Topik pembicaraan hari ini adalah apa yang telah dipelajari Python selama bertahun-tahun keberadaannya dalam bekerja dengan gambar. Memang, selain oldies dari 1990 ImageMagick dan GraphicsMagick, ada perpustakaan modern yang efektif. Misalnya, Bantal dan Bantal-SIMD yang lebih produktif. Pengembang aktif mereka Alexander Karpinsky (
homm ) di MoscowPython membandingkan perpustakaan yang berbeda untuk bekerja dengan gambar dalam Python, menyajikan tolok ukur dan berbicara tentang fitur yang tidak jelas yang selalu cukup. Dalam artikel ini, transkrip laporan akan membantu Anda memilih perpustakaan untuk aplikasi Anda, dan membuatnya berfungsi seefisien mungkin.
Tentang pembicara: Alexander Karpinsky bekerja di
Uploadcare dan terlibat dalam layanan modifikasi gambar cepat dengan cepat. Dia terlibat dalam pengembangan
Pillow , perpustakaan populer untuk bekerja dengan gambar dengan Python, dan sedang mengembangkan garpu sendiri dari perpustakaan ini,
Pillow-SIMD , yang menggunakan instruksi prosesor modern untuk kinerja maksimal.
Latar belakang
Layanan modifikasi gambar Uploadcare adalah server yang menerima permintaan HTTP dengan pengenal gambar dan beberapa operasi yang perlu dilakukan klien. Server harus menyelesaikan operasi dan merespons secepat mungkin. Klien paling sering bertindak sebagai browser.
Seluruh layanan dapat digambarkan sebagai pembungkus di sekitar perpustakaan grafik. Kualitas keseluruhan proyek tergantung pada kualitas, kinerja, dan kegunaan perpustakaan grafis. Mudah ditebak bahwa Uploadcare menggunakan Bantal sebagai perpustakaan grafik.
Perpustakaan
Kami akan meninjau secara singkat perpustakaan grafis seperti apa yang secara umum menggunakan Python untuk lebih memahami apa yang akan dibahas nanti.
Bantal
Bantal - garpu PIL (Python Imaging Library). Ini adalah proyek yang sangat lama, dirilis pada 1995 untuk Python 1.2. Anda bisa bayangkan berapa usianya! Pada titik tertentu, Perpustakaan Pencitraan Python ditinggalkan dan pengembangannya terhenti. Garpu Bantal dibuat untuk menginstal dan membangun Perpustakaan Pencitraan Python pada sistem modern. Secara bertahap, jumlah perubahan yang dibutuhkan orang di Python Imaging Library tumbuh, dan Pillow 2.0 keluar, yang menambahkan dukungan untuk Python 3. Ini dapat dianggap sebagai awal dari kehidupan yang terpisah dari proyek Pillow.
Bantal adalah modul asli untuk Python, setengah dari kode ditulis dalam C, setengah dalam Python. Versi paling beragam dari Python didukung: 2.7, 3.3+, PP, .
Bantal-SIMD
Ini adalah fork of Pillow saya, yang keluar pada bulan Mei 2016. SIMD adalah singkatan dari Single Instruction, Multiple Data
- Suatu pendekatan di mana prosesor dapat melakukan jumlah tindakan yang lebih besar per siklus menggunakan instruksi modern.
Pillow-SIMD bukan garpu dalam arti klasik ketika sebuah proyek mulai menjalani hidupnya sendiri. Ini adalah pengganti Bantal, yaitu, Anda menginstal satu perpustakaan bukan yang lain, jangan mengubah baris dalam kode sumber Anda, dan mendapatkan lebih banyak kinerja.
Bantal-SIMD dapat dirakit dengan instruksi SSE4 (standar). Ini adalah serangkaian instruksi yang ditemukan di hampir semua prosesor x86 modern. Bantal-SIMD juga dapat dirakit dengan set instruksi AVX2. Serangkaian instruksi ini, dimulai dengan arsitektur Haswell, yaitu sekitar tahun 2013.
Opencv
Pustaka lain untuk bekerja dengan gambar dalam Python yang mungkin Anda pernah dengar adalah
OpenCV (Open Computer Vision). Ini telah bekerja sejak tahun 2000. Ikatan python disertakan. Ini berarti mengikat secara konstan relevan, tidak ada sinkronisasi antara perpustakaan itu sendiri dan mengikat.
Sayangnya, pustaka ini belum didukung di PyPy, karena OpenCV didasarkan pada numpy, dan numpy baru saja mulai bekerja di bawah PyPy, dan PyC belum mendukung OpenCV.
VIPS
Perpustakaan lain yang layak diperhatikan adalah VIPS. Gagasan utama
VIPS adalah Anda tidak perlu memuat seluruh gambar ke dalam memori untuk bekerja dengan gambar. Perpustakaan dapat memuat beberapa potongan kecil, memprosesnya dan menyimpan. Jadi, untuk memproses gambar gigapixel, Anda tidak perlu menghabiskan memori gigabyte.
Ini adalah perpustakaan yang agak tua - 1993, tetapi mengambil alih waktunya. Untuk waktu yang lama ada sedikit yang terdengar tentang hal itu, tetapi baru-baru ini untuk pengikat VIPS untuk berbagai bahasa mulai muncul, termasuk untuk Go, Node.js, Ruby.
