Saya memposting laporan kedua dari
mitap pertama kami, yang diadakan pada bulan September. Terakhir kali Anda bisa membaca (dan melihat) tentang
menggunakan Konsul untuk meningkatkan skala layanan dari Ivan Bubnov dari BIT.GAMES, dan hari ini kita akan berbicara tentang CICD. Lebih tepatnya, administrator sistem kami Egor Panov akan memberi tahu tentang hal ini, yang bertanggung jawab atas ketersediaan infrastruktur dan layanan di Pixonic. Di bawah cut - decoding kinerja.
Untuk memulainya, industri game lebih berisiko - Anda tidak pernah tahu persis apa yang akan meresap ke hati pemain. Jadi kami membuat banyak prototipe. Tentu saja, kami membuat prototipe di ujung tongkat, tali, dan bahan improvisasi lainnya.
Tampaknya dengan pendekatan ini, melakukan sesuatu yang kemudian dapat didukung pada umumnya tidak mungkin. Tetapi bahkan pada tahap ini kita bertahan. Kami berpegang pada tiga pilar:
- keahlian penguji yang sangat baik;
- interaksi dekat dengan mereka;
- waktu yang kami berikan untuk pengujian.
Dengan demikian, jika kita tidak membangun proses kita, misalnya, penyebaran atau CI (integrasi berkelanjutan), cepat atau lambat kita akan sampai pada kesimpulan bahwa durasi pengujian akan meningkat dan meningkat setiap saat. Dan kita akan melakukan segalanya dengan lambat dan kehilangan pasar, atau kita akan meledak di setiap penyebaran.
Tetapi membangun proses CICD tidak sesederhana itu. Beberapa orang akan berkata, ya, saya akan taruh Jenkins, saya akan segera menelepon sesuatu, sekarang saya sudah siap CICD. Tidak, ini bukan hanya alat, itu juga praktik. Mari kita mulai.

Yang pertama. Dalam banyak artikel mereka menulis bahwa semuanya perlu disimpan dalam satu repositori: kode, dan tes, dan gunakan, dan bahkan skema database, dan pengaturan IDE yang umum untuk semua. Kami pergi dengan cara kami sendiri.
Kami telah mengalokasikan berbagai repositori: penempatan di repositori kami, tes di tempat lain. Ini bekerja lebih cepat. Ini mungkin tidak cocok untuk Anda, tetapi bagi kami itu jauh lebih nyaman. Karena ada satu poin penting pada titik ini - Anda perlu membangun yang sederhana dan transparan untuk semua arus hit. Tentu saja, Anda dapat mengunduh yang sudah selesai di suatu tempat, tetapi dalam hal apa pun, Anda perlu memperbaiki sendiri, memperbaikinya. Bagi kami, sebagai contoh, sebuah deployment hidup dengan gitflow sendiri, yang lebih seperti aliran GitHub, dan pengembangan server hidup dengan gitflow sendiri.
Paragraf selanjutnya. Anda perlu mengonfigurasi bangunan yang sepenuhnya otomatis. Jelas bahwa pada tahap pertama pengembang itu sendiri secara pribadi mengumpulkan proyek, kemudian ia secara pribadi menyebarkannya menggunakan SCP, meluncurkannya sendiri, mengirimkannya kepada siapa pun yang membutuhkannya. Opsi ini tidak berumur panjang, skrip bash muncul. Nah, karena lingkungan pengembang terus berubah, server khusus yang dibangun telah muncul. Dia hidup sangat lama, selama ini kami berhasil meningkatkan hingga 500 di server, mengkonfigurasi konfigurasi server pada Puppet, mengumpulkan warisan pada Puppet, menolak Puppet, beralih ke Ansible, dan buildserver ini terus hidup.
Mereka memutuskan untuk mengubah segalanya setelah dua panggilan, mereka tidak menunggu untuk yang ketiga. Ceritanya jelas: buildserver adalah satu titik kegagalan dan, tentu saja, ketika kami perlu menyebarkan sesuatu, pusat data benar-benar jatuh bersama dengan buildserver kami. Dan panggilan kedua: kami perlu memperbarui versi Java - kami memperbaruinya pada buildserver, memasangnya di atas panggung, semuanya keren, semuanya bagus dan di sana perlu menjalankan beberapa perbaikan bug kecil pada prod. Tentu saja, kami lupa untuk mundur dan semuanya berantakan.
Setelah itu, mereka menulis ulang semuanya sehingga seluruh build dapat terjadi pada agen TeamCity dan menulis ulang pada Ansible, karena itu dikonfigurasi pada Ansible, mengapa tidak menggunakan alat yang sama untuk penyebaran juga.
Aturan berikut: semakin sering Anda berkomitmen, semakin baik. Mengapa Karena ada yang keempat: setiap komit dikumpulkan. Dan faktanya, bahkan lebih dari setiap komitmen. Saya sudah mengatakan bahwa kami memiliki TeamCity, dan itu memungkinkan Anda untuk menjalankan komit dari IDE favorit Anda (coba tebak apa yang saya maksud). Sebenarnya, umpan balik cepat, semuanya bagus.
Bangunan yang rusak segera diperbaiki. Segera setelah Anda mengatur penyebaran otomatis, Anda perlu mengatur notifikasi otomatis di Slack. Kita semua tahu betul bahwa pengembang tahu bagaimana kodenya bekerja hanya pada saat dia menulisnya. Oleh karena itu: orang tersebut tahu - segera diperbaiki.
