
* Pertanian - (dari pertanian Inggris) - pengulangan panjang dan membosankan dari aksi permainan tertentu untuk tujuan tertentu (mendapatkan pengalaman, mendapatkan sumber daya, dll.).
Pendahuluan
Baru-baru ini (1 Oktober), sesi baru kursus DS / ML yang sangat baik diluncurkan (Saya sangat merekomendasikan siapa pun yang ingin, seperti yang sekarang disebut, untuk "memasuki" DS sebagai kursus awal). Dan, seperti biasa, setelah menyelesaikan kursus apa pun, lulusan memiliki pertanyaan - di mana mendapatkan pengalaman praktis sekarang untuk mengkonsolidasikan pengetahuan teoritis yang belum baku. Jika Anda mengajukan pertanyaan ini di forum profil mana pun, maka jawabannya kemungkinan besar akan menjadi satu - selesaikan dengan Kaggle. Kaggle adalah ya, tetapi di mana untuk memulai dan bagaimana menggunakan platform ini paling efektif untuk keterampilan praktis? Pada artikel ini, penulis akan mencoba memberikan jawaban atas pertanyaan-pertanyaan ini berdasarkan pengalamannya sendiri, serta menggambarkan lokasi rake utama pada bidang DS kompetitif, untuk mempercepat proses pemompaan dan mendapatkan penggemar dari itu.
Beberapa kata tentang kursus dari penciptanya:
Kursus mlcourse.ai adalah salah satu kegiatan berskala besar dari komunitas OpenDataScience. @Yorko dan perusahaan (~ 60 orang) menunjukkan bahwa keterampilan keren dapat diperoleh di luar universitas, dan bahkan benar-benar gratis. Gagasan utama kursus adalah kombinasi optimal antara teori dan praktik. Di satu sisi, penyajian konsep-konsep dasar tidak terjadi tanpa matematika, di sisi lain - banyak pekerjaan rumah, kompetisi dan proyek Kaggle Inclass akan memberikan, dengan investasi tertentu dari usaha Anda, keterampilan pembelajaran mesin yang luar biasa. Tidak mungkin untuk tidak memperhatikan sifat kompetitif dari kursus - penilaian umum siswa sedang dilakukan, yang sangat memotivasi. Kursus ini juga berbeda karena berlangsung di komunitas yang benar-benar bersemangat.
Kursus ini mencakup dua kompetisi Kaggle Inclass. Keduanya sangat menarik, mereka bekerja dengan baik dalam konstruksi tanda. Yang pertama adalah identifikasi pengguna berdasarkan urutan situs yang dikunjungi . Yang kedua adalah prediksi popularitas sebuah artikel di Medium . Manfaat utama adalah dari dua pekerjaan rumah, di mana Anda harus pintar dan mengalahkan garis dasar dalam kompetisi ini.
Setelah membayar upeti ke kursus dan penciptanya, kami melanjutkan kisah kami ...
Saya ingat diri saya satu setengah tahun yang lalu, kursus (masih versi pertama) dari Andrew Ng selesai, spesialisasi dari Institut Fisika dan Teknologi Moskow selesai , segunung buku dibaca - kepala teoritis penuh, tetapi ketika Anda mencoba untuk menyelesaikan tugas tempur dasar - timbullah kehebohan. Tidak, bagaimana mengatasi masalah - jelas algoritma mana yang diterapkan - juga dapat dimengerti, tetapi kode ini sangat sulit untuk ditulis, dengan sklearn / panda membantu diakses setiap menit, dll. Mengapa demikian - tidak ada jaringan pipa yang terakumulasi dan perasaan kode "di ujung jari Anda".
Ini tidak akan berhasil, pikir si penulis, dan pergi ke Kaggle. Sangat menakutkan untuk memulai segera dari kompetisi pertempuran, dan House of Competition " Harga Rumah: Teknik Regresi Lanjut " menjadi tanda pertama, yang membentuk pendekatan untuk pemompaan efektif yang dijelaskan dalam artikel ini.
Dalam apa yang akan dijelaskan nanti, tidak ada pengetahuan, semua teknik, metode dan teknik jelas dan dapat diprediksi, tetapi ini tidak mengurangi efektivitasnya. Setidaknya, mengikuti mereka, penulis berhasil mengambil mati Kaggle Competition Master selama enam bulan dan tiga kompetisi dalam mode solo dan, pada saat menulis artikel ini, memasuki peringkat 200 teratas peringkat dunia Kaggle . Ngomong-ngomong, ini menjawab pertanyaan mengapa penulis bahkan membiarkan dirinya berani menulis artikel semacam ini.
Singkatnya apa itu Kaggle
Kaggle adalah salah satu platform paling terkenal untuk mengadakan kompetisi dalam Ilmu Data. Dalam setiap kompetisi, penyelenggara mengunggah deskripsi masalah, data untuk menyelesaikan masalah ini, metrik yang digunakan untuk mengevaluasi solusi - dan menetapkan tenggat waktu serta hadiah. Peserta diberikan dari 3 hingga 5 upaya (atas kehendak penyelenggara) per hari untuk "mengirimkan" (mengirimkan solusi mereka sendiri).
Data dibagi menjadi sampel pelatihan (kereta) dan tes (tes). Untuk bagian pelatihan, nilai variabel target (target) diketahui, untuk bagian tes - tidak. Tugas para peserta adalah membuat model yang, saat dilatih pada bagian pelatihan data, akan menghasilkan hasil maksimal pada ujian.
Setiap peserta membuat prediksi untuk sampel uji - dan mengirimkan hasilnya ke Kaggle, kemudian robot (yang mengetahui variabel target untuk pengujian) mengevaluasi hasil yang dikirim, yang ditampilkan di papan peringkat.
Tetapi tidak semuanya begitu sederhana - data pengujian, pada gilirannya, dibagi dalam proporsi tertentu menjadi bagian publik (publik) dan privat (privat). Selama kompetisi, keputusan yang dikirim dievaluasi, sesuai dengan metrik yang ditetapkan oleh penyelenggara, pada bagian publik dari data dan diletakkan di leaderboard (yang disebut leaderboard publik) - dimana para peserta dapat mengevaluasi kualitas model mereka. Keputusan akhir (biasanya dua - atas pilihan peserta) dievaluasi pada bagian pribadi dari data pengujian - dan hasilnya jatuh pada papan peringkat pribadi, yang tersedia hanya setelah akhir kompetisi dan dimana, pada kenyataannya, hasil akhir dievaluasi, hadiah, roti, dan medali didistribusikan.
