 Mesin Pembelajaran Lengkap Walk-Through dengan Python: Bagian Dua
Mesin Pembelajaran Lengkap Walk-Through dengan Python: Bagian DuaMenyusun semua bagian dari proyek pembelajaran mesin bisa rumit. Dalam seri artikel ini, kita akan melewati semua tahap implementasi proses pembelajaran mesin menggunakan data nyata, dan mencari tahu bagaimana berbagai teknik digabungkan satu sama lain.
Pada
artikel pertama, kami membersihkan dan menyusun data, melakukan analisis eksplorasi, mengumpulkan serangkaian atribut untuk digunakan dalam model, dan menetapkan garis dasar untuk mengevaluasi hasil. Dengan bantuan artikel ini kita akan belajar bagaimana menerapkan dalam Python dan membandingkan beberapa model pembelajaran mesin, melakukan penyetelan hyperparametric untuk mengoptimalkan model terbaik, dan mengevaluasi kinerja model akhir pada set data uji.
Semua kode proyek ada
di GitHub , dan ini adalah buku catatan kedua yang terkait dengan artikel saat ini. Anda dapat menggunakan dan memodifikasi kode sesuai keinginan!
Evaluasi Model dan Seleksi
Memo: Kami sedang mengerjakan tugas regresi terkontrol, menggunakan
informasi energi untuk bangunan di New York untuk membuat model yang memprediksi
Skor Bintang Energi mana yang akan diterima gedung tertentu. Kami tertarik pada keakuratan peramalan dan interpretabilitas model.
Hari ini Anda dapat memilih dari
banyak model pembelajaran mesin yang tersedia , dan kelimpahan ini bisa menakutkan. Tentu saja, ada
ulasan perbandingan pada jaringan yang akan membantu Anda menavigasi ketika memilih suatu algoritma, tetapi saya lebih suka untuk mencoba beberapa dan melihat mana yang lebih baik. Untuk sebagian besar, pembelajaran mesin didasarkan pada hasil
empiris daripada teoritis , dan hampir
tidak mungkin untuk memahami terlebih dahulu model mana yang lebih akurat .
Biasanya disarankan agar Anda mulai dengan model yang sederhana dan dapat ditafsirkan, seperti regresi linier, dan jika hasilnya tidak memuaskan, kemudian beralih ke metode yang lebih kompleks, tetapi biasanya lebih akurat. Grafik ini (sangat anti-ilmiah) menunjukkan hubungan antara akurasi dan interpretabilitas dari beberapa algoritma:
 Interpretabilitas dan akurasi ( Sumber ).
Interpretabilitas dan akurasi ( Sumber ).Kami akan mengevaluasi lima model dengan berbagai tingkat kompleksitas:
- Regresi linier.
- Metode tetangga terdekat k.
- "Hutan acak."
- Meningkatkan gradien.
- Metode vektor dukungan.
Kami tidak akan mempertimbangkan aparatur teoritis dari model ini, tetapi implementasinya. Jika Anda tertarik pada teori, lihat
Pengantar Pembelajaran Statistik (tersedia gratis) atau
Pembelajaran Mesin Langsung dengan Scikit-Learn dan TensorFlow . Dalam kedua buku, teorinya dijelaskan dengan sempurna dan efektivitas penggunaan metode yang disebutkan dalam bahasa R dan Python, masing-masing, ditampilkan.
Isi nilai yang hilang
Meskipun ketika kami membersihkan data, kami membuang kolom di mana lebih dari setengah nilai hilang, kami masih memiliki banyak nilai. Model pembelajaran mesin tidak dapat bekerja dengan data yang hilang, jadi kita perlu
mengisinya .
Pertama, kami mempertimbangkan data dan mengingat tampilannya:
import pandas as pd import numpy as np
Setiap nilai
NaN adalah catatan yang hilang dalam data.
Anda dapat mengisinya dengan cara yang berbeda , dan kami akan menggunakan metode imputasi median yang cukup sederhana, yang menggantikan data yang hilang dengan nilai rata-rata untuk kolom yang sesuai.
Dalam kode di bawah ini, kita akan membuat objek
Scikit-Learn Imputer dengan strategi median. Kemudian kami melatihnya pada data pelatihan (menggunakan
imputer.fit ), dan menerapkannya untuk mengisi nilai-nilai yang hilang dalam set pelatihan dan tes (menggunakan
imputer.transform ). Artinya, catatan yang hilang dalam
data uji akan diisi dengan nilai median yang sesuai dari
data pelatihan .
