Beberapa hari yang lalu, Splunk merilis rilis baru platform Splunk 7.2-nya, yang memperkenalkan banyak inovasi untuk mengoptimalkan kinerja, termasuk skema penyimpanan data baru, administrasi kinerja yang digunakan, dan banyak lagi. Lihat detail di bawah potongan.
Smartstore
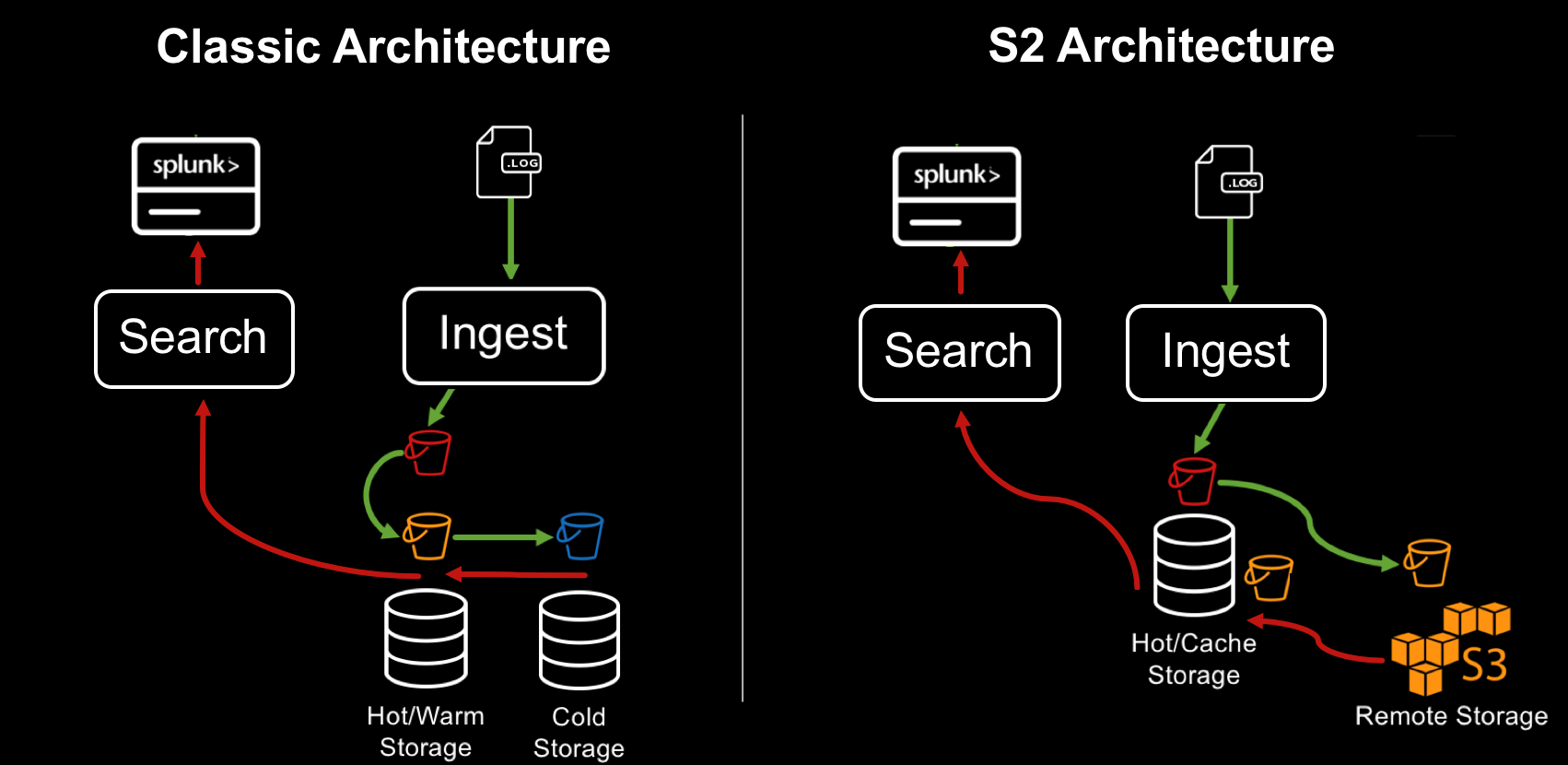
SmartStore adalah cara baru untuk mengelola gudang data di Splunk. Sebelumnya, semua data disimpan dalam pengindeks, ini memungkinkan data menjadi mudah diakses untuk diproses. Jika perlu untuk memperluas volume, pengindeks baru telah ditambahkan ke cluster. Model ini bagus untuk volume data rendah hingga sedang. Ketika Anda menambahkan lebih banyak data, Anda tidak hanya membutuhkan lebih banyak ruang, tetapi juga lebih banyak kekuatan pemrosesan. Namun, dengan volume data yang tumbuh secara eksponensial, permintaan untuk penyimpanan melebihi permintaan untuk komputasi cepat. SmartStore memungkinkan Anda untuk meng-host data secara lokal pada pengindeks atau pada repositori jarak jauh. Pergerakan data antara pengindeks dan penyimpanan jauh dikendalikan oleh manajer cache yang terletak di pengindeks.
