Spamming di jejaring sosial dan pengirim pesan instan sangat merepotkan. Rasa sakit untuk pengguna dan pengembang yang jujur. Bagaimana mereka melawannya di Badoo, kata Mikhail Ovchinnikov di Highload ++, kemudian versi teks dari laporan ini.
Tentang pembicara: Mikhail Ovchinnikov bekerja di Badoo dan telah anti-spam selama lima tahun terakhir.
Badoo memiliki 390 juta pengguna terdaftar (data untuk Oktober 2017). Jika kami membandingkan ukuran pemirsa layanan dengan populasi Rusia, kami dapat mengatakan bahwa, menurut statistik, setiap 100 juta orang dilindungi oleh 500 ribu petugas polisi, dan di Badoo, hanya satu karyawan Antispam yang melindungi setiap 100 juta pengguna dari spam. Tetapi bahkan sejumlah kecil programmer dapat melindungi pengguna dari berbagai masalah di Internet.
Kami memiliki audiens yang besar, dan dapat memiliki pengguna yang berbeda:
- Baik dan sangat bagus, pelanggan pembayaran favorit kami;
- Yang buruk adalah mereka yang, sebaliknya, mencoba menghasilkan uang dari kami: mereka mengirim spam, menipu uang, dan terlibat dalam penipuan.
Siapa yang harus bertarung
Spam dapat berbeda, seringkali tidak dapat dibedakan sama sekali dari perilaku pengguna biasa. Itu bisa manual atau otomatis - bot yang terlibat dalam pengiriman surat otomatis juga ingin menghubungi kami.
Mungkin Anda juga pernah menulis bot - membuat skrip untuk posting otomatis. Jika Anda melakukan ini sekarang, lebih baik tidak membaca lebih lanjut - Anda tidak harus mencari tahu apa yang akan saya katakan sekarang.
Ini, tentu saja, adalah lelucon. Artikel tidak akan memiliki informasi yang akan menyederhanakan kehidupan spammer.

Jadi kita harus bertarung dengan siapa? Ini adalah spammer dan scammer.
Spam muncul sejak lama, sejak awal perkembangan Internet. Dalam layanan kami, spammer, sebagai suatu peraturan, mencoba mendaftarkan akun dengan mengunggah
foto seorang gadis yang menarik di sana . Dalam bentuk yang paling sederhana, mereka mulai mengirimkan jenis tautan spam yang paling jelas.
Opsi yang lebih rumit adalah ketika orang tidak mengirim apa pun secara eksplisit, tidak mengirim tautan apa pun, tidak mengiklankan apa pun, tetapi
memikat pengguna ke tempat yang lebih nyaman bagi mereka, misalnya, pengirim pesan instan : Skype, Viber, WhatsApp. Di sana mereka dapat, tanpa kendali kami, menjual apa pun kepada pengguna, mempromosikan, dll.
Tetapi
spammer bukan masalah terbesar . Mereka jelas dan mudah untuk diperjuangkan. Karakter yang jauh lebih kompleks dan menarik adalah
scammers yang berpura-pura menjadi orang lain dan mencoba menipu pengguna dengan segala cara yang ada di Internet.
Tentu saja, tindakan dari kedua spammer dan scammers tidak selalu sangat berbeda dari perilaku pengguna biasa yang juga melakukan hal ini kadang-kadang. Ada banyak tanda formal pada keduanya yang tidak memungkinkan garis tegas ditarik di antara mereka. Ini hampir tidak pernah mungkin.
Cara menangani spam di era Mesozoikum
- Hal paling sederhana yang dapat dilakukan adalah menulis ekspresi reguler terpisah untuk setiap jenis spam dan memasukkan setiap kata buruk dan setiap domain terpisah ke dalam reguler ini. Semua ini dilakukan secara manual, dan, tentu saja, tidak nyaman dan tidak efisien.
- Anda dapat secara manual menemukan alamat IP yang meragukan dan memasukkannya dalam konfigurasi server sehingga pengguna yang mencurigakan tidak akan pernah lagi mengakses sumber daya Anda. Ini tidak efisien karena alamat IP secara konstan dipindahkan, didistribusikan kembali.
- Tulis skrip satu kali untuk setiap jenis spammer atau bot, gosok log mereka, temukan pola secara manual. Jika ada sedikit perubahan dalam perilaku spammer, semuanya berhenti berfungsi - juga sama sekali tidak efektif.

Pertama, saya akan menunjukkan kepada Anda metode paling sederhana untuk memerangi spam yang dapat diterapkan semua orang untuk diri mereka sendiri. Kemudian saya akan memberi tahu Anda secara rinci tentang sistem yang lebih kompleks yang kami kembangkan menggunakan pembelajaran mesin dan artileri berat lainnya.
Cara termudah untuk menangani spam
Moderasi manual
Dalam layanan apa pun, Anda dapat menyewa moderator yang secara manual akan melihat konten dan profil pengguna, dan memutuskan apa yang harus dilakukan dengan pengguna ini. Biasanya, proses ini terlihat seperti menemukan jarum di tumpukan jerami. Kami memiliki sejumlah besar pengguna, moderator lebih sedikit.

Selain fakta bahwa moderator jelas membutuhkan banyak, Anda memerlukan banyak infrastruktur. Tetapi, pada kenyataannya, hal yang paling sulit adalah yang lain - muncul masalah: bagaimana, sebaliknya, melindungi pengguna dari moderator.
Penting untuk memastikan bahwa moderator tidak mendapatkan akses ke data pribadi. Ini penting karena moderator dapat secara teoritis juga mencoba melakukan kerusakan. Artinya, kita membutuhkan antispam untuk antispam, sehingga moderator berada di bawah kendali ketat.
Jelas, Anda tidak dapat memverifikasi semua pengguna dengan cara ini. Namun demikian,
moderasi dalam hal apapun diperlukan , karena setiap sistem di masa depan perlu pelatihan dan tangan manusia yang akan menentukan apa yang harus dilakukan dengan pengguna.
Koleksi statistik
Anda dapat mencoba menggunakan statistik - untuk mengumpulkan berbagai parameter untuk setiap pengguna.
