Pengembangan jaringan saraf yang dalam untuk pengenalan citra menghembuskan kehidupan baru ke bidang penelitian yang sudah dikenal dalam pembelajaran mesin. Salah satu bidang tersebut adalah adaptasi domain. Inti dari adaptasi ini adalah untuk melatih model pada data dari domain sumber (domain sumber) sehingga menunjukkan kualitas yang sebanding pada domain target (domain target). Misalnya, domain sumber dapat berupa data sintetis yang dapat dihasilkan dengan murah, dan domain target dapat berupa foto pengguna. Maka tugas adaptasi domain adalah untuk melatih model pada data sintetis, yang akan bekerja dengan baik dengan benda "nyata".
Dalam grup visi mesin, Vision.BIZ.Ru, kami sedang mengerjakan berbagai masalah yang diterapkan, dan di antara mereka ada yang sering memiliki data pelatihan yang sedikit. Dalam kasus ini, pembuatan data sintetis dan adaptasi model yang dilatihkan pada mereka dapat sangat membantu. Contoh penerapan yang baik dari pendekatan ini adalah tugas mendeteksi dan mengenali barang di rak-rak di toko. Mendapatkan foto-foto rak seperti itu dan menandai mereka agak melelahkan, tetapi mereka dapat dihasilkan dengan cukup sederhana. Oleh karena itu, kami memutuskan untuk mempelajari lebih dalam topik adaptasi domain.

Studi dalam adaptasi domain mempengaruhi penggunaan pengalaman sebelumnya yang diperoleh oleh jaringan saraf dalam tugas baru. Apakah jaringan dapat mengekstrak beberapa fitur dari domain sumber dan menggunakannya dalam domain target? Meskipun jaringan saraf dalam pembelajaran mesin hanya jauh terkait dengan jaringan saraf di otak manusia, namun, cawan suci peneliti kecerdasan buatan adalah untuk mengajarkan jaringan saraf kemungkinan yang dimiliki seseorang. Dan orang-orang dapat menggunakan pengalaman sebelumnya dan mengumpulkan pengetahuan untuk memahami konsep-konsep baru.
Selain itu, adaptasi domain dapat membantu memecahkan salah satu masalah mendasar pembelajaran mendalam: untuk melatih jaringan besar dengan kualitas pengenalan tinggi, diperlukan data dalam jumlah sangat besar, yang dalam praktiknya tidak selalu tersedia. Salah satu solusinya mungkin menggunakan metode adaptasi domain pada data sintetis yang dapat dihasilkan dalam jumlah yang hampir tidak terbatas.
Cukup sering dalam masalah yang diterapkan ada kasus di mana data dari hanya satu domain tersedia untuk pelatihan, dan model harus diterapkan pada domain lain. Misalnya, jaringan yang menentukan kualitas estetika fotografi dapat dilatih pada basis data yang tersedia di jaringan, yang dikumpulkan dari situs web amatir. Dan direncanakan untuk menggunakan jaringan ini dalam foto biasa, tingkat kualitasnya berbeda rata-rata dari tingkat foto dari situs foto khusus. Sebagai solusinya, kami dapat mempertimbangkan untuk mengadaptasi model ke foto biasa yang tidak berlabel.
Pertanyaan-pertanyaan teoretis dan terapan seperti itu berada dalam domain adaptasi. Dalam artikel ini, saya akan berbicara tentang penelitian utama di bidang ini, berdasarkan pembelajaran yang mendalam, dan kumpulan data untuk membandingkan berbagai metode. Gagasan utama adaptasi domain mendalam adalah untuk melatih jaringan saraf yang mendalam pada domain sumber, yang akan menerjemahkan gambar menjadi embedding (biasanya lapisan terakhir jaringan) yang bila digunakan pada domain target, kualitas tinggi akan diperoleh.
Tolok ukur inti
Seperti dalam bidang pembelajaran mesin, sejumlah penelitian dikumpulkan dalam adaptasi domain dari waktu ke waktu, yang harus dibandingkan satu sama lain. Untuk ini, masyarakat mengembangkan set data, pada bagian pelatihan yang mana model dilatih, dan pada bagian tes mereka dibandingkan. Terlepas dari kenyataan bahwa domain penelitian adaptasi domain dalam masih relatif muda, sudah ada cukup banyak artikel dan database yang digunakan dalam artikel ini. Saya akan membuat daftar yang utama, dengan fokus pada mengadaptasi domain data sintetis menjadi "nyata".
Tokoh
Rupanya, menurut tradisi yang dilembagakan oleh Yann LeCun (salah satu pelopor pembelajaran mendalam, direktur Facebook AI Research), dalam visi komputer, kumpulan data paling sederhana dikaitkan dengan angka atau huruf tulisan tangan. Ada beberapa set data dengan angka yang awalnya muncul untuk bereksperimen dengan model pengenalan gambar. Dalam artikel tentang adaptasi domain, orang dapat menemukan berbagai kombinasi mereka dalam pasangan domain sumber - target. Di antara kumpulan data ini:
- MNIST - nomor tulisan tangan, tidak perlu presentasi tambahan;
- USPS - angka tulisan tangan dalam resolusi rendah;
- SVHN - nomor rumah dengan Google Street View;
- Bilangan Synth adalah angka sintetik, seperti namanya.
