
Masing-masing dari kita memahami teks dengan cara kita sendiri, apakah itu berita di Internet, puisi atau novel klasik. Hal yang sama berlaku untuk algoritma dan metode pembelajaran mesin, yang, sebagai aturan, mempersepsikan teks dalam bentuk matematika, dalam bentuk ruang vektor multidimensi.
Artikel ini dikhususkan untuk visualisasi menggunakan t-SNE yang dihitung oleh Word2Vec representasi vektor multidimensi kata. Visualisasi akan membantu untuk lebih memahami prinsip Word2Vec dan bagaimana menafsirkan hubungan antara vektor kata sebelum digunakan lebih lanjut dalam jaringan saraf dan algoritma pembelajaran mesin lainnya. Artikel ini berfokus pada visualisasi, penelitian lebih lanjut dan analisis data tidak dipertimbangkan. Sebagai sumber data, kami menggunakan artikel dari Google News dan karya klasik oleh L.N. Tolstoy. Kami akan menulis kode dengan Python di Notebook Jupyter.
Embedded Stochastic Neighbor Embedding
T-SNE adalah algoritma pembelajaran mesin untuk visualisasi data berdasarkan metode reduksi dimensi nonlinear, yang dijelaskan secara rinci dalam artikel asli [1] dan tentang
Habré . Prinsip dasar operasi t-SNE adalah untuk mengurangi jarak berpasangan di antara titik-titik sambil mempertahankan posisi relatif mereka. Dengan kata lain, algoritma memetakan data multidimensi ke ruang dimensi yang lebih rendah, sambil mempertahankan struktur lingkungan titik.
Representasi vektor kata dan Word2Vec
Pertama-tama, kita perlu menyajikan kata-kata dalam bentuk vektor. Untuk tugas ini, saya memilih utilitas semantik distribusi Word2Vec, yang dirancang untuk menampilkan makna kata semantik dalam ruang vektor. Word2Vec menemukan hubungan antara kata-kata dengan mengasumsikan bahwa kata-kata yang berhubungan secara semantik ditemukan dalam konteks yang sama. Anda dapat membaca lebih lanjut tentang Word2Vec di artikel asli [2], serta di
sini dan di
sini .
Sebagai masukan, kami mengambil artikel dari Google News dan novel karya L.N. Tolstoy. Dalam kasus pertama, kita akan menggunakan vektor yang sudah dilatih sebelumnya pada dataset Google News (sekitar 100 miliar kata) yang diterbitkan oleh Google
pada halaman proyek .
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
Selain vektor pra-terlatih menggunakan perpustakaan Gensim [3], kami akan melatih model lain dalam teks-teks L.N. Tolstoy. Karena Word2Vec menerima serangkaian kalimat sebagai input, kami menggunakan model Punkt Sentence Tokenizer yang telah dilatih sebelumnya dari paket NLTK untuk secara otomatis membagi teks menjadi kalimat. Model untuk bahasa Rusia dapat diunduh
dari sini .
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
Selanjutnya, dengan menggunakan pustaka Gensim, kita akan melatih model Word2Vec dengan parameter berikut:
- size = 200 - dimensi ruang atribut;
- window = 5 - jumlah kata dari konteks yang dianalisis algoritma;
- min_count = 5 - kata itu harus muncul setidaknya lima kali sehingga model memperhitungkannya.
