Baru-baru ini, saya harus menyelesaikan tugas pelatihan sepele lainnya dari guru saya. Namun, menyelesaikannya, saya berhasil menarik perhatian pada hal-hal yang sebelumnya tidak saya pikirkan, mungkin Anda juga tidak memikirkannya. Artikel ini akan lebih bermanfaat bagi siswa dan semua orang yang memulai perjalanan mereka ke dunia pemrograman paralel menggunakan MPI.

"Diberikan:"
Jadi, esensi dari tugas komputasi kami adalah membandingkan berapa kali suatu program yang menggunakan transfer point-to-point yang tertunda lebih cepat daripada yang menggunakan transfer point-to-point blocking. Kami akan melakukan pengukuran untuk input array dimensi 64, 256, 1024, 4096, 8192, 16384, 65536, 262144, 1048576, 4194304, 16777216, 16777216, 33554432 elemen. Secara default, diusulkan untuk menyelesaikannya dengan empat proses. Dan di sini, pada kenyataannya, adalah apa yang akan kita pertimbangkan:
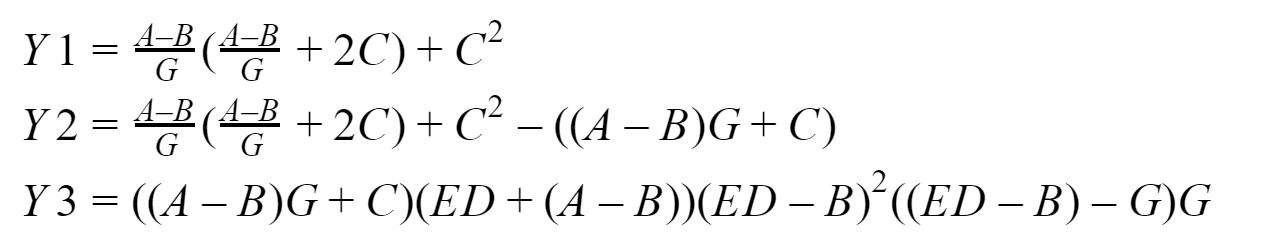
Pada output, kita harus mendapatkan tiga vektor: Y1, Y2 dan Y3, yang proses nol akan kumpulkan. Saya akan menguji semua ini pada sistem saya berdasarkan pada
prosesor Intel dengan 16 GB RAM. Untuk mengembangkan program, kami akan menggunakan implementasi standar
MPI dari Microsoft versi 9.0.1 (pada saat penulisan, ini relevan), Visual Studio Community 2017 dan bukan Fortran.
Materiel
Saya tidak ingin menjelaskan secara rinci bagaimana fungsi MPI yang akan digunakan bekerja, Anda selalu dapat pergi dan
melihat dokumentasi untuk ini , jadi saya hanya akan memberikan gambaran singkat tentang apa yang akan kita gunakan.
Memblokir pertukaran
Untuk memblokir pengiriman pesan titik-ke-titik, kami akan menggunakan fungsi-fungsi:MPI_Send - mengimplementasikan pemblokiran pengiriman pesan, mis. setelah memanggil fungsi, proses diblokir sampai data yang dikirim ke dalamnya ditulis dari memorinya ke buffer sistem internal MPI, setelah itu proses terus bekerja lebih jauh;
MPI_Recv - melakukan pemblokiran penerimaan pesan, mis. Setelah memanggil fungsi, proses diblokir sampai data dari proses pengiriman tiba dan sampai data ini sepenuhnya ditulis ke buffer proses penerimaan oleh lingkungan MPI.
Pertukaran non-blocking yang ditangguhkan
Untuk pengiriman pesan titik-ke-titik yang ditangguhkan, kami akan menggunakan fungsi-fungsi ini:MPI_Send_init - di latar belakang menyiapkan lingkungan untuk mengirim data yang akan terjadi di masa depan dan tidak ada kunci;
MPI_Recv_init - fungsi ini bekerja mirip dengan yang sebelumnya, hanya kali ini untuk menerima data;
MPI_Start - memulai proses penerimaan atau pengiriman pesan, ini juga berjalan di latar belakang a.k.a. tanpa menghalangi;
MPI_Wait - digunakan untuk memeriksa dan, jika perlu, menunggu penyelesaian pengiriman atau penerimaan pesan, tetapi hanya memblokir proses jika perlu (jika data "tidak terkirim" atau "tidak diterima"). Misalnya, suatu proses ingin menggunakan data yang belum mencapainya - tidak baik, oleh karena itu, masukkan MPI_Tunggu di depan tempat yang membutuhkan data ini (masukkan meskipun ada risiko korupsi data). Contoh lain, proses memulai transfer data latar belakang, dan setelah memulai transfer data, ia segera mulai mengubah data ini entah bagaimana - tidak baik, jadi kami menyisipkan MPI_Wait di depan tempat dalam program di mana ia mulai mengubah data ini (di sini kami juga memasukkannya meskipun hanya ada risiko korupsi data).