Dari sudut pandang tugas pelatihan data sintetik untuk digunakan di dunia "nyata", yang paling menarik adalah pasangan:
- Sumber: MNIST, Target: SVHN;
- Sumber: USPS, Target: MNIST;
- Sumber: Nomor Bilangan, Target: SVHN.

Sebagian besar metode memiliki tolok ukur pada dataset "digital". Tetapi jenis domain lain dapat ditemukan jauh dari semua artikel.
Kantor
Dataset ini berisi 31 kategori berbagai item, yang masing-masing diwakili dalam 3 domain: gambar dari Amazon, foto dari webcam, dan foto dari kamera digital.

Berguna untuk memeriksa bagaimana model akan merespons untuk menambahkan latar belakang dan kualitas ke domain target.
Rambu lalu lintas
Sepasang dataset lain untuk melatih model data sintetis dan menerapkannya pada data "nyata":
- Sumber: Synth Signs - gambar rambu jalan yang dihasilkan sehingga terlihat seperti rambu nyata di jalan;
- Target: GTSRB adalah basis pengakuan yang cukup terkenal yang berisi rambu-rambu dari jalan-jalan Jerman.

Fitur dari pasangan database ini adalah bahwa data dari Synth Signs dibuat sangat mirip dengan data "nyata", sehingga domainnya cukup dekat.
Dari jendela mobil
Kumpulan data untuk segmentasi. Pasangan yang cukup menarik, paling dekat dengan kondisi nyata. Sumber data diperoleh dengan menggunakan mesin game (GTA 5), dan data target berasal dari kehidupan nyata. Pendekatan serupa digunakan untuk melatih model yang digunakan pada mobil otonom.
- Mesin SYNTHIA atau GTA 5 - gambar pemandangan kota dari jendela mobil yang dihasilkan menggunakan mesin game;
- Cityscapes - Gambar mobil yang diambil di 50 kota berbeda.

VisDA
Dataset ini digunakan dalam Tantangan Adaptasi Domain Visual , yang merupakan bagian dari lokakarya tentang ECCV dan ICCV. Domain sumber berisi 12 kategori objek berlabel yang dihasilkan menggunakan CAD, seperti pesawat terbang, kuda, seseorang, dll. Domain target berisi gambar yang tidak berlabel dari 12 kategori yang sama yang diambil dari ImageNet. Dalam kompetisi, yang diadakan pada 2018, kategori ke-13 ditambahkan: Tidak Dikenal.
