Saya menyajikan kepada Anda bagian kedua dari artikel tentang pencarian dugaan penipuan berdasarkan data dari Enron Dataset. Jika Anda belum membaca bagian pertama, Anda dapat membiasakan diri dengannya di sini .
Sekarang kita akan berbicara tentang proses membangun, mengoptimalkan dan memilih model yang akan memberikan jawaban: apakah layak mencurigai seseorang yang melakukan penipuan?
Sebelumnya, kami menganalisis salah satu kumpulan data terbuka yang memberikan informasi tentang tersangka dalam kasus Enron dan penipuan di dalamnya. Juga, bias dalam data awal dikoreksi, kesenjangan (NaN) diisi, setelah itu data dinormalisasi dan pemilihan atribut selesai.
Hasilnya akrab bagi banyak orang:
- X_train dan y_train - sampel yang digunakan untuk pelatihan (111 catatan);
- X_test dan y_test - sampel di mana kebenaran prediksi model kami akan diperiksa (28 entri).
Berbicara tentang model ... Untuk memprediksi dengan benar apakah layak mencurigai seseorang, berdasarkan beberapa tanda yang mencirikan kegiatannya, kami akan menggunakan klasifikasi. Jenis utama model yang digunakan untuk menyelesaikan masalah di segmen ini dapat diambil dari Sklearn:
- Naif Bayes (pengklasifikasi naif Bayes);
- SVM (mesin vektor referensi);
- K-tetangga terdekat (metode untuk menemukan tetangga terdekat);
- Hutan Acak (hutan acak);
- Jaringan Saraf Tiruan.
Ada juga gambar yang menggambarkan penerapannya dengan cukup baik:
Di antara mereka ada Decision Tree (pohon keputusan), yang akrab bagi banyak orang, tetapi, mungkin, tidak masuk akal dalam satu tugas untuk menggunakan metode ini bersama dengan Random Forest, yang merupakan ensemble dari pohon keputusan. Oleh karena itu, ganti dengan Regresi Logistik, yang dapat bertindak sebagai penggolong dan menghasilkan salah satu opsi yang diharapkan (0 atau 1).
Mulai
Kami menginisialisasi semua pengklasifikasi yang disebutkan dengan nilai default:
from sklearn.naive_bayes import GaussianNB from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from sklearn.neural_network import MLPClassifier from sklearn.ensemble import RandomForestClassifier random_state = 42 gnb = GaussianNB() svc = SVC() knn = KNeighborsClassifier() log = LogisticRegression(random_state=random_state) rfc = RandomForestClassifier(random_state=random_state) mlp = MLPClassifier(random_state=random_state)
Kami juga akan mengelompokkan mereka sehingga lebih nyaman untuk bekerja dengan mereka sebagai satu set, daripada menulis kode untuk setiap individu. Misalnya, kita bisa melatih semuanya sekaligus:
classifiers = [gnb, svc, knn, log, rfc, mlp] for clf in classifiers: clf.fit(X_train, y_train)
Setelah model dilatih, tiba saatnya untuk uji pertama kualitas prediksi mereka. Selain itu, kami memvisualisasikan hasil kami menggunakan Seaborn:
from sklearn.metrics import accuracy_score def calculate_accuracy(X, y): result = pd.DataFrame(columns=['classifier', 'accuracy']) for clf in classifiers: predicted = clf.predict(X_test) accuracy = round(100.0 * accuracy_score(y_test, predicted), 2) classifier = clf.__class__.__name__ classifier = classifier.replace('Classifier', '') result = result.append({'classifier': classifier, 'accuracy': accuracy}, ignore_index=True) print('Accuracy is {accuracy}% for {classifier_name}'.format(accuracy=accuracy, classifier_name=classifier)) result = result.sort_values(['classifier'], ascending=True) plt.subplots(figsize=(10, 7)) sns.barplot(x="classifier", y='accuracy', palette=cmap, data=result)
Mari kita lihat gagasan umum tentang keakuratan pengklasifikasi:
calculate_accuracy(X_train, y_train)
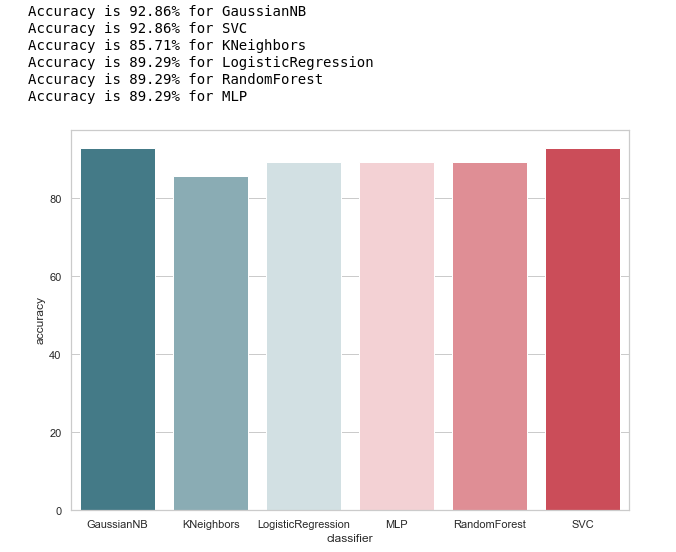
Sekilas, tampilannya cukup bagus, keakuratan prediksi sampel uji berfluktuasi sekitar 90%. Tampaknya tugasnya brilian!