Dengan SmartStore, Anda dapat mengurangi ukuran penyimpanan pengindeks ke minimum dan memilih sumber daya komputasi yang optimal untuk I / O. Sebagian besar data disimpan pada penyimpanan jarak jauh, sementara pengindeks berisi cache lokal yang berisi jumlah minimum data: data panas, salinan data hangat yang baru-baru ini terlibat dalam pencarian.
 Kapan sebaiknya menggunakan SmartStore?
Kapan sebaiknya menggunakan SmartStore?- Biaya infrastruktur memperlambat skalabilitas dan membatasi waktu penyimpanan.
- Pengarsipan data bukanlah solusi yang terjangkau, karena data lama (~ 1 tahun) harus dapat dicari.
- Penggunaan Splunk dalam jumlah besar, biasanya lebih dari ~ 10 pengindeks.
- Sebagian besar (lebih dari 95%) permintaan dilakukan untuk data terbaru (kurang dari 90 hari).
- Pencarian untuk data yang lebih lama (> 90 hari) jarang terjadi, dan kinerja pencarian yang lambat dapat diterima.
Manajemen beban kerja
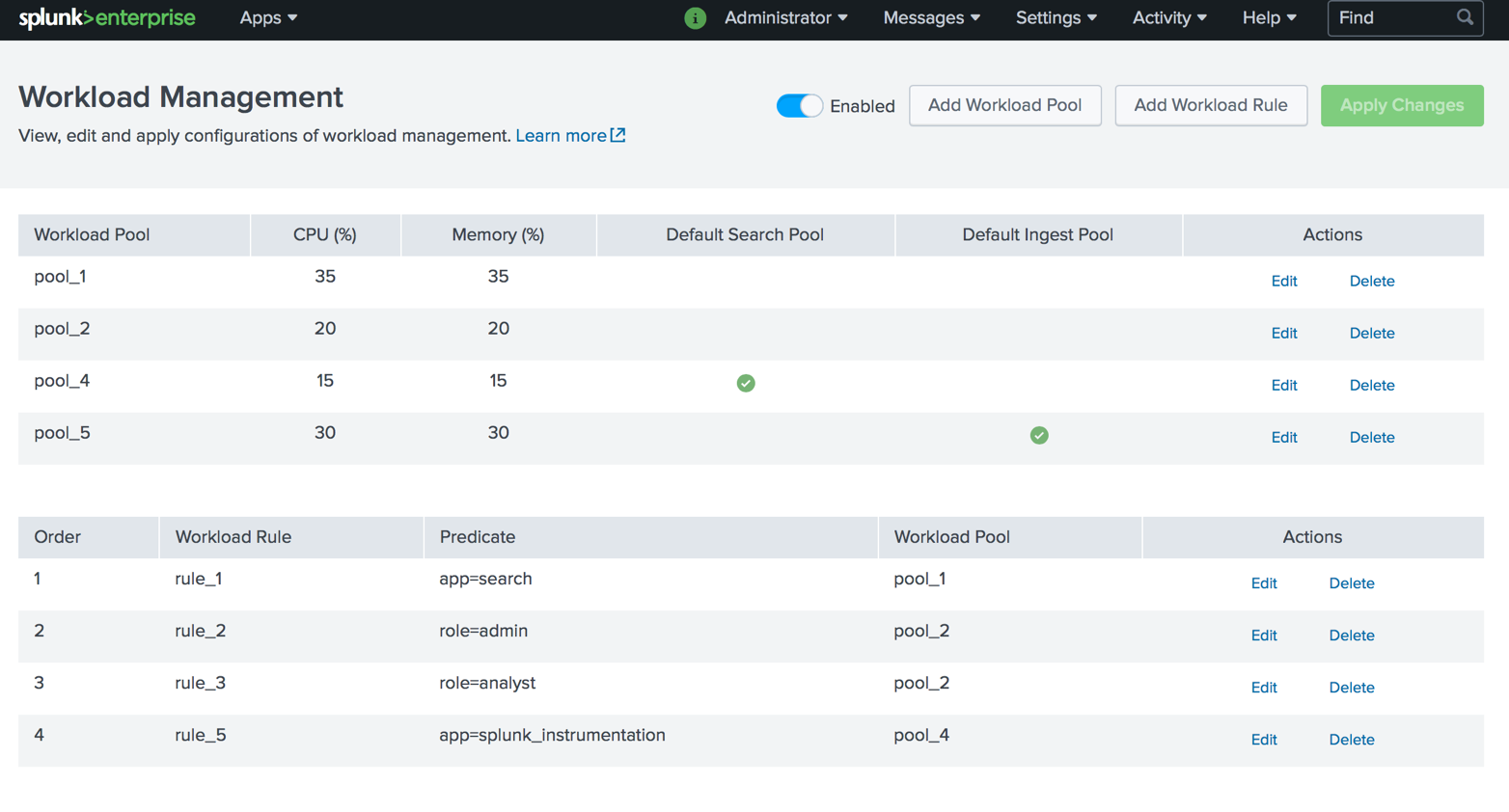
Manajemen Beban Kerja adalah mekanisme berdasarkan kebijakan reservasi sumber daya sistem (CPU, memori) untuk mengunduh data dan melakukan kueri penelusuran sesuai dengan prioritas bisnis. Ini memungkinkan administrator untuk mengklasifikasikan beban kerja ke dalam kelompok yang berbeda dan cadangan bagian sumber daya sistem (CPU, memori) per kelompok beban kerja, terlepas dari total beban sistem.
Kapan lebih baik digunakan?- Untuk menunjukkan prioritas permintaan dan tugas utama;
- Untuk membatasi dampak kinerja keseluruhan permintaan pencarian berat;
- Untuk menghindari keterlambatan dalam memuat data karena sumber daya pencarian yang dikeluarkan.
Pemantauan kesehatan Splunk real-time
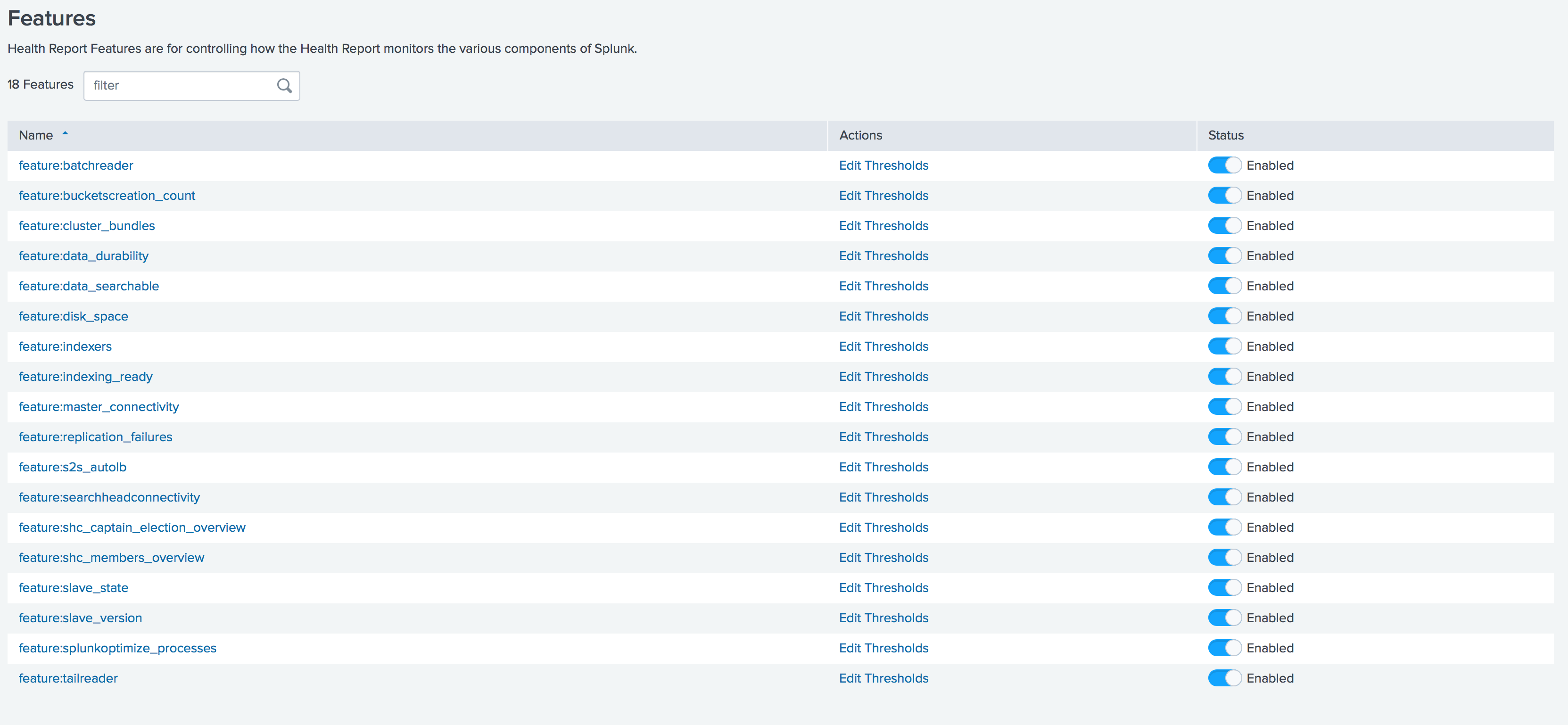
