 Mesin Pembelajaran Lengkap Walk-Through dengan Python: Bagian Tiga
Mesin Pembelajaran Lengkap Walk-Through dengan Python: Bagian TigaBanyak orang tidak suka model pembelajaran mesin itu
kotak hitam : kami memasukkan data ke dalamnya dan mendapatkan jawaban tanpa penjelasan apa pun - seringkali jawaban yang sangat akurat. Pada artikel ini, kami akan mencoba memahami bagaimana model yang kami buat membuat prediksi dan apa yang bisa diceritakan tentang masalah yang kami pecahkan. Dan kami menyimpulkan dengan diskusi tentang bagian paling penting dari proyek pembelajaran mesin: kami mendokumentasikan apa yang telah kami lakukan dan menyajikan hasilnya.
Pada bagian
pertama, kami memeriksa pembersihan data, analisis eksplorasi, desain, dan pemilihan fitur. Pada bagian
kedua, kami mempelajari pengisian data yang hilang, implementasi dan perbandingan model pembelajaran mesin, penyetelan hyperparametric menggunakan pencarian acak dengan validasi silang, dan, akhirnya, evaluasi model yang dihasilkan.
Semua
kode proyek ada di GitHub. Dan Notebook Jupyter ketiga yang terkait dengan artikel ini ada di
sini . Anda dapat menggunakannya untuk proyek Anda!
Jadi, kami sedang mengerjakan solusi untuk masalah menggunakan pembelajaran mesin, atau lebih tepatnya, menggunakan regresi terawasi. Berdasarkan
data energi dari bangunan di New York, kami menciptakan model yang memprediksi Skor Bintang Energi. Kami telah memperoleh model "
regresi berbasis-peningkatan gradien ", yang mampu memprediksi dalam kisaran 9,1 poin (dalam kisaran dari 1 hingga 100) berdasarkan data uji.
Model interpretasi
Gradien meningkatkan regresi terletak kira-kira di tengah
skala interpretabilitas model : model itu sendiri kompleks, tetapi terdiri dari ratusan
pohon keputusan yang cukup sederhana. Ada tiga cara untuk memahami cara kerja model kami:
- Nilai pentingnya gejala .
- Visualisasikan salah satu pohon keputusan.
- Menerapkan metode LIME - Penjelasan Agnostik Model-Interpretable Lokal , penjelasan model-independen yang diartikan lokal.
Dua metode pertama adalah karakteristik ansambel pohon, dan yang ketiga, seperti yang dapat Anda pahami dari namanya, dapat diterapkan pada model pembelajaran mesin apa pun. LIME adalah pendekatan yang relatif baru, ini merupakan langkah maju yang signifikan dalam upaya
menjelaskan operasi pembelajaran mesin .
Pentingnya gejala
Pentingnya tanda memungkinkan Anda untuk melihat hubungan setiap tanda dengan tujuan perkiraan. Rincian teknis dari metode ini sangat kompleks (penurunan pengotor rata-rata atau
penurunan kesalahan karena dimasukkannya sifat diukur ), tetapi kita dapat menggunakan nilai relatif untuk memahami sifat mana yang lebih relevan. Di Scikit-Learn, Anda dapat
mengekstrak pentingnya atribut dari ansambel “siswa” berbasis pohon.