Kami menguji pada lingkungan mengulangi prod. Sederhana, kami memilih Ansible dan AWX. Seseorang mungkin bertanya, tetapi bagaimana dengan Docker, Kubernetes, OpenShift, di mana semua masalah di luar kotak telah lama diselesaikan? Saya lupa mengatakan bahwa kami memiliki komponen Linux dan Windows. Dan, misalnya, server Photon, yang ada di Windows, kami baru saja dapat mengemas lebih atau kurang secara normal dalam wadah buruh pelabuhan 10 GB. Karenanya, kami memiliki aplikasi Windows yang tidak dikemas dengan baik dalam sebuah wadah; Ada aplikasi di Linux (yang ada di Jawa), yang dikemas dengan sempurna, tetapi tidak ada alasan untuk itu, itu berfungsi dengan baik di mana pun Anda menjalankannya. Ini Jawa.
Selanjutnya, kami memilih antara Ansible dan Chef. Keduanya bekerja dengan baik dengan Windows, tetapi Ansible ternyata jauh lebih mudah bagi kami. Ketika kami sudah menginstal AWX - secara umum semua api menjadi. AWX memiliki rahasia, grafik, sejarah. Anda dapat menunjukkan kepada seseorang yang jauh dari semua ini, dia akan segera melihat semuanya dan semuanya akan menjadi jelas.
Dan Anda selalu harus menjaga build dengan cepat. Saya tidak tahu mengapa, tetapi setiap kali Anda meluncurkan proyek baru, Anda benar-benar lupa tentang pembuat server, tentang agen-agen dan memilih beberapa komputer yang ada di sekitar - ini adalah pembuat server kami. Tidak diinginkan untuk mengulangi kesalahan ini, karena semua yang saya bicarakan (umpan balik cepat, plus) - semuanya tidak akan terlalu relevan jika perakitan dimulai pada laptop Anda sendiri lebih cepat daripada pada beberapa jenis pertanian pembuatan server.

7 poin - dan kami telah membangun semacam proses CI. Bagus Diagram berikut tidak terlihat, tetapi masih ada Graylog di samping. Siapa yang membaca artikel kami di Habré, yang sudah melihat
bagaimana kami memilih Graylog dan
cara memasang . Bagaimanapun, itu membantu untuk membelokkan jika masalah masih terjadi.
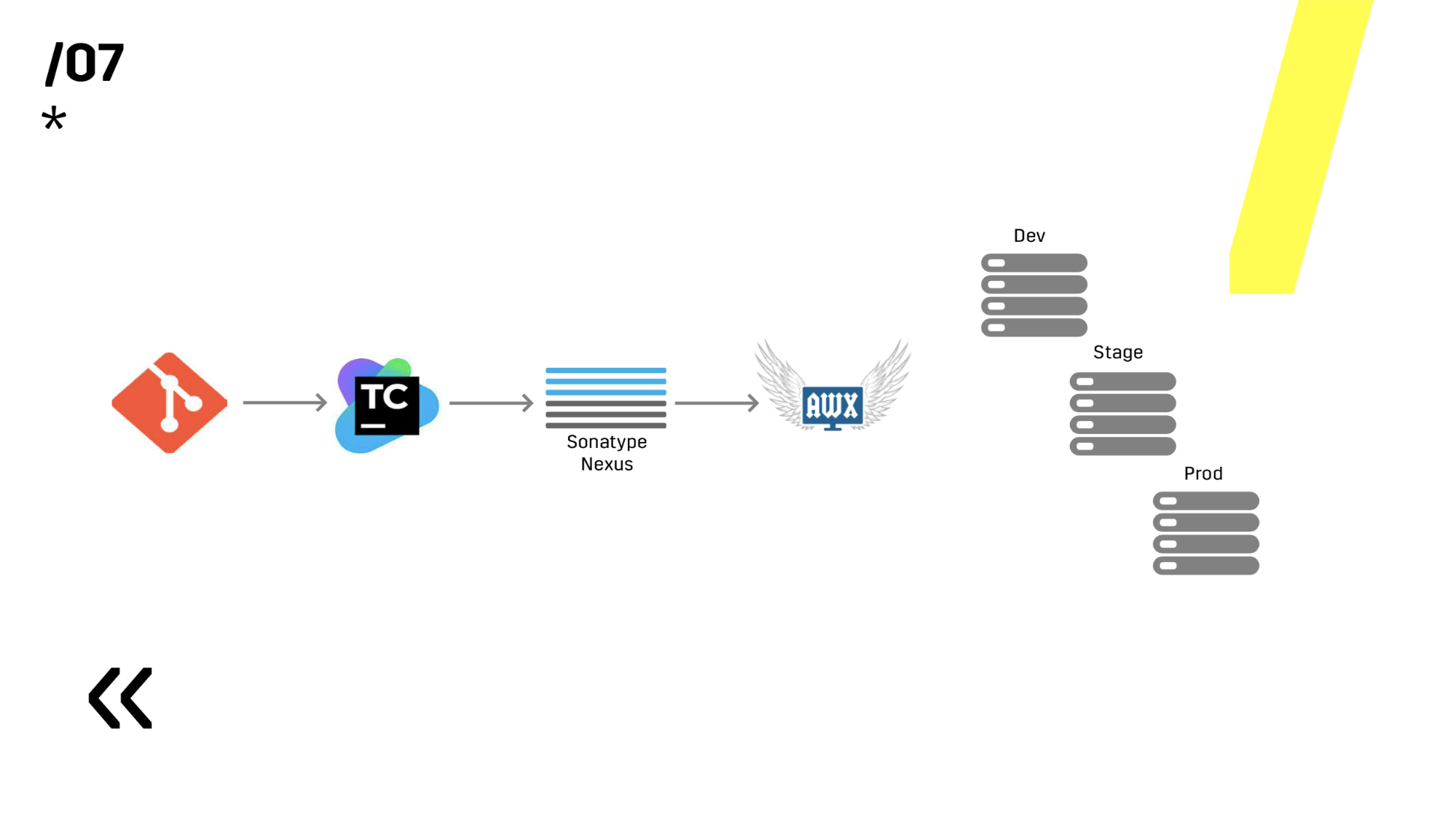
Sekarang di pangkalan ini sudah dimungkinkan untuk melanjutkan ke penyebaran.