Rilis 7.2 secara signifikan memperluas alat pemantauan kesehatan Splunk. Manajer laporan kesehatan sekarang tersedia di mana Anda dapat mengaktifkan / menonaktifkan fungsi dan menetapkan nilai ambang batas untuk masing-masing fungsi secara langsung melalui antarmuka grafis.
Anda juga dapat mengatur peringatan kesehatan Splunk melalui email, Telegram, Slack, dll.

Metrik
Selain itu, fungsi untuk bekerja dengan metrik telah mencapai tingkat yang baru. Pertama, alat yang sepenuhnya baru untuk menganalisis dan memantau metrik tanpa menggunakan kueri penelusuran telah muncul -
Splunk Metrics Workspace . Ini menyediakan antarmuka analisis visual yang mudah digunakan. Anda dapat membuat visualisasi interaktif di ruang kerja, melakukan berbagai fungsi analitis untuk mendapatkan gagasan tentang indikator.
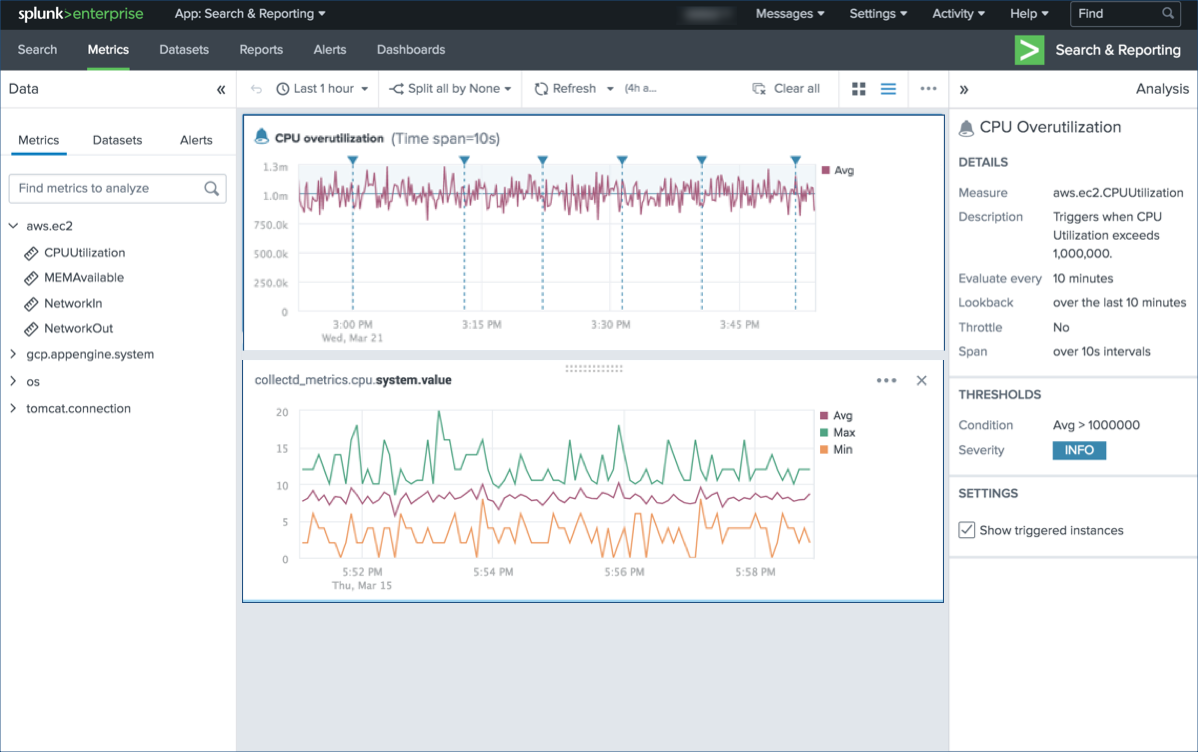 Operasi dan fungsi analitik:
Operasi dan fungsi analitik:- Agregasi
- Perbandingan waktu - overlay grafik sebelumnya pada grafik saat ini.
