
Bayangkan di sebuah restoran Anda ditawari untuk mencoba saus baru untuk hidangan favorit Anda, mencatat bahwa cara ini menjadi dua kali lebih lezat. Dalam hal ini, Anda tidak punya pilihan selain melakukan ini. Lagi pula, tidak mungkin untuk menentukan sebaliknya, mengapa pelayan menilai perasaan subyektifinya sebagai "dua kali lebih enak" dan tidak, misalnya, tiga. Dalam hal pengeluaran untuk infrastruktur TI, hanya sedikit yang mau mengandalkan perasaan atau intuisi orang lain dalam masalah ini. Untuk memilih "opsi dua kali lebih enak" Anda perlu menemukan metode yang andal dan andal untuk menilai efisiensi ekonomi.
Perhitungan ini sangat penting jika Anda perlu meyakinkan manajemen, termasuk direktur keuangan, tentang kebenaran keputusan Anda.
Tujuan artikel ini adalah untuk memahami metodologi TCO untuk berbagai opsi untuk mendapatkan hak untuk menggunakan infrastruktur TI dan melakukan perhitungan yang sesuai untuk mengidentifikasi alternatif yang paling hemat biaya.
HASIL PENELITIAN ADALAH (UPD)
- memahami kebutuhan untuk mempertimbangkan tingkat ketahanan sistem TI sebagai karakteristik utama "membandingkan apel dengan apel";
- perhitungan total biaya kepemilikan infrastruktur TI untuk dua pola penggunaan: sistem ERP dan sumber daya web portal olahraga;
- analisis komparatif dari total biaya kepemilikan infrastruktur TI Anda sendiri dan penyewaan cloud;
- analisis faktor penghematan pada manfaat teknologi cloud dan mengidentifikasi pola yang paling menguntungkan untuk menggunakan cloud.
Apa itu TCO?
Total biaya kepemilikan atau biaya siklus hidup (
eng.Total Biaya Kepemilikan, TCO, ) adalah jumlah total biaya target yang harus ditanggung oleh pemilik sejak saat penerapan entri ke dalam status kepemilikan hingga pemilik meninggalkan status kepemilikan dan memenuhi seluruh kewajiban, terkait dengan kepemilikan.
Teknik TCO dikembangkan pada akhir 80-an abad XX oleh perusahaan Gartner Group untuk menghitung biaya finansial dari memiliki komputer pada platform Wintel (MS Windows + Intel). Itu ditingkatkan pada tahun 1994 oleh Interpose dan dirancang ulang menjadi model lengkap untuk menganalisis sisi keuangan dari penggunaan teknologi informasi. Dengan perhitungan TCO ini, biaya pembuatan platform perangkat keras, pembelian lisensi perangkat lunak, biaya tenaga kerja untuk spesialis TI, dll. Adalah apa yang disebut sebagai pengeluaran "langsung" atau "anggaran". Tetapi masih ada suntikan keuangan implisit ke dalam isi infrastruktur IT-nya, biaya dan kerugian yang terkait dengan fungsinya, dan sebagainya. Selain itu, penulis metodologi TCO berpendapat bahwa biaya tersebut merupakan bagian terbesar dari total biaya kepemilikan infrastruktur TI. Biaya ini disebut "biaya tidak langsung", dan menurut praktik perhitungan TCO selama bertahun-tahun, biaya tersebut melebihi "biaya langsung" yang disebutkan di atas sebanyak 3-5 kali.
Faktanya, perusahaan menghabiskan lebih banyak uang daripada yang mereka perkirakan untuk pemeliharaan perangkat keras mereka . Mengapa ini terjadi dan apakah mungkin untuk mengoptimalkan biaya infrastruktur TI kita sendiri?
Tujuan inilah yang dikejar metodologi TCO. Tetapi untuk memahami bagaimana Anda dapat mengelola biaya perawatan, Anda harus terlebih dahulu menjelaskan bagaimana mereka dihitung [
1 ].
Sampai saat ini, metodologi universal untuk menentukan (menghitung) total biaya kepemilikan tidak ada, karena, tergantung pada objek kepemilikan, karakteristik kepemilikan, struktur biaya dan prinsip-prinsip untuk penentuannya dapat bervariasi sebagian besar. Namun, ada pendekatan umum untuk menentukan nilai pada semua tahap siklus hidup.
Prinsip utama yang diterapkan dalam pengembangan metode untuk menentukan total biaya kepemilikan adalah pendekatan sistematis .
Untuk penilaian terintegrasi dari biaya kepemilikan, metode penyederhanaan perhitungan TCO dapat diterapkan, mengungkapkan, pertama-tama, struktur biaya, dan memberikan gagasan tentang kemungkinan kerugian dalam proses kepemilikan.
Dengan demikian, perlu untuk membuat perhitungan TCO individu untuk setiap kasus dan, terlepas dari kenyataan bahwa sebagian besar biaya dapat ditentukan sebelumnya atau diprediksi dengan akurasi tinggi, beberapa biaya adalah probabilistik, yang melibatkan risiko penyimpangan yang signifikan dari biaya aktual dari perkiraan (diperkirakan )
Bagaimana kami menyarankan untuk menghitung total biaya kepemilikan infrastruktur TI dan mengapa
TCO atau penilaian total biaya kepemilikan karena sifatnya yang probabilistik agak penting bukan dalam dirinya sendiri, melainkan berlaku untuk membandingkan biaya metode alternatif untuk memperoleh sumber daya komputasi yang diperlukan.
Alternatif paling populer untuk membeli perangkat keras dan perangkat lunak virtualisasi Anda sendiri adalah menyewa infrastruktur TI yang sudah jadi di cloud menggunakan model IaaS (
Infrastructure as a Service ).
Tidak ada yang rumit dalam menghitung TCO cloud: kami mengambil dan menambahkan semua pembayaran ke penyedia untuk periode tersebut. Menghitung total biaya infrastruktur Anda sendiri jauh lebih sulit, dan kami akan membicarakannya secara rinci nanti.
Apakah Anda sudah berhasil membuat perhitungan yang diperlukan? Sekarang Anda bisa membandingkan? Ya, jika Anda melakukannya dengan benar.
Jangan lupa tentang karakteristik penting dari infrastruktur TI yang dibuat sebagai sistem - tingkat toleransi kesalahan atau operasi yang tidak terputus dari pekerjaannya. Jelas bahwa semakin tinggi tingkat aksesibilitas layanan, semakin baik: pekerjaan karyawan kantor tidak diam karena kegagalan pada server sistem otomasi akuntansi, dan pelanggan tidak meninggalkan toko online karena "kesalahan 503".
Secara umum, bisnis ingin mendapatkan ketersediaan 99,99%. Namun, menciptakan solusi tingkat ini akan membutuhkan investasi yang signifikan. Tingkat toleransi kesalahan ini, misalnya, solusi berdasarkan pada dua sistem penyimpanan data dengan mirroring sinkron yang terletak di sepasang pusat pemrosesan data yang secara geografis terpisah satu sama lain. Tidak mengherankan, biaya layanan seperti itu akan 2 kali lebih tinggi.
Apakah semua orang membutuhkan solusi seperti itu? Tentu saja tidak. Jika kita berbicara tentang tingkat ketersediaan yang diharapkan dari 99,95% atau 4 jam 23 menit waktu henti per tahun, kita diharapkan hanya kehilangan 0,04% dari waktu kerja ke solusi, yang 2 kali lebih mahal. Dalam tahun non-kabisat, 8760 jam, yang berarti jika tidak ada bencana alam yang hanya menyelamatkan kita dari solusi bencana, kami hanya menambah 3,5 jam setahun ke waktu uptime infrastruktur TI per tahun, menginvestasikan dana yang signifikan.