Bahkan, tidak semuanya begitu cerah.Akurasi tinggi bukanlah jaminan prediksi yang benar. Sampel uji kami memiliki 28 catatan, 4 di antaranya terkait dengan tersangka, dan 24 untuk mereka yang berada di luar dugaan. Bayangkan kami membuat beberapa bentuk algoritma dari bentuk:
def QuaziAlgo(features): return 0
Kemudian mereka memberikan sampel tes kami di pintu masuk, dan mereka menerima bahwa semua 28 orang tidak bersalah. Apa yang akan menjadi akurasi dari algoritma dalam kasus ini?
Menariknya, KNeighbors memiliki akurasi prediksi yang sama ...
Tapi tetap saja, sebelum menyanjung diri kita sendiri, mari kita buat matriks kebingungan untuk hasil prediksi:
from sklearn.metrics import confusion_matrix def make_confussion_matrices(X, y): matrices = {} result = pd.DataFrame(columns=['classifier', 'recall']) for clf in classifiers: classifier = clf.__class__.__name__ classifier = classifier.replace('Classifier', '') predicted = clf.predict(X_test) print(f'{predicted}-{classifier}') matrix = confusion_matrix(y_test,predicted,labels=[1,0]) matrices[classifier] = matrix.T return matrices
Kami menghitung matriks kesalahan untuk setiap classifier dan, bersama dengan ini, lihat apa yang mereka prediksi:
matrices = make_confussion_matrices(X_train,y_train)

Bahkan representasi tekstual dari hasil karya pengklasifikasi sudah cukup untuk memahami bahwa ada sesuatu yang salah.
Metode tetangga terdekat tidak mengungkapkan satu pun tersangka dalam sampel uji sama sekali. Dua pertanyaan muncul:
- Apa alasan perilaku pengklasifikasi KNeighbors ini?
- Mengapa kita membuat matriks kesalahan jika kita tidak menggunakannya, tetapi lihat saja hasil prediksi?
Lihatlah lebih dalam
Mari kita mulai dengan pertanyaan kedua. Mari kita coba memvisualisasikan matriks kesalahan kita dan menyajikan data dalam format grafis untuk memahami di mana kesalahan klasifikasi terjadi:
import itertools from collections import Iterable def draw_confussion_matrices(row,col,matrices,figsize = (16,12)): fig, (axes) = plt.subplots(row,col, sharex='col', sharey='row',figsize=figsize ) if any(isinstance(i, Iterable) for i in axes): axes = list(itertools.chain.from_iterable(axes)) idx = 0 for name,matrix in matrices.items(): df_cm = pd.DataFrame( matrix, index=['True','False'], columns=['True','False'], ) ax = axes[idx] fig.subplots_adjust(wspace=0.1) sns.heatmap(df_cm, annot=True,cmap=cmap,cbar=False ,fmt="d",ax=ax,linewidths=1) ax.set_title(name) idx += 1