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
Visualisasi representasi vektor kata menggunakan t-SNE
T-SNE sangat berguna untuk memvisualisasikan kesamaan antara objek dalam ruang multidimensi. Dengan meningkatnya jumlah data, semakin sulit untuk membuat grafik visual, sehingga dalam praktiknya kata-kata terkait digabungkan ke dalam kelompok untuk visualisasi lebih lanjut. Ambil contoh beberapa kata dari kamus model Word2Vec yang sebelumnya dilatih di Google News.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
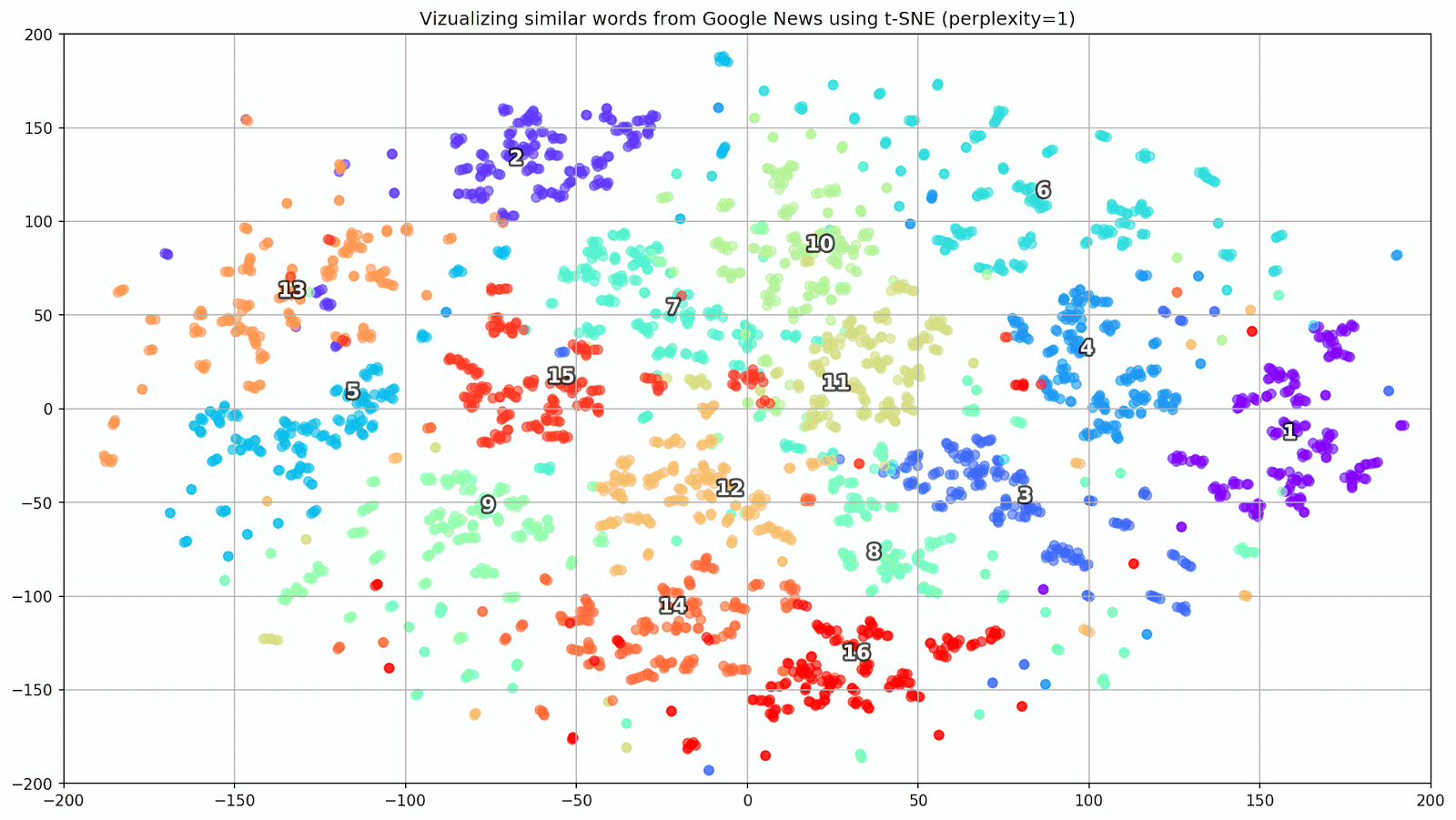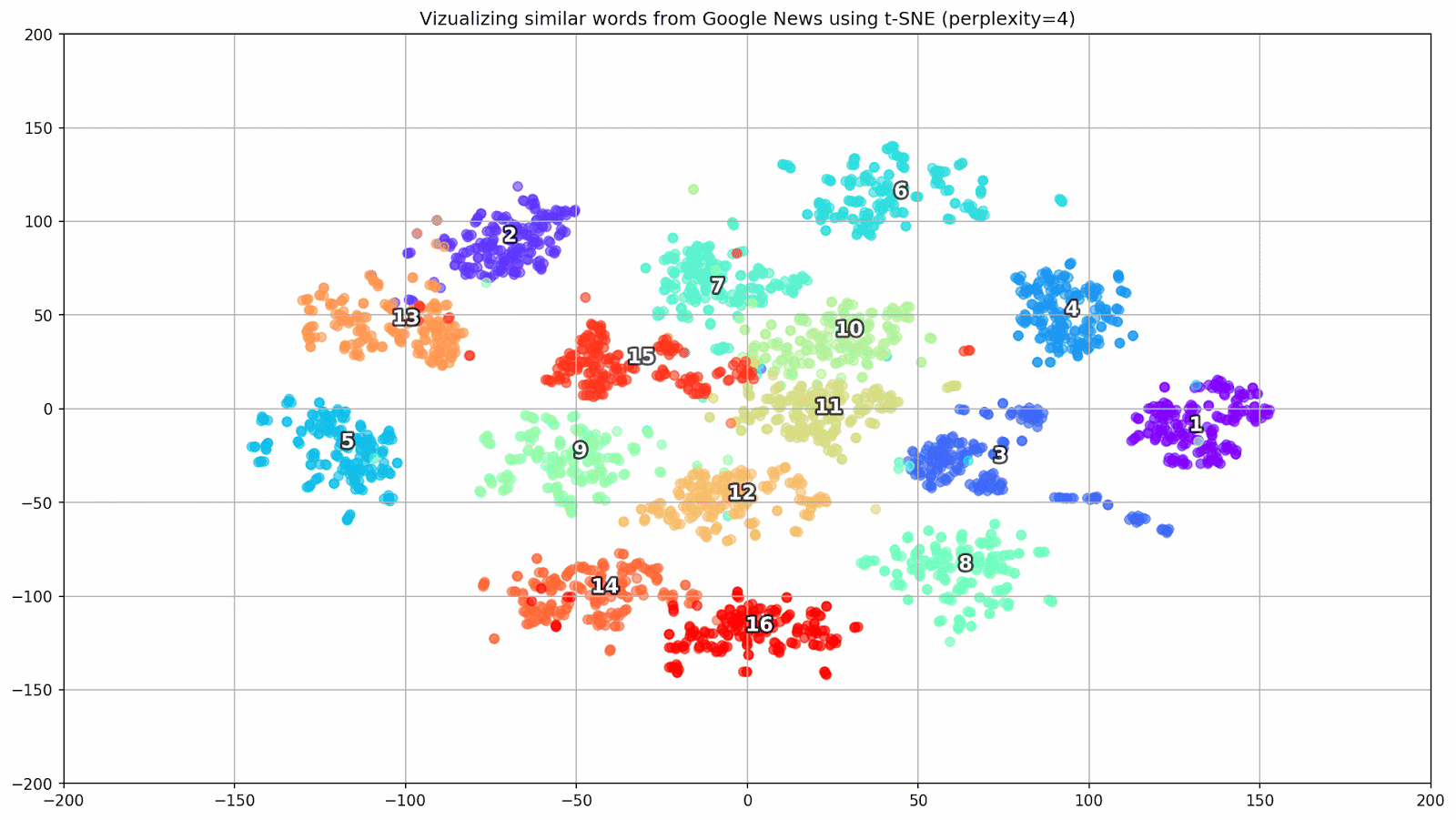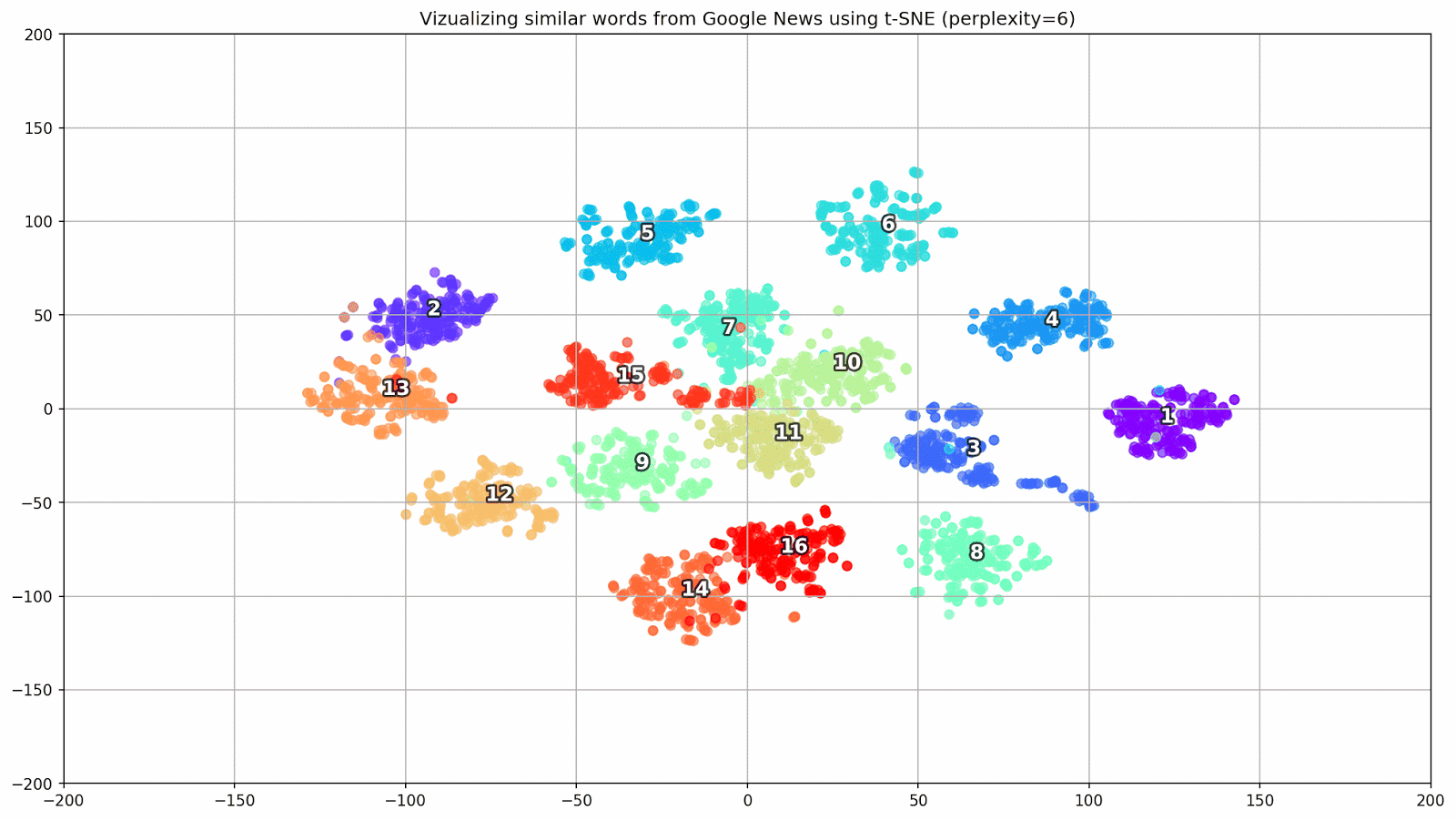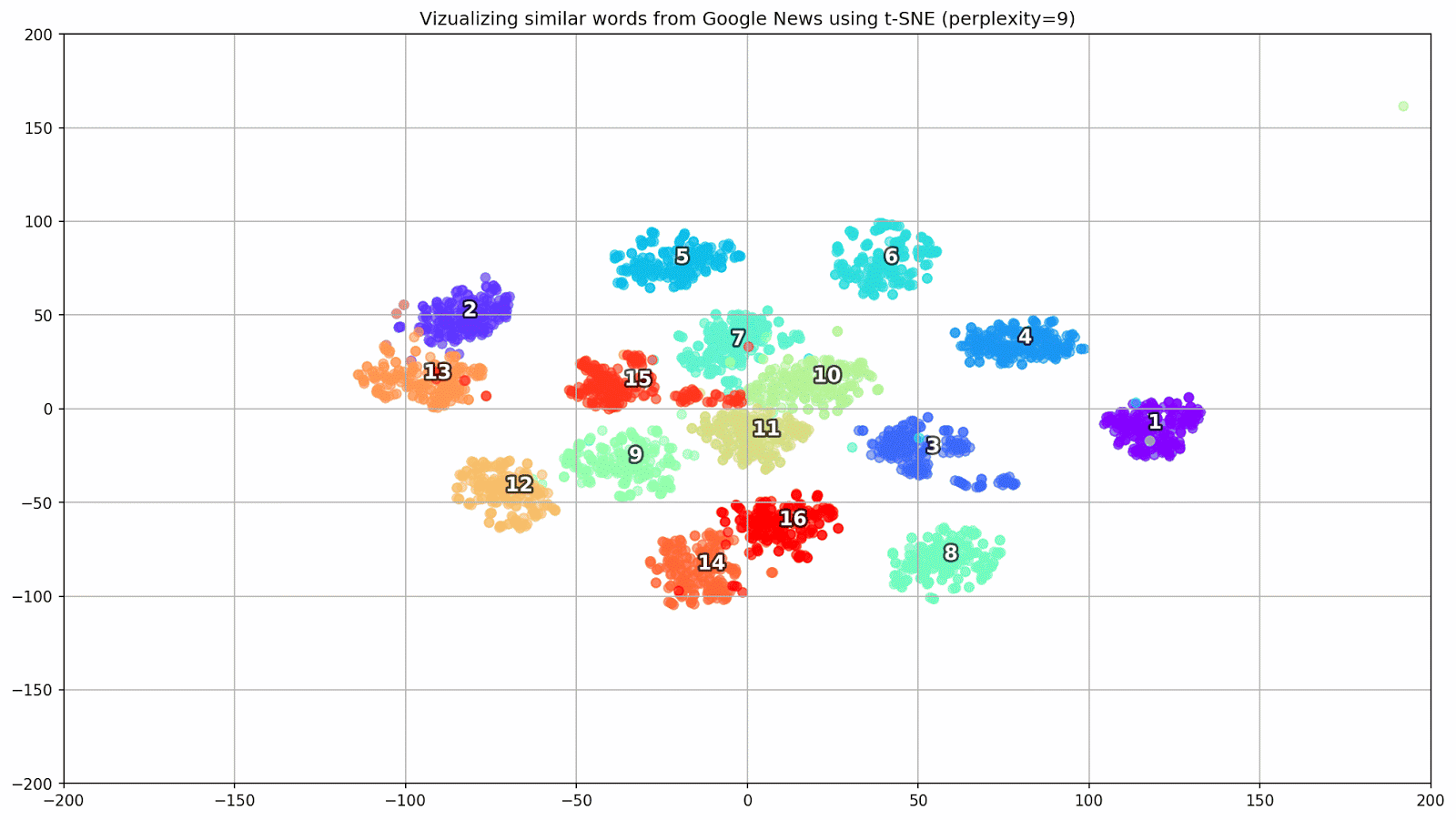 Gambar 1. Grup kata yang mirip dari Google News dengan nilai preplexity yang berbeda.
Gambar 1. Grup kata yang mirip dari Google News dengan nilai preplexity yang berbeda.Selanjutnya, kita beralih ke bagian artikel yang paling luar biasa, konfigurasi t-SNE. Di sini, pertama-tama, Anda harus memperhatikan hyperparameter berikut:
- n_components - jumlah komponen, mis., dimensi ruang nilai;
- kebingungan - kebingungan, nilai yang dalam t-SNE dapat disamakan dengan jumlah tetangga yang efektif. Ini terkait dengan jumlah tetangga terdekat, yang digunakan dalam pembelajaran model lain berdasarkan varietas (lihat gambar di atas). Nilainya direkomendasikan [1] untuk diatur dalam kisaran 5-50;
- init - jenis inisialisasi awal vektor.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
Di bawah ini adalah skrip untuk membangun grafik dua dimensi menggunakan Matplotlib, salah satu perpustakaan paling populer untuk memvisualisasikan data dalam Python.
