Pada bulan September, Hyperbaton keenam diadakan - konferensi Yandex tentang segala sesuatu yang berkaitan dengan dokumentasi teknis. Kami akan menerbitkan beberapa kuliah dari Hyperbaton, yang, menurut pendapat kami, mungkin sangat menarik bagi para pembaca Habr.
Svetlana Kayushina, kepala departemen dokumentasi dan lokalisasi:
- Tampaknya di dunia tidak ada lagi orang yang menerjemahkan secara manual. Hari ini kami ingin berbicara tentang alat dan pendekatan yang membantu perusahaan mengatur proses pelokalan yang efektif, dan para penerjemah memudahkan untuk menyelesaikan masalah sehari-hari mereka. Hari ini kita akan berbicara tentang terjemahan mesin, tentang mengevaluasi efektivitas mesin mesin, dan tentang sistem terjemahan otomatis untuk penerjemah.
Mari kita mulai dengan laporan dari kolega kita. Saya mengundang Irina Rybnikova dan Anastasia Ponomareva - mereka akan berbicara tentang pengalaman Yandex dalam memperkenalkan terjemahan mesin ke dalam proses lokalisasi kami.
Irina Rybnikova:
- Terima kasih. Kami akan memberi tahu Anda tentang riwayat terjemahan mesin dan bagaimana kami menggunakannya dalam Yandex.

Kembali pada abad ke-17, para ilmuwan berpikir tentang keberadaan bahasa yang menghubungkan bahasa lain, dan ini mungkin terlalu lama. Mari kita kembali lebih dekat. Kita semua ingin memahami orang-orang di sekitar kita - dari mana pun kita berasal - kita ingin melihat apa yang tertulis pada tanda-tanda, kita ingin membaca pengumuman, informasi tentang konser. Gagasan tentang ikan Babel mengeruk pikiran para ilmuwan, ditemukan dalam literatur, bioskop - di mana-mana. Kami ingin mengurangi waktu untuk mendapatkan akses ke informasi. Kami ingin membaca artikel tentang teknologi China, memahami situs apa pun yang kami lihat, dan ingin mendapatkannya di sini dan sekarang.

Dalam konteks ini, tidak mungkin untuk tidak berbicara tentang terjemahan mesin. Inilah yang membantu menyelesaikan masalah ini.

Titik awalnya adalah tahun 1954, ketika 60 kalimat pada subjek umum kimia organik diterjemahkan dari bahasa Rusia ke bahasa Inggris di AS menggunakan mesin IBM 701, dan semua ini didasarkan pada 250 istilah glosarium dan enam aturan tata bahasa. Ini disebut eksperimen Georgetown, dan sangat mengejutkan bahwa surat kabar penuh dengan tajuk berita hingga tiga hingga lima tahun lagi, dan masalahnya akan diselesaikan sepenuhnya, semua orang akan bahagia. Tapi seperti yang Anda tahu, semuanya berjalan sedikit berbeda.
Pada 70-an, terjemahan mesin berbasis aturan muncul. Itu juga didasarkan pada kamus bilingual, tetapi juga seperangkat aturan yang membantu menggambarkan bahasa apa pun. Apa pun, tetapi dengan keterbatasan.

Diperlukan ahli linguistik serius yang menetapkan aturan. Ini adalah pekerjaan yang agak rumit, masih tidak dapat memperhitungkan konteksnya, sepenuhnya mencakup bahasa apa pun, tetapi mereka ahli, dan kemudian daya komputasi yang tinggi tidak diperlukan.

Jika kita berbicara tentang kualitas, contoh klasik adalah kutipan dari Alkitab, yang kemudian diterjemahkan seperti ini. Belum cukup. Karena itu, orang terus bekerja pada kualitas. Pada tahun 90-an, model terjemahan statistik, SMT, muncul, yang berbicara tentang distribusi probabilistik kata dan kalimat, dan sistem ini pada dasarnya berbeda karena sama sekali tidak tahu tentang aturan dan linguistik. Dia menerima sejumlah besar teks identik, dipasangkan dalam satu bahasa dan bahasa lain, dan kemudian membuat keputusan sendiri. Mudah dirawat, tidak perlu banyak ahli, tidak perlu menunggu. Anda dapat mengunduh dan mendapatkan hasilnya.