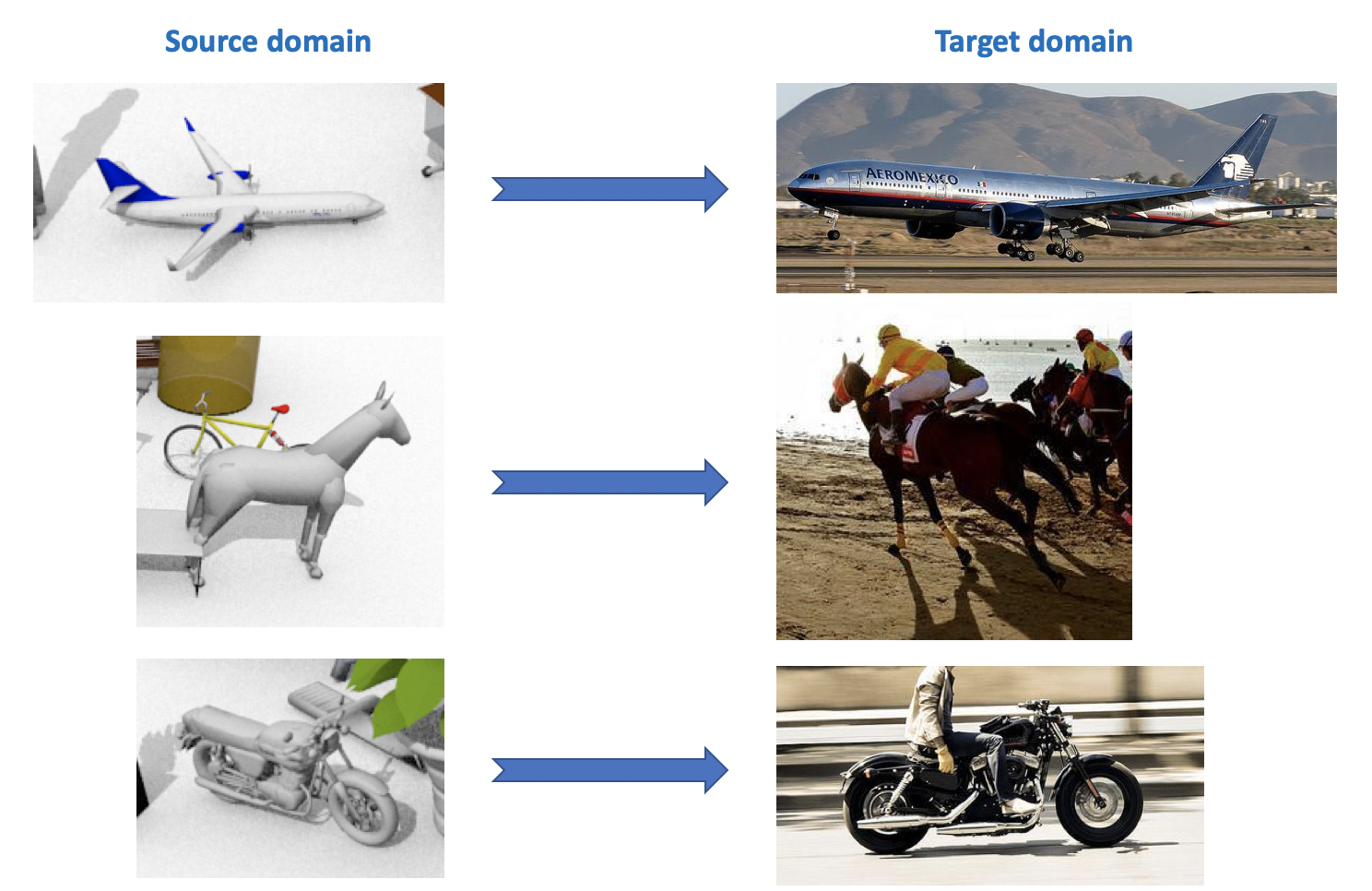
Seperti yang dapat Anda lihat dari semua hal di atas, ada cukup banyak set data yang menarik dan beragam untuk adaptasi domain, Anda dapat melatih dan menguji model untuk mereka untuk berbagai tugas (klasifikasi, segmentasi, deteksi) dan berbagai kondisi (data sintetis, foto, pemandangan jalan).
Adaptasi domain yang mendalam
Ada klasifikasi metode adaptasi domain yang cukup luas dan beragam (misalnya , lihat di sini ). Saya akan memberikan dalam artikel ini pembagian metode yang disederhanakan sesuai dengan fitur utama mereka. Metode modern adaptasi domain mendalam dapat dibagi menjadi 3 kelompok besar:
- Berbasis perbedaan: pendekatan yang didasarkan pada meminimalkan jarak antara representasi vektor pada sumber dan domain target dengan memasukkan jarak ini ke dalam fungsi kerugian.
- Berbasis Adversarial : pendekatan ini menggunakan fungsi kerugian adversarial yang diperkenalkan pada GAN untuk melatih jaringan domain-invarian. Metode keluarga ini telah dikembangkan secara aktif dalam beberapa tahun terakhir.
- Metode campuran yang tidak menggunakan kerugian permusuhan, tetapi menerapkan ide-ide dari keluarga berbasis perbedaan, serta perkembangan terbaru dari pembelajaran yang mendalam: pembuatan sendiri, lapisan baru, fungsi kerugian, dll. Pendekatan-pendekatan ini menunjukkan hasil terbaik dalam kompetisi VisDA.
Dari setiap bagian, beberapa dasar, menurut pendapat saya, hasil yang diperoleh selama 1-3 tahun terakhir akan dipertimbangkan.
Berbasis perbedaan
Ketika masalah muncul mengadaptasi model ke data baru, hal pertama yang terlintas dalam pikiran adalah penggunaan fine-tuning, mis. melatih kembali model pada data baru. Untuk melakukan ini, pertimbangkan perbedaan antara domain. Jenis adaptasi domain dapat dibagi menjadi tiga pendekatan: Kriteria Kelas, Kriteria statistik dan Kriteria Arsitektur.