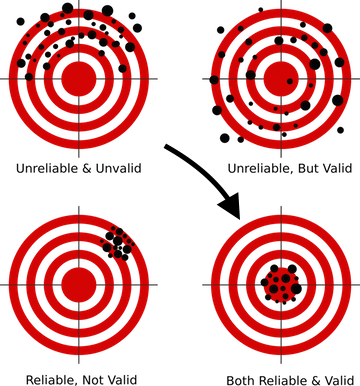
Jadi, selama kompetisi, hanya informasi yang tersedia bagi para peserta ketika model mereka berperilaku (hasil apa - atau menunjukkan kecepatan) pada bagian publik dari data uji. Jika, dalam kasus kuda bulat dalam ruang hampa, bagian pribadi dari data bertepatan dalam distribusi dan statistik dengan publik - semuanya baik-baik saja, tetapi jika tidak - maka model yang telah bekerja dengan baik di depan umum mungkin tidak bekerja di bagian pribadi, yaitu, overfix (retrain). Dan di sini muncul apa yang disebut "penerbangan" dalam jargon, ketika orang-orang dari tempat ke-10 terbang ke bawah 1000-2000 tempat di bagian pribadi karena fakta bahwa model yang mereka pilih telah dilatih ulang dan tidak dapat memberikan akurasi yang diperlukan untuk data baru.

Bagaimana cara menghindarinya? Untuk ini, pertama-tama, perlu untuk membangun skema validasi yang benar, sesuatu yang diajarkan dalam pelajaran pertama di hampir semua kursus DS. Karena jika model Anda tidak dapat memberikan perkiraan yang benar pada data yang belum pernah dilihatnya - tidak peduli teknik canggih apa yang Anda gunakan, tidak peduli seberapa rumit jaringan saraf yang Anda bangun - dalam produksi model seperti itu tidak dapat diproduksi, karena hasilnya tidak berharga.
Untuk setiap kompetisi di Kaggle, halaman terpisah dibuat untuk bagian yang berisi data, dengan deskripsi metrik - dan yang paling menarik bagi kita - sebuah forum dan kernel.
Forum dia dan forum Kaggle, orang-orang menulis, berdiskusi, dan berbagi ide. Tetapi kernel sudah lebih menarik. Faktanya, ini adalah kemampuan untuk menjalankan kode Anda sendiri yang memiliki akses langsung ke data persaingan di cloud Kaggle (analog dari AW Amazon, Google GCE, dll.) Sumber daya terbatas dialokasikan untuk setiap kernel, jadi jika tidak ada banyak data, maka bekerjalah dengan dengan mereka Anda dapat langsung dari browser di situs web Kaggle - menulis kode, menjalankannya untuk eksekusi, mengirimkan hasilnya. Dua tahun lalu, Kaggle diakuisisi oleh Google, jadi tidak mengherankan bahwa fungsi ini menggunakan Google Cloud Engine "di bawah tenda".
Selain itu, ada beberapa kompetisi (baru-baru ini - Mercari ), di mana Anda dapat bekerja dengan data secara umum hanya melalui kernel. Format yang sangat menarik, meratakan perbedaan dalam perangkat keras antara peserta dan memaksa otak untuk mengaktifkan kode dan pendekatan, karena, secara alami, kernel memiliki batasan sumber daya yang ketat, pada saat itu - 4 core / 16 GB RAM / 60 menit run-time / 1 GB awal dan ruang disk keluaran. Saat mengerjakan kompetisi ini, penulis belajar lebih banyak tentang optimasi jaringan saraf daripada dari kursus teori apa pun. Sedikit tidak cukup untuk emas, selesai solo pada tanggal 23, tetapi menerima pengalaman dan kesenangan cukup banyak ...
Mengambil kesempatan ini, saya ingin mengucapkan terima kasih sekali lagi kepada rekan-rekan saya dari ods.ai - Arthur Stepanenko (arthur) , Konstantin Lopukhin (kostia) , Sergey Fironov (sergeif) atas saran dan dukungan mereka dalam kompetisi ini. Secara umum, ada banyak poin menarik, Konstantin Lopukhin (kostia) , yang mengambil tempat pertama dengan Paweł Jankiewicz , kemudian menguraikan apa yang disebut " referensi penghinaan 75 baris " di ruang obrolan - sebuah kernel dalam 75 baris kode yang menampilkan hasil ke zona emas papan peringkat. Ini, tentu saja, harus dilihat :)
Oke, terganggu, dan sebagainya - orang-orang menulis kode dan mengeluarkan kernel dengan solusi, ide menarik dan banyak lagi. Biasanya, dalam setiap kompetisi, setelah beberapa minggu, satu atau dua EDA kernel yang sangat baik (analisis data eksplorasi) muncul, dengan deskripsi rinci tentang dataset, statistik, karakteristik, dll. Dan beberapa garis dasar (solusi dasar), yang, tentu saja, tidak menunjukkan hasil terbaik di papan peringkat, tetapi mereka dapat digunakan sebagai titik awal untuk membuat solusi Anda sendiri.
Kenapa Kaggle?

Faktanya, tidak peduli platform apa yang akan Anda mainkan, hanya Kaggle adalah salah satu yang pertama dan paling dipromosikan, dengan komunitas yang sangat baik dan lingkungan yang cukup nyaman (saya berharap mereka akan memperbaiki kernel untuk stabilitas dan kinerja, jika tidak banyak yang ingat neraka yang terjadi di Mercari ) Tapi, secara umum, platform ini sangat nyaman dan mandiri, dan dadunya masih dihargai.