Dengan demikian, secara
semantik urutan panggilan dengan pertukaran non-pemblokiran yang ditangguhkan adalah sebagai berikut:
- MPI_Send_init / MPI_Recv_init - mempersiapkan lingkungan untuk menerima atau mentransmisikan
- MPI_Start - mulai proses penerimaan / transmisi
- MPI_Wait - kami menyebut beresiko kerusakan (termasuk "undersending" dan "underreporting") dari data yang dikirim atau diterima
Saya juga menggunakan
MPI_Startall ,
MPI_Waitall dalam program pengujian saya, artinya pada dasarnya sama dengan MPI_Start dan MPI_Wait, masing-masing, hanya beroperasi pada beberapa paket dan / atau transmisi. Tapi ini bukan daftar seluruh fungsi mulai dan menunggu, ada beberapa fungsi lagi untuk memeriksa kelengkapan operasi.
Arsitektur antar proses
Untuk kejelasan, kami membuat grafik untuk melakukan perhitungan dengan empat proses. Pada saat yang sama, seseorang harus mencoba untuk mendistribusikan semua operasi aritmatika vektor relatif merata selama proses. Inilah yang saya dapatkan:
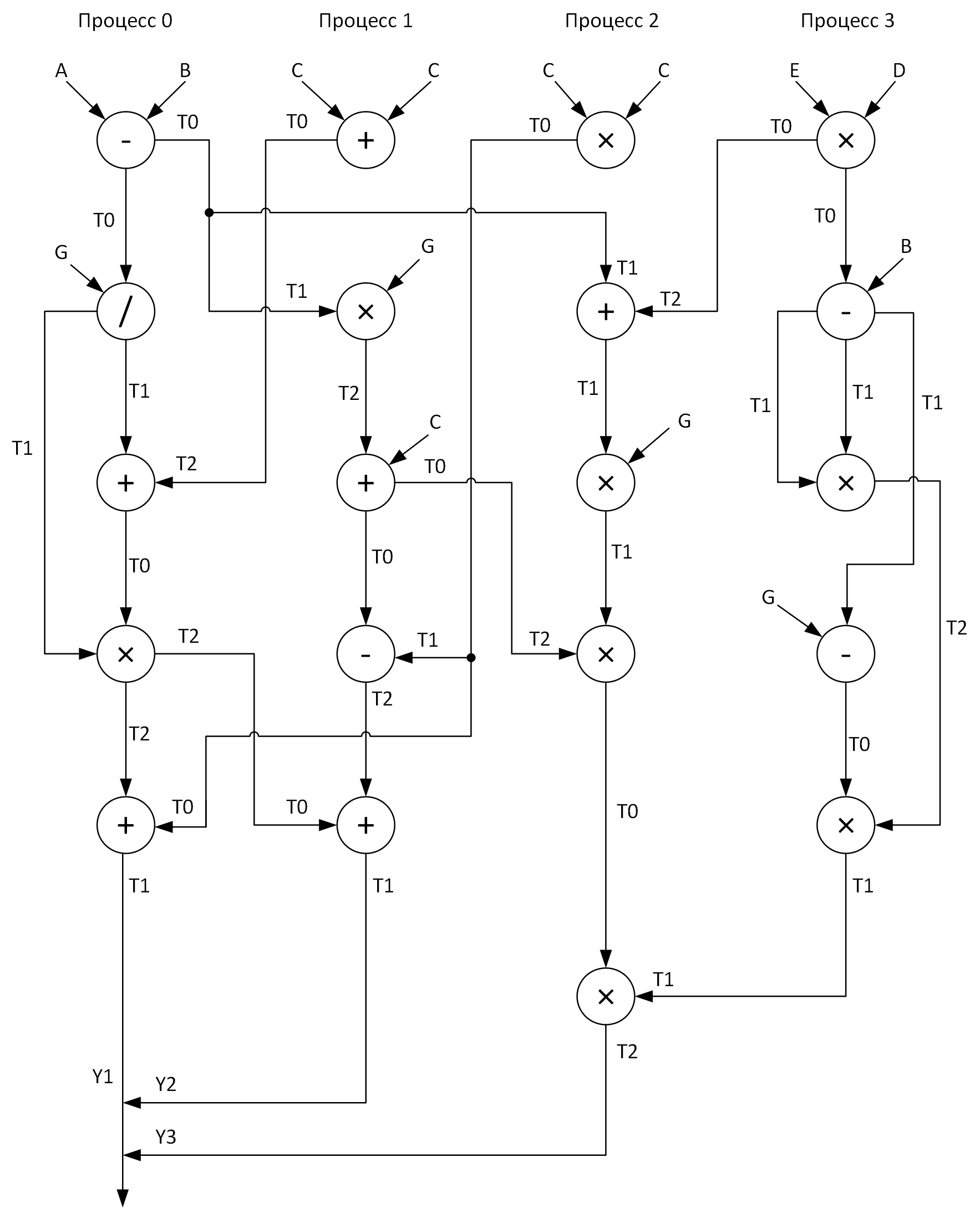
Lihat array ini T0-T2? Ini adalah buffer untuk menyimpan hasil operasi menengah. Juga, pada grafik saat mengirim pesan dari satu proses ke proses lainnya, di awal panah adalah nama array yang datanya ditransmisikan, dan di ujung panah adalah array yang menerima data ini.
Nah, kapan kita akhirnya menjawab pertanyaan:
- Masalah apa yang kita selesaikan?
- Alat apa yang akan kita gunakan untuk menyelesaikannya?
- Bagaimana kita akan menyelesaikannya?
Tetap hanya untuk menyelesaikannya ...
