Saya tidak suka ketika tidak ada petunjuk langkah demi langkah sederhana di jaringan tanpa kata-kata pintar yang menunjukkan bagaimana melakukan hal-hal yang paling tidak jelas. Oleh karena itu, tanpa perkenalan yang tidak perlu hari ini saya akan memberi tahu Anda cara membuat cadangan SQL cluster failover dengan benar. Ya, itu adalah cluster, bukan server SQL yang berdiri sendiri. Banyak yang telah ditulis tentang mereka, tetapi untuk beberapa alasan cluster dihindari.
Dan tanpa perkenalan panjang, kami akan mempertimbangkan lab kami:
- Windows cluster dengan Windows Server 2012 r2 di bawah tenda dan sejumlah node. Untuk kenyamanan, hanya ada dua di lab saya. Muncul pertanyaan yang sah: mengapa menempatkan sebuah cluster pada sebuah cluster? Saya akan menjelaskan sedikit lebih rendah.
- Tiga disk terhubung ke kluster melalui iSCSI: kuorum, disk dengan basis, disk untuk log. Anda bisa berbuat lebih banyak, Anda bisa lebih sedikit, di sini sesuka Anda. Terkadang Anda menyukainya: dua disk lokal (satu untuk sistem, satu untuk menginstal SQL itu sendiri), disk kuorum, disk gabungan untuk root dan basis data sistem, disk untuk basis, disk untuk log, disk untuk TempDB dan disk untuk Cadangan. Teknisi sistem mengatakan bahwa ini juga benar. Tapi saya pikir berapa banyak disk yang Anda miliki tidak akan memainkan peran sama sekali. Jika itu berhasil untuk Anda, maka Anda benar dan berhasil.
- Setiap node memiliki instance SQL yang diinstal, yang memahami bahwa itu adalah bagian dari SQL cluster, dan Windows cluster melihat peran SQL Server.
Sekarang - sebelum kita mulai - mari kita sepakati dua hal penting:
- Buat keputusan dan berhenti ragu (saya ingin memasukkan lelucon di sini tentang pemandian, salib dan celana dalam, tapi
disensor memutuskan untuk melakukannya tanpa). Satu infrastruktur harus ditangani hanya dengan satu solusi. Jika Anda menggunakan solusi A untuk cadangan SQL, dan solusi B untuk cadangan cluster, maka B tidak boleh menyentuh SQL dalam keadaan apa pun. Atau lebih baik tidak menggunakan solusi A sama sekali, jika B dapat melakukan pencadangan granular mesin pada tingkat aplikasi. Mengapa Mari kita bayangkan bahwa kedua aplikasi dapat trankeytit log SQL dan berhasil melakukannya. SQL akan bekerja seperti itu, tentu saja, tetapi dalam cadangan berikutnya Anda akan menerima pesan tentang kondisi tidak konsisten server dalam kasus terbaik, dan dalam kasus terburuk, Anda tidak akan dapat memulihkan dari log transaksi. - Saya tahu ada "ribuan dan ribuan" pilihan untuk perangkat lunak cadangan, semuanya pasti lebih baik karena input_reason_here , tapi maaf, saya hanya akan menulis satu yang bisa melakukan ini tidak lebih buruk daripada yang lain, dan mungkin bahkan lebih baik.
Ayo pergi!
Jadi, seperti yang sudah jelas, kami akan membuat cadangan seluruh node. Pertanyaan pertama segera muncul: mengapa, jika Microsoft SQL cluster out of the box memberi kita tingkat perlindungan yang sangat, sangat layak terhadap jatuh? Misalnya, Anda selalu dapat mengambil peran SQL dan sumber daya ke node lain.
Alasan ini benar, tetapi opsi terlewatkan bahwa node itu sendiri rentan. Singkatnya: cluster di level OS menutup risiko yang terkait dengan fungsi OS mesin tertentu, dan cluster SQL menutup risiko yang terkait secara khusus dengan database. Ya, dan cadangkan konfigurasi ini lebih menarik.
Mari kita bayangkan bahwa malware crypto mendatangi kita dan mulai meletakkan node cluster satu per satu. Di sini kita tidak akan dapat dengan cepat mengembalikan hanya file database. Dan ada juga pembaruan OS yang gagal, perangkat keras yang sekarat, dll.