Sudah lama saya ingin mencoba perpustakaan ini, merasakannya, tetapi saya tidak berhasil karena alasan yang sangat bodoh. Saya tidak tahu cara menginstal VIPS, karena pengikatannya sangat rumit. Tapi sekarang (pada 2017) pengikatan pyvips dirilis dari penulis VIPS itu sendiri, yang tidak ada masalah lagi. Menginstal dan menggunakan VIPS sekarang sangat mudah. Didukung: Python 2.7, 3.3+, RuPu, RuPuZ.
ImageMagick & GraphicsMagick
Jika kita berbicara tentang bekerja dengan grafik, maka kita tidak bisa tidak menyebutkan orang-orang tua -
ImageMagick dan perpustakaan
GraphicsMagick . Yang terakhir ini awalnya merupakan fork ImageMagick dengan kinerja yang lebih besar, tetapi sekarang kinerja mereka tampaknya sama. Sejauh yang saya tahu, tidak ada perbedaan mendasar di antara mereka. Karena itu, Anda dapat menggunakan salah satu, lebih tepatnya, yang Anda sukai.
Ini adalah perpustakaan tertua yang saya sebutkan hari ini (1990). Selama ini, ada beberapa binder untuk Python, dan hampir semuanya sudah mati sekarang. Dari mereka yang dapat digunakan, ada:
- Mengikat tongkat, yang dibangun di atas ctypes, tetapi juga tidak lagi diperbarui.
- Pengikatan pgmagick menggunakan Boost.Python, jadi ia mengkompilasi untuk waktu yang sangat lama dan tidak berfungsi di PyPy. Tetapi, bagaimanapun, Anda dapat menggunakannya, saya akan mengatakan bahwa itu lebih disukai daripada Wand.
Performa
Ketika kita berbicara tentang bekerja dengan gambar, hal pertama yang menarik minat kita (setidaknya bagi saya) adalah kinerja, karena kalau tidak kita bisa menulis sesuatu dengan Python dengan tangan kita.
Kinerja bukanlah hal yang sederhana. Anda tidak bisa mengatakan bahwa satu perpustakaan lebih cepat dari yang lain. Setiap perpustakaan memiliki serangkaian fungsi, dan setiap fungsi bekerja pada kecepatan yang berbeda.
Oleh karena itu, benar untuk mengatakan hanya bahwa kinerja satu fungsi lebih tinggi atau lebih rendah di perpustakaan tertentu. Atau Anda memiliki aplikasi yang memerlukan serangkaian fungsi tertentu, dan Anda membuat tolok ukur khusus untuk fungsi ini, dan mengatakan bahwa perpustakaan ini dan itu bekerja lebih cepat (lebih lambat) untuk aplikasi Anda.
Penting untuk memeriksa hasilnya.
Ketika Anda membuat tolok ukur, sangat penting untuk melihat hasil yang diperoleh. Bahkan jika pada pandangan pertama Anda menulis kode yang sama, ini tidak berarti bahwa itu sama.
Baru-baru ini, dalam sebuah artikel yang membandingkan kinerja Pillow dan OpenCV, saya menemukan kode ini:
from PIL import Image, ImageFilter.BoxBlur im.filter(ImageFilter.BoxBlur(3)) ... import cv2 cv2.blur(im, ksize=(3, 3)) ...
Tampaknya ada di sana, dan di sana, BoxBlur, dan di sana, dan di sana, argumen 3, tetapi pada kenyataannya hasilnya berbeda. Karena pada Pillow (3) ini adalah radius blur, dan dalam OpenCV ksize = (3, 3) adalah ukuran kernel, yaitu, secara garis besar, diameter. Dalam hal ini, nilai yang benar untuk OpenCV adalah 3 * 2 + 1, yaitu (7, 7).
Apa masalahnya?
Mengapa kinerja umumnya menjadi masalah saat bekerja dengan grafik? Karena kompleksitas dari setiap operasi tergantung pada beberapa parameter, dan paling sering kompleksitas tumbuh secara linear dengan masing-masing parameter. Dan jika, misalnya, ada tiga faktor ini, dan kompleksitas linear tergantung pada masing-masing, maka kompleksitas dalam kubus diperoleh.
Contoh: Gaussian blur di OpenCV.

Di sebelah kiri adalah jari-jari 3, di sebelah kanan adalah 30. Seperti yang Anda lihat, perbedaan dalam kecepatan lebih dari 10 kali.
Ketika saya menghadapi tugas menambahkan Gaussian blur ke aplikasi saya, saya tidak senang bahwa, secara hipotesis, 900 ms dapat dihabiskan untuk satu operasi. Ada ribuan operasi seperti itu per menit dalam aplikasi, dan menghabiskan begitu banyak waktu untuk satu itu tidak praktis. Oleh karena itu, saya mempelajari masalah ini dan mengimplementasikan Gaussian blur pada Pillow, yang bekerja dalam waktu konstan relatif terhadap jari-jari. Artinya, hanya ukuran gambar yang memengaruhi kinerja Gaussian blur.
Tetapi hal utama di sini bukanlah sesuatu bekerja lebih cepat atau lebih lambat.
