Saya terus mengunggah laporan dengan Pixonic DevGAMM Talks, pertemuan September kami untuk para pengembang sistem yang sarat muatan. Mereka berbagi banyak pengalaman dan kasus, dan hari ini saya menerbitkan transkrip pidato pengembang backend dari Sabre Interactive Roman Rogozin. Dia berbicara tentang praktik penerapan model aktor menggunakan contoh mengelola pemain dan negara mereka (laporan lain dapat ditemukan di akhir artikel, daftar dilengkapi).
Tim kami sedang mengerjakan backend untuk game Quake Champions, dan saya akan berbicara tentang apa model aktor dan bagaimana digunakan dalam proyek.
Sedikit tentang tumpukan teknologi. Kami menulis kode dalam C #, masing-masing, semua teknologi terikat padanya. Saya ingin mencatat bahwa akan ada beberapa hal spesifik yang akan saya perlihatkan pada contoh bahasa ini, tetapi prinsip-prinsip umum akan tetap tidak berubah.

Saat ini, kami menyelenggarakan layanan kami di Azure. Ada beberapa primitif yang sangat menarik yang kami tidak ingin menyerah, seperti Table Storage dan Cosmos DB (tetapi kami berusaha untuk tidak terlalu ketat pada mereka demi proyek lintas platform).
Sekarang saya ingin memberi tahu sedikit tentang apa model aktor. Dan untuk memulainya, itu, sebagai prinsip, muncul lebih dari 40 tahun yang lalu.
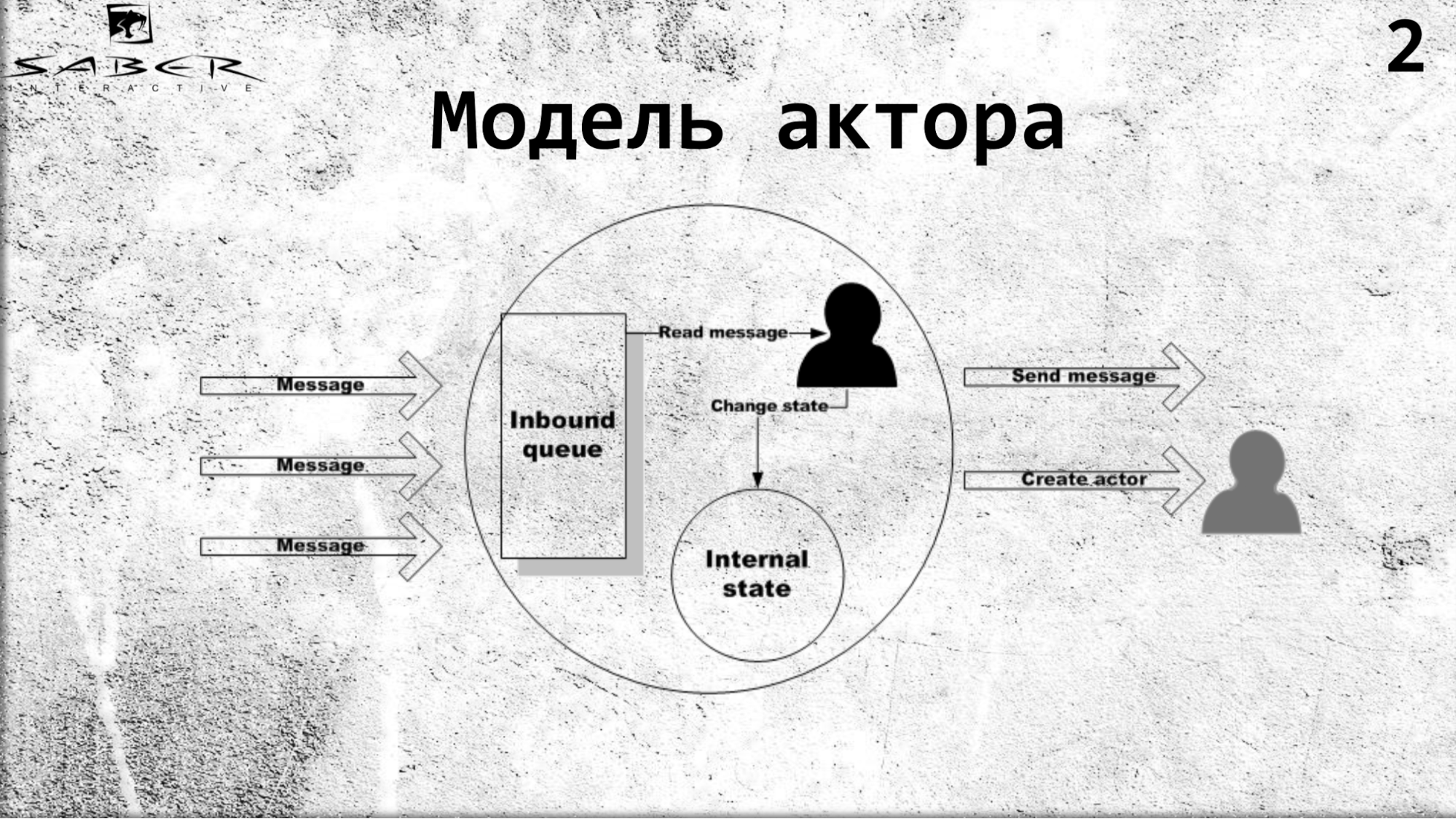
Seorang aktor adalah model komputasi paralel yang menyatakan bahwa ada objek terisolasi tertentu yang memiliki keadaan internal sendiri dan akses eksklusif untuk mengubah keadaan ini. Seorang aktor dapat membaca pesan, dan terlebih lagi, secara berurutan, menjalankan semacam logika bisnis, jika ia ingin mengubah keadaan internalnya, dan mengirim pesan ke layanan eksternal, termasuk aktor lain. Dan dia tahu cara membuat aktor lain.
Aktor berkomunikasi satu sama lain secara tidak sinkron, yang memungkinkan Anda membuat sistem cloud terdistribusi tinggi. Dalam hal ini, model aktor telah banyak digunakan baru-baru ini.
Ringkasnya, mari kita bayangkan bahwa kita memiliki cloud di mana ada beberapa jenis server cluster, dan para aktor kita berputar pada cluster ini.
