
Musim panas ini, kami mengajarkan jaringan saraf untuk menentukan apakah ada dokumen pada gambar, dan jika demikian, yang mana.
Mengapa itu dibutuhkan?
Untuk menurunkan karyawan dan melindungi orang dari penipu. Kami menggunakan jaringan saraf baru di dua area: ketika pengguna mendapatkan kembali akses ke halaman dan untuk menyembunyikan dokumen pribadi dari pencarian umum.
Memulihkan akses ke halaman. Foto dokumen membantu mengembalikan akun ke pemilik sebenarnya. Misalnya, pengguna mungkin kehilangan akses ke nomor teleponnya atau otentikasi dua langkah telah diaktifkan pada halaman, dan tidak ada lagi peluang untuk menerima kode satu kali untuk mengonfirmasi entri. Perkembangan baru mempercepat pertimbangan aplikasi: moderator tidak lagi harus mengembalikan aplikasi yang salah diisi setiap kali. Sistem tidak memungkinkan pengunjung untuk mengirimkan formulir tanpa gambar yang diperlukan dan meminta untuk mengganti gambar acak dengan dokumen. Tentu saja, kami masih dapat mengembalikan akses ke halaman itu sendiri hanya jika memiliki foto asli pemiliknya. Kita berbicara tentang keamanan akun dan pelestarian data pribadi - yang berarti tidak mungkin ada kesalahan dan kecelakaan.
Memfilter hasil pencarian di bagian " Dokumen ". Semua dokumen yang diunggah pengguna ke bagian ini atau kirim melalui pesan pribadi disembunyikan dari mengintip secara default dan tidak termasuk dalam hasil pencarian. Tetapi tingkat privasi dapat dikonfigurasi sendiri secara manual - untuk setiap file individual. Sebelum munculnya jaringan saraf, orang dapat menemukan jumlah dokumen yang layak dengan data sensitif menggunakan kata kunci. Pemilik file-file ini sendiri mengubah pengaturan privasi. Kami mengamankan pengguna dan mulai
menghapus foto
dari pencarian publik di mana kami dapat menentukan keberadaan dokumen.
Bagaimana kami memecahkan masalah
Tampaknya cara termudah untuk mengidentifikasi dokumen dalam suatu gambar adalah dengan membuat jaringan saraf atau melatihnya dari awal dalam sampel besar. Tapi tidak sesederhana itu.
Sampel harus representatif. Sulit untuk menemukan jumlah sampel nyata yang cukup untuk setiap opsi: tidak ada database publik dengan dokumen-dokumen ini dalam domain publik.
Ada banyak sistem yang mengenali dan mem-parsing dokumen. Biasanya mereka ditujukan untuk memperoleh informasi spesifik dari sebuah foto dan menyarankan kualitas gambar asli yang ideal. Misalnya, pengguna mungkin diminta untuk menyelaraskan paspor di sepanjang tepi templat, karena berfungsi di portal Layanan Negara.
Sistem seperti itu tidak cocok untuk tugas kita. Kami secara terpisah mengklarifikasi bahwa ketika menghubungi kami untuk memulihkan akses, pengguna
dapat menutup semua data pada dokumen, kecuali untuk foto, nama depan, nama belakang dan cetak. Pada saat yang sama, kita masih perlu menentukan dokumen - bahkan jika seri dan nomor disembunyikan di atasnya, jika paspor diambil dengan lingkungan sekitar, atau, sebaliknya, hanya sebagian dokumen dengan foto yang muncul pada gambar. Masih perlu mempertimbangkan pencahayaan dan sudut yang berbeda. Jaringan saraf harus menerima semua bahan tersebut. Pertanyaannya adalah bagaimana cara mengajarinya.

Ada kesulitan lain. Misalnya, sulit untuk memisahkan paspor dari jenis dokumen lain, serta dari berbagai tulisan tangan dan kertas cetak.
Berusaha menempuh jalan yang mudah ternyata tidak terlalu berhasil. Pengklasifikasi yang dihasilkan ternyata lemah, dengan kesalahan kecil dari jenis pertama dan kesalahan besar yang kedua. Sebagai contoh, ada kasus-kasus menarik ketika seseorang menulis nama dan nama keluarga dengan tangan, menggambar foto, sampul paspor - dan sistem dengan senang hati menerima dokumen ini.
Kita telah sampai pada apa
Dalam situasi kami, solusi terbaik untuk masalah ini adalah dengan menggunakan ensemble grid dan face detector untuk mengenali dokumen dan menentukan jenisnya. Kami juga menambahkan classifier diferensial, yang mencakup encoder untuk menyoroti fitur karakteristik, dan classifier bentuk yang memungkinkan Anda untuk membedakan gambar dokumen dari file yang tidak relevan. Selain itu, pengelompokan awal dari set pelatihan dilakukan untuk menormalkan dataset. Dari arsitektur,
VGG dan
ResNet telah membuktikan yang
terbaik .