Tapi saya sudah bicara tentang penyebaran di paragraf kedua, jadi saya tidak akan terlalu memikirkan hal ini. Saya akan mengatakan satu hal tentang kehidupan: jika Anda menggunakan Ansible, pastikan untuk menambahkan serial ini, yang ada di slide. Itu terjadi lebih dari sekali ketika Anda memulai sesuatu, dan kemudian Anda mengerti, tapi saya memulainya dengan salah, atau salah, atau salah, dan kemudian Anda melihat bahwa ini hanya satu server. Dan kami dapat dengan mudah kehilangan satu server dan Anda cukup mengunggahnya lagi, tidak ada yang menyadarinya.
Plus, mereka menginstal repositori artefak pada Nexus - ini adalah titik masuk tunggal untuk semua orang, bukan hanya CI.
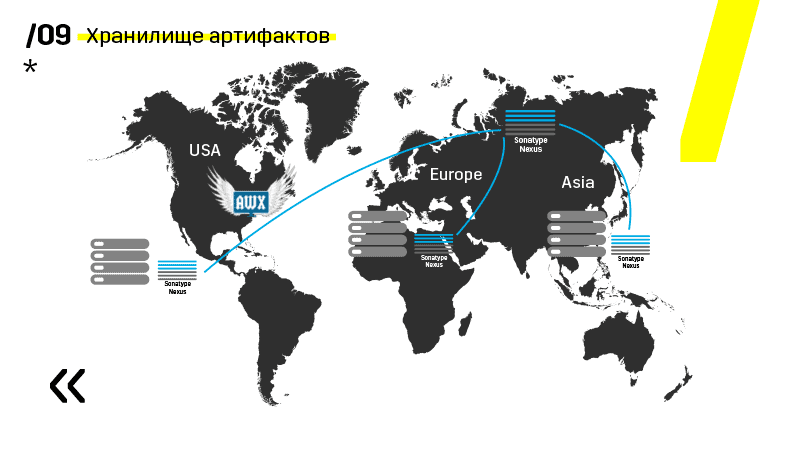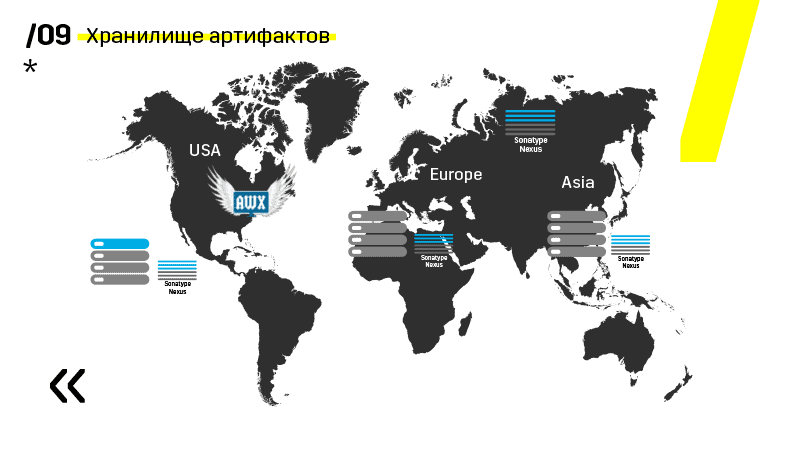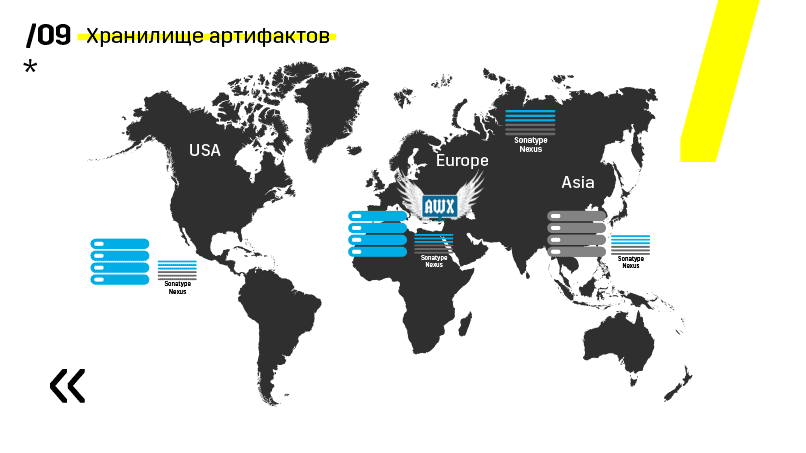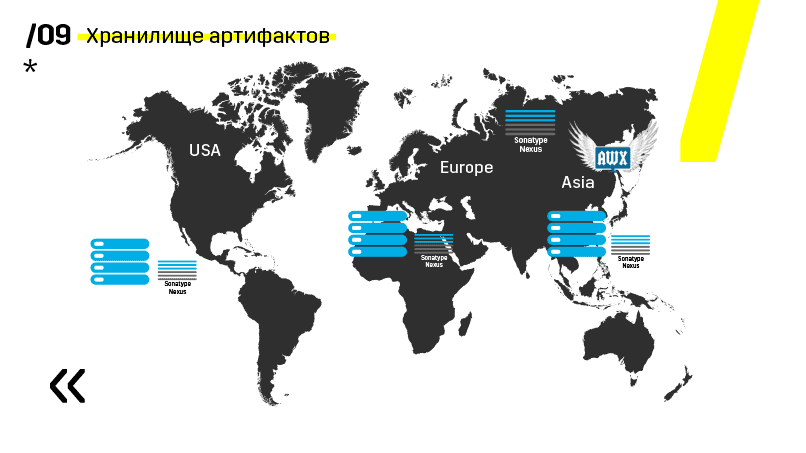
Dan itu sangat membantu kita untuk memastikan pengulangan. Yah, karena nexus dapat berfungsi sebagai layanan proxy di berbagai wilayah, mereka mempercepat penyebaran, pemasangan paket-paket rpm, gambar buruh pelabuhan, apa saja.