Kami mengisi dan tidak melatih model pada data sebagaimana adanya, untuk menghindari masalah
kebocoran data uji ketika informasi dari dataset uji masuk ke pelatihan.
Sekarang semua nilai diisi, tidak ada celah.
Penskalaan Fitur
Penskalaan adalah proses umum untuk mengubah rentang karakteristik.
Ini adalah langkah yang perlu , karena tanda-tanda diukur dalam unit yang berbeda, yang berarti mereka mencakup rentang yang berbeda. Ini sangat mendistorsi hasil algoritma seperti metode
vektor dukungan dan metode tetangga k-terdekat, yang memperhitungkan jarak antara pengukuran. Dan penskalaan memungkinkan Anda untuk menghindari ini. Meskipun metode seperti
regresi linier dan "hutan acak" tidak memerlukan penskalaan fitur, lebih baik untuk tidak mengabaikan langkah ini ketika membandingkan beberapa algoritma.
Kami akan skala menggunakan setiap atribut ke rentang dari 0 hingga 1. Kami mengambil semua nilai atribut, pilih minimum dan membaginya dengan perbedaan antara maksimum dan minimum (rentang). Metode penskalaan ini sering disebut
normalisasi, dan cara utama lainnya adalah standardisasi .
Proses ini mudah diterapkan secara manual, jadi kami
MinMaxScaler menggunakan objek MinMaxScaler dari Scikit-Learn. Kode untuk metode ini identik dengan kode untuk mengisi nilai yang hilang, hanya penskalaan yang digunakan alih-alih menempel. Ingat bahwa kita mempelajari model hanya pada set pelatihan, dan kemudian kita mengubah semua data.
Sekarang, setiap atribut memiliki nilai minimum 0, dan maksimum 1. Mengisi nilai-nilai yang hilang dan penskalaan atribut - dua tahap ini diperlukan di hampir semua proses pembelajaran mesin.
Kami menerapkan model pembelajaran mesin di Scikit-Learn
Setelah semua pekerjaan persiapan, proses membuat, melatih, dan menjalankan model relatif sederhana. Kita akan menggunakan
pustaka Scikit-Learn dalam Python, yang didokumentasikan dengan indah dan dengan sintaksis yang rumit untuk membangun model. Dengan mempelajari cara membuat model di Scikit-Learn, Anda dapat dengan cepat mengimplementasikan semua jenis algoritma.
Kami akan mengilustrasikan proses penciptaan, pelatihan (
.fit ) dan pengujian (
.predict ) menggunakan gradient boosting:
from sklearn.ensemble import GradientBoostingRegressor
Hanya satu baris kode untuk membuat, melatih, dan menguji. Untuk membangun model lain, kami menggunakan sintaks yang sama, hanya mengubah nama algoritma.

Untuk mengevaluasi model secara objektif, kami menghitung level dasar menggunakan nilai median tujuan dan mendapat 24,5. Dan hasilnya jauh lebih baik, sehingga masalah kita dapat diselesaikan dengan menggunakan pembelajaran mesin.
Dalam kasus kami,
peningkatan gradien (MAE = 10.013) ternyata sedikit lebih baik daripada "hutan acak" (10.014 MAE). Meskipun hasil ini tidak dapat dianggap sepenuhnya jujur, karena untuk hyperparameter kami lebih banyak menggunakan nilai default. Keefektifan model sangat tergantung pada pengaturan ini,
terutama dalam metode vektor dukungan . Namun demikian, berdasarkan hasil ini, kami akan memilih peningkatan gradien dan mulai mengoptimalkannya.
Optimalisasi model hyperparametric
Setelah memilih model, Anda dapat mengoptimalkannya agar tugas dapat diselesaikan dengan menyesuaikan parameter hiper.
Tapi pertama-tama, mari kita pahami
apa itu hyperparameters dan bagaimana mereka berbeda dari parameter biasa ?
- Hyperparameters model dapat dianggap sebagai pengaturan algoritma, yang kami atur sebelum dimulainya pelatihannya. Misalnya, hyperparameter adalah jumlah pohon di "hutan acak", atau jumlah tetangga dalam metode tetangga k-terdekat.
- Parameter model - apa yang dia pelajari selama pelatihan, misalnya, bobot dalam regresi linier.
Dengan mengendalikan hiperparameter, kami memengaruhi hasil model, mengubah keseimbangan antara
pendidikan kurang dan pelatihan ulang . Under learning adalah situasi di mana modelnya tidak cukup kompleks (memiliki tingkat kebebasan yang terlalu sedikit) untuk mempelajari korespondensi tanda dan tujuan. Model yang kurang terlatih memiliki bias yang
tinggi , yang dapat diperbaiki dengan menyulitkan model tersebut.