Jadi, kami sampai pada pertanyaan tentang berapa menit waktu henti untuk bisnis Anda dan tingkat toleransi kesalahan yang Anda butuhkan. Apakah Anda terbiasa dengan frasa menakutkan "biaya waktu henti"?
Menurut survei Ponemon Institute 2014, biaya rata-rata downtime adalah $ 7.900, dibandingkan dengan $ 5.600 per menit empat tahun sebelumnya. Meskipun angka-angka ini mungkin terlihat bencana, mereka dapat dengan mudah dibuang sebagai relevan hanya untuk beberapa perusahaan terbesar di Amerika Serikat.
Untuk raksasa e-commerce seperti Amazon, angkanya bahkan lebih tinggi. Kerugian hingga $ 66.240 dilaporkan untuk setiap menit downtime layanan. Pada saat ini, satu menit downtime untuk usaha kecil jauh lebih murah, biaya relatif masih signifikan. Anehnya, upaya untuk mengukur dan mengelola risiko-risiko ini baru saja menjadi prioritas bisnis. Akibatnya, mudah untuk membuat kesalahan dengan mengabaikan bahaya downtime infrastruktur TI, dan tidak mencoba menilai dampaknya terhadap kinerja.
Bagaimana Anda bisa memperkirakan kerugian downtime jika Anda adalah bisnis kecil atau menengah? Tidak mengherankan, matematika kerugian yang sesuai kurang mengesankan. Tapi jangan biarkan angka menipu Anda. Bahkan toko eceran yang ceruk dengan penghasilan yang relatif sederhana akan merasakan “sakitnya” waktu henti. Mari kita lihat daftar faktor-faktor yang bersama-sama membentuk total biaya kerugian:
Kerugian pendapatan penjualan langsung

Ini mungkin tampak sepele, tetapi dengan asumsi bahwa pendapatan dihasilkan secara online atau sangat tergantung pada IT, Anda hanya perlu membagi jumlah penjualan tahunan sebesar 525.600 (60 mnt. 24 jam x 365 hari) untuk menentukan biaya rata-rata waktu henti per menit. Dengan demikian, rumus kerugian dapat terlihat seperti ini:

Di mana t menunjukkan jumlah menit downtime infrastruktur TI Anda.
Kerugian dari produktivitas karyawan
Perkiraan biaya waktu untuk pekerja yang terkena downtime dan yang tidak bisa bekerja seperti biasa.
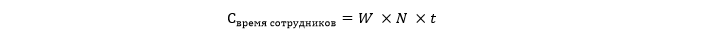
Di mana W adalah upah rata-rata per jam per karyawan, dan N adalah jumlah karyawan yang terpengaruh oleh downtime. t dalam hal ini dinyatakan dalam jam.
Biaya memulihkan infrastruktur TI
Biaya waktu untuk staf TI yang sibuk memulihkan sistem Anda dari cadangan atau mengganti peralatan yang gagal.

Di mana N_IT menunjukkan jumlah karyawan yang terlibat dalam operasi pemulihan TI alih-alih kegiatan ramah bisnis lainnya, dan ini menunjukkan waktu yang diperlukan untuk memperbaiki masalah semua sistem yang terpengaruh dan kembali normal.
Kehilangan pendapatan yang diprediksi karena berkurangnya loyalitas pelanggan
Untuk kesederhanaan, mari kita asumsikan bahwa bisnis yang dimaksud tidak banyak dicakup oleh media, oleh karena itu, pendapatan yang diproyeksikan akan dihitung berdasarkan pada hilangnya kemungkinan penjualan kembali.

Dimana r menunjukkan tingkat rata-rata (persentase) dari penurunan penjualan berulang, dan D adalah pendapatan dari penjualan berulang untuk tahun tersebut.
Proyeksi kehilangan reputasi karena rusaknya reputasi
Kehilangan penjualan ke pelanggan yang menjelajahi pasar untuk mendapatkan kesepakatan terbaik atau mengumpulkan rekomendasi.
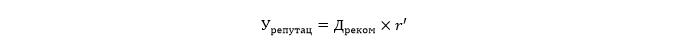
Di mana r 'menunjukkan persentase penurunan penjualan yang terkait dengan pelanggan yang datang dari situs dengan ulasan untuk membandingkan produk / layanan dan dari jejaring sosial.
Dengan demikian, rumus total biaya waktu henti (TCoDT) mungkin terlihat seperti ini:
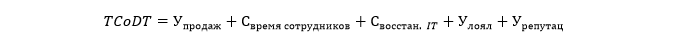
Di mana U_sales, S_time karyawan, S_vosstan. IT, U_loyal, U_reputats masing-masing berarti kehilangan pendapatan, biaya kerugian karena berkurangnya produktivitas karyawan, biaya pemulihan infrastruktur TI, prediksi hilangnya penjualan berulang dan prediksi kerugian karena rusaknya reputasi.
Sebagai contoh, perhatikan toko online dengan 50 juta rubel dalam penjualan dan 15 karyawan di negara bagian. Setiap jam 5708 rubel atau sedikit lebih dari 95 rubel per menit adalah hilangnya pendapatan langsung.Berapa lama waktu henti yang diharapkan selama tahun ini bagi perusahaan?