Ketika Anda meletakkan proyek baru, disarankan untuk memilih komponen yang mudah diotomatisasi. Misalnya, kami tidak berhasil dengan server Photon. Bagaimanapun, itu adalah solusi terbaik dalam hal lain. Tapi Cassandra, misalnya, sangat mudah diperbarui dan diotomatisasi.
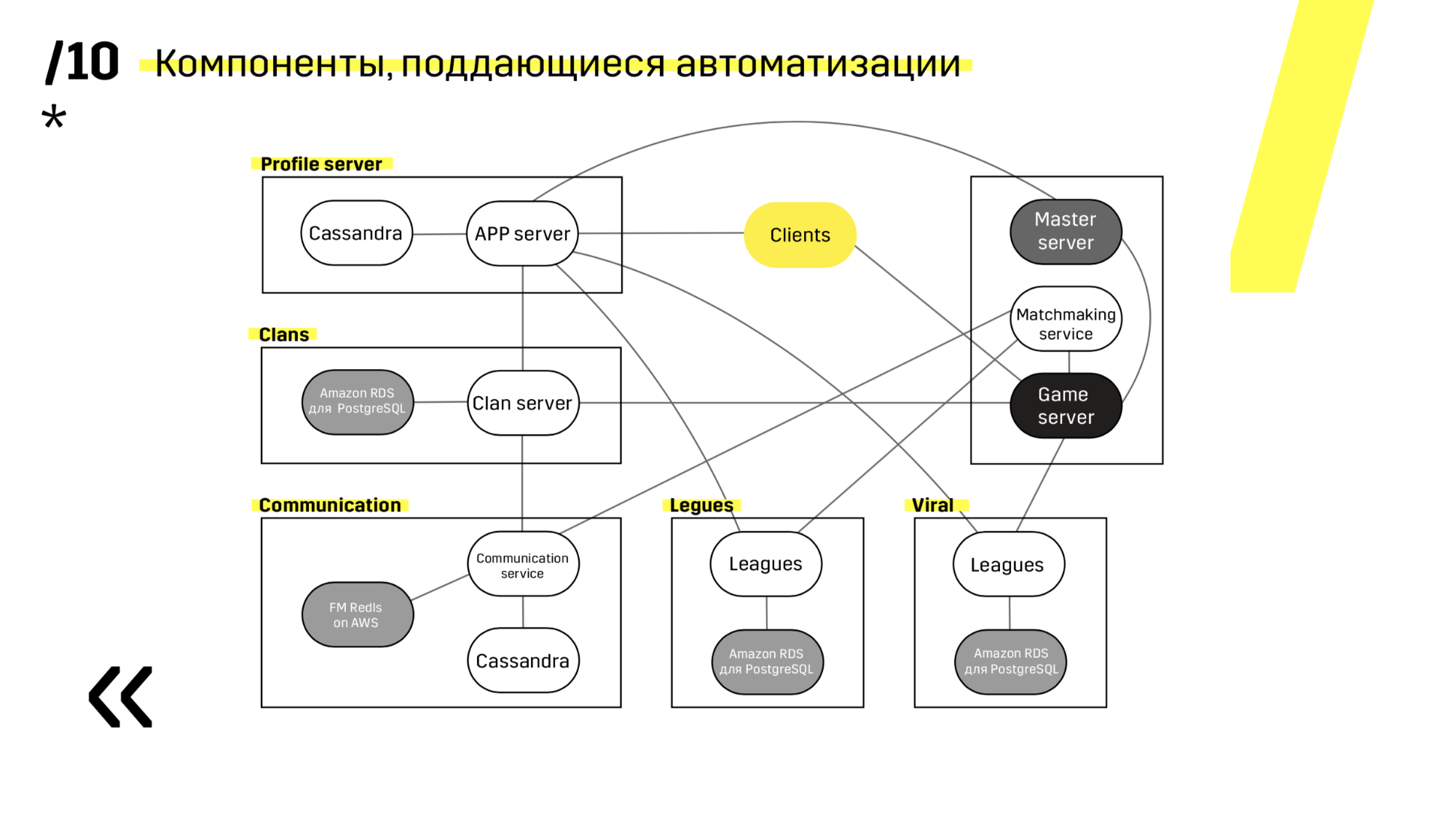
Ini adalah contoh dari salah satu proyek kami. Klien datang ke server APP, di mana ia memiliki profil di basis data Cassandra, dan kemudian pergi ke server master, yang dengan bantuan perjodohan memberinya server permainan dengan beberapa jenis ruang. Semua layanan lain dibuat dalam bentuk "aplikasi - database" dan diperbarui dengan cara yang persis sama.
