output = trainer.run(train_loader, max_epochs=1)
Kita sampai di layar
Epoch[1] Iteration[50/322] Loss: 3.5112 Epoch[1] Iteration[100/322] Loss: 2.9840 Epoch[1] Iteration[150/322] Loss: 2.8807 Epoch[1] Iteration[200/322] Loss: 2.9285 Epoch[1] Iteration[250/322] Loss: 2.5026 Epoch[1] Iteration[300/322] Loss: 2.1944 Compute train metrics... Training Results - Epoch: 1 Average Loss: 2.1018 | Accuracy: 0.3699 | Precision: 0.3981 | Recall: 0.3686 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 2.0519 | Accuracy: 0.3850 | Precision: 0.3578 | Recall: 0.3845
Sudah lebih baik!
Beberapa detail
Mari kita lihat sedikit kode sebelumnya. Pembaca mungkin memperhatikan baris kode berikut:
metrics = train_evaluator.run(train_eval_loader).metrics
dan mungkin ada pertanyaan tentang jenis objek yang diperoleh dari train_evaluator.run(train_eval_loader) , yang memiliki atribut metrics .
Bahkan, kelas Engine berisi struktur yang disebut state (tipe State ) agar dapat mentransfer data antara event handler. Atribut state ini berisi informasi dasar tentang era saat ini, iterasi, jumlah era, dll. Itu juga dapat digunakan untuk mentransfer data pengguna apa pun, termasuk hasil perhitungan metrik.
state = train_evaluator.run(train_eval_loader) metrics = state.metrics
Perhitungan metrik selama pelatihan
Jika tugas memiliki sampel pelatihan yang sangat besar dan penghitungan metrik setelah setiap zaman pelatihan mahal, tetapi Anda masih ingin melihat beberapa metrik berubah selama pelatihan, Anda dapat menggunakan pengendali event RunningAverage berikut dari kotak. Sebagai contoh, kami ingin menghitung dan menampilkan akurasi classifier:
acc_metric = RunningAverage(CategoryAccuracy(...), alpha=0.98) acc_metric.attach(trainer, 'running_avg_accuracy') @trainer.on(Events.ITERATION_COMPLETED) def log_running_avg_metrics(engine): print("running avg accuracy:", engine.state.metrics['running_avg_accuracy'])
Untuk menggunakan fungsionalitas RunningAverage , Anda perlu menginstal ignite dari sumber:
pip install git+https:
Penjadwalan tingkat pembelajaran
Ada beberapa cara untuk mengubah kecepatan belajar menggunakan ignite . Selanjutnya, pertimbangkan metode paling sederhana dengan memanggil fungsi lr_scheduler.step() di awal setiap era.
from torch.optim.lr_scheduler import ExponentialLR lr_scheduler = ExponentialLR(optimizer, gamma=0.8) @trainer.on(Events.EPOCH_STARTED) def update_lr_scheduler(engine): lr_scheduler.step()
Menyimpan model terbaik dan parameter lain selama pelatihan
Selama pelatihan, akan sangat bagus untuk merekam bobot model terbaik pada disk, serta secara berkala menyimpan bobot model, parameter pengoptimal, dan parameter untuk mengubah kecepatan belajar. Yang terakhir ini mungkin berguna untuk melanjutkan belajar dari keadaan tersimpan terakhir.
Ignite memiliki kelas ModelCheckpoint khusus untuk ini. Jadi, mari kita membuat event ModelCheckpoint dan menyimpan model terbaik dalam hal akurasi dalam set tes. Dalam kasus ini, kami mendefinisikan fungsi score_function yang memberikan nilai akurasi ke pengendali event dan memutuskan apakah akan menyimpan model atau tidak:
from ignite.handlers import ModelCheckpoint def score_function(engine): val_avg_accuracy = engine.state.metrics['avg_accuracy'] return val_avg_accuracy best_model_saver = ModelCheckpoint("best_models", filename_prefix="model", score_name="val_accuracy", score_function=score_function, n_saved=3, save_as_state_dict=True, create_dir=True)
Sekarang buat event ModelCheckpoint lain untuk mempertahankan status pembelajaran setiap 1000 iterasi:
training_saver = ModelCheckpoint("checkpoint", filename_prefix="checkpoint", save_interval=1000, n_saved=1, save_as_state_dict=True, create_dir=True) to_save = {"model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler} trainer.add_event_handler(Events.ITERATION_COMPLETED, training_saver, to_save)
Jadi, hampir semuanya sudah siap, tambahkan elemen terakhir:
Pelatihan hentikan dini (hentikan dini)
Mari kita tambahkan event handler lain yang akan berhenti belajar jika tidak ada peningkatan kualitas model lebih dari 10 era. Kami akan mengevaluasi kualitas model lagi menggunakan score_function score_function.
