 Terjemahan dari Proyek Pembelajaran Mesin Lengkap Walk-Through dengan Python: Bagian Satu .
Terjemahan dari Proyek Pembelajaran Mesin Lengkap Walk-Through dengan Python: Bagian Satu .Ketika Anda membaca buku atau mendengarkan kursus pelatihan tentang analisis data, Anda sering merasa bahwa Anda menghadapi beberapa bagian terpisah dari gambar yang tidak dapat disatukan. Anda mungkin takut dengan prospek mengambil langkah berikutnya dan menyelesaikan masalah sepenuhnya dengan bantuan pembelajaran mesin, tetapi dengan bantuan seri artikel ini Anda akan mendapatkan kepercayaan pada kemampuan untuk memecahkan masalah apa pun di bidang ilmu data.
Agar Anda akhirnya memiliki gambaran lengkap di kepala Anda, kami menyarankan untuk menganalisis dari awal hingga akhir proyek menggunakan pembelajaran mesin menggunakan data nyata.
Ikuti langkah-langkahnya:
- Membersihkan dan memformat data.
- Analisis data eksplorasi.
- Desain dan pemilihan fitur.
- Perbandingan metrik beberapa model pembelajaran mesin.
- Tuning hyperparametric model terbaik.
- Evaluasi model terbaik pada set data uji.
- Interpretasi hasil model.
- Kesimpulan dan bekerja dengan dokumen.
Anda akan belajar bagaimana tahapan berjalan satu sama lain dan bagaimana mengimplementasikannya dengan Python.
Seluruh proyek tersedia di GitHub, bagian pertama ada di
sini. Pada artikel ini kita akan membahas tiga tahap pertama.
Deskripsi tugas
Sebelum menulis kode, Anda harus memahami masalah yang sedang dipecahkan dan data yang tersedia. Dalam proyek ini, kami akan bekerja dengan
data efisiensi energi yang tersedia untuk umum
untuk bangunan di New York.
Tujuan kami: untuk menggunakan data yang tersedia untuk membangun model yang memprediksi jumlah Skor Bintang Energi untuk bangunan tertentu, dan menafsirkan hasilnya untuk menemukan faktor-faktor yang mempengaruhi skor akhir.
Data sudah termasuk Skor Energy Star yang ditugaskan, jadi tugas kami adalah pembelajaran mesin dengan regresi terkontrol:
- Dibimbing: Kami tahu tanda dan tujuan, dan tugas kami adalah melatih model yang dapat membandingkan yang pertama dengan yang kedua.
- Regresi: Skor Bintang Energi adalah variabel kontinu.
Model kami harus akurat - sehingga dapat memprediksi nilai Skor Bintang Energi mendekati benar - dan dapat ditafsirkan - sehingga kami dapat memahami prediksi tersebut. Mengetahui data target, kita dapat menggunakannya ketika membuat keputusan saat kita masuk lebih dalam ke data dan membuat model.
Pembersihan data
Tidak setiap set data adalah set pengamatan yang sangat cocok, tanpa anomali dan nilai yang hilang (sedikit dari data
mtcars dan
iris ). Dalam data nyata, ada sedikit pesanan, jadi sebelum Anda memulai analisis, Anda perlu
menghapusnya dan membawanya ke format yang dapat diterima. Pembersihan data adalah prosedur yang tidak menyenangkan tetapi wajib dalam menyelesaikan sebagian besar tugas analisis data.
Pertama, Anda dapat memuat data dalam bentuk kerangka data Pandas dan memeriksanya:
import pandas as pd import numpy as np # Read in data into a dataframe data = pd.read_csv('data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv') # Display top of dataframe data.head()
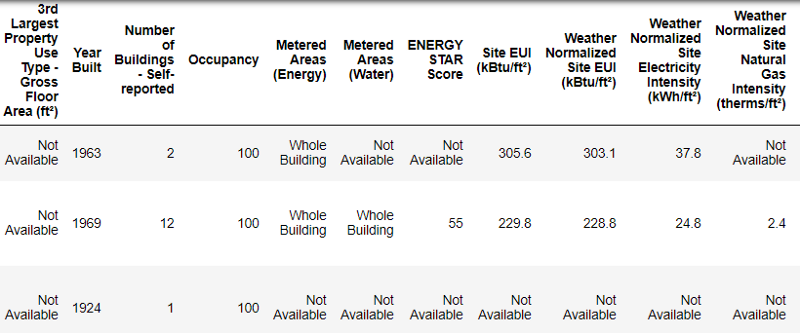 Beginilah tampilan data nyata.
Beginilah tampilan data nyata.Ini adalah fragmen dari tabel 60 kolom. Bahkan di sini, beberapa masalah terlihat: kita perlu memprediksi
Energy Star Score , tetapi kita tidak tahu apa arti semua kolom ini. Meskipun ini belum tentu menjadi masalah, karena Anda sering dapat membuat model yang akurat tanpa mengetahui apa pun tentang variabel sama sekali. Tetapi interpretabilitas penting bagi kami, jadi kami perlu mencari tahu arti dari setidaknya beberapa kolom.