Poin kedua - Anda perlu menyediakan arsitektur penyebaran yang sederhana dan longgar. Kami telah berhasil.
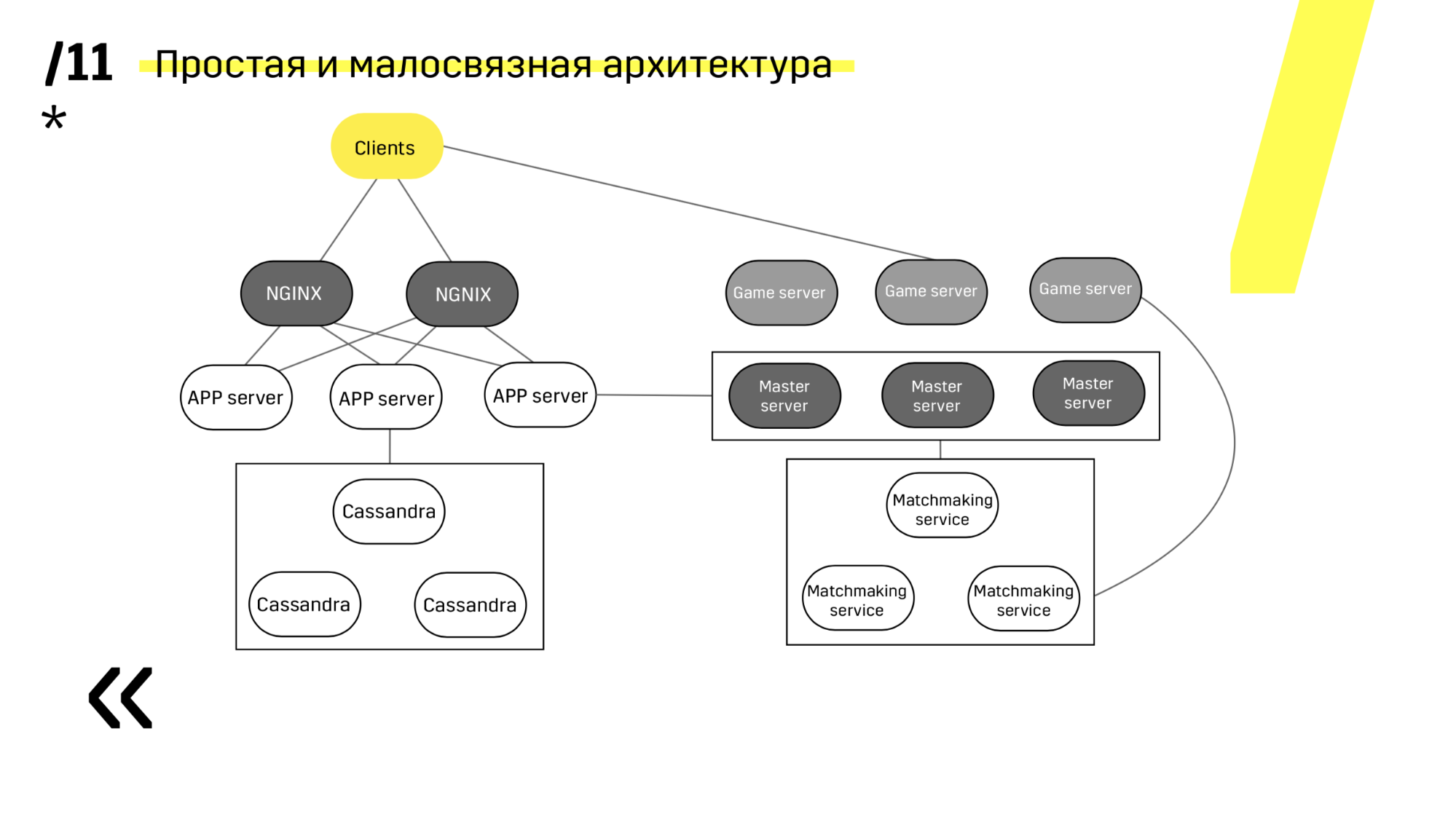
Lihat, memperbarui misalnya server aplikasi. Kami telah mendedikasikan layanan penemuan yang mengkonfigurasi ulang penyeimbang, jadi kami hanya pergi ke server aplikasi, memadamkannya, macet dari penyeimbangan, kami memperbarui semuanya. Demikian juga dengan masing-masing individu.
Server master diperbarui hampir secara identik. Klien ping setiap server master di wilayah tersebut dan pergi ke yang di mana ping lebih baik. Dengan demikian, jika kita memperbarui server master, maka mungkin gim akan berjalan sedikit lebih lambat, tetapi itu diperbarui dengan mudah dan sederhana.
Server gim diperbarui sedikit berbeda karena masih ada gim yang terjadi. Kami pergi menjodohkan, memintanya untuk melempar server tertentu dari saldo, datang ke server game, tunggu sampai game menjadi benar-benar nol, dan perbarui. Lalu kita kembali ke balancing.