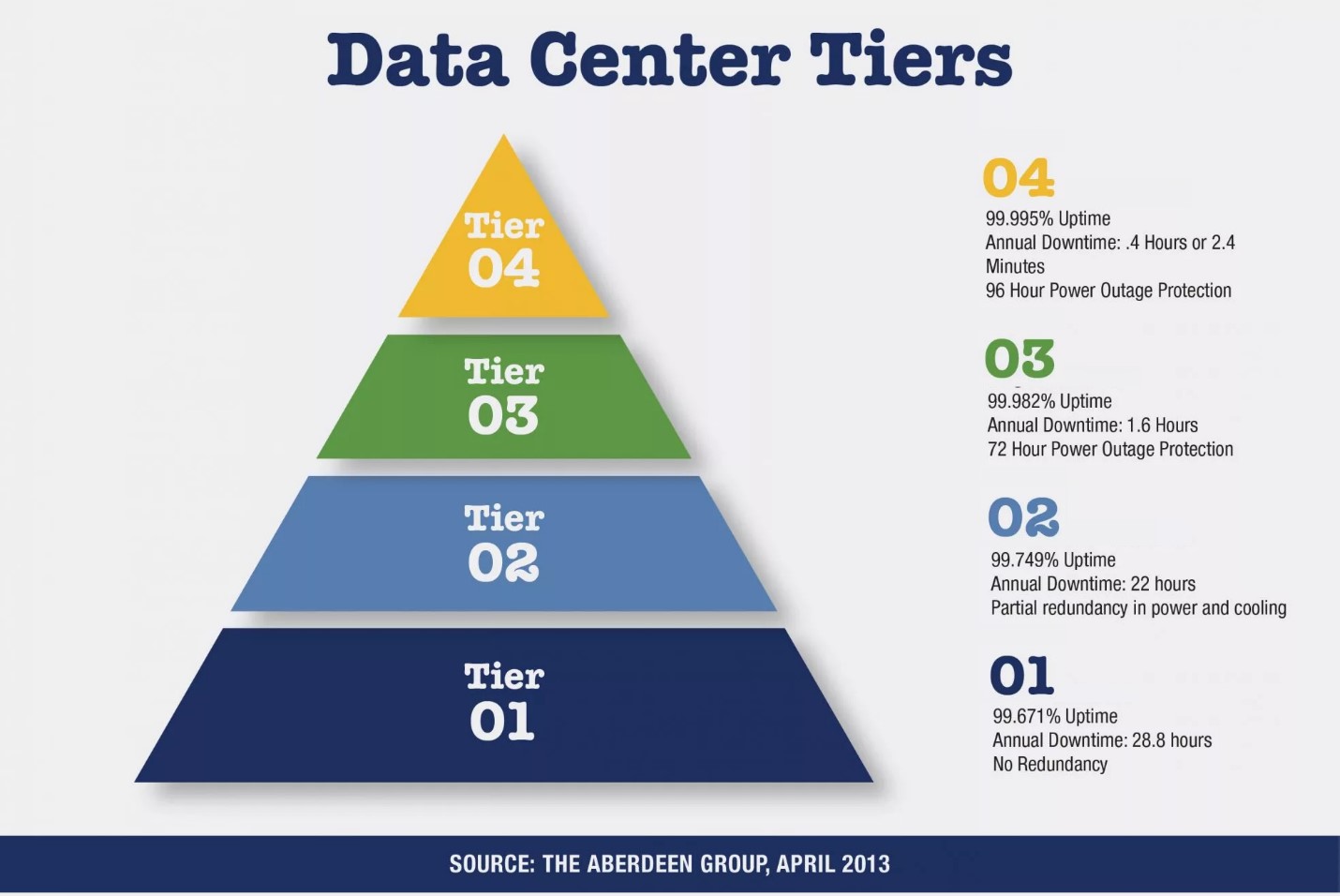
Banyak tergantung pada bagaimana sistem TI bisnis ini diatur. Objek yang dipelajari dan tipikal adalah pusat data publik. Uptime Institute telah menciptakan sistem klasifikasi berjenjang untuk secara sistematis mengevaluasi berbagai fasilitas dan peralatan pusat data dalam hal kinerja infrastruktur potensial atau waktu aktif. Sistem ini terdiri dari empat level, setiap level mencakup persyaratan level yang lebih rendah (Tier):
- Tingkat I: Kapasitas Dasar - kapasitas dasar, infrastruktur tanpa redundansi;
- Tingkat II: Komponen Kapasitas Redundan - duplikasi komponen penting, infrastruktur berlebihan;
- Tingkat III: Dapat dipertahankan secara bersamaan - infrastruktur dengan kemungkinan perbaikan / pemeliharaan paralel tanpa gangguan pekerjaan;
- Tingkat IV: Toleran Kesalahan - Infrastruktur Failover.
Meskipun Uptime Institute menghapus informasi tentang "waktu henti yang diharapkan satu tahun" dari Tier Standard pada 2009 [
2 ,
3 ], kita dapat menyimpulkan bahwa sebelumnya, dengan menerbitkan data ini, para ahli operasi pusat data merangkum informasi tentang kegagalan dan datang untuk kesimpulan bahwa infrastruktur dasar tanpa redundansi diharapkan bekerja 99,671% per tahun tanpa kegagalan atau menganggur karena kecelakaan selama 28,8 jam.
Seringkali di perusahaan atau cabang terpencil mereka, server di mana berada secara lokal, tidak ada ruang khusus untuk server dan switching node, rak tidak terlindungi, tidak ada kontrol akses, tidak ada redundansi, manajemen kabel berada pada level rendah, dan tidak ada diskusi tentang sistem pendingin khusus dan sistem pemadam kebakaran sedang berpikir. Dan ini bahkan bukan Tier 1 dengan downtime yang diharapkan lebih dari satu hari. Kebakaran di tempat seperti itu lebih mungkin terjadi, dan waktu henti terakhir bisa berlangsung sebulan dan menyebabkan kebangkrutan.
 Keadaan "menyedihkan" dari server dapat menyebabkan kecelakaan besar
Keadaan "menyedihkan" dari server dapat menyebabkan kecelakaan besarPerlu dicatat bahwa seluruh sistem TI organisasi adalah sekelompok sistem pendukung (listrik, pendingin, keamanan, dll.), Saluran komunikasi, server, peralatan jaringan dan sistem penyimpanan data, sistem-lebar dan perangkat lunak aplikasi. Dalam sistem berjenjang seperti itu, waktu aktif yang diharapkan secara keseluruhan adalah produk dari tingkat toleransi kesalahan masing-masing komponen atau
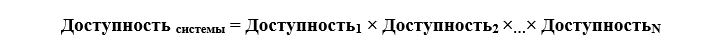 Sebagai contoh, Ketersediaan = 99.671% (pusat data lokal tanpa redundansi) × 99.671% (peralatan TI tanpa redundansi) = 99.343% atau sekitar 2,5 hari downtime yang diharapkan jika kegagalan disebabkan oleh alasan yang berbeda dan pada waktu yang berbeda.
Sebagai contoh, Ketersediaan = 99.671% (pusat data lokal tanpa redundansi) × 99.671% (peralatan TI tanpa redundansi) = 99.343% atau sekitar 2,5 hari downtime yang diharapkan jika kegagalan disebabkan oleh alasan yang berbeda dan pada waktu yang berbeda.Misalkan Anda memiliki kegiatan yang cukup terorganisir, dan infrastruktur TI sederhana berlangsung tidak lebih dari sembilan jam setahun, sedikit tidak mencapai tiga kali sembilan (99,9%). Ini berarti bahwa semua pekerja yang terpengaruh oleh kerusakan (mungkin 2/3) tidak dapat bekerja secara normal, setidaknya untuk periode waktu ini. Jika kita mengambil upah rata-rata per jam dengan pajak dan biaya 500 rubel, ini akan membebani perusahaan 45.000 rubel karena hilangnya produktivitas.
Adalah logis bahwa tim TI akan menghabiskan lebih banyak waktu untuk mencari tahu apa yang salah, kemudian untuk mencegah kegagalan berulang. Bayangkan bahwa kejeniusan IT Anda akan membutuhkan 50 jam (800 rubel / jam) untuk memperbaikinya. Kali ini, karyawan dapat menghabiskan untuk memecahkan masalah pengembangan bisnis Anda. Bahkan jika Anda mengalokasikan hanya satu karyawan untuk masalah ini, ini adalah tambahan 40.000 rubel, yang harus dimasukkan dalam biaya pemulihan TI.
Akhirnya, tidak hanya pelanggan yang Anda hilangkan dengan "mengirim" ke salah satu pesaing Anda tidak akan pernah kembali, pelanggan baru cenderung melakukan pembelian Anda atas saran dari mitra atau pada rekomendasi dan ulasan di situs web untuk membandingkan produk dan layanan.
Jadi, kami menambahkan perkiraan kehilangan 50.000 rubel untuk memperhitungkan tambahan 1% dari perkiraan kerugian pada penjualan berulang tahun ini dan 35.000 rubel untuk kehilangan penjualan 2% menurut ulasan dan rekomendasi yang disebabkan oleh downtime. Sebuah gambar yang tidak menyenangkan muncul, tetapi mari kita tambahkan semuanya:
Kehilangan penjualan
| 51 372
|
Kehilangan kinerja
| 45.000
|
Biaya pemulihan TI
| 40.000
|
Ulangi Kerugian
| 50.000
|
Kerugian penjualan berdasarkan ulasan
| 35.000
|
Total biaya downtime infrastruktur TI
| 221 372 gosok.
|
Dengan cepat menjadi jelas mengapa ada kesenjangan yang signifikan dalam cara perusahaan kecil dan perusahaan mendekati penilaian kerugian downtime, dari mengukur konsekuensi hingga kebutuhan jangka panjang yang jelas untuk membangun respons dan prosedur pemulihan.