Persyaratan untuk data yang masuk cukup rata-rata, dari 1 hingga 10 juta segmen. Segmen - kalimat, frasa kecil. Tetapi kesulitan mereka tetap dan konteksnya tidak diperhitungkan, semuanya tidak mudah. Dan di Rusia, misalnya, kasus seperti itu muncul.

Saya juga suka contoh menerjemahkan game GTA, hasilnya sangat bagus. Segalanya tidak berhenti. 2016 adalah tonggak penting ketika terjemahan mesin saraf dimulai. Itu adalah peristiwa yang agak membuat zaman yang sangat mengubah hidup. Kolega saya, setelah melihat terjemahannya dan bagaimana kami menggunakannya, mengatakan, ”Keren, dia berbicara dengan kata-kata saya.” Dan itu sangat bagus.
Fitur apa? Persyaratan masuk tinggi, materi pelatihan. Sulit untuk mempertahankan di dalam perusahaan, tetapi peningkatan yang signifikan dalam kualitas adalah apa yang dipahami. Hanya terjemahan yang berkualitas tinggi yang akan menyelesaikan tugas dan membuat hidup lebih mudah bagi semua peserta dalam proses, penerjemah yang sama yang tidak ingin memperbaiki terjemahan yang buruk, mereka ingin melakukan tugas kreatif baru, dan memberikan frasa rutin ke mesin.
Ada dua pendekatan untuk terjemahan mesin. Penilaian ahli / analisis linguistik teks, yaitu, verifikasi oleh ahli bahasa nyata, ahli untuk kepatuhan terhadap makna, literasi bahasa. Dalam beberapa kasus, para ahli masih ditanam, mereka diizinkan untuk mengurangi teks terjemahan dan mengevaluasi seberapa efektif dari sudut pandang ini.

Apa saja fitur dari metode ini? Tidak diperlukan terjemahan sampel, kami melihat teks yang sudah diterjemahkan sekarang dan mengevaluasinya secara objektif untuk bagian mana pun. Tapi itu mahal dan panjang.

Ada pendekatan kedua - metrik referensi otomatis. Ada banyak dari mereka, masing-masing memiliki pro dan kontra. Saya tidak akan masuk lebih dalam. Anda dapat membaca lebih lanjut tentang kata kunci ini nanti.
Fitur apa? Bahkan, ini adalah perbandingan teks mesin yang diterjemahkan dengan beberapa terjemahan teladan. Ini adalah metrik kuantitatif yang menunjukkan perbedaan antara terjemahan teladan dan apa yang terjadi. Ini cepat, murah dan bisa dilakukan dengan cukup mudah. Tetapi ada fitur.

Bahkan, paling sering mereka menggunakan metode hybrid. Ini adalah ketika sesuatu secara otomatis dievaluasi pada awalnya, kemudian matriks kesalahan dianalisis, kemudian analisis ahli bahasa dilakukan pada tubuh teks yang lebih kecil.

Baru-baru ini, praktik ini masih tersebar luas ketika kami tidak memanggil ahli bahasa di sana, tetapi hanya pengguna. Sebuah antarmuka sedang dibuat - tampilkan terjemahan mana yang paling Anda sukai. Atau ketika Anda pergi ke penerjemah online, Anda memasukkan teks, dan Anda sering dapat memilih apa yang paling Anda sukai, apakah pendekatan ini cocok atau tidak. Faktanya, kita semua sekarang melatih mesin ini, dan mereka menggunakan segalanya untuk pelatihan untuk pelatihan dan bekerja pada kualitas mereka.
Saya ingin memberi tahu bagaimana kami menggunakan terjemahan mesin dalam pekerjaan kami. Saya meneruskan kata itu ke Anastasia.
Anastasia Ponomareva:
- Kami di Yandex di departemen lokalisasi menyadari dengan cepat bahwa teknologi terjemahan mesin memiliki potensi besar, dan memutuskan untuk mencoba menggunakannya dalam tugas sehari-hari kami. Di mana kita mulai? Kami memutuskan untuk melakukan percobaan kecil. Kami memutuskan untuk menerjemahkan teks yang sama melalui penerjemah jaringan saraf biasa, dan juga mengumpulkan penerjemah mesin yang terlatih. Untuk melakukan ini, kami telah menyiapkan kumpulan teks dalam sepasang bahasa Rusia-Inggris untuk tahun-tahun ketika kami di Yandex terlibat dalam pelokalan teks dalam bahasa-bahasa ini. Kemudian kami datang dengan kumpulan teks ini ke rekan-rekan kami dari Yandex. Terjemahan dan diminta untuk melatih mesin.