Kriteria kelas
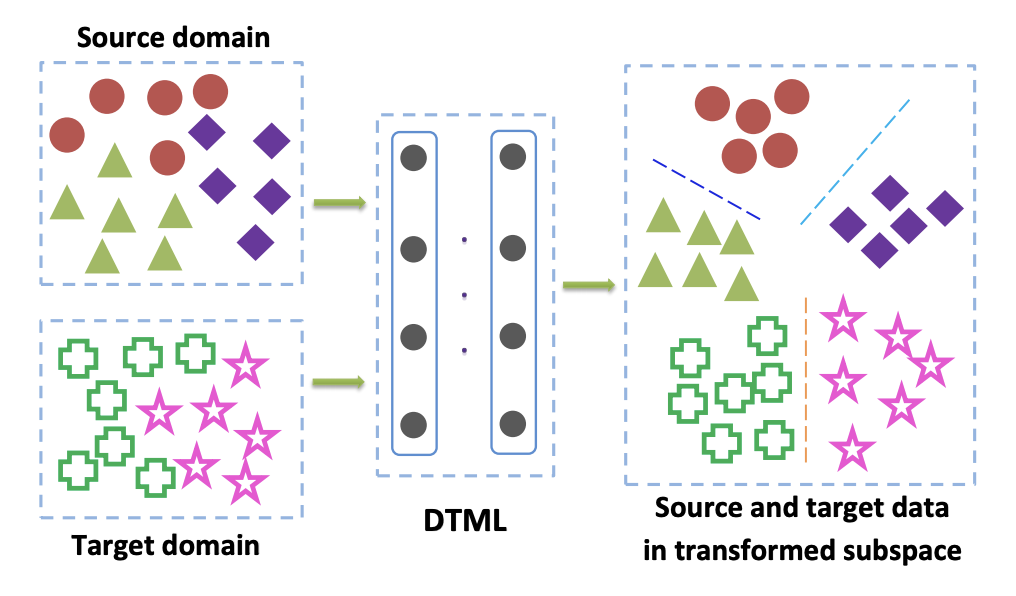
Metode dari keluarga ini terutama digunakan ketika kami memiliki akses ke data yang ditandai dari domain target. Salah satu pilihan populer untuk Kriteria Kelas adalah pendekatan pembelajaran transfer metrik Jauh . Seperti namanya, ini didasarkan pada pembelajaran metrik, yang intinya adalah untuk melatih representasi vektor yang diperoleh dari jaringan saraf sehingga perwakilan satu kelas akan dekat satu sama lain dalam representasi ini menurut metrik yang diberikan (paling sering digunakan L 2 atau metrik cosinus). Dalam artikel Deep transfer metric learning (DTML) , kerugian yang terdiri dari jumlah istilah digunakan untuk menerapkan pendekatan ini:
- Kedekatan perwakilan satu kelas satu sama lain (kekompakan intraclass);
- Meningkatnya jarak antara perwakilan dari kelas yang berbeda (pemisahan antar kelas);
- Metrik Perbedaan Maksimum (MMD) antar domain. Metrik ini milik keluarga kriteria statistik (lihat di bawah), tetapi juga digunakan dalam kriteria kelas.
MMD antar domain ditulis sebagai
MMD2(Ds,Dt)= Vert frac1M sumMi=1 phi(xsi)− frac1N sumNj=1 phi(xtj) Vert2H,
dimana phi(x) - ini adalah beberapa inti, dalam kasus kami - representasi vektor dari jaringan, xsi,i in1 ldotsM - data dari domain sumber, xti,i in1 ldotsN - data dari domain target. Jadi, ketika meminimalkan metrik MMD selama pelatihan, jaringan seperti itu dipilih phi(x) sehingga representasi vektor rata-rata di kedua domain dekat. Gagasan utama DTML:
Jika data dalam domain target tidak diberi label (adaptasi domain tanpa pengawasan), metode yang dijelaskan dalam Pikiran Bias Bobot Kelas: Perbedaan Ketimpangan Maksimum Tertimbang untuk Adaptasi Domain Tanpa pengawasan menawarkan untuk melatih model pada domain sumber dan menggunakannya untuk mendapatkan label semu (pseudo- label) pada domain target. Yaitu data dari domain target dijalankan melalui jaringan dan hasilnya disebut pseudo-label. Kemudian mereka digunakan sebagai markup untuk domain target, yang memungkinkan kriteria MMD untuk diterapkan dalam fungsi kerugian (dengan bobot yang berbeda untuk komponen yang bertanggung jawab untuk domain yang berbeda).
Kriteria statistik
Metode yang terkait dengan keluarga ini digunakan untuk memecahkan masalah adaptasi domain tanpa pengawasan. Kasus ketika domain target tidak ditetapkan terjadi dalam banyak masalah, dan semua metode adaptasi domain, yang akan dibahas kemudian dalam artikel ini, menyelesaikan masalah seperti itu.
Pendekatan berdasarkan kriteria statistik mencoba mengukur perbedaan antara distribusi representasi vektor jaringan yang diperoleh dari data domain sumber dan target. Mereka kemudian menggunakan perbedaan yang dihitung untuk menyatukan kedua distribusi ini.
Salah satu kriteria ini adalah Perbedaan Maksimum Maksimum (MMD) yang telah dijelaskan di atas. Variannya digunakan dalam beberapa metode:
Diagram dari ketiga metode ini disajikan di bawah ini. Di dalamnya, varian MMD digunakan untuk menentukan perbedaan antara distribusi pada lapisan jaringan saraf convolutional yang diterapkan pada domain sumber dan target. Harap dicatat bahwa masing-masing menggunakan modifikasi MMD sebagai kehilangan antara lapisan jaringan konvolusi (gambar kuning pada diagram).

Kriteria CORAL (CORrelation Alignment) dan perluasannya dengan bantuan jaringan Deep CORAL bertujuan untuk mempelajari representasi data sedemikian rupa sehingga statistik tingkat kedua antar domain cocok dengan maksimum. Untuk ini, matriks kovarians representasi vektor dari jaringan digunakan. Konvergensi statistik orde kedua pada kedua domain dalam beberapa kasus memungkinkan seseorang memperoleh hasil adaptasi yang lebih baik daripada MMD.