Saya ingin menyampaikan bahwa ketika Anda sedang membangun semacam sistem, penting untuk memahami parameter apa yang bergantung pada kompleksitas output. Kemudian Anda dapat membatasi parameter ini atau dengan cara lain untuk mengatasi kompleksitas ini.
Mungkin operasi paling umum yang kita lakukan dengan gambar setelah dibuka adalah ukuran.
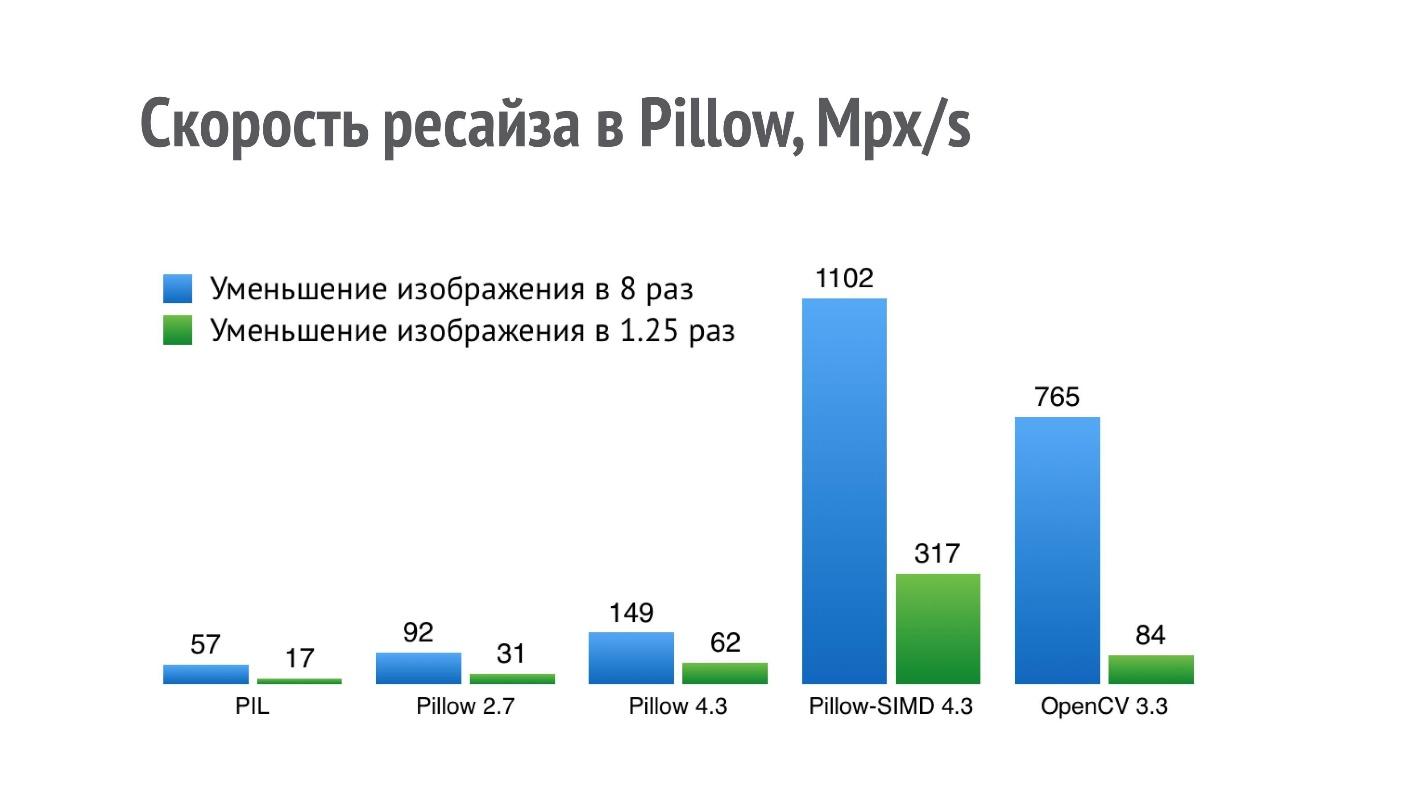
Grafik menunjukkan kinerja (lebih banyak lebih baik) dari berbagai pustaka untuk operasi pengurangan gambar sebanyak 8 dan 1,25 kali.
Untuk PIL, hasil dari 17 Mpx / s berarti bahwa foto dari iPhone (12 Mpx) dapat dikurangi 1,25 kali sedikit dalam waktu kurang dari satu detik. Performa seperti itu tidak cukup untuk aplikasi serius yang melakukan banyak operasi ini.
Saya mulai mengoptimalkan kinerja pengubahan ukuran, dan pada Pillow 2.7 saya berhasil mencapai peningkatan dua kali lipat dalam produktivitas, dan pada Pillow 4.3 - threefold (versi Pillow 5.3 saat ini relevan, tetapi kinerja pengubahan ukuran di dalamnya sama).
Tapi operasi pengubahan ukuran adalah hal yang sangat pas di SIMD. Ia mendekati instruksi tunggal, banyak data, dan oleh karena itu, dalam versi Pillow-SIMD saat ini, saya berhasil
meningkatkan kecepatan mengubah ukuran sebanyak 19 kali dibandingkan dengan Pustaka Pencitraan Python asli menggunakan sumber daya yang sama.
