Enron Corporation adalah salah satu tokoh paling terkenal dalam bisnis Amerika di tahun 2000-an. Ini difasilitasi bukan oleh bidang kegiatan mereka (listrik dan kontrak untuk pasokannya), tetapi oleh resonansi karena kecurangan di dalamnya. Selama 15 tahun, pendapatan perusahaan telah berkembang pesat, dan pekerjaan di dalamnya menjanjikan gaji yang baik. Namun semuanya berakhir dengan cepat: pada periode 2000-2001. harga saham turun dari $ 90 / unit menjadi hampir nol karena penipuan yang diungkapkan dengan pendapatan yang diumumkan. Sejak itu, kata "Enron" telah menjadi kata rumah tangga dan bertindak sebagai label untuk perusahaan yang beroperasi dalam pola yang sama.
Selama persidangan, 18 orang (termasuk terdakwa terbesar dalam kasus ini: Andrew Fastov, Jeff Skilling dan Kenneth Lay) dihukum.
![image! [image] (http: // https: //habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)](https://habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)
Pada saat yang sama, arsip korespondensi elektronik antara karyawan perusahaan, yang lebih dikenal sebagai Enron Email Dataset, dan informasi orang dalam tentang pendapatan karyawan perusahaan ini dipublikasikan.
Artikel ini akan memeriksa sumber-sumber data ini dan membangun model yang didasarkan padanya untuk menentukan apakah seseorang dicurigai melakukan penipuan. Kedengarannya menarik? Lalu, selamat datang di habrakat.
Deskripsi dataset
Dataset Enron (dataset) adalah kumpulan gabungan dari data terbuka yang berisi catatan orang yang bekerja di perusahaan yang mudah diingat dengan nama yang sesuai.
Itu dapat membedakan 3 bagian:
- payment_features - grup yang mencirikan pergerakan keuangan;
- stock_features - grup yang mencerminkan tanda-tanda yang terkait dengan saham;
- email_features - grup yang mencerminkan informasi tentang email orang tertentu dalam bentuk agregat.
Tentu saja, ada juga variabel target yang menunjukkan apakah orang tersebut diduga melakukan penipuan (tanda 'poi' ).
Unduh data kami dan mulai bekerja dengannya:
import pickle with open("final_project/enron_dataset.pkl", "rb") as data_file: data_dict = pickle.load(data_file)
Setelah itu, kami mengubah data_dict yang diatur ke dalam kerangka data Pandas untuk pekerjaan yang lebih nyaman dengan data:
import pandas as pd import warnings warnings.filterwarnings('ignore') source_df = pd.DataFrame.from_dict(data_dict, orient = 'index') source_df.drop('TOTAL',inplace=True)
Kami mengelompokkan tanda-tanda sesuai dengan jenis yang ditunjukkan sebelumnya. Ini harus memfasilitasi pekerjaan dengan data sesudahnya:
payments_features = ['salary', 'bonus', 'long_term_incentive', 'deferred_income', 'deferral_payments', 'loan_advances', 'other', 'expenses', 'director_fees', 'total_payments'] stock_features = ['exercised_stock_options', 'restricted_stock', 'restricted_stock_deferred','total_stock_value'] email_features = ['to_messages', 'from_poi_to_this_person', 'from_messages', 'from_this_person_to_poi', 'shared_receipt_with_poi'] target_field = 'poi'
Data keuangan
Dalam dataset ini ada NaN yang dikenal banyak orang, dan itu mengungkapkan kesenjangan biasa dalam data. Dengan kata lain, pembuat dataset tidak dapat menemukan informasi tentang atribut tertentu yang terkait dengan garis tertentu dalam bingkai data. Akibatnya, kita dapat mengasumsikan bahwa NaN adalah 0, karena tidak ada informasi tentang sifat tertentu.
payments = source_df[payments_features] payments = payments.replace('NaN', 0)
Verifikasi data
Ketika membandingkan dengan PDF asli yang mendasari dataset, ternyata datanya sedikit terdistorsi, karena tidak untuk semua baris dalam kerangka data pembayaran , bidang total_payments adalah jumlah dari semua transaksi keuangan orang ini. Anda dapat memverifikasi ini sebagai berikut:
errors = payments[payments[payments_features[:-1]].sum(axis='columns') != payments['total_payments']] errors.head()

Kami melihat bahwa BELFER ROBERT dan BHATNAGAR SANJAY memiliki jumlah pembayaran yang salah.
