Banyak peserta reguler
ML-training berpendapat bahwa berpartisipasi dalam kontes adalah cara tercepat untuk masuk ke profesi. Kami bahkan punya
artikel tentang hal ini. Penulis kuliah hari ini Arthur Kuzin, menggunakan contohnya sendiri, menunjukkan bagaimana mungkin dalam beberapa tahun untuk berlatih kembali dari bidang yang sama sekali tidak terkait dengan pemrograman menjadi spesialis dalam analisis data.
- Halo semuanya. Nama saya Arthur Cousin, saya adalah ilmuwan data utama di Dbrain.
Emil memiliki laporan yang agak komprehensif, menceritakan banyak aspek. Saya akan fokus pada apa yang saya anggap paling penting dan menyenangkan. Sebelum saya membahas topik laporan ini, saya ingin memperkenalkan diri. Secara umum, saya lulus dari Fisika dan selama sekitar 8 tahun, dari tahun ketiga, saya bekerja di laboratorium, yang terletak di lantai NK. Laboratorium ini terlibat dalam pembuatan mikro dan struktur nano.

Selama ini saya bekerja sebagai peneliti, dan ini tidak ada hubungannya dengan ML atau bahkan pemrograman. Ini menunjukkan seberapa rendah ambang untuk memasuki pembelajaran mesin, seberapa cepat Anda dapat mengembangkan ini. Selanjutnya, di wilayah 2013, teman-teman saya memanggil saya ke startup yang bergerak di ML. Dan selama 2-3 tahun saya belajar pemrograman dan ML pada saat yang sama. Kemajuan saya agak lambat - saya mempelajari materi, menyelidiki, tetapi tidak secepat yang terjadi sekarang. Bagi saya, semuanya berubah ketika saya mulai berpartisipasi dalam kompetisi ML. Kompetisi pertama adalah dari Avito, tentang klasifikasi mobil. Saya tidak benar-benar tahu bagaimana berpartisipasi di dalamnya, tetapi berhasil mengambil tempat ketiga. Segera setelah itu, kompetisi lain dimulai, sudah didedikasikan untuk klasifikasi iklan. Ada gambar, teks, deskripsi, harga - itu adalah kompetisi yang kompleks. Di dalamnya, saya mengambil tempat pertama, setelah itu saya segera menerima tawaran dan mereka membawa saya ke Avito. Kemudian tidak ada posisi junior, saya langsung diambil oleh kalangan menengah - hampir tanpa pengalaman yang relevan.
Selanjutnya, ketika saya sudah bekerja di Avito, saya mulai berpartisipasi dalam kompetisi di Kaggle dan sekitar satu tahun saya menerima grand master. Sekarang saya berada di posisi ke-58 di peringkat keseluruhan. Ini profil saya. Setelah bekerja di Avito selama satu setengah tahun, saya pindah ke Dbrain dan sekarang saya sedikit menjadi direktur ilmu data, mengoordinasikan pekerjaan tujuh ilmuwan data. Semua yang saya gunakan dalam pekerjaan saya saya pelajari dari kompetisi. Oleh karena itu, saya percaya bahwa ini adalah topik yang sangat keren, dan dalam segala hal saya menganjurkan untuk berpartisipasi dalam kompetisi dan pengembangan.
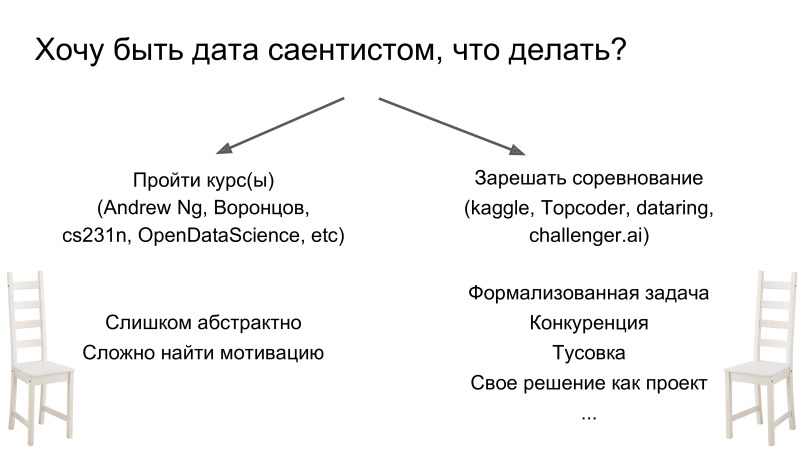
Terkadang mereka bertanya kepada saya apa yang perlu dilakukan jika Anda ingin menjadi ilmuwan data. Ada dua cara. Pertama-tama dengarkan suatu kursus. Ada banyak dari mereka, semuanya berkualitas cukup tinggi. Tetapi bagi saya pribadi itu tidak berfungsi sama sekali. Semua orang berbeda, tetapi saya tidak menyukainya, hanya karena, sebagai aturan, kursus adalah tugas yang sangat abstrak, dan ketika saya membaca bagian, saya tidak selalu mengerti mengapa saya perlu mengetahuinya. Berbeda dengan pendekatan ini, Anda cukup mengambil dan mulai menyelesaikan kompetisi. Dan ini adalah aliran yang sangat berbeda dalam hal pendekatan. Ini berbeda karena Anda segera memperoleh sejumlah pengetahuan dan mulai mempelajari topik baru ketika Anda menemukan sesuatu yang tidak dikenal. Artinya, Anda mulai memutuskan dan memahami bahwa Anda kurang pengetahuan tentang cara melatih jaringan saraf. Anda ambil, google dan belajar - hanya ketika Anda membutuhkannya. Ini sangat sederhana dalam hal motivasi, kemajuan, karena Anda sudah memiliki tugas yang dirumuskan dengan ketat dalam kerangka kompetisi, metrik target dan banyak dukungan dalam hal obrolan Ilmu Data Terbuka. Dan, sebagai bonus jauh, adalah bahwa keputusan Anda akan menjadi proyek yang belum ada di sana.