Menurut survei terhadap perwakilan bisnis besar di AS, 37% organisasi memperkirakan waktu henti sebagai kerugian lebih dari $ 10.000, yang menggemakan 38% responden yang melaporkan pendapatan tahunan lebih dari $ 10 juta. Dengan demikian, sementara angka untuk usaha kecil dan menengah secara signifikan lebih rendah daripada kerugian aktual selama downtime untuk perusahaan, juga jelas bahwa bahkan usaha kecil yang mengandalkan teknologi modern harus mengambil masalah uptime dengan serius mengingat skala mereka.
Dengan waktu henti yang lebih lama yang harus dialami pelanggan Anda, dengan setiap jam tambahan, kemungkinan kerugian dari penjualan berulang dan karena ulasan negatif tumbuh lebih cepat. Dengan demikian, kecelakaan dalam infrastruktur TI tidak hanya dapat menyebabkan kerugian, tetapi juga menghilangkan stabilitas keuangan perusahaan.
Pasal 4 Undang-Undang 24 Juli 2007 No. 209-FZ dan Keputusan Pemerintah Federasi Rusia 4 April 2016 No. 265 memberi tahu kami tentang pendapatan dan jumlah karyawan, yang merupakan kriteria bagi suatu bisnis untuk memperoleh status hukum tertentu.
Nilai batas jumlah rata-rata karyawan untuk tahun kalender sebelumnya
| Penghasilan tahun berjalan menurut aturan akuntansi pajak tidak akan melebihi:
|
15 orang - untuk usaha mikro;
16–100 orang - untuk usaha kecil;
101–250 orang - untuk perusahaan menengah
| 120 juta rubel. - untuk usaha mikro;
800 juta rubel. - untuk usaha kecil;
2000 juta rubel. - untuk perusahaan menengah
|
Jadi, bahkan contoh perusahaan mikro dengan 15 karyawan dan 50 juta rubel pendapatan tahunan yang telah kami periksa menunjukkan bahwa 0,1% sederhana yang tidak signifikan per tahun membawa kerugian serius bagi bisnis, yang dapat membentuk persentase signifikan dari laba tahunan. Itu sebabnya perusahaan kecil dan menengah perlu menerapkan sistem TI dengan tingkat keandalan mendekati 99,95%. Pilihan semacam itu adalah "rerata emas" antara biaya tambahan solusi tahan bencana dan meminimalkan downtime dari sistem yang kurang andal.
Perhitungan di atas menggambarkan pekerjaan yang harus dilakukan CIO sebagai titik awal untuk memilih alternatif. Setelah menentukan selera risiko Anda dan kerugian yang diijinkan dari downtime sistem TI, perlu untuk merancang semua elemen sistem berdasarkan tingkat kesinambungan proses yang direncanakan secara keseluruhan. Hasilnya harus konsisten dengan tujuan bisnis taktis dan strategis, dan tidak membatasi atau menjadi penghalang bagi pencapaian mereka.
Sebagai bagian dari pekerjaan ini, kami akan menetapkan tingkat target kesinambungan pekerjaan TI pada tingkat 99,95% per tahun. Selanjutnya, kami melanjutkan ke perhitungan total biaya kepemilikan untuk berbagai model penggunaan infrastruktur TI dengan hanya tingkat toleransi kesalahan yang diharapkan.Solusi on-premise TCO
Untuk menambahkan sedikit fleksibilitas pada contoh kita, kita akan berbicara tentang satu konfigurasi peralatan, tetapi untuk dua pola penggunaannya. Contoh kita akan menjadi
- 350 pengguna ERP
- Situs web portal olahraga populer
Kami akan menghitung TCO untuk periode 3 dan 5 tahun.
Akuisisi peralatan sendiri
Untuk melakukan perhitungan untuk tugas-tugas ini, konfigurasi peralatan berikut akan digunakan. Berfokus pada harga pasar rata-rata untuk peralatan server kelas atas dan penyimpanan kelas menengah, kami mendapatkan biaya yang diharapkan:
Peralatan
| Harga
|
3+1 : CPU Xeon® E5 4 core 2,6GHz, RAM 64 Gb, 210Gb
| 1 500 000
|
SAS 11 ( 1 RAID1, RAID6)
| 2 300 000
|
1+1
| 200 000
|
Mengapa penyimpanan kelas menengah? Tingkat rata-rata sudah merupakan sistem yang serius di mana perlindungan terhadap sebagian besar skenario kegagalan dipikirkan, tingkat pemeliharaannya lebih tinggi (termasuk kemampuan untuk memantau pusat layanan dari jarak jauh dan mengganti disk di tempat dalam garansi).Keandalan sistem tersebut dihitung dengan jumlah "sembilan", dari urutan, misalnya, 99,999% dari waktu aktif yang dinyatakan selama setahun. Sebagian besar operasi perbaikan dan banyak operasi peningkatan besi dan perangkat lunak (sayangnya, tidak semua) dapat dilakukan tanpa gangguan. Dan kita ingat bahwa kita sedang membangun sebuah sistem dengan toleransi kesalahan total minimal 99,95%. Dengan demikian, kami menghemat uang dengan tidak membeli sistem penyimpanan kelas atas, yang biayanya beberapa kali lebih banyak, tetapi kami juga tidak kehilangan operasi tanpa gangguan.Peralatan server dipilih kelas atas, karena justru untuk server tingkat perusahaanlah berbagai fungsi pemantauan dan kontrol diterapkan, toleransi kesalahan dan skalabilitas yang baik disediakan.Jadi, kami mendapat biaya modal pertama untuk pembelian peralatan. Mereka berjumlah 3.000.000 rubel.Ini bisa berakhir dengan biaya peralatan, tetapi karena kami memperkirakan TCO selama 5 tahun, dan garansi standar sering berakhir setelah 3 tahun, kami menambahkan biaya untuk memperluas layanan garansi selama 2 tahun. Karena biaya perpanjangan jaminan berbeda untuk setiap vendor, kami menilai biaya ini sebagai 20% dari biaya peralatan selama 2 tahun atau 600.000 rubel dalam kasus kami. Kami menghitung persentase biaya layanan purna jual menggunakan teknologi HPE sebagai contoh [ 4 ].Penempatan untuk penempatan: pusat data atau di tempat
Selanjutnya, kita perlu memutuskan di mana kita akan menempatkan peralatan kita. Nah, jika Anda memiliki ruang server yang bagus yang penuh dengan sistem modern, tetapi bagaimana jika Anda membangunnya dari awal? Berapa biaya proyek semacam itu?Untuk mengevaluasi biaya, kami beralih ke studi “Memperkirakan total biaya kepemilikan pusat data” L.A. Pirogova, V.I. Grekul dan B.E. Poklonova [ 5] Berdasarkan analisis pasar konstruksi pusat data komersial, menurut hasil pemodelan regresi biaya modal untuk pembangunan 1 rak di pusat data di Moskow, penulis sampai pada interval kepercayaan 59 hingga 88 ribu dolar AS. Dengan demikian, bahkan pada skala ekonomis, untuk mendapatkan platform yang andal untuk peralatan, yang dapat memenuhi waktu henti peralatan yang diharapkan minimal 99,95%, perlu untuk menghabiskan sekitar 4,5 juta rubel hanya untuk konstruksi dan peralatan, tidak termasuk biaya operasi. Tentu saja, opsi biaya non-inti semacam itu menghilang untuk hampir semua organisasi.Pilihan logis adalah menempatkan server atau menyewa rak di pusat data komersial, yang disebut Colocation. Pasar untuk layanan pusat data komersial dikembangkan dengan baik, pendekatan penempatan peralatan ini telah diterima secara umum karena alasan ekonomi yang jelas.Penempatan 6 unit di pusat data Tier III (redundansi catu daya, pendingin, infrastruktur telekomunikasi, dan sistem pemadam kebakaran, kemungkinan untuk memperbaiki sistem tanpa menghentikan ruang server) di Moskow dengan harga pasar rata-rata, dengan memperhitungkan tambahan pada tarif dasar untuk konsumsi listrik dan saluran yang dijamin, akan menjadi sekitar 40.000 rubel per bulan.Jika Anda masih memutuskan untuk menempatkan peralatan di ruang server Anda sendiri, maka Anda harus mempertimbangkan konsumsi daya penuh dari pusat data Anda (server) - ini adalah konsumsi energi dari peralatan TI ditambah konsumsi segala sesuatu yang mendukung pekerjaannya, yaitu:- sistem catu daya, termasuk UPS, switchgears, generator, baterai; ini juga termasuk kerugian dalam distribusi daya eksternal ke peralatan TI;
- komponen sistem pendingin: pendingin, menara pendingin, pompa, unit ventilasi dan pendingin udara di ruang mesin, pelembab udara, dll.;
- beban lainnya, misalnya, pencahayaan pusat data.