Anda dapat memperbaiki kesalahan ini dengan memindahkan data di baris kesalahan ke kiri atau ke kanan dan menghitung jumlah semua pembayaran lagi:
import numpy as np shifted_values = payments.loc['BELFER ROBERT', payments_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) payments.loc['BELFER ROBERT', payments_features] = shifted_values shifted_values = payments.loc['BHATNAGAR SANJAY', payments_features[:-1]].values payments.loc['BHATNAGAR SANJAY', payments_features] = np.insert(shifted_values, 0, 0)
Stok Data
stocks = source_df[stock_features] stocks = stocks.replace('NaN', 0)
Lakukan pemeriksaan validasi dalam kasus ini juga:
errors = stocks[stocks[stock_features[:-1]].sum(axis='columns') != stocks['total_stock_value']] errors.head()

Kami juga akan memperbaiki kesalahan dalam persediaan:
shifted_values = stocks.loc['BELFER ROBERT', stock_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) stocks.loc['BELFER ROBERT', stock_features] = shifted_values shifted_values = stocks.loc['BHATNAGAR SANJAY', stock_features[:-1]].values stocks.loc['BHATNAGAR SANJAY', stock_features] = np.insert(shifted_values, 0, shifted_values[-1])
Korespondensi Email
Jika untuk keuangan atau saham ini NaN setara dengan 0, dan ini cocok dengan hasil akhir untuk masing-masing kelompok ini, dalam hal email, NaN lebih masuk akal untuk diganti dengan beberapa nilai default. Untuk melakukan ini, Anda dapat menggunakan Imputer:
from sklearn.impute import SimpleImputer imp = SimpleImputer()
Pada saat yang sama, kami akan mempertimbangkan nilai default untuk setiap kategori (apakah kami mencurigai seseorang melakukan penipuan) secara terpisah:
target = source_df[target_field] email_data = source_df[email_features] email_data = pd.concat([email_data, target], axis=1) email_data_poi = email_data[email_data[target_field]][email_features] email_data_nonpoi = email_data[email_data[target_field] == False][email_features] email_data_poi[email_features] = imp.fit_transform(email_data_poi) email_data_nonpoi[email_features] = imp.fit_transform(email_data_nonpoi) email_data = email_data_poi.append(email_data_nonpoi)
Dataset akhir setelah koreksi:
df = payments.join(stocks) df = df.join(email_data) df = df.astype(float)
Emisi
Pada langkah terakhir dari tahap ini, kami akan menghapus semua outlier, yang dapat mengubah pelatihan. Pada saat yang sama, pertanyaan selalu muncul: berapa banyak data yang dapat kita hapus dari sampel dan masih tidak hilang sebagai model yang terlatih? Saya mengikuti saran dari salah satu dosen di kursus ML (Machine Learning) tentang Udacity - "Hapus 10 dan periksa emisi lagi."
first_quartile = df.quantile(q=0.25) third_quartile = df.quantile(q=0.75) IQR = third_quartile - first_quartile outliers = df[(df > (third_quartile + 1.5 * IQR)) | (df < (first_quartile - 1.5 * IQR))].count(axis=1) outliers.sort_values(axis=0, ascending=False, inplace=True) outliers = outliers.head(10) outliers
Pada saat yang sama, kami tidak akan menghapus catatan yang outlier dan diduga penipuan. Alasannya adalah bahwa hanya ada 18 baris dengan data seperti itu, dan kami tidak dapat mengorbankannya, karena ini dapat menyebabkan kurangnya contoh pelatihan. Akibatnya, kami menghapus hanya orang-orang yang tidak dicurigai melakukan penipuan, tetapi pada saat yang sama memiliki sejumlah besar tanda-tanda dimana emisi diamati:
target_for_outliers = target.loc[outliers.index] outliers = pd.concat([outliers, target_for_outliers], axis=1) non_poi_outliers = outliers[np.logical_not(outliers.poi)] df.drop(non_poi_outliers.index, inplace=True)
Menyelesaikan
Kami menormalkan data kami:
from sklearn.preprocessing import scale df[df.columns] = scale(df)
Memungkinkan target variabel target ke tampilan yang kompatibel:
target.drop(non_poi_outliers.index, inplace=True) target = target.map({True: 1, False: 0}) target.value_counts()

Akibatnya, 18 tersangka dan 121 orang yang tidak dicurigai.