Dalam kode di bawah ini,
model adalah
model kami yang terlatih, dan menggunakan
model.feature_importances_ Anda dapat menentukan pentingnya atribut. Kemudian kami mengirimnya ke bingkai data Pandas dan menampilkan 10 atribut paling penting:
import pandas as pd
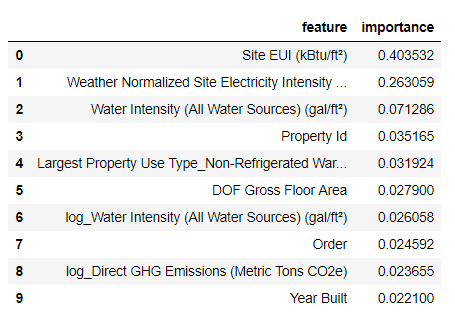
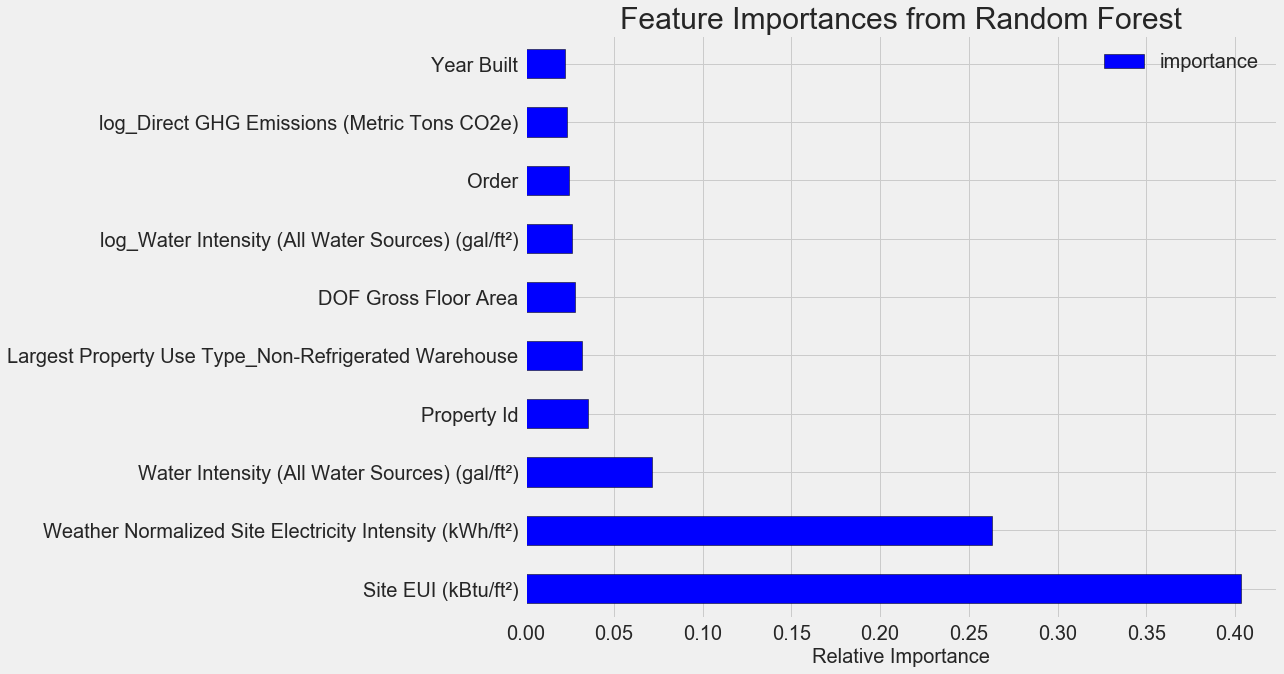
Fitur yang paling penting adalah
Site EUI (
Intensitas Konsumsi Energi ) dan
Weather Normalized Site Electricity Intensity , yang mencakup lebih dari 66% dari total kepentingan. Sudah pada atribut ketiga, kepentingannya sangat berkurang, ini
menunjukkan bahwa kita tidak perlu menggunakan semua 64 atribut untuk mencapai akurasi perkiraan yang tinggi (dalam
notebook Jupyter, teori ini diuji hanya dengan menggunakan 10 atribut paling penting, dan modelnya tidak terlalu akurat).
Berdasarkan hasil ini, salah satu pertanyaan awal akhirnya dapat dijawab: indikator paling penting dari Skor Bintang Energi adalah Situs EUI dan Intensitas Listrik Situs Normalisasi Cuaca. Kami tidak akan pergi
terlalu jauh ke dalam hutan tentang pentingnya atribut , kami hanya akan mengatakan bahwa dengan mereka Anda dapat mulai memahami mekanisme peramalan oleh model.
