Hampir semua karyawan Yandex baru kagum pada besarnya tekanan yang dialami produk kami. Ribuan host dengan ratusan ribu permintaan per detik. Dan ini hanyalah salah satu layanan. Pada saat yang sama, kita harus menanggapi permintaan dalam sepersekian detik. Bahkan sedikit perubahan pada produk dapat memiliki dampak signifikan pada kinerja, jadi penting untuk menguji dan mengevaluasi dampak kode Anda pada layanan.
Dalam layanan kami tentang teknologi periklanan, pengujian bekerja dalam kerangka metodologi integrasi berkelanjutan, yang akan kami diskusikan secara lebih rinci tentang organisasi pada tanggal 25 Oktober di acara Yandex dari dalam , dan hari ini kami akan berbagi dengan pembaca Habr pengalaman mengotomatisasi evaluasi metrik produk penting yang terkait dengan kinerja layanan. Anda akan belajar cara mempercayakan analisis ke mesin, dan tidak mengikutinya pada grafik. Ayo pergi!

Ini bukan tentang cara menguji situs. Ada banyak alat online untuk ini. Hari ini kita akan berbicara tentang layanan backend internal yang sangat dimuat, yang merupakan bagian dari sistem besar dan menyiapkan informasi untuk layanan eksternal. Dalam kasus kami, untuk halaman hasil pencarian dan situs mitra. Jika komponen kami tidak punya waktu untuk merespons, maka informasi darinya tidak akan diberikan kepada pengguna. Jadi, perusahaan akan kehilangan uang. Karena itu, sangat penting untuk merespons tepat waktu.
Metrik server penting apa yang dapat disorot?
- Permintaan per detik (RPS) . Kebahagiaan satu pengguna, tentu saja, penting bagi kami. Tetapi bagaimana jika bukan satu, tetapi ribuan pengguna mendatangi Anda. Berapa banyak permintaan per detik yang dapat ditahan server Anda dan tidak jatuh?
- Waktu per permintaan . Konten situs harus diberikan secepat mungkin sehingga pengguna tidak bosan menunggu, dan dia tidak pergi ke toko untuk membeli popcorn. Dalam kasus kami, dia tidak akan melihat bagian penting dari informasi di halaman.
- Resident set size (RSS) . Pastikan untuk memantau seberapa banyak program Anda menggunakan memori. Jika layanan memakan semua memori, hampir tidak mungkin untuk berbicara tentang toleransi kesalahan.
- Kesalahan HTTP .
Jadi mari kita selesaikan.
Minta per detik
Pengembang kami, yang telah berurusan dengan pengujian beban untuk waktu yang lama, suka berbicara tentang sumber daya kritis sistem. Mari kita lihat apa itu.
Setiap sistem memiliki karakteristik konfigurasi sendiri yang menentukan operasi. Misalnya, panjang antrian, batas waktu respons, kumpulan pekerja thread, dll. Dan mungkin saja kapasitas layanan Anda bergantung pada salah satu sumber daya ini. Anda dapat melakukan percobaan. Tingkatkan setiap sumber daya secara bergantian. Sumber daya, peningkatan yang akan meningkatkan kapasitas layanan Anda, akan sangat penting bagi Anda. Dalam sistem yang dikonfigurasikan dengan baik, untuk meningkatkan kapasitas, Anda harus menambah bukan hanya satu sumber daya, tetapi beberapa. Tapi ini masih bisa "dirasakan". Akan sangat bagus jika Anda dapat mengkonfigurasi sistem Anda sehingga semua sumber daya bekerja dengan kekuatan penuh, dan layanan sesuai dengan kerangka waktu yang diberikan kepadanya.
Untuk memperkirakan berapa banyak permintaan per detik yang dapat ditahan server Anda, Anda perlu mengarahkan aliran permintaan ke sana. Karena kami memiliki proses ini dibangun ke dalam sistem CI, kami menggunakan "pistol" yang sangat sederhana dengan fungsi terbatas. Tetapi dari perangkat lunak sumber terbuka Yandex.Tank sangat cocok untuk tugas ini. Dia memiliki dokumentasi terperinci. Hadiah untuk Tank adalah layanan untuk melihat hasilnya.