Kami menampilkannya dalam 2 baris dan 3 kolom:
draw_confussion_matrices(2,3,matrices)
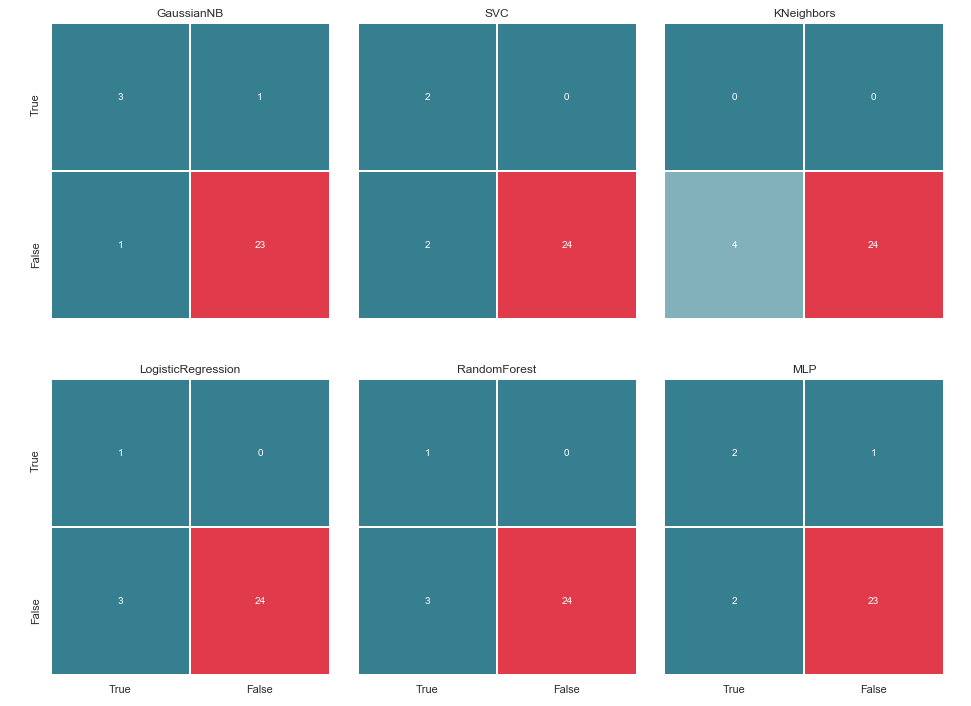
Sebelum melanjutkan, ada baiknya memberikan beberapa klarifikasi. Penunjukan Benar, yang terletak di sebelah kiri matriks kesalahan dari penggolong tertentu, berarti bahwa penggolong menganggap orang itu tersangka, nilai Salah berarti bahwa orang itu berada di luar kecurigaan. Demikian pula, Benar dan Salah di bagian bawah gambar memberi kita keadaan nyata, yang mungkin tidak sesuai dengan keputusan pengklasifikasi.
Sebagai contoh, kita melihat bahwa keputusan KNeighbors dengan akurasi prediksi 85,71% bertepatan dengan situasi nyata ketika 24 orang, yang tidak dicurigai, dimasukkan dalam daftar yang sama oleh pengklasifikasi. Tetapi 4 orang dari daftar tersangka juga termasuk dalam daftar ini. Jika pengklasifikasi ini membuat keputusan, mungkin seseorang dapat menghindari pengadilan.
Dengan demikian, matriks kesalahan adalah alat yang sangat baik untuk memahami apa yang salah dengan masalah klasifikasi. Keuntungan utama mereka adalah visibilitas, dan oleh karena itu kami menarik bagi mereka.
Metrik
Secara umum, ini dapat diilustrasikan oleh gambar berikut:

Dan apa TP, TN, FP dan beberapa jenis FN dalam kasus ini?
Dengan kata lain, kami berusaha untuk memastikan bahwa jawaban dari pengklasifikasi dan keadaan sebenarnya sesuai. Artinya, untuk memastikan bahwa semua angka didistribusikan antara sel TP dan TN (solusi sejati) dan tidak jatuh ke FN dan FP (solusi palsu).
tidak selalu semuanya begitu dramatis dan tidak ambiguMisalnya, dalam kasus kanonik dengan diagnosis kanker, FP lebih disukai daripada FN, karena dalam kasus vonis palsu pada kanker, pasien akan diberi resep obat dan akan dirawat. Ya, itu akan memengaruhi kesehatan dan dompetnya, tetapi tetap saja dianggap lebih berbahaya daripada FN dan periode yang terlewat di mana kanker dapat dikalahkan dengan cara kecil.
Bagaimana dengan para tersangka dalam kasus kami? FN mungkin tidak seburuk FP. Tetapi lebih lanjut tentang itu nanti ...
