Memeriksa satu server tidak menjadi masalah. Anda mengambil daftar periksa dan memeriksa urutan: prosesor, memori, disk. Tetapi dengan seratus server, metode ini tidak mungkin bekerja dengan baik. Untuk mengecualikan faktor manusia, untuk membuat pemeriksaan lebih andal dan lebih cepat, perlu untuk mengotomatisasi proses. Siapa yang perlu tahu bagaimana melakukan ini lebih baik daripada penyedia hosting? Artyom Artemyev di HighLoad ++ Siberia memberi tahu metode apa yang dapat digunakan, apa yang lebih baik untuk dijalankan dengan tangan Anda, dan apa yang bekerja dengan baik untuk mengotomatisasi. Selanjutnya, versi teks dari laporan dengan tips yang dapat diulang oleh siapa pun yang bekerja dengan besi dan perlu memeriksa kinerjanya.
 Tentang pembicara:
Tentang pembicara: Artyom Artemyev (
artemirk ) direktur teknis di penyedia hosting besar FirstVDS, ia bekerja dengan besi.
FirstVDS memiliki dua pusat data. Yang pertama adalah milik mereka sendiri, mereka membangun gedung mereka sendiri, membawa dan memasang rak mereka, mereka sendiri memelihara, khawatir tentang arus dan pendinginan pusat data. Pusat data kedua adalah ruang besar di pusat data besar yang disewakan, semuanya lebih mudah dengan itu, tetapi juga ada. Totalnya adalah 60 rak dan sekitar 3.000 server besi. Ada sesuatu untuk dilatih dan diuji pendekatan yang berbeda, yang berarti bahwa kami sedang menunggu rekomendasi yang dikonfirmasi secara praktis. Mari mulai melihat atau membaca laporan.
Sekitar 6-7 tahun yang lalu, kami menyadari bahwa hanya menempatkan sistem operasi di server tidak cukup. OS menyala, server terjaga dan siap untuk bertempur. Kami meluncurkannya pada produksi - reboot dan pembekuan yang tidak dapat dipahami dimulai. Apa yang harus dilakukan, tidak jelas - proses sedang berlangsung, mentransfer seluruh draft kerja ke sepotong logam baru itu sulit, mahal, menyakitkan. Kemana harus lari?
Metode penyebaran modern memungkinkan kami untuk menghindari ini dan mengangkut server dalam 5 detik, tetapi klien kami (terutama 6 tahun yang lalu) tidak terbang di awan, berjalan di tanah dan menggunakan potongan besi biasa.