Sebuah offtop kecil. Yandex.Tank memiliki fungsionalitas yang cukup kaya, tidak terbatas pada permintaan shelling otomatis. Ini juga akan membantu untuk mengumpulkan metrik layanan Anda, membuat grafik dan mengencangkan modul dengan logika yang Anda butuhkan. Secara umum, kami sangat merekomendasikan untuk mengenalnya.
Sekarang Anda perlu memberi makan permintaan ke Tank sehingga mereka dapat menembak layanan kami. Permintaan yang Anda gunakan untuk meng-shell server bisa dari jenis yang sama, dibuat dan diperbanyak secara buatan. Namun, pengukuran akan jauh lebih akurat jika Anda dapat mengumpulkan kumpulan permintaan nyata dari pengguna untuk periode waktu tertentu.
Kapasitas dapat diukur dengan dua cara.
Model beban terbuka (stress testing)
Buat "pengguna", yaitu, beberapa utas yang akan mengirim permintaan ke sistem Anda. Beban yang tidak akan kami berikan adalah konstan, tetapi menumpuk atau bahkan memberinya makan dalam gelombang. Maka itu akan membawa kita lebih dekat ke kehidupan nyata. Kami meningkatkan RPS dan menangkap titik di mana layanan yang dikupas "menerobos" SLA. Dengan demikian, Anda dapat menemukan batasan sistem.
Untuk menghitung jumlah pengguna, Anda dapat menggunakan rumus Little (Anda dapat membacanya di sini ). Menghilangkan teorinya, rumusnya terlihat seperti ini:
RPS = 1000 / T * pekerja, di mana
• T - waktu rata-rata pemrosesan permintaan (dalam milidetik);
• pekerja - jumlah utas;
• 1000 / T permintaan per detik - nilai ini akan dihasilkan oleh generator single-threaded.
Model beban tertutup (uji beban)
Kami mengambil sejumlah "pengguna" tetap. Anda perlu mengkonfigurasinya sehingga antrian input yang sesuai dengan konfigurasi layanan Anda selalu tersumbat. Pada saat yang sama, tidak masuk akal untuk membuat jumlah utas lebih besar dari batas antrian, karena kita akan bertumpu pada nomor ini, dan permintaan yang tersisa akan dibuang oleh server dengan kesalahan 5xx. Kami melihat berapa banyak permintaan per detik yang dapat dikeluarkan desain. Skema seperti itu dalam kasus umum tidak mirip dengan aliran permintaan yang sebenarnya, tetapi akan membantu untuk menunjukkan perilaku sistem pada beban maksimum dan mengevaluasi throughput saat ini.
Untuk sebagian besar sistem (di mana sumber daya kritis tidak terkait dengan pemrosesan koneksi), hasilnya akan sama. Pada saat yang sama, model tertutup memiliki lebih sedikit noise, karena sistem berada dalam area beban yang menarik bagi kami sepanjang waktu pengujian.
Saat menguji layanan kami, kami menggunakan model tertutup. Setelah penembakan, pistol memberi kami berapa banyak permintaan per detik yang dapat dikeluarkan layanan kami. Yandex.Tank indikator ini juga mudah diceritakan.
Waktu per permintaan
Jika kita kembali ke paragraf sebelumnya, menjadi jelas bahwa dengan skema seperti itu, tidak masuk akal untuk mengevaluasi waktu respons terhadap permintaan. Semakin kuat kita memuat sistem, semakin akan terdegradasi dan semakin lama akan merespons. Oleh karena itu, untuk menguji waktu respons, pendekatannya harus berbeda.
Untuk mendapatkan waktu respons rata-rata, kami akan menggunakan Yandex.Tank yang sama. Hanya sekarang kami akan menetapkan RPS yang sesuai dengan indikator rata-rata sistem Anda dalam produksi. Setelah penembakan kita mendapatkan waktu respons untuk setiap permintaan. Berdasarkan data yang dikumpulkan, persentil waktu respons dapat dihitung.
Selanjutnya Anda perlu memahami persentil apa yang kami anggap penting. Sebagai contoh, kami membangun berdasarkan produksi. Kami dapat meninggalkan 1% dari permintaan untuk kesalahan, non-jawaban, permintaan debugging yang bekerja untuk waktu yang lama, masalah dengan jaringan, dll. Oleh karena itu, kami menganggap penting waktu respons, yang mengakomodasi 99% permintaan.