"Solusi:" kami
Selanjutnya, saya akan mempresentasikan kode-kode dari dua program yang dibahas di atas, tetapi untuk permulaan saya akan memberikan beberapa penjelasan lebih lanjut tentang apa dan bagaimana.
Saya mengambil semua operasi aritmatika vektor dalam prosedur terpisah (tambahkan, sub, mul, div) untuk meningkatkan keterbacaan kode. Semua array input diinisialisasi sesuai dengan rumus yang saya sebutkan
hampir secara acak. Karena proses nol mengumpulkan hasil kerja dari semua proses lain, maka, itu bekerja paling lama, oleh karena itu logis untuk mempertimbangkan waktu kerjanya sama dengan runtime program (seperti yang kita ingat, kita tertarik pada: aritmatika + pesan) dalam kasus pertama dan kedua. Kami akan mengukur interval waktu menggunakan fungsi
MPI_Wtime, dan pada saat yang sama saya memutuskan untuk menampilkan resolusi jam tangan apa yang saya miliki di sana menggunakan
MPI_Wtick (di suatu tempat di jiwa saya, saya berharap mereka cocok dengan TSC saya yang invarian, dalam hal ini, saya bahkan siap memaafkan kesalahan mereka. terkait dengan waktu fungsi itu disebut MPI_Wtime). Jadi, kita akan mengumpulkan semua yang saya tulis di atas dan sesuai dengan grafik kita akhirnya akan mengembangkan program-program ini (dan tentu saja debug juga).
Siapa yang peduli melihat kode:
Program dengan memblokir transfer data#include "pch.h" #include <iostream> #include <iomanip> #include <fstream> #include <mpi.h> using namespace std; void add(double *A, double *B, double *C, int n); void sub(double *A, double *B, double *C, int n); void mul(double *A, double *B, double *C, int n); void div(double *A, double *B, double *C, int n); int main(int argc, char **argv) { if (argc < 2) { return 1; } int n = atoi(argv[1]); int rank; double start_time, end_time; MPI_Status status; double *A = new double[n]; double *B = new double[n]; double *C = new double[n]; double *D = new double[n]; double *E = new double[n]; double *G = new double[n]; double *T0 = new double[n]; double *T1 = new double[n]; double *T2 = new double[n]; for (int i = 0; i < n; i++) { A[i] = double (2 * i + 1); B[i] = double(2 * i); C[i] = double(0.003 * (i + 1)); D[i] = A[i] * 0.001; E[i] = B[i]; G[i] = C[i]; } cout.setf(ios::fixed); cout << fixed << setprecision(9); MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); if (rank == 0) { start_time = MPI_Wtime(); sub(A, B, T0, n); MPI_Send(T0, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD); MPI_Send(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD); div(T0, G, T1, n); MPI_Recv(T2, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &status); add(T1, T2, T0, n); mul(T0, T1, T2, n); MPI_Recv(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &status); MPI_Send(T2, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD); add(T0, T2, T1, n); MPI_Recv(T0, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &status); MPI_Recv(T2, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &status); end_time = MPI_Wtime(); cout << "Clock resolution: " << MPI_Wtick() << " secs" << endl; cout << "Thread " << rank << " execution time: " << end_time - start_time << endl; } if (rank == 1) { add(C, C, T0, n); MPI_Recv(T1, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &status); MPI_Send(T0, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD); mul(T1, G, T2, n); add(T2, C, T0, n); MPI_Recv(T1, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &status); MPI_Send(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD); sub(T1, T0, T2, n); MPI_Recv(T0, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &status); add(T0, T2, T1, n); MPI_Send(T1, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD); } if (rank == 2) { mul(C, C, T0, n); MPI_Recv(T1, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &status); MPI_Recv(T2, n, MPI_DOUBLE, 3, 0, MPI_COMM_WORLD, &status); MPI_Send(T0, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD); MPI_Send(T0, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD); add(T1, T2, T0, n); mul(T0, G, T1, n); MPI_Recv(T2, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &status); mul(T1, T2, T0, n); MPI_Recv(T1, n, MPI_DOUBLE, 3, 0, MPI_COMM_WORLD, &status); mul(T0, T1, T2, n); MPI_Send(T2, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD); } if (rank == 3) { mul(E, D, T0, n); MPI_Send(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD); sub(T0, B, T1, n); mul(T1, T1, T2, n); sub(T1, G, T0, n); mul(T0, T2, T1, n); MPI_Send(T1, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD); } MPI_Finalize(); delete[] A; delete[] B; delete[] C; delete[] D; delete[] E; delete[] G; delete[] T0; delete[] T1; delete[] T2; return 0; } void add(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] + B[i]; } } void sub(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] - B[i]; } } void mul(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] * B[i]; } } void div(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] / B[i]; } }
Program dengan transfer data non-pemblokiran yang ditangguhkan #include "pch.h" #include <iostream> #include <iomanip> #include <fstream> #include <mpi.h> using namespace std; void add(double *A, double *B, double *C, int n); void sub(double *A, double *B, double *C, int n); void mul(double *A, double *B, double *C, int n); void div(double *A, double *B, double *C, int n); int main(int argc, char **argv) { if (argc < 2) { return 1; } int n = atoi(argv[1]); int rank; double start_time, end_time; MPI_Request request[7]; MPI_Status statuses[4]; double *A = new double[n]; double *B = new double[n]; double *C = new double[n]; double *D = new double[n]; double *E = new double[n]; double *G = new double[n]; double *T0 = new double[n]; double *T1 = new double[n]; double *T2 = new double[n]; for (int i = 0; i < n; i++) { A[i] = double(2 * i + 1); B[i] = double(2 * i); C[i] = double(0.003 * (i + 1)); D[i] = A[i] * 0.001; E[i] = B[i]; G[i] = C[i]; } cout.setf(ios::fixed); cout << fixed << setprecision(9); MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); if (rank == 0) { start_time = MPI_Wtime(); MPI_Send_init(T0, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &request[0]);// MPI_Send_init(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[1]);// MPI_Recv_init(T2, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &request[2]);// MPI_Recv_init(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[3]);// MPI_Send_init(T2, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &request[4]);// MPI_Recv_init(T0, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &request[5]);// MPI_Recv_init(T2, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[6]);// MPI_Start(&request[2]); sub(A, B, T0, n); MPI_Startall(2, &request[0]); div(T0, G, T1, n); MPI_Waitall(3, &request[0], statuses); add(T1, T2, T0, n); mul(T0, T1, T2, n); MPI_Startall(2, &request[3]); MPI_Wait(&request[3], &statuses[0]); add(T0, T2, T1, n); MPI_Startall(2, &request[5]); MPI_Wait(&request[4], &statuses[0]); MPI_Waitall(2, &request[5], statuses); end_time = MPI_Wtime(); cout << "Clock resolution: " << MPI_Wtick() << " secs" << endl; cout << "Thread " << rank << " execution time: " << end_time - start_time << endl; } if (rank == 1) { MPI_Recv_init(T1, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[0]);// MPI_Send_init(T0, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[1]);// MPI_Recv_init(T1, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[2]);// MPI_Send_init(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[3]);// MPI_Recv_init(T0, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[4]);// MPI_Send_init(T1, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[5]);// MPI_Start(&request[0]); add(C, C, T0, n); MPI_Start(&request[1]); MPI_Wait(&request[0], &statuses[0]); mul(T1, G, T2, n); MPI_Start(&request[2]); MPI_Wait(&request[1], &statuses[0]); add(T2, C, T0, n); MPI_Start(&request[3]); MPI_Wait(&request[2], &statuses[0]); sub(T1, T0, T2, n); MPI_Wait(&request[3], &statuses[0]); MPI_Start(&request[4]); MPI_Wait(&request[4], &statuses[0]); add(T0, T2, T1, n); MPI_Start(&request[5]); MPI_Wait(&request[5], &statuses[0]); } if (rank == 2) { MPI_Recv_init(T1, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[0]);// MPI_Recv_init(T2, n, MPI_DOUBLE, 3, 0, MPI_COMM_WORLD, &request[1]);// MPI_Send_init(T0, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &request[2]);// MPI_Send_init(T0, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[3]);// MPI_Recv_init(T2, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &request[4]);// MPI_Recv_init(T1, n, MPI_DOUBLE, 3, 0, MPI_COMM_WORLD, &request[5]);// MPI_Send_init(T2, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[6]);// MPI_Startall(2, &request[0]); mul(C, C, T0, n); MPI_Startall(2, &request[2]); MPI_Waitall(4, &request[0], statuses); add(T1, T2, T0, n); MPI_Start(&request[4]); mul(T0, G, T1, n); MPI_Wait(&request[4], &statuses[0]); mul(T1, T2, T0, n); MPI_Start(&request[5]); MPI_Wait(&request[5], &statuses[0]); mul(T0, T1, T2, n); MPI_Start(&request[6]); MPI_Wait(&request[6], &statuses[0]); } if (rank == 3) { MPI_Send_init(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[0]); MPI_Send_init(T1, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[1]); mul(E, D, T0, n); MPI_Start(&request[0]); sub(T0, B, T1, n); mul(T1, T1, T2, n); MPI_Wait(&request[0], &statuses[0]); sub(T1, G, T0, n); mul(T0, T2, T1, n); MPI_Start(&request[1]); MPI_Wait(&request[1], &statuses[0]); } MPI_Finalize(); delete[] A; delete[] B; delete[] C; delete[] D; delete[] E; delete[] G; delete[] T0; delete[] T1; delete[] T2; return 0; } void add(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] + B[i]; } } void sub(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] - B[i]; } } void mul(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] * B[i]; } } void div(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] / B[i]; } }
Pengujian dan analisis
Mari kita jalankan program kami untuk array dengan ukuran berbeda dan lihat apa yang terjadi. Hasil pengujian dirangkum dalam tabel, di kolom terakhir yang kami hitung dan tulis koefisien percepatannya, yang kami definisikan sebagai berikut: K
accele = T
ex. non-blok. / T
blok.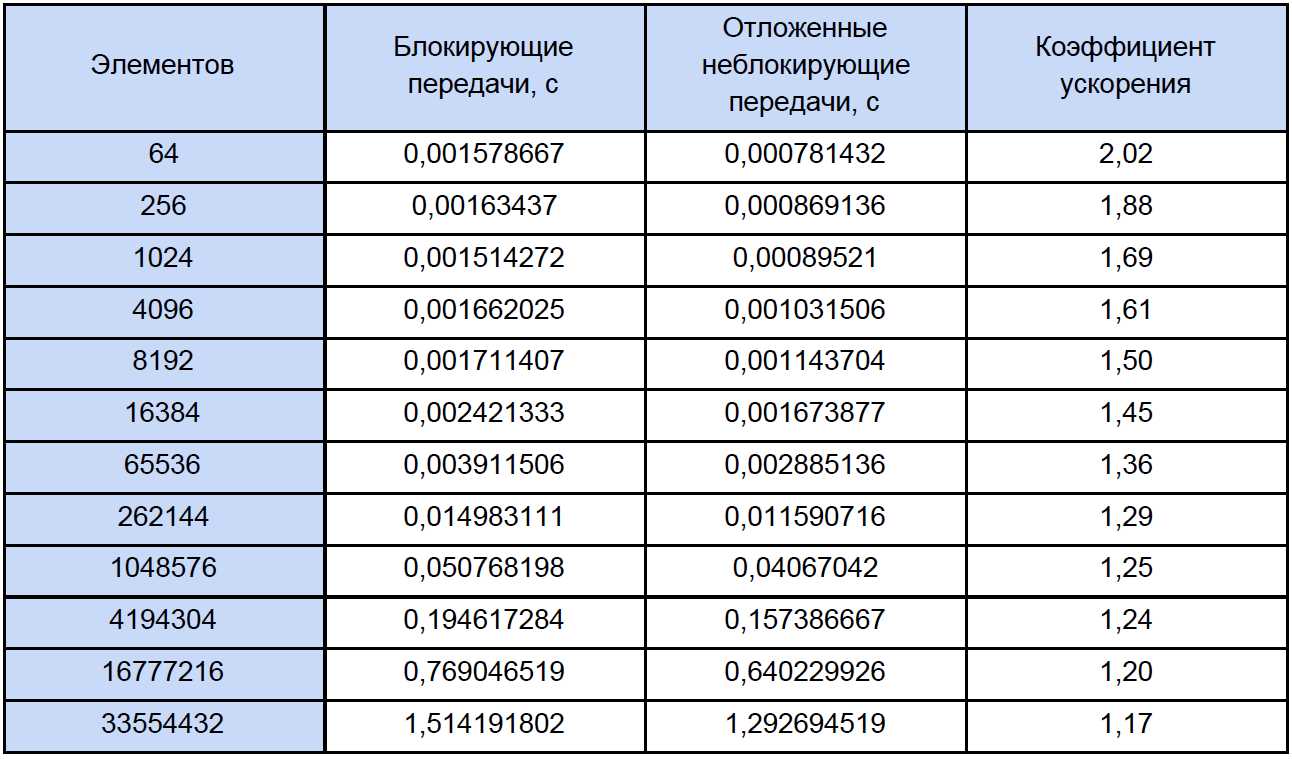
Jika Anda melihat tabel ini sedikit lebih hati-hati dari biasanya, Anda akan melihat bahwa dengan peningkatan jumlah elemen yang diproses, koefisien percepatan menurun entah bagaimana seperti ini:

Mari kita coba menentukan apa masalahnya? Untuk melakukan ini, saya mengusulkan untuk menulis program uji kecil yang akan mengukur waktu setiap operasi aritmatika vektor dan dengan hati-hati mengurangi hasilnya menjadi file teks biasa.
Di sini, pada kenyataannya, program itu sendiri:
Pengukuran waktu #include "pch.h" #include <iostream> #include <iomanip> #include <Windows.h> #include <fstream> using namespace std; void add(double *A, double *B, double *C, int n); void sub(double *A, double *B, double *C, int n); void mul(double *A, double *B, double *C, int n); void div(double *A, double *B, double *C, int n); int main() { struct res { double add; double sub; double mul; double div; }; int i, j, k, n, loop; LARGE_INTEGER start_time, end_time, freq; ofstream fout("test_measuring.txt"); int N[12] = { 64, 256, 1024, 4096, 8192, 16384, 65536, 262144, 1048576, 4194304, 16777216, 33554432 }; SetConsoleOutputCP(1251); cout << " loop: "; cin >> loop; fout << setiosflags(ios::fixed) << setiosflags(ios::right) << setprecision(9); fout << " : " << loop << endl; fout << setw(10) << "\n " << setw(30) << ". (c)" << setw(30) << ". (c)" << setw(30) << ". (c)" << setw(30) << ". (c)" << endl; QueryPerformanceFrequency(&freq); cout << "\n : " << freq.QuadPart << " " << endl; for (k = 0; k < sizeof(N) / sizeof(int); k++) { res output = {}; n = N[k]; double *A = new double[n]; double *B = new double[n]; double *C = new double[n]; for (i = 0; i < n; i++) { A[i] = 2.0 * i; B[i] = 2.0 * i + 1; C[i] = 0; } for (j = 0; j < loop; j++) { QueryPerformanceCounter(&start_time); add(A, B, C, n); QueryPerformanceCounter(&end_time); output.add += double(end_time.QuadPart - start_time.QuadPart) / double(freq.QuadPart); QueryPerformanceCounter(&start_time); sub(A, B, C, n); QueryPerformanceCounter(&end_time); output.sub += double(end_time.QuadPart - start_time.QuadPart) / double(freq.QuadPart); QueryPerformanceCounter(&start_time); mul(A, B, C, n); QueryPerformanceCounter(&end_time); output.mul += double(end_time.QuadPart - start_time.QuadPart) / double(freq.QuadPart); QueryPerformanceCounter(&start_time); div(A, B, C, n); QueryPerformanceCounter(&end_time); output.div += double(end_time.QuadPart - start_time.QuadPart) / double(freq.QuadPart); } fout << setw(10) << n << setw(30) << output.add / loop << setw(30) << output.sub / loop << setw(30) << output.mul / loop << setw(30) << output.div / loop << endl; delete[] A; delete[] B; delete[] C; } fout.close(); cout << endl; system("pause"); return 0; } void add(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] + B[i]; } } void sub(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] - B[i]; } } void mul(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] * B[i]; } } void div(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] / B[i]; } }
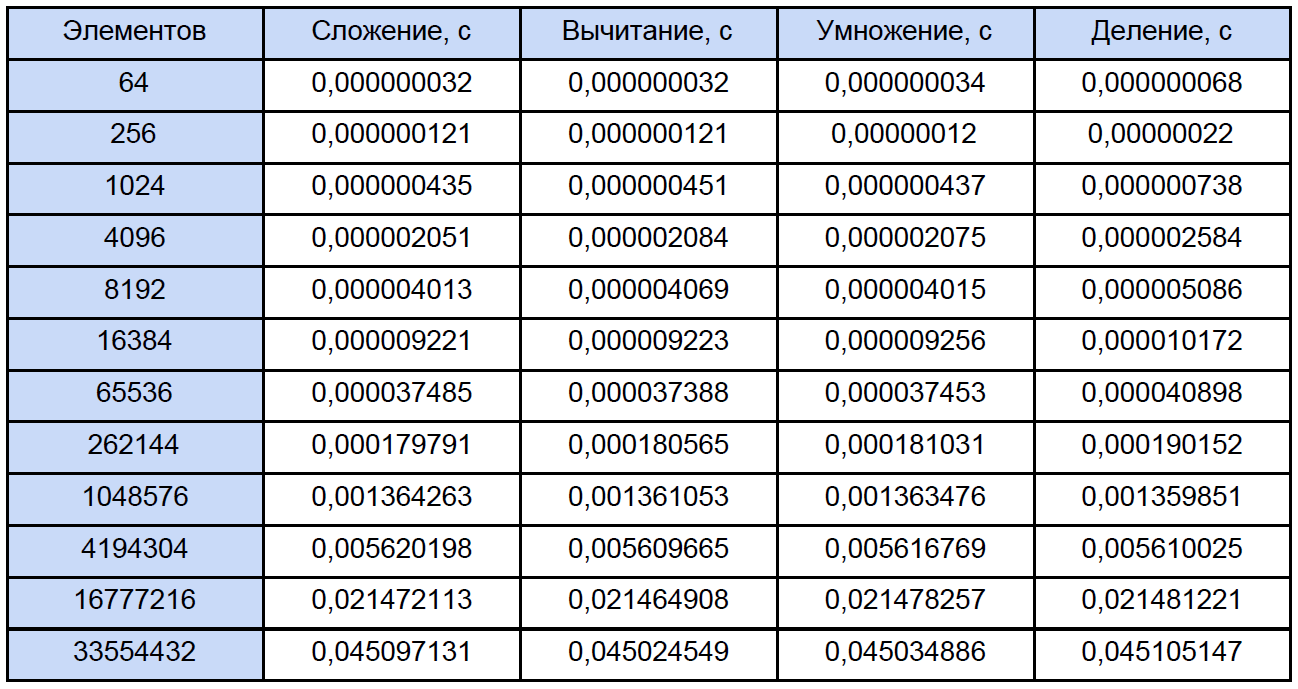
Saat startup, ia meminta Anda untuk memasukkan jumlah siklus pengukuran, saya menguji 10.000 siklus. Pada output, kami memperoleh hasil rata-rata untuk setiap operasi:
Untuk mengukur waktu, saya menggunakan
QueryPerformanceCounter tingkat tinggi. Saya sangat menyarankan membaca
FAQ ini sehingga sebagian besar pertanyaan tentang mengukur waktu dengan fungsi ini akan hilang sendiri. Menurut pengamatan saya, itu melekat pada TSC (tetapi secara teoritis mungkin bukan untuk itu), tetapi mengembalikan, menurut bantuan, jumlah kutu saat ini dari kutu. Tetapi kenyataannya adalah bahwa penghitung saya secara fisik tidak dapat mengukur interval waktu 32 ns (lihat baris pertama dari tabel hasil). Hasil ini disebabkan oleh fakta bahwa antara dua panggilan dari QueryPerformanceCounter 0 ticks atau 1 ticks pass. Untuk baris pertama dalam tabel, kita hanya dapat menyimpulkan bahwa sekitar sepertiga dari 10.000 hasil adalah 1 tick.
Jadi data dalam tabel ini untuk 64, 256 dan bahkan untuk 1024 elemen adalah sesuatu yang cukup mendekati. Sekarang, mari kita buka salah satu program dan hitung berapa banyak total operasi dari setiap jenis yang dihadapinya, secara tradisional kita akan “menyebar” semuanya sesuai dengan tabel berikut:
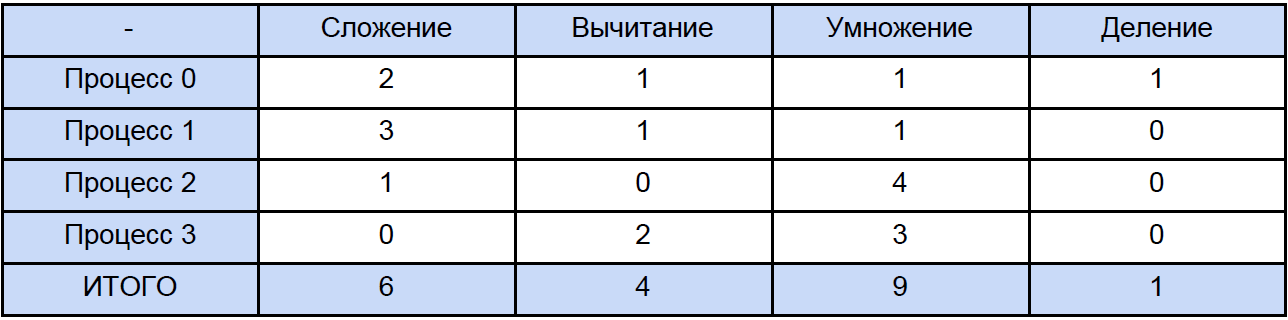
Akhirnya, kita tahu waktu setiap operasi aritmatika vektor dan berapa banyak yang ada dalam program kami, cobalah untuk mencari tahu berapa banyak waktu yang dihabiskan untuk operasi ini dalam program paralel dan berapa banyak waktu yang dihabiskan untuk memblokir dan menunda pertukaran data non-blocking antara proses dan sekali lagi, untuk kejelasan, kami akan mengurangi ini menjadi meja:
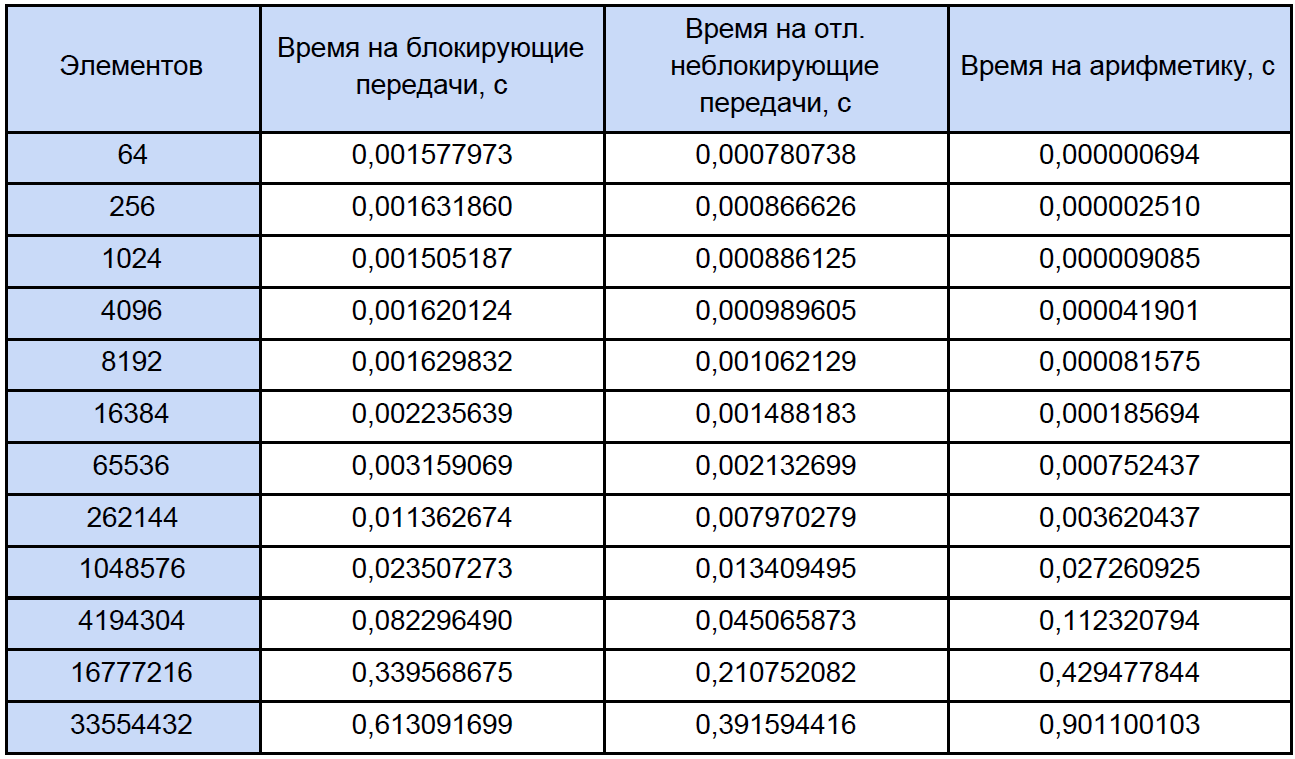
Berdasarkan hasil data yang diperoleh, kami membuat grafik tiga fungsi: yang pertama menjelaskan perubahan waktu yang dihabiskan untuk memblokir transfer antar proses, dari jumlah elemen array, yang kedua menjelaskan perubahan waktu yang dihabiskan untuk transfer non-blocking yang ditangguhkan antar proses, pada jumlah elemen array dan yang ketiga menjelaskan perubahan waktu, dihabiskan untuk operasi aritmatika, dari sejumlah elemen array:
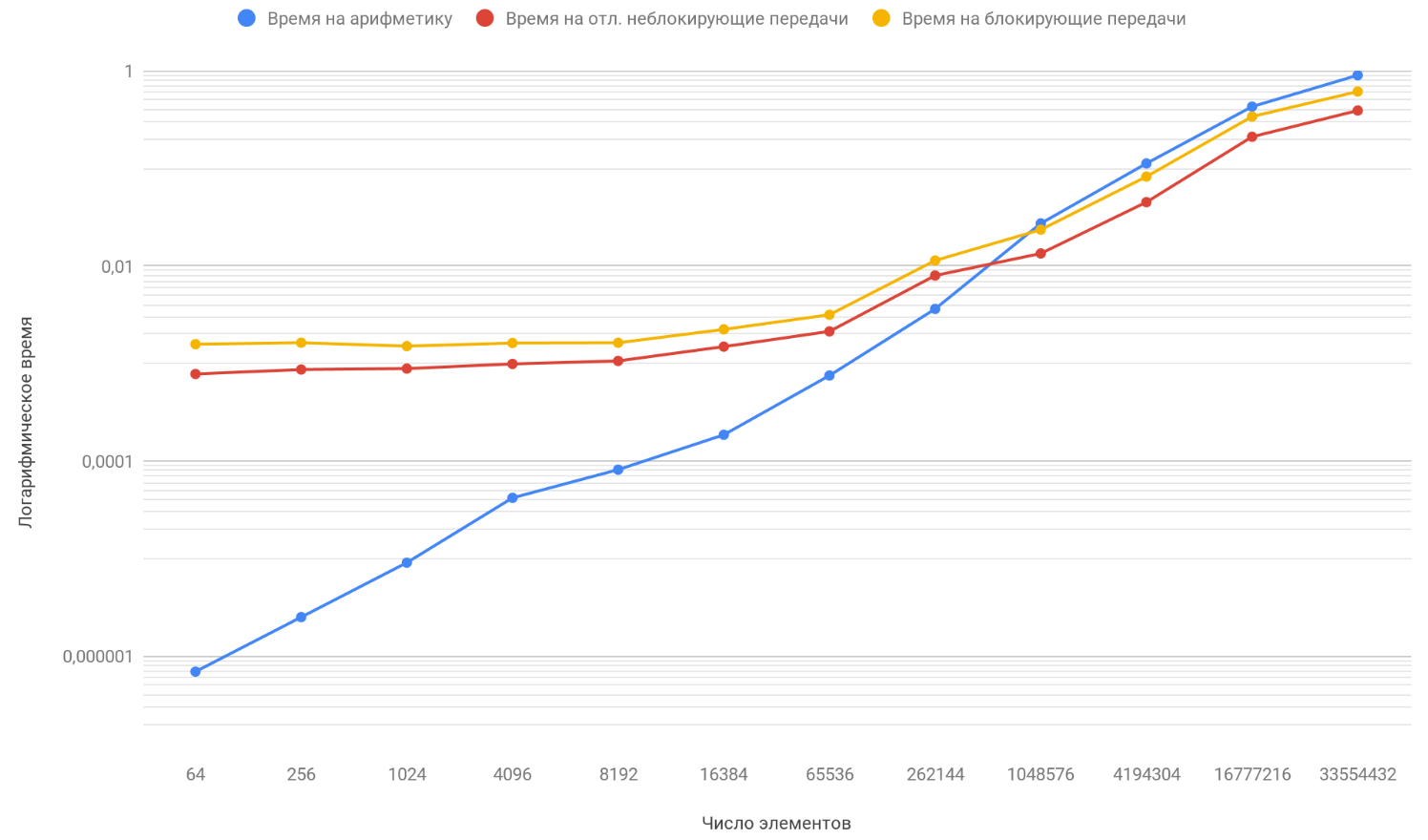
Seperti yang telah Anda perhatikan, skala vertikal grafik adalah logaritmik, karena itu adalah ukuran yang perlu, karena penyebaran waktu terlalu besar dan pada grafik biasa tidak ada yang terlihat. Perhatikan fungsi ketergantungan waktu yang dihabiskan untuk aritmatika pada jumlah elemen, itu dengan aman menyalip dua fungsi lainnya oleh sekitar 1 juta elemen. Masalahnya adalah ia tumbuh lebih cepat daripada dua lawannya. Oleh karena itu, dengan peningkatan jumlah elemen yang diproses, runtime program lebih banyak ditentukan oleh aritmatika daripada transfer. Misalkan Anda meningkatkan jumlah transfer antar proses, secara konseptual Anda hanya akan melihat bahwa saat ketika fungsi aritmatika menyusul dua lainnya akan terjadi kemudian.
Ringkasan
Dengan demikian, terus meningkatkan panjang array, Anda akan sampai pada kesimpulan bahwa program dengan transfer non-blocking yang ditangguhkan hanya akan sedikit lebih cepat daripada yang menggunakan blocking exchange. Dan jika Anda mengarahkan panjang array ke tak terhingga (baik, atau hanya mengambil array sangat lama), maka waktu operasi program Anda akan 100% ditentukan oleh perhitungan, dan koefisien akselerasi dengan aman akan cenderung ke 1.