Ketika mesin itu dilatih, kami menerjemahkan kumpulan teks berikutnya, dan seperti yang dikatakan Irina, dengan bantuan para ahli, kami mengevaluasi hasilnya. Kami meminta penerjemah untuk melihat keaksaraan, gaya, ejaan, dan transmisi makna. Tetapi titik baliknya adalah ketika salah seorang penerjemah mengatakan bahwa "Saya mengenali gaya saya, saya mengenali terjemahan saya."
Untuk memperkuat sensasi ini, kami memutuskan untuk menghitung indikator statistik. Pertama, kami menghitung koefisien BLEU untuk transfer yang dilakukan melalui mesin jaringan saraf biasa, dan kami mendapatkan angka ini (0,34). Tampaknya perlu dibandingkan dengan sesuatu. Kami kembali mendatangi kolega dari Yandex.Translator dan diminta untuk menjelaskan koefisien BLEU apa yang dianggap sebagai ambang batas untuk transfer yang dilakukan oleh orang sungguhan. Ini dari 0,6.
Kemudian kami memutuskan untuk memeriksa apa hasil terjemahan yang dilatih itu. Mendapat 0,5. Hasilnya sangat menggembirakan.

Saya memberi contoh. Ini adalah ungkapan Rusia yang sebenarnya dari dokumentasi Direct. Kemudian itu ditransfer melalui mesin jaringan saraf biasa, dan kemudian melalui mesin jaringan saraf terlatih dalam teks kami. Sudah di baris pertama kami perhatikan bahwa jenis iklan tradisional untuk Direct tidak dikenali. Dan sudah di mesin jaringan saraf terlatih terjemahan kami muncul, dan bahkan singkatannya hampir benar.
Kami sangat terdorong oleh hasilnya, dan memutuskan bahwa mungkin layak menggunakan mesin di pasangan lain, dalam teks lain, tidak hanya pada set dasar dokumentasi teknis. Serangkaian percobaan dilakukan selama beberapa bulan. Menghadapi banyak fitur dan masalah, ini adalah masalah paling umum yang harus kami pecahkan.

Saya akan memberi tahu Anda lebih banyak tentang masing-masing.

Jika Anda, seperti kami, berencana membuat mesin khusus, Anda akan membutuhkan data paralel berkualitas tinggi dalam jumlah yang cukup besar. Mesin besar dapat dilatih pada jumlah 10 ribu penawaran, dalam kasus kami, kami telah menyiapkan 135 ribu penawaran paralel.

Tidak pada semua jenis teks, mesin Anda akan menunjukkan hasil yang sama baiknya. Dalam dokumentasi teknis, di mana ada kalimat yang panjang, struktur, dokumentasi pengguna, dan bahkan di antarmuka, di mana ada tombol pendek tapi jelas, kemungkinan besar Anda akan baik-baik saja. Tetapi mungkin, seperti kami, Anda akan menghadapi masalah pemasaran.
Kami melakukan percobaan, menerjemahkan daftar putar musik, dan mendapatkan contoh seperti itu.

Itulah yang dipikirkan penerjemah mesin tentang pekerja pabrik bintang. Apa yang dimaksud dengan penabuh drum.

Saat menerjemahkan melalui mesin mesin, konteks tidak diperhitungkan. Ini bukan lagi contoh yang konyol, tapi cukup nyata, dari dokumentasi teknis Yandex.Direct. Tampaknya itu bisa dimengerti ketika Anda membaca dokumentasi teknis, itu adalah teknis. Tapi tidak, mesinnya tidak kena.

Anda juga harus mempertimbangkan bahwa kualitas dan makna terjemahan akan sangat bergantung pada bahasa aslinya. Kami menerjemahkan frasa ke Prancis dari Rusia, kami mendapatkan satu hasil. Kami mendapatkan frasa yang sama dengan makna yang sama, tetapi dari bahasa Inggris, dan kami mendapatkan hasil yang berbeda.

Jika Anda, seperti dalam teks kami, memiliki sejumlah besar tag, markup, beberapa fitur teknis, kemungkinan besar Anda harus melacaknya, mengedit dan menulis beberapa skrip.
Berikut adalah contoh frasa nyata dari peramban. Dalam tanda kurung adalah informasi teknis yang tidak boleh diterjemahkan, dalam beberapa bentuk tertentu. Dalam bahasa Inggris mereka dalam bahasa Inggris, dan dalam bahasa Jerman mereka juga harus tetap dalam bahasa Inggris, tetapi mereka diterjemahkan. Anda harus melacak titik-titik ini.
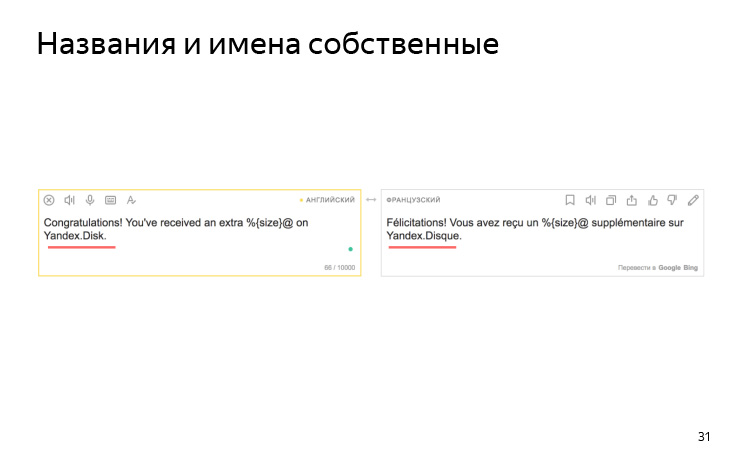
Mesin tidak tahu apa-apa tentang konvensi penamaan Anda. Misalnya, kami memiliki perjanjian bahwa kami selalu memanggil Yandex.Disk dalam bahasa Latin dalam semua bahasa. Namun dalam bahasa Prancis, ia berubah menjadi cakram dalam bahasa Prancis.

Singkatan kadang-kadang diakui dengan benar, kadang tidak. Dalam contoh ini, BY, yang menunjukkan milik persyaratan teknis Belarusia untuk iklan, berubah menjadi alasan dalam bahasa Inggris.

Salah satu contoh favorit saya adalah kata-kata baru dan dipinjam. Berikut adalah contoh keren, kata penafian, "bahasa Rusia kuno." Terminologi harus diverifikasi untuk setiap bagian teks.
Dan satu lagi, masalah yang tidak terlalu signifikan - tulisan usang.

Sebelumnya, Internet adalah hal yang baru, huruf kapital ditulis dalam semua teks, dan ketika kami melatih mesin kami, di mana pun Internet ditulis dengan huruf besar. Sekarang adalah era baru, Internet sudah ditulis dengan huruf kecil. Jika Anda ingin mesin Anda terus menulis Internet dengan huruf kecil, Anda harus melatihnya kembali.

Kami tidak putus asa, memecahkan masalah ini. Pertama, mereka mengubah kumpulan teks, mencoba menerjemahkan topik lain. Kami mengirimkan komentar kami kepada kolega dari Yandex.Translator, melatih kembali jaringan saraf dan melihat hasilnya, mengevaluasi, dan meminta untuk menyelesaikan. Misalnya, pengenalan tag, pemrosesan markup HTML.
Saya akan menunjukkan kasus penggunaan nyata. Kami memiliki terjemahan mesin yang baik untuk dokumentasi teknis. Ini adalah kasus nyata.

Berikut adalah frasa dalam bahasa Inggris dan Rusia. Penerjemah yang menangani dokumentasi ini sangat terdorong oleh pilihan terminologi yang tepat. Contoh lain.

Penerjemah menghargai pilihan bukan tanda hubung, bahwa struktur frasa telah berubah menjadi bahasa Inggris, pilihan yang memadai dari istilah yang benar, dan kata Anda, yang tidak dalam aslinya, tetapi membuat terjemahan ini persis bahasa Inggris, alami.

Kasus lain adalah terjemahan antarmuka dengan cepat. Salah satu layanan memutuskan untuk tidak mengganggu pelokalan dan menerjemahkan teks saat boot. Tetapi setelah mengganti mesin sebulan sekali, kata "pengiriman" berubah dalam lingkaran. Kami menyarankan agar tim terhubung bukan mesin jaringan saraf biasa, tetapi milik kami, terlatih dalam dokumentasi teknis, sehingga istilah yang sama selalu digunakan, disepakati dengan tim yang sudah ada dalam dokumentasi.

Bagaimana semua ini bekerja untuk momen moneter? Awalnya, kebetulan bahwa sepasang Rusia-Ukraina membutuhkan pengeditan terjemahan Ukraina yang minimal. Karena itu, beberapa bulan yang lalu kami memutuskan untuk beralih ke sistem post-editing. Beginilah cara tabungan kami tumbuh. September belum berakhir, tetapi kami memperkirakan bahwa kami telah mengurangi biaya pengeditan setelah sekitar sepertiga di Ukraina, dan kami akan mengedit hampir semua hal kecuali teks pemasaran. Kata Irina untuk meringkas.
Irina:
- Bagi setiap orang menjadi jelas bahwa perlu untuk menggunakannya, itu sudah menjadi kenyataan kita, dan tidak mungkin untuk mengeluarkannya dari proses dan minat kita. Tetapi Anda perlu memikirkan beberapa hal.

Tentukan jenis dokumen, konteks tempat Anda bekerja. Apakah teknologi ini tepat untuk Anda?
Momen kedua. Kami berbicara tentang Yandex.Translator, karena kami berada dalam hubungan yang baik, kami memiliki akses langsung ke pengembang, dan sebagainya, tetapi sebenarnya Anda perlu memutuskan mesin mana yang paling optimal untuk Anda secara spesifik, untuk bahasa Anda, subjek Anda. Laporan
selanjutnya akan dikhususkan untuk topik ini. Bersiaplah bahwa masih ada kesulitan, para pengembang mesin bekerja sama untuk memecahkan kesulitan, tetapi sejauh ini mereka masih bertemu.

Saya ingin memahami apa yang menanti kita di masa depan. Tetapi pada kenyataannya, ini tidak lebih jauh, tetapi waktu kita sekarang, apa yang terjadi di sini dan sekarang. Kita semua lebih membutuhkan penyesuaian untuk terminologi kita, untuk teks kita, dan inilah yang sekarang menjadi publik. Sekarang semua orang bekerja untuk memastikan bahwa Anda tidak masuk ke dalam perusahaan, tidak setuju dengan pengembang mesin tertentu, cara mengoptimalkan ini untuk Anda. Anda akan dapat menerimanya di mesin terbuka publik di API.
Kustomisasi tidak hanya dalam teks, tetapi juga dalam terminologi, untuk mengkonfigurasi terminologi untuk kebutuhan Anda sendiri. Ini poin penting. Topik kedua adalah terjemahan interaktif. Ketika penerjemah menerjemahkan teks, teknologi memungkinkannya untuk memprediksi kata-kata berikut dengan mempertimbangkan bahasa sumber, teks sumber. Auger ini dapat sangat memudahkan pekerjaan.
Itu sekarang sangat mahal. Semua orang berpikir bagaimana mengajar beberapa mesin jauh lebih efektif dengan jumlah teks yang lebih sedikit. Inilah yang terjadi di mana-mana dan berjalan di mana-mana. Saya pikir topiknya sangat menarik, dan kemudian akan menjadi lebih menarik.
Kami telah mengumpulkan beberapa artikel yang mungkin menarik bagi Anda. Terima kasih
-
Dua model lebih baik dari satu. Pengalaman Yandex.Translator-
Bagaimana Yandex menerapkan teknologi kecerdasan buatan untuk menerjemahkan halaman web- Terjemahan
mesin. Dari perang dingin ke dipllerning