Visualisasi dari pohon keputusan tunggal
Sulit untuk memahami keseluruhan model regresi berdasarkan peningkatan gradien, yang tidak dapat dikatakan tentang pohon keputusan individu. Anda dapat memvisualisasikan pohon apa saja menggunakan fungsi
Scikit-Learn- export_graphviz . Pertama, ekstrak pohon dari ensemble, dan kemudian simpan sebagai file-dot:
from sklearn import tree
Menggunakan
visualizer Graphviz, konversikan file-dot menjadi png dengan mengetik:
dot -Tpng images/tree.dot -o images/tree.pngPunya pohon keputusan lengkap:

Sedikit merepotkan! Meskipun pohon ini hanya memiliki 6 lapisan, sulit untuk melacak semua transisi. Mari kita mengubah
export_graphviz fungsi
export_graphviz dan membatasi kedalaman pohon menjadi dua lapisan:
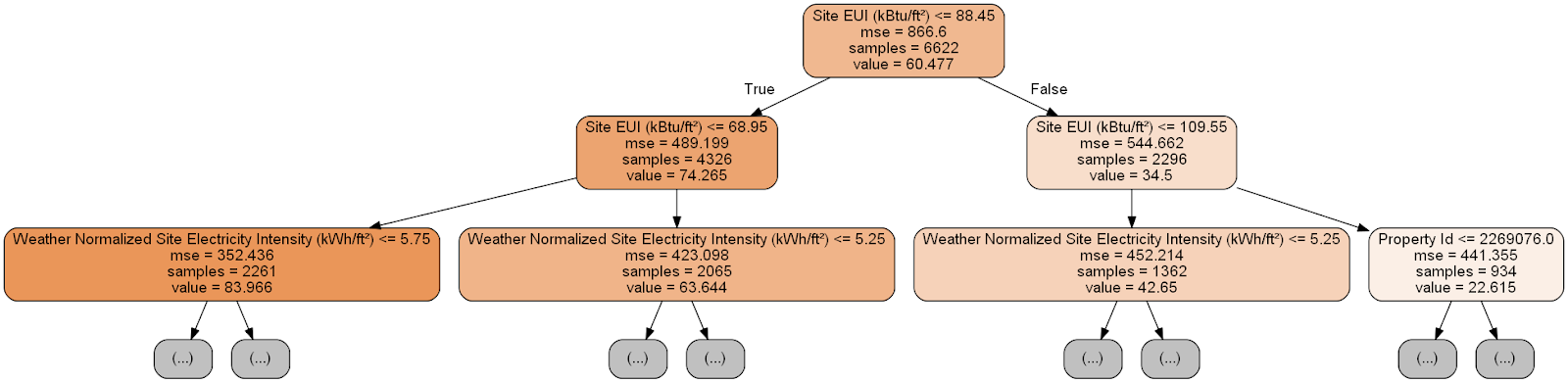
Setiap simpul (persegi panjang) dari pohon berisi empat baris:
- Pertanyaan yang diajukan tentang nilai salah satu tanda dimensi tertentu: itu tergantung pada arah mana kita akan keluar dari simpul ini.
Mse adalah ukuran kesalahan dalam suatu node.Samples - jumlah sampel data (pengukuran) dalam node.Value - penilaian sasaran untuk semua sampel data dalam simpul.
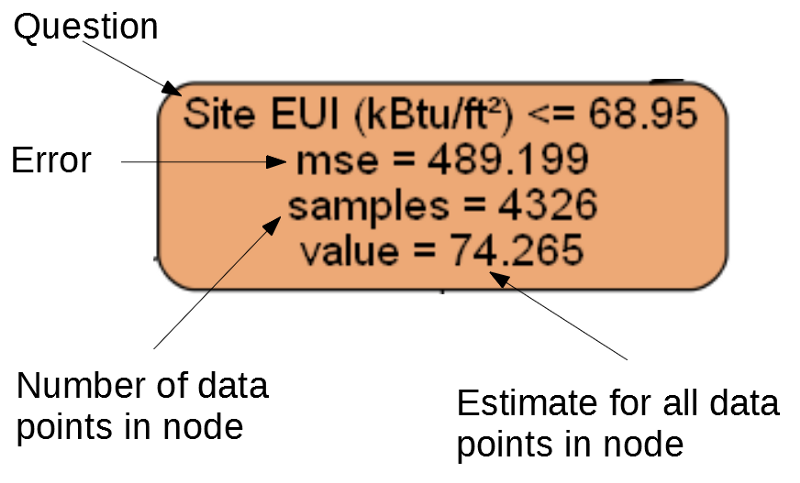 Pisahkan simpul.