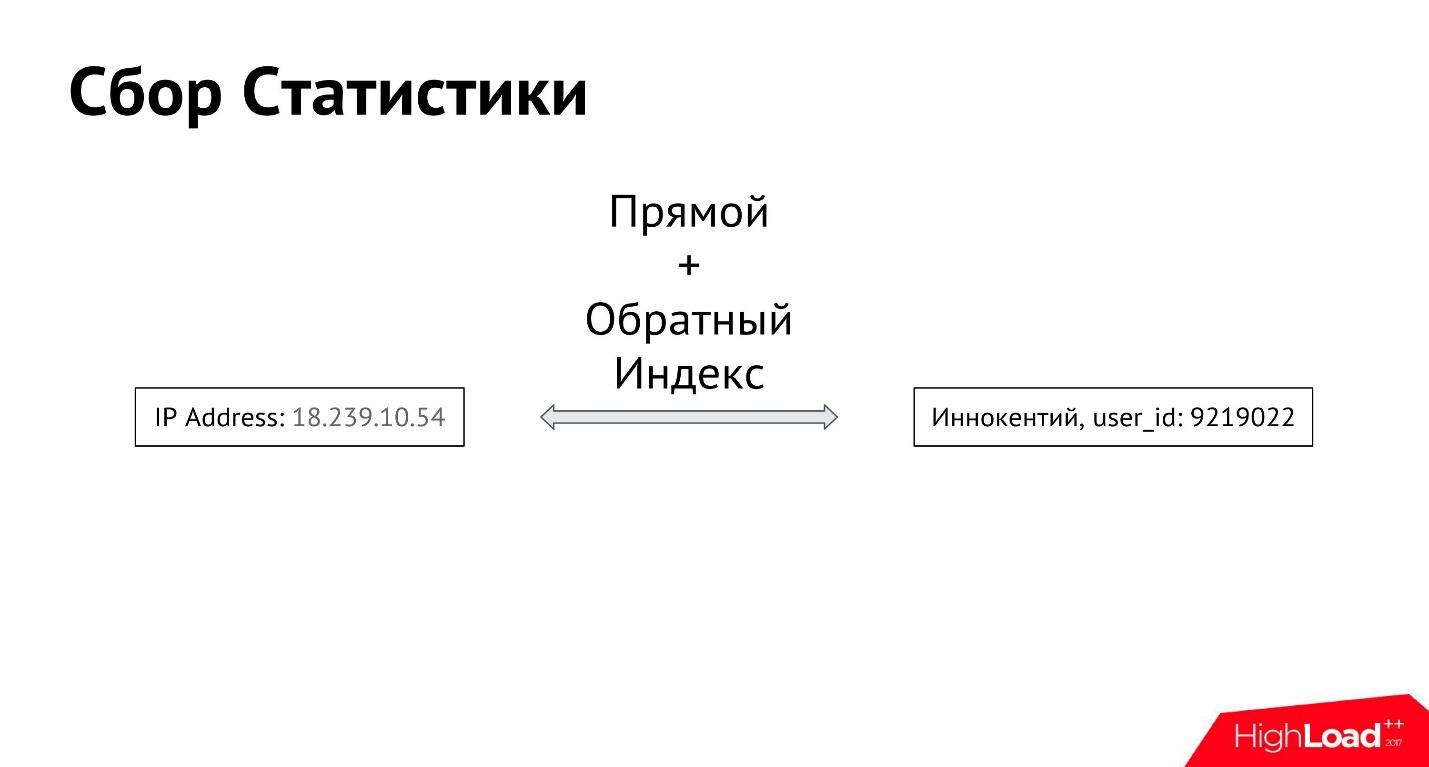
Pengguna Innokenty login dari alamat IP-nya. Hal pertama yang kami lakukan adalah masuk ke alamat IP yang dimasukkan. Selanjutnya, kami membuat indeks maju dan mundur antara semua alamat IP dan semua pengguna, sehingga Anda bisa mendapatkan semua alamat IP dari mana pengguna tertentu masuk, serta semua pengguna yang masuk dari alamat IP tertentu.
Dengan cara ini kita mendapatkan koneksi antara atribut dan pengguna. Mungkin ada banyak atribut seperti itu. Kita dapat mulai mengumpulkan informasi tidak hanya tentang alamat IP, tetapi juga foto, perangkat dari mana pengguna masuk - tentang segala sesuatu yang dapat kita tentukan.
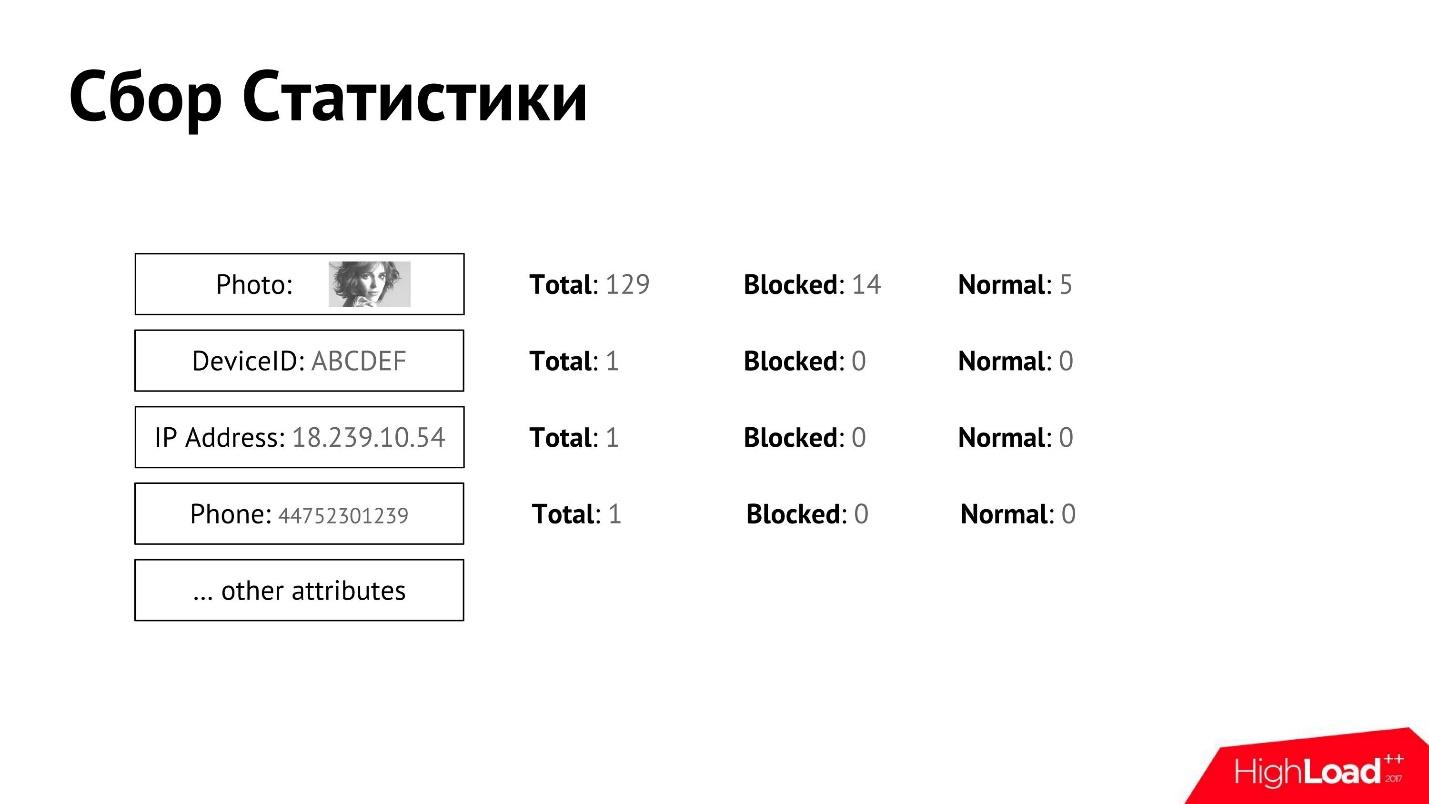
Kami mengumpulkan statistik tersebut dan mengaitkannya dengan pengguna. Untuk setiap atribut, kami dapat mengumpulkan penghitung terperinci.