Mengapa ini sangat menyenangkan? Dari mana emosi positif itu berasal? Idenya adalah bahwa ketika Anda mengirim kiriman dan itu sedikit lebih baik daripada yang sebelumnya, kata mereka - Anda meningkatkan metrik, itu keren. Anda memanjat leaderboard. Sebaliknya, jika Anda tidak melakukan apa pun dan tidak mengirim kiriman, maka Anda turun. Dan itu menyebabkan umpan balik: Anda merasa baik ketika Anda maju, dan sebaliknya. Ini adalah mekanisme keren yang mengeksploitasi, sepertinya, hanya Kaggle. Dan poin lainnya: Kaggle mengeksploitasi mekanisme ketergantungan yang sama seperti mesin slot dan Tinder. Anda tidak tahu apakah kiriman Anda lebih baik atau lebih buruk. Ini menyebabkan ekspektasi hasil yang tidak Anda ketahui. Jadi, Kaggle sangat adiktif, tetapi cukup konstruktif: Anda mengembangkan dan mencoba untuk meningkatkan keputusan Anda.
Bagaimana cara mendapatkan dosis pertama? Anda harus masuk ke bagian kernel. Mereka mengeluarkan beberapa pipa atau seluruh solusi. Pertanyaan terpisah adalah mengapa orang melakukan ini. Seorang pria menghabiskan waktu untuk berkembang - apa gunanya mempublikasikannya di depan umum? Mereka dapat mengambil keuntungan dan memotong penulis.
Idenya adalah bahwa, pertama, solusi terbaik tidak ditata. Biasanya, solusi ini tidak optimal dari sudut pandang model pelatihan, mereka tidak memiliki semua nuansa, tetapi ada pipa keseluruhan dari awal hingga akhir sehingga Anda tidak menyelesaikan tugas rutin yang terkait dengan pemrosesan data, postprocessing, mengirimkan koleksi, dll. Ini menurunkan ambang masuk untuk menarik pendatang baru. Anda perlu memahami bahwa komunitas data Para ilmuwan sangat terbuka untuk diskusi dan, secara umum, cukup positif. Saya belum melihat ini di komunitas ilmiah. Motivasi utama adalah bahwa orang-orang baru datang dengan ide-ide baru. Ini mengembangkan diskusi tentang masalah, persaingan dan memungkinkan seluruh komunitas untuk berkembang.
Jika Anda mengambil keputusan orang lain, meluncurkannya, mulai melatih, maka hal berikutnya yang saya sangat sarankan lakukan adalah melihat ke dalam data. Saran dangkal, tetapi Anda tidak akan percaya berapa banyak orang dari atas yang tidak menggunakannya. Untuk memahami mengapa ini penting, saya menyarankan Anda untuk melihat laporan Eugene Nizhibitsky. Dia berbicara tentang
wajah -
wajah di kompetisi film dan tentang
wajah di Airbus , yang juga bisa dilihat hanya dengan melihat data. Ini tidak memakan banyak waktu dan membantu untuk memahami masalahnya. Dan wajah-wajah dalam gambar adalah tentang fakta bahwa pada platform yang berbeda dan dalam kompetisi yang berbeda dimungkinkan untuk mendapatkan jawaban tes dari kereta. Artinya, Anda tidak dapat melatih model apa pun, tetapi cukup melihat data dan memahami bagaimana Anda dapat mengumpulkan jawaban untuk tes Anda - sebagian atau seluruhnya. Ini adalah kebiasaan yang penting tidak hanya dalam kompetisi, tetapi juga dalam praktik nyata, ketika Anda bekerja dengan para ilmuwan data. Dalam kehidupan nyata, kemungkinan besar, tugas itu akan dirumuskan dengan buruk. Anda tidak merumuskannya, tetapi Anda perlu memahami apa esensi dan esensi datanya. Kebiasaan melihat data sangat penting, menghabiskan waktu di sana.
Selanjutnya Anda perlu memahami apa tugasnya. Jika Anda melihat data dan memahami apa targetnya ... Anda, jika saya mengerti dengan benar, sebagian besar, berasal dari Fiztekh. Anda harus memiliki pemikiran kritis yang menimbulkan pertanyaan: mengapa orang yang merancang kompetisi melakukan segalanya dengan benar? Mengapa tidak mengubah, misalnya, metrik target, mencari sesuatu yang lain, dan mengumpulkan hal-hal yang benar dari metrik baru? Menurut pendapat saya, sekarang ada banyak tutorial dan kode orang lain, membuat prediksi feed tidak menjadi masalah. Untuk melatih model, untuk melatih jaringan saraf adalah tugas yang sangat sederhana, dapat diakses oleh lingkaran orang yang sangat luas. Tetapi penting untuk memahami apa target Anda, apa yang Anda prediksi, dan bagaimana cara menyusun metrik target Anda. Jika Anda memprediksi sesuatu yang tidak relevan dalam realitas objektif, maka model itu sama sekali tidak belajar dan Anda mendapatkan kecepatan yang sangat buruk.
Contohnya. Ada kompetisi yang terjadi di Topcoder Konica-Minolta.