Pelatihan ulang adalah situasi di mana model pada dasarnya mengingat data pelatihan. Model yang dilatih ulang memiliki varian yang
tinggi , yang dapat disesuaikan dengan membatasi kompleksitas model melalui regularisasi. Kedua model yang kurang terlatih dan dilatih ulang tidak akan dapat menggeneralisasikan data uji dengan baik.
Kesulitan dalam memilih hyperparameters yang tepat adalah bahwa untuk setiap tugas akan ada satu set optimal yang unik. Oleh karena itu, satu-satunya cara untuk memilih pengaturan terbaik adalah dengan mencoba berbagai kombinasi pada dataset baru. Untungnya, Scikit-Learn memiliki sejumlah metode yang memungkinkan Anda mengevaluasi hiperparameter secara efektif. Selain itu, proyek-proyek seperti
TPOT berusaha untuk mengoptimalkan pencarian hyperparameter menggunakan pendekatan seperti
pemrograman genetik . Dalam artikel ini, kami membatasi diri untuk menggunakan Scikit-Learn.
Periksa ulang pencarian acak
Mari kita terapkan metode penyetelan hyperparameter yang disebut pencarian lintas-validasi acak:
- Pencarian acak - teknik untuk memilih hiperparameter. Kami mendefinisikan kisi, dan kemudian secara acak memilih berbagai kombinasi darinya, berbeda dengan pencarian kisi, di mana kami berturut-turut mencoba setiap kombinasi. Ngomong-ngomong, pencarian acak bekerja hampir seperti halnya pencarian grid , tetapi jauh lebih cepat.
- Pemeriksaan silang adalah cara mengevaluasi kombinasi hyperparameter yang dipilih. Alih-alih membagi data ke dalam set pelatihan dan tes, yang mengurangi jumlah data yang tersedia untuk pelatihan, kami akan menggunakan validasi silang k-block (K-Fold Cross Validation). Untuk melakukan ini, kita akan membagi data pelatihan menjadi blok k, dan kemudian menjalankan proses iteratif, di mana kita pertama-tama melatih model pada blok k-1, dan kemudian membandingkan hasilnya ketika belajar di blok k-th. Kami akan mengulangi proses k kali, dan pada akhirnya kami akan mendapatkan nilai kesalahan rata-rata untuk setiap iterasi. Ini akan menjadi penilaian akhir.
Berikut ini adalah ilustrasi grafik validasi silang k-block pada k = 5:

Seluruh proses pencarian acak validasi silang terlihat seperti ini:
- Kami menetapkan kotak hyperparameter.
- Pilih kombinasi hiperparameter secara acak.
- Buat model menggunakan kombinasi ini.
- Kami mengevaluasi hasil model menggunakan k-block cross-validation.
- Kami memutuskan hyperparameter mana yang memberikan hasil terbaik.
Tentu saja, semua ini dilakukan tidak secara manual, tetapi menggunakan
RandomizedSearchCV dari Scikit-Learn!
Kami akan menggunakan model regresi berbasis gradien boost. Ini adalah metode kolektif, yaitu, model terdiri dari banyak "pelajar yang lemah", dalam hal ini, dari pohon keputusan yang terpisah. Jika siswa belajar dalam
algoritma paralel
seperti "hutan acak" , dan kemudian hasil prediksi dipilih dengan memilih, maka dalam
meningkatkan algoritma seperti meningkatkan gradien, siswa belajar secara berurutan, dan masing-masing dari mereka "berfokus" pada kesalahan yang dibuat oleh pendahulunya.
Dalam beberapa tahun terakhir, meningkatkan algoritma telah menjadi populer dan sering menang dalam kompetisi pembelajaran mesin.
Gradient boosting adalah salah satu implementasi dimana Gradient Descent digunakan untuk meminimalkan biaya fungsi. Implementasi peningkatan gradien di Scikit-Learn dianggap tidak seefektif di perpustakaan lain, misalnya, di
XGBoost , tetapi bekerja dengan baik pada dataset kecil dan memberikan perkiraan yang cukup akurat.