Penyimpangan kecil pada umumnya pada topik kompetitif DS. Sangat sering, dalam artikel, percakapan dan komunikasi lainnya, pikiran terdengar bahwa ini semua omong kosong, pengalaman dalam kompetisi tidak ada hubungannya dengan tugas nyata, dan orang-orang di sana terlibat dalam penyetelan tempat desimal ke-5, yang gila dan bercerai dari kenyataan. Mari kita lihat masalah ini sedikit lebih detail:
Sebagai dokter spesialis DS, tidak seperti akademisi dan sains, kami, dalam pekerjaan kami, harus dan akan menyelesaikan masalah bisnis. Itu (di sini adalah referensi ke CRISP-DM ) untuk menyelesaikan tugas itu perlu:
- memahami tantangan bisnis
- mengevaluasi data pada subjek apakah jawaban untuk tugas bisnis ini mungkin disembunyikan di dalamnya
- kumpulkan data tambahan jika yang ada tidak cukup untuk mendapatkan jawaban
- pilih metrik yang paling mendekati tujuan bisnis
- dan hanya setelah itu pilih model, konversikan data ke model yang dipilih dan "tiriskan hgbusta". (C)
Empat poin pertama dari daftar ini tidak diajarkan di mana pun (koreksi saya, jika kursus seperti itu telah muncul - saya akan mendaftar tanpa ragu-ragu), di sini kita hanya dapat belajar dari pengalaman rekan kerja yang bekerja di industri ini. Dan inilah poin terakhir - mulai dari pilihan model dan seterusnya, adalah mungkin dan perlu untuk memompa dalam kompetisi.
Dalam kompetisi apa pun, sebagian besar pekerjaan untuk kami dilakukan oleh penyelenggara. Kami memiliki tujuan bisnis yang diuraikan, metrik perkiraan telah dipilih, data telah dikumpulkan - dan tugas kami adalah membangun saluran pipa yang berfungsi dari semua lego ini. Dan di sini keterampilan dipompa - bagaimana bekerja dengan pass, bagaimana mempersiapkan data untuk jaringan saraf dan pohon (dan mengapa jaringan saraf memerlukan pendekatan khusus), cara membangun validasi dengan benar, bagaimana tidak melatih ulang, bagaimana memilih hyperparameters, bagaimana ....... selusin atau dua “bagaimana,” yang kinerjanya kompeten membedakan seorang spesialis yang baik dari orang-orang yang melewati profesi kami.
Apa yang Anda bisa "bertani" di Kaggle

Pada dasarnya, dan ini masuk akal, semua pendatang baru datang ke Kaggle untuk mendapatkan dan meningkatkan pengalaman praktis, tetapi jangan lupa bahwa di samping ini setidaknya ada dua tujuan lagi:
- Medali pertanian dan dadu
- Reputasi Pertanian di Komunitas Kaggle
Hal utama yang perlu diingat adalah bahwa ketiga tujuan ini sangat berbeda, diperlukan pendekatan yang berbeda untuk mencapainya, dan Anda tidak boleh mencampurkannya terutama pada tahap awal!
Bukan untuk apa-apa yang ditekankan "pada tahap awal" ketika Anda memompa - tiga tujuan ini akan bergabung menjadi satu dan akan diselesaikan secara paralel, tetapi saat Anda baru memulai - jangan mencampurnya ! Dengan cara ini Anda akan menghindari rasa sakit, kekecewaan, dan kebencian di dunia yang tidak adil ini.
Mari kita membahas tujuan dari bawah ke atas secara singkat:
- Reputasi - dipompa dengan menulis posting yang bagus (dan komentar) di forum dan membuat kernel yang bermanfaat. Misalnya, kernel EDA (lihat di atas), postingan yang menggambarkan teknik non-standar, dll.
- Medali adalah topik yang sangat kontroversial dan benci, tetapi oh well. Ini dipompa dengan memadukan kernel publik (*), partisipasi dalam tim dengan bias dalam pengalaman, dan menciptakan saluran pipa teratas Anda sendiri.
- Pengalaman - dipompa melalui analisis keputusan dan mengerjakan kesalahan.
(*) pencampuran kernel publik adalah teknik medali pertanian di mana kernel diletakkan dengan kecepatan maksimum pada leaderboard publik dipilih, prediksi mereka dirata-rata (dicampur), dan hasilnya diserahkan. Biasanya, metode ini mengarah pada pakaian keras (pelatihan ulang untuk melatih) dan terbang di privet, tetapi kadang-kadang memungkinkan Anda untuk mendapatkan kiriman hampir berwarna perak. Penulis, pada tahap awal, tidak merekomendasikan pendekatan yang sama (baca di bawah tentang ikat pinggang dan celana).
Saya merekomendasikan tujuan pertama untuk memilih "pengalaman" dan berpegang teguh pada itu sampai saat ketika Anda merasa bahwa Anda siap untuk mengerjakan dua / tiga tujuan secara bersamaan.
Ada dua poin lagi yang layak disebut (Vladimir Iglovikov (ternaus) - terima kasih atas pengingatnya).
Yang pertama adalah konversi dari upaya yang diinvestasikan dalam Kaggle menjadi tempat kerja baru, lebih menarik dan / atau dibayar tinggi. Tidak peduli bagaimana kematian Kaggle diratakan sekarang, untuk memahami orang, garis dalam ringkasan Master Kompetisi Kaggle, dan prestasi lainnya masih berharga.
Untuk menggambarkan hal ini, kita dapat mengutip dua wawancara ( satu , dua ) dengan rekan kami Sergey Mushinsky (cepera_ang) dan Alexander Buslaev (albu)
Dan juga pendapat Valery Babushkin ( Venhead) :
Valery Babushkin - Kepala Ilmu Data di X5 Retail Group (jumlah staf saat ini adalah 30 orang + 20 lowongan sejak 2019)
Kepala grup analitik Yandex Advisor
Master Kompetisi Kaggle adalah metrik proxy yang sangat baik untuk mengevaluasi anggota tim di masa depan. Tentu saja, sehubungan dengan acara terbaru dalam bentuk tim yang terdiri dari 30 orang dan lokomotif yang tidak ditutup-tutupi, diperlukan studi profil yang sedikit lebih teliti daripada sebelumnya, tetapi ini masih dalam hitungan beberapa menit. Seseorang yang telah mencapai gelar master, dengan tingkat probabilitas tinggi tahu cara menulis kode dengan kualitas paling tidak rata-rata, cukup berpengalaman dalam pembelajaran mesin, tahu cara membersihkan data, dan membangun solusi yang stabil. Jika Anda masih tidak bisa membanggakan lidah master, fakta partisipasi juga merupakan nilai tambah, setidaknya kandidat tahu tentang keberadaan Kagl dan tidak terlalu malas dan menghabiskan waktu menguasainya. Dan jika sesuatu selain kernel publik diluncurkan dan solusi yang dihasilkan melebihi hasilnya (yang cukup mudah untuk diperiksa), maka ini adalah kesempatan untuk diskusi rinci tentang detail teknis, yang jauh lebih baik dan lebih menarik daripada pertanyaan teori klasik, jawaban yang memberikan kurang pemahaman tentang bagaimana seseorang akan melakukan pekerjaan di masa depan. Satu-satunya hal yang saya harus takuti dan dengan apa yang saya temui adalah beberapa orang berpikir bahwa pekerjaan DS adalah sesuatu seperti Kagl, yang pada dasarnya salah. Banyak yang berpikir bahwa DS = ML, yang juga merupakan kesalahan
Poin kedua adalah bahwa solusi untuk banyak masalah dapat dibingkai dalam bentuk pra-cetak atau artikel, yang di satu sisi memungkinkan pengetahuan bahwa pikiran kolektif melahirkan selama kompetisi tidak mati di belantara forum, tetapi di sisi lain menambahkan satu baris lagi ke portofolio penulis dan +1 untuk visibilitas, yang dalam hal apa pun memiliki efek positif pada karier dan indeks kutipan.