from ignite.handlers import EarlyStopping early_stopping = EarlyStopping(patience=10, score_function=score_function, trainer=trainer) val_evaluator.add_event_handler(Events.EPOCH_COMPLETED, early_stopping)
Mulai pelatihan
Untuk memulai pelatihan, cukup bagi kita untuk memanggil metode run() . Kami akan melatih model untuk 10 era:
max_epochs = 10 output = trainer.run(train_loader, max_epochs=max_epochs)
Output layar Learning rate: 0.01 Epoch[1] Iteration[50/322] Loss: 2.7984 Epoch[1] Iteration[100/322] Loss: 1.9736 Epoch[1] Iteration[150/322] Loss: 4.3419 Epoch[1] Iteration[200/322] Loss: 2.0261 Epoch[1] Iteration[250/322] Loss: 2.1724 Epoch[1] Iteration[300/322] Loss: 2.1599 Compute train metrics... Training Results - Epoch: 1 Average Loss: 1.5363 | Accuracy: 0.5177 | Precision: 0.5477 | Recall: 0.5178 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 1.5116 | Accuracy: 0.5139 | Precision: 0.5400 | Recall: 0.5140 Learning rate: 0.008 Epoch[2] Iteration[50/322] Loss: 1.4076 Epoch[2] Iteration[100/322] Loss: 1.4892 Epoch[2] Iteration[150/322] Loss: 1.2485 Epoch[2] Iteration[200/322] Loss: 1.6511 Epoch[2] Iteration[250/322] Loss: 3.3376 Epoch[2] Iteration[300/322] Loss: 1.3299 Compute train metrics... Training Results - Epoch: 2 Average Loss: 3.2686 | Accuracy: 0.1977 | Precision: 0.1792 | Recall: 0.1942 Compute validation metrics... Validation Results - Epoch: 2 Average Loss: 3.2772 | Accuracy: 0.1962 | Precision: 0.1628 | Recall: 0.1918 Learning rate: 0.006400000000000001 Epoch[3] Iteration[50/322] Loss: 0.9016 Epoch[3] Iteration[100/322] Loss: 1.2006 Epoch[3] Iteration[150/322] Loss: 0.8892 Epoch[3] Iteration[200/322] Loss: 0.8141 Epoch[3] Iteration[250/322] Loss: 1.4005 Epoch[3] Iteration[300/322] Loss: 0.8888 Compute train metrics... Training Results - Epoch: 3 Average Loss: 0.7368 | Accuracy: 0.7554 | Precision: 0.7818 | Recall: 0.7554 Compute validation metrics... Validation Results - Epoch: 3 Average Loss: 0.7177 | Accuracy: 0.7623 | Precision: 0.7863 | Recall: 0.7611 Learning rate: 0.005120000000000001 Epoch[4] Iteration[50/322] Loss: 0.8490 Epoch[4] Iteration[100/322] Loss: 0.8493 Epoch[4] Iteration[150/322] Loss: 0.8100 Epoch[4] Iteration[200/322] Loss: 0.9165 Epoch[4] Iteration[250/322] Loss: 0.9370 Epoch[4] Iteration[300/322] Loss: 0.6548 Compute train metrics... Training Results - Epoch: 4 Average Loss: 0.7047 | Accuracy: 0.7713 | Precision: 0.8040 | Recall: 0.7728 Compute validation metrics... Validation Results - Epoch: 4 Average Loss: 0.6737 | Accuracy: 0.7778 | Precision: 0.7955 | Recall: 0.7806 Learning rate: 0.004096000000000001 Epoch[5] Iteration[50/322] Loss: 0.6965 Epoch[5] Iteration[100/322] Loss: 0.6196 Epoch[5] Iteration[150/322] Loss: 0.6194 Epoch[5] Iteration[200/322] Loss: 0.3986 Epoch[5] Iteration[250/322] Loss: 0.6032 Epoch[5] Iteration[300/322] Loss: 0.7152 Compute train metrics... Training Results - Epoch: 5 Average Loss: 0.5049 | Accuracy: 0.8282 | Precision: 0.8393 | Recall: 0.8314 Compute validation metrics... Validation Results - Epoch: 5 Average Loss: 