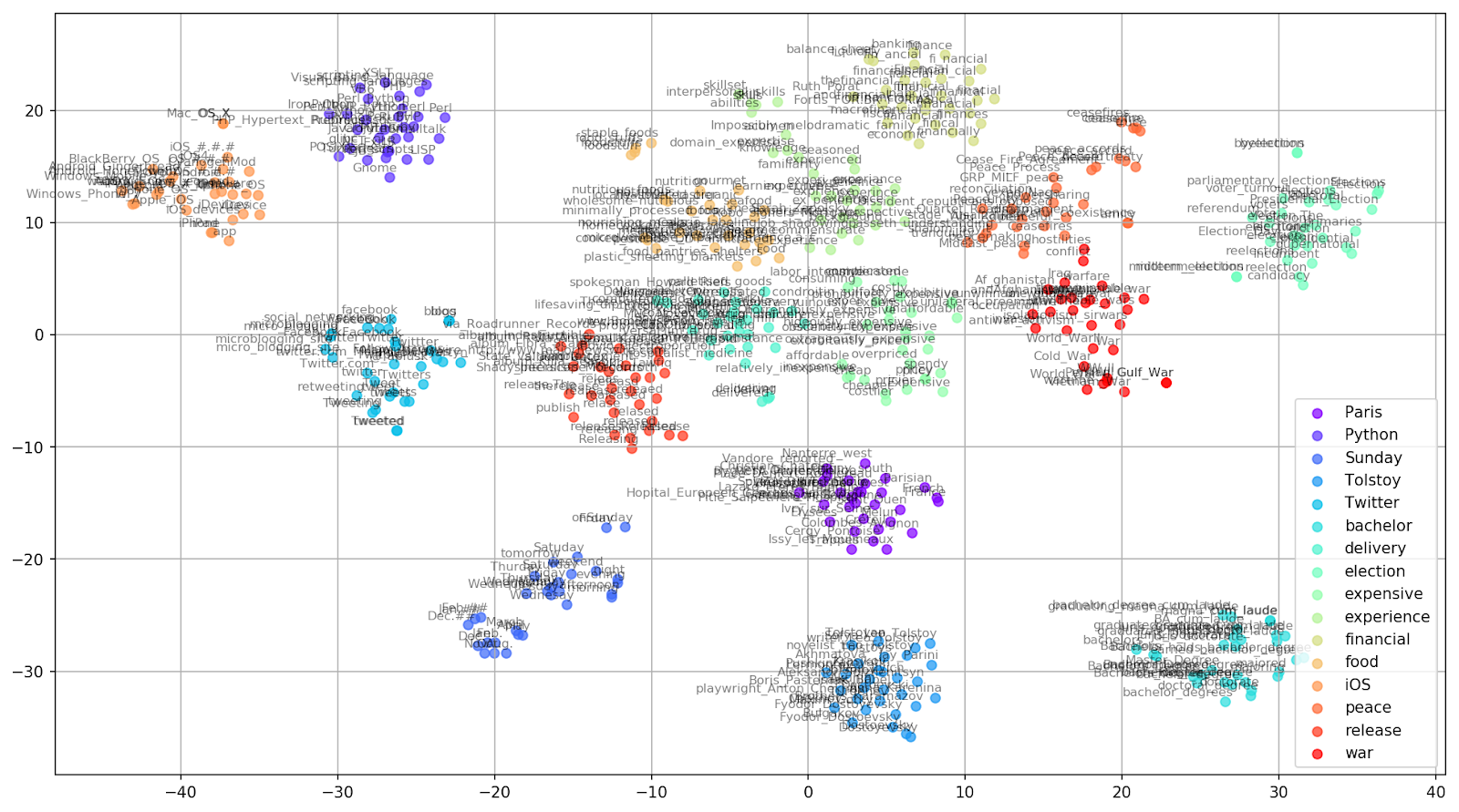 Gambar 2. Grup kata yang mirip dari Google News (preplexity = 15).
Gambar 2. Grup kata yang mirip dari Google News (preplexity = 15). from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
Kadang-kadang perlu untuk membangun bukan kumpulan kata-kata yang terpisah, tetapi keseluruhan kamus. Untuk tujuan ini, mari kita menganalisis Anna Karenina, kisah hebat tentang hasrat, pengkhianatan, tragedi, dan penebusan.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
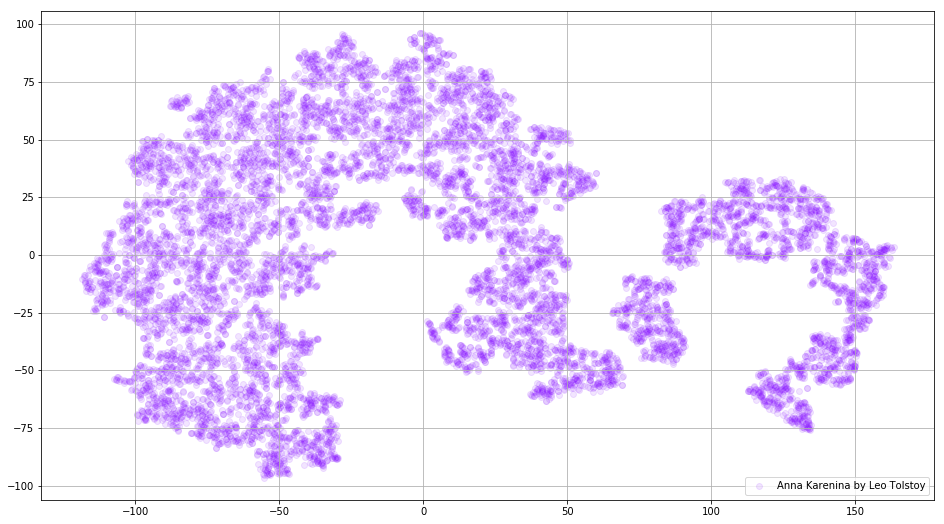
 Gambar 3. Visualisasi kamus model Word2Vec, dilatih pada novel "Anna Karenina."