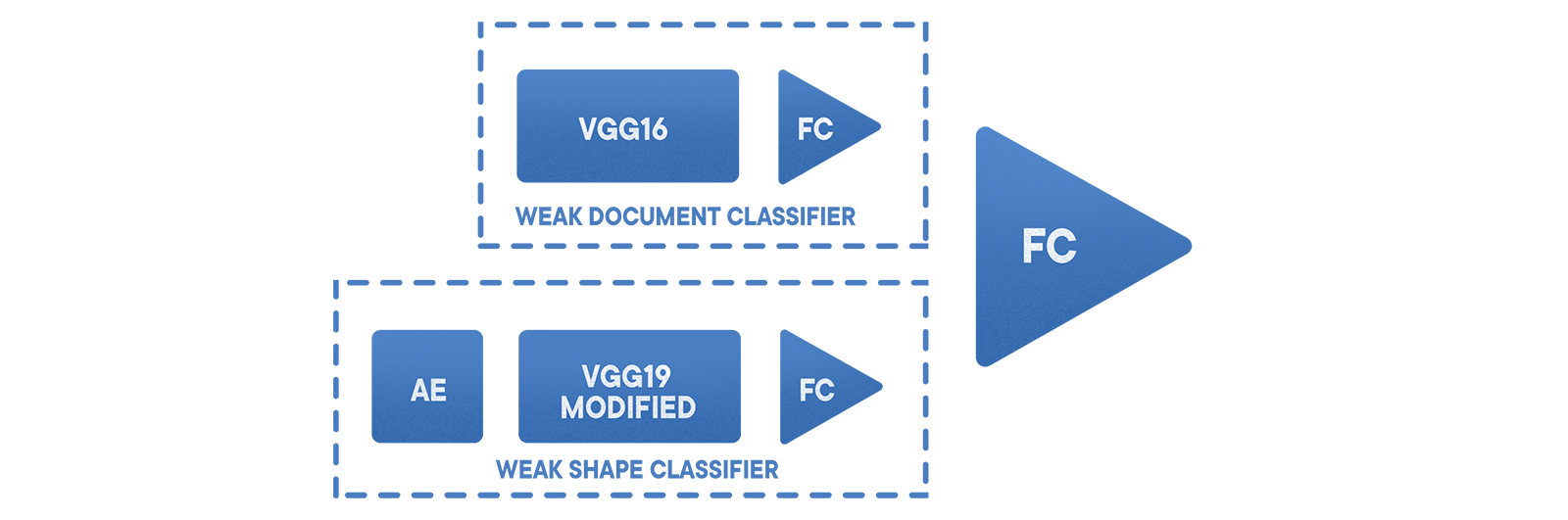
Klasifikasi dasar "dokumen / non-dokumen" bekerja berdasarkan VGG yang disetel dengan 19 lapisan dan sampel yang dikategorikan. Di atasnya, sebuah ensemble gabungan dari pengklasifikasi digunakan, yang mengurangi kesalahan jenis kedua dan membedakan hasilnya. Pertama datang
stratified sampling , kemudian encoder untuk mengekstrak informasi near-loop, kemudian VGG yang dimodifikasi dan akhirnya satu grid. Pendekatan ini memungkinkan untuk meminimalkan kesalahan dari jenis pertama ke level sekitar 0,002. Probabilitas false negative dalam hal ini tergantung pada dataset yang dipilih dan aplikasi spesifik.
Sekarang kami telah belajar bagaimana mendeteksi secara otomatis keberadaan paspor dan SIM di gambar. Pengakuan berhasil terjadi di sudut mana saja, dengan latar belakang apa pun, bahkan dalam kondisi pencahayaan yang buruk - hal utama adalah gambar tersebut berisi bagian dokumen dengan foto dan nama. Namun, untuk mengidentifikasi jenis dokumen lainnya, hanya set data yang relevan akan diperlukan. Kami melatih jaringan pada data kami sendiri, ukuran sampel dokumen adalah dari lima hingga sepuluh ribu (tetapi tidak representatif). Untuk gambar lain, sampelnya acak, tetapi ada pengelompokan apriori baik di sana maupun di sana.
Dari sudut pandang teknis, sistem ini ditulis dengan python /
keras /
tensorflow /
glib /
opencv . Untuk aplikasi praktis dari sistem baru, itu sudah cukup untuk mengintegrasikannya ke dalam python-handler infrastruktur pembelajaran mesin. Pada tahap yang sama, detektor perubahan foto dalam editor grafis ditambahkan, tetapi topik ini layak mendapatkan artikel terpisah.
Apa hasilnya
Sekarang 6% aplikasi untuk restorasi akses secara otomatis dikembalikan ke penulis dengan permintaan untuk menambah atau mengganti foto dokumen, dan 2,5% aplikasi ditolak. Jika Anda melihat analisis gambar secara keseluruhan, termasuk heuristik dan pencarian wajah dalam gambar, itu
mengotomatiskan hingga 20% dari pekerjaan departemen .
Setelah peluncuran jaringan saraf, kami juga dapat menghitung jumlah paspor yang diunggah ke bagian "Dokumen". Ternyata dalam hasil pencarian umum setiap hari ada sekitar dua ribu kartu identitas. Sekarang probabilitas bahwa mereka akan jatuh ke tangan asing adalah minimal.
Jaringan saraf sudah membantu kami memerangi spam dan segala macam penipuan. Kami tidak menghentikan percobaan dan terus membicarakannya di blog kami.