Pada artikel ini saya akan memberi tahu Anda metode apa yang kami coba, mana yang kami ambil root, yang tidak berakar, mana yang baik untuk dijalankan dengan tangan Anda, dan bagaimana mengotomatiskan semua ini. Saya akan memberi Anda saran, dan Anda dapat mengulanginya di perusahaan Anda jika Anda bekerja dengan besi dan Anda memiliki kebutuhan seperti itu.
Apa masalahnya?
Secara teori, memeriksa server tidak menjadi masalah. Awalnya, kami memiliki proses, seperti pada gambar di bawah ini. Seorang pria duduk, mengambil daftar periksa, memeriksa: prosesor, memori, disk, kerutan dahinya, membuat keputusan.
Kemudian 3 server diinstal per bulan. Tetapi, ketika ada semakin banyak server, orang ini mulai menangis dan mengeluh bahwa dia sekarat di tempat kerja. Seseorang semakin keliru, karena verifikasi telah menjadi rutinitas.
Kami membuat keputusan: kami mengotomatisasi! Seseorang akan melakukan hal-hal yang lebih bermanfaat.
Tamasya singkat
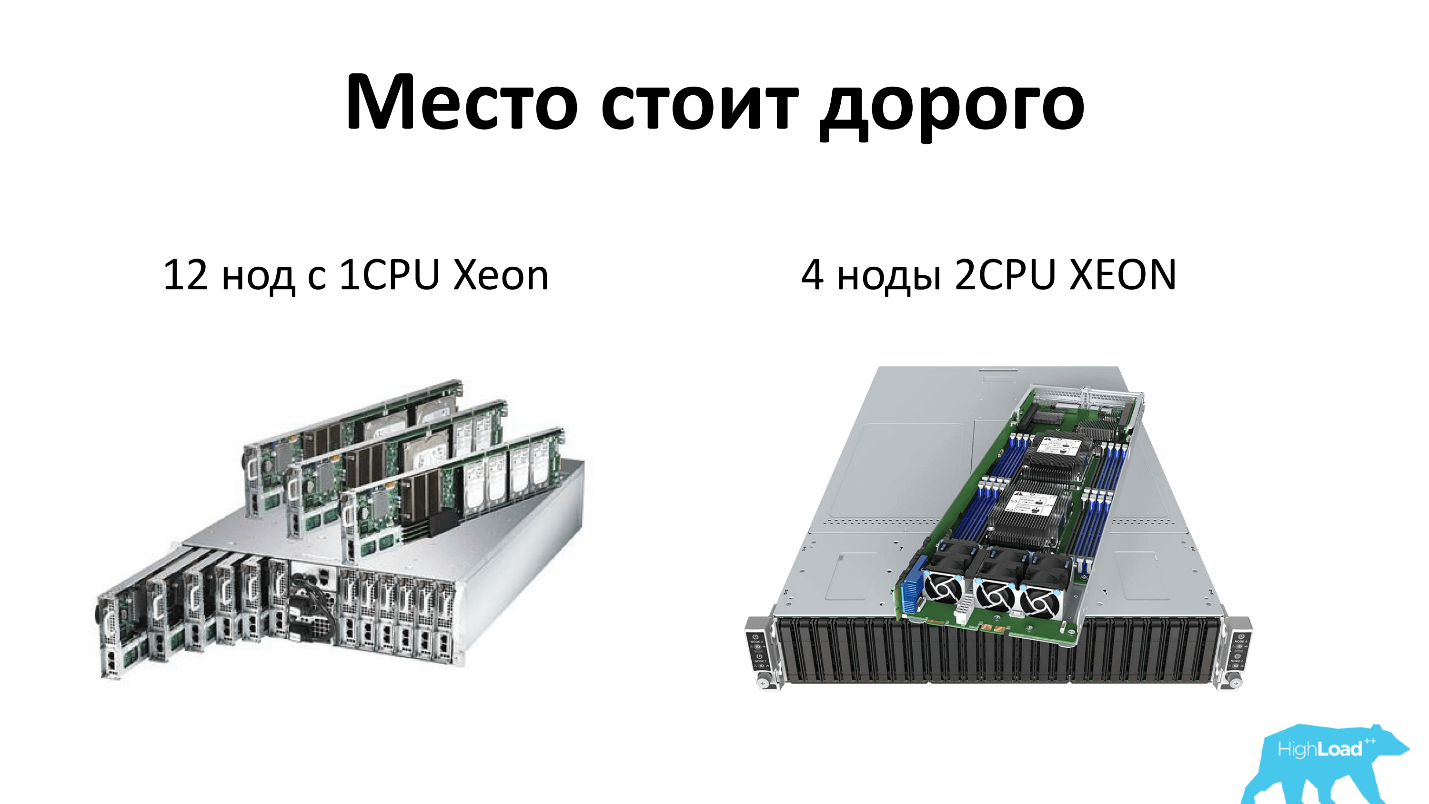
Saya akan mengklarifikasi apa yang saya maksud ketika saya berbicara tentang server hari ini. Kami, seperti orang lain, menghemat ruang rak dan menggunakan server kepadatan tinggi. Saat ini 2 unit, yang dapat memuat 12 node server prosesor tunggal, atau 4 node server prosesor ganda. Artinya, setiap server mendapat 4 disk - semuanya dengan jujur. Plus, ada dua catu daya di rak, yaitu semuanya redundan dan semua orang menyukainya.
Dari mana besinya?
Besi dibawa ke pusat data kami oleh pemasok kami - biasanya Supermicro dan Intel. Di pusat data, operator-operator kami memasang server di ruang kosong di rak dan menghubungkan dua kabel, jaringan dan daya. Ini juga merupakan tanggung jawab operator untuk mengkonfigurasi BIOS di server. Yaitu, sambungkan keyboard, monitor, dan konfigurasikan dua parameter:
Restore on AC/Power Loss — [Power On] , sehingga server selalu menyala segera setelah daya muncul. Ini harus bekerja tanpa henti. Perangkat
First boot device — [PXE] kedua
First boot device — [PXE] , yaitu, kami meletakkan perangkat boot pertama di jaringan, jika tidak, kami tidak akan dapat mencapai server, karena itu bukan fakta bahwa ia memiliki disk segera, dll.