Biasanya digunakan indikator PUE untuk menentukan efisiensi energi di industri. Parameter PUE (Power Usage Effectiveness) didefinisikan sebagai rasio kebutuhan energi infrastruktur TI terhadap semua energi yang dipasok ke pusat data. Nilai PUE yang ideal sama dengan satu, dalam hal ini semua energi yang digunakan oleh platform digunakan untuk mendukung operasi server. Dalam praktiknya, situasi ini tidak mungkin, nilai PUE minimum mencapai sekitar 1.1-1.15, organisasi kerja menggunakan "metode terbaik" memberikan rata-rata 1,6, dan di seluruh dunia rata-rata PUE untuk pusat data TIER III adalah 1 , 98.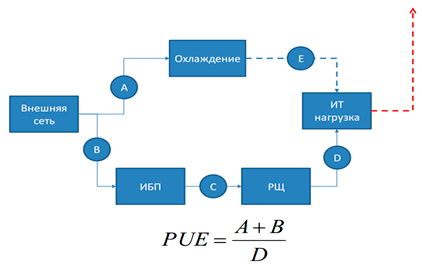 Sumber: APC oleh Schneider Electric, 2010Jadi, jika daya pengenal peralatan TI Anda adalah 4 kW, maka dengan PUE 2, Anda akan membutuhkan 8 kW * h. Jika ruang server bekerja sepanjang waktu, sekitar 5800 kW akan keluar per bulan, yang pada tingkat 5 rubel per kW akan memberikan biaya 29.000 rubel. Dari sini menjadi jelas bahwa dalam harga akomodasi di pusat data komersial, sebagian besar biaya ditanggung oleh listrik, dan biaya lainnya dialokasikan kepada banyak penyewa yang membayar lebih sedikit daripada jika mereka akan menerapkan kondisi seperti itu secara lokal di perusahaan.Kami menetapkan biaya 40.000 rubel per bulan untuk penempatan peralatan di pusat data komersial sebagai pilihan yang optimal secara ekonomi dan di masa mendatang kami hanya akan menggunakan opsi ini untuk perhitungan.
Sumber: APC oleh Schneider Electric, 2010Jadi, jika daya pengenal peralatan TI Anda adalah 4 kW, maka dengan PUE 2, Anda akan membutuhkan 8 kW * h. Jika ruang server bekerja sepanjang waktu, sekitar 5800 kW akan keluar per bulan, yang pada tingkat 5 rubel per kW akan memberikan biaya 29.000 rubel. Dari sini menjadi jelas bahwa dalam harga akomodasi di pusat data komersial, sebagian besar biaya ditanggung oleh listrik, dan biaya lainnya dialokasikan kepada banyak penyewa yang membayar lebih sedikit daripada jika mereka akan menerapkan kondisi seperti itu secara lokal di perusahaan.Kami menetapkan biaya 40.000 rubel per bulan untuk penempatan peralatan di pusat data komersial sebagai pilihan yang optimal secara ekonomi dan di masa mendatang kami hanya akan menggunakan opsi ini untuk perhitungan.Biaya perangkat lunak
Mengapa kita mempertimbangkan contoh menggunakan virtualisasi? Virtualisasi dapat meningkatkan kemampuan beradaptasi, fleksibilitas dan skalabilitas lingkungan TI dan secara signifikan mengurangi biaya. Virtualisasi mempercepat penyebaran beban kerja, meningkatkan produktivitas dan ketersediaannya, dan juga memungkinkan untuk mengotomatisasi proses, sebagai akibatnya infrastruktur TI perusahaan menjadi lebih mudah dikelola dan ekonomis. Manfaat tambahan termasuk yang berikut:- pengurangan modal dan biaya operasi;
- meminimalkan atau menghilangkan downtime;
- meningkatkan kecepatan respons, kemampuan beradaptasi, dan kinerja keseluruhan staf TI;
- Mempercepat inisialisasi aplikasi dan sumber daya
- kelangsungan bisnis dan pemulihan bencana;
- penyederhanaan manajemen pusat data;
- Pembuatan pusat data perangkat lunak lengkap.