Sebagai contoh, daftar karya rekan-rekan kami mengikuti hasil dari beberapa kompetisiPenulis (dalam urutan abjad):
Andrei. snikolenko, ternaus, twoleggedeye, versus, vicident, zfturbo
Cara menghindari rasa sakit karena kehilangan medali

Untuk mencetak gol!
Saya akan jelaskan. Di hampir setiap kompetisi, mendekati akhir, sebuah kernel diletakkan pada publik dengan solusi yang menggeser seluruh papan peringkat ke atas, tetapi untuk Anda, dengan keputusan Anda, turun sesuai dengan itu. Dan setiap kali forum mulai NYERI! Bagaimana mungkin saya punya keputusan tentang perak, dan sekarang saya bahkan tidak menarik perunggu. Ada apa, dapatkan kembali.
Ingat - Kaggle adalah DS kompetitif. Tempat di papan peringkat Anda berada di tangan Anda. , , , .
— .
, — . , , , - . , — . , - .
, , — … . , , — — .
, . — . ( Talking Data , 8- ) , (ppleskov) : " , , — ". , .
— :
" "()
, .

— python 3.6 jupyter notebook ubuntu . Python - DS, , jupyter , jupyter_contrib_nbextensions , , ubuntu — , bash :)
jupyter_contrib_nbextensions :
- Collapsible headings ( )
- Code folding ( )
- Split cells (, - )
.
- , . — . — .
, jupyter notebook , , . ( , , ( (ternaus) )
, jupyter - IDE, pycharm .
, , " ". , .
/OOF (.) .
(*) OOF — out of folds , -. . .
Bagaimana? :
Secara umum, di masyarakat ada kecenderungan untuk secara bertahap beralih ke opsi ketiga, karena dan yang pertama dan kedua memiliki kelemahan mereka, tetapi mereka sederhana, dapat diandalkan dan, terus terang, bagi Kaggle mereka sudah cukup.

Ya, lebih lanjut tentang python untuk mereka yang bukan programmer - jangan takut. Tugas Anda adalah untuk memahami struktur dasar kode dan esensi dasar bahasa untuk memahami kernel orang lain dan menulis perpustakaan Anda. Ada banyak kursus bagus untuk pemula di Web, mungkin di komentar mereka akan memberi tahu Anda di mana tepatnya. Sayangnya (atau untungnya) saya tidak bisa menilai kualitas kursus seperti itu, jadi saya tidak memberikan tautan dalam artikel.
Jadi, mari kita beralih ke framework.

Catatan
Semua deskripsi lebih lanjut akan didasarkan pada pekerjaan dengan data tabel dan teks. Gambar, yang sekarang sangat banyak di Kaggle, adalah topik terpisah dengan kerangka kerja terpisah. Pada tingkat dasar, adalah baik untuk dapat memprosesnya, jika hanya untuk mendorong melalui sesuatu seperti ResNet / VGG dan mengeluarkan fitur, tetapi bekerja lebih dalam dan lebih halus dengan mereka adalah topik terpisah dan sangat luas yang tidak dipertimbangkan dalam kerangka artikel ini.
Penulis dengan jujur mengakui bahwa ia tidak pandai menggambar. Satu-satunya upaya untuk terlibat dalam keindahan adalah dalam kompetisi Identifikasi Kamera , di mana, omong-omong, tim kami dengan tag [ ods.ai ] meledakkan seluruh papan peringkat sedemikian rupa sehingga admin Kaggle harus mengunjungi kami di slack untuk memastikan semuanya ada di dalam aturan - dan meyakinkan komunitas. Jadi, dalam kompetisi ini saya mendapat perak kehormatan dengan tempat ke-46, dan ketika saya membaca deskripsi solusi teratas dari rekan-rekan kami, saya menyadari bahwa saya tidak bisa naik lebih tinggi - mereka benar-benar menggunakan ilmu hitam dengan augmentasi, kebaikan 300GB data, pengorbanan dan sebagainya.
Secara umum, jika Anda ingin memulai dengan gambar, maka Anda memerlukan kerangka kerja lain dan panduan lainnya.
Tujuan utama
Tugas Anda adalah menulis pipa (dirancang sebagai modul notebook jupyter +) untuk tugas-tugas berikut:
- EDA (analisis data eksplorasi) . Di sini kita perlu membuat komentar - ada orang-orang terlatih khusus di Kaggle :) yang melihat kernel EDA yang menakjubkan di setiap kompetisi. Anda hampir tidak akan berhasil melampaui mereka, tetapi Anda masih harus memahami bagaimana Anda dapat melihat data, karena Dalam misi tempur, orang yang terlatih khusus ini adalah Anda. Oleh karena itu, kami mempelajari pendekatan, memperluas perpustakaan kami.
- Pembersihan Data - segala sesuatu tentang pembersihan data. Emisi, kelalaian, dll.
- Persiapan data - semua yang terkait dengan persiapan data untuk model. Beberapa blok:
- Model
- Model linier
- Model pohon
- Jaringan saraf
- Eksotis (FM / FFM)
- Pemilihan fitur
- Pencarian Hyperparameter
- Ensemble
Dalam kernel, biasanya semua tugas ini dikumpulkan dalam satu kode, yang dapat dimengerti, tetapi saya sangat merekomendasikan bahwa untuk masing-masing subtugas ini dibuat laptop terpisah dan modul terpisah (satu set modul). Jadi akan lebih mudah bagi Anda nanti.