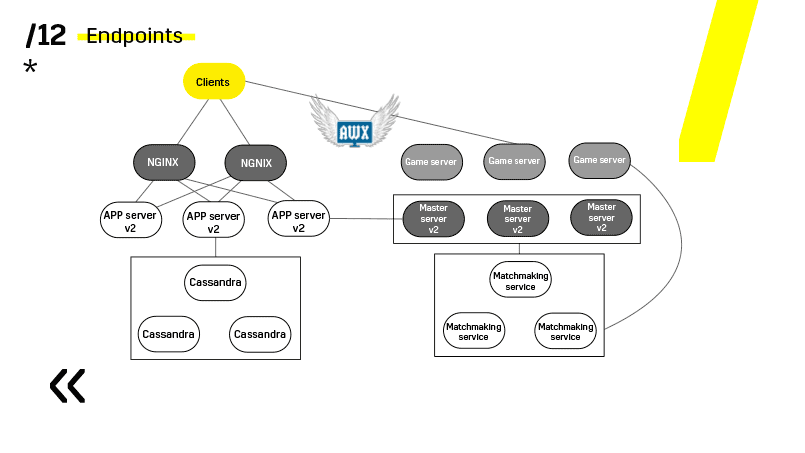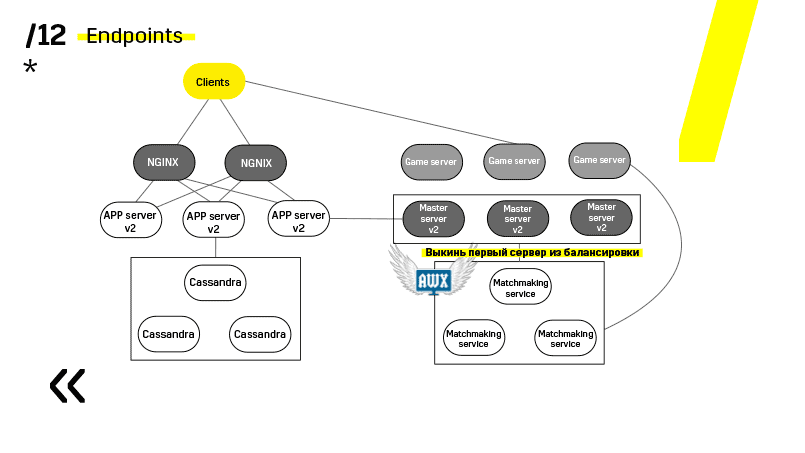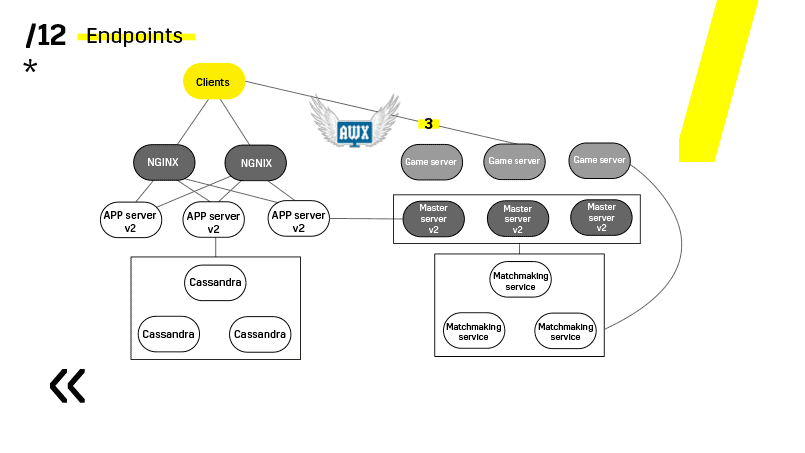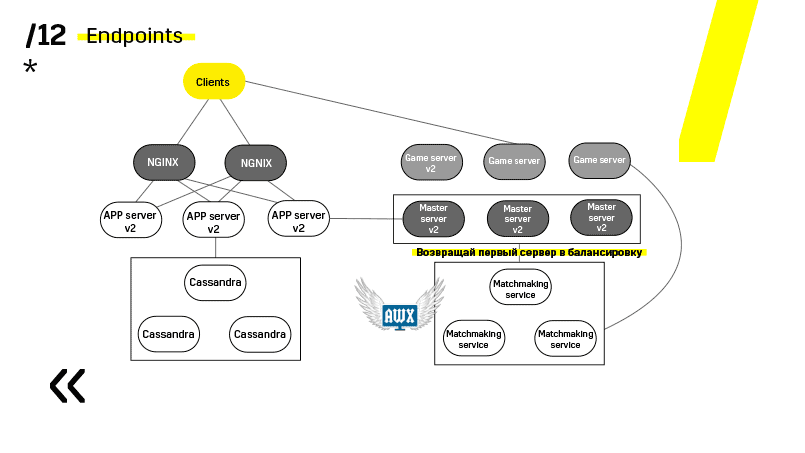
Poin kunci di sini adalah titik akhir yang dimiliki masing-masing komponen, dan yang dengannya mudah dan sederhana untuk berkomunikasi. Jika Anda memerlukan contoh, maka ada cluster Elasticsearch. Menggunakan permintaan http biasa di JSON, Anda dapat dengan mudah berkomunikasi dengannya. Dan dia langsung di JSON yang sama memberikan segala macam metrik dan informasi tingkat tinggi tentang klaster: hijau, kuning, merah.
Setelah menyelesaikan 12 langkah ini, kami meningkatkan jumlah lingkungan, mulai menguji lebih banyak, penyebaran dipercepat, orang-orang mulai menerima umpan balik cepat.

Yang sangat penting, kami mendapatkan kesederhanaan dan kecepatan percobaan. Dan ini sangat penting, karena ketika ada banyak percobaan, kita dapat dengan mudah menyaring ide-ide yang salah dan fokus pada yang benar. Dan bukan atas dasar penilaian subyektif, tetapi atas dasar indikator objektif.