- Pemisahan - menunjukkan hasil untuk pengukuran tertentu.
- Filter - penyertaan atau pengecualian hasil tertentu.
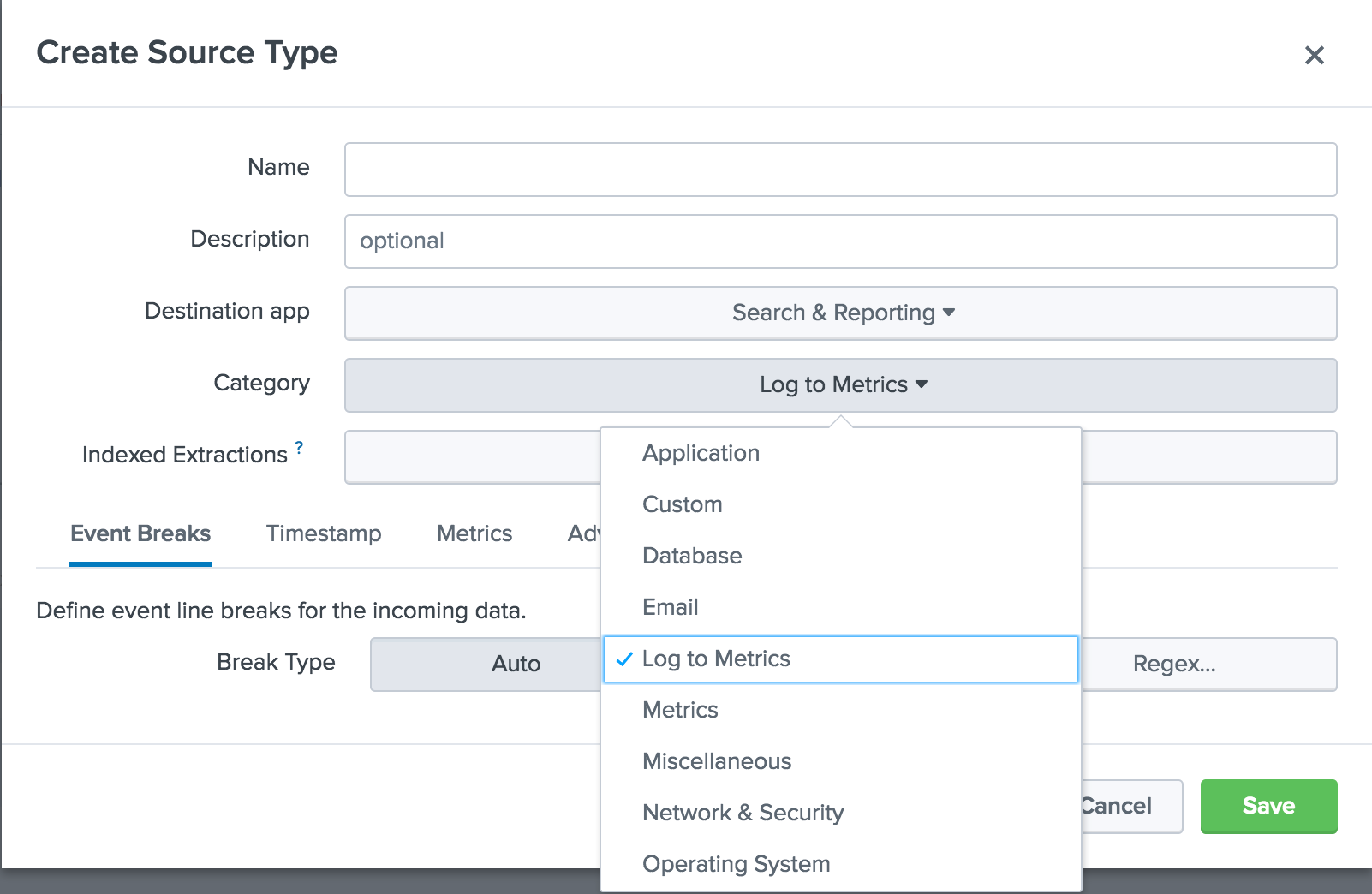
Kedua, menjadi mungkin untuk mengubah log terstruktur dan tidak terstruktur menjadi metrik. Sebelumnya, ada dua metode utama untuk menerima metrik di Splunk: menggunakan agen seperti statsd dan collectd, dan juga dengan membuat dan menyimpan data menggunakan mcollect. Fitur