Peringatan kemungkinan holivar - struktur kerangka kerja ini bukan kebenaran pamungkas, ada banyak cara lain untuk menyusun jaringan pipa Anda - ini hanyalah salah satunya.
Data ditransmisikan antara modul baik dalam bentuk CSV, atau bulu / acar / hdf - yang lebih nyaman bagi Anda dan apa yang Anda terbiasa atau jiwa bohong.
Sebenarnya, masih banyak tergantung pada jumlah data, di TalkingData, misalnya, saya harus melalui memmap untuk mengatasi kekurangan memori saat membuat dataset untuk lgb.
Dalam kasus lain, data utama disimpan dalam hdf / feather, sesuatu yang kecil (seperti seperangkat atribut yang dipilih) ada di CSV . Saya ulangi - tidak ada template, yang terbiasa dengan apa, bekerja dengan itu.
Tahap awal
Kami mengikuti kompetisi Memulai apa pun (seperti yang telah disebutkan, penulis mulai dengan Harga Rumah: Teknik Regresi Lanjut ), dan mulai membuat laptop kami. Kami membaca kernel publik, menyalin potongan kode, prosedur, pendekatan, dll. dll. Kami menjalankan data melalui jalur pipa, mengirimkan - kami melihat hasilnya, kami meningkatkan dan seterusnya dalam lingkaran.
Tugas pada tahap ini adalah mengumpulkan pipa siklus penuh yang bekerja secara efisien, mulai dari pemuatan dan pembersihan data hingga pengiriman akhir.
Daftar sampel apa yang harus siap dan berfungsi 100% sebelum melanjutkan ke langkah berikutnya:
- EDA . (statistik pada dataset, plot-plot, kisaran kategori, ...)
- Pembersihan Data. (melewati fillna, kategori pembersihan, menggabungkan kategori)
- Persiapan data
- Umum (memproses kategori - label / ohe / frekuensi, proyeksi angka pada kategori, transformasi angka, binning)
- Untuk regresi (berbagai penskalaan)
- Model
- Model linear (berbagai regresi - ridge / logistik)
- Model pohon (lgb)
- Pemilihan fitur
- Ensemble
Pergi berperang

Pilih kompetisi yang Anda suka dan ... mulai :)
Meskipun tidak ada skema validasi yang berfungsi - tidak ada langkah lebih lanjut !!!
- Jalankan data melalui saluran yang kami hasilkan dan kirimkan hasilnya
- Kami memegang kepala kami, gila, tenang ... dan terus ...
- Kami membaca semua kernel tentang teknik dan pendekatan yang digunakan.
- Baca semua diskusi forum
- Kami merombak / menambah pipa dengan teknik baru
- Kami lolos ke langkah 1
Ingat - tujuan kami pada tahap ini adalah untuk mendapatkan pengalaman ! Isi pipa kami dengan pendekatan dan metode kerja, isi modul kami dengan kode kerja. Kami tidak peduli dengan medali - atau lebih tepatnya, itu bagus jika Anda dapat segera mengambil tempat Anda di leaderboard, tetapi jika tidak, jangan khawatir. Kami tidak datang ke sini selama lima menit, medali dan mati tidak akan pergi ke mana pun.
Di sini kompetisi berakhir, apakah Anda di suatu tempat di luar sana, tampaknya semua orang akan meraih yang berikutnya?
TIDAK!
Apa yang Anda lakukan selanjutnya:
- Menunggu lima hari. Jangan membaca forum, lupakan Kaggle saat ini. Biarkan otak Anda rileks dan mengaburkan mata Anda.
- Kembali ke kompetisi. Selama lima hari ini, dengan aturan selera yang baik, semua atasan akan memposting deskripsi keputusan mereka - dalam posting di forum, dalam bentuk kernel, dalam bentuk repositori github.
Dan di sini dimulai NERAKA pribadi Anda!
- Anda mengambil beberapa lembar format A4, pada setiap tuliskan nama modul dari kerangka kerja di atas (EDA / Persiapan / Model / Ensemble / Pemilihan fitur / Pencarian Hyperparameters / ...)
- Secara konsisten baca semua solusi, tulis teknik, metode, dan pendekatan baru yang baru bagi Anda di selebaran yang sesuai.
Dan hal terburuk:
- Secara konsisten untuk setiap modul, tulis (mata-mata) implementasi pendekatan dan metode ini, perluas pipeline dan perpustakaan Anda.
- Dalam mode pasca-kirim, jalankan data melalui pipa Anda yang diperbarui sampai Anda memiliki solusi di zona emas atau sampai kesabaran dan saraf habis.
Dan hanya setelah itu kami melanjutkan ke kompetisi berikutnya.
Tidak, saya tidak kacau. Ya, itu mungkin dan lebih mudah. Anda yang memutuskan.
Mengapa menunggu 5 hari dan tidak langsung membaca, karena di forum Anda dapat mengajukan pertanyaan? Pada tahap ini (menurut saya) lebih baik membaca utas yang sudah terbentuk dengan diskusi solusi, pertanyaan yang mungkin Anda miliki - apakah seseorang akan bertanya, atau lebih baik tidak bertanya sama sekali, tetapi untuk mencari jawabannya sendiri)
Mengapa semua ini terjadi? Nah, sekali lagi - tugas tahap ini adalah mengembangkan database solusi, metode, dan pendekatan. Memerangi basis kerja. Sehingga dalam kompetisi berikutnya Anda tidak membuang waktu, tetapi segera katakan - ya, maksud pengkodean target bisa masuk, dan omong-omong, saya memiliki kode yang benar untuk ini melalui lipatan di lipatan. Atau oh! Saya ingat kemudian ensemble melewati scipy.optimize , dan omong-omong, kode sudah siap untuk saya.
Sesuatu seperti itu ...
Pergi ke mode kerja
Dalam mode ini, kami menyelesaikan beberapa kompetisi. Setiap kali kami memperhatikan bahwa ada semakin sedikit catatan di lembar, dan semakin banyak kode dalam modul. Perlahan-lahan, tugas analisis dikurangi menjadi fakta bahwa Anda baru saja membaca deskripsi solusinya, katakan ya, wow, oh itu dia! Dan tambahkan satu atau dua mantra atau pendekatan baru ke celengan Anda.