Setelah itu, operator membuka panel akuntansi server besi, di mana Anda perlu mencatat fakta menginstal server, yang ditunjukkan:
- rak;
- stiker
- port jaringan
- port daya
- nomor unit.
Setelah itu, port jaringan tempat operator menginstal server baru, untuk tujuan keamanan, pergi ke karantina VLAN khusus, yang juga hang DHCP, Pxe, TFtp. Selanjutnya, server memuat Linux favorit kami, yang memiliki semua utilitas yang diperlukan, dan proses diagnostik dimulai.
Karena server masih memiliki perangkat boot pertama di jaringan, untuk server yang masuk ke produksi, port beralih ke VLAN lain. Tidak ada DHCP di VLAN lain, dan kami tidak takut bahwa kami akan menginstal ulang server produksi kami secara tidak sengaja. Untuk ini, kami memiliki VLAN terpisah.
Itu terjadi bahwa server diinstal, semuanya baik-baik saja, tetapi tidak bisa boot ke sistem diagnostik. Ini terjadi, sebagai suatu peraturan, karena fakta bahwa dengan penundaan dalam beralih VLAN, tidak semua switch jaringan dengan cepat beralih VLAN, dll.

Kemudian operator menerima tugas me-restart server dengan tangannya. Sebelumnya, tidak ada IPMI, kami memasang soket jarak jauh dan memperbaiki port soket server, menarik soket melalui jaringan, dan server reboot.
Tetapi outlet yang dikelola juga tidak selalu berfungsi dengan baik, jadi kami sekarang mengelola daya server dari IPMI. Tetapi ketika server baru, IPMI tidak dikonfigurasi, itu hanya dapat di-boot dengan naik dan menekan tombol. Karena itu, seorang pria duduk, menunggu - lampu menyala - berjalan dan menekan tombol. Begitulah pekerjaannya.
Jika setelah itu server tidak bisa boot, maka dimasukkan dalam daftar khusus untuk diperbaiki. Daftar ini termasuk server di mana diagnostik tidak memulai, atau hasilnya tidak memuaskan. Seorang individu - yang mencintai besi - duduk dan membongkar setiap hari - mengumpulkan, mencari, mengapa tidak bekerja.
CPU
Semuanya baik-baik saja, server sudah mulai, kami mulai menguji. Pertama, kami menguji prosesor sebagai salah satu elemen paling penting.

Impuls pertama adalah menggunakan aplikasi dari vendor. Kami memiliki hampir semua prosesor Intel - kami pergi ke situs tersebut, mengunduh Intel Processor Diagnostic Tool - semuanya baik-baik saja, ini menunjukkan banyak informasi menarik, termasuk jam operasi server dalam jam dan grafik konsumsi daya.
Tetapi masalahnya adalah bahwa Intel PTD bekerja di bawah Windows, yang tidak kita sukai lagi. Untuk memulai tes di dalamnya, Anda hanya perlu menggerakkan mouse, tekan tombol "MULAI", dan tes akan dimulai. Hasilnya ditampilkan di layar, tetapi tidak ada cara untuk mengekspornya di mana saja. Ini tidak cocok untuk kita, karena prosesnya tidak otomatis.

Kami pergi membaca forum dan menemukan dua cara termudah.
- Lingkaran abadi kucing / dev / nol> / dev / null . Anda dapat memeriksa di atas - 100% satu inti dikonsumsi. Kami menghitung jumlah inti, menjalankan jumlah kucing / dev / nol yang diperlukan, dikalikan dengan jumlah inti yang diinginkan. Semuanya bekerja dengan baik!
- Utilitas / bin / stres . Dia membangun matriks dalam memori dan mulai secara konstan membalikkannya. Semuanya baik-baik saja - prosesor sedang melakukan pemanasan, ada beban.
Kami memberikan server dalam produksi, pengguna kembali dan mengatakan bahwa prosesor tidak stabil. Dicentang - prosesor tidak stabil. Mereka mulai menyelidiki, mereka mengambil server, yang lolos pemeriksaan, tetapi crash dalam pertempuran, menyalakan kernel debug di Linux, dan mengumpulkan Core dump. Server sebelum mem-boot flush ke file semua yang ada di memori sebelum crash.