Bahkan, saya tidak lagi mengikuti ketika kami memiliki penempatan di sana, saat rilis. Tidak ada "oh, lepaskan!" Merasa, semuanya berkumpul dan merinding. Sekarang ini adalah operasi rutin, saya secara berkala melihat di ruang obrolan bahwa ada sesuatu yang muncul, oke. Ini sangat keren. Administrator sistem Anda akan mengaum dengan gembira ketika Anda melakukannya.
Tetapi dunia tidak tinggal diam, terkadang memantul. Kami memiliki sesuatu untuk diperbaiki. Sebagai contoh, saya ingin meletakkan log build di Graylog juga. Ini akan membutuhkan penyempurnaan lebih lanjut dari penebangan sehingga tidak ada cerita yang terpisah, tetapi jelas: ini adalah bagaimana membangun itu dirakit, sehingga diuji, itu digunakan, dan berperilaku pada prod. Dan pemantauan terus menerus - ini adalah kisah yang lebih rumit.

Kami menggunakan Zabbix, dan dia sama sekali tidak siap untuk pendekatan seperti itu. Versi 4 akan segera dirilis, kami akan mencari tahu apa yang ada di sana dan jika semuanya buruk, maka kami akan datang dengan solusi yang berbeda. Saya akan memberi tahu Anda bagaimana hasilnya pada pertemuan berikutnya.
Pertanyaan dari audiens
Dan apa yang terjadi ketika Anda membuang sampah dalam produksi? Misalnya, Anda tidak menghitung sesuatu berdasarkan kinerja dan semuanya baik-baik saja pada integrasi, tetapi dalam produksi, lihat - server Anda mulai macet. Bagaimana Anda memutar kembali? Apakah ada tombol simpan saya?Kami mencoba melakukan otomatisasi rollback. Anda kemudian dapat berbicara tentang laporan tentang cara kerjanya yang keren, betapa indahnya semuanya. Tetapi pertama-tama, kami merancang agar versi-versi tersebut kompatibel dengan versi sebelumnya dan menguji ini. Dan ketika kami melakukan hal yang sepenuhnya otomatis ini, yang memeriksa sesuatu dan mengembalikannya, dan kemudian mulai hidup dengannya, kami menyadari bahwa kami berupaya lebih keras daripada jika kami hanya mengambil versi lama dengan pedal yang sama .
Mengenai pembaruan otomatis penyebaran: mengapa Anda membuat perubahan ke server saat ini, dan tidak menambahkan yang baru dan hanya menambahkannya ke grup target atau penyeimbang?Jadi lebih cepat.
Misalnya, jika Anda perlu memperbarui versi Java, Anda mengubah keadaan instance di Amazon, memperbarui versi Java atau yang lainnya, lalu bagaimana Anda memutar balik dalam kasus itu? Apakah Anda membuat perubahan pada server produksi?Ya, setiap komponen berfungsi dengan baik dengan versi yang baru dan yang lama. Ya, Anda mungkin harus memuat ulang server.
Ada perubahan kondisi saat masalah besar mungkin terjadi ...Lalu meledak.
Sepertinya saya menambahkan server baru dan hanya meletakkannya di grup target di grup target - tugas kecil dalam kompleksitas dan praktik yang cukup bagus.Kita dihosting di perangkat keras, bukan di awan. Kami dapat menambahkan server - itu mungkin, tetapi sedikit lebih lama daripada hanya mengklik di cloud. Oleh karena itu, kami mengambil server kami saat ini (kami tidak memiliki muatan sedemikian sehingga kami tidak dapat mengeluarkan beberapa mesin) - kami mengeluarkan beberapa mesin, memperbarui mereka, memasukkan lalu lintas penjualan di sana, melihat cara kerjanya, jika semuanya baik-baik saja, maka kami akan terus melakukan semuanya mobil lain.
Anda mengatakan jika setiap komit dikumpulkan dan jika semuanya buruk - pengembang segera mengatur semuanya. Apakah Anda mengerti bahwa semuanya buruk? Komitmen apa yang dilakukan?Biasanya, pada awalnya itu semacam pengujian manual, umpan baliknya lambat. Kemudian, dengan beberapa jenis tes otomatis pada Appium, semua ini dibahas, ia bekerja dan memberikan semacam umpan balik tentang apakah tes jatuh atau tidak jatuh.
Yaitu Pertama, setiap komit diluncurkan dan apakah para penguji memperhatikannya?Ya, tidak semua orang, ini adalah latihan. Kami membuat satu latihan dari 12 poin ini - dipercepat. Padahal, ini adalah kerja keras dan panjang, mungkin sepanjang tahun. Tapi idealnya Anda datang ke ini dan semuanya berfungsi. Ya, kami membutuhkan semacam uji otomatis, setidaknya satu set minimal, agar semuanya berfungsi untuk Anda.
Dan pertanyaannya lebih kecil: ada server aplikasi dalam gambar dan sebagainya, apakah itu yang menarik minat saya di sana? Anda mengatakan bahwa sepertinya Anda tidak memiliki Docker, apakah itu server? Jawa telanjang atau apa?Di suatu tempat ini adalah Photon pada Windows (server game), server App adalah aplikasi Java di Tomcat.
Yaitu tidak ada virtualoks, tidak ada wadah, tidak ada?Nah, Jawa bisa dibilang sebuah wadah.
Dan apakah semuanya berjalan dengan Ansible?Ya Yaitu pada saat tertentu, kami sama sekali tidak berinvestasi dalam orkestrasi, karena mengapa? Dalam hal apa pun Windows harus dikelola secara terpisah dengan cara yang sama, dan di sini semuanya tertutup dengan satu alat.