Log to Metrics yang baru memungkinkan platform Splunk untuk mengonversi log yang berisi data metrik ke titik data metrik diskrit. Anda juga dapat menentukan tindakan yang harus diekstraksi sebagai metrik, dan membuat daftar hitam bidang yang tidak boleh ditampilkan dalam data metrik
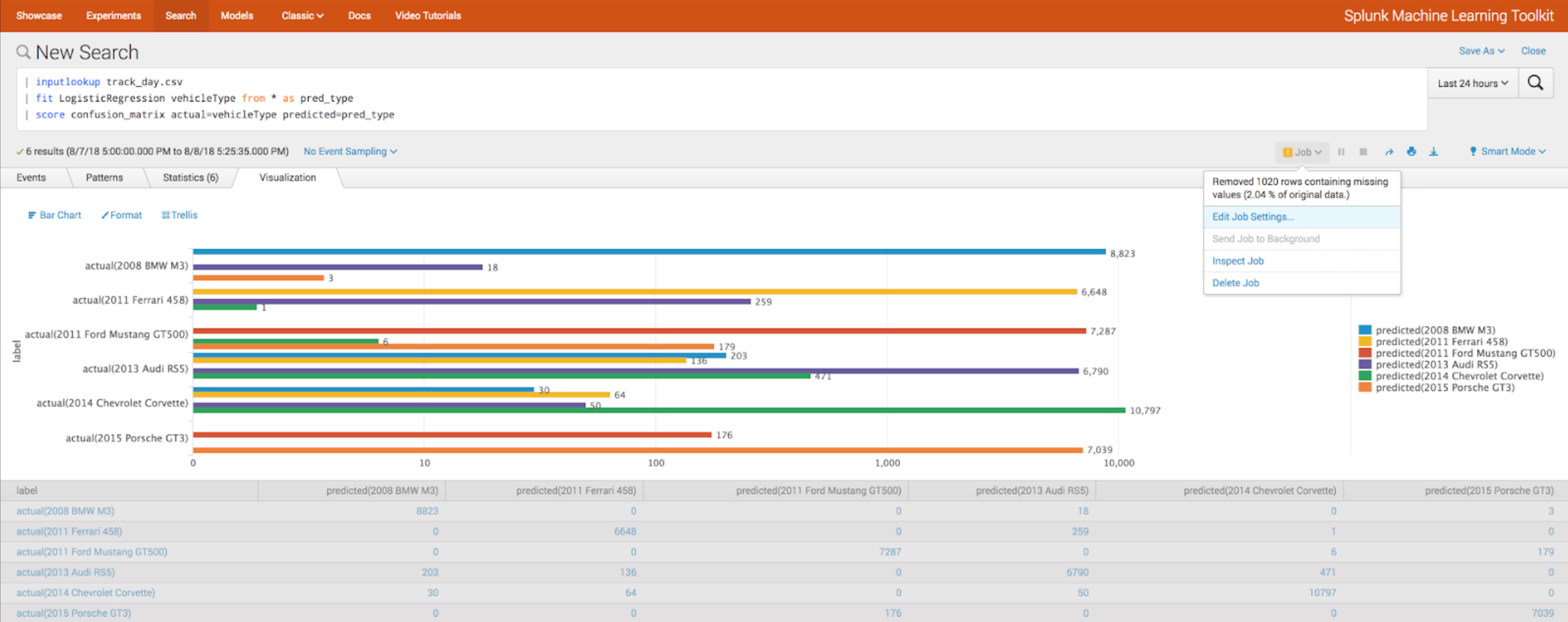
MTLK 4.0
Dengan rilis Splunk baru, versi baru dari Toolkit Pembelajaran Mesin Splunk juga dirilis. Kami menulis tentang rilis MTLK
sebelumnya , dan sekarang mari kita lihat apa yang baru muncul sekarang.
