Teori permainan adalah disiplin matematika yang mempertimbangkan pemodelan tindakan pemain yang memiliki tujuan, yaitu memilih strategi optimal untuk perilaku dalam suatu konflik. Mengenai Habré, topik ini sudah
dibahas , tetapi hari ini kita akan membahas beberapa aspeknya secara lebih rinci dan mempertimbangkan contoh-contoh di Kotlin.
Jadi, strategi adalah seperangkat aturan yang menentukan pilihan tindakan untuk setiap langkah pribadi, tergantung pada situasinya. Strategi pemain yang optimal adalah strategi yang memastikan posisi terbaik dalam permainan yang diberikan, mis. keuntungan maksimum. Jika permainan diulang beberapa kali dan berisi, selain gerakan pribadi, acak, maka strategi optimal memberikan kemenangan rata-rata maksimum.
Tugas teori permainan adalah mengidentifikasi strategi optimal untuk pemain. Asumsi utama atas dasar strategi optimal ditemukan adalah bahwa lawan (atau lawan) tidak kurang cerdas dari pemain itu sendiri dan melakukan segalanya untuk mencapai tujuannya. Perhitungan lawan yang masuk akal hanyalah salah satu posisi potensial dalam konflik, tetapi dalam teori permainan, hal itulah yang diletakkan di dasar.
Ada permainan dengan sifat di mana hanya ada satu peserta yang memaksimalkan keuntungan mereka. Game dengan alam adalah model matematika di mana pilihan solusi tergantung pada realitas objektif. Misalnya, permintaan konsumen, keadaan alam, dll. "Alam" adalah konsep umum dari musuh yang tidak mengejar tujuannya sendiri. Dalam hal ini, beberapa kriteria digunakan untuk memilih strategi optimal.
Ada dua jenis tugas dalam game dengan alam:
- tugas membuat keputusan dalam kondisi risiko ketika probabilitas yang diterima sifatnya masing-masing negara yang mungkin diketahui;
- tugas pengambilan keputusan dalam kondisi ketidakpastian, ketika tidak mungkin untuk mendapatkan informasi tentang kemungkinan terjadinya keadaan alamiah.
Secara singkat tentang kriteria ini dijelaskan di
sini .
Sekarang kita akan mempertimbangkan kriteria pengambilan keputusan dalam strategi murni, dan pada akhir artikel kita akan menyelesaikan permainan dalam strategi campuran dengan metode analitis.
ReservasiSaya bukan spesialis dalam teori permainan, tetapi dalam karya ini saya menggunakan Kotlin untuk pertama kalinya. Namun, saya memutuskan untuk membagikan hasil saya. Jika Anda melihat kesalahan dalam artikel atau ingin memberikan saran, silakan di PM.
Pernyataan masalah
Kami akan menganalisis semua kriteria pengambilan keputusan menggunakan contoh melalui. Tugasnya adalah ini: petani perlu menentukan dalam proporsi apa untuk menanam ladangnya dengan tiga tanaman, jika hasil panen ini, dan, oleh karena itu, keuntungannya, tergantung pada bagaimana musim panas akan: dingin dan hujan, normal, atau panas dan kering. Petani menghitung laba bersih dari 1 hektar dari berbagai tanaman tergantung pada cuaca. Permainan ditentukan oleh matriks berikut:

Selanjutnya kami akan menyajikan matriks ini dalam bentuk strategi:
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1)
Strategi optimal yang diinginkan dilambangkan dengan
uopt . Kami akan menyelesaikan permainan menggunakan kriteria Wald, optimisme, pesimisme, Savage, dan Hurwitz dalam kondisi ketidakpastian dan kriteria Bayes dan Laplace dalam kondisi risiko.
Seperti disebutkan di atas, contohnya ada di Kotlin. Saya perhatikan bahwa secara umum ada solusi seperti Gambit (ditulis dalam C), Axelrod dan PyNFG (ditulis dengan Python), tetapi kita akan mengendarai sepeda kita sendiri, berkumpul di lutut, hanya untuk menyodok sedikit gaya, modis dan bahasa pemrograman pemuda.
Untuk mengimplementasikan solusi permainan secara terprogram, kami akan memperkenalkan beberapa kelas. Pertama, kita membutuhkan kelas yang memungkinkan kita untuk mendeskripsikan baris atau kolom dari matriks game. Kelas ini sangat sederhana dan berisi daftar nilai yang mungkin (alternatif atau keadaan alami) dan nama yang sesuai. Bidang
key akan digunakan untuk identifikasi, serta untuk perbandingan, dan perbandingan akan diperlukan dalam pelaksanaan dominasi.