Resident mengatur ukuran
Server kami langsung bekerja dengan file melalui mmap . Mengukur indeks RSS, kami ingin tahu berapa banyak memori yang diambil program dari sistem operasi selama operasi.
Di Linux, file / proc / PID / smaps ditulis - ini adalah ekstensi berbasis peta yang menunjukkan konsumsi memori untuk setiap pemetaan proses. Jika proses Anda menggunakan tmpfs, maka memori anonim dan non-anonim akan bertabrakan. Memori non-anonim mencakup, misalnya, file yang dimuat ke dalam memori. Berikut adalah contoh entri di smaps. File tertentu ditentukan, dan parameternya Anonim = 0kB.
7fea65a60000-7fea65a61000 r--s 00000000 09:03 79169191 /place/home/.../some.yabs Size: 4 kB Rss: 4 kB Pss: 4 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 4 kB Private_Dirty: 0 kB Referenced: 4 kB Anonymous: 0 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd mr me ms
Dan ini adalah contoh alokasi memori anonim. Ketika suatu proses (mmap yang sama) membuat permintaan ke sistem operasi untuk mengalokasikan ukuran memori tertentu, alamat dialokasikan untuk itu. Sementara prosesnya hanya memakan memori virtual. Pada titik ini, kita belum tahu bagian memori mana yang akan dialokasikan. Kami melihat catatan tanpa nama. Ini adalah contoh alokasi memori anonim. Sistem diminta ukuran 24572 kB, tetapi mereka tidak menggunakannya dan sebenarnya hanya RSS = 4 kB yang diambil.
7fea67264000-7fea68a63000 rw-p 00000000 00:00 0 Size: 24572 kB Rss: 4 kB Pss: 4 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 4 kB Referenced: 4 kB Anonymous: 4 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd wr mr mw me ac
Karena memori non-anonim yang dialokasikan tidak akan pergi ke mana pun setelah proses dihentikan, file tidak akan dihapus, kami tidak tertarik dengan RSS tersebut.
Sebelum Anda mulai memotret di server, kami merangkum RSS dari / proc / PID / smaps, dialokasikan untuk memori anonim, dan mengingatnya. Kami melakukan penembakan, mirip dengan waktu pengujian per permintaan. Setelah selesai, pertimbangkan RSS lagi. Perbedaan antara kondisi awal dan akhir adalah jumlah memori yang digunakan proses Anda selama operasi.
Kesalahan HTTP
Jangan lupa untuk mengikuti kode respons yang dikembalikan layanan selama pengujian. Jika ada sesuatu dalam pengaturan pengujian atau lingkungan yang salah, dan server mengembalikan kesalahan 5xx dan 4xx untuk semua permintaan Anda, maka tidak banyak gunanya dalam pengujian semacam itu. Kami memantau proporsi tanggapan buruk. Jika ada banyak kesalahan, maka tes tersebut dianggap tidak valid.
Sedikit tentang akurasi pengukuran
Dan sekarang yang paling penting. Mari kita kembali ke paragraf sebelumnya. Nilai absolut dari metrik yang dihitung oleh kami, ternyata, tidak begitu penting bagi kami. Tidak, tentu saja, Anda dapat mencapai stabilitas indikator, dengan mempertimbangkan semua faktor, kesalahan, dan fluktuasi. Secara paralel, tulis karya ilmiah tentang topik ini (ngomong-ngomong, jika seseorang mencari satu, ini mungkin pilihan yang baik). Tapi ini bukan yang menarik minat kita.
Penting bagi kita untuk mempengaruhi komit spesifik pada kode relatif terhadap kondisi sistem sebelumnya. Artinya, perbedaan antara metrik dari komit ke komit adalah penting. Dan di sini perlu untuk mengatur proses yang akan membandingkan perbedaan ini dan pada saat yang sama memastikan stabilitas nilai absolut dalam interval ini.