Integrasi:- Tensorflow
- Apache percikan
- Github
Algoritma baru:- LocalOutlierFactor
- Klasifikasi MLP
Evaluasi Algoritma- Fungsi skor
- Validasi silang (parameter kfold_cv)
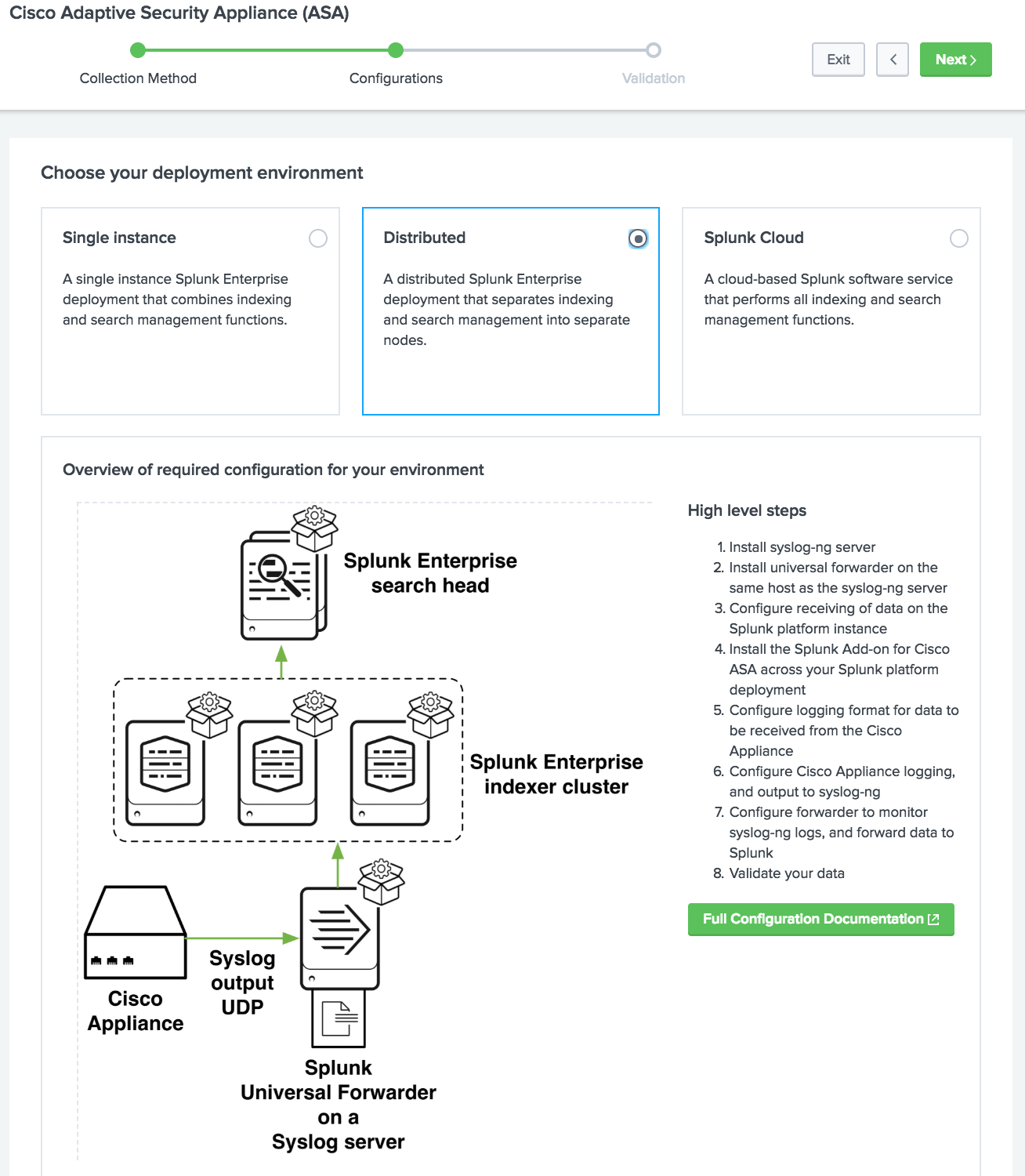
Onboarding Data yang Dikelola
Antarmuka pengguna grafis baru dengan panduan memuat data untuk membantu pengguna Splunk memahami konsep-konsep penting untuk mendapatkan data dari berbagai sumber di Splunk.