Pisahkan simpul.(Daun hanya mengandung 2.4., Karena mereka mewakili skor akhir dan tidak memiliki simpul anak).
Peramalan untuk pengukuran yang diberikan dalam pohon keputusan dimulai dari simpul atas - root, dan kemudian turun turun pohon. Di setiap node, Anda perlu menjawab pertanyaan "ya" atau "tidak". Sebagai contoh, ilustrasi sebelumnya bertanya: "Apakah situs yang dibangun EUI kurang dari atau sama dengan 68,95?" Jika ya, algoritme tersebut menuju ke simpul anak kanan, jika tidak, kemudian ke kiri.
Prosedur ini diulangi pada setiap lapisan pohon sampai algoritme mencapai simpul daun pada lapisan terakhir (simpul-simpul ini tidak diperlihatkan dalam ilustrasi dengan pohon yang direduksi). Prakiraan untuk dimensi apa pun di lembar kerja adalah
value . Jika beberapa pengukuran sampai pada sheet, maka masing-masing dari mereka akan menerima perkiraan yang sama. Dengan meningkatnya kedalaman pohon, kesalahan pada data pelatihan akan berkurang, karena akan ada lebih banyak daun dan sampel akan dibagi lebih hati-hati. Namun, pohon yang terlalu dalam akan menyebabkan
pelatihan ulang pada data pelatihan dan tidak akan bisa menggeneralisasi data uji.
Pada
artikel kedua, kami mengatur jumlah model hyperparameters yang mengontrol setiap pohon, misalnya, kedalaman maksimum pohon dan jumlah minimum sampel yang diperlukan untuk setiap lembar. Kedua parameter ini sangat memengaruhi keseimbangan antara pembelajaran yang berlebihan dan yang kurang, serta visualisasi pohon keputusan akan memungkinkan kami untuk memahami cara kerja pengaturan ini.
Meskipun kita tidak dapat mempelajari semua pohon dalam model, analisis salah satunya akan membantu untuk memahami bagaimana masing-masing "siswa" memprediksi. Metode berbasis diagram alur ini sangat mirip dengan bagaimana seseorang membuat keputusan.
Ensemble pohon keputusan menggabungkan prakiraan berbagai pohon secara individu, yang memungkinkan Anda membuat model yang lebih akurat dengan variabilitas yang lebih sedikit. Ansambel seperti itu
sangat akurat dan mudah dijelaskan.
Penjelasan Ketergantungan Model Interpretable Lokal (LIME)
Alat terakhir yang dapat digunakan untuk mencari tahu bagaimana model kami “berpikir”. LIME memungkinkan Anda menjelaskan
bagaimana perkiraan tunggal dihasilkan untuk model pembelajaran mesin apa pun . Untuk melakukan ini, secara lokal, di sebelah beberapa pengukuran, model yang disederhanakan dibuat berdasarkan model sederhana seperti regresi linier (perincian dijelaskan dalam karya ini:
https://arxiv.org/pdf/1602.04938.pdf ).
Kami akan menggunakan metode LIME untuk mempelajari perkiraan yang keliru dari model kami dan memahami mengapa itu salah.