Ketika kami menerima data ini, kami tidak bertanya tentang nilai-nilai, tetapi melihat nama file:
dan memutuskan untuk mencari "Hukum Lokal 84". Kami menemukan
halaman ini , yang mengatakan bahwa itu adalah undang-undang New York, yang menurutnya pemilik semua bangunan dengan ukuran tertentu harus melaporkan konsumsi energi. Pencarian lebih lanjut membantu menemukan
semua nilai kolom . Jadi jangan abaikan nama file, itu bisa menjadi titik awal yang baik. Selain itu, ini adalah pengingat agar Anda tidak tergesa-gesa dan tidak ketinggalan sesuatu yang penting!
Kami tidak akan mempelajari semua kolom, tetapi kami pasti akan berurusan dengan Skor Bintang Energi, yang digambarkan sebagai berikut:
Peringkat persentil adalah dari 1 hingga 100, yang dihitung berdasarkan laporan tahunan tentang konsumsi energi oleh pemilik bangunan itu sendiri. Skor Energy Star adalah ukuran relatif yang digunakan untuk membandingkan kinerja energi bangunan.
Masalah pertama diselesaikan, tetapi yang kedua tetap - nilai yang hilang, ditandai sebagai "Tidak Tersedia". Ini adalah nilai string dalam Python, yang berarti bahwa bahkan string dengan angka akan disimpan sebagai tipe data
object , karena jika ada string dalam kolom, Pandas mengubahnya menjadi kolom yang seluruhnya terdiri dari string. Jenis data kolom dapat ditemukan menggunakan metode
dataframe.info() :
# See the column data types and non-missing values data.info()
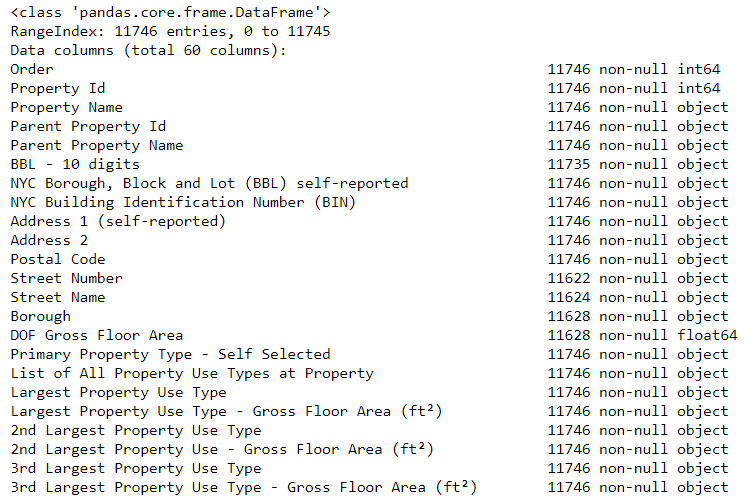
Tentunya beberapa kolom yang secara eksplisit berisi angka (seperti ft²) disimpan sebagai objek. Kami tidak dapat menerapkan analisis numerik ke nilai string, jadi kami mengonversinya menjadi tipe data numerik (terutama
float )!
Kode ini pertama-tama menggantikan semua “Tidak Tersedia” dengan
bukan angka (
np.nan ), yang dapat diartikan sebagai angka, dan kemudian mengonversi konten kolom tertentu ke tipe
float :
# Replace all occurrences of Not Available with numpy not a number data = data.replace({'Not Available': np.nan}) # Iterate through the columns for col in list(data.columns): # Select columns that should be numeric if ('ft²' in col or 'kBtu' in col or 'Metric Tons CO2e' in col or 'kWh' in col or 'therms' in col or 'gal' in col or 'Score' in col): # Convert the data type to float data[col] = data[col].astype(float)
Ketika nilai-nilai di kolom yang sesuai dengan kami menjadi angka, kita dapat mulai memeriksa data.
Data tidak ada dan tidak normal
Seiring dengan tipe data yang salah, salah satu masalah yang paling umum adalah nilai yang hilang. Mereka mungkin absen karena berbagai alasan, dan sebelum melatih model, nilai-nilai ini harus diisi atau dihapus. Pertama, mari kita cari tahu berapa banyak nilai yang kita miliki di setiap kolom (
kode ada di sini ).