Gambar 3. Visualisasi kamus model Word2Vec, dilatih pada novel "Anna Karenina."Gambar dapat menjadi lebih informatif jika kita menggunakan ruang tiga dimensi. Lihatlah Perang dan Damai, salah satu novel utama sastra dunia.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
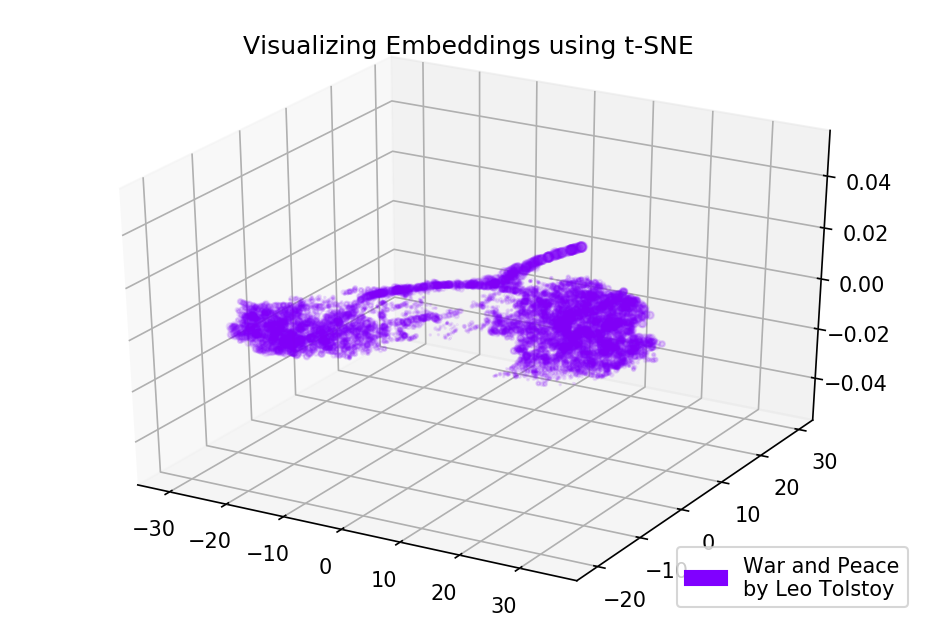 Gambar 4. Visualisasi kamus model-Word2Vec, dilatih pada novel "War and Peace."
Gambar 4. Visualisasi kamus model-Word2Vec, dilatih pada novel "War and Peace."Kode sumber
Kode ini tersedia di
GitHub . Di sana Anda dapat menemukan kode untuk merender animasi.
Sumber
- Maaten L., Hinton G. Memvisualisasikan data menggunakan t-SNE // Jurnal penelitian pembelajaran mesin. - 2008. - T. 9. - S. 2579-2605.
- Representasi Kata-kata dan Frasa Terdistribusi dan Komposisionalitasnya // Kemajuan dalam Sistem Pemrosesan Informasi Saraf Tiruan . - 2013 .-- S. 3111-3119.
- Rehurek R., Sojka P. Kerangka kerja perangkat lunak untuk pemodelan topik dengan perusahaan besar // Dalam Prosiding LREC 2010 Workshop tentang Tantangan Baru untuk Kerangka NLP. - 2010.