Lingkungan, permintaan, data, status layanan - semua faktor yang tersedia untuk kita harus diperbaiki. Sistem inilah yang berfungsi bagi kami sebagai bagian dari integrasi berkelanjutan, yang memberi kami informasi tentang semua jenis perubahan yang terjadi dalam setiap komit. Meskipun demikian, tidak akan mungkin untuk memperbaiki semuanya, akan ada kebisingan. Kita dapat mengurangi kebisingan, jelas, dengan menambah sampel, yaitu, membuat beberapa iterasi pengambilan gambar. Selanjutnya, setelah memotret, katakanlah, 15 iterasi, kita dapat menghitung median dari sampel yang dihasilkan. Selain itu, perlu untuk menemukan keseimbangan antara kebisingan dan durasi pemotretan. Sebagai contoh, kami menyelesaikan kesalahan 1%. Jika Anda ingin memilih metode statistik yang lebih kompleks dan akurat sesuai dengan kebutuhan Anda, kami merekomendasikan buku yang mencantumkan opsi dengan deskripsi kapan dan mana yang digunakan.
Apa lagi yang bisa dilakukan dengan kebisingan?
Perhatikan bahwa lingkungan tempat Anda melakukan tes memainkan peran penting dalam pengujian tersebut. Bangku tes harus andal, tidak boleh menjalankan program lain, karena dapat menyebabkan penurunan layanan Anda. Selain itu, hasilnya dapat dan akan tergantung pada profil beban, lingkungan, basis data, dan berbagai "badai magnetik".
Sebagai bagian dari tes komit tunggal, kami melakukan beberapa iterasi pada host yang berbeda. Pertama, jika Anda menggunakan cloud, maka apa pun bisa terjadi di sana. Sekalipun cloud itu khusus, seperti milik kami, proses layanan masih berfungsi di sana. Karenanya, Anda tidak dapat mengandalkan hasil dari satu host. Dan jika Anda memiliki inang besi, di mana tidak ada, seperti di awan, mekanisme standar untuk meningkatkan lingkungan, maka Anda bahkan dapat secara tidak sengaja memecahkannya sekali dan membiarkannya seperti itu. Dan dia akan selalu berbohong padamu. Karena itu, kami mengendarai pengujian kami di cloud.
Benar, pertanyaan lain muncul dari ini. Jika pengukuran Anda dilakukan setiap kali pada host yang berbeda, maka hasilnya dapat membuat sedikit kebisingan dan karena ini termasuk. Kemudian Anda dapat menormalkan bacaan ke host. Yaitu, menurut data historis, kumpulkan "koefisien tuan rumah" dan memperhitungkannya ketika menganalisis hasilnya.
Analisis data historis menunjukkan bahwa perangkat kerasnya berbeda. Kata "perangkat keras" di sini termasuk versi kernel dan konsekuensi dari uptime (tampaknya, objek kernel tidak bergerak dalam memori).
Jadi, untuk setiap "host" (saat reboot, host "mati" dan "baru" muncul) kami mengasosiasikan koreksi yang dengannya kami melipatgandakan RPS sebelum agregasi.
Kami mempertimbangkan dan memperbarui amandemen dengan cara yang sangat kikuk, mencurigakan mengingatkan pada beberapa opsi pelatihan penguatan.
Untuk vektor koreksi posthost tertentu, kami mempertimbangkan fungsi tujuan:
- dalam setiap tes kami mempertimbangkan standar deviasi dari hasil RPS "dikoreksi" yang diperoleh
- ambil rata-rata dari mereka dengan bobot yang sama ,
- kami punya tau = 1 minggu.
Kemudian kami memperbaiki satu koreksi (untuk host yang jumlah bobotnya adalah yang terbesar), memperbaikinya pada 1.0 dan mencari nilai-nilai semua koreksi lainnya yang memberikan minimum fungsi objektif.
Untuk memvalidasi hasil pada data historis, kami mempertimbangkan koreksi pada data lama, kami mempertimbangkan hasil yang diperbaiki pada yang baru, dibandingkan dengan yang tidak dikoreksi.
Pilihan lain untuk menyesuaikan hasil dan mengurangi kebisingan adalah normalisasi menjadi "sintetis." Sebelum memulai layanan untuk diuji, jalankan "program sintetis" pada host, dari mana Anda dapat mengevaluasi keadaan host dan menghitung faktor koreksi. Tetapi dalam kasus kami, kami menggunakan koreksi berbasis host, dan ide ini tetap merupakan ide. Mungkin salah satu dari Anda akan menyukainya.