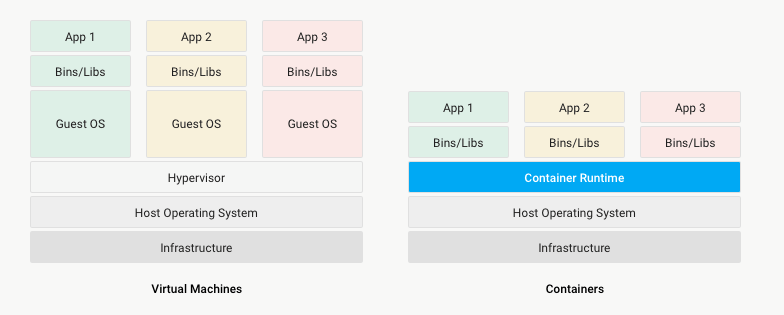
Dukungan Docker
Dengan rilis Enterprise 7.2, pengguna Splunk sekarang memiliki kemampuan untuk menyebarkan Splunk dalam wadah Docker. Wadah adalah paket perangkat lunak ringan yang menggabungkan kode aplikasi dengan runtime, alat, pustaka sistem, dan pengaturan lingkungan yang diperlukan untuk pelaksanaannya. Ini memungkinkan Anda untuk mengabstraksi aplikasi dari lingkungan tempat aplikasi itu dijalankan, mengisolasinya dari aplikasi lain, dan menyederhanakan penskalaan.
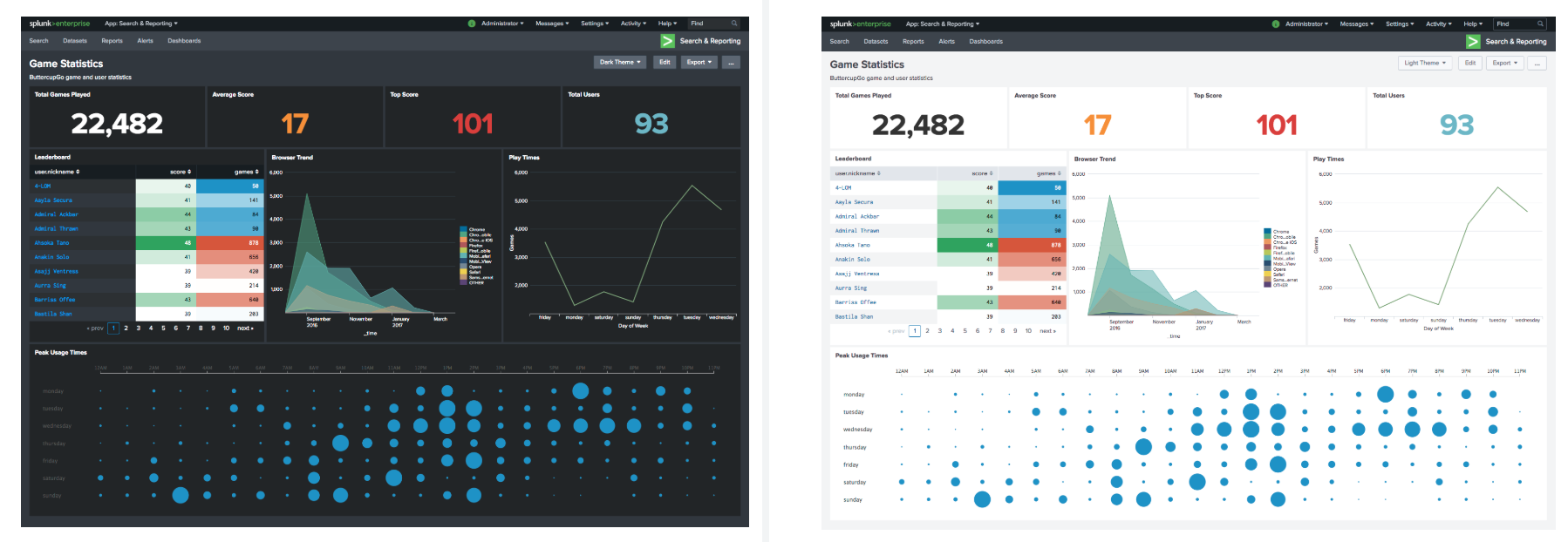
Antarmuka gelap
Ya ya Sekarang Anda dapat menggunakan tema gelap yang dikembangkan oleh desainer Splunk di dasbor Anda. Tentu saja, sebelumnya juga dimungkinkan untuk menyesuaikan latar belakang gelap dashboard menggunakan CSS, tetapi agar tema terlihat normal, masih perlu untuk memilih dan menambahkan palet warna untuk semua elemen, yang agak suram. Sekarang, masalah ini diselesaikan dengan mengklik tombol.
Untuk studi yang paling mendalam tentang semua fitur baru, Anda harus menginstal aplikasi
Tinjauan Ringkas Perusahaan 7.2 , serta menonton
video rilis
resmi .