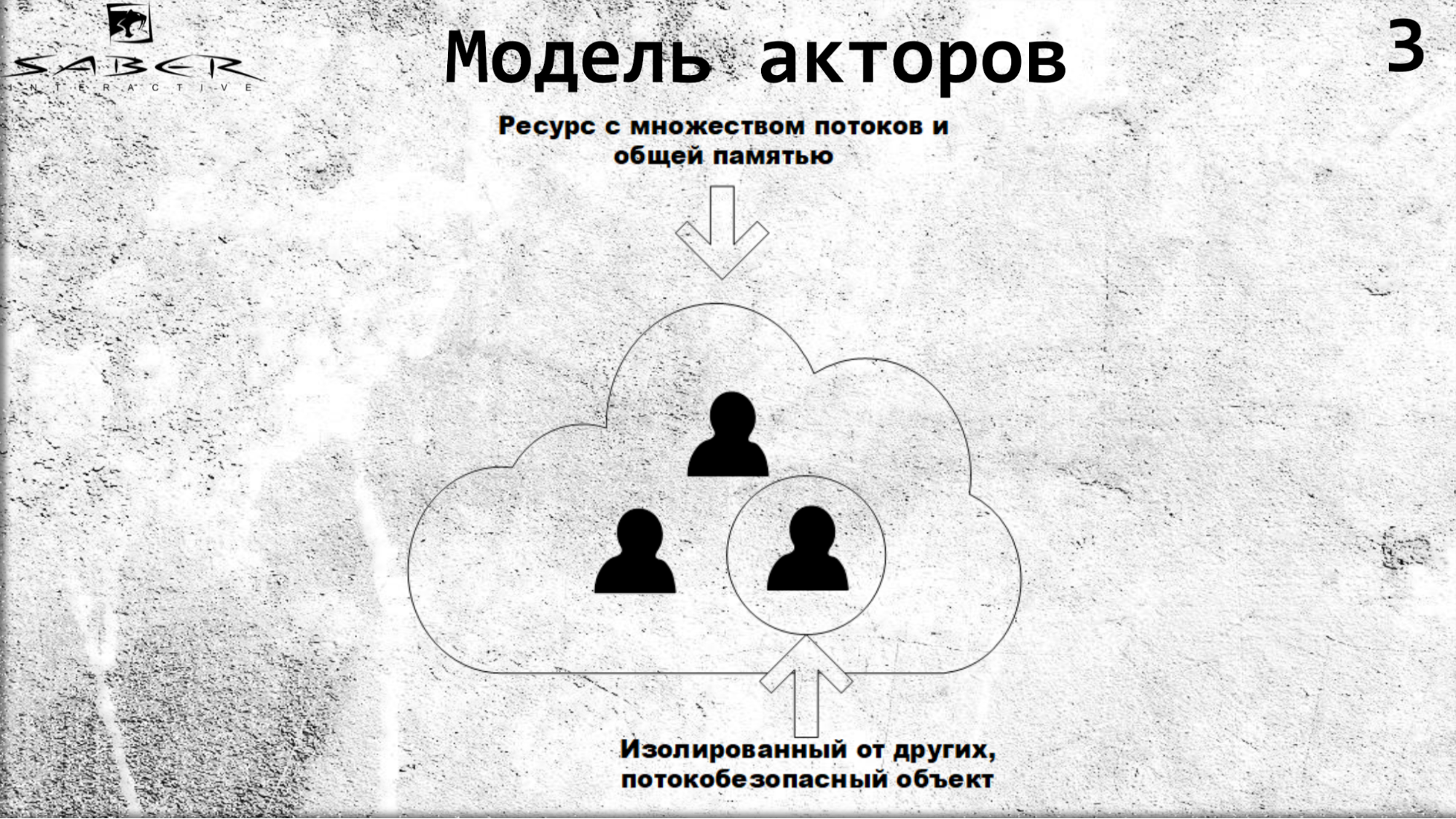
Aktor diisolasi dari satu sama lain, berkomunikasi melalui panggilan asinkron, dan di dalam diri mereka, para aktor aman.
Seperti apa bentuknya. Misalkan kita memiliki beberapa pengguna (bukan beban yang sangat besar), dan pada titik tertentu kita mengerti bahwa ada masuknya pemain, dan kami sangat perlu melakukan peningkatan.
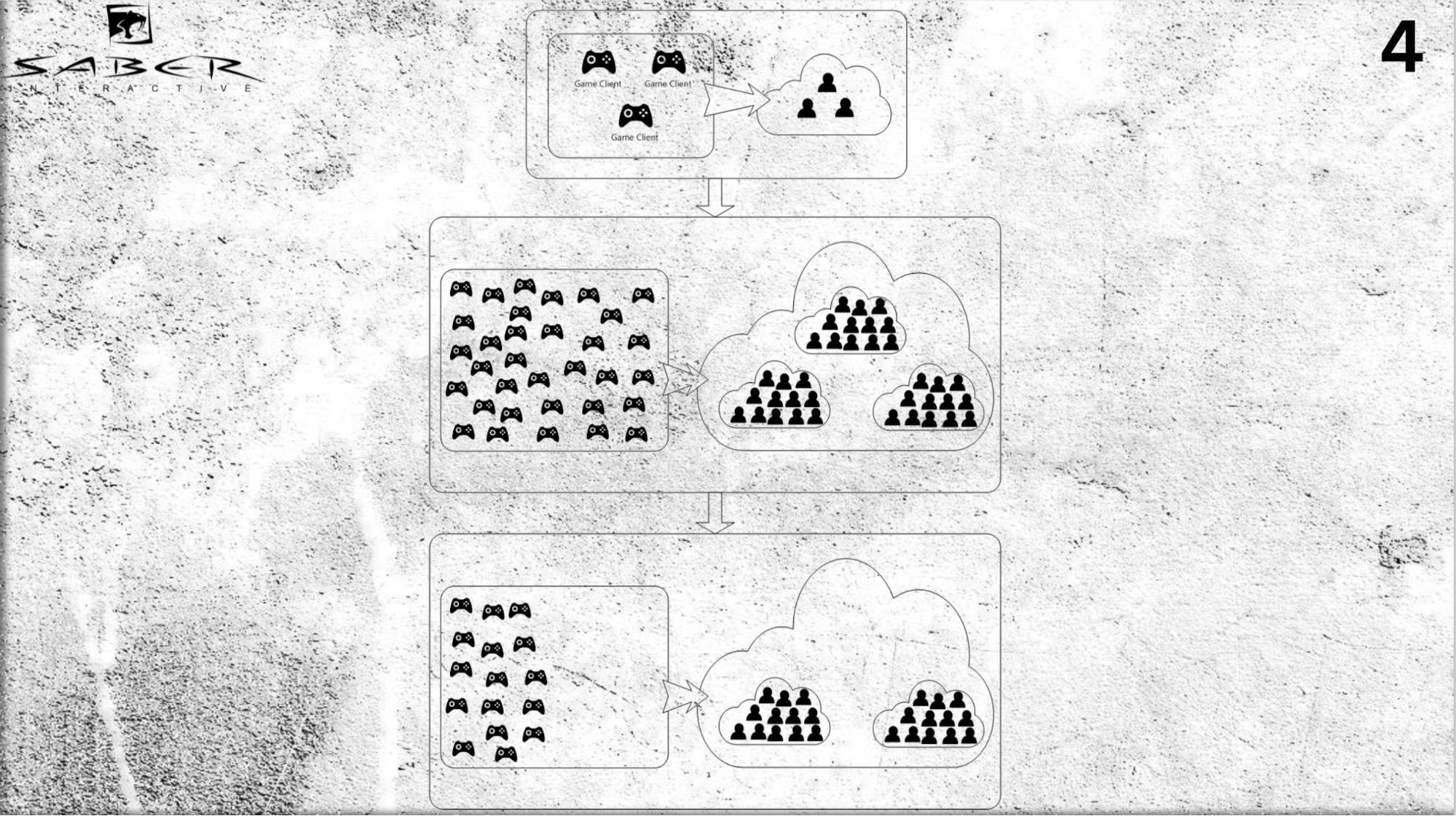
Kami dapat menambahkan server ke cloud kami dan, menggunakan model aktor, mendorong pengguna individual - menetapkan setiap aktor individual dan mengalokasikan ruang untuk memori dan waktu prosesor untuk aktor ini di cloud.
Dengan demikian, aktor, pertama, memainkan peran cache, dan kedua, itu adalah "cache pintar", yang dapat memproses beberapa pesan dan menjalankan logika bisnis. Sekali lagi, jika Anda perlu membuat downscale (misalnya, para pemain telah pergi) - juga tidak ada masalah menghapus aktor-aktor ini dari sistem.