Pertama, kami menemukan ramalan yang salah ini. Untuk melakukan ini, kami akan melatih model, menghasilkan perkiraan, dan memilih nilai dengan kesalahan terbesar:
from sklearn.ensemble import GradientBoostingRegressor
Prediksi: 12.8615
Nilai Aktual: 100.0000Kemudian kami membuat explainer dan memberikannya data pelatihan, informasi mode, label untuk data pelatihan dan nama-nama atribut. Sekarang dimungkinkan untuk menyampaikan data pengamatan dan fungsi perkiraan ke penjelajah, dan kemudian meminta mereka untuk menjelaskan alasan kesalahan perkiraan.
import lime
Bagan Penjelasan Prakiraan:
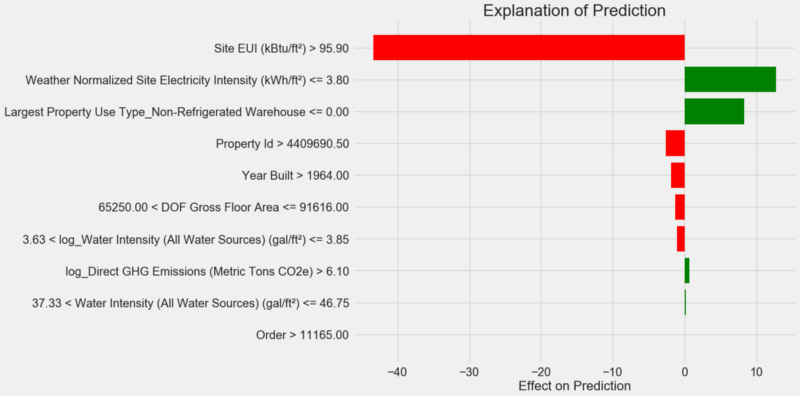
Cara menafsirkan diagram: setiap rekaman sepanjang sumbu Y menunjukkan satu nilai variabel, dan bilah merah dan hijau mencerminkan pengaruh nilai ini pada perkiraan. Misalnya, menurut catatan tertinggi, pengaruh
Site EUI lebih dari 95,90, sebagai hasilnya, sekitar 40 poin dikurangkan dari perkiraan. Menurut catatan kedua, pengaruh
Weather Normalized Site Electricity Intensity kurang dari 3,80, dan karenanya sekitar 10 poin ditambahkan ke perkiraan. Perkiraan akhir adalah jumlah intersep dan efek dari masing-masing nilai yang tercantum.
Mari kita melihatnya dengan cara lain dan memanggil metode
.show_in_notebook() :

Proses pengambilan keputusan oleh model ditunjukkan di sebelah kiri: efek pada perkiraan setiap variabel ditampilkan secara visual. Tabel di sebelah kanan menunjukkan nilai aktual dari variabel untuk pengukuran yang diberikan.
Dalam hal ini, model memperkirakan sekitar 12 poin, tetapi kenyataannya adalah 100. Pada awalnya Anda mungkin bertanya-tanya mengapa ini terjadi, tetapi jika Anda menganalisis penjelasannya, ternyata ini bukan asumsi yang sangat berani, tetapi hasil perhitungan berdasarkan nilai-nilai tertentu.
Site EUI relatif tinggi dan orang dapat mengharapkan Skor Bintang Energi yang rendah (karena sangat dipengaruhi oleh EUI), yang dilakukan oleh model kami. Tetapi dalam kasus ini, logika ini ternyata salah, karena sebenarnya bangunan tersebut menerima Skor Bintang Energi tertinggi - 100.
Kesalahan model dapat mengganggu Anda, tetapi penjelasan seperti itu akan membantu Anda memahami mengapa model itu salah. Selain itu, berkat penjelasannya, Anda dapat mulai menggali mengapa bangunan mendapatkan skor tertinggi meskipun Situs EUI tinggi. Mungkin kita akan belajar sesuatu yang baru tentang tugas kita yang akan menghindari perhatian kita jika kita tidak mulai menganalisis kesalahan model. Alat seperti itu tidak ideal, tetapi mereka dapat sangat memudahkan pemahaman model dan membuat
keputusan yang lebih baik .