Baris atau kolom matriks game import java.text.DecimalFormat import java.text.NumberFormat open class GameVector(name: String, values: List<Double>, key: Int = -1) : Comparable<GameVector> { val name: String val values: List<Double> val key: Int private val formatter:NumberFormat = DecimalFormat("#0.00") init { this.name = name; this.values = values; this.key = key; } public fun max(): Double? { return values.max(); } public fun min(): Double? { return values.min(); } override fun toString(): String{ return name + ": " + values .map { v -> formatter.format(v) } .reduce( {f1: String, f2: String -> "$f1 $f2"}) } override fun compareTo(other: GameVector): Int { var compare = 0 if (this.key == other.key){ return compare } var great = true for (i in 0..this.values.lastIndex){ great = great && this.values[i] >= other.values[i] } if (great){ compare = 1 }else{ var less = true for (i in 0..this.values.lastIndex){ less = less && this.values[i] <= other.values[i] } if (less){ compare = -1 } } return compare } }
Matriks permainan berisi informasi tentang alternatif dan keadaan alami. Selain itu, ia mengimplementasikan beberapa metode, misalnya, menemukan set dominan dan harga bersih game.
Matriks game open class GameMatrix(matrix: List<List<Double>>, alternativeNames: List<String>, natureStateNames: List<String>) { val matrix: List<List<Double>> val alternativeNames: List<String> val natureStateNames: List<String> val alternatives: List<GameVector> val natureStates: List<GameVector> init { this.matrix = matrix; this.alternativeNames = alternativeNames this.natureStateNames = natureStateNames var alts: MutableList<GameVector> = mutableListOf() for (i in 0..matrix.lastIndex) { val currAlternative = alternativeNames[i] val gameVector = GameVector(currAlternative, matrix[i], i) alts.add(gameVector) } alternatives = alts.toList() var nss: MutableList<GameVector> = mutableListOf() val lastIndex = matrix[0].lastIndex // , for (j in 0..lastIndex) { val currState = natureStateNames[j] var states: MutableList<Double> = mutableListOf() for (i in 0..matrix.lastIndex) { states.add(matrix[i][j]) } val gameVector = GameVector(currState, states.toList(), j) nss.add(gameVector) } natureStates = nss.toList() } open fun change (i : Int, j : Int, value : Double) : GameMatrix{ var mml = this.matrix.toMutableList() var rowi = mml[i].toMutableList() rowi.set(j, value) mml.set(i, rowi) return GameMatrix(mml.toList(), alternativeNames, natureStateNames) } open fun changeAlternativeName (i : Int, value : String) : GameMatrix{ var list = alternativeNames.toMutableList() list.set(i, value) return GameMatrix(matrix, list.toList(), natureStateNames) } open fun changeNatureStateName (j : Int, value : String) : GameMatrix{ var list = natureStateNames.toMutableList() list.set(j, value) return GameMatrix(matrix, alternativeNames, list.toList()) } fun size() : Pair<Int, Int>{ return Pair(alternatives.size, natureStates.size) } override fun toString(): String { return " :\n" + natureStateNames.reduce { n1: String, n2: String -> "$n1;\n$n2" } + "\n :\n" + alternatives .map { a: GameVector -> a.toString() } .reduce { a1: String, a2: String -> "$a1;\n$a2" } } protected fun dominateSet(gvl: List<GameVector>, list: MutableList<String>, dvv: Int) : MutableSet<GameVector>{ var dSet: MutableSet<GameVector> = mutableSetOf() for (gv in gvl){ for (gvv in gvl){ if (!dSet.contains(gv) && !dSet.contains(gvv)) { if (gv.compareTo(gvv) == dvv) { dSet.add(gv) list.add("[$gvv] [$gv]") } } } } return dSet } open fun newMatrix(dCol: MutableSet<GameVector>, dRow: MutableSet<GameVector>) : GameMatrix{ var result: MutableList<MutableList<Double>> = mutableListOf() var ralternativeNames: MutableList<String> = mutableListOf() var rnatureStateNames: MutableList<String> = mutableListOf() val dIndex = dCol.map { c -> c.key }.toList() for (i in 0 .. natureStateNames.lastIndex){ if (!dIndex.contains(i)){ rnatureStateNames.add(natureStateNames[i]) } } for (gv in this.alternatives){ if (!dRow.contains(gv)){ var nr: MutableList<Double> = mutableListOf() for (i in 0 .. gv.values.lastIndex){ if (!dIndex.contains(i)){ nr.add(gv.values[i]) } } result.add(nr) ralternativeNames.add(gv.name) } } val rlist = result.map { r -> r.toList() }.toList() return GameMatrix(rlist, ralternativeNames.toList(), rnatureStateNames.toList()) } fun dominateMatrix(): Pair<GameMatrix, List<String>>{ var list: MutableList<String> = mutableListOf() var dCol: MutableSet<GameVector> = dominateSet(this.natureStates, list, 1) var dRow: MutableSet<GameVector> = dominateSet(this.alternatives, list, -1) val newMatrix = newMatrix(dCol, dRow) var ddgm = Pair(newMatrix, list.toList()) val ret = iterate(ddgm, list) return ret; } protected fun iterate(ddgm: Pair<GameMatrix, List<String>>, list: MutableList<String>) : Pair<GameMatrix, List<String>>{ var dgm = this var lddgm = ddgm while (dgm.size() != lddgm.first.size()){ dgm = lddgm.first list.addAll(lddgm.second) lddgm = dgm.dominateMatrix() } return Pair(dgm,list.toList().distinct()) } fun minClearPrice(): Double{ val map: List<Double> = this.alternatives.map { a -> a?.min() ?: 0.0 } return map?.max() ?: 0.0 } fun maxClearPrice(): Double{ val map: List<Double> = this.natureStates.map { a -> a?.max() ?: 0.0 } return map?.min() ?: 0.0 } fun existsClearStrategy() : Boolean{ return minClearPrice() >= maxClearPrice() } }
Kami menggambarkan antarmuka yang memenuhi kriteria
Kriteria interface ICriteria { fun optimum(): List<GameVector> }
Pengambilan keputusan di bawah ketidakpastian
Membuat keputusan dalam menghadapi ketidakpastian menunjukkan bahwa pemain tidak ditentang oleh lawan yang masuk akal.
Kriteria Wald
Kriteria Wald memaksimalkan hasil yang paling buruk:
uopt=maximinj[U]
Menggunakan kriteria mengasuransikan hasil terburuk, tetapi harga dari strategi seperti itu adalah hilangnya kesempatan untuk mendapatkan hasil terbaik.
Pertimbangkan sebuah contoh. Untuk strategi
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) temukan posisi terendah dan dapatkan tiga berikutnya
S=(0,1,−1) . Maksimum untuk triple yang ditunjukkan adalah nilai 1, oleh karena itu, menurut kriteria Wald, strategi yang menang adalah strategi
U2=(2,3,1) sesuai dengan Budaya Tanam 2.
Implementasi perangkat lunak kriteria Wald sederhana:
class WaldCriteria(gameMatrix : GameMatrix) : ICriteria { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } override fun optimum(): List<GameVector> { val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) } val max = mins.maxWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)}) return mins .filter { m -> m.second == max!!.second } .map { m -> m.first } } }
Demi kejelasan, untuk pertama kalinya saya akan menunjukkan bagaimana solusi akan terlihat seperti tes:
Tes private fun matrix(): GameMatrix { val alternativeNames: List<String> = listOf(" 1", " 2", " 3") val natureStateNames: List<String> = listOf(" ", "", " ") val matrix: List<List<Double>> = listOf( listOf(0.0, 2.0, 5.0), listOf(2.0, 3.0, 1.0), listOf(4.0, 3.0, -1.0) ) val gm = GameMatrix(matrix, alternativeNames, natureStateNames) return gm; } } private fun testCriteria(gameMatrix: GameMatrix, criteria: ICriteria, name: String){ println(gameMatrix.toString()) val optimum = criteria.optimum() println("$name. : ") optimum.forEach { o -> println(o.toString()) } } @Test fun testWaldCriteria() { val matrix = matrix(); val criteria = WaldCriteria(matrix) testCriteria(matrix, criteria, " ") }
Mudah ditebak bahwa untuk kriteria lain, perbedaannya hanya ada pada penciptaan objek
criteria .