Terlepas dari otomatisasi dan semua kelebihannya, jangan lupakan dinamika indikator Anda. Penting untuk memastikan bahwa layanan tidak menurun seiring waktu. Anda mungkin tidak melihat drawdown kecil, mereka dapat menumpuk, dan dalam jangka waktu yang lama, indikator Anda mungkin melorot. Berikut adalah contoh grafik kami yang kami lihat di RPS. Ini menunjukkan nilai relatif pada setiap komit yang diperiksa, jumlahnya dan kemampuan untuk melihat dari mana rilis tersebut dialokasikan.
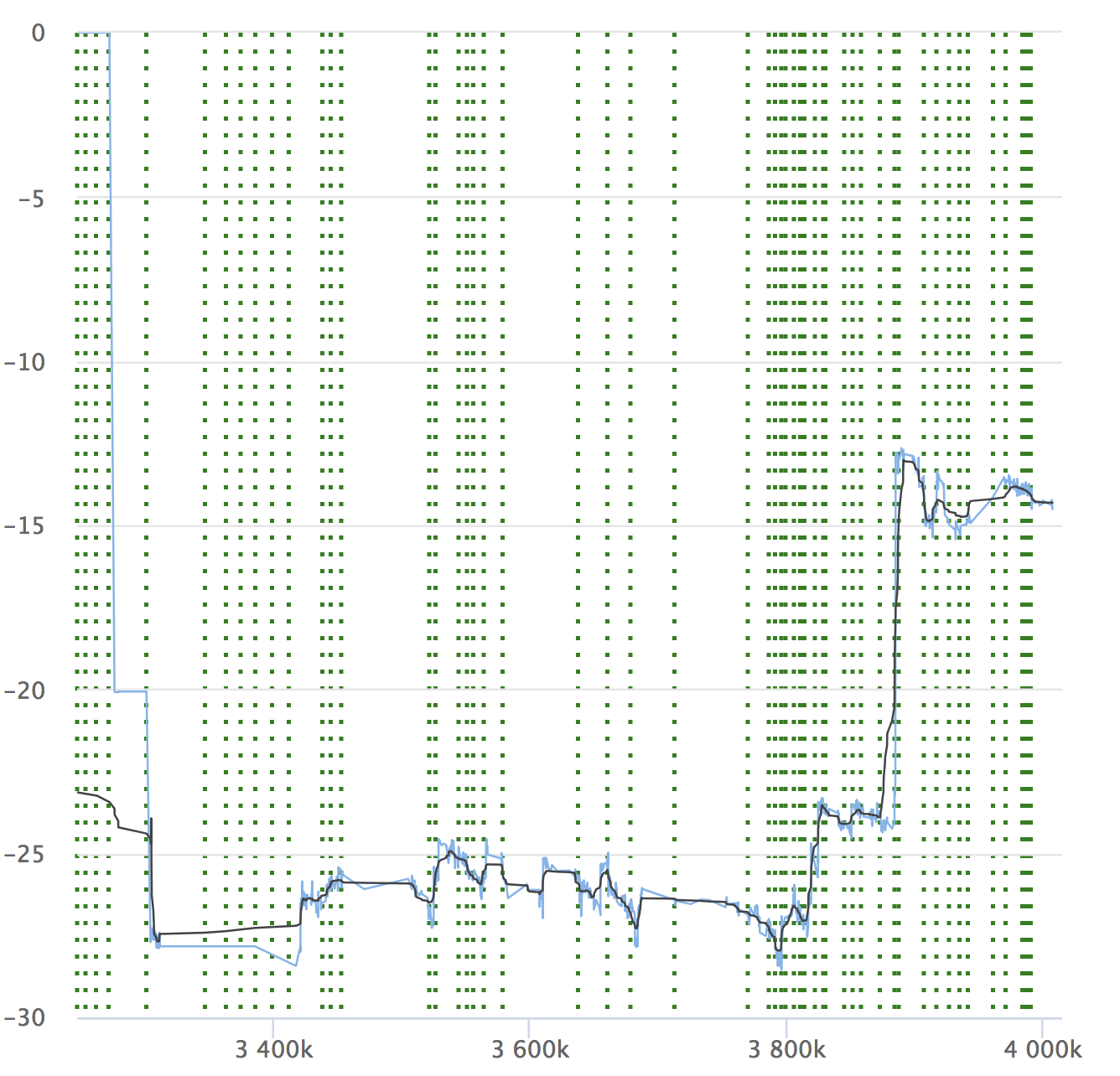
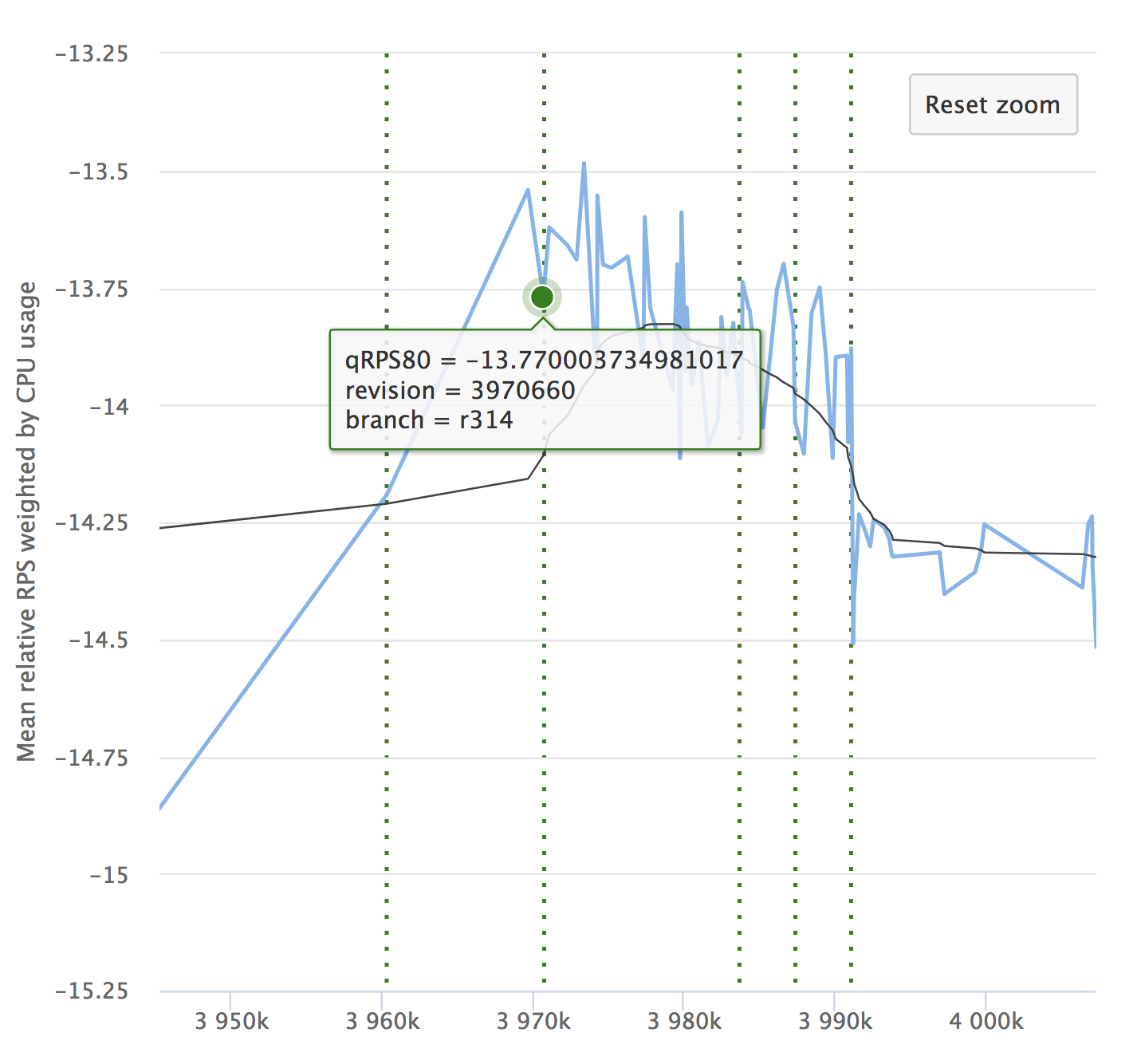
Jika Anda membaca artikel tersebut, maka pasti akan menarik bagi Anda untuk melihat laporan tentang Yandex.Tank dan analisis hasil pengujian beban.
Kami juga mengingatkan Anda bahwa secara lebih rinci tentang organisasi integrasi Berkelanjutan kami akan berbicara tentang 25 Oktober di acara Yandex dari dalam . Datang untuk mengunjungi!