Di antara jejaring sosial, Twitter lebih cocok daripada yang lain untuk mengekstraksi data teks karena pembatasan ketat pada panjang pesan di mana pengguna dipaksa untuk menempatkan semua yang paling penting.
Saya sarankan Anda menebak teknologi apa yang frame cloud kata ini?
Menggunakan Twitter API, Anda dapat mengekstraksi dan menganalisis berbagai informasi. Artikel tentang cara melakukan ini dengan bahasa pemrograman R.
Menulis kode tidak memerlukan banyak waktu, kesulitan dapat timbul karena perubahan dan pengetatan API Twitter, tampaknya perusahaan itu sangat khawatir tentang masalah keamanan setelah diseret keluar di Kongres AS setelah penyelidikan pengaruh "peretas Rusia" pada pemilihan AS pada 2016.
Akses API
Mengapa seseorang perlu mengambil data industri dari Twitter? Yah, misalnya, membantu membuat prediksi yang lebih akurat mengenai hasil acara olahraga. Tapi saya yakin ada skenario pengguna lain.
Untuk memulai, jelas bahwa Anda harus memiliki akun Twitter dengan nomor telepon. Ini diperlukan untuk membuat aplikasi, langkah inilah yang memberikan akses ke API.
Kami pergi ke halaman pengembang dan klik tombol Buat aplikasi . Berikutnya adalah halaman di mana Anda perlu mengisi informasi tentang aplikasi. Saat ini halaman terdiri dari bidang-bidang berikut.
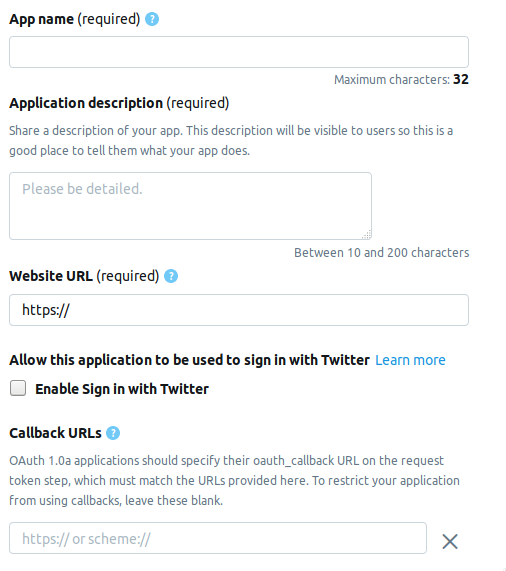
- AppName - nama aplikasi (wajib).
- Deskripsi aplikasi - deskripsi aplikasi (wajib).
- URL situs web - halaman situs web aplikasi (wajib), Anda dapat memasukkan apa pun yang tampak seperti URL.
- Aktifkan Masuk dengan Twitter (kotak centang) - Masuk dari halaman aplikasi di Twitter dapat dihilangkan.
- URL Panggilan Balik - Panggilan balik aplikasi selama otentikasi (wajib) dan perlu , Anda dapat meninggalkan
http://127.0.0.1:1410 .
Berikut ini adalah bidang opsional: alamat halaman untuk persyaratan layanan, nama organisasi, dll.
Saat membuat akun pengembang, pilih satu dari tiga opsi yang memungkinkan.
- Standar - Versi dasar, Anda dapat mencari catatan hingga kedalaman ≤ 7 hari, gratis.
- Premium - Opsi yang lebih canggih, Anda dapat mencari catatan hingga kedalaman ≤ 30 hari dan sejak 2006. Gratis, tetapi mereka tidak langsung memberikannya saat mempertimbangkan aplikasi.
- Perusahaan - Kelas bisnis, tarif berbayar, dan andal.
Saya memilih Premium , butuh sekitar satu minggu untuk menunggu persetujuan. Saya tidak dapat memberi tahu semua orang apakah mereka memberikannya kepada saya secara berurutan, tetapi tetap patut dicoba, dan Standar tidak akan pergi ke mana pun.
Koneksi Twitter
Setelah Anda membuat aplikasi, satu set yang berisi elemen-elemen berikut akan muncul di tab Tombol dan token . Di bawah ini adalah nama dan variabel yang sesuai dari R.
Kunci API konsumen
- Kunci API -
api_key - Kunci rahasia API -
api_secret
Token akses & rahasia token akses
- Token akses -
access_token - Rahasia token akses -
access_token_secret
Instal paket yang diperlukan.
install.packages("rtweet") install.packages("tm") install.packages("wordcloud")
Potongan kode ini akan terlihat seperti ini.
library("rtweet") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret)
Setelah otentikasi, R akan meminta Anda untuk menyimpan kode OAuth pada disk untuk digunakan nanti.