Kami di backend tidak menggunakan model aktor klasik, tetapi berdasarkan kerangka kerja Orleans. Apa bedanya - Saya akan mencoba memberi tahu Anda sekarang.

Pertama, Orleans memperkenalkan konsep aktor virtual atau, sebagaimana juga disebut, grain. Berbeda dengan model aktor klasik, di mana sebuah layanan bertanggung jawab untuk menciptakan aktor ini dan menempatkannya di beberapa server, Orleans mengambil alih pekerjaan. Yaitu jika layanan pengguna tertentu meminta nilai tertentu, maka Orleans akan memahami server mana yang sekarang kurang dimuat, itu akan menempatkan aktor di sana dan mengembalikan hasilnya ke layanan pengguna.
Sebuah contoh Untuk biji-bijian, penting untuk hanya mengetahui jenis aktor, misalnya, status pengguna, dan ID. Misalkan ID pengguna 777, kami mendapatkan graine dari pengguna ini dan tidak memikirkan bagaimana cara menyimpan graine ini, kami tidak mengontrol siklus hidup graine. Orleans, bagaimanapun, dalam dirinya sendiri menyimpan jalur semua aktor dengan cara yang sangat licik. Jika tidak ada aktor, ia menciptakan mereka, jika aktor itu hidup, ia mengembalikannya, dan untuk layanan pengguna semuanya terlihat sehingga semua aktor selalu hidup.
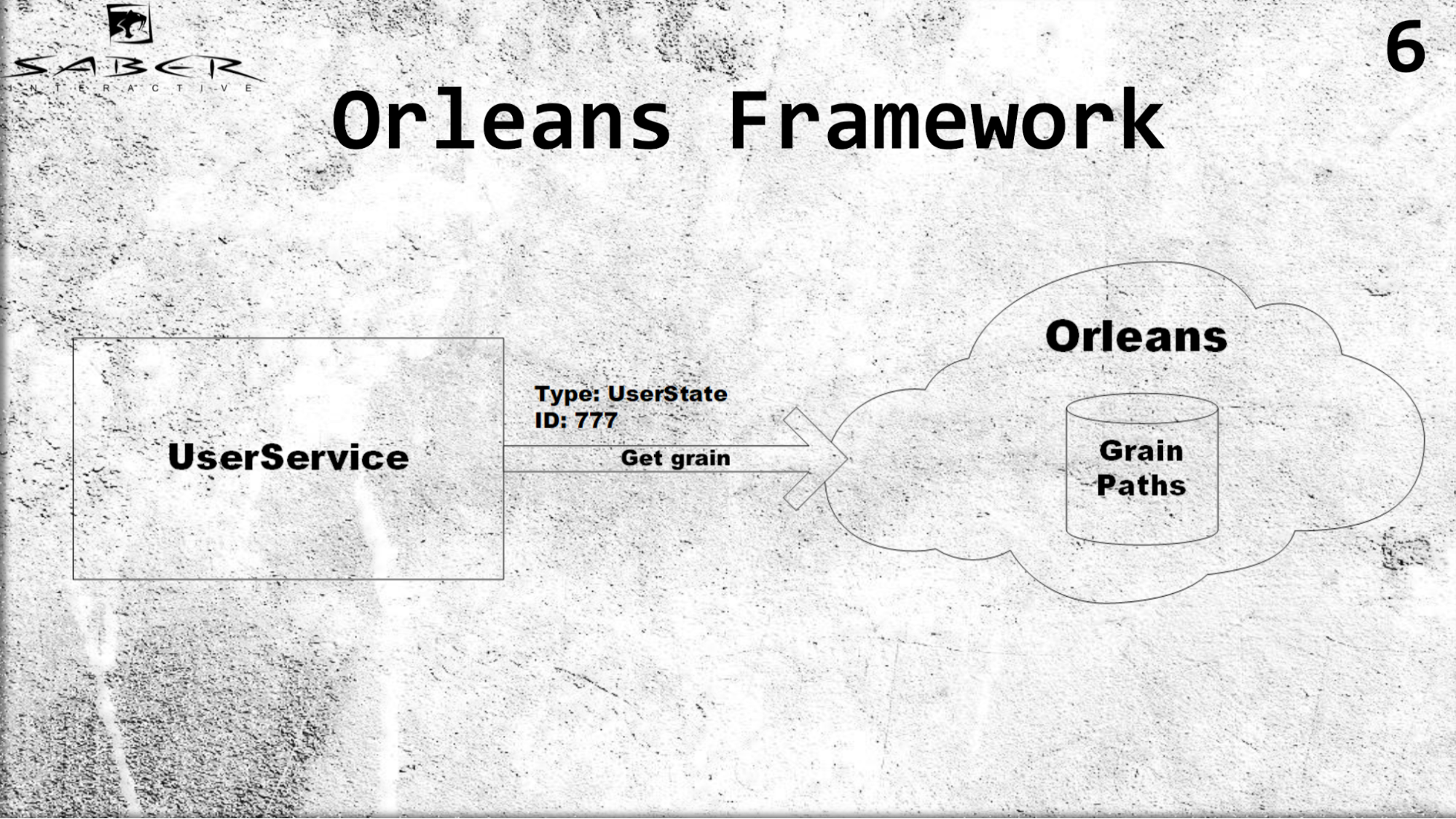
Apa manfaatnya bagi kita? Pertama, load balancing transparan karena fakta bahwa programmer tidak perlu mengatur lokasi aktor sendiri. Dia hanya mengatakan Orleans, yang digunakan pada beberapa server: beri saya aktor seperti itu dari server Anda.
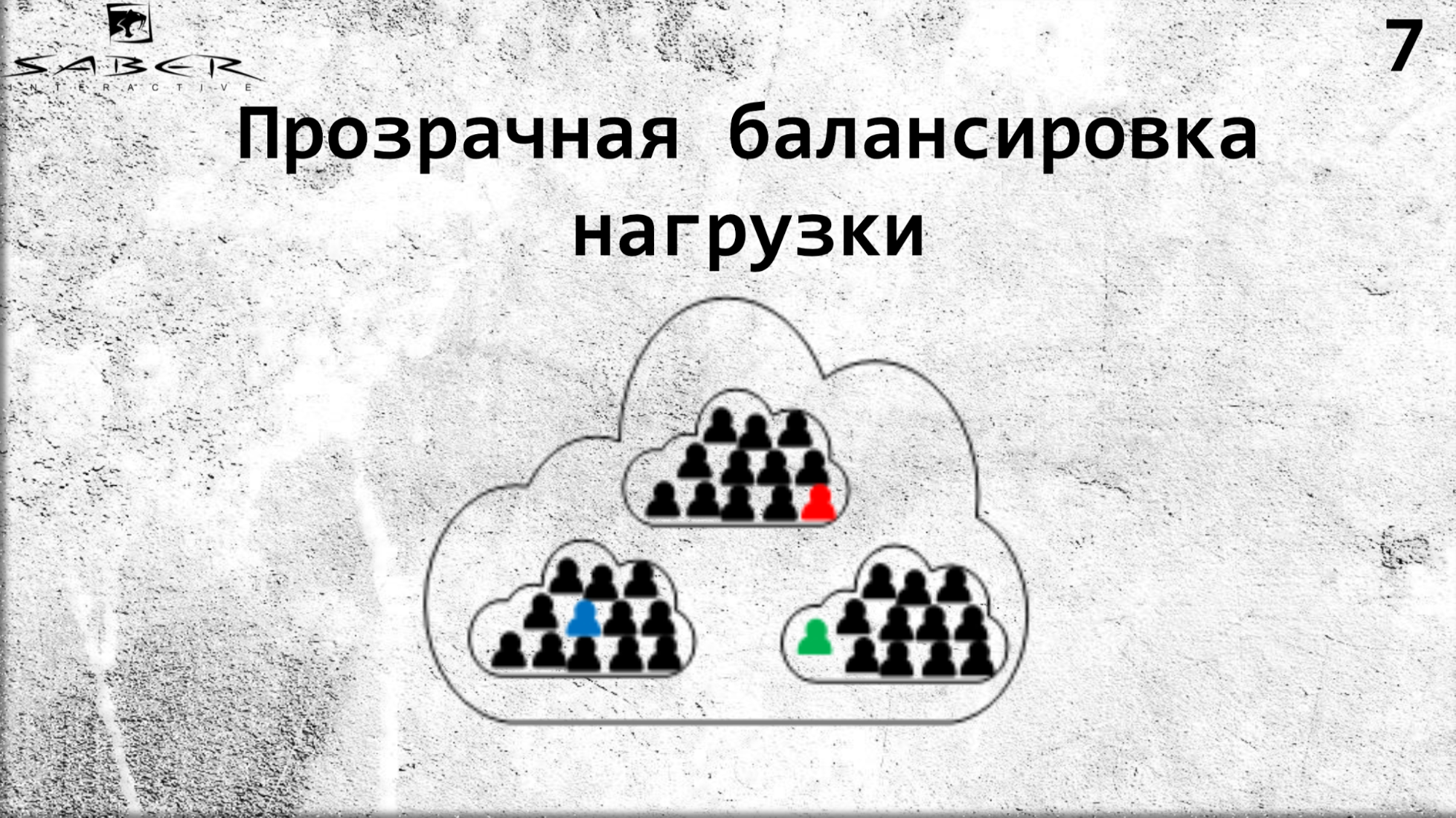
Jika diinginkan, Anda dapat menurunkan skala jika beban pada prosesor dan memori kecil. Sekali lagi, Anda dapat melakukan kelas atas di arah yang berlawanan. Tetapi layanan tidak tahu apa-apa tentang ini, dia meminta graine, dan Orleans memberinya graine itu. Dengan demikian, Orleans mengambil perawatan infrastruktur untuk siklus hidup biji-bijian.