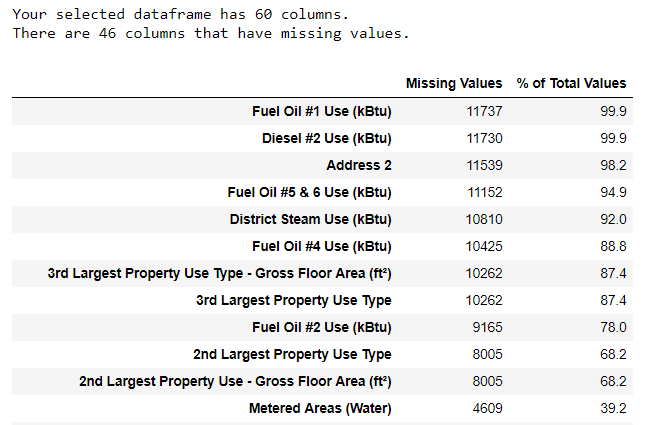 Untuk membuat tabel, fungsi dari cabang di StackOverflow digunakan .
Untuk membuat tabel, fungsi dari cabang di StackOverflow digunakan .Informasi harus selalu dihapus dengan hati-hati, dan jika ada banyak nilai di kolom, maka itu mungkin tidak akan menguntungkan model kita. Ambang batas setelah itu lebih baik membuang kolom tergantung pada tugas Anda (di
sini adalah diskusi ), dan dalam proyek kami, kami akan menghapus kolom yang lebih dari setengah kosong.
Juga pada tahap ini lebih baik untuk menghapus nilai abnormal. Mereka dapat terjadi karena kesalahan ketik saat memasukkan data atau karena kesalahan dalam unit pengukuran, atau mereka bisa benar, tetapi nilai ekstrim. Dalam hal ini, kami akan menghapus nilai "ekstra", dipandu oleh
definisi anomali ekstrim :
- Di bawah kuartil pertama adalah rentang interkuartil 3..
- Di atas kuartil ketiga + 3 range rentang interkuartil.
Kode yang menghilangkan kolom dan anomali tercantum pada Notepad di Github. Setelah menyelesaikan proses pembersihan data dan menghilangkan anomali, kami memiliki lebih dari 11.000 bangunan dan 49 tanda.
Analisis data eksplorasi
Tahap pembersihan data yang membosankan namun perlu, Anda bisa pergi ke ruang belajar!
Analisis data eksplorasi (RAD) adalah proses waktu tanpa batas di mana kami menghitung statistik dan mencari tren, anomali, pola, atau hubungan dalam data.
Singkatnya, RAD adalah upaya untuk mencari tahu data apa yang dapat memberi tahu kami. Biasanya, analisis dimulai dengan ulasan yang dangkal, kemudian kami menemukan fragmen yang menarik dan menganalisisnya secara lebih rinci. Temuan mungkin menarik dalam hak mereka sendiri, atau mereka dapat berkontribusi pada pilihan model, membantu memutuskan fitur mana yang akan kita gunakan.
Grafik variabel tunggal
Tujuan kami adalah untuk memprediksi nilai Skor Bintang Energi (diubah namanya menjadi
score kami di data kami), jadi masuk akal untuk memulai dengan memeriksa distribusi variabel ini. Histogram adalah cara sederhana namun efektif untuk memvisualisasikan distribusi variabel tunggal, dan dapat dengan mudah dibangun menggunakan
matplotlib .
import matplotlib.pyplot as plt # Histogram of the Energy Star Score plt.style.use('fivethirtyeight') plt.hist(data['score'].dropna(), bins = 100, edgecolor = 'k'); plt.xlabel('Score'); plt.ylabel('Number of Buildings'); plt.title('Energy Star Score Distribution');
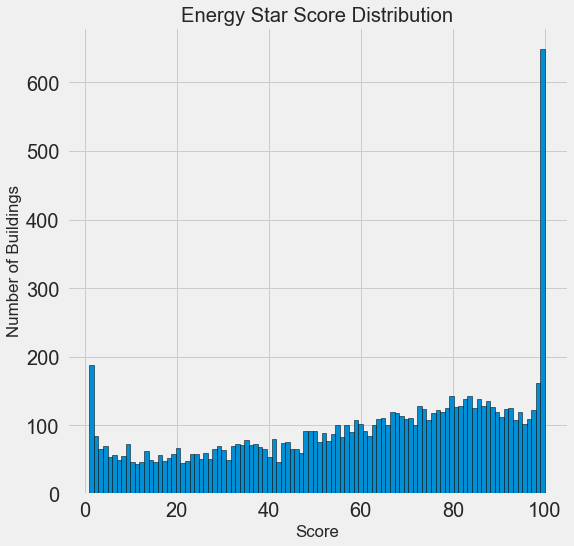
Terlihat mencurigakan! Skor Energy Star adalah persentil, jadi Anda harus mengharapkan distribusi yang seragam ketika setiap titik ditugaskan ke jumlah gedung yang sama. Namun, sejumlah besar bangunan secara tidak proporsional menerima hasil tertinggi dan terendah (untuk Skor Energy Star, semakin besar semakin baik).
Jika kita kembali melihat definisi skor ini, kita akan melihat bahwa itu dihitung berdasarkan "laporan yang diisi secara independen oleh pemilik bangunan," yang mungkin menjelaskan kelebihan nilai yang sangat besar. Meminta pemilik gedung untuk melaporkan konsumsi energi mereka seperti meminta siswa untuk melaporkan nilai mereka dalam ujian. Jadi ini mungkin bukan kriteria yang paling objektif untuk menilai efisiensi energi real estat.
Jika kita memiliki persediaan waktu yang tidak terbatas, kita dapat mengetahui mengapa begitu banyak bangunan mendapat poin yang sangat tinggi dan sangat rendah. Untuk melakukan ini, kita harus memilih bangunan yang sesuai dan menganalisisnya dengan cermat. Tetapi kita hanya perlu belajar bagaimana memprediksi skor, dan tidak mengembangkan metode penilaian yang lebih akurat. Anda dapat menandai diri sendiri bahwa poin memiliki distribusi yang mencurigakan, tetapi kami akan fokus pada perkiraan.
Pencarian hubungan
Bagian utama dari AHFR adalah pencarian hubungan antara tanda dan tujuan kita. Variabel yang berhubungan dengannya berguna untuk digunakan dalam model, karena mereka dapat digunakan untuk peramalan. Salah satu cara untuk mempelajari pengaruh variabel kategorikal (yang hanya mengambil satu set nilai terbatas) pada tujuannya adalah dengan memplot kepadatan menggunakan perpustakaan Seaborn.
Grafik kerapatan dapat dianggap sebagai histogram yang dihaluskan karena menunjukkan distribusi variabel tunggal. Anda bisa memberi warna pada masing-masing kelas pada grafik untuk melihat bagaimana variabel kategori mengubah distribusi. Kode ini memplot grafik kerapatan Skor Bintang Energi, diwarnai sesuai dengan jenis bangunan (untuk daftar bangunan dengan lebih dari 100 dimensi):
# Create a list of buildings with more than 100 measurements types = data.dropna(subset=['score']) types = types['Largest Property Use Type'].value_counts() types = list(types[types.values > 100].index) # Plot of distribution of scores for building categories figsize(12, 10) # Plot each building for b_type in types: # Select the building type subset = data[data['Largest Property Use Type'] == b_type] # Density plot of Energy Star Scores sns.kdeplot(subset['score'].dropna(), label = b_type, shade = False, alpha = 0.8); # label the plot plt.xlabel('Energy Star Score', size = 20); plt.ylabel('Density', size = 20); plt.title('Density Plot of Energy Star Scores by Building Type', size = 28);
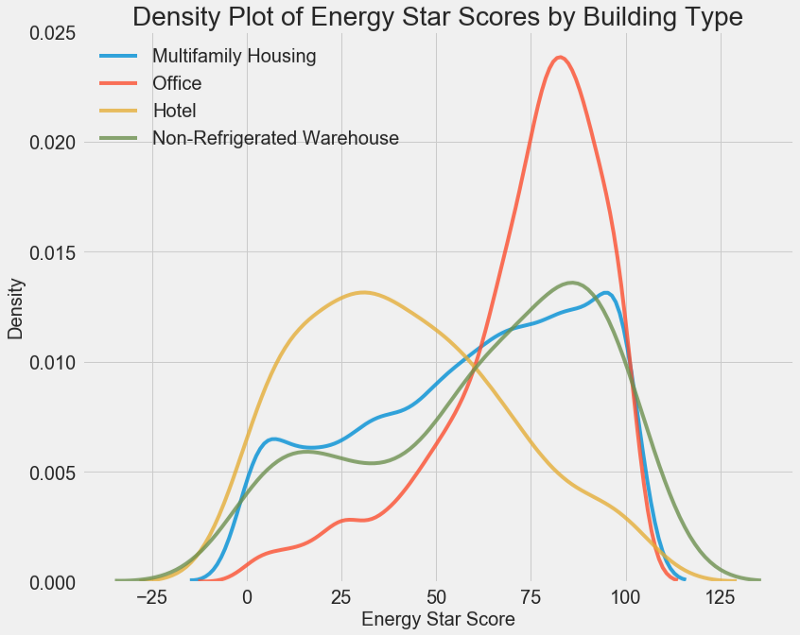
Seperti yang Anda lihat, jenis bangunan sangat mempengaruhi jumlah titik. Bangunan kantor biasanya memiliki skor lebih tinggi dan hotel lebih rendah. Jadi, Anda perlu memasukkan jenis bangunan dalam model, karena tanda ini memengaruhi tujuan kami. Sebagai variabel kategori, kita harus melakukan pengkodean satu-panas dari tipe bangunan.
Grafik serupa dapat digunakan untuk memperkirakan Skor Bintang Energi berdasarkan distrik kota:
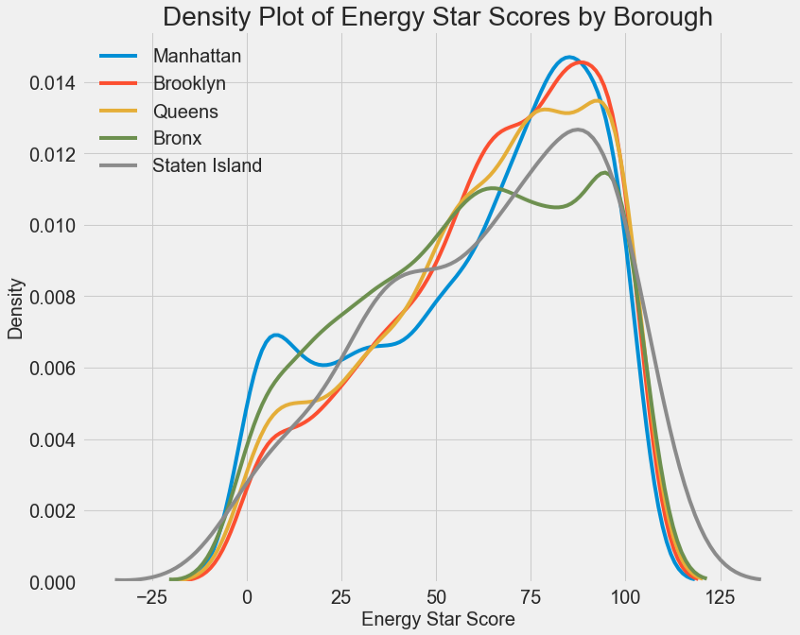
Area tidak mempengaruhi skor sebanyak jenis bangunan. Namun demikian, kami akan memasukkannya dalam model, karena ada sedikit perbedaan antara daerah.
Untuk menghitung hubungan antar variabel, Anda dapat menggunakan
koefisien korelasi Pearson . Ini adalah ukuran intensitas dan arah hubungan linear antara dua variabel. Nilai +1 berarti hubungan positif linear sempurna, dan -1 berarti hubungan negatif linear sempurna. Berikut adalah beberapa contoh nilai
koefisien korelasi Pearson :

Meskipun koefisien ini tidak dapat mencerminkan ketergantungan nonlinier, dimungkinkan untuk mulai dengan itu untuk mengevaluasi hubungan variabel. Di Pandas, Anda dapat dengan mudah menghitung korelasi antara kolom apa pun dalam bingkai data:
# Find all correlations with the score and sort correlations_data = data.corr()['score'].sort_values()
Korelasi paling negatif dengan tujuan:

dan yang paling positif:

Ada beberapa korelasi negatif yang kuat antara atribut dan tujuan, dan yang terbesar dari mereka termasuk dalam kategori EUI yang berbeda (metode untuk menghitung indikator ini sedikit berbeda).
EUI (Energy Use Intensity ) adalah jumlah energi yang dikonsumsi oleh bangunan dibagi dengan luas kaki persegi. Nilai spesifik ini digunakan untuk mengevaluasi efisiensi energi, dan semakin kecil, semakin baik. Logika menunjukkan bahwa korelasi ini dibenarkan: jika EUI meningkat, maka Skor Bintang Energi akan menurun.
Grafik dua variabel
Kami menggunakan plot pencar untuk memvisualisasikan hubungan antara dua variabel kontinu. Anda dapat menambahkan informasi tambahan ke warna titik-titik, misalnya, variabel kategori. Hubungan antara Skor Bintang Energi dan EUI ditunjukkan di bawah ini, warna menunjukkan berbagai jenis bangunan:
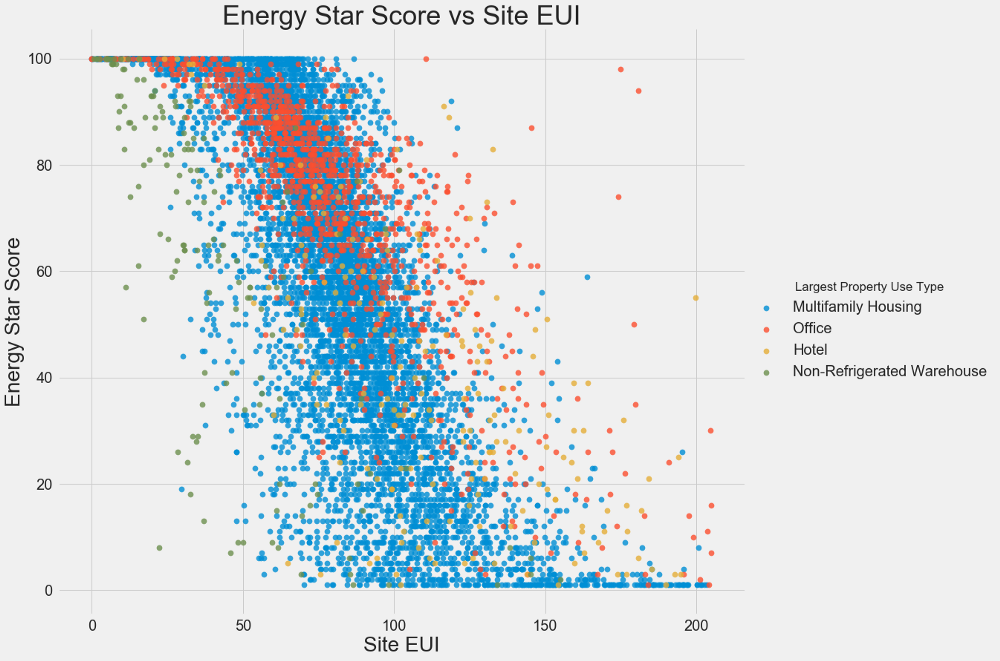
Grafik ini memungkinkan Anda untuk memvisualisasikan koefisien korelasi -0,7. Ketika EUI berkurang, Skor Energy Star meningkat, hubungan ini diamati pada berbagai jenis bangunan.
Bagan penelitian terbaru kami disebut
Pairs Plot . Ini adalah alat yang hebat untuk melihat hubungan antara pasangan variabel yang berbeda dan distribusi variabel tunggal. Kami akan menggunakan perpustakaan Seaborn dan fungsi PairGrid untuk membuat bagan pasangan dengan bagan sebar di segitiga atas, dengan histogram diagonal, bagan kerapatan inti dua dimensi dan koefisien korelasi di segitiga bawah.
# Extract the columns to plot plot_data = features[['score', 'Site EUI (kBtu/ft²)', 'Weather Normalized Source EUI (kBtu/ft²)', 'log_Total GHG Emissions (Metric Tons CO2e)']] # Replace the inf with nan plot_data = plot_data.replace({np.inf: np.nan, -np.inf: np.nan}) # Rename columns plot_data = plot_data.rename(columns = {'Site EUI (kBtu/ft²)': 'Site EUI', 'Weather Normalized Source EUI (kBtu/ft²)': 'Weather Norm EUI', 'log_Total GHG Emissions (Metric Tons CO2e)': 'log GHG Emissions'}) # Drop na values plot_data = plot_data.dropna() # Function to calculate correlation coefficient between two columns def corr_func(x, y, **kwargs): r = np.corrcoef(x, y)[0][1] ax = plt.gca() ax.annotate("r = {:.2f}".format(r), xy=(.2, .8), xycoords=ax.transAxes, size = 20) # Create the pairgrid object grid = sns.PairGrid(data = plot_data, size = 3) # Upper is a scatter plot grid.map_upper(plt.scatter, color = 'red', alpha = 0.6) # Diagonal is a histogram grid.map_diag(plt.hist, color = 'red', edgecolor = 'black') # Bottom is correlation and density plot grid.map_lower(corr_func); grid.map_lower(sns.kdeplot, cmap = plt.cm.Reds) # Title for entire plot plt.suptitle('Pairs Plot of Energy Data', size = 36, y = 1.02);
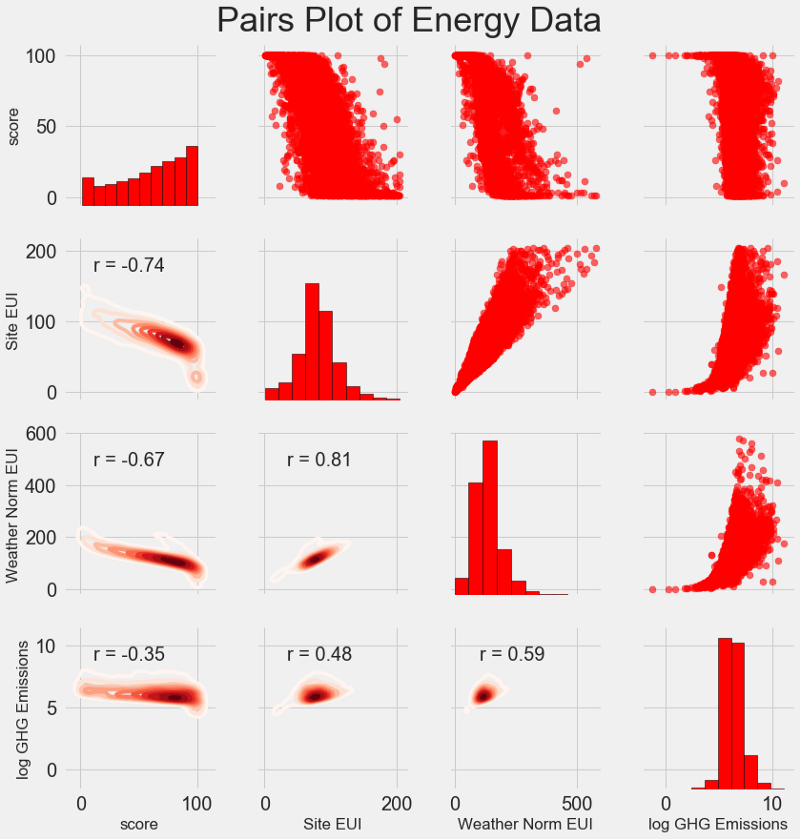
Untuk melihat hubungan variabel, cari persimpangan baris dan kolom. Misalkan Anda ingin melihat korelasi antara
Weather Norm EUI dan
score , maka kami mencari seri
Weather Norm EUI dan kolom
score , di persimpangan di mana terdapat koefisien korelasi -0,67. Grafik ini tidak hanya terlihat keren, tetapi juga membantu memilih variabel untuk model.