[1] "Using direct authentication" Use a local file to cache OAuth access credentials between R sessions? 1: Yes 2: No
Kedua opsi dapat diterima, saya memilih tanggal 1.
Cari dan saring hasil
tweets <- search_tweets("hadoop", include_rts=FALSE, n=600)
Tombol include_rts memungkinkan Anda untuk mengontrol apakah retweet dimasukkan atau dikecualikan dari pencarian. Pada output, kami mendapatkan tabel dengan banyak bidang di mana ada detail dan detail dari setiap catatan. Inilah 20 yang pertama.
> head(names(tweets), n=20) [1] "user_id" "status_id" "created_at" [4] "screen_name" "text" "source" [7] "display_text_width" "reply_to_status_id" "reply_to_user_id" [10] "reply_to_screen_name" "is_quote" "is_retweet" [13] "favorite_count" "retweet_count" "hashtags" [16] "symbols" "urls_url" "urls_t.co" [19] "urls_expanded_url" "media_url"
Anda dapat membuat string pencarian yang lebih kompleks.
search_string <- paste0(c("data mining","#bigdata"),collapse = "+") search_tweets(search_string, include_rts=FALSE, n=100)
Hasil pencarian dapat disimpan dalam file teks.
write.table(tweets$text, file="datamine.txt")
Kami menggabungkan ke dalam teks, kami memfilter dari kata-kata layanan, tanda baca dan menerjemahkan semuanya menjadi huruf kecil.
Ada fungsi pencarian lain - searchTwitter , yang membutuhkan pustaka twitteR . Dalam beberapa hal, ini lebih nyaman daripada search_tweets , tetapi dalam beberapa hal lebih rendah daripada itu.
Plus - keberadaan filter berdasarkan waktu.
tweets <- searchTwitter("hadoop", since="2017-09-01", n=500) text = sapply(tweets, function(x) x$getText())
Minus - outputnya bukan tabel, tetapi objek yang bertipe status . Untuk menggunakannya dalam contoh kita, kita perlu mengekstrak bidang teks dari output. Ini membuat sapply di baris kedua.
corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "hadoop", stopwords("english")), removeNumbers = TRUE, tolower = TRUE))
Pada baris kedua, fungsi tm_map diperlukan untuk mengubah semua jenis karakter emoji menjadi huruf kecil, jika tidak konversi ke huruf kecil menggunakan tolower akan gagal.
Membangun kata cloud
Cloud Word pertama kali muncul di hosting foto Flickr , sejauh yang saya tahu, dan sejak itu semakin populer. Untuk tugas ini, kita membutuhkan pustaka wordcloud .
m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Fungsi search_string memungkinkan Anda untuk mengatur bahasa sebagai parameter.
search_tweets(search_string, include_rts=FALSE, n=100, lang="ru")
Namun, karena fakta bahwa paket NLP untuk R adalah Russified buruk, khususnya, tidak ada daftar layanan atau kata-kata penghentian, saya tidak berhasil membangun kata cloud dengan pencarian dalam bahasa Rusia. Saya akan senang jika Anda menemukan solusi yang lebih baik di komentar.
Sebenarnya ...
seluruh naskah library("rtweet") library("tm") library("wordcloud") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret) oauth_callback <- "http://127.0.0.1:1410" setup_twitter_oauth (api_key, api_secret, access_token, access_token_secret) appname="my_app" twitter_token <- create_token(app = appname, consumer_key = api_key, consumer_secret = api_secret) tweets <- search_tweets("devops", include_rts=FALSE, n=600) corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "drupal", stopwords("english")), removeNumbers = TRUE, tolower = TRUE)) m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Bahan bekas.
Tautan pendek:
Tautan asli:
https://stats.seandolinar.com/collecting-twitter-data-getting-started/
https://opensourceforu.com/2018/07/using-r-to-mine-and-analyse-popular-sentiments/
http://dkhramov.dp.ua/images/edu/Stu.WebMining/ch17_twitter.pdf
http://opensourceforu.com/2018/02/explore-twitter-data-using-r/
https://cran.r-project.org/web/packages/tm/vignettes/tm.pdf
PS Petunjuk, kata kunci cloud pada KDPV tidak digunakan dalam program, ini terkait dengan artikel saya sebelumnya .