Dan karena kita berbicara tentang singkatan, sekarang saatnya untuk mengingat metrik akurasi (Presisi) dan kelengkapan (Ingat).
Jika Anda berangkat dari catatan resmi, maka Precision dapat dinyatakan sebagai:
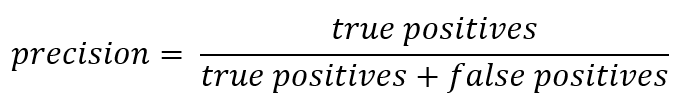
Dengan kata lain, akun menyimpan berapa banyak tanggapan positif yang diterima dari pengklasifikasi yang benar. Semakin besar akurasinya, semakin sedikit jumlah klik salah (akurasinya adalah 1 jika tidak ada FP).
Recall umumnya disajikan sebagai:
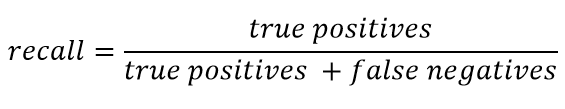
Ingat karakteristik kemampuan classifier untuk "menebak" sebanyak mungkin jawaban positif. Semakin tinggi kelengkapannya, semakin rendah FN.
Biasanya mereka mencoba menyeimbangkan antara keduanya, tetapi dalam hal ini prioritas akan sepenuhnya diberikan kepada Precision. Alasannya: pendekatan yang lebih humanistik, keinginan untuk meminimalkan jumlah positif palsu dan, sebagai akibatnya, untuk menghindari kecurigaan yang jatuh pada orang yang tidak bersalah.
Kami menghitung Presisi untuk pengklasifikasi kami:
from sklearn.metrics import precision_score def calculate_precision(X, y): result = pd.DataFrame(columns=['classifier', 'precision']) for clf in classifiers: predicted = clf.predict(X_test) precision = precision_score(y_test, predicted, average='macro') classifier = clf.__class__.__name__ classifier = classifier.replace('Classifier', '') result = result.append({'classifier': classifier, 'precision': precision}, ignore_index=True) print('Precision is {precision} for {classifier_name}'.format(precision=round(precision,2), classifier_name=classifier)) result = result.sort_values(['classifier'], ascending=True) plt.subplots(figsize=(10, 7)) sns.barplot(x="classifier", y='precision', palette=cmap, data=result) calculate_precision(X_train, y_train)
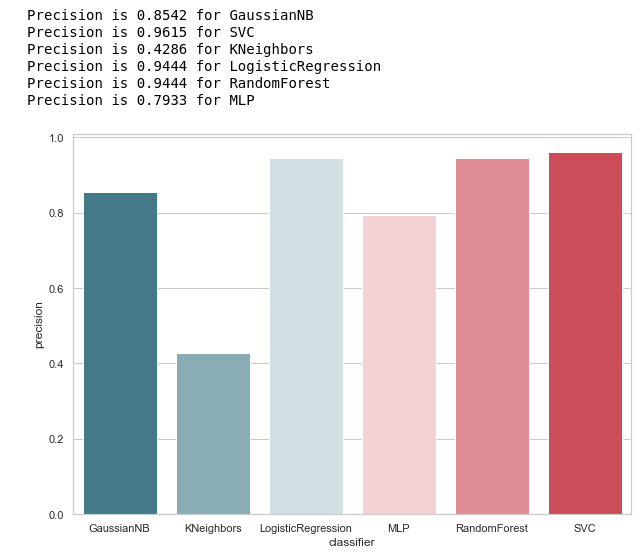
Sebagai berikut dari gambar, itu keluar seperti yang diharapkan: akurasi KNeighbors ternyata yang terendah, karena nilai TP adalah yang terendah.
Pada saat yang sama, ada artikel bagus tentang metrik di Habré, dan mereka yang ingin menyelami topik ini lebih dalam harus mengenalnya.
Pemilihan parameter hiper
Setelah kami menemukan metrik yang paling sesuai dengan kondisi yang dipilih (kami mengurangi jumlah FP), kami dapat kembali ke pertanyaan pertama: Apa alasan untuk perilaku pengklasifikasi KNeighbors ini?
Alasannya terletak pada pengaturan default yang digunakan model ini. Dan, kemungkinan besar, banyak yang bisa berseru ke tahap ini: mengapa berlatih pada parameter default? Ada alat seleksi khusus, misalnya, GridSearchCV yang sering digunakan.