Kembali ke pengaturan hyperparametric
Dalam regresi menggunakan gradient boosting, ada banyak hiperparameter yang perlu dikonfigurasi, untuk detail saya merujuk Anda ke dokumentasi Scikit-Learn. Kami akan mengoptimalkan:
loss : meminimalkan fungsi loss;n_estimators : jumlah pohon keputusan lemah yang digunakan (pohon keputusan);max_depth : kedalaman maksimum setiap pohon keputusan;min_samples_leaf : jumlah minimum contoh yang harus ada di simpul daun dari pohon keputusan;min_samples_split : jumlah minimum contoh yang diperlukan untuk membagi simpul pohon keputusan;max_features : Jumlah maksimum fitur yang digunakan untuk memisahkan node.
Tidak yakin apakah ada yang benar-benar mengerti cara kerjanya, dan satu-satunya cara untuk menemukan kombinasi terbaik adalah dengan mencoba berbagai opsi.
Dalam kode ini, kami membuat kisi hiperparameter, lalu membuat objek
RandomizedSearchCV dan mencari menggunakan 4-blok cross-validation untuk 25 kombinasi hiperparameter yang berbeda:
Anda dapat menggunakan hasil ini untuk pencarian kisi dengan memilih parameter untuk kisi yang dekat dengan nilai optimal ini. Tetapi penyempurnaan lebih lanjut tidak mungkin meningkatkan model secara signifikan. Ada aturan umum: konstruksi fitur yang kompeten akan memiliki dampak yang jauh lebih besar pada keakuratan model daripada pengaturan hyperparameter yang paling mahal. Ini adalah
hukum penurunan profitabilitas dalam kaitannya dengan pembelajaran mesin : merancang atribut memberikan pengembalian tertinggi, dan penyetelan hyperparametric hanya membawa manfaat sederhana.
Untuk mengubah jumlah estimator (pohon keputusan) sambil mempertahankan nilai-nilai hiperparameter lainnya, satu percobaan dapat dilakukan yang akan menunjukkan peran pengaturan ini. Implementasinya diberikan di
sini , tetapi inilah hasilnya:
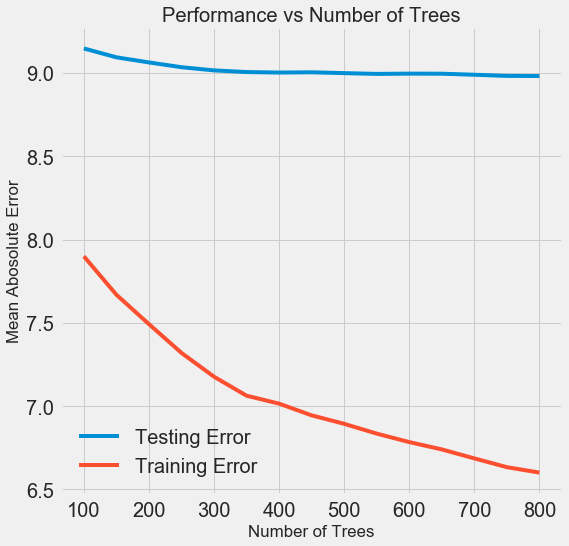
Ketika jumlah pohon yang digunakan oleh model meningkat, tingkat kesalahan selama pelatihan dan pengujian menurun. Tetapi kesalahan belajar berkurang jauh lebih cepat, dan sebagai hasilnya, model dilatih ulang: itu menunjukkan hasil yang sangat baik pada data pelatihan, tetapi bekerja lebih buruk pada data uji.
Pada data uji, akurasi selalu menurun (karena model melihat jawaban yang benar untuk dataset pelatihan), tetapi penurunan yang signifikan
menunjukkan pelatihan ulang . Masalah ini dapat diatasi dengan meningkatkan jumlah data pelatihan atau
mengurangi kompleksitas model menggunakan hyperparameters . Di sini kami tidak akan menyentuh hyperparameters, tetapi saya sarankan Anda selalu memperhatikan masalah pelatihan ulang.
Untuk model akhir kami, kami akan mengambil 800 evaluator, karena ini akan memberi kami tingkat kesalahan terendah dalam validasi silang. Sekarang coba modelnya!
Penilaian Menggunakan Data Uji
Sebagai orang yang bertanggung jawab, kami memastikan bahwa model kami sama sekali tidak mendapatkan akses ke data uji selama pelatihan. Oleh karena itu,
kita dapat menggunakan keakuratan ketika bekerja dengan data uji sebagai indikator kualitas model ketika dimasukkan ke tugas nyata.
Kami memberi makan data uji model dan menghitung kesalahan. Berikut ini adalah perbandingan hasil dari algoritma peningkatan gradien default dan model khusus kami:
Tuning Hyperparametric membantu meningkatkan akurasi model sekitar 10%. Bergantung pada situasinya, ini bisa menjadi peningkatan yang sangat signifikan, tetapi butuh banyak waktu.