Berbagai optimasi dibangun ke prosesor untuk operasi yang sering. Kita dapat melihat bendera yang mencerminkan optimasi yang didukung prosesor, misalnya, optimasi untuk bekerja dengan angka floating point, optimasi multimedia, dll. Tapi kami / bin / stress, dan siklus abadi hanya membakar prosesor dalam satu operasi dan tidak menggunakan fitur tambahan. Investigasi menunjukkan bahwa CPU macet ketika mencoba menggunakan fungsi dari salah satu flag bawaan.
Impuls pertama adalah meninggalkan / bin / stres - biarkan prosesor hangat. Kemudian dalam satu siklus kita menjalankan semua bendera, tarik mereka. Sambil berpikir tentang bagaimana mengimplementasikan ini, yang memerintahkan untuk memanggil untuk memanggil fungsi dari masing-masing flag, kita membaca forum.
Pada forum overclocker, kami menemukan sebuah proyek yang menarik untuk mencari bilangan prima
Great Internet Mersenne Prime Search . Para ilmuwan telah membuat jaringan terdistribusi yang dapat dihubungkan oleh siapa saja dan membantu menemukan bilangan prima. Para ilmuwan tidak mempercayai siapa pun, sehingga program ini bekerja dengan sangat cerdik: pertama Anda menjalankannya, ia menghitung bilangan prima yang sudah diketahui, dan membandingkan hasilnya dengan apa yang diketahui. Jika hasilnya tidak cocok, berarti prosesor tidak berfungsi. Kami benar-benar menyukai properti ini: dengan segala omong kosong itu cenderung jatuh.
Selain itu, tujuan dari proyek ini adalah untuk menemukan bilangan prima sebanyak mungkin, oleh karena itu program ini terus dioptimalkan untuk sifat-sifat prosesor baru, sebagai akibatnya menarik banyak bendera.
Mprime tidak memiliki batas waktu, jika tidak dihentikan, ia bekerja selamanya. Kami menjalankannya selama 30 menit.
/usr/bin/timeout 30m /opt/mprime -t /bin/grep -i error /root/result.txt
Setelah menyelesaikan pekerjaan, kami memeriksa bahwa tidak ada kesalahan dalam result.txt, dan melihat log kernel, khususnya, dalam file / proc / kmsg kami mencari kesalahan.
Tamasya lain

Pada 3 Januari 2018, mereka menemukan bilangan prima Mersenne ke-50 (2
p -1). Dari jumlah ini, hanya 23 juta digit. Anda dapat mengunduhnya untuk melihatnya -
ini adalah
arsip zip 12 Mb .
Mengapa kita membutuhkan bilangan prima? Pertama, setiap enkripsi RSA menggunakan nomor prima. Semakin banyak bilangan prima yang kita tahu, semakin dapat diandalkan kunci SSH Anda. Kedua, para ilmuwan menguji hipotesis dan teorema matematika mereka, dan kami tidak keberatan membantu para ilmuwan - tidak ada biaya bagi kami. Ternyata win-win history.

Jadi, prosesornya bekerja, semuanya baik-baik saja. Masih mencari tahu jenis prosesornya. Kami menggunakan prosesor dmidecode -t dan melihat semua slot yang ada di motherboard, dan prosesor mana yang ada di slot ini. Informasi ini memasuki sistem akuntansi kami, kami akan menafsirkannya nanti.
Tangkap
Dengan demikian, secara mengejutkan, kaki yang patah dapat ditemukan. / bin / stres dan siklus abadi bekerja, dan Mprime jatuh. Mereka mengemudi untuk waktu yang lama, mencari, menemukan - hasil dalam gambar di bawah ini - semuanya jelas di sini.

Prosesor seperti itu tidak dimulai. Operator sangat kuat, mengambil prosesor yang salah - tetapi bisa memberikan.

Kasus indah lainnya. Baris hitam pada foto di bawah adalah kipas, panah menunjukkan bagaimana udara berhembus. Kita lihat: radiator berdiri di seberang sungai. Tentu saja, semuanya kepanasan dan mati.