Desain dan pemilihan fitur
Merancang dan memilih fitur sering kali menghasilkan keuntungan terbesar dalam hal waktu yang dihabiskan untuk pembelajaran mesin. Pertama, kami memberikan definisi:
- Konstruksi karakter: Proses mengekstraksi atau membuat karakteristik baru dari data mentah. Untuk menggunakan variabel dalam model, Anda mungkin harus mentransformasikannya, katakanlah, ambil logaritma natural, atau ekstrak akar kuadrat, atau terapkan satu-hot coding dari variabel kategori. Desain karakteristik dapat dianggap sebagai menciptakan fitur tambahan dari data mentah.
- Pemilihan Fitur: Proses pemilihan fitur yang paling relevan dari data, di mana kami menghapus beberapa fitur untuk membantu model menggeneralisasikan data baru dengan lebih baik untuk mendapatkan model yang lebih dapat ditafsirkan. Pilihan tanda dapat dianggap sebagai penghilangan "berlebihan" sehingga hanya yang paling penting yang tersisa.
Model pembelajaran mesin hanya dapat belajar dari data yang kami sediakan, sehingga sangat penting untuk memastikan bahwa kami menyertakan semua informasi yang relevan dengan tugas kami. Jika Anda tidak memberikan model dengan data yang benar, model tidak akan dapat belajar dan tidak akan menghasilkan perkiraan yang akurat!
Kami akan melakukan hal berikut:
- Berlaku untuk variabel kategori (seperempat dan jenis kepemilikan), one-hot coding.
- Tambahkan logaritma natural dari semua variabel numerik.
Pengodean satu-panas diperlukan untuk memasukkan variabel kategori dalam model. Algoritma pembelajaran mesin tidak akan dapat memahami jenis "kantor", jadi jika bangunan itu adalah kantor, kami akan memberinya tanda 1, dan jika bukan kantor, maka 0.
Menambahkan fitur yang diubah akan membantu model belajar tentang hubungan nonlinear dalam data. Dalam analisis data, adalah praktik normal
untuk mengekstrak akar kuadrat, mengambil logaritma alami atau mengubah tanda-tanda , tergantung pada tugas khusus atau pengetahuan Anda tentang teknik terbaik. Dalam hal ini, kami akan menambahkan logaritma natural dari semua tanda numerik.
Kode ini memilih tanda-tanda numerik, menghitung logaritma mereka, memilih dua tanda kategori, menerapkan pengkodean satu-panas untuk mereka, dan menggabungkan kedua set menjadi satu. Dilihat dari uraiannya, masih banyak pekerjaan yang harus dilakukan, tetapi di Panda semuanya sangat sederhana!
# Copy the original data features = data.copy() # Select the numeric columns numeric_subset = data.select_dtypes('number') # Create columns with log of numeric columns for col in numeric_subset.columns: # Skip the Energy Star Score column if col == 'score': next else: numeric_subset['log_' + col] = np.log(numeric_subset[col]) # Select the categorical columns categorical_subset = data[['Borough', 'Largest Property Use Type']] # One hot encode categorical_subset = pd.get_dummies(categorical_subset) # Join the two dataframes using concat # Make sure to use axis = 1 to perform a column bind features = pd.concat([numeric_subset, categorical_subset], axis = 1)
Sekarang kami memiliki lebih dari 11.000 pengamatan (bangunan) dengan 110 kolom (tag). Tidak semua tanda akan berguna untuk memprediksi Skor Bintang Energi, jadi kami akan mengambil pilihan tanda dan menghapus beberapa variabel.
Pemilihan Fitur
Banyak dari 110 tanda yang tersedia berlebihan karena mereka sangat berkorelasi satu sama lain. Misalnya, berikut adalah grafik EUI dan Weather Normalized Site EUI, dengan koefisien korelasi 0,997.