Pemilihan Fitur
Mungkin salah satu poin utama sebelum mempelajari model apa pun adalah pemilihan fitur yang paling penting.
Uji Multikolinearitas
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.set(style="whitegrid") corr = df.corr() * 100 # Select upper triangle of correlation matrix mask = np.zeros_like(corr, dtype=np.bool) mask[np.triu_indices_from(mask)] = True # Set up the matplotlib figure f, ax = plt.subplots(figsize=(15, 11)) # Generate a custom diverging colormap cmap = sns.diverging_palette(220, 10) # Draw the heatmap with the mask and correct aspect ratio sns.heatmap(corr, mask=mask, cmap=cmap, center=0, linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")
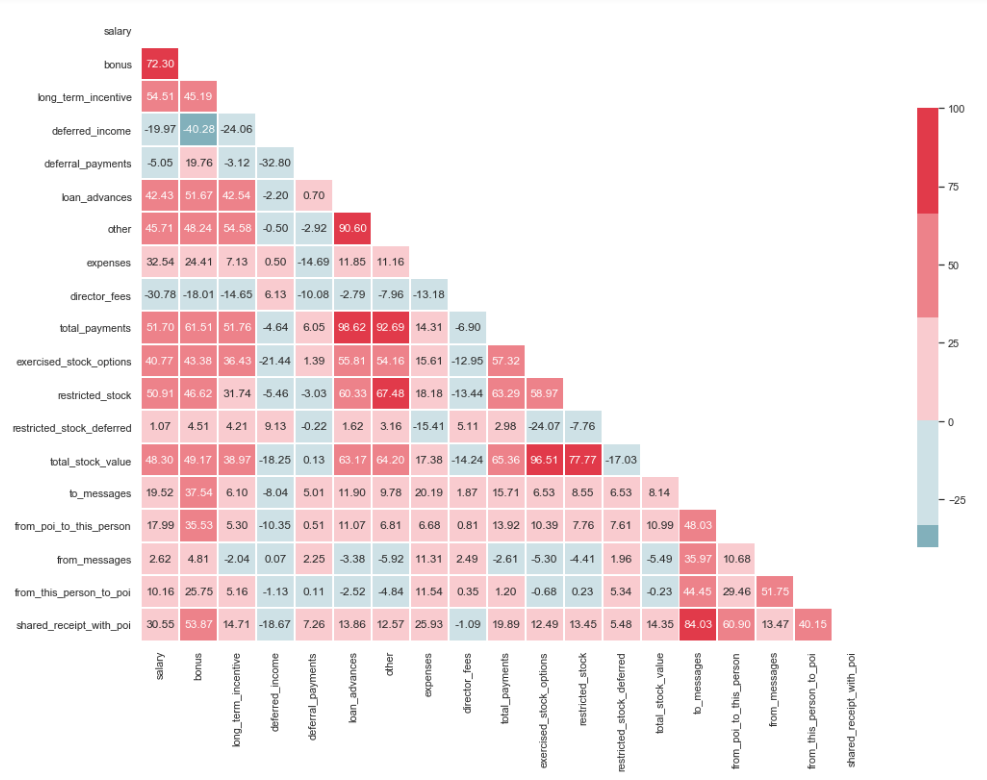
Seperti yang dapat Anda lihat dari gambar, kami memiliki hubungan yang jelas antara 'loan_advanced' dan 'total_payments', serta antara 'total_stock_value' dan 'dibatasi_stock'. Seperti yang disebutkan sebelumnya, 'total_payments' dan 'total_stock_value' hanyalah hasil dari menjumlahkan semua indikator dalam grup tertentu. Karena itu, mereka dapat dihapus:
df.drop(columns=['total_payments', 'total_stock_value'], inplace=True)
Menciptakan Karakteristik Baru
Ada juga asumsi bahwa tersangka menulis untuk menemani lebih sering daripada kepada karyawan yang tidak terlibat dalam hal ini. Dan sebagai hasilnya, proporsi pesan semacam itu harus lebih besar daripada proporsi pesan untuk karyawan biasa. Berdasarkan pernyataan ini, Anda dapat membuat tanda-tanda baru yang mencerminkan persentase masuk / keluar terkait dengan tersangka:
df['ratio_of_poi_mail'] = df['from_poi_to_this_person']/df['to_messages'] df['ratio_of_mail_to_poi'] = df['from_this_person_to_poi']/df['from_messages']
Menyaring tanda-tanda yang tidak perlu