Memori
Dengan memori, semuanya sangat sederhana. Ini adalah sel tempat kita menulis informasi, dan setelah beberapa saat kita membacanya lagi. Jika tetap sama dengan yang kami tulis, maka sel ini berfungsi.

Semua orang tahu program
Memtest86 + yang baik, langsung klasik, yang berjalan dari media apa pun, melalui jaringan, atau bahkan dari floppy disk. Itu dibuat untuk memeriksa sel-sel memori sebanyak mungkin. Setiap sel yang ditempati tidak lagi dapat diperiksa. Karena itu memtest86 + memiliki ukuran minimum agar tidak menempati memori. Sayangnya,
memtest86 + hanya menampilkan statistiknya di layar . Kami mencoba mengembangkannya entah bagaimana, tetapi semuanya berujung pada kenyataan bahwa di dalam program itu bahkan tidak ada tumpukan jaringan. Untuk mengembangkannya, seseorang harus membawa kernel Linux dan yang lainnya.
Ada versi berbayar dari program ini yang sudah tahu cara mengirim informasi ke disk. Tetapi server kami tidak selalu memiliki disk, dan tidak selalu ada sistem file pada disk ini. Tetapi drive jaringan, seperti yang telah kita ketahui, tidak dapat dihubungkan.
Kami mulai menggali lebih jauh dan menemukan program
Memtester serupa. Program ini bekerja dari level OS dari Linux. Minus terbesar adalah bahwa OS itu sendiri dan Memtester menempati beberapa sel memori, dan sel-sel ini tidak akan diperiksa.
Memtester dimulai dengan perintah: memtester `cat / proc / meminfo | grep MemFree | awk '{print $ 2-1024}' 'k 5
Di sini kami mentransfer jumlah memori bebas minus 1 MB. Ini dilakukan, karena jika tidak Memtester mengambil semua memori dan pembunuh bawah membunuhnya. Kami mengendarai tes ini selama 5 siklus, pada output kami memiliki plat dengan OK atau gagal.
| Terjebak alamat | oke |
| Nilai acak | oke |
| Bandingkan XOR | oke |
| Bandingkan SUB | oke |
| Bandingkan MUL | oke |
| Bandingkan DIV | oke |
| Bandingkan ATAU | oke |
| Bandingkan DAN | oke |
Kami menyimpan hasil akhir dan menganalisis lebih lanjut untuk kegagalan.

Untuk memahami tingkat masalahnya - server terkecil kami memiliki memori 32 GB, citra Linux kami dengan Memtester membutuhkan 60 MB,
kami tidak memeriksa 2% dari memori . Tetapi menurut statistik selama 6 tahun terakhir, tidak ada hal seperti itu yang dipukuli memori terus-menerus masuk ke produksi. Ini adalah kompromi yang kita setujui, dan yang mahal untuk kita perbaiki, dan kita hidup dengannya.
Sepanjang jalan, kami juga mengumpulkan dmidecode -t memory, yang memberikan semua bank memori yang kami miliki di motherboard (biasanya hingga 24 buah), dan yang mati ada di setiap bank. Informasi ini berguna jika kita ingin meningkatkan server - kita akan tahu ke mana harus menambahkan apa, berapa banyak strip yang harus diambil dan server mana yang harus dituju.
Perangkat penyimpanan
6 tahun yang lalu, semua disc dengan pancake yang berputar. Sebuah cerita terpisah adalah menyusun daftar semua disk. Ada beberapa pendekatan yang berbeda, karena tidak percaya bahwa Anda bisa melihat ls / dev / sd. Tetapi pada akhirnya, kami berhenti melihat ls / dev / sd * dan ls / dev / cciss / c0d *. Dalam kasus pertama, ini adalah perangkat SATA, dalam perangkat kedua - SCSI dan SAS.