Setelah itu, mode berubah ke mode penanganan kesalahan. Pangkalan siap untuk Anda, sekarang hanya perlu diterapkan dengan benar. Setelah setiap kompetisi, saat membaca deskripsi solusi, lihat apa yang tidak Anda lakukan, apa yang bisa dilakukan lebih baik, apa yang Anda lewatkan, atau di mana Anda masuk ke dalamnya, seperti yang saya lakukan di Toxic . Dia berjalan cukup baik, di perut emas, dan secara pribadi terbang turun 1.500 posisi. Ini memalukan untuk menangis ... tetapi tenang, menemukan kesalahan, menulis posting di malas - dan belajar pelajaran.
Tanda jalan keluar terakhir ke mode operasi dapat menjadi kenyataan bahwa salah satu deskripsi dari solusi teratas akan ditulis dari nama panggilan Anda.
Apa yang kira - kira harus ada dalam pipa pada akhir tahap ini:
- Semua jenis opsi untuk preprocessing dan membuat fitur numerik - proyeksi, hubungan,
- Berbagai metode bekerja dengan kategori - Penyandian target rata-rata dalam versi, frekuensi, label / ohe yang benar,
- Berbagai skema penyematan di atas teks (Glove, Word2Vec, Fasttext)
- Berbagai skema vektorisasi teks (Hitung, TF-IDF, Hash)
- Beberapa skema validasi (N * M untuk validasi silang standar, berbasis waktu, berdasarkan grup)
- Optimalisasi Bayesian / hyperopt / sesuatu yang lain untuk memilih hyperparameters
- Acak / Sasaran permutasi / Boruta / RFE - untuk memilih fitur
- Model linear - dengan gaya yang sama pada satu set data
- LGB / XGB / Catboost - dengan gaya yang sama pada satu set data
Penulis membuat metaclasses secara terpisah untuk model linier dan berbasis pohon, dengan antarmuka eksternal tunggal untuk tingkat perbedaan dalam API untuk model yang berbeda. Tetapi sekarang Anda dapat menjalankan dalam satu baris kunci tunggal, misalnya, LGB atau XGB melalui satu set data yang diproses.
- Beberapa jaringan saraf untuk semua kesempatan (kami tidak mengambil gambar untuk saat ini) - embeddings / CNN / RNN untuk teks, RNN untuk urutan, Feed-Forward untuk yang lainnya. Adalah baik untuk memahami dan dapat membuat enkoder otomatis .
- Ensemble berdasarkan lgb / regression / scipy - untuk tugas-tugas regresi dan klasifikasi
- Baik sudah bisa menggunakan Algoritma Genetika , kadang-kadang berjalan dengan baik
Untuk meringkas
Olahraga apa pun, dan DS kompetitif juga merupakan olahraga, banyak berkeringat dan banyak pekerjaan. Ini tidak baik atau buruk, itu adalah fakta. Partisipasi dalam kompetisi (jika Anda mendekati prosesnya dengan benar) memompa keterampilan teknis dengan sangat baik, ditambah lagi sedikit atau sedikit mengguncang semangat olahraga ketika Anda benar-benar tidak ingin melakukan sesuatu, secara langsung merusak segalanya - tetapi Anda bangun dengan laptop Anda, mengulang modelnya, memulai perhitungan, sehingga kunyah desimal ke-5 malang ini.
Jadi putuskan Kaggle - pengalaman bertani, medali, dan penggemar!
Beberapa kata tentang jalur pipa penulis
Pada bagian ini saya akan mencoba untuk menggambarkan ide utama dari jaringan pipa dan modul yang dikumpulkan lebih dari satu setengah tahun. Lagi - pendekatan ini tidak mengklaim sebagai universal atau unik, tetapi tiba-tiba seseorang akan membantu.
- Semua kode rekayasa fitur, kecuali pengkodean target rata-rata, dikeluarkan dalam modul terpisah dalam bentuk fungsi. Saya mencoba mengumpulkan melalui objek, ternyata tidak praktis, dan dalam hal ini tidak perlu juga.
- Semua fitur rekayasa fitur dibuat dalam gaya yang sama dan memiliki satu panggilan dan tanda tangan kembali:
def do_cat_dummy(data, attrs, prefix_sep='_ohe_', params=None): # do something return _data, new_attrs
Kami melewati dataset, atribut untuk pekerjaan, awalan untuk atribut baru dan parameter tambahan ke input. Pada output, kita mendapatkan dataset baru dengan atribut baru dan daftar atribut ini. Selanjutnya dataset baru ini disimpan dalam acar / bulu yang terpisah.
Apa yang diberikan ini adalah bahwa kita mendapat kesempatan untuk dengan cepat mengumpulkan dataset untuk pelatihan dari kubus yang dibuat sebelumnya. Misalnya, untuk kategori kami melakukan tiga pemrosesan sekaligus - Label Encoding / OHE / Frequency, simpan dalam tiga bulu terpisah, dan kemudian pada tahap pemodelan kami hanya bermain dengan blok-blok ini, menciptakan berbagai set data pelatihan dalam satu gerakan elegan.
pickle_list = [ 'attrs_base', 'cat67_ohe', # 'cat67_freq', ] short_prefix = 'base_ohe' _attrs, use_columns, data = load_attrs_from_pickle(pickle_list) cat_columns = []
Jika Anda perlu membuat dataset lain, ubah pickle_list , reboot, dan bekerja dengan dataset baru.
Himpunan fungsi utama atas data tabular (nyata dan kategorikal) meliputi berbagai pengkodean kategori, proyeksi atribut numerik pada kategorikal, serta berbagai transformasi.
def do_cat_le(data, attrs, params=None, prefix='le_'): def do_cat_dummy(data, attrs, prefix_sep='_ohe_', params=None): def do_cat_cnt(data, attrs, params=None, prefix='cnt_'): def do_cat_fact(data, attrs, params=None, prefix='bin_'): def do_cat_comb(data, attrs_op, params=None, prefix='cat_'): def do_proj_num_2cat(data, attrs_op, params=None, prefix='prj_'):
Pisau Swiss universal untuk menggabungkan atribut, di mana kita mentransfer daftar atribut sumber dan daftar fungsi konversi, pada output yang kita dapatkan, seperti biasa, dataset dan daftar atribut baru.
def do_iter_num(data, attrs_op, params=None, prefix='comb_'):
Ditambah berbagai konverter khusus tambahan.
Untuk memproses data teks, modul terpisah digunakan, yang mencakup berbagai metode preprocessing, tokenization, lemmatization / stemming, terjemahan ke dalam tabel frekuensi, dan sebagainya. dll. Semuanya standar menggunakan sklearn , nltk dan keras .
Rangkaian waktu juga diproses oleh modul terpisah, dengan fungsi untuk mengubah dataset asli untuk kedua tugas biasa (regresi / klasifikasi) dan urutan-ke-urutan. Terima kasih kepada François Chollet untuk penyelesaian yang keras sehingga pembangunan model seq-2-seq tidak akan menyerupai ritual voodoo memanggil setan.
Dalam modul yang sama, omong-omong, ada fungsi analisis statistik seri yang biasa - memeriksa stasioneritas, dekomposisi STL, dll ... Sangat membantu pada tahap awal analisis untuk "merasakan" seri dan melihat seperti apa rasanya.
Fungsi-fungsi yang tidak dapat langsung diterapkan ke seluruh dataset, tetapi perlu digunakan di dalam lipatan selama cross-validasi, ditempatkan dalam modul terpisah:
- Artinya pengkodean target
- Upsampling / downsampling
Mereka dilewatkan di dalam kelas model (baca tentang model di bawah) pada tahap pelatihan.
_fpreproc = fpr_target_enc _fpreproc_params = fpr_target_enc_params _fpreproc_params.update(**{ 'use_columns' : cat_columns, })
- Untuk pemodelan, metaclass telah dibuat yang menggeneralisasi konsep model dengan metode abstrak: fit / predict / set_params / etc. Untuk setiap perpustakaan tertentu (LGB, XGB, Catboost, SKLearn, RGF, ...) implementasi dari metaclass ini dibuat.
Artinya, untuk bekerja dengan LGB kami membuat model
model_to_use = 'lgb' model = KudsonLGB(task='classification')
Untuk XGB:
model_to_use = 'xgb' metric_name= 'auc' task='classification' model = KudsonXGB(task=task, metric_name=metric_name)
Dan semua fungsi selanjutnya beroperasi dengan model .
Untuk validasi, beberapa fungsi telah dibuat yang segera menghitung prediksi dan OOF untuk beberapa seed selama cross-validation, serta fungsi terpisah untuk validasi reguler melalui train_test_split. Semua fungsi validasi dioperasikan menggunakan metode meta-model, yang memberikan kode model-independen dan memfasilitasi koneksi ke pipa saluran perpustakaan lain.
res = cv_make_oof( model, model_params, fit_params, dataset_params, XX_train[use_columns], yy_train, XX_Kaggle[use_columns], folds, scorer=scorer, metric_name=metric_name, fpreproc=_fpreproc, fpreproc_params=_fpreproc_params, model_seed=model_seed, silence=True ) score = res['score'] XX_train [use_columns], yy_train, XX_Kaggle [use_columns], lipatan, pencetak gol terbanyak = pencetak gol terbanyak, METRIC_NAME = METRIC_NAME, fpreproc = _fpreproc, fpreproc_params = _fpreproc_params, model_seed = model_seed, diam = True res = cv_make_oof( model, model_params, fit_params, dataset_params, XX_train[use_columns], yy_train, XX_Kaggle[use_columns], folds, scorer=scorer, metric_name=metric_name, fpreproc=_fpreproc, fpreproc_params=_fpreproc_params, model_seed=model_seed, silence=True ) score = res['score']
Untuk pemilihan fitur - tidak ada yang menarik, RFE standar, dan permutasi acak acak saya dalam semua cara yang mungkin.
Untuk mencari hyperparameters, optimasi Bayesian terutama digunakan, sekali lagi dalam bentuk terpadu sehingga Anda dapat menjalankan pencarian untuk model apa pun (melalui modul validasi silang). Unit ini hidup di laptop yang sama dengan simulasi.
Beberapa fungsi dibuat untuk ansambel, disatukan untuk tugas-tugas regresi dan klasifikasi berdasarkan Ridge / Logreg, LGB, jaringan saraf dan scipy.optimize favorit saya.
Penjelasan kecil - setiap model dari pipeline memberikan dua file sebagai hasilnya: sub_xxx dan oof_xxx , yang merupakan prediksi untuk tes dan prediksi OOF untuk kereta. Selanjutnya, dalam modul ensemble dari direktori yang ditentukan, kami mengunggah pasangan prediksi dari semua model ke dalam dua frame data - df_sub / df_oof . Baiklah, kemudian kita melihat korelasinya, pilih yang terbaik, lalu bangun model level 2 di atas df_oof dan terapkan ke df_sub .
Terkadang, untuk mencari subset model terbaik, pencarian dengan algoritma genetika adalah baik (penulis menggunakan perpustakaan ini ), kadang-kadang metode dari Caruana . Dalam kasus paling sederhana, regresi standar dan scipy.optimize berfungsi dengan baik.
Jaringan saraf hidup dalam modul terpisah, penulis menggunakan keras dalam gaya fungsional , ya, tidak sefleksibel pytorch , tetapi cukup untuk saat ini. Sekali lagi, fungsi pelatihan universal ditulis yang tidak sesuai dengan jenis jaringan.
Saluran pipa ini sekali lagi diuji dalam kompetisi baru-baru ini dari Home Credit , penggunaan yang cermat dan akurat dari semua blok dan modul membawa tempat ke 94 dan perak.
Penulis umumnya siap untuk mengungkapkan gagasan yang menghasut bahwa untuk data tabular dan pipa yang dibuat secara normal, pengajuan akhir untuk setiap kompetisi harus terbang ke dalam 100 papan peringkat teratas. Secara alami, ada pengecualian, tetapi secara umum pernyataan ini tampaknya benar.
Tentang kerja tim

Tidak sesederhana apakah memutuskan Kaggle dalam tim atau solo sangat tergantung pada orang (dan pada tim), tetapi saran saya bagi mereka yang baru memulai adalah mencoba memulai solo. Mengapa Saya akan mencoba menjelaskan sudut pandang saya:
- Pertama, Anda akan memahami kekuatan Anda, melihat kelemahan dan, secara umum, dapat menilai potensi Anda sebagai praktik DS.