Ini jauh lebih tinggi daripada kinerja pengubahan ukuran OpenCV. Tetapi perbandingannya tidak sepenuhnya benar, karena OpenCV menggunakan metode pengubahan ukuran yang sedikit kurang berkualitas dengan filter kotak, dan pada Pillow-SIMD, pengubahan ukuran dilakukan menggunakan konvolusi.
Ini adalah daftar operasi yang tidak lengkap yang dipercepat dalam Bantal-SIMD dibandingkan dengan Bantal biasa.
- Ubah ukuran: 4 hingga 7 kali.
- Blur: 2,8 kali.
- Penerapan inti 3 × 3 atau 5 × 5: 11 kali.
- Perkalian dan pembagian dengan saluran alfa: 4 dan 10 kali.
- Komposisi alfa: 5 kali.
Saya telah mengatakan bahwa seseorang tidak dapat mengatakan bahwa beberapa perpustakaan bekerja lebih cepat daripada yang lain, tetapi Anda dapat membuat beberapa rangkaian operasi yang menarik bagi Anda. Saya memilih serangkaian operasi yang menarik dalam aplikasi saya, membuat tolok ukur dan mendapatkan hasil seperti itu.

Ternyata Pillow-SIMD pada set ini bekerja 2 kali lebih cepat dari Pillow. Pada akhirnya adalah Wand (ingat bahwa ini adalah ImageMagick).
Tapi saya tertarik pada sesuatu yang lain - mengapa OpenCV dan VIPS sangat buruk dalam hasil, karena ini adalah perpustakaan yang juga dirancang dengan maksud untuk kinerja? Ternyata dalam kasus OpenCV, rakitan OpenCV biner yang diinstal menggunakan pip dirakit dengan codec JPEG lambat (penulis rakitan diberitahu, masalah ini telah dipecahkan untuk 2018). Itu dibangun dengan libjpeg, sementara sebagian besar sistem, setidaknya berbasis debian, menggunakan libjpeg-turbo, yang beberapa kali lebih cepat. Jika Anda membuat OpenCV sendiri dari sumbernya, maka kinerjanya akan lebih besar.
Dalam kasus VIPS, situasinya berbeda. Saya menghubungi penulis VIPS, menunjukkan kepadanya tolok ukur ini, dan kami berkorespondensi untuk waktu yang lama dan membuahkan hasil. Setelah itu, penulis VIPS menemukan beberapa tempat di VIPS itu sendiri, di mana eksekusi tidak pada rute yang optimal, dan memperbaikinya.
Itulah yang akan terjadi pada kinerja jika Anda membangun OpenCV dari sumber versi saat ini, dan VIPS dari master, yang sudah ada di sana.
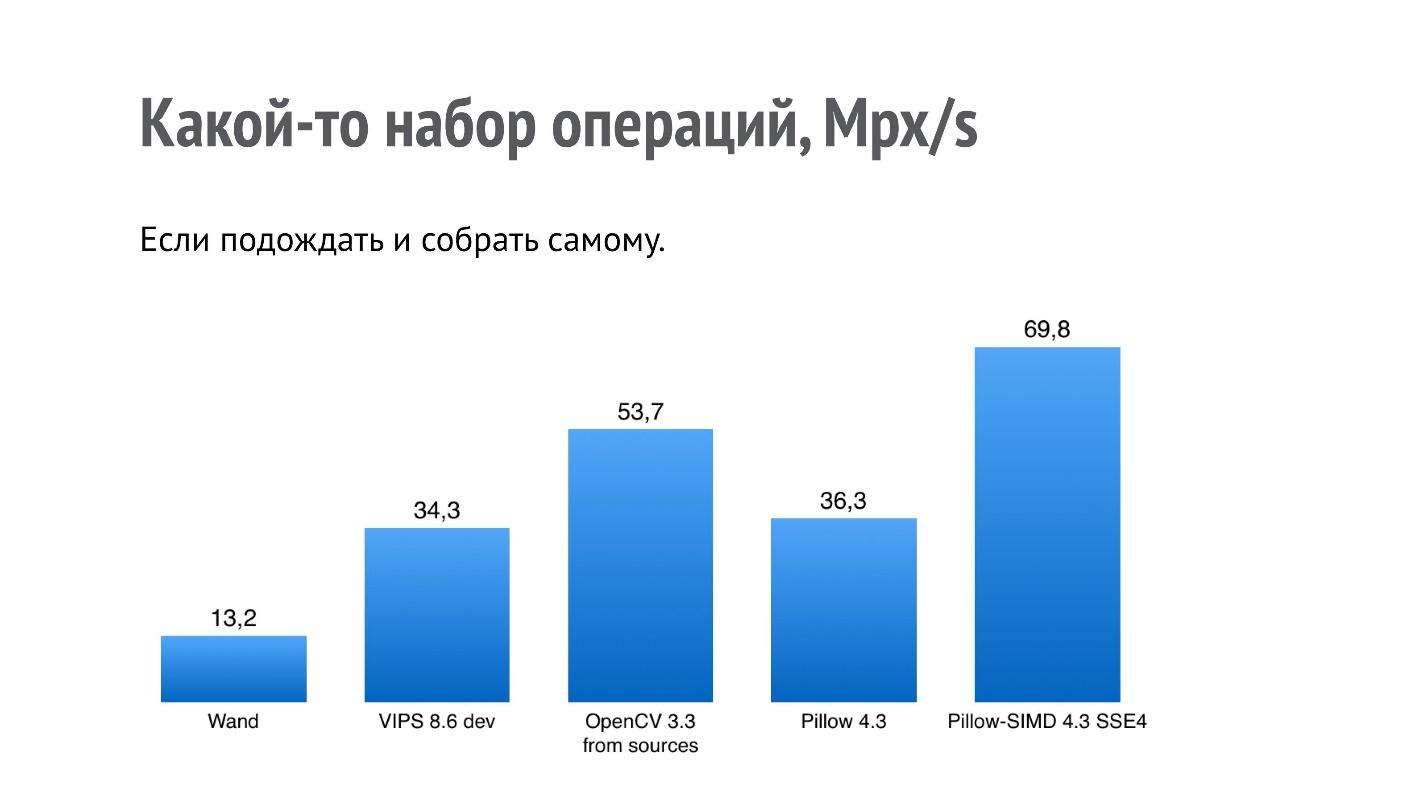
Bahkan jika Anda menemukan semacam tolok ukur, itu bukan fakta bahwa semuanya akan bekerja dengan kecepatan ini persis di mesin Anda.