Kedua, Orleans menangani crash server.

Ini berarti bahwa jika dalam model klasik, programmer bertanggung jawab untuk menangani kasus seperti itu sendiri (mereka menempatkan aktor di beberapa server, dan server ini macet, dan kita sendiri harus menaikkan aktor ini di salah satu server langsung), yang menambahkan lebih banyak mekanik atau kerja jaringan yang rumit untuk seorang programmer, maka di Orleans terlihat transparan. Kami meminta graine, Orleans melihat bahwa itu tidak tersedia, mengambilnya (menempatkannya di beberapa server langsung) dan mengembalikannya ke layanan.
Untuk membuatnya lebih jelas, mari kita analisis contoh kecil tentang bagaimana pengguna membaca sebagian dari keadaannya.
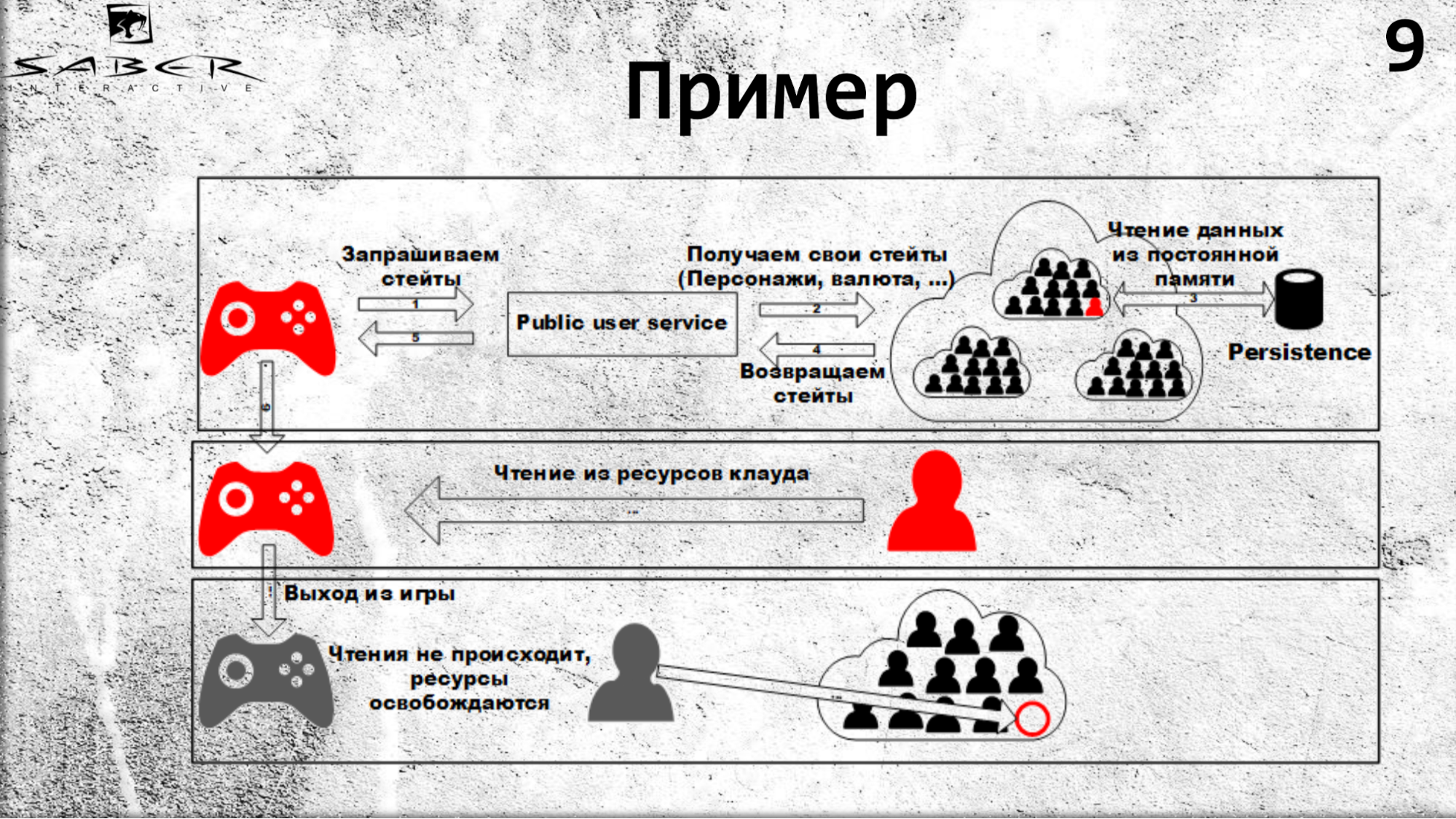
Suatu negara mungkin adalah kondisi ekonominya, yang menyimpan baju besi, senjata, mata uang, atau juara pengguna itu. Untuk mendapatkan status ini, ia memanggil PublicUserService, yang beralih ke Orleans untuk negara bagian. Apa yang terjadi: Orleans melihat bahwa belum ada aktor seperti itu (mis., Biji-bijian), ia membuatnya di server gratis, dan biji-bijian membaca kondisinya dari beberapa toko Persistence.
Jadi, lain kali Anda membaca sumber daya dari cloud, seperti yang ditunjukkan dalam slide, semua bacaan akan berasal dari cache cache. Jika pengguna meninggalkan permainan, sumber daya bacaan tidak terjadi, jadi Orleans memahami bahwa bulir tidak lagi digunakan oleh siapa pun dan dapat dinonaktifkan.
Jika kami memiliki beberapa klien (klien game, server game), mereka dapat meminta status pengguna, dan salah satunya akan meningkatkan jumlah ini. Lebih tepatnya, itu akan membuat Orleans mengambilnya, dan kemudian semua panggilan, seperti yang sudah kita ketahui, terjadi di dalamnya thread-safe, secara berurutan. Pertama, klien akan menerima status, dan kemudian server game.