Secara harfiah tahun ini, mereka mulai menjual disk nvme dan menambahkan daftar nvme di sini.
Setelah daftar disk dikompilasi, kami mencoba membaca 0 byte darinya untuk memahami bahwa ini adalah perangkat blok dan semuanya baik-baik saja. Jika Anda tidak bisa membacanya, maka kami percaya bahwa ini semacam hantu, dan kami tidak pernah dan tidak pernah memiliki disk seperti itu.
Pendekatan pertama untuk memeriksa disk adalah jelas: "Mari kita menulis data acak ke disk dan melihat kecepatannya" -
dd -o nocache -o direct if=/dev/urandom of=${disk} . Sebagai aturan, pancake disk memberikan 130-150 Mb / s. Kami memicingkan mata dan memutuskan untuk diri kami sendiri bahwa 90 MB / s adalah angka yang setelah itu ada disk yang dapat diservis, semua yang lebih kecil mengalami malfungsi.
Tetapi sekali lagi, pengguna mulai kembali dan mengatakan bahwa drive buruk. Ternyata fisika berbahaya bercanda lagi dengan kami.
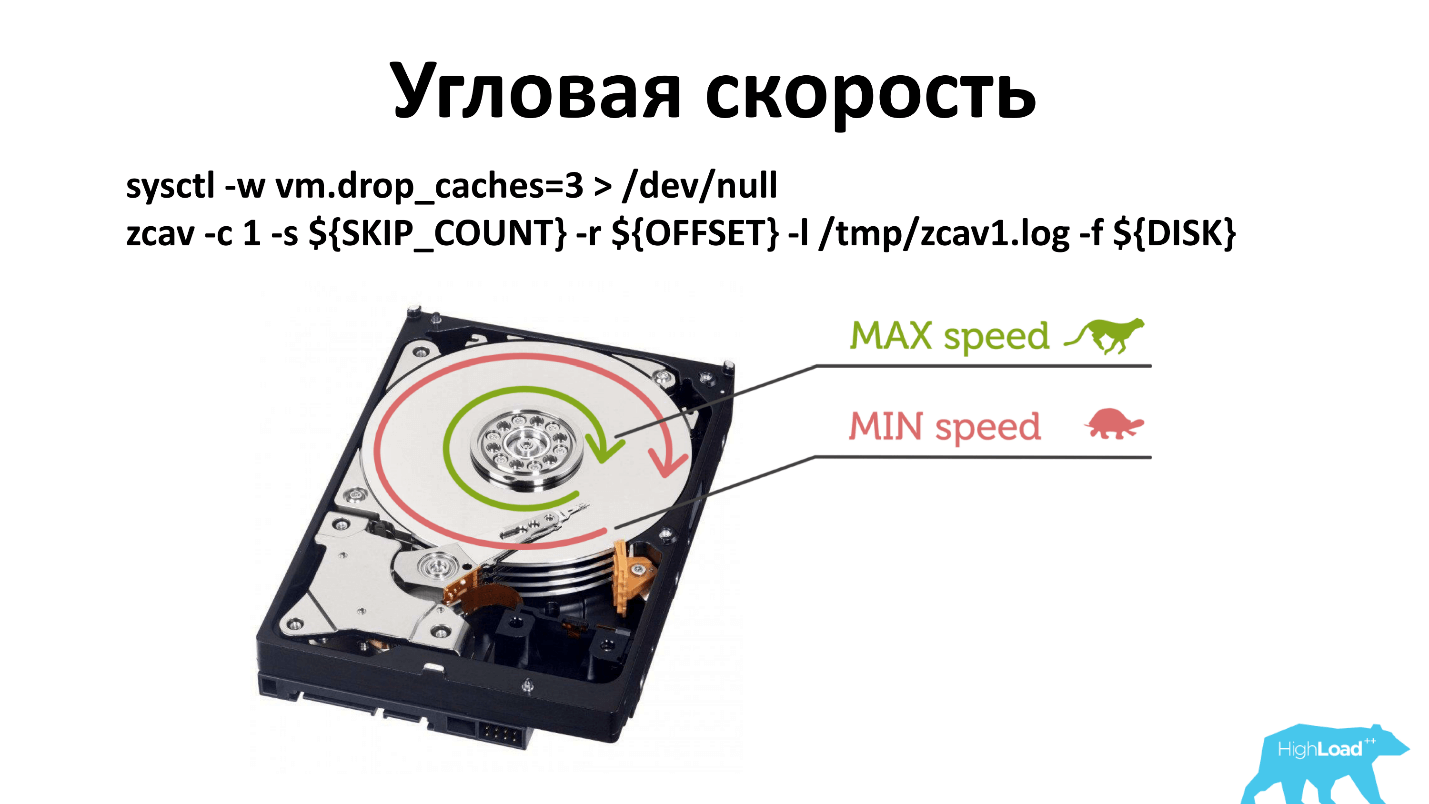
Ada kecepatan sudut, dan, sebagai aturannya, ketika Anda menjalankan -dd, ia menulis di dekat spindle. Jika karena alasan tertentu kecepatan spindel telah menurun, maka ini kurang terlihat dibandingkan jika Anda menulis dari tepi disk.
Saya harus mengubah prinsip verifikasi. Sekarang kita periksa di tiga tempat: dekat gelendong, di tengah dan di luar. Mungkin, itu dapat diperiksa hanya dari luar, tetapi ini adalah bagaimana itu terjadi secara historis. Dan apa yang berhasil, jangan disentuh.
Anda dapat menggunakan
smartctl untuk bertanya pada disk bagaimana kabarnya. Kami percaya bahwa dorongan yang baik:
- Tidak ada Sektor Reallocated (Sektor Reallocated Count = 0) , yaitu, semua sektor yang telah meninggalkan pekerjaan pabrik.
- Kami tidak menggunakan cakram yang lebih dari 4 tahun , meskipun cakram itu cukup berfungsi. Sebelum kami memperkenalkan praktik ini, kami memiliki disk selama 7 tahun. Sekarang kami percaya bahwa setelah 4 tahun disk telah terbayar, dan kami tidak siap untuk menerima risiko keausan.
- Tidak ada sektor yang akan dialokasikan kembali ( Current_Pending_Sector = 0 ).
- UltraDMA CRC Error Count = 0 - ini adalah kesalahan pada kabel SATA. Jika ada kesalahan, Anda hanya perlu mengganti kabel, Anda tidak perlu mengganti disk.