0.5084 | Accuracy: 0.8304 | Precision: 0.8386 | Recall: 0.8328 Learning rate: 0.0032768000000000007 Epoch[6] Iteration[50/322] Loss: 0.4433 Epoch[6] Iteration[100/322] Loss: 0.4764 Epoch[6] Iteration[150/322] Loss: 0.5578 Epoch[6] Iteration[200/322] Loss: 0.3684 Epoch[6] Iteration[250/322] Loss: 0.4847 Epoch[6] Iteration[300/322] Loss: 0.3811 Compute train metrics... Training Results - Epoch: 6 Average Loss: 0.4383 | Accuracy: 0.8474 | Precision: 0.8618 | Recall: 0.8495 Compute validation metrics... Validation Results - Epoch: 6 Average Loss: 0.4419 | Accuracy: 0.8446 | Precision: 0.8532 | Recall: 0.8442 Learning rate: 0.002621440000000001 Epoch[7] Iteration[50/322] Loss: 0.4447 Epoch[7] Iteration[100/322] Loss: 0.4602 Epoch[7] Iteration[150/322] Loss: 0.5345 Epoch[7] Iteration[200/322] Loss: 0.3973 Epoch[7] Iteration[250/322] Loss: 0.5023 Epoch[7] Iteration[300/322] Loss: 0.5303 Compute train metrics... Training Results - Epoch: 7 Average Loss: 0.4305 | Accuracy: 0.8579 | Precision: 0.8691 | Recall: 0.8596 Compute validation metrics... Validation Results - Epoch: 7 Average Loss: 0.4262 | Accuracy: 0.8590 | Precision: 0.8685 | Recall: 0.8606 Learning rate: 0.002097152000000001 Epoch[8] Iteration[50/322] Loss: 0.4867 Epoch[8] Iteration[100/322] Loss: 0.3090 Epoch[8] Iteration[150/322] Loss: 0.3721 Epoch[8] Iteration[200/322] Loss: 0.4559 Epoch[8] Iteration[250/322] Loss: 0.3958 Epoch[8] Iteration[300/322] Loss: 0.4222 Compute train metrics... Training Results - Epoch: 8 Average Loss: 0.3432 | Accuracy: 0.8818 | Precision: 0.8895 | Recall: 0.8817 Compute validation metrics... Validation Results - Epoch: 8 Average Loss: 0.3644 | Accuracy: 0.8713 | Precision: 0.8784 | Recall: 0.8707 Learning rate: 0.001677721600000001 Epoch[9] Iteration[50/322] Loss: 0.3557 Epoch[9] Iteration[100/322] Loss: 0.3692 Epoch[9] Iteration[150/322] Loss: 0.3510 Epoch[9] Iteration[200/322] Loss: 0.3446 Epoch[9] Iteration[250/322] Loss: 0.3966 Epoch[9] Iteration[300/322] Loss: 0.3451 Compute train metrics... Training Results - Epoch: 9 Average Loss: 0.3315 | Accuracy: 0.8954 | Precision: 0.9001 | Recall: 0.8982 Compute validation metrics... Validation Results - Epoch: 9 Average Loss: 0.3559 | Accuracy: 0.8818 | Precision: 0.8876 | Recall: 0.8847 Learning rate: 0.0013421772800000006 Epoch[10] Iteration[50/322] Loss: 0.3340 Epoch[10] Iteration[100/322] Loss: 0.3370 Epoch[10] Iteration[150/322] Loss: 0.3694 Epoch[10] Iteration[200/322] Loss: 0.3409 Epoch[10] Iteration[250/322] Loss: 0.4420 Epoch[10] Iteration[300/322] Loss: 0.2770 Compute train metrics... Training Results - Epoch: 10 Average Loss: 0.3246 | Accuracy: 0.8921 | Precision: 0.8988 | Recall: 0.8925 Compute validation metrics... Validation Results - Epoch: 10 Average Loss: 0.3536 | Accuracy: 0.8731 | Precision: 0.8785 | Recall: 0.8722
Sekarang periksa model dan parameter yang disimpan ke disk:
ls best_models/ model_best_model_10_val_accuracy=0.8730994.pth model_best_model_8_val_accuracy=0.8712978.pth model_best_model_9_val_accuracy=0.8818188.pth
dan