LCORAL= frac14d2 VertCS−CT Vert2F,
dimana ||∗||2F Apakah kuadrat dari norma matriks Frobenius, dan Cs dan Ct - data matriks kovarians dari domain sumber dan target, masing-masing, d - dimensi representasi vektor.
Pada dataset Office, kualitas rata-rata adaptasi menggunakan Deep CORAL untuk pasangan domain Amazon dan Webcam adalah 72,1%. Pada Tanda-Tanda Synth -> domain tanda jalan GTSRB, hasilnya juga sangat rata-rata: akurasi 86,9% pada domain target.
Pengembangan ide-ide MMD dan CORAL adalah kriteria Central Moment Discrepancy (CMD) , yang membandingkan momen pusat data dari domain sumber dan target semua pesanan hingga K inklusif ( K - parameter algoritma). Pada dataset Office, kualitas adaptasi CMD rata-rata untuk pasangan domain Amazon dan Webcam adalah 77,0%.
Kriteria arsitektur
Algoritma jenis ini didasarkan pada asumsi bahwa informasi dasar yang bertanggung jawab untuk beradaptasi dengan domain baru tertanam dalam parameter jaringan saraf.
Dalam sejumlah makalah [1] , [2], ketika melatih jaringan untuk domain sumber dan target menggunakan fungsi kehilangan untuk setiap pasangan lapisan, informasi yang tidak berubah berkenaan dengan domain dipelajari pada bobot lapisan ini. Contoh arsitektur seperti itu diberikan di bawah ini.
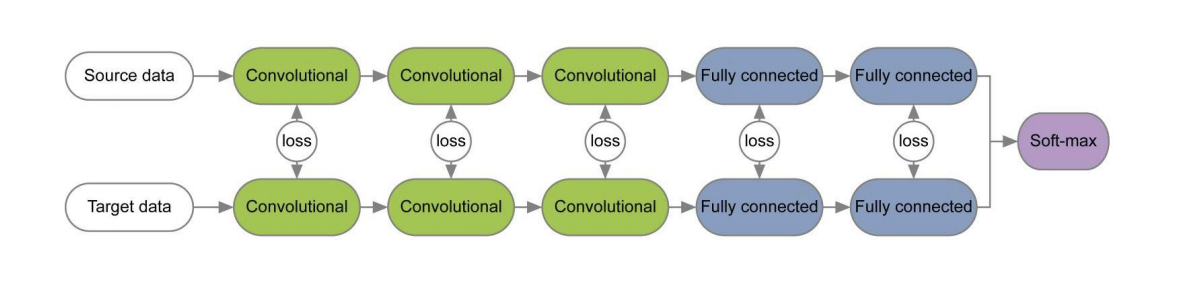
Dalam artikel " Meninjau Kembali Normalisasi Batch Untuk Praktis Domain Adaptasi" ide diajukan bahwa skala jaringan berisi informasi yang berkaitan dengan kelas-kelas di mana jaringan sedang belajar, dan informasi domain tertanam dalam statistik (rata-rata dan standar deviasi) dari lapisan Normalisasi Batch (BN). Oleh karena itu, untuk adaptasi, perlu menghitung ulang statistik ini pada data dari domain target. Menggunakan teknik ini bersama dengan CORAL dapat meningkatkan kualitas adaptasi pada dataset Office untuk pasangan domain Amazon dan Webcam hingga 75,0%. Itu kemudian menunjukkan bahwa menggunakan lapisan Normalisasi Instans (IN) bukannya BN lebih meningkatkan kualitas adaptasi. Tidak seperti BN, yang menormalkan tensor input dengan batch, IN menghitung statistik untuk normalisasi oleh saluran dan, karenanya, tidak tergantung pada batch.
Pendekatan berbasis permusuhan
Dalam 1-2 tahun terakhir, sebagian besar hasil dalam adaptasi domain mendalam terkait dengan pendekatan berbasis permusuhan. Hal ini sebagian besar disebabkan oleh perkembangan pesat dan popularitas Generative Adversarial Networks (GAN) , karena pendekatan berbasis permusuhan terhadap adaptasi domain menggunakan fungsi tujuan permusuhan yang sama dalam pelatihan seperti GAN. Dengan mengoptimalkannya, metode adaptasi domain mendalam tersebut meminimalkan jarak antara distribusi empiris representasi data vektor pada domain sumber dan target. Dengan melatih jaringan dengan cara ini, mereka mencoba membuatnya tidak berubah sehubungan dengan domain.
GAN terdiri dari dua model: generator G , pada output yang datanya dari distribusi target tertentu diperoleh; dan diskriminator D , yang menentukan apakah data dari set pelatihan atau dibuat menggunakan G . Dua model ini dilatih menggunakan fungsi tujuan permusuhan:
minG maxDV(D,G)= mathbbEx simpdata(x)[ logD(x)]+ mathbbEz simp(z)[1− logD(G(z))].
Dengan pelatihan seperti itu, generator belajar untuk "menipu" pembeda, yang memungkinkan Anda untuk mendekatkan target dan domain sumber.