Kami memiliki moderasi manual yang memutuskan pengguna mana yang baik, mana yang buruk, dan pada titik tertentu pengguna diblokir atau dikenali sebagai normal. Kami dapat memperoleh data secara terpisah untuk setiap atribut, berapa total pengguna, berapa banyak dari mereka yang diblokir, berapa banyak yang dikenali sebagai normal.
Memiliki statistik seperti itu untuk masing-masing atribut, kami secara kasar dapat menentukan siapa pengirim spam, siapa yang bukan.

Katakanlah kita memiliki dua alamat IP - 80% spammer pada satu dan 1% pada yang kedua. Jelas, yang pertama jauh lebih banyak spam, Anda perlu melakukan sesuatu dengannya dan menerapkan semacam sanksi.
Yang paling sederhana adalah menulis
aturan heuristik . Misalnya, jika pengguna yang diblokir lebih dari 80%, dan mereka yang dianggap normal - kurang dari 5%, maka alamat IP ini dianggap buruk. Kemudian kami melarang atau melakukan sesuatu yang lain dengan semua pengguna dengan alamat IP ini.
Koleksi statistik dari teks
Selain atribut jelas yang dimiliki pengguna, Anda juga dapat melakukan analisis teks. Anda dapat secara otomatis mem-parsing pesan pengguna, mengisolasi dari mereka segala sesuatu yang berhubungan dengan spam: sebutkan pengirim pesan, telepon, email, tautan, domain, dll., Dan kumpulkan statistik yang persis sama dari mereka.

Misalnya, jika nama domain dikirim dalam pesan oleh 100 pengguna, yang 50 di antaranya diblokir, maka nama domain ini buruk. Itu bisa dimasukkan daftar hitam.
Kami akan menerima sejumlah besar statistik tambahan untuk masing-masing pengguna berdasarkan teks pesan. Tidak diperlukan pembelajaran mesin untuk ini.
Hentikan kata-kata
Selain hal-hal yang jelas - telepon dan tautan - Anda dapat mengekstrak frasa atau kata-kata dari teks yang sangat umum untuk spammer. Anda dapat mempertahankan daftar kata berhenti ini secara manual.
Misalnya, pada akun spammer dan scammer, frasa: "Ada banyak pemalsuan" sering ditemukan. Mereka menulis bahwa mereka umumnya satu-satunya di sini yang ditetapkan untuk sesuatu yang serius, semua palsu lainnya, yang tidak dapat dipercaya.
Di situs kencan menurut statistik, spammer lebih sering daripada orang biasa menggunakan frasa: "Saya mencari hubungan yang serius." Tidak mungkin bahwa orang biasa akan menulis ini di situs kencan - dengan kemungkinan 70% ini adalah spammer yang mencoba memikat seseorang.
Cari akun serupa
Dengan statistik atribut dan kata-kata penghenti yang ditemukan dalam teks, Anda dapat membangun sistem untuk mencari akun yang serupa. Ini diperlukan untuk menemukan dan mencekal semua akun yang dibuat oleh orang yang sama. Spammer yang telah diblokir dapat segera mendaftarkan akun baru.
Misalnya, pengguna Harold masuk, masuk ke situs dan memberikan atributnya yang agak unik: alamat IP, foto, kata berhenti yang ia gunakan. Mungkin dia bahkan mendaftar dengan akun Facebook palsu.
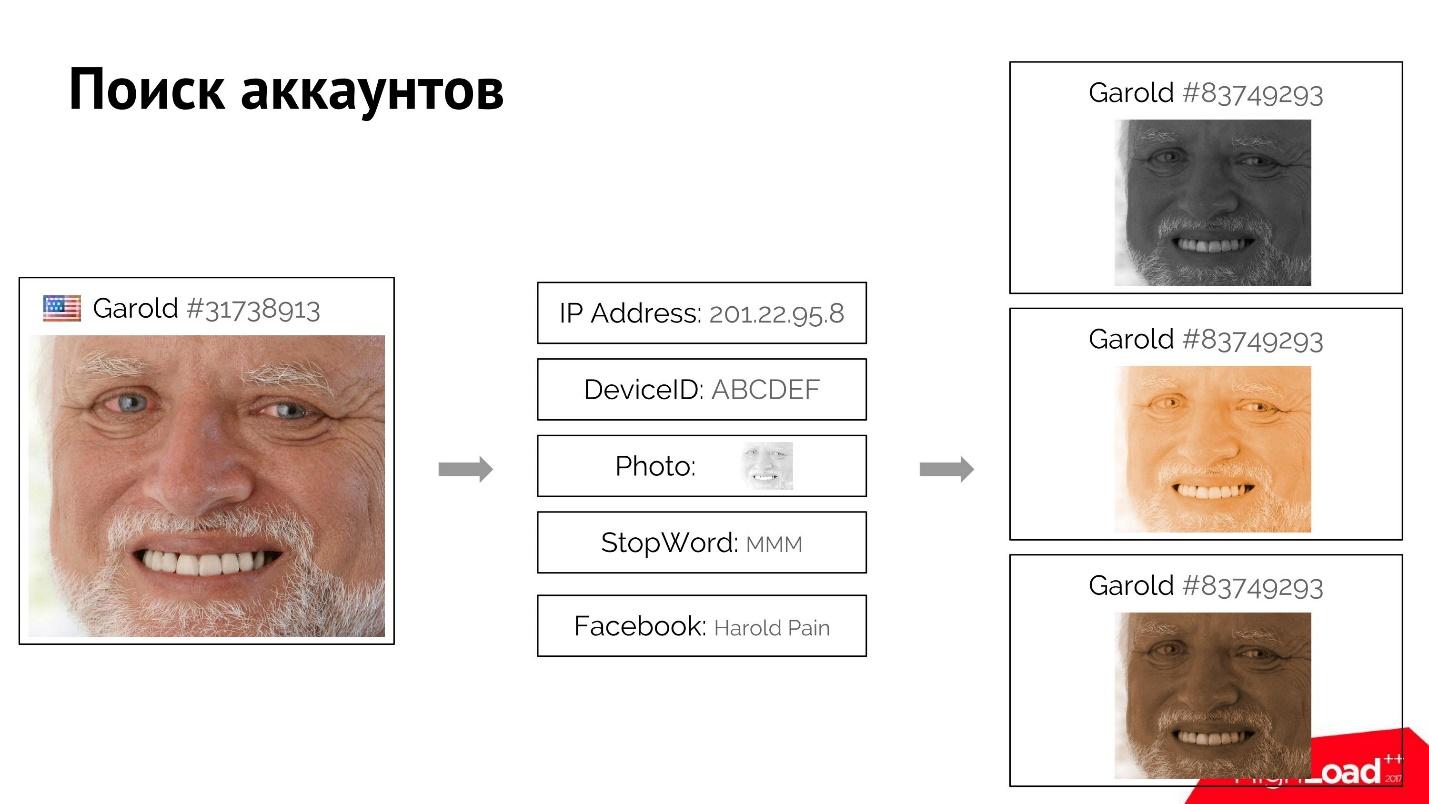
Kami dapat menemukan semua pengguna yang mirip dengannya yang memiliki satu atau lebih atribut yang cocok. Ketika kami tahu pasti bahwa pengguna ini terhubung, menggunakan indeks sangat maju dan mundur, kami menemukan atribut, dan oleh mereka semua pengguna, dan peringkat mereka. Jika, katakanlah Harold pertama, kita blokir, maka sisanya juga mudah untuk "membunuh" menggunakan sistem ini.