SSD yang didistribusikan umumnya adalah drive yang sangat baik, mereka bekerja dengan cepat, tidak membuat suara, tidak memanas. Kami percaya bahwa SSD yang baik memiliki kecepatan tulis lebih dari 200 MB / s. Pelanggan kami menyukai harga murah, dan model server yang mengeluarkan 320-350 MB / s tidak selalu sampai kepada kami.
Untuk SSD, kami juga melihat smartctl. Realokasi yang sama, Power_On_Hours, Current_Pending_Sector. Semua SSD dapat menampilkan tingkat keausan, ini menunjukkan parameter Media_Wearout_Indicator. Kami menghapus cakram hingga 5% dari kehidupan, dan hanya kemudian mengeluarkannya. Disk semacam itu terkadang menemukan kehidupan kedua dalam kebutuhan pribadi karyawan. Sebagai contoh, saya baru-baru ini menemukan bahwa dalam 2 tahun disk seperti itu telah usang oleh 1% lain di laptop karyawan, meskipun di negara kita itu di bawah cache SSD habis 95% dalam waktu sekitar 10 bulan.
Tetapi masalahnya adalah bahwa tidak semua produsen disk menyetujui nama parameter, dan Media_Wearout_Indicator ini, misalnya, disebut Percent_Lifetime_Digunakan untuk Toshiba, Hitungan Leveling Wear lainnya, Persen Seumur Hidup yang Tersisa untuk produsen lain, atau hanya. * Pakai. *.
Sangat penting tidak memiliki opsi ini sama sekali. Kemudian kita hanya mempertimbangkan jumlah penulisan ulang disk - "byte ditulis" - berapa banyak byte yang telah kita tulis ke disk ini. Selanjutnya, sesuai dengan spesifikasi, kami mencoba mencari tahu berapa banyak penulisan ulang disk ini yang dihitung oleh pabrikan. Dengan matematika dasar kita menentukan berapa banyak lagi dia akan hidup. Jika sudah waktunya untuk berubah - ubah.
RAID
Saya tidak tahu mengapa di dunia modern pelanggan kami masih menginginkan RAID. Orang-orang membeli RAID, meletakkan 4 SSD di sana, yang jauh lebih cepat daripada RAID ini (6 Gb). Mereka memiliki semacam instruksi, dan mereka mengumpulkannya. Saya pikir ini adalah hal yang hampir tidak perlu.
Dulu ada 3 produsen: Adaptec; 3ware; Intel Kami memiliki 3 utilitas, kami terganggu, tetapi kami menjalankan diagnostik untuk semua orang. Sekarang LSI membeli semua orang - hanya ada satu utilitas yang tersisa.
Ketika sistem diagnostik kami melihat RAID, ia mem-parsing volume logis ke disk terpisah sehingga Anda dapat mengukur kecepatan setiap disk dan membaca Smart-nya. Setelah itu, RAID tetap memeriksa baterai. Siapa yang tidak tahu - ada cukup baterai di RAID untuk memutar semua disk selama 2 jam. Artinya, Anda mematikan server, mengeluarkannya, dan memutar disk selama 2 jam untuk menyelesaikan semua rekaman.
Jaringan
Dengan jaringan, semuanya cukup sederhana - harus ada kurang dari 300 Mbit di dalam pusat data. Jika kurang, Anda harus memperbaikinya. Kami juga melihat kesalahan pada antarmuka.
Kesalahan pada antarmuka jaringan tidak boleh sama sekali , dan jika ada, maka semuanya buruk.
Kami mencoba memperbarui BIOS dan firmware IPMI di sepanjang jalan. Ternyata kami tidak suka semua BIOS. Kami masih memiliki BIOS yang tidak tahu cara UEFI dan fitur lain yang kami gunakan. Kami mencoba memperbaruinya secara otomatis, tetapi ini tidak selalu berhasil, semuanya tidak terlalu sederhana di sana. Jika itu tidak berhasil, maka orang tersebut pergi dan memperbarui dengan tangannya.
Kami tidak memberikan IPMI Supermicro kepada dunia, kami memilikinya di alamat abu-abu melalui OpenVPN. Namun demikian, kami takut bahwa suatu hari kerentanan lain akan keluar dan kami akan menderita. Oleh karena itu, kami mencoba menjaga agar firmware IPMI selalu menjadi yang terakhir. Jika tidak, perbarui.
Dari hal yang aneh, baru-baru ini keluar bahwa Intel pada kartu jaringan 10 dan 40-gigabit tidak termasuk boot PXE. Ternyata jika server berada di rak di mana hanya ada kartu 40-gigabit, maka tidak mungkin untuk melakukan booting melalui jaringan, karena Anda perlu boot ke kartu gigabit. Kami secara terpisah mem-flash kartu jaringan pada 40G sehingga mereka memiliki PXE dan dapat terus hidup.
Setelah semuanya diperiksa, server segera mulai dijual . Harganya dihitung, di mana ia diletakkan di situs dan dijual.