Ada dua pendekatan besar dalam adaptasi domain berbasis adversarial yang berbeda dalam apakah generator digunakan atau tidak. G .
Model non-generatif
Fitur utama metode dari keluarga ini adalah pelatihan jaringan saraf dengan representasi vektor yang tidak berubah terhadap domain sumber dan target. Kemudian jaringan yang dilatih pada domain sumber yang ditandai dapat digunakan pada domain target, idealnya - praktis tanpa kehilangan kualitas klasifikasi.
Diperkenalkan pada tahun 2015, algoritma ( kode ) Pelatihan Domain-Adversarial Neural Networks (DANN ) terdiri dari 3 bagian:
- Jaringan utama, dengan bantuan representasi vektor (ekstraktor fitur) diperoleh (bagian hijau dalam ilustrasi di bawah);
- "Kepala" yang bertanggung jawab atas klasifikasi pada domain sumber (bagian biru dalam ilustrasi);
- "Head" yang belajar untuk membedakan data dari domain sumber dari domain target (bagian merah dalam ilustrasi).
Ketika pelatihan menggunakan gradient descent (SGD) (panah untuk memasukkan dalam ilustrasi), klasifikasi dan kerugian domain diminimalkan. Selain itu, selama propagasi mundur kesalahan pembelajaran untuk "kepala" yang bertanggung jawab untuk domain, lapisan pembalikan Gradien (bagian hitam dalam ilustrasi) digunakan, yang mengalikan gradien yang melewatinya dengan konstanta negatif, meningkatkan kehilangan domain. Ini memastikan bahwa distribusi representasi vektor pada kedua domain menjadi dekat.
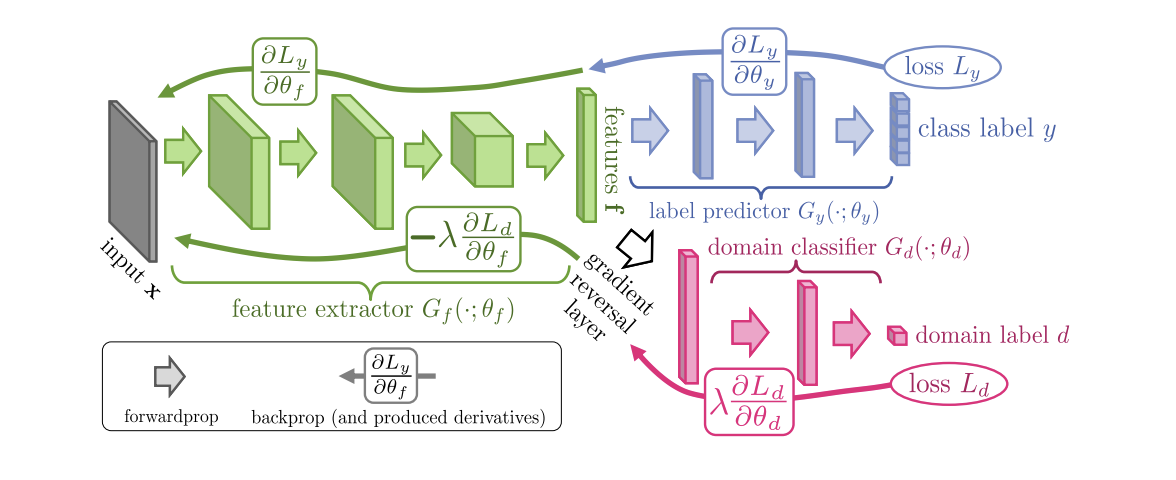
DANN hasil benchmark:
- Pada sepasang domain digital Nomor Bilangan -> SVHN: 91,09%.
- Pada Tanda-Tanda Synth -> tanda-tanda jalan GTSRB, ia melampaui CORAL dengan hasil 88,7%.
- Pada dataset Office, kualitas adaptasi rata-rata untuk pasangan domain Amazon dan Webcam adalah 73,0%.
Perwakilan penting berikutnya dari keluarga model non-generatif adalah metode Adversarial Discriminative Domain Adaptation (ADDA) ( kode ), yang melibatkan pemisahan jaringan untuk domain sumber dan jaringan untuk domain target. Algoritme terdiri dari langkah-langkah berikut:
- Pertama, kami melatih jaringan klasifikasi pada domain sumber. Kami menunjukkan representasi vektornya Ms , dan mathbfXs - domain sumber.
- Sekarang inisialisasi jaringan saraf untuk domain target menggunakan jaringan terlatih dari langkah sebelumnya. Biarkan dia Mt , dan mathbfXt - domain target.