Semua metode yang baru saja saya jelaskan sangat sederhana: mudah mengumpulkan statistik, lalu mudah mencari pengguna menggunakan atribut ini. Tetapi, meskipun mudah, dengan bantuan hal-hal sederhana seperti - moderasi sederhana, statistik sederhana, kata-kata berhenti sederhana - mereka berhasil
mengalahkan 50% dari spam .
Di perusahaan kami, selama enam bulan pertama bekerja, departemen Antispam mengalahkan 50% spam. 50% sisanya, seperti yang Anda tahu, jauh lebih rumit.
Cara menyulitkan hidup para spammer
Spammer menciptakan sesuatu, mencoba menyulitkan hidup kita, dan kita berusaha untuk melawannya. Ini adalah perang tanpa akhir. Ada lebih banyak dari mereka daripada kita, dan pada setiap langkah kita datang dengan multi-path mereka sendiri.
Saya yakin bahwa konferensi spammer berlangsung di suatu tempat di mana para pembicara berbicara tentang bagaimana mereka mengalahkan Badoo Antispam, tentang KPI mereka, atau tentang bagaimana membangun spam yang toleran terhadap kesalahan yang dapat diukur menggunakan teknologi terbaru.
Sayangnya, kami tidak diundang ke konferensi semacam itu.
Tapi kita bisa membuat hidup sulit bagi spammer. Misalnya, alih-alih langsung menunjukkan kepada pengguna jendela "Anda dikunci", Anda dapat menggunakan apa yang disebut
pelarangan Stealth - ini adalah saat kami tidak mengatakan kepada pengguna bahwa ia dilarang. Dia seharusnya tidak curiga.

Pengguna masuk ke kotak pasir (Silent Hill), di mana semuanya tampak nyata: Anda dapat mengirim pesan, memilih, tetapi sebenarnya semuanya masuk ke dalam kekosongan, ke dalam kabut. Tidak ada yang akan melihat dan mendengar, tidak ada yang akan menerima pesan dan suaranya.
Kami memiliki kasus ketika seorang spammer melakukan spam dalam waktu yang lama, mempromosikan barang dan layanan buruknya, dan enam bulan kemudian memutuskan untuk menggunakan layanan sebagaimana dimaksud. Dia mendaftarkan akun aslinya: foto asli, nama, dll. Secara alami, mesin pencari kami untuk akun yang serupa dengan cepat menemukan jawabannya dan memasukkannya ke dalam larangan Stealth. Setelah itu, ia menulis selama enam bulan dengan kekosongan bahwa ia sangat kesepian, tidak ada yang menjawab. Secara umum, ia mencurahkan seluruh jiwanya ke kabut Bukit Silent, tetapi tidak menerima jawaban.
Spammer, tentu saja, bukan orang bodoh. Entah bagaimana mereka berusaha untuk menentukan bahwa mereka masuk ke kotak pasir dan bahwa mereka diblokir, keluar dari akun lama dan menemukan yang baru. Kami kadang-kadang bahkan mendapat ide bahwa akan lebih baik untuk mengirim beberapa spammer ini ke kotak pasir bersama, sehingga di sana mereka akan menjual satu sama lain semua yang mereka inginkan dan bersenang-senang sesuka Anda. Tetapi sementara kami belum mencapai titik ini, kami sedang memikirkan metode lain, misalnya foto dan verifikasi telepon.

Seperti yang Anda ketahui, sulit bagi seorang spammer yang merupakan bot dan bukan orang yang lolos verifikasi melalui telepon atau foto.
Dalam kasus kami, verifikasi berdasarkan foto terlihat seperti ini: pengguna diminta untuk mengambil gambar dengan gerakan tertentu, foto yang dihasilkan dibandingkan dengan foto yang sudah dimuat dalam profil. Jika wajahnya sama, maka kemungkinan besar orang itu asli, mengunggah foto aslinya dan dapat ditinggalkan selama beberapa waktu.
Tidak mudah bagi spammer untuk lulus tes ini. Kami bahkan mendapatkan permainan kecil di dalam perusahaan bernama Guess Who the Spammer. Diberikan empat foto, Anda perlu memahami yang mana di antara mereka adalah spammer.