Secara total, kami melakukan sekitar 350 cek per bulan, 69% server dapat diservis, 31% tidak dapat diservis. Ini karena fakta bahwa kami memiliki sejarah yang kaya, beberapa server telah berdiri selama 10 tahun. Sebagian besar server yang tidak lulus tes, kami hanya membuang.
Untuk yang penasaran: kami memiliki 3 klien yang masih hidup di Pentium IV dan tidak ingin pergi ke mana pun. Mereka memiliki RAM 512 MB.
Masa depan telah tiba! Jika saya memagari sistem ini hari ini ...

Utilitas yang luar biasa,
Hardware Lister (lshw), dirilis, yang dapat berkomunikasi dengan kernel, dengan indah menampilkan jenis perangkat keras apa yang ada di dalam kernel, apa yang dapat dideteksi oleh kernel. Tidak semua tarian ini dibutuhkan. Jika Anda ulangi - Saya sangat menyarankan Anda untuk melihat utilitas ini dan menggunakannya. Semuanya akan menjadi lebih sederhana.
Ringkasan:
- Kompromi itu tidak buruk, itu hanya masalah harga. Jika solusinya sangat mahal, Anda perlu mencari tingkat di mana keandalan dan harga dapat diterima.
- Program non-inti terkadang keren untuk pengujian. Tetap hanya untuk menemukan mereka.
- Uji semua yang Anda raih!
HighLoad ++ berikutnya sudah pada 8 dan 9 November di Moskow. Program ini mencakup spesialis terkenal dan nama baru, tugas tradisional dan baru. Di bagian DevOps, misalnya, yang berikut sudah diterima:
Pelajari daftar laporan dan cepatlah bergabung. Atau berlangganan buletin kami dan Anda akan menerima ulasan berkala atas laporan, laporan tentang artikel dan video baru.