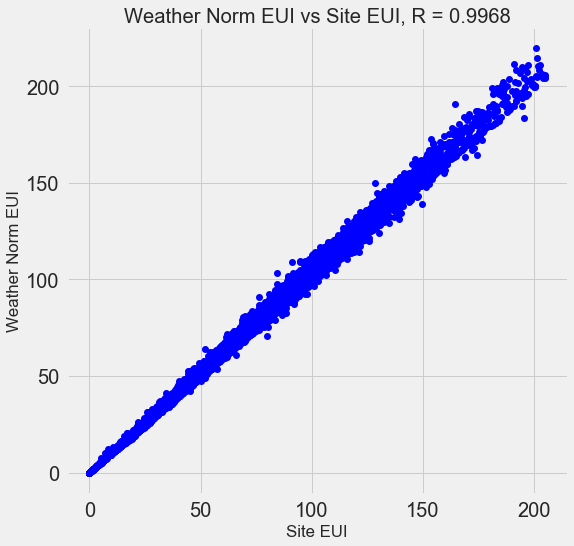
Tanda-tanda yang sangat berkorelasi satu sama lain disebut
collinear . Menghapus satu variabel dalam pasangan atribut semacam itu sering membantu
model untuk menggeneralisasi dan menjadi lebih dapat ditafsirkan . Harap dicatat bahwa kita berbicara tentang korelasi beberapa tanda dengan yang lain, dan bukan tentang korelasi dengan tujuan, yang hanya akan membantu model kita!
Ada sejumlah metode untuk menghitung collinearity fitur, dan salah satu yang paling populer adalah
variance inflation factor . Kami akan menggunakan koefisien korelasi untuk mencari dan menghapus fitur collinear. Kami membuang satu pasang tanda jika koefisien korelasi di antara mereka lebih dari 0,6. Kode ada di notepad (dan sebagai respons terhadap
Stack Overflow ).
Nilai ini terlihat sewenang-wenang, tetapi sebenarnya saya mencoba ambang yang berbeda, dan di atas memungkinkan saya untuk membuat model terbaik. Pembelajaran mesin bersifat
empiris , dan seringkali harus bereksperimen untuk menemukan solusi terbaik. Setelah seleksi, kami memiliki 64 atribut dan satu tujuan.
# Remove any columns with all na values features = features.dropna(axis=1, how = 'all') print(features.shape) (11319, 65)
Pilih level dasar
Kami membersihkan data, melakukan analisis eksplorasi, dan membangun tanda-tanda. Dan sebelum melanjutkan ke pembuatan model, Anda harus memilih level dasar awal (garis dasar naif) - semacam asumsi yang akan kami bandingkan dengan hasil model. Jika mereka jatuh di bawah tingkat dasar, kami akan menganggap bahwa pembelajaran mesin tidak berlaku untuk tugas ini, atau bahwa pendekatan yang berbeda harus dicoba.
Untuk tugas-tugas regresi, sebagai level dasar, masuk akal untuk menebak nilai median tujuan pada set pelatihan untuk semua contoh dalam set tes. Kit ini menetapkan penghalang yang relatif rendah untuk model apa pun.
Sebagai metrik, kami mengambil
kesalahan absolut rata -
rata (mae) dalam perkiraan. Ada banyak metrik lain untuk regresi, tetapi saya suka
saran untuk memilih satu metrik dan menggunakannya untuk mengevaluasi model. Dan kesalahan absolut rata-rata mudah untuk dihitung dan ditafsirkan.
Sebelum menghitung level dasar, Anda perlu membagi data ke dalam set pelatihan dan tes:
- Serangkaian pelatihan atribut adalah apa yang kami berikan model kami bersama dengan jawaban selama pelatihan. Model harus belajar untuk mencocokkan karakteristik tujuan.
- Set fitur uji digunakan untuk mengevaluasi model yang dilatih. Ketika dia memproses suite tes, dia tidak melihat jawaban yang benar dan harus memprediksi berdasarkan fitur yang tersedia saja. Kami tahu jawaban untuk data pengujian dan dapat membandingkan hasil perkiraan dengan mereka.
Untuk pelatihan, kami menggunakan 70% dari data, dan untuk pengujian - 30%:
# Split into 70% training and 30% testing set X, X_test, y, y_test = train_test_split(features, targets, test_size = 0.3, random_state = 42)
Sekarang kita menghitung indikator untuk level dasar awal:
# Function to calculate mean absolute error def mae(y_true, y_pred): return np.mean(abs(y_true - y_pred)) baseline_guess = np.median(y) print('The baseline guess is a score of %0.2f' % baseline_guess) print("Baseline Performance on the test set: MAE = %0.4f" % mae(y_test, baseline_guess))
Tebakan dasar adalah skor 66,00
Kinerja Dasar pada set tes: MAE = 24.5164Kesalahan absolut rata-rata pada set tes adalah sekitar 25 poin. Karena kami mengevaluasi dalam kisaran dari 1 hingga 100, kesalahannya adalah 25% - penghalang yang agak rendah untuk model!
Kesimpulan
Anda di artikel ini, kami telah melalui tiga tahap pertama dalam menyelesaikan masalah menggunakan pembelajaran mesin. Setelah mengatur tugas, kami:
- Data mentah yang dihapus dan diformat.
- Melakukan analisis eksplorasi untuk mempelajari data yang tersedia.
- Kami mengembangkan serangkaian fitur yang akan kami gunakan untuk model kami.
, , .
Scikit-Learn , .