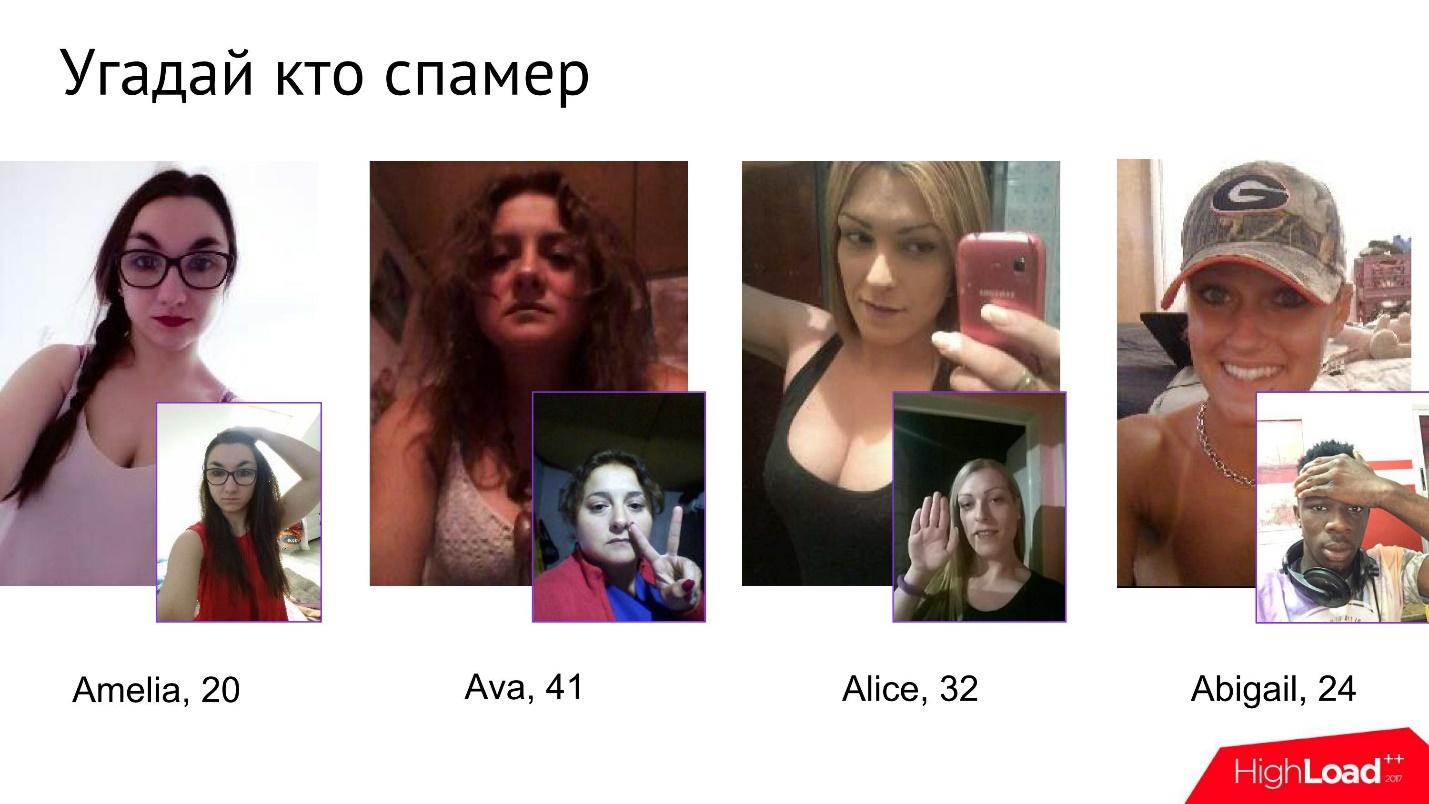
Pada pandangan pertama, gadis-gadis ini terlihat benar-benar tidak berbahaya, tetapi segera setelah mereka mulai menjalani verifikasi foto, pada titik tertentu menjadi jelas bahwa salah satu dari mereka benar-benar tidak seperti yang ia klaim.
Bagaimanapun, spammer kesulitan memperjuangkan verifikasi foto. Mereka benar-benar menderita, mencoba untuk menghindarinya, menipu, dan menunjukkan semua keterampilan photoshop mereka.

Spammer melakukan semua yang mereka bisa, dan kadang-kadang mereka berpikir, mungkin, bahwa semua ini sepenuhnya diproses oleh beberapa teknologi modern yang luar biasa yang dibangun dengan buruk sehingga mereka mudah untuk dibodohi.
Mereka tidak tahu bahwa setiap foto sekali lagi diperiksa secara manual oleh moderator.
Tidak ada waktu
Faktanya, terlepas dari kenyataan bahwa kita datang dengan berbagai cara untuk membuat hidup lebih sulit bagi para spammer, biasanya tidak ada cukup waktu, karena anti-spam harus bekerja secara instan. Ia harus menemukan dan menetralisir pengguna sebelum memulai aktivitas negatifnya.
Hal terbaik yang dapat dilakukan adalah menentukan pada tahap pendaftaran bahwa pengguna tidak terlalu baik. Ini dapat dilakukan, misalnya, menggunakan pengelompokan.
Pengelompokan pengguna
Kami dapat mengumpulkan semua informasi yang mungkin setelah pendaftaran. Kami masih belum memiliki perangkat apa pun yang digunakan untuk masuk oleh pengguna, atau foto, tidak ada statistik. Kami tidak mengirimi dia untuk verifikasi, dia tidak melakukan sesuatu yang mencurigakan. Tetapi kami sudah memiliki informasi primer:
- jenis kelamin
- umur
- negara pendaftaran;
- negara dan penyedia IP;
- Domain email
- operator telepon (jika ada);
- data dari fb (jika ada) - berapa banyak teman yang dia miliki, berapa banyak foto yang dia unggah, berapa lama dia mendaftar di sana, dll.
Semua informasi ini dapat digunakan untuk menemukan kluster pengguna. Kami menggunakan algoritma pengelompokan
K-means yang sederhana dan populer. Ini diimplementasikan dengan sempurna di mana-mana, didukung di semua pustaka MachineLearning, paralel sempurna, ia bekerja dengan cepat. Ada versi streaming dari algoritme ini yang memungkinkan Anda untuk mendistribusikan pengguna di cluster on the fly. Bahkan dalam volume kami, semua ini bekerja cukup cepat.
Setelah menerima grup pengguna seperti itu, kami dapat melakukan tindakan apa pun. Jika pengguna sangat mirip (cluster sangat terhubung), maka kemungkinan besar ini adalah pendaftaran massal, itu harus segera dihentikan. Pengguna belum punya waktu untuk melakukan apa pun, cukup klik tombol "Daftar" - dan itu saja, ia sudah masuk ke kotak pasir.
Statistik dapat dikumpulkan pada cluster - jika 50% dari cluster diblokir, maka 50% sisanya dapat dikirim untuk verifikasi, atau secara individual memoderasi semua cluster secara manual, melihat atribut yang dengannya mereka bertepatan, dan membuat keputusan. Berdasarkan data tersebut, analis dapat mengidentifikasi pola.
Pola
Pola adalah sekumpulan atribut pengguna paling sederhana yang segera kita ketahui. Beberapa pola sebenarnya bekerja sangat efektif terhadap jenis spammer tertentu.
Misalnya, pertimbangkan kombinasi tiga atribut yang sepenuhnya independen dan cukup umum:
- Pengguna terdaftar di AS;
- Penyedia adalah Privax LTD (operator VPN);
- Email-Domain: [mail.ru, list.ru, bk.ru, inbox.ru].
Ketiga atribut ini, yang tampaknya secara terpisah tidak mewakili diri mereka sendiri, bersama-sama memberikan kemungkinan bahwa ini adalah spammer, hampir 90%.
Anda dapat mengekstrak pola tersebut sebanyak yang Anda suka untuk setiap jenis spammer. Ini jauh lebih efisien dan lebih mudah daripada secara manual melihat semua akun atau bahkan cluster.
Pengelompokan teks
Selain mengelompokkan pengguna berdasarkan atribut, Anda dapat menemukan pengguna yang menulis teks yang sama. Tentu saja, ini tidak sesederhana itu. Faktanya adalah layanan kami bekerja dalam banyak bahasa. Selain itu, pengguna sering menulis dengan singkatan, gaul, kadang-kadang dengan kesalahan. Nah, pesannya sendiri biasanya sangat pendek, secara harfiah 3-4 kata (sekitar 25 karakter).
Karenanya, jika kita ingin menemukan teks serupa di antara miliaran pesan yang ditulis pengguna, kita perlu membuat sesuatu yang tidak biasa. Jika Anda mencoba menggunakan metode klasik berdasarkan analisis morfologi dan pemrosesan bahasa yang benar-benar jujur, maka dengan semua batasan, slangs, akronim, dan banyak bahasa ini, ini sangat sulit.
Anda dapat melakukan sedikit lebih sederhana - terapkan algoritma
n-gram . Setiap pesan yang muncul dipecah menjadi n-gram. Jika n = 2, maka ini adalah bigrams (pasangan huruf). Secara bertahap, seluruh pesan dibagi menjadi pasangan huruf dan statistik dikumpulkan, berapa kali setiap bigram muncul dalam teks.

Anda tidak bisa berhenti di bigrams, tetapi tambahkan trigram, skipgram (statistik pada huruf setelah 1, 2, dll.). Semakin banyak informasi yang kami dapatkan, semakin baik. Tetapi bahkan bigRams sudah bekerja dengan cukup baik.
Kemudian kita mendapatkan vektor dari bigrams dari setiap pesan yang panjangnya sama dengan kuadrat panjang alfabet.
Sangat nyaman untuk bekerja dengan vektor ini dan mengelompokkannya, karena:
- terdiri dari angka-angka;
- terkompresi, tidak ada rongga;
- selalu ukuran tetap.
- algoritma k-means dengan vektor terkompresi dengan ukuran tetap sangat cepat. Miliaran pesan kami dikelompokkan dalam beberapa menit.
Tapi itu belum semuanya. Sayangnya, jika kami hanya mengumpulkan semua pesan yang memiliki frekuensi serupa dengan bigrams, kami mendapatkan pesan yang memiliki frekuensi yang hampir sama dengan bigrams. Namun, mereka tidak harus pada kenyataannya setidaknya agak mirip artinya. Seringkali ada teks panjang di mana vektor-vektornya sangat dekat, hampir sama, tetapi teks itu sendiri sangat berbeda. Selain itu, mulai dari panjang teks tertentu, metode pengelompokan ini umumnya akan berhenti bekerja, karena frekuensi bigrams sama.

Karena itu, Anda perlu menambahkan pemfilteran. Karena cluster sudah ada, mereka cukup kecil, kita dapat dengan mudah melakukan penyaringan di dalam cluster menggunakan Stemming atau Bag of Words. Di dalam kluster kecil, Anda dapat benar-benar membandingkan semua pesan dengan semua orang, dan mendapatkan kluster yang dijamin memiliki pesan yang sama yang bertepatan tidak hanya dalam statistik, tetapi juga dalam kenyataan.
, — , , ( ) . , - .
— VPN, TOR, Proxy, . , , , .
, , « IP».

VPN — , IP- , IP- VPN, Proxy .
:
- ISP (Internet Service Provider), IP- . , .
- Whois . IP- Whois : ; ; , IP-; , IP- .. , IP-.
- GeolP. , IP- , , IP- , , , IP- - .
- — IP- , GeolP, Whois, .
, , , IP- VPN .
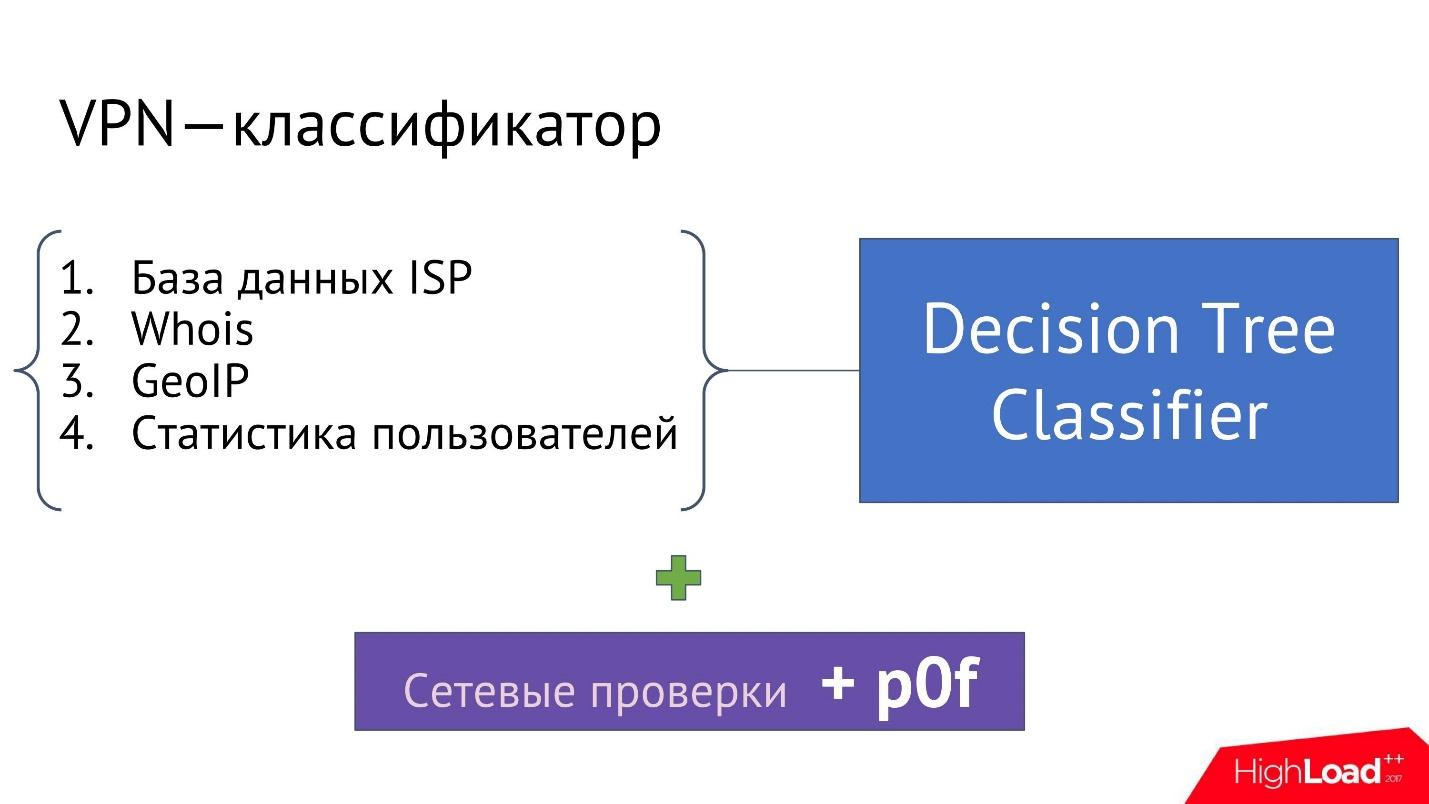
, — , , .., , IP- VPN.
, . , advanced-, 100% . .
, IP- VPN, , IP- . , , . SOCKS-proxy, IP- .
, , ,
p0f . , fingerprinting , : , VPN-, Proxy .. , .
, , , , , : ? — ! , , , .
— ? . 2 , .
, , , , , , , .

, , ?
«User Decency»
— , .
«» :
.
. , , , .
, , «
». , , , , . .
1, , , , — .
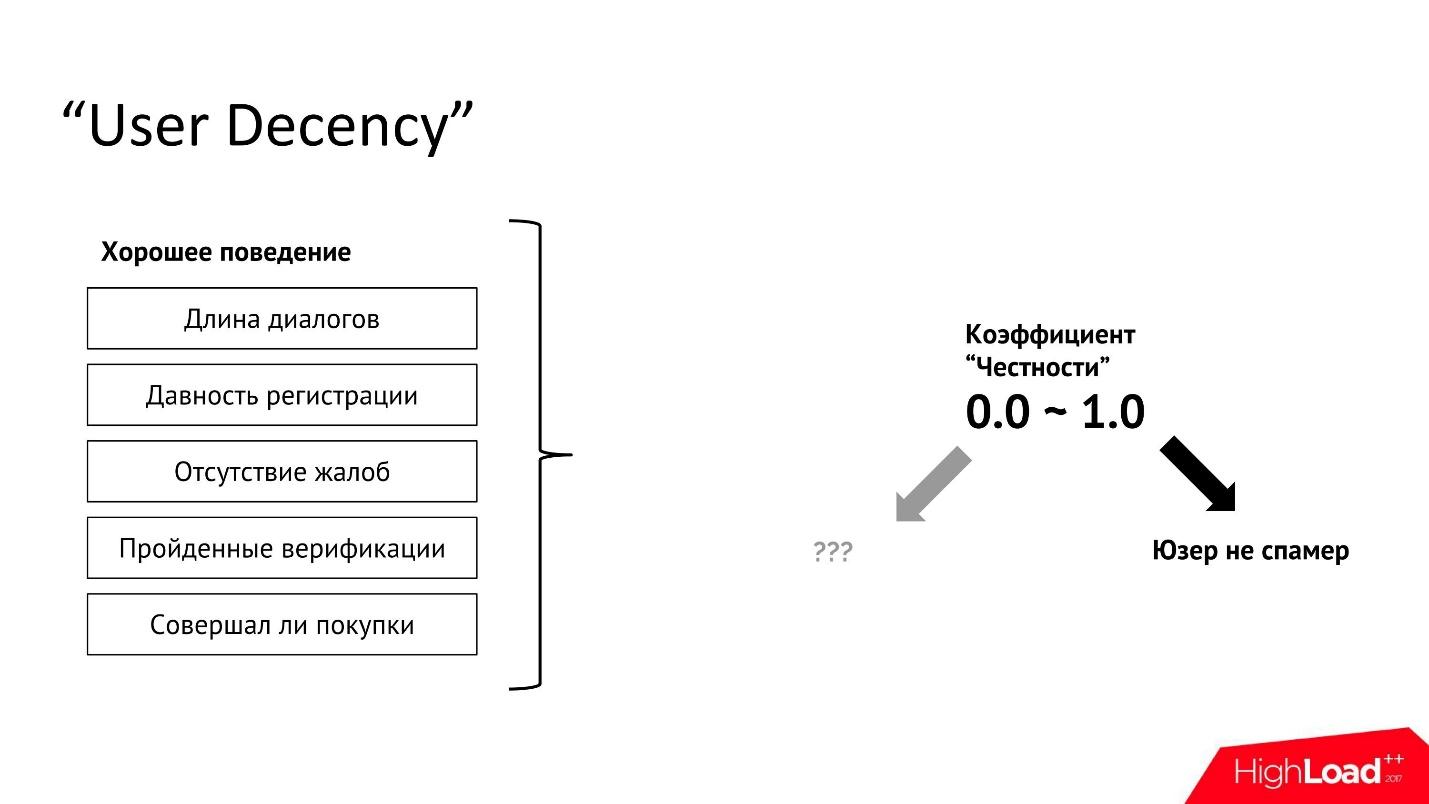
.
False positive
, — . , IP-. , -, . , fingerprint, , , — , , , , - .
: : «, — Pornhub — ?» , - , .
. , , , .
- «Pornhub». - , - .
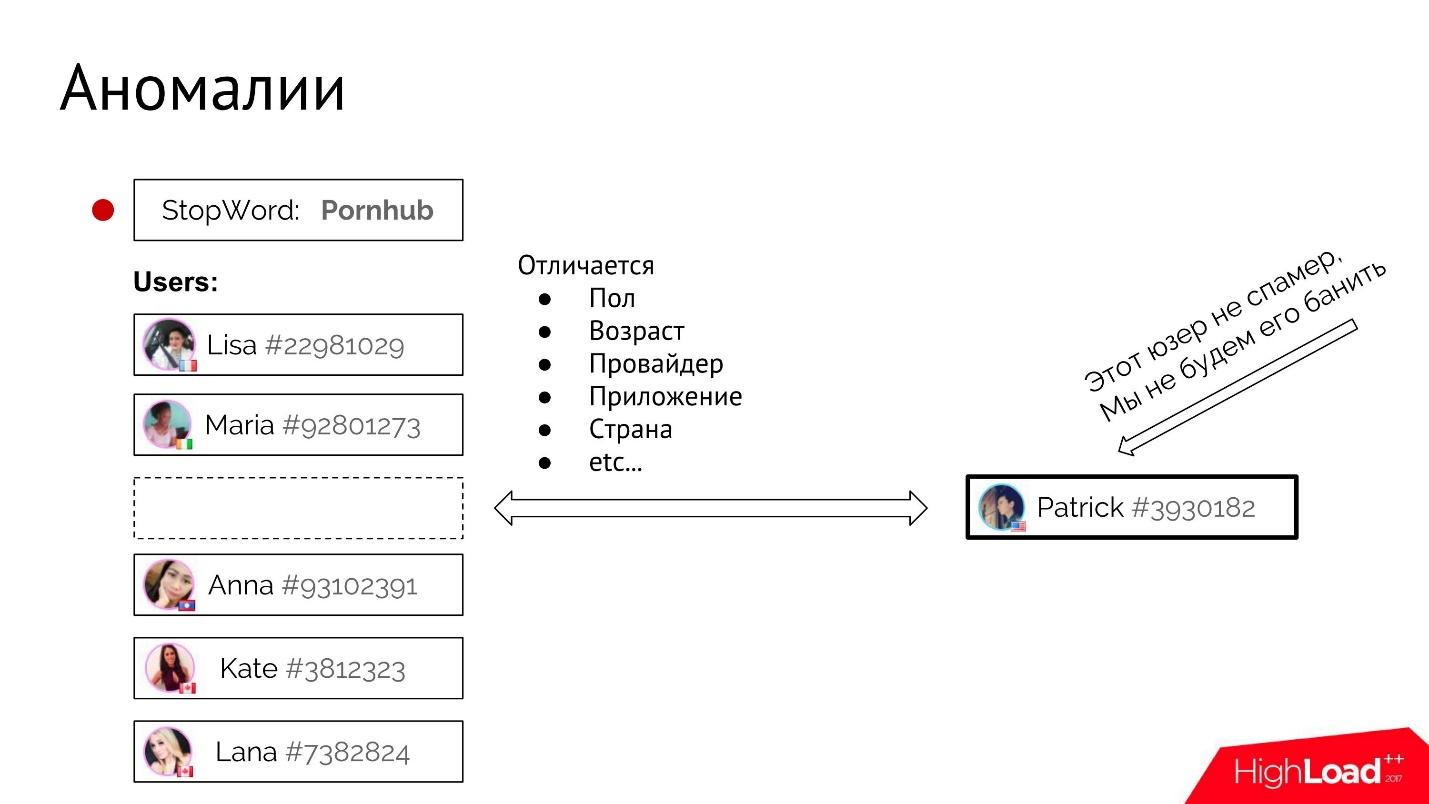
- -, .
, , . : , , , , .. , «» . , , , . , , .
, .
-
— MachineLearning, , 0 1 — .
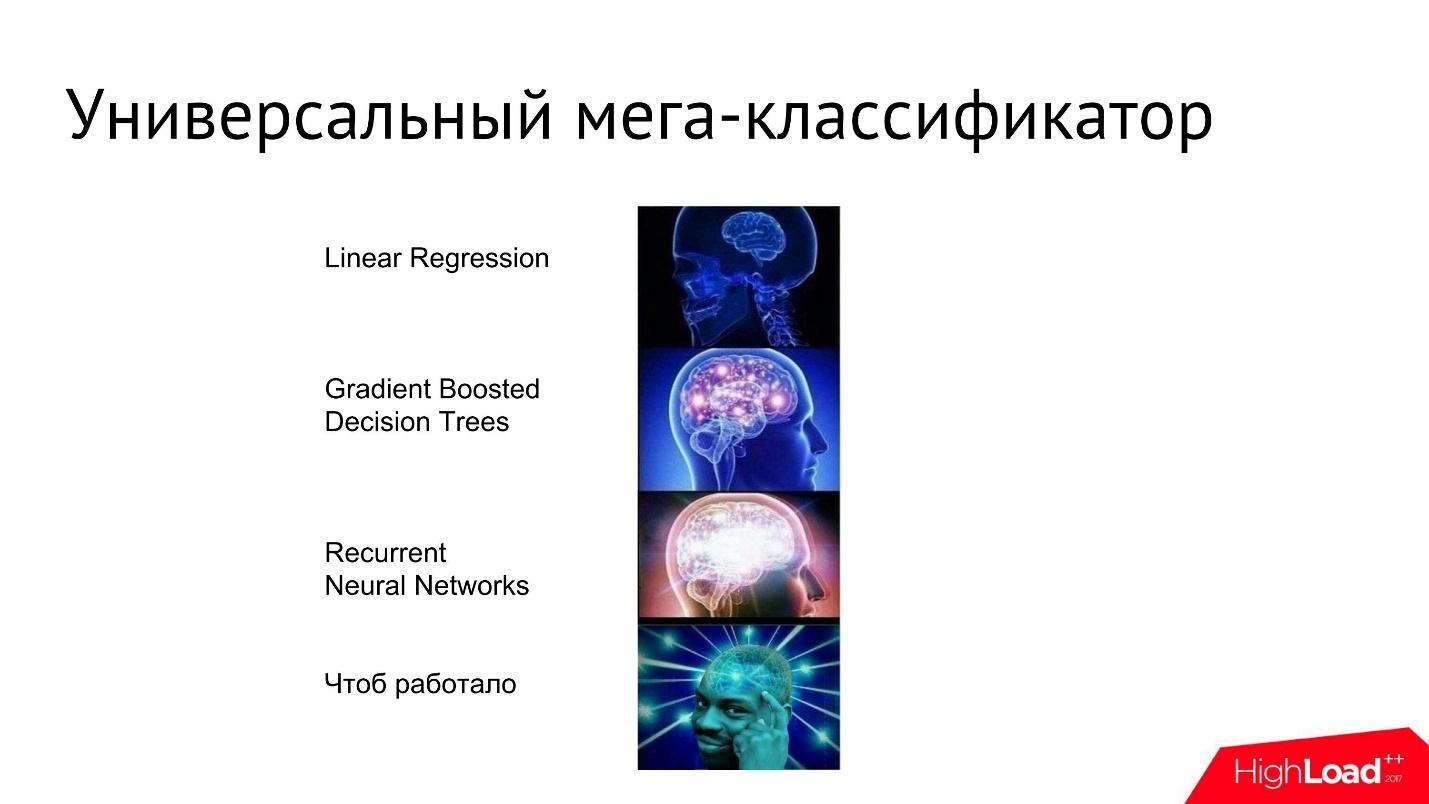
, ,
, . , , . , - , .
, — . — , .
, ( ) , , . , , , : , , . .
HighLoad++ 2018 , , :
- ML- ,
- NVIDIA , .
- use case .
youtube- , — , .