Oleh karena itu, saya mengusulkan untuk mempertimbangkan bahwa kami sepakat tentang perlunya cadangan seluruh server, dan sekarang kami beralih ke alat. Saya akan menulis bagaimana mencapai tujuan Anda dan menjadi luar biasa dengan Veeam Backup & Replication 9.5 Versi lain yang lalu Veeam hanya dapat mem-backup secara terpusat mesin virtual, tetapi sekarang ia telah menerima dukungan penuh untuk backup server fisik, dan akan menjadi dosa jika tidak mengetahuinya.
Kelompok perlindungan
Untuk cadangan, kami akan menggunakan Grup Perlindungan . Ini adalah entitas logis sederhana, pada kenyataannya - wadah di mana mesin yang perlu didukung dikelompokkan. Misalnya, di dalamnya Anda dapat mengelompokkan beberapa objek dari AD dan tidak khawatir bahwa mesin baru tidak akan masuk ke cadangan. Grup Perlindungan secara otomatis memindai perubahan dan melakukan tindakan yang diperlukan sesuai dengan jadwal yang ditentukan. Singkatnya, hal yang sangat nyaman, terutama di infrastruktur campuran besar.
Tapi kami beralih dari kata ke tindakan: kami meluncurkan Veeam Backup & Replication , kami pergi ke tab Inventory dan kami meluncurkan wizard penciptaan Grup Perlindungan.

Pada langkah pertama, Anda perlu menentukan nama grup dan beberapa deskripsi yang diperlukan, semuanya jelas di sini.
Tetapi pada langkah berikutnya, Anda harus sudah memilih di mana Grup Perlindungan akan menerima informasi tentang mesin yang dilindungi. Anda dapat menambahkannya dengan cara lama secara manual dengan nama DNS atau IP, Anda dapat memberikan daftar dalam bentuk file CSV, seperti yang dilakukan Jedi nyata, tetapi kami adalah orang yang lebih sederhana dan kami akan menggunakan objek Direktori Aktif. Dalam kasus kami, ini juga berarti bahwa semua node cluster akan terdeteksi secara otomatis, termasuk yang baru.
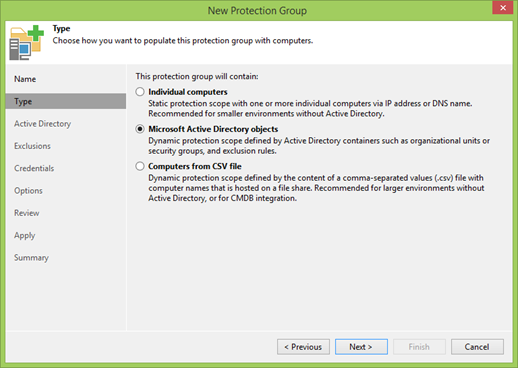
Pada langkah berikutnya, hal pertama yang Anda akan diminta untuk menentukan alamat pengontrol domain, port dan data pengguna untuk terhubung.
Jika semuanya baik-baik saja, klik Tambah dan pilih OU yang Anda butuhkan.
Poin penting: Anda hanya perlu menambahkan cluster! Node terpisah tidak perlu ditambahkan.
Cluster saya disebut WINCLU, dan saya akan menambahkannya.
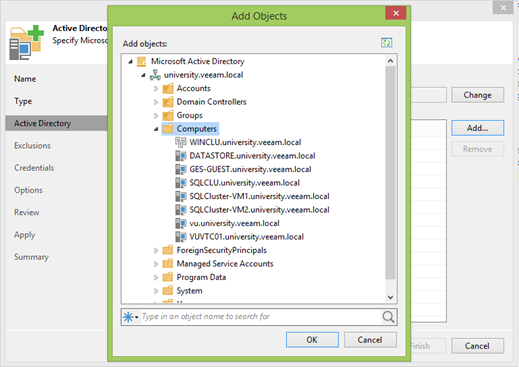
Pada langkah berikutnya, aturan ditetapkan untuk mengecualikan mesin dari pemindaian. Di dunia modern, OU sering mengandung mesin virtual dan fisik, dan dalam beberapa kasus mereka didukung dalam skenario yang berbeda. Bahkan, ada bahkan cluster campuran di mana mesin fisik dan virtual digunakan. Semacam perlindungan tingkat ketiga.
Secara default, dua kotak centang pertama dipilih, dan Anda mungkin tidak perlu menghapusnya, tetapi lab saya sepenuhnya virtual, dan pada awalnya kami sepakat untuk melihat fungsionalitas cadangan mesin fisik.
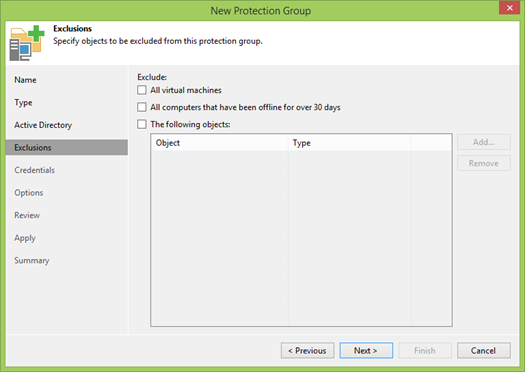
Sekarang kita perlu menentukan pengguna mana yang akan kita gunakan. Dalam beberapa kasus ideal, kami telah membuat pengguna khusus dalam AD yang memiliki hak admin lokal di semua mesin. Tetapi jika tidak demikian, maka Veeam memungkinkan Anda untuk menetapkan pengguna terpisah untuk setiap objek.
Mengapa saya memerlukan admin lokal?
- Pertama, untuk menginstal Veeam Agent di setiap mesin, yang akan mengelola proses pencadangan lokal.
- Kedua, agar Veeam Agent dapat membuat cadangan ini, ia membutuhkan hak administrator lokal untuk bekerja dengan VSS. Begitulah cara Windows bekerja, dan tidak ada yang bisa dilakukan tentang itu.
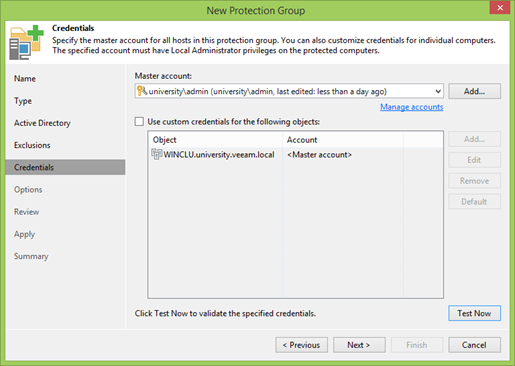
Secara terpisah, Anda perlu fokus pada tombol Uji Sekarang . Suatu hal yang hebat yang memungkinkan Anda untuk dengan cepat memeriksa bahwa semua akun dimasukkan dengan benar, dan dalam kasus cluster, pastikan sebelumnya bahwa semua node terlihat dan dapat diakses.
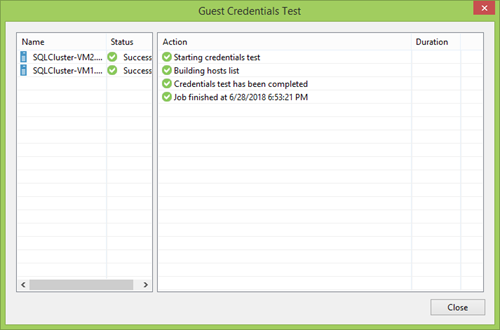
Maka Anda perlu mengatur interval dan waktu untuk memindai peserta PG. Anda dapat setidaknya sekali seminggu, tetapi Anda dapat mengkonfigurasi pembaruan terus menerus. Terserah Anda, tetapi biasanya pilihan yang bagus adalah mengulang frekuensi cadangan sehingga semua peserta baru dapat mencapai titik pemulihan terdekat.
Di bawah ini adalah opsi yang kurang jelas tetapi penting.
Server distribusi adalah mesin yang akan memasang Agen Veeam. Secara umum, cukup menggunakan server Veeam Backup, tetapi dalam infrastruktur yang didistribusikan secara geografis dengan koneksi yang buruk masuk akal untuk menentukan opsi yang lebih dekat. Dalam semua kasus lain, perubahan tidak masuk akal.
Lebih jauh Saya tidak tahu alasan mengapa agen tidak boleh dipasang dan tidak diperbarui secara otomatis, tetapi jika Anda tidak mempercayai otomatisasi, Anda dapat menolak dengan aman. Tetapi perlu diingat bahwa karena perbedaan versi, Anda mungkin dibiarkan tanpa titik cadangan lain.
Anda juga dapat menyetujui untuk menginstal driver CBT kami, yang akan melacak perubahan disk pada tingkat sistem file. Ini akan memungkinkan Anda untuk mengirim ke cadangan hanya sektor yang benar-benar berubah, yang berarti bahwa titik pemulihan kurang, cadangan lebih cepat, beban pada server kurang. Tetapi jika Anda tidak percaya, lalu lintas tidak penting bagi Anda, disk Anda besar dan koneksi sangat baik, maka Anda tidak dapat mengaturnya.
Ada nuansa dengan reboot otomatis: ini digunakan tidak hanya selama instalasi pertama, tetapi juga selama pembaruan. Jadi jangan lupa hapus centang jika Anda tidak mampu membeli barang mewah seperti itu.
Pada langkah berikutnya, kita akan diberitahu tentang perlunya menginstal ulang komponen pada server Distribusi. Bahkan jika mereka tidak ada di sana, dalam satu menit mereka akan berada di sana dengan mengklik tombol Terapkan .
Pada langkah terakhir, kami akan diberitahu bahwa Grup Perlindungan (PG) telah berhasil dibuat dan akan ditawari untuk meluncurkan penemuan, mis. kelompok sesuai dengan kondisi yang ditentukan akan membuat daftar mesin dan menurut pengaturan akan memulai pemasangan agen. Sementara semua operasi yang diperlukan akan terjadi, Anda dapat pergi dan menuangkan kopi untuk diri Anda sendiri.
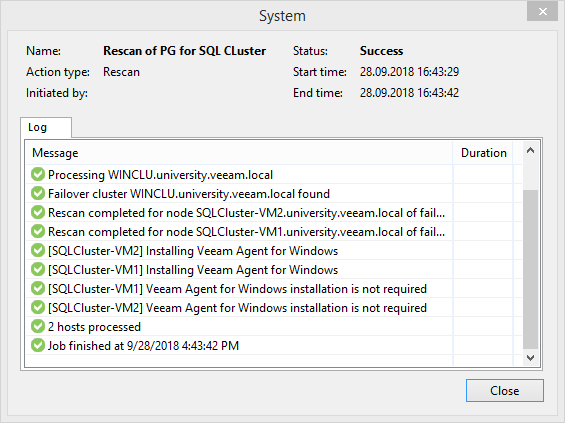
Dengan mengosongkan secangkir kopi, Anda mungkin menemukan bahwa agen tidak dapat diinstal pada salah satu node karena kesalahan akses jaringan. Jika kesedihan seperti itu terjadi pada Anda, maka cukup lepaskan disk kuorum dari node ini. Tidak sering, tetapi itu terjadi. Atau mungkin ini hanya fitur lab saya. Jadi tidak memiliki ketekunan untuk menangani masalah ini sampai akhir.
Buat cadangan
Jadi, jika pada tahap sebelumnya semuanya berakhir dengan sukses, maka Grup Perlindungan Anda sekarang memiliki sebuah cluster dan daftar node-nya dengan agen yang berhasil diinstal. Oleh karena itu, kami beralih ke yang paling menarik: kami membuat cadangan dalam mode Failover Cluster sehingga semua node dan semua disk yang terpasang masuk ke dalamnya.
Apa perbedaan utama dan mengapa Anda tidak bisa menyimpannya sebagai mesin terpisah? Secara teknis, Anda bisa melakukan ini dengan semua node kecuali satu - pemegang saat ini dari peran cluster. Jika Anda mulai mencadangkannya langsung di dahi, simpul lainnya mungkin kehilangan kontak dengannya dan mulai menarik selimut ke diri mereka sendiri, yang pada akhirnya akan menyebabkan keruntuhan dan penghentian seluruh gugus. Ini sangat sering terjadi pada sistem yang sibuk.

Menggunakan tombol kanan mouse (RMB), mengklik PG, kami meluncurkan panduan penciptaan pekerjaan cadangan dan segera memilih mode Failover Cluster . Tugas semacam itu hanya dapat dibuat di Server Pencadangan pusat, tidak seperti cadangan agen lokal. Tapi ini logis: seperti yang Anda ingat, kami ingin mencadangkan SQL secara penuh pada saat yang sama, yang berarti bahwa log akan ditrank secara teratur - di mana, dalam hal apa pun, Anda akan memerlukan komunikasi antara server.
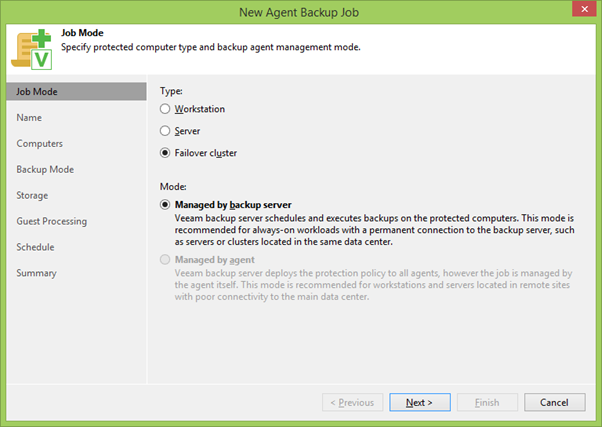
Kemudian pilih nama pekerjaan dan daftar peserta cadangan. Secara default, hanya akan ada PG yang dipilih, tetapi di sini Anda juga dapat menambahkan sesuatu tambahan.
Pada langkah berikutnya, Anda harus memilih antara cadangan disk individu atau seluruh mesin. Secara umum, jika Anda dapat membuat cadangan seluruh mesin, Anda perlu membuat cadangan seluruh mesin. Dalam kasus kami, ini benar, karena kita harus mencadangkan semua disk cluster yang mungkin muncul di sembarang node cluster kami.
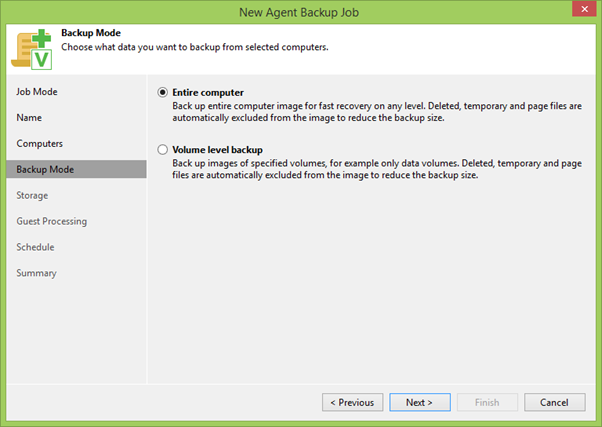
Kemudian kami memilih repositori untuk cadangan dan menentukan berapa banyak poin pemulihan yang akan kami miliki. Menggunakan tombol Advanced , Anda dapat memanggil menu fine-tuning, di mana Anda dapat memilih cara membuat rantai cadangan, mengaktifkan pemeriksaan integritas file tambahan dan banyak lagi, yang kami tidak akan membuang waktu sekarang, karena bagian yang paling menarik adalah bagian Guest Processing .

Itu tergantung pada pengaturan pada tab ini apakah kita bisa mendapatkan apa yang disebut cadangan konsisten aplikasi (yang kadang-kadang diterjemahkan sebagai cadangan integral atau sebagai cadangan dengan mempertimbangkan keadaan aplikasi, atau belum memahami bagaimana dan, yang paling penting, mengapa). Oleh karena itu, buka Aplikasi , pilih PG kami dan klik Edit .

Pastikan bahwa tab pertama termasuk Pemrosesan Aplikasi-Sadar . Dalam hal ini, subsistem VSS akan terlibat, pekerjaan yang harus dilewati tanpa kesalahan. Sebaliknya, ini mungkin berfungsi dengan kesalahan, tetapi dalam kasus ini, cadangan tidak akan dibuat dan Anda harus memahami penyebab kegagalan. Di sini Anda juga perlu menentukan nasib log transaksi: Veeam dapat mengabaikannya, cukup menyalin ke cadangan atau memotong.
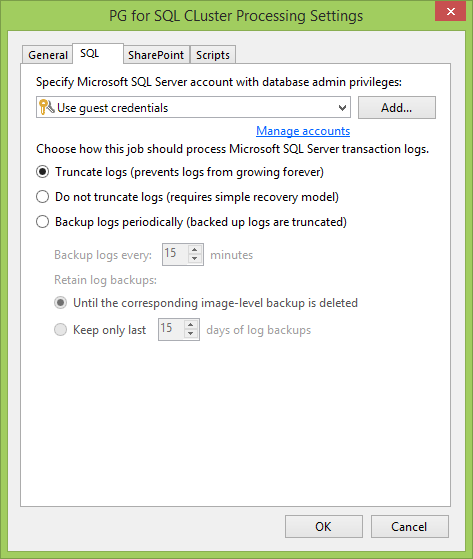
Sekarang buka tab SQL . Hal pertama yang harus dilakukan adalah mengatur akun pengguna untuk berinteraksi dengan server SQL dan databasenya. Di dunia yang ideal, ini cocok dengan administrator lokal yang kami tentukan saat membuat PG. Kalau tidak, yang utama adalah bahwa pengguna ini harus memiliki hak-hak Pemilik Database .
Kemudian kita memilih bagaimana kita akan berinteraksi dengan log. Misalnya, jika Anda memiliki basis data dalam mode Pemulihan Penuh , sangat mudah untuk mengambil log. Atau Anda dapat membuat cadangan log transaksi pada jadwal yang terpisah sehingga Anda dapat dengan cepat memutar kembali database ke waktu yang tepat, dan tidak kehilangan semua yang ada di antara cadangan. Tentu saja, Anda tidak dapat melakukan apa pun dengan log sama sekali.
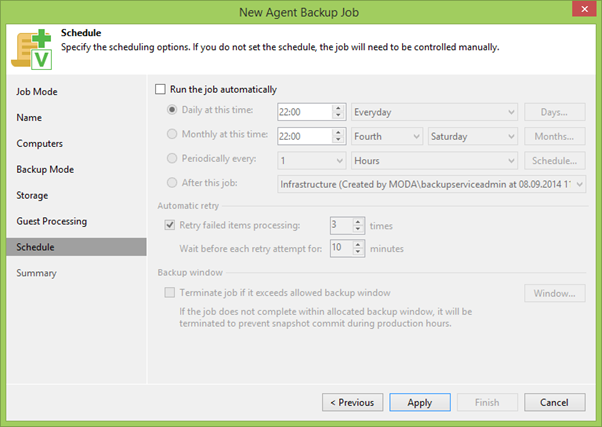
Kami lolos ke titik kedua dari belakang Jadwal , di mana kami mengatur jadwal sesuai dengan kebutuhan Anda. Sudah cukup untuk seseorang sekali sehari, seseorang sekali jam, terserah Anda.
Kami menyelesaikan tugas dengan mengklik Terapkan beberapa kali dan nikmati hasilnya.
Di dunia yang ideal, jika Anda tidak memiliki trik dengan menginstal agen yang berfungsi sebagai tautan antara kluster dan Veeam Server, atau jika Anda tiba-tiba lupa memuat lisensi yang diperlukan untuk agen, pekerjaan akan bekerja dengan sempurna, dan Anda akan melihat gambar berikut.
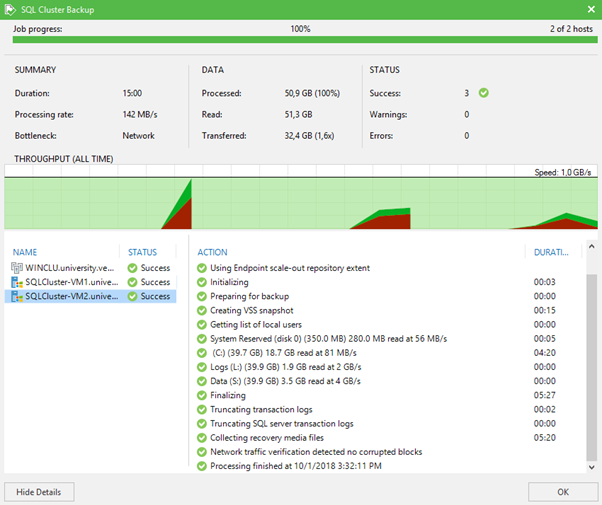
Itu saja. Ternyata cluster cadangan tidak begitu menyeramkan seperti biasanya dipikirkan. Bahkan jika itu adalah cluster di dalam cluster lain.
Jika Anda tertarik mempelajari tentang skenario cadangan / restoran lain, maka tulislah di komentar, dan kami akan memberi tahu Anda segalanya dengan cara sebaik mungkin.