Departemen TI dihadapkan pada keterbatasan server x86 modern, yang dirancang untuk menjalankan hanya satu sistem operasi dan satu aplikasi pada satu waktu. Akibatnya, bahkan di pusat data kecil, Anda harus menggunakan sejumlah besar server, yang masing-masingnya hanya 5-15%. Itu tidak efektif dari sudut pandang manapun [ 6 ].Dalam virtualisasi, perangkat lunak digunakan untuk mensimulasikan ketersediaan peralatan dan membuat sistem komputer virtual. Berkat ini, unit bisnis dapat menjalankan beberapa sistem virtual, serta beberapa sistem operasi dan aplikasi pada satu server. Pendekatan ini memberikan skala ekonomi dan peningkatan efisiensi.Bisakah saya menggunakan platform virtualisasi gratis?Jika Anda TIDAK membutuhkan penyebaran server virtual besar-besaran di suatu organisasi, pemantauan konstan kinerja server fisik di bawah beban yang berubah dan ketersediaannya yang tinggi, Anda dapat menggunakan mesin virtual berdasarkan platform gratis untuk mendukung server organisasi internal [ 7 ]. Dengan peningkatan jumlah server virtual dan tingkat konsolidasi yang tinggi pada platform fisik, penggunaan alat manajemen dan pemeliharaan yang kuat untuk infrastruktur virtual diperlukan.Bergantung pada apakah Anda perlu menggunakan berbagai sistem dan jaringan penyimpanan, misalnya, Storage Area Network (SAN), alat pencadangan dan pemulihan setelah kegagalan, dan migrasi langsung dari menjalankan mesin virtual ke peralatan lain, Anda mungkin tidak memiliki cukup fitur gratis platform virtualisasi, bagaimanapun, harus dicatat bahwa platform gratis terus diperbarui dan memperoleh fitur baru, yang memperluas ruang lingkup penggunaannya.Poin penting lainnya adalah dukungan teknis. Platform virtualisasi gratis ada baik dalam kerangka komunitas Open Source, di mana banyak penggemar terlibat dalam menyelesaikan produk dan dukungannya, atau didukung oleh vendor platform. Opsi pertama melibatkan partisipasi aktif pengguna dalam pengembangan produk, persiapan laporan kesalahan oleh mereka dan tidak menjamin solusi untuk masalah Anda saat menggunakan platform, dalam kasus kedua, paling sering, dukungan teknis tidak disediakan sama sekali. Oleh karena itu, kualifikasi personel yang menggunakan platform gratis harus pada level tinggi.Jadi, kita sampai pada kesimpulan bahwa untuk kasus penggunaan perusahaan, misalnya, sistem ERP, kita perlu perangkat lunak virtualisasi berbayar dengan fungsionalitas canggih. Pemimpin pasar adalah VMware. Semua perusahaan Fortune 500 memilih Platform Infrastruktur VMware, yang telah membantu pelanggan menghemat puluhan miliar dolar.Faktor penting dalam memilih platform perangkat lunak VMware adalah total biaya kepemilikan terendah dibandingkan dengan solusi yang bersaing. Anda dapat secara mandiri menggunakan kalkulator dari total biaya kepemilikan dan pengembalian investasi untuk membandingkan dengan alternatif, seperti solusi dari Microsoft dan infrastruktur TI tradisional [ 8 ].Karena kami awalnya memutuskan bahwa kami akan mempertimbangkan dua kasus penggunaan, untuk kasus dengan portal olahraga, kami setuju bahwa solusi perangkat lunak sumber terbuka gratis akan digunakan, dan dalam kasus ERP, perangkat lunak berlisensi dari VMware. Total untuk perangkat lunak virtualisasi - 1,2 juta rubel. Biaya tahunan dukungan teknis dan akses ke pembaruan produk adalah 334 ribu rubel.Tambahkan ke ini lisensi perangkat lunak penyimpanan tingkat menengah - 100 ribu rubel.
Total untuk perangkat lunak virtualisasi - 1,2 juta rubel. Biaya tahunan dukungan teknis dan akses ke pembaruan produk adalah 334 ribu rubel.Tambahkan ke ini lisensi perangkat lunak penyimpanan tingkat menengah - 100 ribu rubel.Biaya staf
Sementara biaya staf aktual untuk mendukung operasi yang stabil dari infrastruktur TI biasanya terdiri dari remunerasi beberapa orang yang berbeda, untuk kesederhanaan kami akan menggunakan rasio sederhana antara jumlah server dan jumlah orang yang dibawa AWS untuk digunakan dalam model biayanya. Kami akan menyebutnya koefisien "server-ke-admin".Berdasarkan diskusi dengan pelanggan, AWS menemukan bahwa rasio 50 banding 1 adalah rata-rata yang baik dari kisaran khas banyak perusahaan. Kami menyarankan Anda menyesuaikan asumsi ini berdasarkan penelitian dan pengalaman Anda sendiri dan termasuk dalam biaya personil semua orang yang terlibat dalam membuat dan mengelola pusat data fisik Anda, dan bukan hanya orang-orang yang menginstal dan mengelola server. Hubungan aktual antara orang-orang dan server dapat sangat bervariasi, karena itu tergantung pada sejumlah faktor, seperti kompleksitas otomatisasi, alat yang digunakan, pilihan yang mendukung lingkungan yang tervirtualisasi atau non-tervirtualisasi.Karena kita berbicara tentang beberapa karyawan abstrak yang akan memiliki spesialisasi berbeda sesuai dengan tugas saat ini, kami akan menggunakan gaji bulanan rata-rata seorang spesialis TI untuk paruh pertama tahun 2018 dari laporan layanan My Circle [ 9 ].Menurut survei, itu adalah 90.000 rubel per orang setelah dikurangi semua pajak dan biaya. Menambahkan 50% lagi ke pembayaran ke PFR, MHIF, FSS dan PIT, kami mendapatkan 135.000 rubel. Ini adalah biaya dari satu spesialis TI yang 100% sarat dengan bekerja dengan infrastruktur TI, penciptaan yang kami jelaskan dalam kasus kami.Karena kami memiliki 4 server dan 1 penyimpanan, menggunakan "server-ke-admin" sama dengan 50 banding 1, kami mendapatkan sekitar 10% dari waktu yang dihabiskan untuk bekerja oleh satu karyawan "universal" atau 13,5 ribu rubel per bulan.Total biaya untuk infrastruktur sendiri
Capex (pengeluaran modal atau pengeluaran modal) berarti biaya atau pengeluaran modal. Ini adalah biaya, sebagai suatu peraturan, satu kali (tidak teratur) yang dialokasikan oleh perusahaan untuk pembelian aset tidak lancar, modernisasi dan rekonstruksi mereka.
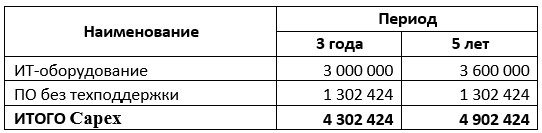 Opex (Eng. Biaya operasi, biaya operasi
Opex (Eng. Biaya operasi, biaya operasi - biaya operasi) - biaya yang
dikeluarkan perusahaan dalam proses kegiatan saat ini untuk memastikan berfungsi. Pengeluaran semacam itu juga disebut biaya periode sekarang.
 TCO final infrastruktur tersebut akan berjumlah 7.331.498 rubel selama 3 tahun, dan 9.884.214 rubel selama 5 tahun.
TCO final infrastruktur tersebut akan berjumlah 7.331.498 rubel selama 3 tahun, dan 9.884.214 rubel selama 5 tahun.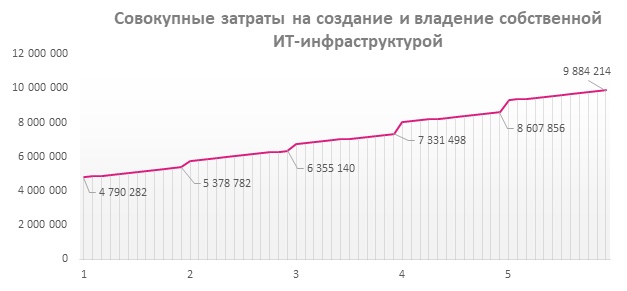
Dengan demikian, investasi awal dalam perangkat lunak dan perangkat keras selama 5 tahun ke depan lebih dari dua kali lipat. Sendiri, 4,8 juta yang dibutuhkan untuk menjalankan infrastruktur ini juga membawa risiko.
Pertama, harga adalah kesalahan. Jika kita tidak berbicara tentang perusahaan yang stabil dengan kebutuhan daya komputasi yang diprediksi dengan baik, tetapi kami sedang mempertimbangkan startup dengan layanan baru yang mencoba menaklukkan pasar, semua investasi awal dapat sia-sia. Ya, tentu saja, peralatan yang dibeli dapat dijual. Namun, transaksi semacam itu dilakukan dengan diskon besar, dan pencarian pembeli bisa memakan waktu berbulan-bulan.
Kedua, nilai uang. Seringkali, proyek-proyek seperti itu dilaksanakan dengan bantuan dana kredit. Setelah menerima pinjaman sebesar 4 juta rubel dengan tingkat bunga mendekati ambang minimum untuk badan hukum. orang pada 12% per tahun, jumlah bunga selama 3 tahun akan berjumlah 783 ribu rubel.
Kami tidak akan menambahkan
biaya opsional ini ke dalam perhitungan TCO kami, namun, ketika Anda menganalisis kasus Anda, Anda harus memperhitungkan kondisi untuk menerima uang dari bisnis Anda dan menambahkan biaya yang sesuai.
Ternyata memiliki perangkat keras sendiri cukup mahal. Alternatifnya adalah menggunakan layanan cloud. Mari kita beralih ke perbandingan.Hitung awan TCO
Karena kami tidak dapat berbicara tentang biaya cloud tanpa memilih penyedia tertentu, kami akan melakukan analisis TCO menggunakan contoh kami sendiri.
Sejak didirikan pada tahun 2009, Cloud4Y, penyedia cloud perusahaan, telah berfokus pada kebutuhan dan persyaratan bisnis yang tinggi untuk layanan TI. Kami menawarkan pusat data yang dapat dikonfigurasi oleh perangkat lunak (vDC) berdasarkan pada solusi cluster VMware vSphere dengan manajemen melalui portal layanan mandiri VMware vCloud Director.
Selain model IaaS (infrastruktur sebagai layanan), kami telah mengembangkan dan berhasil menyediakan pelanggan dengan banyak produk SaaS yang relevan dan populer (1C di cloud, desktop jarak jauh, surat perusahaan, antispam, dan banyak lagi).
Tumpukan teknologi VMware bekas (vSphere, NSX, vCloud Director),
peralatan andal (server blade HP, sistem penyimpanan all-flash, switch Cisco dan Juniper) yang terletak di jaringan pusat data TIER 3 aman yang terhubung oleh cincin optik ketersediaan tinggi dengan duplikasi saluran komunikasi memastikan kualitas layanan yang tepat dan toleransi kesalahan yang diperlukan untuk klien-Perusahaan.

Cloud4Y menyediakan redundansi perangkat keras lengkap untuk server dan peralatan jaringan. Pencadangan dilakukan ke pusat data yang jauh secara geografis. Secara default, opsi-opsi VMware cluster diimplementasikan: migrasi langsung vMotion, transfer otomatis mesin virtual ke host cadangan jika terjadi kegagalan VM (ketersediaan tinggi) VMware, keseimbangan beban antara host VMware DRS.
Jika Anda ingin mengurangi downtime ke waktu minimum, Anda dapat menggunakan teknologi Toleransi Kesalahan VMware. Gagasan utama dari opsi ini dapat digambarkan sebagai membuat replika mesin virtual yang bekerja secara serempak di server lain dan langsung beralih ke itu ketika tuan rumah utama gagal.
Dukungan teknis diberikan 24 * 7 * 365. Dukungan dibagi menjadi tiga baris:
- Jalur dukungan teknis pertama berkaitan dengan aksesibilitas dan masalah teknis hingga dan termasuk tingkat OS, tiket mulai dan memberi saran kepada klien. Dalam hal permintaan yang tidak mempengaruhi data dan tidak berhubungan dengan keuangan, masalah pelanggan dapat diselesaikan dengan menggunakan salah satu metode yang tersedia.
- Baris kedua dari dukungan teknis berkaitan dengan masalah tingkat hypervisor dan OS, pengaturan perangkat lunak klien, penyesuaian, analisis log, masalah integrasi dan dukungan mendalam untuk sistem informasi klien.
- Lini ketiga dukungan menyelesaikan masalah secara global pada tingkat jaringan, tingkat sistem penyimpanan dan bertanggung jawab atas arsitektur dan aksesibilitas secara keseluruhan.
Kami melihat bahwa semua komponen cloud Cloud4Y dirancang untuk memberikan tingkat uptime tertinggi. Ini memungkinkan kita untuk berbicara tentang tingkat yang diharapkan secara umum dari ketersediaan sistem 99,982% per tahun. Bukan elemen tunggal dari sistem, apakah itu jaringan, peralatan, platform lokasi, atau platform virtualisasi, adalah tautan yang lemah.Level ketersediaan adalah 99.982% lebih tinggi dari level minimum yang direncanakan oleh kami. Jadi, mari kita beralih ke menghitung TCO di cloud dan mencari tahu apakah kita bisa mendapatkan layanan tanpa premi untuk peningkatan toleransi kesalahan.
Konfigurasi nominal alternatif di cloud adalah 32 vCPUs, 256 Gb RAM dan 11 Tb Medium SAS (4400 IOPS). Saat menghitung pada kalkulator di situs web, kami mendapat 250 824 rubel per bulan dan menawarkan diskon. Tergantung pada proyeknya, diskon akan berbeda, tetapi kami merencanakan kemungkinan diskon sebesar 20%, yang pada akhirnya akan memberi kami 2.407.910 rubel per tahun, 7,22 juta selama 3 tahun dan 12 juta rubel selama 5 tahun.
Pada tahap ini, solusi cloud kehilangan penciptaan infrastruktur TI sendiri, tetapi jangan buru-buru mengambil kesimpulan.
Reservasi
Pertama, cadangan perangkat keras sudah disediakan oleh penyedia, jika gagal Anda akan dialokasikan tuan rumah lain dari kumpulan sumber daya penyedia. Jadi konfigurasi daya alternatif adalah 24 vCPU, 196 Gb RAM dan 1 Tb Medium SAS dan 10 Tb Low. Kami sudah mendapatkan 187.793 rubel per bulan atau 150.234 rubel. dikenakan diskon.
Dengan penyesuaian ini, kami telah mencapai total biaya yang lebih rendah daripada arsitektur kami sendiri.
Kami berbicara tentang 7,3 juta rubel selama 3 tahun, dan 9,9 juta rubel selama 5 tahun untuk perangkat keras kami sendiri. Pada tahap ini, cloud sudah lebih murah - 5,4 dan 9 juta rubel, masing-masing.Elastisitas
Keuntungan penting dari komputasi awan adalah elastisitas yang cepat. Sumber daya dapat dengan cepat dialokasikan dan dihilangkan, dalam beberapa kasus secara otomatis, untuk penskalaan cepat sesuai dengan permintaan. Bagi konsumen, kemungkinan menyediakan sumber daya dilihat sebagai tidak terbatas, yaitu, mereka dapat ditetapkan dalam jumlah berapa pun dan kapan saja.
Dengan kata lain, jika Anda membutuhkan 30 CPU, maka Anda hanya menyewa 30 CPU di cloud. Tapi, jika Anda sedang membangun sumber daya Anda sendiri, maka Anda pasti tidak akan membuat tepat 30. Bayangkan bahwa Anda adalah direktur TI dari portal web olahraga, dan Anda sedang mempersiapkan kekuatan komputasi untuk Piala Dunia. Dalam hal ini, Anda harus siap untuk puncak kunjungan selama periode ini, dan pertanyaan kunci bagi Anda adalah sumber daya mana yang cukup. Jika mereka direncanakan terlalu sedikit, maka selama periode acara olahraga besar mereka tidak akan cukup, dan jika ada terlalu banyak, mereka akan diam selama sisa waktu.