Di toolkit orang yang terkait dengan ML, ada banyak alat yang sangat baik untuk memilih fitur yang paling signifikan (SelectKBest, SelectPercentile, VarianceThreshold, dll.). Dalam hal ini, RFECV akan digunakan, karena ini mencakup validasi silang, yang memungkinkan Anda untuk menghitung fitur yang paling penting dan memeriksanya di semua himpunan bagian sampel:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df, target, test_size=0.2, random_state=42)
from sklearn.feature_selection import RFECV from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(random_state=42) rfecv = RFECV(estimator=forest, cv=5, scoring='accuracy') rfecv = rfecv.fit(X_train, y_train) plt.figure() plt.xlabel("Number of features selected") plt.ylabel("Cross validation score of number of selected features") plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, '--o') indices = rfecv.get_support() columns = X_train.columns[indices] print('The most important columns are {}'.format(','.join(columns)))
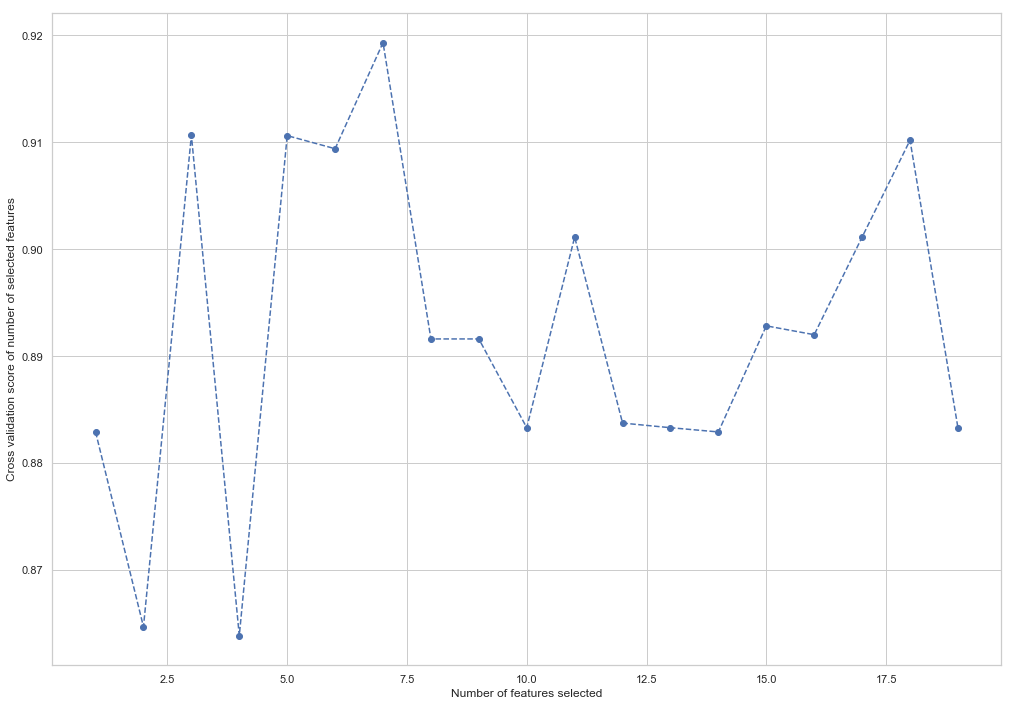
Seperti yang Anda lihat, RandomForestClassifier menghitung bahwa hanya 7 dari 18 atribut yang penting. Menggunakan sisanya menyebabkan penurunan akurasi model.
The most important columns are bonus, deferred_income, other, exercised_stock_options, shared_receipt_with_poi, ratio_of_poi_mail, ratio_of_mail_to_poi
7 fitur ini akan digunakan di masa depan untuk menyederhanakan model dan mengurangi risiko pelatihan ulang:
- bonus
- deferred_income
- lainnya
- exercise_stock_options
- shared_receipt_with_poi
- ratio_of_poi_mail
- ratio_of_mail_to_poi
Ubah struktur pelatihan dan sampel uji untuk pelatihan model mendatang:
X_train = X_train[columns] X_test = X_test[columns]
Ini adalah akhir dari bagian pertama yang menggambarkan penggunaan Enron Dataset sebagai contoh tugas klasifikasi dalam ML. Berdasarkan materi dari kursus Pengantar Pembelajaran Mesin di Udacity. Ada juga notebook python yang mencerminkan seluruh rangkaian tindakan.
Bagian kedua ada di sini