Itu terdiri dari yang berikut: Anda memiliki dua gambar, yang teratas, dan salah satunya memiliki kotoran, titik kecil di sebelah kanan. Itu perlu untuk menyorot dan mengelompokkannya. Tampaknya tugas yang sangat sederhana, dan jaringan saraf harus menyelesaikannya sekaligus. Tetapi masalahnya adalah bahwa ini adalah dua gambar yang diambil baik dengan perbedaan waktu, atau dari kamera yang berbeda. Akibatnya, satu gambar bergerak sedikit relatif ke yang lain. Skala itu benar-benar sangat kecil. Tetapi ada fitur lain dari tugas ini bahwa topeng juga kecil. Ada gambar yang bergerak relatif ke yang lain, sementara topeng masih bergerak relatif terhadap itu. Kira-kira jelas apa kesulitannya.

Aleksey Buslaev di tempat ketiga, ia mengambil jaringan saraf Siam dengan dua input sehingga para kepala Siam ini belajar beberapa transformasi mengenai gambar yang menyimpang ini. Setelah itu, ia menggabungkan fitur-fitur ini, memiliki serangkaian konvolusi, dan ia mendapat semacam prediksi. Untuk meratakan ini dalam data, ia mengumpulkan jaringan yang agak rumit. Misalnya, saya tidak pernah melatih jaringan Siam, saya tidak harus melakukan ini. Dia melakukannya, itu sangat keren, dia mengambil tempat ketiga. Di tempat pertama adalah Evgeny (nrzb.), Yang hanya mengubah ukuran gambar. Dia melihat ini sebagai cant dalam data, karena dia melihat mereka, mengubah ukuran gambar, dan melatih vanilla UNet. Ini adalah jaringan saraf yang sangat sederhana, hanya ada di buku teks, di artikel. Ini menunjukkan bahwa jika Anda melihat data dan memilih target yang benar, Anda bisa berada di atas dengan solusi sederhana.
Saya berakhir di posisi kedua, karena saya berteman dengan Zhenya, setelah itu topcoder tersinggung karena beberapa alasan dan tidak membawa saya ke tim Kaggle. Tapi mereka orang yang sangat keren, Topcoder mengambil tempat 5-6, ini (NRZB.) Dan Victor Durnov. Alexander Buslaev menempati posisi ketiga. Mereka selanjutnya bekerja sama dan menunjukkan kelas dalam kompetisi di Kaggle. Ini juga merupakan contoh dari solusi yang sangat indah, ketika para dudes tidak hanya mengembangkan arsitektur yang mengerikan, tetapi memilih target yang tepat.

Tugas di sini adalah untuk mengelompokkan sel-sel, dan tidak hanya untuk mengatakan di mana sel itu dan di mana tidak, tetapi itu perlu untuk mengisolasi sel-sel individual, seperti segmentasi instage dari masing-masing sel independen. Terlebih lagi, sebelum kompetisi ini ada banyak kompetisi segmentasi, dan diklaim bahwa masalah segmentasi diselesaikan oleh komunitas ODS dengan cukup baik, pada tingkat keahlian, suatu kemajuan ilmu pengetahuan yang memungkinkan kita untuk menyelesaikan masalah ini dengan baik.
Pada saat yang sama, tugas Segmentasi inst, ketika Anda perlu memisahkan sel, diselesaikan dengan sangat buruk. Yang paling canggih sebelum kompetisi ini adalah MacrCNN, yang merupakan jenis detektor, beberapa fitur ekstraktor, kemudian blok yang melakukan segmentasi masker, dan itu semua cukup sulit untuk dilatih, Anda perlu melatih setiap bagian dari pipa secara terpisah, itu adalah seluruh lagu.
Alih-alih, Topcoder mengembangkan pipa ketika Anda hanya memprediksi sel dan batas. Segmentasi pipa dipersulit oleh minor dan memungkinkan Anda melakukan segmentasi yang sangat indah, mengurangi batas dari sel. Setelah itu, mereka meningkatkan standar dalam hal akurasi algoritma ini, sementara jaringan saraf mereka yang terpisah memprediksi sel lebih baik daripada apa pun yang telah dilakukan oleh para akademisi di bidang ini sebelumnya. Ini keren untuk topcoder dan sangat buruk bagi akademisi. Sejauh yang saya tahu, baru-baru ini akademisi mencoba menerbitkan artikel tentang data ini, mereka menolaknya karena mereka tidak bisa mengalahkan hasilnya di Kaggle. Masa sulit telah datang untuk akademisi, sekarang kita perlu melakukan sesuatu yang normal, dan tidak hanya melakukan pekerjaan enkripsi di bidangnya.

Hal berikutnya yang saya sangat tenggelam, tidak hanya di Kaggle, tetapi juga di tempat kerja, adalah pelatihan pipa. Saya tidak melihat banyak nilai dalam membuat arsitektur jaringan saraf yang mengerikan, menghasilkan potongan-potongan keren dengan atenuasi, dengan rangkaian fitur. Semuanya berfungsi, tetapi jauh lebih penting untuk hanya dapat melatih jaringan saraf. Dan tidak ada roket akal, itu adalah hal yang cukup sederhana, mengingat sekarang ada banyak artikel, tutorial, dan sebagainya. Saya melihat banyak nilai dalam kenyataan bahwa Anda baru saja mengikuti pelatihan saluran pipa. Saya memahami ini sebagai kode yang berjalan pada konfigurasi, dan mengajarkan Anda jaringan saraf dengan cara yang terkontrol, dapat diprediksi dan cukup cepat.
Slide ini menunjukkan log pelatihan dari kompetisi yang sedang berlangsung sekarang, Kaggle Salt. Saya masih punya banyak kartu video, ini juga bonus. Idenya adalah bahwa dengan bantuan pipa, saya melakukan pencarian grid arsitektur yang menurut saya paling menarik. Saya baru saja membuat satu konfigurasi peluncuran untuk semua arsitektur, dengan konvensi, sebuah forum di kebun binatang jaringan saraf, berjalan dan melatih semua jaringan saraf tanpa berusaha. Ini adalah bonus yang sangat besar, dan inilah yang saya gunakan kembali dari kompetisi ke kompetisi dan di tempat kerja. Oleh karena itu, saya sangat gelisah tidak hanya untuk melatih jaringan saraf, tetapi juga untuk memikirkan tentang apa yang Anda ajarkan dan apa yang Anda tulis dalam kaitannya dengan pipa, bahwa Anda harus menggunakannya kembali.

Di sini saya menyoroti beberapa hal penting yang harus ada dalam pipa pelatihan. Ini adalah konfigurasi startup yang sepenuhnya mendefinisikan proses pembelajaran. Di mana Anda menentukan semua parameter tentang data, tentang jaringan saraf, tentang kerugian - semuanya harus ada dalam konfigurasi peluncuran. Ini harus dapat dikontrol. Penebangan lebih lanjut. Catatan indah yang saya perlihatkan adalah hasil dari fakta bahwa saya mencatat setiap langkah yang saya ambil.
Modularitas berarti Anda tidak perlu banyak waktu untuk menambahkan jaringan saraf baru, augmentasi baru, dataset baru. Ini semua harus sangat sederhana dan dapat dipelihara.
Reproduksibilitas hanya memperbaiki benih, sementara tidak hanya yang acak di NumPy dan Acak, tetapi masih ada beberapa paiterchiks, saya akan memberi tahu Anda lebih banyak. Dan usabilitas ulang. Setelah Anda mengembangkan saluran pipa, itu dapat digunakan dalam tugas-tugas lain. Dan ini adalah bonus besar, mereka yang mulai berpartisipasi dalam kompetisi lebih awal, dapat terus menggunakan pipa ini dalam kompetisi dan dalam pekerjaan, ini semua memberikan bonus besar kepada peserta lain.
Beberapa orang mungkin bertanya: Saya tidak tahu cara kode, apa yang harus dilakukan, bagaimana mengembangkan pipa? Ada solusinya.

Sergey Kolesnikov adalah kolega saya yang bekerja di Dbrain, ia telah mengembangkan hal semacam itu sejak lama. Awalnya dia memanggilnya PyTorch Common, lalu dia memanggil Prometheus, sekarang disebut Catalist. Kemungkinan besar, dalam seminggu nama akan berbeda, tetapi tautannya akan ke nama berikutnya, ikuti tautan "Catalist".
Idenya adalah bahwa Sergey telah mengembangkan semacam lib, yang merupakan trainloop. Dan itu dalam versi saat ini memiliki hampir semua properti yang saya jelaskan. Masih ada banyak contoh tentang bagaimana melakukan klasifikasi, segmentasi dan banyak hal keren lainnya yang ia kembangkan.
Berikut adalah daftar fitur yang ada, dan sedang dikembangkan. Anda dapat mengambil lib ini dan mulai menggunakannya untuk melatih algoritma Anda, jaringan saraf Anda dalam kompetisi yang saat ini sedang berlangsung. Saya merekomendasikan semua orang untuk melakukannya.
Sebaliknya, ada FastAI lain, yang baru-baru ini dirilis versi 1.0, tetapi ada kode yang menjijikkan dan tidak ada yang jelas.
Anda bisa menguasainya, itu akan memberi Anda beberapa pertumbuhan, tetapi karena fakta bahwa itu ditulis dengan buruk dalam hal kode, mereka memiliki aliran sendiri dalam hal bagaimana seharusnya ditulis. Mulai pada titik tertentu, Anda tidak akan mengerti apa yang terjadi. Karena itu, saya tidak merekomendasikan FastAI, saya sarankan menggunakan "Catalist".

Sekarang seandainya Anda telah melalui semua ini, Anda memiliki saluran pipa sendiri, keputusan Anda sendiri, dan sekarang Anda dapat berpartisipasi dalam tim. Emil baru saja ditanya bagaimana dibenarkan untuk bergabung dengan tim jika Anda berpartisipasi dalam bagaimana ini terjadi. Bagi saya, tampaknya bekerja sama itu sepadan, bahkan jika Anda tidak berada di puncak, tetapi di suatu tempat di tengah. Jika Anda mengembangkan solusi Anda sendiri, maka itu selalu berbeda dari keputusan orang lain dalam beberapa detail. Dan ketika digabungkan, hampir selalu memberi dorongan dengan peserta lain.
Selain itu, sangat menyenangkan, ini adalah kerja tim dalam hal fakta bahwa sekarang Anda akan memiliki repositori bersama di mana Anda dapat melihat kode satu sama lain, Anda memiliki format umum untuk pengiriman dan ruang obrolan tempat semua kesenangan terjadi. Interaksi sosial dan soft skill juga sangat penting dalam pekerjaan, yang juga layak untuk dikembangkan.
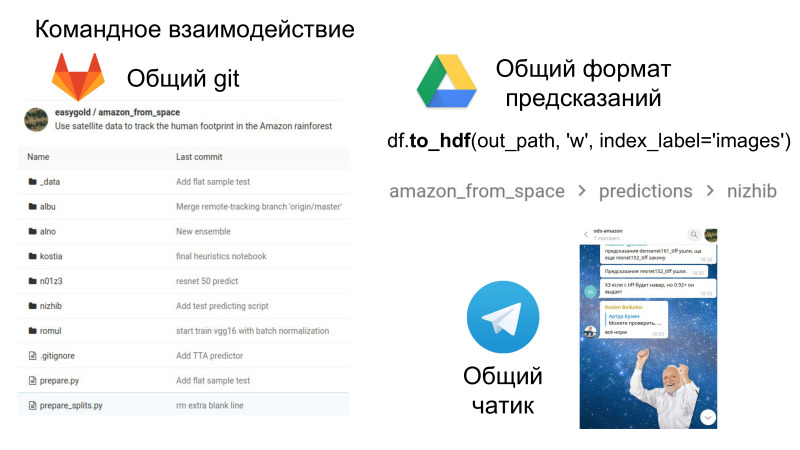
Ini adalah bonus besar dalam arti bahwa sekarang Anda melihat kode orang lain, bagaimana mereka membuat keputusan ini atau itu. Dan cukup sering saya melihat ke repositori dengan perintah saya sebelumnya, menemukan ada solusi keren dalam hal kode itu sendiri. Inilah yang bisa dikeluarkan dari kompetisi dalam bentuk kerja tim.
Misalkan Anda sudah melakukan semua putaran ini. Apa yang sudah kamu alami?

Kemungkinan besar, Anda belajar menjalankan kode orang lain. Saya sangat berharap bahwa Anda telah mengembangkan kebiasaan melihat data. Anda memahami masalahnya, telah belajar melakukan eksperimen, Anda memiliki semacam solusi sendiri, dan sekarang Anda dapat mendesainnya dalam bentuk proyek. Jika Anda melihat secara abstrak, ini sangat mirip dengan pekerjaan normal di beberapa perusahaan IT. Jika Anda mengikuti kompetisi dan menunjukkan hasil yang baik, ini adalah poin kuat dalam resume, setidaknya untuk saya. Di suatu tempat sekitar 20-25 saya diwawancarai ketika saya direkrut di Dbrain. Beberapa kasus batas dapat diidentifikasi di sana. Ada seorang pria yang baru saja menjalankan kernel publik, dan tidak benar-benar mengetahuinya. Terlihat buruk bagi saya, saya hanya ingin pria itu memahami masalahnya, saya tidak menerimanya.
Seorang pria lain yang dengan jujur mengatakan bahwa ia berada di papan peringkat, tetapi pada saat yang sama mengatakan semua detail keputusannya, yang ada di Datascience Bowl, kami mengambilnya, saya benar-benar suka bekerja dengannya. Kaggle dan keputusan Anda ada poin yang cukup kuat dalam resume Anda, jika Anda dapat memformatnya dalam bentuk presentasi dengan benar, ada baiknya untuk menunjukkannya kepada perusahaan yang akan datang.
Jika pertanyaan tentang keuntungan pribadi, saya harap saya tutup, mengapa perusahaan membutuhkan ini?

Saya bekerja di Avito, mereka secara teratur mengadakan kontes analisis data. Ada beberapa alasan untuk ini. Ketika kompetisi diadakan, Anda harus mengumpulkan setidaknya set data, dan merumuskan tugas dengan sangat baik, yang merupakan rasa sakit.

Artinya, pernyataan masalah plus dataset sudah banyak bagi perusahaan. , «» , , , , . — , , .
, , , , . , , . - , , , .
, , — . , . , «» , . «» — , .

, — . , - . , — , . , , , . — importance XGBoost . , , . . , . , . , .
, , - , , , . , , , .

—
Coursera , . —
ML- ODS- . .