- Mari kita beralih ke pelatihan permusuhan: kita akan melatih pembeda D di tetap Ms dan Mt menggunakan fungsi tujuan berikut:
minDLadvD( mathbfXs, mathbfXt,Ms,Mt)=− mathbbExs sim mathbfXs[ logD(Ms(xs))]− mathbbExt sim mathbfXt[ log(1−D(Mt(xt)))]
- Bekukan diskriminator dan pelatihan ulang Mt pada domain target:
minMs,MtLadvM( mathbfXs, mathbfXt,D)=− mathbbExt sim mathbfXt[ logD(Mt(xt))]
3 4 . ADDA , , adversarial- , . :
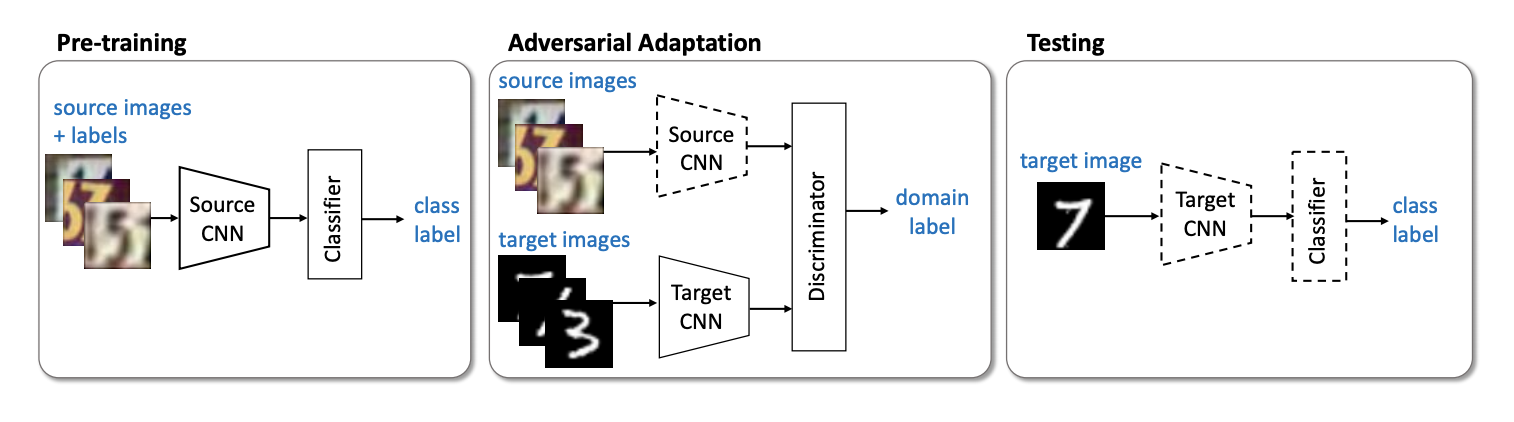
USPS -> MNIST ADDA 90,1 % .
ADDA ICML-2018 M-ADDA: Unsupervised Domain Adaptation with Deep Metric Learning ( ).
, M-ADDA metric learning, L2 -. 1 ADDA - Triplet loss ( ( ) ). , K ( K — ). Cj,j∈1…K .
ADDA, .. 2-4. 4 , Cj , :
Ext∼Xt[minj||Mt(xt)−Cj||2].
.
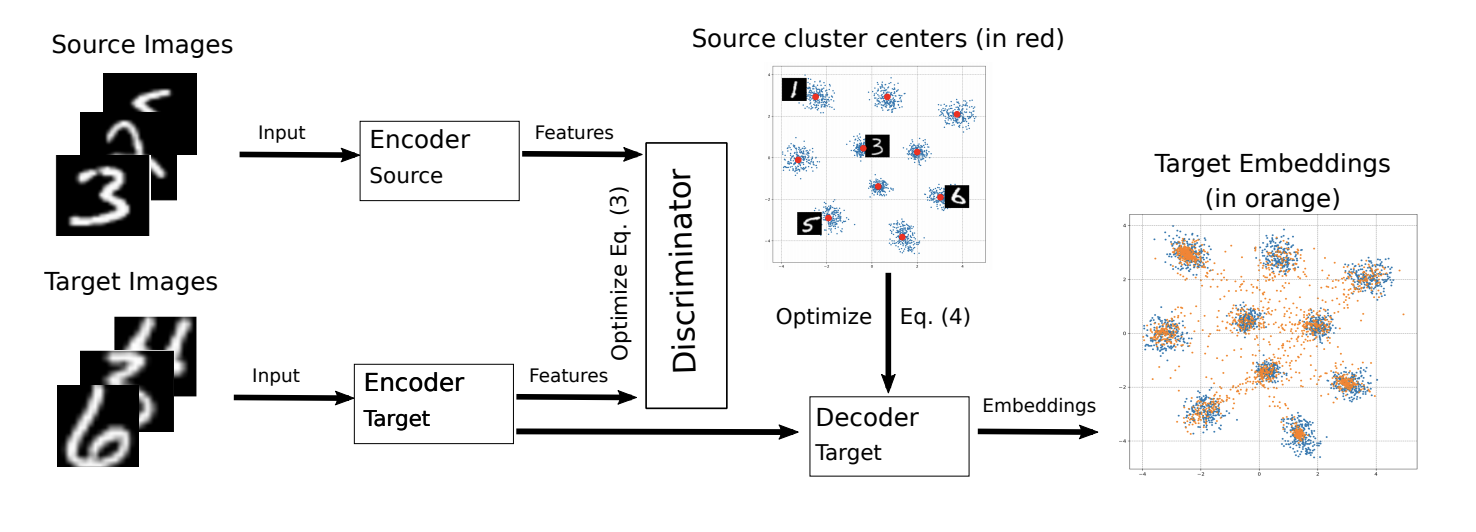
M-ADDA USPS -> MNIST 94,0 %.
non-generative Maximum Classifier Discrepancy for Unsupervised Domain Adaptation ( ). (), . , , .