- Kedua, bahkan ketika bekerja dalam sebuah tim (kecuali jika itu adalah tim mapan dengan pemisahan peran), mereka masih akan menunggu solusi lengkap yang sudah jadi dari Anda - yaitu, Anda harus sudah memiliki jaringan pipa yang berfungsi. (" Kirim atau tidak ") (C)
- Dan ketiga, ini optimal ketika level pemain dalam tim hampir sama (dan cukup tinggi), maka Anda dapat belajar sesuatu yang sangat berguna tingkat tinggi) Dalam tim yang lemah (tidak ada yang merendahkan, saya berbicara tentang tingkat pelatihan dan pengalaman di Kaggle) imho sangat sulit untuk mempelajari apa pun, lebih baik menggigit forum dan kernel. Ya, Anda bisa bertani medali, tetapi lihat di atas untuk tujuan dan sabuk untuk menjaga celana)
Kiat berguna dari kapten untuk bukti dan kartu rake yang dijanjikan :)

Kiat-kiat ini mencerminkan pengalaman penulis, bukan dogma, dan dapat (dan harus) diverifikasi oleh eksperimen kami sendiri
Selalu mulai dengan membangun validasi yang kompeten - tidak akan ada, semua upaya lain akan terbang ke tungku. Lihat lagi di papan peringkat Mercedes .
Penulis sangat senang bahwa dalam kompetisi ini ia membangun skema validasi silang yang stabil (3x10 lipatan), yang menjaga kecepatan dan membawa tempat ke-42 yang sah)
Jika validasi yang kompeten dibangun, selalu percaya hasil validasi Anda . Jika kecepatan model Anda meningkat saat validasi, tetapi memburuk di depan umum - lebih masuk akal untuk memercayai validasi. Saat menganalisis, cukup baca sepotong data di mana papan peringkat publik dianggap sebagai lipatan lain. Anda tidak ingin memenuhi sampai melimpahi model Anda satu kali?
Jika model dan skema memungkinkan, selalu buat prediksi OOF dan dekatkan dengan model. Pada tahap ansambel, Anda tidak pernah tahu apa yang akan ditembakkan.
Selalu simpan kode / OOF di sebelah hasil untuk menerimanya . Tidak masalah di github, secara lokal, di mana saja. Dua kali, ternyata dalam ansambel model terbaik adalah yang dibuat dua minggu yang lalu di luar kotak, dan kode itu tidak disimpan. Nyeri
Palu pada pemilihan sisi "kanan" untuk validasi silang , ia sendiri berdosa pada awalnya. Lebih baik pilih tiga dan lakukan validasi silang 3xN. Hasilnya akan lebih stabil dan lebih mudah.
Jangan mengejar jumlah model dalam ansambel - lebih baik lebih sedikit, tetapi lebih beragam - lebih beragam dalam model, dalam preprocessing, dalam dataset. Dalam kasus terburuk, menurut parameter, misalnya, satu pohon dalam dengan regularisasi kaku, satu dangkal.
Gunakan shuffle / boruta / RFE untuk memilih fitur , ingat bahwa fitur penting dalam berbagai model berbasis pohon adalah metrik pada burung beo pada kantong serbuk gergaji.
Pendapat pribadi penulis (mungkin tidak sesuai dengan pendapat pembaca) Optimasi Bayesian > pencarian acak> hyperopt untuk memilih hyperparameter. (">" == lebih baik)
Leaderboard merobek diletakkan pada kernel publik paling baik ditangani sebagai berikut:
- Ada waktu - kita melihat apa yang baru dan membangun diri kita sendiri
- Lebih sedikit waktu - ulangi untuk validasi kami, lakukan OOF - dan kencangkan ke ansambel
- Tidak ada waktu sama sekali - kami dengan bodoh berbaur dengan solusi terbaik kami dan terlihat cepat.
Bagaimana memilih dua pengiriman akhir - dengan intuisi, tentu saja. Namun serius, maka biasanya setiap orang mempraktikkan pendekatan berikut:
- Pengajuan konservatif (pada model berkelanjutan) / pengajuan berisiko.
- Terbaik di OOF / Kepemimpinan Publik
Ingat - semuanya angka dan kemungkinan pemrosesan hanya bergantung pada imajinasi Anda. Gunakan klasifikasi alih-alih regresi, perlakukan urutan sebagai gambar, dll.
Dan akhirnya:
- Bergabunglah dengan ods.ai :) mengobrol dan dapatkan kesenangan dari DS dan dari kehidupan! )
Tautan yang bermanfaat

Jenderal
http://ods.ai/ - bagi mereka yang ingin bergabung dengan komunitas DS terbaik :)
https://mlcourse.ai/ - situs web kursus ods.ai
https://www.Kaggle.com/general/68205 - memposting tentang kursus di Kaggle
Secara umum, saya sangat merekomendasikan bahwa dalam mode yang sama yang dijelaskan dalam artikel, tonton siklus video mltrainings - ada banyak pendekatan dan teknik yang menarik.
Video
Kursus
Anda dapat mempelajari lebih lanjut tentang metode dan pendekatan untuk menyelesaikan masalah di Kaggle dari tahun kedua spesialisasi , " Cara Memenangkan Kompetisi Ilmu Data: Belajar dari Kagglers Top"
Bacaan ekstrakurikuler:
Kesimpulan

Topik Ilmu Data secara umum dan kompetitif, khususnya Ilmu Data, sama tidak habisnya dengan atom (C). Dalam artikel ini, penulis hanya sedikit mengungkap topik memompa keterampilan praktis menggunakan platform kompetitif. Jika itu menjadi menarik - hubungkan, lihat-lihat, kumpulkan pengalaman - dan tulis artikel Anda. Semakin banyak konten yang baik, semakin baik bagi kita semua!
Mengantisipasi pertanyaan - tidak, jalur pipa dan perpustakaan penulis belum tersedia secara bebas.
Terima kasih banyak kepada kolega dari ods.ai: Vladimir Iglovikov (ternaus) , Yuri Kashnitsky (yorko) , Valery Babushkin ( venheads) , Alexei Pronkin (pronkin_alexey) , Dmitry Petrov (dmitry_petrov) , Arthur Kuzin (n01z3) , dan juga semua orang yang membaca Anda artikel sebelum publikasi, untuk pengeditan dan ulasan.
Terima kasih khusus kepada Nikita Zavgorodnoy (njz) untuk proofreading terakhir.
Terima kasih atas perhatiannya, semoga artikel ini bermanfaat bagi seseorang.
Nama panggilan saya di Kaggle / ods.ai : kruegger