Esensi
Ternyata untuk ini cukup menjalankan seperangkat perintah:
git clone https://github.com/attardi/wikiextractor.git cd wikiextractor wget http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 python3 WikiExtractor.py -o ../data/wiki/ --no-templates --processes 8 ../data/ruwiki-latest-pages-articles.xml.bz2
dan kemudian memoles sedikit dengan skrip untuk pemrosesan pasca
python3 process_wikipedia.py
Hasilnya adalah file .csv selesai dengan tubuh Anda.
Jelas bahwa:
http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 dapat diubah ke bahasa yang Anda butuhkan, lebih detail di sini [4] ;- Semua informasi tentang parameter
wikiextractor dapat ditemukan di manual (sepertinya bahkan dock resmi belum diperbarui, tidak seperti mana);
Skrip pasca pemrosesan mengonversi file wiki ke tabel seperti ini:
| idx | article_uuid | hukuman | kalimat dibersihkan | panjang kalimat dibersihkan |
|---|
| 0 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean I de Chatillon (Count de Pentevre) Jean I de ... | jean i de châtillon menghitung de pentevre jean i de cha ... | 38 |
| 1 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Di bawah perlindungan Robert de Vera, Count O ... | dijaga oleh robert de vera graph oxford ... | 18 |
| 2 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Namun, Henry de Gromont, ... | Namun, Henry de Gromon gras menentang ini ... | 14 |
| 3 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Raja menawarinya fitur penting lainnya sebagai seorang istri ... | raja menawari istrinya satu lagi orang penting ... | 48 |
| 4 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean dibebaskan dan kembali ke Prancis pada 138 ... | Jean dibebaskan kembali perancis tahun ... | 52 |
article_uuid - kunci pseudo-unik, urutan ide harus dipertahankan setelah pra-pemrosesan tersebut.
Mengapa
Mungkin, saat ini, pengembangan alat-ML telah mencapai tingkat [8] sehingga beberapa hari sudah cukup untuk membangun model / pipa NLP yang berfungsi. Masalah muncul hanya dengan tidak adanya dataset yang dapat diandalkan / embeddings siap / model bahasa siap. Tujuan artikel ini adalah sedikit meredakan rasa sakit Anda dengan menunjukkan bahwa beberapa jam sudah cukup untuk memproses seluruh Wikipedia (secara teori, korpus paling populer untuk melatih kata embeddings dalam NLP). Lagi pula, jika beberapa hari sudah cukup untuk membangun model sederhana, mengapa menghabiskan lebih banyak waktu untuk mendapatkan data untuk model ini?
Prinsip naskah
wikiExtractor menyimpan artikel Wiki sebagai teks yang dipisahkan oleh blok <doc> . Sebenarnya, skrip didasarkan pada logika berikut:
- Ambil daftar semua file dalam output;
- Kami membagi file menjadi artikel;
- Hapus semua tag HTML dan karakter khusus yang tersisa;
- Menggunakan
nltk.sent_tokenize membaginya menjadi kalimat; - Agar kode tidak tumbuh ke ukuran yang sangat besar dan tetap dapat dibaca, setiap artikel diberikan uuid sendiri;
Sebagai preprocessing teks, ini sederhana (Anda dapat dengan mudah memotongnya sendiri):
- Hapus karakter bukan huruf;
- Hapus kata-kata berhenti;
Dataset, bagaimana sekarang?
Aplikasi utama
Paling sering dalam prakteknya di NLP kita harus berurusan dengan tugas membangun embeddings.
Untuk mengatasinya, biasanya gunakan salah satu alat berikut:
- Vektor / embeddings kata yang sudah jadi [6];
- Keadaan internal CNN dilatih pada tugas-tugas seperti menentukan kalimat palsu / pemodelan bahasa / klasifikasi [7];
- Kombinasi metode di atas;
Selain itu, telah diperlihatkan berkali-kali [9] bahwa sebagai dasar yang baik untuk menanamkan kalimat, seseorang juga dapat mengambil hanya rata-rata (dengan beberapa detail kecil, yang akan kita hilangkan sekarang) vektor kata.
Kasus penggunaan lainnya
- Kami menggunakan kalimat acak dari Wiki sebagai contoh negatif untuk kehilangan triplet;
- Kami melatih pembuat enkode untuk kalimat menggunakan definisi frase palsu [10];
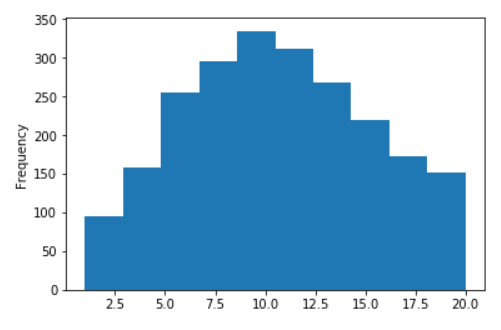
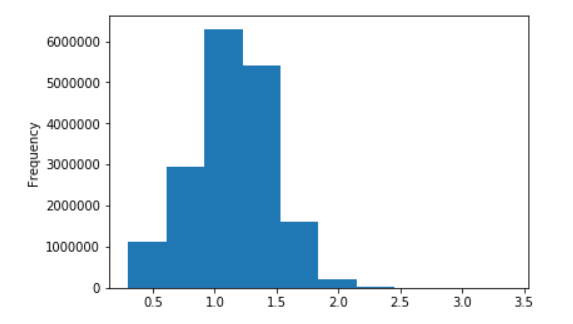
Beberapa grafik untuk Wiki Rusia
Distribusi panjang kalimat untuk Wikipedia bahasa Rusia
Tidak ada logaritma (pada sumbu X, nilai dibatasi hingga 20)
Dalam logaritma desimal
Referensi
- Vektor kata teks cepat dilatih pada wiki;
- Model teks-cepat dan Word2Vec untuk bahasa Rusia;
- Perpustakaan wiki extractor yang mengagumkan untuk python;
- Halaman resmi dengan tautan untuk Wiki;
- Script kami untuk post-processing;
- Artikel utama tentang embeddings kata: Word2Vec , Fast-Text , tuning ;
- Beberapa pendekatan SOTA saat ini:
- InferSent ;
- CNN pra-pelatihan generatif;
- ULMFiT ;
- Pendekatan kontekstual untuk representasi kata - kata (Elmo);
- Momen imagenet di NLP ?
- Baseline untuk menyematkan proposal 1 , 2 , 3 , 4 ;
- Definisi frasa palsu untuk enkoder tawaran;