Set tolok ukur
Semua tolok ukur yang saya bicarakan dapat ditemukan di
halaman hasil . Ini adalah proyek kecil yang terpisah di mana saya menulis tolok ukur yang saya sendiri perlu kembangkan sebagai Pillow-SIMD, menjalankannya dan memposting hasilnya.
GitHub memiliki
proyek dengan kerangka kerja pengujian di mana setiap orang dapat menawarkan tolok ukur sendiri atau memperbaiki yang sudah ada.
Pekerjaan paralel
Sejauh ini saya telah berbicara tentang kinerja murni, yaitu, pada inti prosesor tunggal. Tapi kita semua sudah lama memiliki akses ke sistem dengan core lebih banyak, dan saya ingin membuangnya. Di sini saya harus mengatakan bahwa sebenarnya Bantal adalah satu-satunya perpustakaan dari semua yang tidak menggunakan paralelisasi tugas. Saya akan mencoba menjelaskan mengapa ini terjadi. Semua perpustakaan lain dalam satu bentuk atau yang lain menggunakannya.
Metrik kinerja
Dalam hal kinerja, kami tertarik pada 2 parameter:
- Real time pelaksanaan satu operasi. Ada operasi (atau urutan operasi), dan Anda bertanya-tanya kapan waktu sebenarnya (jam dinding) urutan ini akan dieksekusi. Parameter ini penting di desktop, di mana ada pengguna yang memberi perintah dan menunggu hasilnya.
- Throughput seluruh sistem (alur kerja). Ketika Anda memiliki serangkaian operasi yang sedang berlangsung, atau banyak operasi independen, dan kecepatan pemrosesan operasi ini pada perangkat keras Anda penting bagi Anda. Metrik ini lebih penting pada server di mana ada banyak klien, dan Anda harus melayani mereka semua. Waktu yang diperlukan untuk melayani satu klien penting, tentu saja, tetapi sedikit kurang dari total bandwidth.
Berdasarkan dua metrik ini, kami mempertimbangkan berbagai cara operasi paralel.
Metode Kerja Paralel
1.
Pada level aplikasi , ketika Anda memutuskan pada level aplikasi bahwa operasi diproses dalam utas yang berbeda. Pada saat yang sama, waktu eksekusi aktual dari satu operasi tidak berubah, karena seperti sebelumnya, satu inti terlibat dalam satu urutan operasi. Kapasitas sistem meningkat secara proporsional dengan jumlah inti, yaitu sangat baik.
2.
Pada tingkat operasi grafis - itulah yang sebenarnya ada di sebagian besar perpustakaan grafis. Ketika pustaka grafis menerima beberapa jenis operasi, ia menciptakan jumlah utas yang diperlukan di dalamnya, membagi satu operasi menjadi beberapa yang lebih kecil, dan menjalankannya. Pada saat yang sama, waktu eksekusi aktual berkurang - satu operasi lebih cepat. Tetapi
throughput tidak tumbuh secara linear dengan jumlah core. Ada operasi yang tidak paralel, dan contoh yang mencolok adalah decoding file PNG - tidak dapat diparalelkan dengan cara apa pun. Selain itu, ada overhead untuk membuat utas, tugas pemisahan, yang juga tidak memungkinkan bandwidth tumbuh secara linear.
3.
Pada tingkat perintah dan data prosesor . Kami menyiapkan data dengan cara khusus dan menggunakan perintah khusus untuk membuat prosesor bekerja lebih cepat. Ini adalah pendekatan SIMD, yang, pada kenyataannya, digunakan dalam Pillow-SIMD. Waktu runtime real-time menurun, throughput meningkat -
ini adalah
opsi win-win .
Cara menggabungkan kerja paralel
Jika kita ingin menggabungkan kerja paralel, maka SIMD bekerja dengan baik dengan paralelisasi di dalam operasi, dan SIMD bekerja dengan baik dengan paralelisasi di dalam suatu aplikasi.