Dokumentasi pekerjaan dan presentasi hasil
Banyak proyek tidak terlalu memperhatikan dokumentasi dan laporan. Anda dapat melakukan analisis terbaik di dunia, tetapi jika Anda tidak
menyajikan hasilnya dengan benar , itu tidak akan menjadi masalah!
Dengan mendokumentasikan proyek analisis data, kami mengemas semua versi data dan kode sehingga orang lain dapat mereproduksi atau mengumpulkan proyek. Ingatlah bahwa kode dibaca lebih sering daripada ditulis, oleh karena itu pekerjaan kita harus jelas bagi orang lain, dan bagi kita, jika kita kembali ke sana dalam beberapa bulan. Karena itu, masukkan komentar yang berguna ke dalam kode dan jelaskan keputusan Anda.
Jupyter Notebooks adalah alat yang hebat untuk mendokumentasikan, mereka membiarkan Anda pertama kali menjelaskan solusi dan kemudian menunjukkan kode.
Selain itu, Jupyter Notebook adalah platform yang baik untuk berinteraksi dengan spesialis lain. Dengan menggunakan
ekstensi untuk buku catatan, Anda dapat
menyembunyikan kode dari laporan akhir , karena betapa pun sulitnya untuk percaya, tidak semua orang ingin melihat banyak kode dalam dokumen!
Anda mungkin tidak ingin memeras, tetapi tunjukkan semua detailnya. Namun, penting
untuk memahami audiens Anda ketika mempresentasikan proyek Anda, dan
menyiapkan laporan yang sesuai . Berikut adalah contoh ringkasan esensi dari proyek kami:
- Dengan menggunakan data konsumsi energi bangunan di New York, Anda dapat membangun model yang memprediksi jumlah Energy Star Points dengan kesalahan 9,1 poin.
- Situs EUI dan Intensitas Listrik Normalisasi Cuaca adalah faktor utama yang mempengaruhi perkiraan.
Kami menulis deskripsi terperinci dan kesimpulan di Notebook Jupyter, tetapi alih-alih PDF, kami mengonversi file
.tex ke
Latx , yang kemudian kami edit di
texStudio , dan
versi yang dihasilkan dikonversi ke PDF. Faktanya adalah bahwa hasil ekspor default dari Jupyter ke PDF terlihat cukup baik, tetapi itu dapat sangat ditingkatkan hanya dalam beberapa menit pengeditan. Selain itu, Lateks adalah sistem persiapan dokumen yang kuat yang berguna untuk dimiliki.
Pada akhirnya, nilai pekerjaan kita ditentukan oleh keputusan yang membantu untuk membuat, dan sangat penting untuk dapat "mengirimkan barang secara langsung". Dengan mendokumentasikan dengan benar, kami membantu orang lain mereproduksi hasil kami dan memberi kami umpan balik, yang akan memungkinkan kami untuk menjadi lebih berpengalaman dan mengandalkan hasil yang diperoleh di masa depan.
Kesimpulan
Dalam seri publikasi kami, kami telah membahas tutorial pembelajaran mesin dari awal hingga akhir. Kami mulai dengan membersihkan data, kemudian menciptakan model, dan pada akhirnya kami belajar bagaimana menafsirkannya. Ingat struktur umum proyek pembelajaran mesin:
- Membersihkan dan memformat data.
- Analisis data eksplorasi.
- Desain dan pemilihan fitur.
- Perbandingan metrik beberapa model pembelajaran mesin.
- Tuning hyperparametric model terbaik.
- Evaluasi model terbaik pada set data uji.
- Interpretasi hasil model.
- Kesimpulan dan laporan yang terdokumentasi dengan baik.
Seperangkat langkah dapat bervariasi tergantung pada proyek, dan pembelajaran mesin sering berulang daripada linier, jadi panduan ini akan membantu Anda di masa depan. Kami harap Anda sekarang dapat dengan yakin mengimplementasikan proyek Anda, tetapi ingat: tidak ada yang bertindak sendiri! Jika Anda membutuhkan bantuan, ada banyak komunitas yang sangat berguna di mana Anda akan diberikan saran.
Sumber-sumber ini dapat membantu Anda: