Halo semuanya.
Dia menulis perpustakaan untuk melatih jaringan saraf. Tolong, siapa yang peduli.
Saya sudah lama ingin menjadikan diri saya instrumen tingkat ini. C musim panas dia turun ke bisnis. Inilah yang terjadi:
- perpustakaan ditulis dari awal dalam C ++ (hanya STL + OpenBLAS untuk perhitungan), C-interface, win / linux;
- struktur jaringan ditentukan dalam JSON;
- lapisan dasar: terhubung sepenuhnya, convolutional, pooling. Tambahan: mengubah ukuran, memotong ..;
- fitur dasar: batchNorm, dropout, pengoptimal berat - adam, adagrad ..;
- OpenBLAS digunakan untuk menghitung CPU, CUDA / cuDNN untuk kartu video. Dia juga meletakkan implementasinya pada OpenCL, untuk masa depan;
- untuk setiap lapisan ada peluang untuk secara terpisah mengatur apa yang harus dipertimbangkan - CPU atau GPU (dan yang mana);
- ukuran data input tidak ditetapkan secara kaku, dapat berubah selama pekerjaan / pelatihan;
- membuat antarmuka untuk C ++ dan Python. C # akan datang nanti juga.
Perpustakaan itu disebut SkyNet. (Semuanya rumit dengan nama, yang lain adalah pilihan, tetapi ada sesuatu yang tidak beres ..)
Perbandingan dengan PyTorch menggunakan contoh MNIST:
PyTorch: Akurasi: 98%, Waktu: 140 detik
SkyNet: Akurasi: 95%, Waktu: 150 detik
Mesin: i5-2300, GF1060. Kode uji.
Arsitektur perangkat lunak
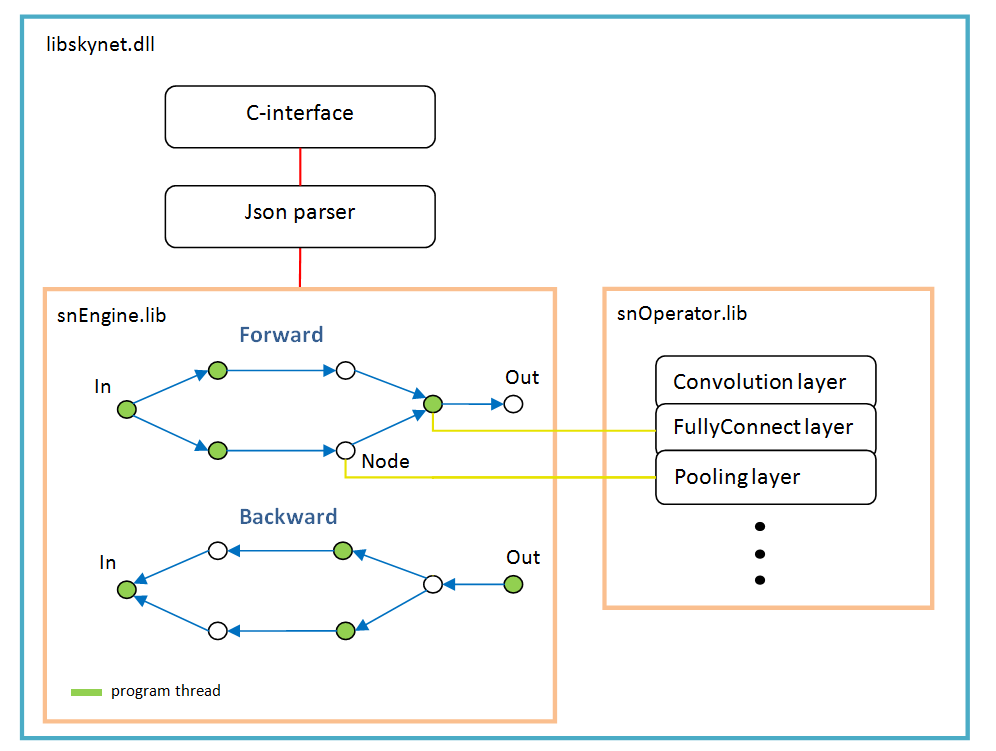
Ini didasarkan pada grafik operasi yang dibuat secara dinamis sekali setelah mem-parsing struktur jaringan.
Untuk setiap cabang, utas baru. Setiap node jaringan (Node) adalah lapisan perhitungan.
Ada fitur pekerjaan:
- fungsi aktivasi, normalisasi secara batch, dropout - semuanya diimplementasikan sebagai parameter lapisan tertentu, dengan kata lain, fungsi-fungsi ini tidak ada sebagai lapisan yang terpisah. Mungkin batchNorm harus dipilih di layer terpisah di masa depan;
- softMax juga bukan layer terpisah, itu milik layer LossFunction khusus. Di mana digunakan saat memilih jenis perhitungan kesalahan tertentu;
- lapisan "LossFunction" digunakan untuk secara otomatis menghitung kesalahan, Anda jelas tidak dapat menggunakan langkah maju / mundur (di bawah ini adalah contoh bekerja dengan lapisan ini);
- tidak ada lapisan "Ratakan", itu tidak diperlukan karena lapisan "FullyConnect" itu sendiri menarik array input;
- pengoptimal berat harus ditetapkan untuk setiap lapisan berat, secara default, 'adam' digunakan oleh semua orang.
Contohnya
Mnist

Kode C ++ terlihat seperti ini: Kode lengkap tersedia di
sini . Menambahkan beberapa gambar ke repositori, yang terletak di sebelah contoh. Saya menggunakan OpenCV untuk membaca gambar, saya tidak memasukkannya ke dalam kit.
Jaringan lain dari rencana yang sama, lebih rumit.

Kode untuk membuat jaringan seperti itu: Dalam contoh itu bukan, Anda dapat menyalin dari sini.
Dalam Python, kodenya juga terlihat // snet = snNet.Net() snet.addNode("Input", Input(), "C1 C2 C3") \ .addNode("C1", Convolution(15, 0, calcMode.CUDA), "P1") \ .addNode("P1", Pooling(calcMode.CUDA), "FC1") \ .addNode("C2", Convolution(12, 0, calcMode.CUDA), "P2") \ .addNode("P2", Pooling(calcMode.CUDA), "FC3") \ .addNode("C3", Convolution(12, 0, calcMode.CUDA), "P3") \ .addNode("P3", Pooling(calcMode.CUDA), "FC5") \ \ .addNode("FC1", FullyConnected(128, calcMode.CUDA), "FC2") \ .addNode("FC2", FullyConnected(10, calcMode.CUDA), "LS1") \ .addNode("LS1", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("FC3", FullyConnected(128, calcMode.CUDA), "FC4") \ .addNode("FC4", FullyConnected(10, calcMode.CUDA), "LS2") \ .addNode("LS2", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("FC5", FullyConnected(128, calcMode.CUDA), "FC6") \ .addNode("FC6", FullyConnected(10, calcMode.CUDA), "LS3") \ .addNode("LS3", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("Summ", LossFunction(lossType.softMaxToCrossEntropy), "Output") .............
CIFAR-10

Di sini saya sudah harus mengaktifkan batchNorm. Grid ini mempelajari akurasi hingga 50% lebih dari 1000 iterasi, batch 100.
Kode ini ternyata sn::Net snet; snet.addNode("Input", sn::Input(), "C1") .addNode("C1", sn::Convolution(15, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C2") .addNode("C2", sn::Convolution(15, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3") .addNode("C3", sn::Convolution(25, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C4") .addNode("C4", sn::Convolution(25, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5") .addNode("C5", sn::Convolution(40, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C6") .addNode("C6", sn::Convolution(40, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P3") .addNode("P3", sn::Pooling(sn::calcMode::CUDA), "FC1") .addNode("FC1", sn::FullyConnected(2048, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC2") .addNode("FC2", sn::FullyConnected(128, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC3") .addNode("FC3", sn::FullyConnected(10, sn::calcMode::CUDA), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output");
Saya pikir jelas bahwa setiap kelas gambar dapat diganti.
U-net tyni
Contoh terakhir. U-Net asli yang disederhanakan untuk demonstrasi.

Biarkan saya jelaskan sedikit: lapisan DC1 ... - membalikkan lilitan, lapisan Concat1 ... - lapisan penambahan saluran,
Rsz1 ... - digunakan untuk menyetujui jumlah saluran pada langkah yang berlawanan, karena kesalahan dari jumlah saluran kembali dari lapisan Concat.
Kode C ++. sn::Net snet; snet.addNode("In", sn::Input(), "C1") .addNode("C1", sn::Convolution(10, -1, sn::calcMode::CUDA), "C2") .addNode("C2", sn::Convolution(10, 0, sn::calcMode::CUDA), "P1 Crop1") .addNode("Crop1", sn::Crop(sn::rect(0, 0, 487, 487)), "Rsz1") .addNode("Rsz1", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3") .addNode("C3", sn::Convolution(10, -1, sn::calcMode::CUDA), "C4") .addNode("C4", sn::Convolution(10, 0, sn::calcMode::CUDA), "P2 Crop2") .addNode("Crop2", sn::Crop(sn::rect(0, 0, 247, 247)), "Rsz2") .addNode("Rsz2", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5") .addNode("C5", sn::Convolution(10, 0, sn::calcMode::CUDA), "C6") .addNode("C6", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC1") .addNode("DC1", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz3") .addNode("Rsz3", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc2") .addNode("Conc2", sn::Concat("Rsz2 Rsz3"), "C7") .addNode("C7", sn::Convolution(10, 0, sn::calcMode::CUDA), "C8") .addNode("C8", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC2") .addNode("DC2", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz4") .addNode("Rsz4", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc1") .addNode("Conc1", sn::Concat("Rsz1 Rsz4"), "C9") .addNode("C9", sn::Convolution(10, 0, sn::calcMode::CUDA), "C10"); sn::Convolution convOut(1, 0, sn::calcMode::CUDA); convOut.act = sn::active::sigmoid; snet.addNode("C10", convOut, "Output");
Kode lengkap dan gambar ada di
sini .
Matematika open source seperti ini .
Saya menguji semua layer pada MNIST; TF berfungsi sebagai standar untuk mengevaluasi kesalahan.
Apa selanjutnya
Perpustakaan tidak akan tumbuh lebar, yaitu, tidak ada pembuka, soket, dll, agar tidak mengembang.
Antarmuka perpustakaan tidak akan berubah / berkembang, saya tidak akan mengatakan itu sama sekali dan tidak pernah, tapi yang terakhir tapi tidak kalah pentingnya.
Hanya secara mendalam: Saya akan melakukan perhitungan pada OpenCL, antarmuka untuk C #, jaringan RNN dapat ...
MKL Saya pikir tidak masuk akal untuk menambahkan, karena jaringannya sedikit lebih dalam - ini lebih cepat pada kartu video, dan rata-rata kartu kinerja tidak kekurangan sama sekali.
Impor / ekspor bobot dengan kerangka kerja lain - melalui Python (belum diimplementasikan). Peta jalan akan jika minat muncul pada orang.
Siapa yang dapat mendukung kode ini, silakan. Namun ada keterbatasan agar arsitektur saat ini tidak pecah.
Anda dapat memperluas antarmuka untuk python menjadi tidak mungkin, seperti halnya dermaga dan contoh diperlukan.
Untuk menginstal dari Python:
* pip install libskynet - CPU
* pip instal libskynet-cu - CUDA9.2 + cuDNN7.3.1
Panduan pengguna Wiki.
Perangkat lunak ini didistribusikan secara bebas, lisensi MIT.
Terima kasih