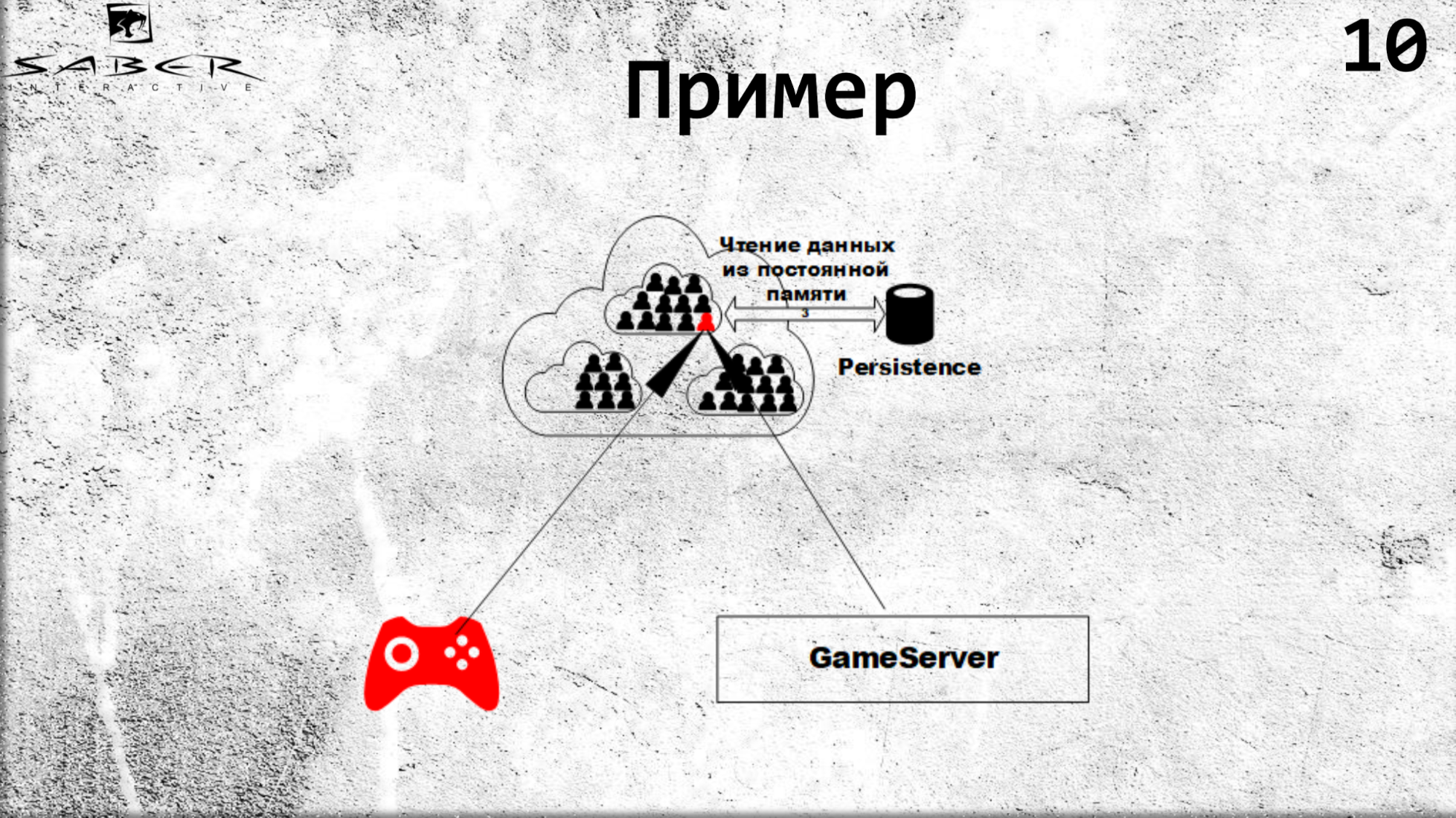
Aliran yang sama pada pembaruan. Ketika klien ingin memperbarui keadaan, ia akan mentransfer tanggung jawab ini ke butir, yaitu akan memberitahunya: "beri pengguna ini 10 emas", dan gandum naik, ia memproses keadaan ini dengan semacam logika bisnis di dalam gandum. Dan kemudian datang pembaruan cache cache dan, jika diinginkan, kegigihan dalam Kegigihan.

Mengapa Ketekunan diperlukan di sini? Ini adalah topik yang terpisah dan terletak pada fakta bahwa kadang-kadang itu tidak terlalu penting bagi kita bahwa Butir terus-menerus mempertahankan statusnya dalam Persistence. Jika ini keadaan pemain online, kami siap mengambil risiko kehilangan demi produktivitas, jika itu menyangkut ekonomi, maka kita harus yakin bahwa keadaannya dilestarikan.
Kasus paling sederhana: untuk setiap panggilan save state, tulis pembaruan ini untuk Persistence. Dengan demikian, jika grey tiba-tiba jatuh secara tidak terduga, peningkatan graine berikutnya pada beberapa server lain akan menyebabkan pembaruan cache dengan data saat ini.
Contoh kecil bagaimana tampilannya.

Seperti yang sudah saya katakan, sebutir terdiri dari tipe dan beberapa kunci (dalam hal ini, jenisnya adalah IPlayerState, kuncinya adalah IGrainWithGuidKey, yang artinya adalah Guid). Dan kami memiliki antarmuka yang kami implementasikan, mis. GetStates mengembalikan beberapa daftar status dan ApplyState, yang berlaku beberapa negara. Metode Orleans mengembalikan Tugas. Apa artinya ini: Tugas adalah janji yang memberi tahu kita bahwa ketika negara kembali, janji akan berada dalam keadaan terselesaikan. Kami juga memiliki beberapa PlayerState yang kami dapatkan dengan GrainFactory. Yaitu di sini kami mendapatkan tautan, dan kami tidak tahu apa-apa tentang lokasi fisik gandum ini. Saat memanggil GetStates, Orleans akan menaikkan graine kami, membaca status dari toko Persistence ke dalam ingatannya, dan ketika ApplyState akan menerapkan status baru, ia juga akan memperbarui status ini baik dalam memorinya maupun dalam Persistence.
Saya ingin membuat contoh yang sedikit lebih kompleks pada arsitektur tingkat tinggi dari layanan UserStates kami.