Anda dapat membandingkan waktu pelatihan untuk kedua model menggunakan perintah magic
%timeit di Notebook Jupyter. Pertama, ukur durasi default model:
%%timeit -n 1 -r 5 default_model.fit(X, y) 1.09 s ± 153 ms per loop (mean ± std. dev. of 5 runs, 1 loop each)
Satu detik untuk belajar sangat layak. Tetapi model yang disetel tidak begitu cepat:
%%timeit -n 1 -r 5 final_model.fit(X, y) 12.1 s ± 1.33 s per loop (mean ± std. dev. of 5 runs, 1 loop each)
Situasi ini menggambarkan aspek mendasar dari pembelajaran mesin:
ini semua tentang kompromi . Penting untuk memilih keseimbangan antara akurasi dan interpretabilitas, antara
perpindahan dan dispersi , antara akurasi dan waktu operasi, dan sebagainya. Kombinasi yang tepat sepenuhnya ditentukan oleh tugas tertentu. Dalam kasus kami, peningkatan 12 kali lipat dalam durasi kerja dalam hal relatif adalah besar, tetapi secara absolut tidak signifikan.
Kami mendapatkan hasil peramalan akhir, sekarang mari kita menganalisisnya dan mencari tahu apakah ada penyimpangan yang nyata. Di sebelah kiri adalah grafik kerapatan nilai yang diprediksi dan nyata, di sebelah kanan adalah histogram kesalahan:
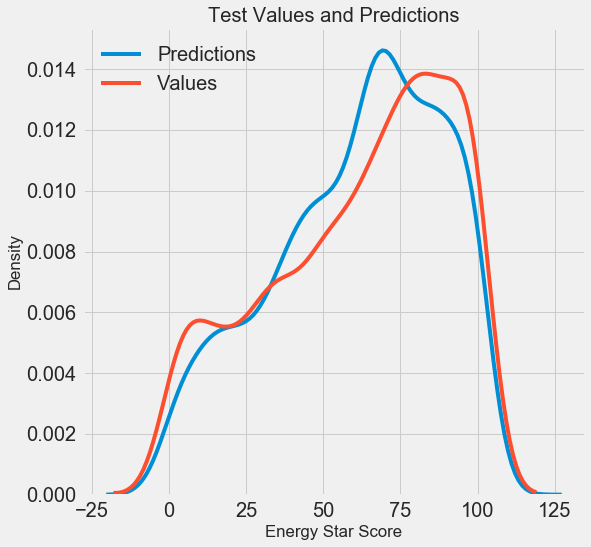

Perkiraan model mengulangi distribusi nilai-nilai nyata dengan baik, sedangkan pada data pelatihan, puncak kepadatan terletak lebih dekat dengan nilai median (66) daripada ke puncak kepadatan nyata (sekitar 100). Kesalahan memiliki distribusi yang hampir normal, meskipun ada beberapa nilai negatif besar ketika perkiraan model sangat berbeda dari data nyata. Pada artikel selanjutnya, kita akan memeriksa interpretasi hasil secara lebih rinci.
Kesimpulan
Dalam artikel ini, kami memeriksa beberapa tahap pemecahan masalah pembelajaran mesin:
- Mengisi nilai yang hilang dan fitur penskalaan.
- Evaluasi dan perbandingan hasil beberapa model.
- Tuning hiperparametrik menggunakan pencarian grid acak dan validasi silang.
- Evaluasi model terbaik menggunakan data uji.
Hasil menunjukkan bahwa kita dapat menggunakan pembelajaran mesin untuk memprediksi Skor Energy Star berdasarkan statistik yang tersedia. Dengan bantuan peningkatan gradien, kesalahan 9,1 dicapai pada data uji. Penyesuaian Hyperparametric dapat sangat meningkatkan hasil, tetapi dengan biaya perlambatan yang signifikan. Ini adalah salah satu dari banyak trade-off untuk dipertimbangkan dalam pembelajaran mesin.
Pada artikel selanjutnya, kami akan mencoba mencari tahu bagaimana model kami bekerja. Kami juga akan melihat faktor-faktor utama yang mempengaruhi Skor Bintang Energi. Jika kita tahu bahwa model itu akurat, maka kita akan mencoba memahami mengapa model itu memprediksi dengan cara ini dan apa yang dikatakannya tentang masalah itu sendiri.