Tetapi paralelisasi di dalam aplikasi dan di dalam operasi tidak kompatibel satu sama lain. Jika Anda mencoba melakukan ini, Anda akan mendapatkan kontra dari kedua pendekatan. Waktu operasi yang sebenarnya akan sama seperti pada satu inti, dan throughput sistem akan meningkat, tetapi tidak secara linier berkenaan dengan jumlah core.
Multithreading
Jika kita berbicara tentang utas, kita semua menulis dalam Python dan tahu bahwa ia memiliki GIL yang mencegah dua utas berjalan pada saat yang sama. Python adalah bahasa yang sangat berurutan tunggal.
Tentu saja, ini tidak benar, karena GIL sebenarnya mencegah dua utas dari mengeksekusi di Python, dan jika kode ditulis dalam bahasa lain dan tidak menggunakan struktur internal Python selama operasinya, kode ini dapat melepaskan GIL dan dengan demikian membebaskan penerjemah untuk tugas-tugas lain.
Banyak perpustakaan grafis merilis GIL selama bekerja, termasuk Pillow, OpenCV, pyvips, Wand. Hanya satu pgmagick yang tidak gratis. Artinya, Anda dapat dengan aman membuat utas untuk melakukan beberapa operasi, dan ini akan bekerja secara paralel dengan sisa kode.
Tetapi muncul pertanyaan:
berapa banyak utas yang harus dibuat?Jika kita membuat jumlah utas yang tak terbatas untuk setiap tugas yang kita miliki, maka mereka hanya mengambil semua memori dan seluruh prosesor - kita tidak akan mendapatkan pekerjaan yang efektif. Saya merumuskan aturan khusus.
Aturan N +1
Untuk pekerjaan produktif, Anda harus membuat tidak lebih dari N + 1 pekerja, di mana N adalah jumlah inti atau benang prosesor pada mesin, dan pekerja adalah proses atau benang yang terlibat dalam pemrosesan.
Proses paling baik digunakan, karena bahkan dalam juru bahasa yang sama ada hambatan dan overhead.
Sebagai contoh, dalam aplikasi kita, N + 1 instance Tornado digunakan, keseimbangan di antaranya dilakukan oleh ngnix. Jika Tornado disebutkan, maka mari kita bicara tentang operasi asinkron.
Operasi asinkron
Waktu dimana pustaka grafis benar-benar berguna - pemrosesan gambar - dapat dan harus digunakan untuk input / output, jika Anda memilikinya dalam aplikasi. Kerangka kerja asinkron sangat relevan di sini.
Tetapi ada masalah - ketika kita memanggil semacam pemrosesan, itu disebut secara sinkron. Bahkan jika perpustakaan merilis GIL pada saat itu, Perulangan Kejadian masih diblokir.
@gen.coroutine def get(self, *args, **kwargs): im = process_image(...) ...
Untungnya, masalah ini sangat mudah dipecahkan dengan membuat ThreadPoolExecutor dengan satu utas di mana pemrosesan gambar dimulai. Panggilan ini sudah terjadi secara tidak sinkron.
@run_on_executor(executor=ThreadPoolExecutor(1)) def process_image(self, ... @gen.coroutine def get(self, *args, **kwargs): im = yield process_image(...) ...
Intinya, antrian dengan satu pekerja dibuat di sini yang melakukan operasi grafis, dan Peristiwa Peristiwa tidak diblokir dan berjalan diam-diam secara paralel di utas lainnya.
Input / output
Topik lain yang ingin saya bahas dalam diskusi operasi grafis adalah input / output. Faktanya adalah bahwa kita jarang membuat gambar apa pun menggunakan pustaka grafis. Paling sering, kami membuka gambar yang datang kepada kami dari pengguna dalam bentuk file yang disandikan (JPEG, PNG, BMP, TIFF, dll.).
Dengan demikian, pustaka grafis untuk membangun aplikasi yang baik harus memiliki beberapa barang untuk input / output dari file.
Pemuatan malas
Roti seperti itu adalah pemuatan malas. Jika, misalnya, di Bantal Anda membuka gambar, maka pada saat ini penguraian gambar tidak terjadi. Anda dikembalikan dengan objek yang tampak seolah-olah gambar sudah dimuat dan berfungsi. Anda dapat melihat propertinya dan memutuskan berdasarkan pada properti dari gambar ini apakah Anda siap untuk bekerja dengannya lebih jauh, jika pengguna telah mengunduh, misalnya, gambar gigapixel untuk memutuskan layanan Anda.
>>> from PIL import Image >>> %time im = Image.open() Wall time: 1.2 ms >>> im.mode, im.size ('RGB', (2152, 1345))
Jika Anda memutuskan apa yang harus dilakukan selanjutnya, kemudian menggunakan panggilan eksplisit atau implisit untuk memuat, gambar ini diterjemahkan. Sudah pada saat ini jumlah memori yang diperlukan dialokasikan.
>>> from PIL import Image >>> %time im = Image.open() Wall time: 1.2 ms >>> im.mode, im.size ('RGB', (2152, 1345)) >>> %time im.load() Wall time: 73.6 ms
Mode gambar rusak
Sanggul kedua yang diperlukan saat bekerja dengan konten buatan pengguna adalah mode gambar rusak. File yang kami terima dari pengguna sangat sering mengandung beberapa inkonsistensi dengan format di mana mereka dikodekan.