G — , F1 dan F2 — , . , G , F 1 dan F 2 -; , ; , ; F 1 dan F 2 .
, adversarial-, G , .
(Discrepancy Loss)
d ( p 1 , p 2 ) = 1K K ∑ k=1| p1k-p2k| ,
K — , p 1 kp 2 k — softmax k - F 1 dan F 2 .
3 :
- A. G , F 1 dan F 2 .
- B. , .
- C . , , Discrepancy Loss.
n ( ). B C:
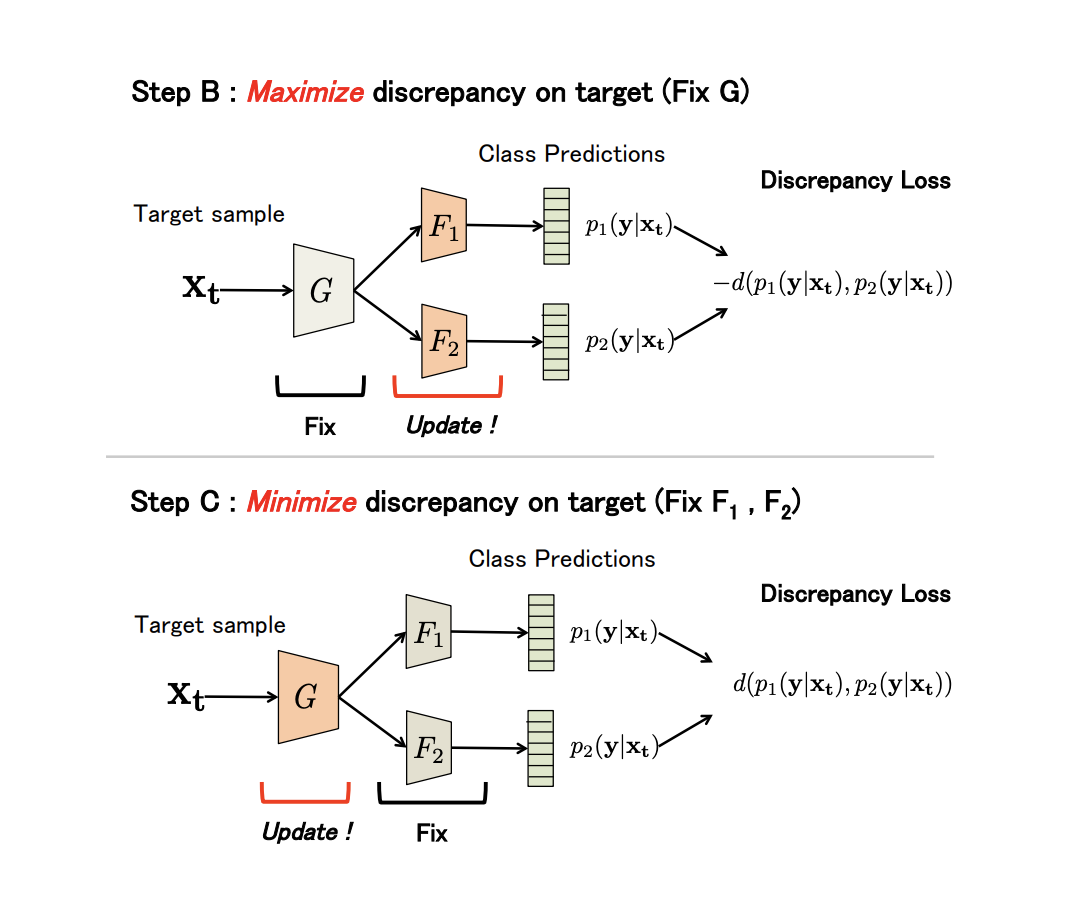
:
- USPS -> MNIST: 94,1 %.
- Synth Signs -> GTSRB : 94,4 %.
- VisDA 12 Unknown: 71,9 %.
- GTA 5 -> Cityscapes: Mean IoU = 39,7 %, Synthia -> Cityscapes: Mean IoU = 37,3 %
non-generative models:
.
Kami memeriksa dataset utama untuk adaptasi domain, pendekatan berbasis perbedaan: kriteria kelas, kriteria statistik dan kriteria arsitektur, serta keluarga non-generatif pertama dari metode berbasis permusuhan. Model dari pendekatan ini menunjukkan kinerja yang baik pada tolok ukur dan berlaku untuk banyak tugas adaptasi. Pada bagian selanjutnya, kami akan mempertimbangkan pendekatan yang paling kompleks dan efektif: model generatif dan metode campuran non-permusuhan.