Ya, benar, dan waktunya telah tiba untuk menggunakan itu,
Tetapi sebelum itu, kami menghapus classifier Bayesian dari daftar kami. Ini memungkinkan satu FP, dan pada saat yang sama, algoritma ini tidak menerima parameter variabel apa pun, sehingga hasilnya tidak akan berubah.
classifiers.remove(gnb)
Penyetelan yang bagus
Kami mendefinisikan kotak parameter untuk setiap classifier:
parameters = {'SVC':{'kernel':('linear', 'rbf','poly'), 'C':[i for i in range(1,11)],'random_state': (random_state,)}, 'KNeighbors':{'algorithm':('ball_tree', 'kd_tree'), 'n_neighbors':[i for i in range(2,20)]}, 'LogisticRegression':{'penalty':('l1', 'l2'), 'C':[i for i in range(1,11)],'random_state': (random_state,)}, 'RandomForest':{'n_estimators':[i for i in range(10,101,10)],'random_state': (random_state,)}, 'MLP':{'activation':('relu','logistic'),'solver':('sgd','lbfgs'),'max_iter':(500,1000), 'hidden_layer_sizes':[(7,),(7,7)],'random_state': (random_state,)}}
Selain itu, saya ingin memperhatikan jumlah lapisan / neuron dalam MLP.
Diputuskan untuk mengatur mereka bukan dengan pencarian lengkap dari semua nilai yang mungkin, tetapi masih didasarkan pada rumus :
Saya ingin mengatakan segera, pelatihan dan validasi silang akan dilakukan hanya pada sampel pelatihan. Saya berasumsi bahwa ada pendapat bahwa Anda dapat melakukan ini pada semua data, seperti dalam contoh dengan Iris Dataset. Tetapi, menurut saya, pendekatan ini tidak sepenuhnya dibenarkan, karena tidak akan mungkin mempercayai hasil verifikasi pada sampel uji.
Kami akan melakukan pengoptimalan dan mengganti pengklasifikasi kami dengan versi yang disempurnakan:
from sklearn.model_selection import GridSearchCV warnings.filterwarnings('ignore') for idx,clf in enumerate(classifiers): classifier = clf.__class__.__name__ classifier = classifier.replace('Classifier', '') params = parameters.get(classifier) if not params: continue new_clf = clf.__class__() gs = GridSearchCV(new_clf, params, cv=5) result =gs.fit(X_train, y_train) print(f'The best params for {classifier} are {result.best_params_}') classifiers[idx] = result.best_estimator_

Setelah kami memilih metrik untuk penilaian dan melakukan GridSearchCV, kami siap untuk menggambar garis akhir.
Untuk meringkas