Perbedaan ini terjadi karena berbagai alasan. Terkadang ini adalah kesalahan transmisi melalui jaringan, kadang-kadang itu hanya semacam codec bengkok yang menyandikan gambar. Secara default, Pillow, ketika melihat gambar yang tidak sesuai dengan format sampai akhir, hanya melempar pengecualian.
from PIL import Image Image.open('trucated.jpg').save('trucated.out.jpg') IOError: image file is truncated (143 bytes not processed)
Tetapi pengguna tidak bisa disalahkan karena fakta bahwa fotonya rusak, ia masih ingin mendapatkan hasilnya. Untungnya, Bantal memiliki mode gambar yang rusak. Kami mengubah satu pengaturan, dan Pillow mencoba mengabaikan hingga maksimum semua kesalahan pengodean yang ada dalam gambar. Dengan demikian, pengguna melihat setidaknya sesuatu.
from PIL import Image, ImageFile ImageFile.LOAD_TRUNCATED_IMAGES = True Image.open('trucated.jpg').save('trucated.out.jpg')

Bahkan gambar yang dipangkas masih lebih baik daripada tidak sama sekali - hanya halaman dengan kesalahan.
Tabel ringkasan
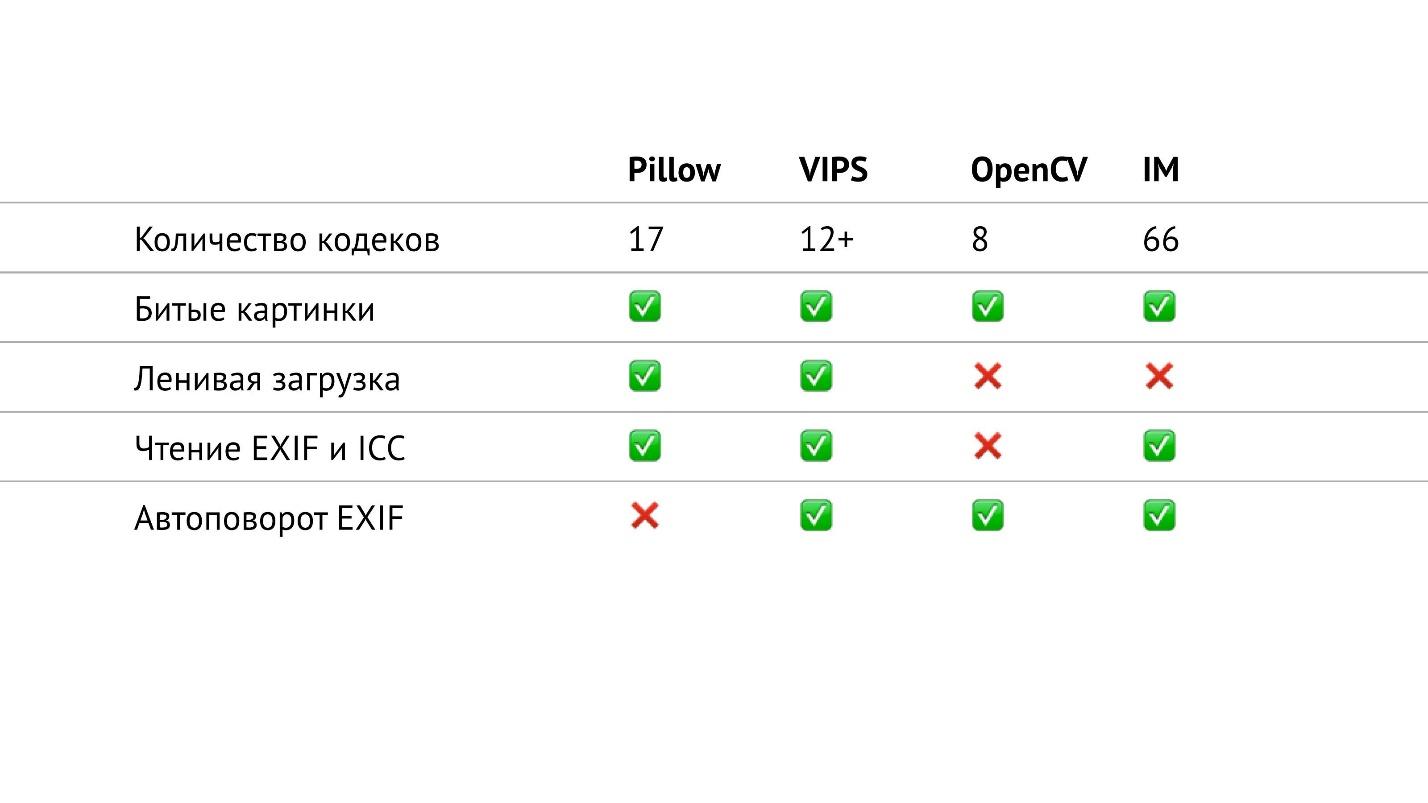
Dalam tabel di atas, saya telah mengumpulkan semua yang berhubungan dengan input / output di perpustakaan yang saya bicarakan. Secara khusus, saya menghitung jumlah codec dari berbagai format yang ada di perpustakaan. Ternyata di OpenCV mereka yang paling sedikit, di ImageMagick - paling banyak. Tampaknya di ImageMagick Anda dapat membuka semua gambar yang Anda temui. VIPS memiliki 12 codec asli, tetapi VIPS dapat menggunakan ImageMagick sebagai perantara. Saya belum menguji cara kerjanya, semoga mulus.