Dan bagaimana database digunakan? Ketergantungan pada komponen atau layanan?Ada skema dalam layanan itu sendiri yang akan digunakan ketika muncul dan perlu dikembangkan sehingga tidak ada yang dihapus, tetapi hanya ada sesuatu yang ditambahkan dan itu kompatibel ke belakang.
Apakah pangkalan Anda juga besi atau pangkalan di suatu tempat di awan di Amazon?Basis terbesar adalah besi, tetapi ada yang lain. Ada yang kecil, RDS tidak lagi besi, virtual. Layanan kecil yang saya perlihatkan: obrolan, liga, mengobrol dengan Facebook, klan, salah satunya adalah RDS.
Master server - seperti apa rasanya?Ini, pada kenyataannya, adalah server permainan yang sama, hanya dengan tanda master dan dia penyeimbang. Yaitu klien mengirim semua master, lalu menerima yang pingnya kurang, dan sudah menjadi server master dengan bantuan penjaruman mengumpulkan kamar di server game dan mengirimkan pemain.
Saya mengerti benar bahwa untuk setiap peluncuran yang Anda tulis (jika ada fitur yang muncul) migrasi untuk memperbarui data? Anda mengatakan bahwa Anda mengambil artefak lama dan mengisinya - apa yang terjadi pada data? Apakah Anda menulis migrasi untuk mengembalikan basis?Ini adalah operasi rollback yang sangat langka. Ya, Anda menulis migrasi pena, dan apa yang harus dilakukan.
Bagaimana pembaruan server disinkronkan dengan pembaruan klien? Yaitu Anda harus merilis versi baru gim - akankah Anda memperbarui semua server terlebih dahulu, kemudian klien akan diperbarui? Apakah server mendukung versi lama dan baru?Ya, kami sedang mengembangkan fitur c toggling dan fitur peredupan. Yaitu Ini adalah pegangan khusus, sebuah tuas yang memungkinkan Anda untuk mengaktifkan beberapa fitur nanti. Anda dapat memutakhirkan dengan sangat tenang, melihat bahwa semuanya bekerja untuk Anda, tetapi tidak menyertakan fitur ini. Dan ketika Anda telah menyebar klien, maka Anda dapat memperketat 10% dengan fiddimming, melihat bahwa semuanya baik-baik saja, dan kemudian sampai penuh.
Anda mengatakan bahwa Anda telah secara terpisah menyimpan bagian-bagian dari proyek di repositori yang berbeda, yaitu apakah Anda memiliki semacam proses pengembangan? Jika Anda mengubah proyek itu sendiri, maka tes Anda akan jatuh karena Anda mengubah proyek itu. Jadi tes yang terletak secara terpisah perlu diperbaiki secepat mungkin.Saya katakan tentang paus "interaksi erat dengan penguji." Skema dengan repositori yang berbeda ini bekerja sangat baik hanya jika ada komunikasi yang sangat padat. Ini bukan masalah bagi kami, semua orang mudah berkomunikasi satu sama lain, ada komunikasi yang baik.
Yaitu apakah penguji mendukung repositori tes di tim Anda? Dan autotest terletak secara terpisah?Ya Anda membuat beberapa fitur dan Anda dapat mengumpulkan autotest yang Anda butuhkan dari repositori penguji, dan tidak memeriksa yang lainnya.
Pendekatan seperti itu, ketika semuanya dengan cepat bergulir - Anda mampu untuk segera pergi ke prod untuk setiap komit. Apakah Anda mengikuti taktik seperti itu atau membuat beberapa rilis? Yaitu sekali seminggu, bukan pada hari Jumat, bukan pada akhir pekan, apakah Anda memiliki taktik rilis atau apakah fitur siap, dapatkah saya melepaskannya? Karena jika Anda membuat rilis kecil dari fitur-fitur kecil, maka Anda kecil kemungkinannya bahwa semuanya akan rusak, dan jika sesuatu rusak, maka Anda pasti tahu apa.Memaksa pengguna klien untuk mengunduh versi baru setiap lima menit atau setiap hari bukanlah ide yang bagus. Bagaimanapun, Anda akan dilampirkan ke klien. Sangat bagus ketika Anda memiliki proyek web di mana Anda dapat memperbarui setidaknya setiap hari dan tidak perlu melakukan apa pun. Ceritanya lebih rumit dengan klien, kami memiliki semacam taktik rilis dan kami berpegang teguh pada itu.
Anda berbicara tentang meluncurkan otomatisasi ke server produk, dan (seperti yang saya mengerti) ada juga meluncurkan otomatisasi untuk pengujian - bagaimana dengan lingkungan pengembang? Apakah ada otomatisasi yang digunakan oleh pengembang?Hal yang hampir sama. Satu-satunya hal yang bukan server besi, tetapi di mesin virtual, tetapi esensinya hampir sama. Pada saat yang sama, pada Ansible yang sama, kami menulis (kami memiliki Ovirt) pembuatan mesin virtual ini dan knurling di atasnya.
Apakah Anda memiliki keseluruhan cerita yang disimpan dalam satu proyek bersama-sama dengan prod dan konfigurasi yang mungkin, atau apakah itu hidup dan berkembang secara terpisah?Kita dapat mengatakan bahwa ini adalah proyek terpisah. Dev (kami menyebutnya devbox) adalah cerita ketika semuanya ada dalam satu paket, dan pada prod itu adalah cerita yang didistribusikan.
Lebih banyak pembicaraan dengan Pixonic DevGAMM Talks