Kriteria optimisme
Ketika menggunakan kriteria seorang optimis, pemain memilih solusi yang memberikan hasil terbaik, sementara optimis menganggap bahwa kondisi permainan akan paling menguntungkan baginya:
uopt=maximaxj[U]
Strategi optimis dapat mengakibatkan konsekuensi negatif ketika pasokan maksimum bertepatan dengan permintaan minimum - perusahaan dapat menerima kerugian ketika menghapus produk yang tidak terjual. Pada saat yang sama, strategi optimis memiliki arti tertentu, misalnya, Anda tidak perlu mengurus pelanggan yang tidak puas, karena setiap permintaan yang mungkin selalu dipenuhi, oleh karena itu tidak perlu mempertahankan lokasi pelanggan. Jika permintaan maksimum terwujud, maka strategi optimis memungkinkan Anda untuk mendapatkan utilitas maksimum sementara strategi lain akan menyebabkan hilangnya laba. Ini memberikan keunggulan kompetitif tertentu.
Pertimbangkan sebuah contoh. Untuk strategi
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) temukan, temukan maksimum dan dapatkan tiga berikutnya
S=(5,3,4) . Maksimum untuk triple yang ditunjukkan adalah nilai 5, oleh karena itu, menurut kriteria optimisme, strategi yang menang adalah strategi
U1=(0.2.5) sesuai dengan Budaya Tanam 1.
Penerapan kriteria optimisme hampir tidak berbeda dengan kriteria Wald
class WaldCriteria(gameMatrix : GameMatrix) : ICriteria { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } override fun optimum(): List<GameVector> { val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) } val max = mins.maxWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)}) return mins .filter { m -> m.second == max!!.second } .map { m -> m.first } } }
Kriteria pesimisme
Kriteria ini dimaksudkan untuk memilih elemen terkecil dari matriks game dari elemen minimum yang mungkin:
uopt=miniminj[U]
Kriteria pesimisme menunjukkan bahwa perkembangan acara tidak akan menguntungkan bagi pembuat keputusan. Ketika menggunakan kriteria ini, pembuat keputusan dipandu oleh kemungkinan hilangnya kendali atas situasi, oleh karena itu, ia mencoba untuk mengecualikan risiko potensial dengan memilih opsi dengan profitabilitas minimal.
Pertimbangkan sebuah contoh. Untuk strategi
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) temukan, temukan yang minimum dan dapatkan tiga berikutnya
S=(0,1,−1) . Minimum untuk triple yang ditunjukkan adalah nilai -1, oleh karena itu, menurut kriteria pesimisme, strategi yang menang adalah strategi
U3=(4.3,−1) sesuai dengan Budaya Tanam 3.
Setelah mengetahui kriteria dan optimisme Wald, mudah untuk menebak bagaimana kelas kriteria pesimisme akan terlihat seperti:
class PessimismCriteria(gameMatrix : GameMatrix) : ICriteria { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } override fun optimum(): List<GameVector> { val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) } val min = mins.minWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)}) return mins .filter { m -> m.second == min!!.second } .map { m -> m.first } } }
Kriteria Savage
Kriteria Savage (kriteria pesimistis pesimis) melibatkan meminimalkan laba yang hilang terbesar, dengan kata lain, penyesalan terbesar atas laba yang hilang diminimalkan:
uopt=minimaxj[S]si,j=(maks beginbmatrixu1,ju2,j...un,j endbmatrix−ui,j)
Dalam hal ini, S adalah matriks penyesalan.
Solusi optimal menurut kriteria Savage harus memberikan penyesalan paling sedikit dari penyesalan yang ditemukan pada langkah sebelumnya. Solusi yang sesuai dengan utilitas yang ditemukan akan optimal.
Fitur dari solusi yang diperoleh termasuk tidak adanya kekecewaan terbesar yang dijamin dan penurunan dijamin dalam kemenangan maksimum yang mungkin dari pemain lain.
Pertimbangkan sebuah contoh. Untuk strategi
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) buat matriks penyesalan:
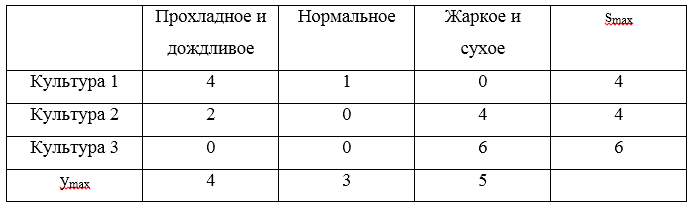
Tiga penyesalan maksimal
S=(4,4,6) . Nilai minimum risiko ini adalah nilai 4, yang sesuai dengan strategi
U1 dan
U2 .
Memprogram tes Savage sedikit lebih sulit:
class SavageCriteria(gameMatrix: GameMatrix) : ICriteria { val gameMatrix: GameMatrix init { this.gameMatrix = gameMatrix } fun GameMatrix.risk(): List<Pair<GameVector, Double?>> { val maxStates = this.natureStates.map { n -> Pair(n, n.values.max()) } .map { n -> n.first.key to n.second }.toMap() var am: MutableList<Pair<GameVector, List<Double>>> = mutableListOf() for (a in this.alternatives) { var v: MutableList<Double> = mutableListOf() for (i in 0..a.values.lastIndex) { val mn = maxStates.get(i) v.add(mn!! - a.values[i]) } am.add(Pair(a, v.toList())) } return am.map { m -> Pair(m.first, m.second.max()) } } override fun optimum(): List<GameVector> { val risk = gameMatrix.risk() val minRisk = risk.minWith(Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!) }) return risk .filter { r -> r.second == minRisk!!.second } .map { m -> m.first } } }
Kriteria Hurwitz
Kriteria Hurwitz adalah kompromi yang diatur antara pesimisme ekstrem dan optimisme total:
uopt=maks( gamma×A(k)+A(0)×(1− gamma))
A (0) adalah strategi pesimis ekstrem, A (k) adalah strategi optimis penuh,
gamma=1 - Nilai set koefisien berat:
0 leq gamma leq1 ;
gamma=0 - pesimisme ekstrim,
gamma=1 - optimisme penuh.
Dengan sejumlah kecil strategi tersendiri, atur nilai koefisien bobot yang diinginkan
gamma , dan kemudian bulatkan hasilnya ke nilai terdekat yang mungkin, dengan mempertimbangkan diskritisasi yang dilakukan.
Pertimbangkan sebuah contoh. Untuk strategi
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) . Kami berasumsi bahwa koefisien optimisme
gamma=$0, . Sekarang buat tabel:
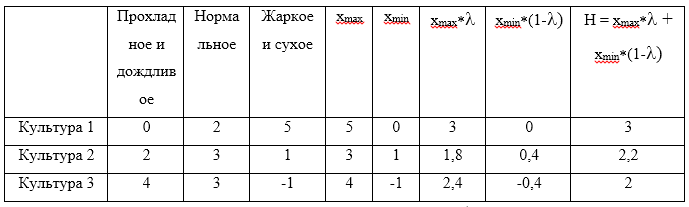
Nilai maksimum dari H yang dihitung akan menjadi nilai 3, yang sesuai dengan strategi
U1 .
Penerapan kriteria Hurwitz sudah lebih banyak:
class HurwitzCriteria(gameMatrix: GameMatrix, optimisticKoef: Double) : ICriteria { val gameMatrix: GameMatrix val optimisticKoef: Double init { this.gameMatrix = gameMatrix this.optimisticKoef = optimisticKoef } inner class HurwitzParam(xmax: Double, xmin: Double, optXmax: Double){ val xmax: Double val xmin: Double val optXmax: Double val value: Double init{ this.xmax = xmax this.xmin = xmin this.optXmax = optXmax value = xmax * optXmax + xmin * (1 - optXmax) } } fun GameMatrix.getHurwitzParams(): List<Pair<GameVector, HurwitzParam>> { return this.alternatives.map { a -> Pair(a, HurwitzParam(a.max()!!, a.min()!!, optimisticKoef)) } } override fun optimum(): List<GameVector> { val hpar = gameMatrix.getHurwitzParams() val maxHurw = hpar.maxWith(Comparator { o1, o2 -> o1.second.value.compareTo(o2.second.value) }) return hpar .filter { r -> r.second == maxHurw!!.second } .map { m -> m.first } } }
Pengambilan keputusan berisiko
Metode pengambilan keputusan dapat mengandalkan kriteria untuk pengambilan keputusan dalam kondisi risiko, tunduk pada kondisi berikut:
- kurangnya informasi yang dapat dipercaya tentang kemungkinan konsekuensi;
- adanya distribusi probabilitas;
- pengetahuan tentang kemungkinan hasil atau konsekuensi untuk setiap keputusan.
Jika keputusan dibuat dalam kondisi risiko, maka biaya keputusan alternatif dijelaskan oleh distribusi probabilitas. Dalam hal ini, keputusan didasarkan pada penggunaan kriteria nilai yang diharapkan, yang menurutnya solusi alternatif dibandingkan dalam hal memaksimalkan keuntungan yang diharapkan atau meminimalkan biaya yang diharapkan.
Kriteria nilai yang diharapkan dapat dikurangi baik untuk memaksimalkan laba (rata-rata) yang diharapkan, atau untuk meminimalkan biaya yang diharapkan. Dalam hal ini, diasumsikan bahwa laba (biaya) yang terkait dengan setiap solusi alternatif adalah variabel acak.
Perumusan tugas-tugas tersebut biasanya sebagai berikut: seseorang memilih tindakan apa pun dalam situasi di mana peristiwa acak memengaruhi hasil tindakan. Tetapi pemain memiliki beberapa pengetahuan tentang probabilitas peristiwa ini dan dapat menghitung kombinasi dan urutan tindakannya yang paling menguntungkan.
Untuk terus memberikan contoh, kami melengkapi matriks game dengan probabilitas:
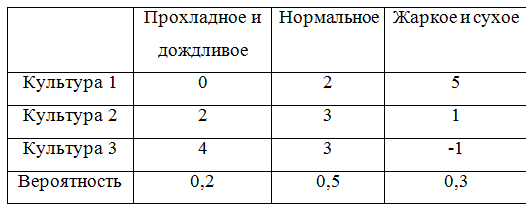
Untuk memperhitungkan probabilitas, kelas yang menggambarkan matriks game harus diulang sedikit. Ternyata, sebenarnya, tidak terlalu elegan, tapi oh well.
Matriks game dengan probabilitas open class ProbabilityGameMatrix(matrix: List<List<Double>>, alternativeNames: List<String>, natureStateNames: List<String>, probabilities: List<Double>) : GameMatrix(matrix, alternativeNames, natureStateNames) { val probabilities: List<Double> init { this.probabilities = probabilities; } override fun change (i : Int, j : Int, value : Double) : GameMatrix{ val cm = super.change(i, j, value) return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities) } override fun changeAlternativeName (i : Int, value : String) : GameMatrix{ val cm = super.changeAlternativeName(i, value) return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities) } override fun changeNatureStateName (j : Int, value : String) : GameMatrix{ val cm = super.changeNatureStateName(j, value) return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities) } fun changeProbability (j : Int, value : Double) : GameMatrix{ var list = probabilities.toMutableList() list.set(j, value) return ProbabilityGameMatrix(matrix, alternativeNames, natureStateNames, list.toList()) } override fun toString(): String { var s = "" val formatter: NumberFormat = DecimalFormat("#0.00") for (i in 0 .. natureStateNames.lastIndex){ s += natureStateNames[i] + " = " + formatter.format(probabilities[i]) + "\n" } return " :\n" + s + " :\n" + alternatives .map { a: GameVector -> a.toString() } .reduce { a1: String, a2: String -> "$a1;\n$a2" } } override fun newMatrix(dCol: MutableSet<GameVector>, dRow: MutableSet<GameVector>) : GameMatrix{ var result: MutableList<MutableList<Double>> = mutableListOf() var ralternativeNames: MutableList<String> = mutableListOf() var rnatureStateNames: MutableList<String> = mutableListOf() var rprobailities: MutableList<Double> = mutableListOf() val dIndex = dCol.map { c -> c.key }.toList() for (i in 0 .. natureStateNames.lastIndex){ if (!dIndex.contains(i)){ rnatureStateNames.add(natureStateNames[i]) } } for (i in 0 .. probabilities.lastIndex){ if (!dIndex.contains(i)){ rprobailities.add(probabilities[i]) } } for (gv in this.alternatives){ if (!dRow.contains(gv)){ var nr: MutableList<Double> = mutableListOf() for (i in 0 .. gv.values.lastIndex){ if (!dIndex.contains(i)){ nr.add(gv.values[i]) } } result.add(nr) ralternativeNames.add(gv.name) } } val rlist = result.map { r -> r.toList() }.toList() return ProbabilityGameMatrix(rlist, ralternativeNames.toList(), rnatureStateNames.toList(), rprobailities.toList()) } } }
Kriteria bayes
Kriteria Bayes (kriteria harapan) digunakan dalam masalah pengambilan keputusan dalam kondisi risiko sebagai penilaian strategi
ui ekspektasi matematis dari variabel acak yang sesuai muncul. Menurut aturan ini, strategi pemain optimal
uopt ditemukan dari kondisi:
uopt=max1 leqi leqnM(ui)M(ui)=max1 leqi leqn summj=1ui,j cdoty0j
Dengan kata lain, indikator inefisiensi strategi
ui menurut Bayes kriteria mengenai risiko adalah nilai rata-rata (ekspektasi) dari risiko baris ke-i
U yang probabilitasnya bertepatan dengan probabilitas alam. Kemudian optimal di antara strategi murni dengan kriteria Bayes mengenai risiko adalah strategi
uopt memiliki inefisiensi minimal, yaitu risiko rata-rata minimal. Kriteria Bayesian setara dengan sehubungan dengan keuntungan dan relatif terhadap risiko, yaitu jika strateginya
uopt optimal dengan kriteria Bayes berkenaan dengan menang, maka optimal dengan kriteria Bayes sehubungan dengan risiko, dan sebaliknya.
Mari kita beralih ke contoh dan menghitung ekspektasi matematis:
M1=0 cdot0.2+2 cdot0.5+5 cdot0.3=2.5;M2=2 cdot0.2+3 cdot0.5+1 cdot0.3=2.2;M4=0 cdot0.2+3 cdot0.5+(−1) cdot0.3=2.0;
Harapan matematika maksimum adalah
M1 oleh karena itu, strategi kemenangan adalah strategi
U1 .
Implementasi perangkat lunak kriteria Bayes:
class BayesCriteria(gameMatrix: ProbabilityGameMatrix) : ICriteria { val gameMatrix: ProbabilityGameMatrix init { this.gameMatrix = gameMatrix } fun ProbabilityGameMatrix.bayesProbability(): List<Pair<GameVector, Double?>> { var am: MutableList<Pair<GameVector, Double>> = mutableListOf() for (a in this.alternatives) { var alprob: Double = 0.0 for (i in 0..a.values.lastIndex) { alprob += a.values[i] * this.probabilities[i] } am.add(Pair(a, alprob)) } return am.toList(); } override fun optimum(): List<GameVector> { val risk = gameMatrix.bayesProbability() val maxBayes = risk.maxWith(Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!) }) return risk .filter { r -> r.second == maxBayes!!.second } .map { m -> m.first } } }
Kriteria Laplace
Kriteria Laplace menyajikan maksimalisasi sederhana dari ekspektasi matematis utilitas ketika asumsi probabilitas tingkat permintaan yang sama valid, yang menghilangkan kebutuhan untuk mengumpulkan statistik nyata.
Secara umum, ketika menggunakan kriteria Laplace, matriks utilitas yang diharapkan dan kriteria optimal ditentukan sebagai berikut:
uopt=maks[ overlineU] overlineU= beginbmatrix overlineu1 overlineu2... overlineun endbmatrix, overlineui= frac1n sumnj=1ui,j
Pertimbangkan contoh pengambilan keputusan berdasarkan kriteria Laplace. Kami menghitung rata-rata aritmatika untuk setiap strategi:
overlineu1= frac13 cdot(0+2+5)=2.3 overlineu2= frac13 cdot(2+3+1)=2.0 o v e r l i n e u 3 = f r a c 1 3 c d o t ( 4 + 3 - 1 ) = $ 2.
Jadi strategi yang menang adalah strategi
U 1 .
Implementasi perangkat lunak dari kriteria Laplace:
class LaplaceCriteria(gameMatrix: GameMatrix) : ICriteria { val gameMatrix: GameMatrix init { this.gameMatrix = gameMatrix } fun GameMatrix.arithemicMean(): List<Pair<GameVector, Double>> { return this.alternatives.map { m -> Pair(m, m.values.average()) } } override fun optimum(): List<GameVector> { val risk = gameMatrix.arithemicMean() val maxBayes = risk.maxWith(Comparator { o1, o2 -> o1.second.compareTo(o2.second) }) return risk .filter { r -> r.second == maxBayes!!.second } .map { m -> m.first } } }
Strategi campuran. Metode analitik
Metode analitis memungkinkan Anda untuk menyelesaikan permainan dalam berbagai strategi.
Untuk merumuskan algoritma untuk menemukan solusi untuk permainan dengan metode analitis, kami mempertimbangkan beberapa konsep tambahan.StrategiU i strategi didominasiU i - 1 , jika semuanyau 1 .. n ∈ U i ≥ u 1 .. n ∈ U i - 1 .