Bantal memiliki 17 codec. Sekarang ini adalah satu-satunya pustaka yang tidak ada putar otomatis EXIF. Tetapi sekarang ini adalah masalah kecil, karena Anda dapat membaca EXIF sendiri dan memutar gambar sesuai dengannya. Ini adalah pertanyaan tentang cuplikan kecil, yang dengan mudah google dan membutuhkan maksimal 20 baris.
Fitur-fitur dari OpenCV
Jika Anda melihat tabel ini dengan seksama, Anda dapat melihatnya di OpenCV, pada kenyataannya, tidak semuanya baik dengan input / output. Ini memiliki jumlah codec paling sedikit, tidak ada pemuatan malas, dan Anda tidak dapat membaca EXIF dan profil warna.
Tapi itu belum semuanya. Faktanya, OpenCV memiliki lebih banyak fitur. Ketika kita hanya membuka gambar,
cv2.imread(filename) memutar file JPEG sesuai dengan EXIF (lihat tabel), tetapi mengabaikan saluran alfa file PNG - perilaku yang agak aneh!
Untungnya, OpenCV memiliki flag:
cv2.imread(filename, flags=cv2.IMREAD_UNCHANGED) .
Jika Anda menentukan flag IMREAD_UNCHANGED, maka OpenCV meninggalkan saluran alpha untuk file PNG, tetapi berhenti memutar file JPEG sesuai dengan EXIF. Artinya, bendera yang sama mempengaruhi dua properti yang sama sekali berbeda. Seperti dapat dilihat dari tabel, OpenCV tidak memiliki kemampuan untuk membaca EXIF, dan ternyata dalam kasus flag ini tidak mungkin untuk memutar JPEG sama sekali.
Bagaimana jika Anda tidak tahu sebelumnya apa format gambar Anda dan Anda perlu saluran alpha untuk PNG dan auto-rotate untuk JPEG? Tidak ada hubungannya - OpenCV tidak berfungsi seperti itu.
Alasan mengapa OpenCV memiliki masalah seperti itu terletak pada nama perpustakaan ini. Ini memiliki banyak fungsi untuk visi komputer dan analisis gambar. Faktanya, OpenCV dirancang untuk bekerja dengan sumber yang diverifikasi. Ini adalah, misalnya, kamera pengintai luar ruang yang mengambil gambar satu detik sekali dan melakukan ini selama 5 tahun dalam format yang sama dan resolusi yang sama. Tidak perlu variabilitas dalam masalah I / O.
Orang yang membutuhkan fungsionalitas OpenCV tidak benar-benar membutuhkan fungsionalitas konten pengguna.
Tetapi bagaimana jika aplikasi Anda masih membutuhkan fungsionalitas untuk bekerja dengan konten pengguna, dan pada saat yang sama Anda membutuhkan semua kekuatan OpenCV untuk pemrosesan dan statistik?

Solusinya adalah menggabungkan perpustakaan. Faktanya adalah bahwa OpenCV dibangun berdasarkan numpy, dan Pillow memiliki semua sarana untuk mengekspor gambar dari Pillow ke array numpy. Artinya, kami mengekspor array numpy, dan OpenCV dapat terus bekerja dengan gambar ini, seperti miliknya sendiri. Ini dilakukan dengan sangat mudah:
import numpy from PIL import Image ... pillow_image = Image.open(filename) cv_image = numpy.array(pillow_image)
Lebih lanjut, ketika kita melakukan sihir menggunakan OpenCV (pemrosesan), kita memanggil metode Bantal lain dan mengimpor gambar dari OpenCV kembali ke format Bantal. Dengan demikian, I / O dapat digunakan kembali.
import numpy from PIL import Image ... pillow_image = Image.fromarray(cv_image, "RGB") pillow_image.save(filename)
Jadi, ternyata kami menggunakan input / output dari Pillow, dan pemrosesan dari OpenCV, yaitu, kami mengambil yang terbaik dari dua dunia.
Semoga ini membantu Anda membangun aplikasi grafis yang dimuat.
Anda dapat mempelajari beberapa rahasia pengembangan lainnya dengan Python, belajar dari pengalaman yang tak ternilai dan terkadang tak terduga, dan yang paling penting, Anda dapat mendiskusikan tugas Anda segera di Moscow Python Conf ++ . Misalnya, perhatikan nama dan topik tersebut dalam jadwal.
- Donald Whyte dengan sebuah cerita tentang bagaimana membuat matematika 10 kali lebih cepat menggunakan perpustakaan populer, trik dan kelicikan, dan kodenya dapat dimengerti dan didukung.
- Andrei Popov adalah tentang mengumpulkan sejumlah besar data dan menganalisisnya untuk ancaman.
- Ephraim Matosyan dalam laporannya "Make Python fast again" akan memberi tahu Anda cara meningkatkan kinerja daemon yang memproses pesan dari bus.
Daftar lengkap apa yang akan dibahas pada 22 dan 23 Oktober di sini , punya waktu untuk bergabung.