Pada awalnya, kami berbicara tentang dua pola penggunaan. Dalam kasus sistem ERP, kami akan meningkatkan jumlah sumber daya yang digunakan dari 2/3 dalam tiga tahun pertama menjadi pembuangan penuh (payload) dalam waktu 4 dan 5 tahun. Untuk sumber daya dari portal olahraga, kami akan memberikan dua puncak beban hampir 100% per tahun dengan durasi masing-masing 1 bulan, sisa waktu sumber daya hanya akan digunakan oleh 40%.

Ini adalah pemanfaatan sumber daya yang tinggi dan manajemen yang efektif yang memungkinkan penyedia cloud untuk menghasilkan uang pada bisnis mereka sendiri. Bagaimana ini bisa membantu menyelamatkan penyewa?
Kami melanjutkan ke perhitungan.
Skenario ERP: 2/3 dari pemanfaatan sumber daya (121 ribu rubel / bulan) dalam tiga tahun pertama akan menelan biaya 4,356 juta rubel, dan semua 5 tahun, dengan mempertimbangkan pertumbuhan - 7,961 juta rubel.
Portal olahraga: 1/6 dari pemanfaatan hingga 100% dari jumlah maksimum sumber daya, dan 5/6 - 40% dari pemanfaatan. Sumber daya penyimpanan - tumbuh dari 40% menjadi 90% selama 5 tahun.
Pada grafik di bawah ini Anda dapat melihat bagaimana biaya tumbuh selama 5 tahun dan bagaimana puncak aktivitas pengguna di portal mempengaruhi biaya infrastruktur cloud.
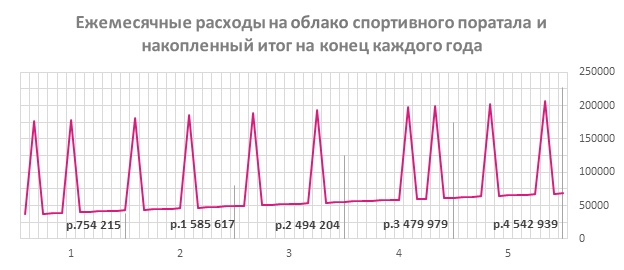
Menggunakan sumber daya seperlunya, Anda dapat mengurangi biaya hingga 2,494 juta rubel. selama tiga tahun dan 4,543 juta rubel. selama 5 tahun.
Jadi, kami akhirnya siap untuk membandingkan TCO dari solusi cloud dan pembelian perangkat keras kami sendiri.
Menurut perkiraan kami, cloud untuk skenario penggunaan perusahaan lebih murah sebesar 1,9 juta rubel, atau 19,5% lebih murah dalam 5 tahun dan 40,5% lebih murah dalam 3 tahun mendatang.
Kami menambahkan opsi menggunakan perangkat lunak virtualisasi gratis dan menyewa server fisik di pusat data dengan lisensi kami sendiri, tetapi bahkan mereka kehilangan cloud selama 3 tahun. Ketika membandingkan TCO berusia 5 tahun, opsi ini ternyata “lebih menguntungkan,” tetapi mereka menyiratkan penurunan dalam pengelolaan, toleransi kesalahan, dan fleksibilitas. Opsi tersebut tidak berlaku untuk IT perusahaan, sedangkan dalam kasus penggunaan untuk portal olahraga, opsi ini hilang dari cloud di TSO-5let.
Nilai uang
Setidaknya uang yang dihemat dapat digunakan oleh bisnis untuk proyek lain, yang berarti menghasilkan keuntungan. Mengambil pengembalian investasi 10% per tahun, kita bisa bicara
- pada laba dari 1,7 juta rubel dari arus kas bebas (perbedaan antara on-premise bulanan dan biaya cloud) dan 1,9 juta dihemat selama 5 tahun dalam skenario dengan ERP
- dan 2,5 juta keuntungan "belum dirilis" untuk portal olahraga, ditambah 5,3 juta rubel disimpan.
Bayar saat Anda pergi
Cloud4Y menyediakan model pembayaran Pay as you go untuk setiap jenis sumber daya secara individual. Pendekatan ini memungkinkan untuk membayar sumber daya setelah dikonsumsi. Kami menggunakan core dan RAM saat ini sebanyak yang diperlukan. Perlu dicatat bahwa dalam semua kasus, biaya untuk CPU dan RAM hanya diambil untuk waktu "aktif", pada saat Anda tidak menggunakan mesin virtual - biayanya tidak dikenakan biaya. Tetapi penyimpanan harus dibayar terlepas dari apakah mesin dihidupkan atau dimatikan - muatan diambil sampai disk memiliki data, jika disk kosong, tidak ada biaya.
Di situs ini Anda dapat menemukan kalkulator biaya layanan, tetapi perlu dicatat bahwa kalkulator ini berfungsi berdasarkan asumsi menggunakan VM dalam mode 24x7x30. Menggunakan VM dalam mode 12x5x30, biaya layanan untuk Anda dapat lebih rendah lebih dari 50-60%. Pola pemanfaatan sumber daya semacam itu khas, misalnya, untuk infrastruktur desktop jarak jauh virtual atau "kantor cloud". Ketika karyawan organisasi tidak bekerja, mesin virtual dengan desktop mereka dimatikan, dan penghematan dimulai. Kami tidak mempertimbangkan use case seperti itu dibandingkan dengan TCO, tetapi logis dan diverifikasi dalam praktiknya bahwa cloud mem-bypass alternatif lain dalam kasus ini.
Kesimpulan
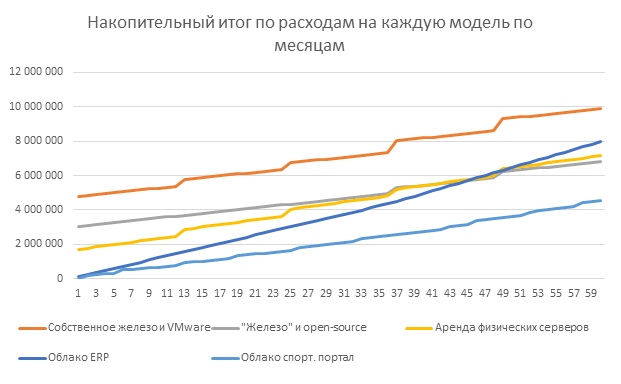
Grafik dengan jelas menunjukkan bahwa selama 5 tahun masa pakai infrastruktur IT, Cloud4Y menang atas pembelian perangkat kerasnya sendiri. Di luar periode ini, kemungkinan besar, server secara moral usang dan perlu untuk membeli yang baru. Penyedia sendiri juga bertanggung jawab untuk memperbarui peralatan di cloud. Dengan demikian, pertimbangan periode yang lebih lama tidak akan mengubah situasi dengan kelayakan ekonomi cloud.
Ada beberapa opsi saat cloud menjadi kurang menguntungkan. Pada dasarnya, ini adalah kasus-kasus dengan kehadiran peralatan yang sudah diakuisisi dan menganggur atau pembelian server untuk sedikit meningkatkan sumber daya yang ada dan digunakan secara efisien. Kita juga dapat menyimpulkan bahwa ada keuntungan yang lebih besar dalam layanan cloud dalam skenario dengan pemanfaatan kapasitas yang spasmodik atau tidak dapat diprediksi.
Untuk mendapatkan saran dan perhitungan TCO di cloud untuk kasus organisasi Anda, hubungi manajer
Cloud4Y dengan
cara yang nyaman bagi Anda.
Tautan Pengunduhan White Paper Free: Perhitungan TCO “Server Cloud vs Buying” (.pdf)