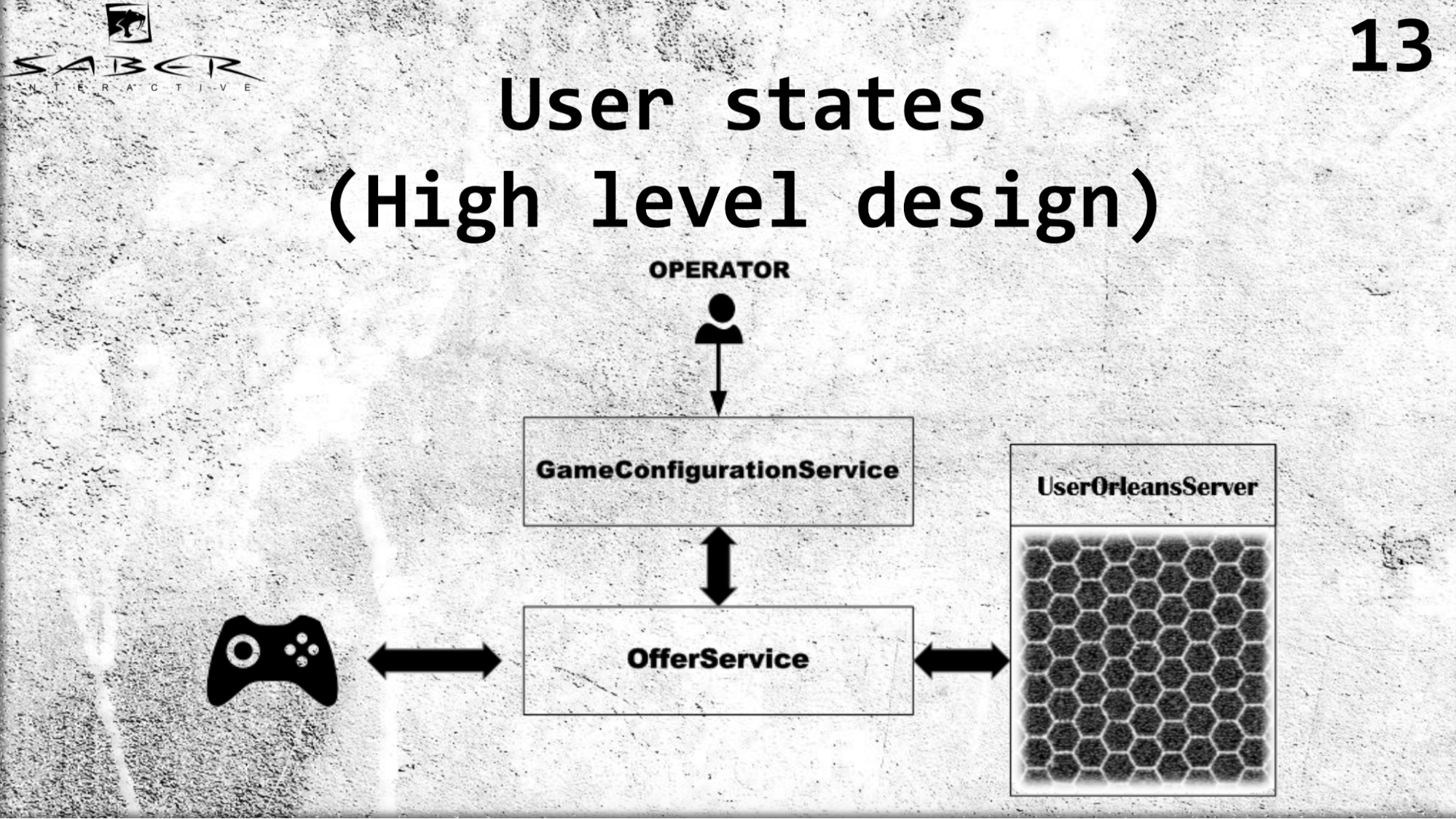
Kami memiliki semacam klien game yang mendapatkan statusnya melalui OfferSevice. Kami memiliki GameConfigurationService, yang bertanggung jawab atas model ekonomi sekelompok pengguna, dalam hal ini, pengguna kami. Dan kami memiliki operator yang mengubah model ekonomi ini. Sesuai dengan itu, pengguna meminta OfferSevice untuk menerima status mereka. Dan OfferSevice sudah mengakses layanan UserOrleans, yang terdiri dari biji-bijian ini, ia meningkatkan status pengguna dalam memorinya, mungkin menjalankan semacam logika bisnis, dan mengembalikan data kembali ke pengguna melalui OfferService.
Secara umum, saya ingin menarik perhatian pada fakta bahwa Orleans baik untuk kemampuan paralelismenya yang tinggi karena fakta bahwa biji-bijian tidak saling tergantung satu sama lain. Dan di sisi lain, di dalam graine, kita tidak perlu menggunakan primitif sinkronisasi, karena kita tahu bahwa setiap panggilan ke graine ini entah bagaimana akan konsisten.
Di sini saya ingin melihat beberapa jebakan dari model ini.

Yang pertama terlalu banyak butiran. Karena semua panggilan dalam greine aman, satu demi satu, dan jika kita memiliki logika berminyak pada greine, kita harus menunggu terlalu lama. Sekali lagi, terlalu banyak memori yang dialokasikan untuk satu butir tersebut. Tidak ada algoritma yang tepat untuk ukuran butir, karena butir yang terlalu kecil juga buruk. Di sini perlu untuk melanjutkan dari nilai optimal. Saya tidak akan mengatakan yang mana, terserah programmer untuk memutuskan.
Masalah kedua tidak begitu jelas - inilah yang disebut reaksi berantai. Ketika seorang pengguna menaikkan beberapa butir, dan dia, pada gilirannya, secara implisit dapat meningkatkan butir lain dalam sistem. Bagaimana ini terjadi: pengguna menerima statusnya, dan pengguna memiliki teman dan dia menerima status teman-temannya. Jadi, seluruh sistem menyimpan semua butirannya dalam memori, dan jika kita memiliki 1000 pengguna, dan masing-masing memiliki 100 teman, maka 100.000 butir dapat aktif begitu saja. Kasus ini juga perlu dihindari - entah bagaimana menyimpan status teman dalam semacam memori bersama.

Nah, teknologi apa yang ada untuk mengimplementasikan model aktor. Mungkin yang paling terkenal adalah Akka, yang datang kepada kami dengan Jawa. Ada garpu yang disebut Akka.NET untuk .NET. Ada Orleans, yang merupakan open-source dan dalam bahasa lain, sebagai implementasi. Ada primitif Azure seperti Service Fabric Actor - ada banyak teknologi.
Pertanyaan dari audiens
- Bagaimana Anda memecahkan masalah klasik seperti CICD, memperbarui aktor-aktor ini, apakah Anda menggunakan Docker dan apakah diperlukan sama sekali?- Kami belum menggunakan buruh pelabuhan. Secara umum, DevOps terlibat dalam penyebaran, mereka menggunakan layanan kami di layanan cloud Azure.
- Pembaruan berkelanjutan, tanpa waktu henti, bagaimana itu terjadi? Orleans sendiri memutuskan ke server mana server akan pergi, ke server mana permintaan akan pergi, dan cara memperbarui layanan ini. Yaitu logika bisnis baru telah muncul, pembaruan dari aktor yang sama telah muncul - bagaimana pembaruan ini dilakukan?- Jika kita berbicara tentang memperbarui seluruh layanan, dan jika kita telah memperbarui beberapa logika bisnis aktor, kita dapat meluncurkan layanan Orleans baru untuk itu. Biasanya ini diselesaikan dengan primitif kita yang disebut topologi. Kami meluncurkan beberapa layanan Orleans baru, yang untuk saat ini, misalkan, kosong, dan tanpa aktor, menampilkan layanan lama dan menggantinya dengan yang baru. Tidak akan ada aktor dalam sistem sama sekali, tetapi pada permintaan pengguna berikutnya, aktor-aktor ini sudah akan dibuat. Mungkin akan ada semacam lonjakan di awal. Dalam kasus seperti itu, pembaruan biasanya terjadi di pagi hari, karena di pagi hari kami memiliki jumlah pemain terkecil.
"Bagaimana Orleans memahami bahwa servernya crash?" Anda mengatakan bahwa dia dengan cepat melemparkan aktor ke server lain ...- Dia memiliki pingator yang secara berkala memahami server mana yang masih hidup.
- Apakah dia ping aktor atau server secara khusus?- Khususnya, server.
- Pertanyaan seperti itu: kesalahan terjadi di dalam aktor, Anda mengatakan dia pergi langkah demi langkah, setiap instruksi. Tetapi kesalahan terjadi dan apa yang terjadi pada aktor? Misalkan ada kesalahan yang tidak diproses. Apakah aktor itu sekarat?- Tidak, Orleans melempar pengecualian dalam skema .NET standar.
- Dengar, kami tidak menangani pengecualian, aktor itu ternyata meninggal. Pemain saya tidak tahu bagaimana penampilannya, tetapi kemudian apa yang terjadi? Apakah Anda mencoba me-restart aktor ini atau melakukan hal lain seperti itu?- Itu tergantung pada case yang tergantung pada case yang mana. Misalnya retriable atau tidak retriable.
- Yaitu Apakah ini semua dapat dikonfigurasi?- Sebaliknya, diprogram. Kami sedang menangani beberapa pengecualian. Yaitu kita melihat dengan jelas bahwa kode kesalahan seperti itu, dan beberapa, seperti pengecualian yang tidak ditangani, sudah didorong lebih jauh.
- Apakah Anda memiliki beberapa Ketekunan - apakah itu seperti database?- Kegigihan, ya, database dengan penyimpanan persisten.
- Katakanlah sebuah basis data meletakkan di mana (syarat) uang game. Apa yang terjadi jika seorang aktor tidak dapat menghubunginya? Bagaimana Anda menanganinya?- Pertama-tama, ini Storage. Saat ini, kami menggunakan Azure Table Storage, dan masalah seperti itu benar-benar terjadi - Storage macet. Biasanya dalam hal ini Anda harus mengkonfigurasi ulang.
- Jika aktor tidak bisa mendapatkan sesuatu di Storage, seperti apa pemain itu? Dia benar-benar tidak punya uang ini atau dia segera menutup permainan?- Ini adalah perubahan penting bagi pengguna. Karena setiap layanan memiliki tingkat keparahannya sendiri, dalam hal ini, layanan pengguna adalah keadaan terminal, dan klien hanya macet.
- Tampak bagi saya bahwa pesan-pesan para aktor terjadi melalui antrian asinkron. Bagaimana solusi yang dioptimalkan ini? Tidak membengkak, bukankah itu membuat pemain menutup telepon? Bukankah lebih baik menggunakan pendekatan reaktif?- Masalah antrian aktor cukup terkenal, karena kami jelas tidak dapat mengontrol ukuran antrian, Anda benar. Tapi Orleans, pertama, mengambil beberapa jenis pekerjaan manajemen dan, kedua, saya pikir hanya dengan akses timeout ke aktor akan jatuh, yaitu kita tidak bisa menjangkau aktor, misalnya.
- Dan bagaimana ini akan mempengaruhi pemain?- Karena layanan pengguna menghubungi aktor, mereka akan membuang pengecualian batas waktu pengecualian dan, jika itu adalah layanan "kritis", klien akan melempar kesalahan dan menutup. Dan jika itu kurang kritis, maka itu akan menunggu.
- Yaitu Apakah Anda memiliki ancaman DDoS? Sejumlah besar tindakan kecil dapat menempatkan pemain? Katakanlah seseorang dengan cepat mulai mengundang teman, dll.- Tidak, ada pembatas permintaan yang tidak akan memungkinkan Anda untuk mengakses layanan terlalu sering.
- Bagaimana Anda menangani konsistensi data? Misalkan kita memiliki dua pengguna, kita perlu mengambil sesuatu dari satu, dan menagih sesuatu ke yang lain, sehingga bersifat transaksional.- Pertanyaan bagus. Pertama, Orleans 2.0 mendukung Transaksi Aktor Terdistribusi - ini adalah rilis pertama. Lebih tepatnya, sudah perlu berbicara tentang ekonomi. Dan sebagai cara termudah - di Orleans terakhir, transaksi antar aktor dilaksanakan tanpa masalah.
- Yaitu Apakah sudah tahu cara menjamin bahwa data akan tetap ada dalam integritas?- Ya.
Lebih banyak pembicaraan dengan Pixonic DevGAMM Talks