Matriks kesalahan v.2
matrices = make_confussion_matrices(X_train,y_train) draw_confussion_matrices(1,2,first_row,figsize = (10.5,6)) draw_confussion_matrices(1,3,second_row,figsize = (16,6))

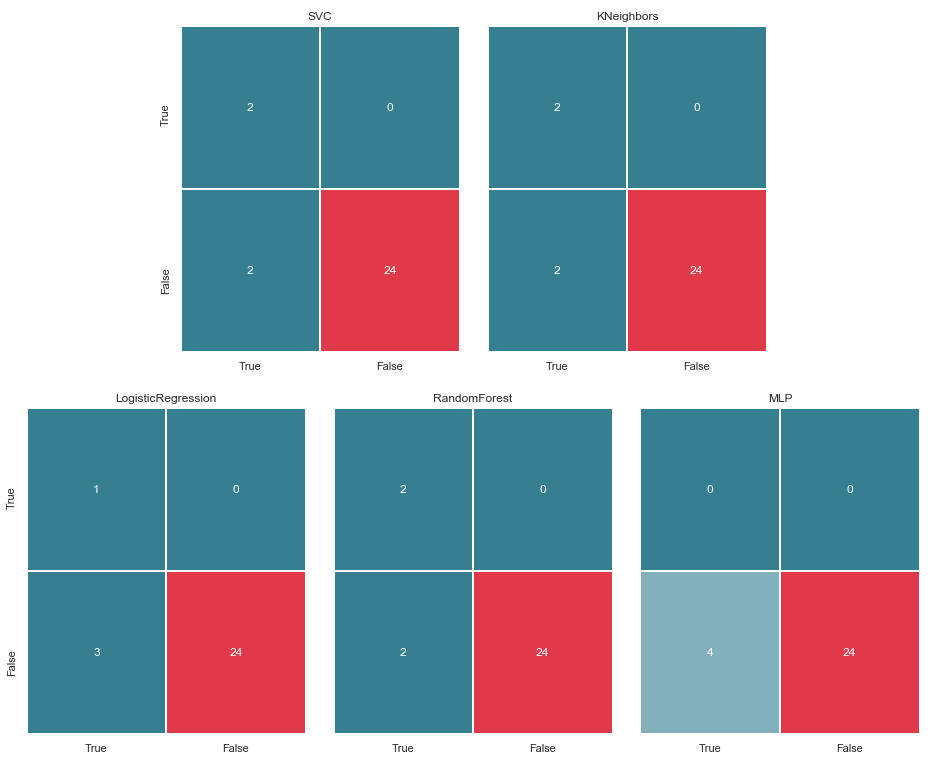
Seperti dapat dilihat dari matriks, MLP menunjukkan degradasi dan menganggap bahwa tidak ada tersangka dalam sampel uji. Random Forest memperoleh akurasi dan mengoreksi parameter untuk False Negative dan True Positive. Dan KNeighbors menunjukkan peningkatan dalam prediksi. Prakiraan orang lain belum berubah.
Akurasi v.2
Sekarang, tidak ada pengklasifikasi kami saat ini yang memiliki kesalahan dengan False Positive, yang merupakan kabar baik. Tapi, jika kita mengekspresikan semuanya dalam bahasa angka, kita mendapatkan gambar berikut:
calculate_precision(X_train, y_train)
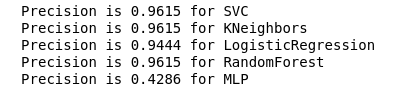
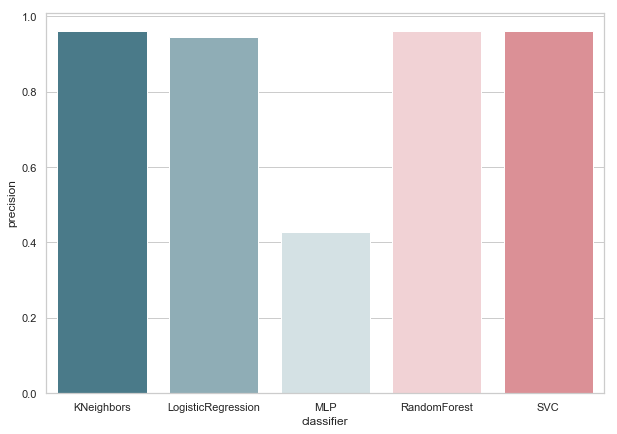
3 pengklasifikasi dengan skor Presisi tertinggi diidentifikasi. Dan mereka memiliki nilai yang sama, berdasarkan matriks kesalahan. Pengklasifikasi mana yang harus dipilih?
Siapa yang lebih baik
Tampak bagi saya bahwa ini adalah pertanyaan yang agak sulit yang tidak ada jawaban universal. Namun, sudut pandang saya dalam kasus ini akan terlihat seperti ini:
1. Pengklasifikasi harus sesederhana mungkin dalam penerapan teknisnya. Maka ia akan memiliki risiko lebih kecil untuk pelatihan ulang (mungkin ini terjadi dengan MLP). Oleh karena itu, ini bukan Hutan Acak, karena algoritma ini adalah ansambel 30 pohon dan, sebagai akibatnya, bergantung pada mereka. Konsonan dengan salah satu ide Python Zen: sederhana lebih baik daripada kompleks.
2. Tidak buruk ketika algoritma itu intuitif. Artinya, KNeighbours dianggap lebih sederhana daripada SVM dengan ruang multidimensi potensial.
Yang pada gilirannya mirip dengan pernyataan lain: eksplisit lebih baik daripada implisit.
Karena itu, KNeighbors dengan 3 tetangga, menurut saya, adalah kandidat terbaik.
Ini adalah akhir dari bagian kedua, menggambarkan penggunaan Enron Dataset sebagai contoh tugas klasifikasi dalam pembelajaran mesin. Berdasarkan materi dari kursus Pengantar Pembelajaran Mesin di Udacity. Ada juga notebook python yang mencerminkan seluruh rangkaian tindakan yang dijelaskan.