ls checkpoint/ checkpoint_lr_scheduler_3000.pth checkpoint_optimizer_3000.pth checkpoint_model_3000.pth
Prediksi oleh model yang terlatih
Pertama, buat pemuat data uji (misalnya, ambil sampel validasi) sehingga kumpulan data terdiri dari gambar dan indeksnya:
class TestDataset(Dataset): def __init__(self, ds): self.ds = ds def __len__(self): return len(self.ds) def __getitem__(self, index): return self.ds[index][0], index test_dataset = TestDataset(val_dataset) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
Menggunakan ignite, kami akan membuat mesin prediksi baru untuk data uji. Untuk melakukan ini, kita mendefinisikan fungsi inference_update , yang mengembalikan hasil prediksi dan indeks gambar. Untuk meningkatkan akurasi, kami juga akan menggunakan trik terkenal "test time augmentation" (TTA).
import torch.nn.functional as F from ignite._utils import convert_tensor def _prepare_batch(batch): x, index = batch x = convert_tensor(x, device=device) return x, index def inference_update(engine, batch): x, indices = _prepare_batch(batch) y_pred = model(x) y_pred = F.softmax(y_pred, dim=1) return {"y_pred": convert_tensor(y_pred, device='cpu'), "indices": indices} model.eval() inferencer = Engine(inference_update)
Selanjutnya, buat pengendali acara yang akan memberi tahu tentang tahap prediksi dan menyimpan prediksi dalam array khusus:
@inferencer.on(Events.EPOCH_COMPLETED) def log_tta(engine): print("TTA {} / {}".format(engine.state.epoch, n_tta)) n_tta = 3 num_classes = 81 n_samples = len(val_dataset) # y_probas_tta = np.zeros((n_samples, num_classes, n_tta), dtype=np.float32) @inferencer.on(Events.ITERATION_COMPLETED) def save_results(engine): output = engine.state.output tta_index = engine.state.epoch - 1 start_index = ((engine.state.iteration - 1) % len(test_loader)) * batch_size end_index = min(start_index + batch_size, n_samples) batch_y_probas = output['y_pred'].detach().numpy() y_probas_tta[start_index:end_index, :, tta_index] = batch_y_probas
Sebelum memulai proses, mari unduh model terbaik:
model = squeezenet1_1(pretrained=False, num_classes=64) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device) model_state_dict = torch.load("best_models/model_best_model_10_val_accuracy=0.8730994.pth") model.load_state_dict(model_state_dict)
Kami meluncurkan:
inferencer.run(test_loader, max_epochs=n_tta) > TTA 1 / 3 > TTA 2 / 3 > TTA 3 / 3
Selanjutnya, dengan cara standar, kami mengambil rata-rata prediksi TTA dan menghitung indeks kelas dengan probabilitas tertinggi:
y_probas = np.mean(y_probas_tta, axis=-1) y_preds = np.argmax(y_probas, axis=-1)
Dan sekarang kita dapat sekali lagi menghitung keakuratan model sesuai dengan prediksi:
from sklearn.metrics import accuracy_score y_test_true = [y for _, y in val_dataset] accuracy_score(y_test_true, y_preds) > 0.9310369676443035
, , . , , , ignite .
.
github
- fast neural transfer
- reinforcement learning
- dcgan
Kesimpulan
, ignite Facebook (. ). 0.1.0, API (Engine, State, Events, Metric, ...) . , , , pull request- github .
Terima kasih atas perhatian anda!