Dengan kata lain, jika dalam satu baris matriks pembayaran semua elemen lebih besar atau sama dengan elemen yang sesuai dari baris lain, maka baris pertama mendominasi yang kedua dan disebut baris dominan. Dan juga jika dalam beberapa kolom matriks pembayaran semua elemen kurang dari atau sama dengan elemen yang sesuai dari kolom lain, maka kolom pertama mendominasi yang kedua dan disebut kolom dominan.Harga terendah dari gim ini disebutα = m a x i m i n j u i j .
Harga teratas permainan disebut β = m i n j m a x i u i j .
Sekarang Anda dapat merumuskan algoritma untuk menyelesaikan permainan dengan metode analitis:- Hitung bagian bawah α dan atasharga game β . Jikaα = β , kemudian tuliskan jawabannya dalam strategi murni, jika tidak, lanjutkan solusinya
- Hapus baris dominan kolom. Mungkin ada beberapa. Di tempat mereka dalam strategi optimal, komponen yang sesuai adalah 0
- Pecahkan permainan matriks dengan pemrograman linier.
Untuk memberikan contoh, Anda perlu memberikan kelas yang menjelaskan solusinyaPecahkan class Solve(gamePriceObr: Double, solutions: List<Double>, names: List<String>) { val gamePrice: Double val gamePriceObr: Double val solutions: List<Double> val names: List<String> private val formatter: NumberFormat = DecimalFormat("#0.00") init{ this.gamePrice = 1 / gamePriceObr this.gamePriceObr = gamePriceObr; this.solutions = solutions this.names = names } override fun toString(): String{ var s = " : " + formatter.format(gamePrice) + "\n" for (i in 0..solutions.lastIndex){ s += "$i) " + names[i] + " = " + formatter.format(solutions[i] / gamePriceObr) + "\n" } return s } fun itersect(matrix: GameMatrix): String{ var s = " : " + formatter.format(gamePrice) + "\n" for (j in 0..matrix.alternativeNames.lastIndex) { var f = false val a = matrix.alternativeNames[j] for (i in 0..solutions.lastIndex) { if (a.equals(names[i])) { s += "$j) " + names[i] + " = " + formatter.format(solutions[i] / gamePriceObr) + "\n" f = true break } } if (!f){ s += "$j) " + a + " = 0\n" } } return s } }
Dan kelas yang melakukan solusi dengan metode simpleks. Karena saya tidak mengerti matematika, saya menggunakan implementasi yang sudah jadi dari Apache Commons MathSolver open class Solver (gameMatrix: GameMatrix) { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } fun solve(): Solve{ val goalf: List<Double> = gameMatrix.alternatives.map { a -> 1.0 } val f = LinearObjectiveFunction(goalf.toDoubleArray(), 0.0) val constraints = ArrayList<LinearConstraint>() for (alt in gameMatrix.alternatives){ constraints.add(LinearConstraint(alt.values.toDoubleArray(), Relationship.LEQ, 1.0)) } val solution = SimplexSolver().optimize(f, LinearConstraintSet(constraints), GoalType.MAXIMIZE, NonNegativeConstraint(true)) val sl: List<Double> = solution.getPoint().toList() val solve = Solve(solution.getValue(), sl, gameMatrix.alternativeNames) return solve } }
Sekarang kami menjalankan solusi dengan metode analitis. Untuk kejelasan, kami mengambil matriks game lain:( 2 4 8 5 6 2 4 6 3 2 5 4 )
Ada set dominan dalam matriks ini:( 2 4 6 2 )
Solusi val alternativeNames: List<String> = listOf(" 1", " 2", " 3") val natureStateNames: List<String> = listOf(" ", "", " ", "") val matrix: List<List<Double>> = listOf( listOf(2.0, 4.0, 8.0, 5.0), listOf(6.0, 2.0, 4.0, 6.0), listOf(3.0, 2.0, 5.0, 4.0) ) val gm = GameMatrix(matrix, alternativeNames, natureStateNames) val (dgm, list) = gm.dominateMatrix() println(dgm.toString()) println(list.reduce({s1, s2 -> s1 + "\n" + s2})) println() val s: Solver = Solver(dgm) val solve = s.solve() println(solve)
Solusi permainan ( 0 , 33 ; 0 , 67 ; 0 ) dengan harga permainan sama dengan 3,33Alih-alih sebuah kesimpulan
Saya harap artikel ini akan bermanfaat bagi mereka yang membutuhkan pendekatan pertama dengan solusi game dengan alam. Alih-alih kesimpulan, tautan ke GitHub .Saya akan berterima kasih atas umpan balik yang membangun!