Catatan perev. : Artikel asli ditulis oleh seorang penulis teknis dari Google, mengerjakan dokumentasi untuk Kubernetes (Andrew Chen), dan direktur rekayasa perangkat lunak dari SAP (Dominik Tornow). Tujuannya adalah untuk menjelaskan dengan jelas dan jelas dasar-dasar pengorganisasian dan penerapan ketersediaan tinggi di Kubernetes. Tampaknya bagi kami bahwa penulis berhasil, jadi kami senang berbagi terjemahan.
Kubernetes adalah mesin orkestrasi wadah yang dirancang untuk menjalankan aplikasi kemas pada banyak node, biasanya disebut sebagai cluster. Dalam publikasi ini, kami menggunakan pendekatan pemodelan sistem untuk meningkatkan pemahaman tentang Kubernet dan konsep dasarnya. Pembaca didorong untuk sudah memiliki pemahaman dasar tentang Kubernet.
Kubernetes adalah mesin orkestrasi kontainer yang dapat diskalakan dan andal. Skalabilitas di sini ditentukan oleh responsif di hadapan beban, dan keandalan ditentukan oleh responsif di hadapan kegagalan.
Perhatikan bahwa skalabilitas dan keandalan Kubernetes tidak berarti skalabilitas dan keandalan aplikasi yang berjalan di dalamnya. Kubernetes adalah platform yang dapat diskalakan dan andal, tetapi setiap aplikasi K8 belum melalui langkah-langkah tertentu untuk menjadi satu dan menghindari kemacetan dan titik kegagalan tunggal.
Misalnya, jika aplikasi dikerahkan sebagai ReplicaSet atau Deployment, Kubernetes (kembali) merencanakan dan (kembali) meluncurkan pod yang dipengaruhi oleh crash node. Namun, jika aplikasi ini digunakan sebagai pod, Kubernetes tidak akan mengambil tindakan apa pun jika terjadi kegagalan simpul. Oleh karena itu, meskipun Kubernetes sendiri tetap beroperasi, daya tanggap aplikasi Anda bergantung pada arsitektur dan keputusan penempatan yang dipilih.
Publikasi ini berfokus pada keandalan Kubernetes. Dia berbicara tentang bagaimana Kubernetes mempertahankan daya tanggap di hadapan kegagalan.
Arsitektur Kubernetes
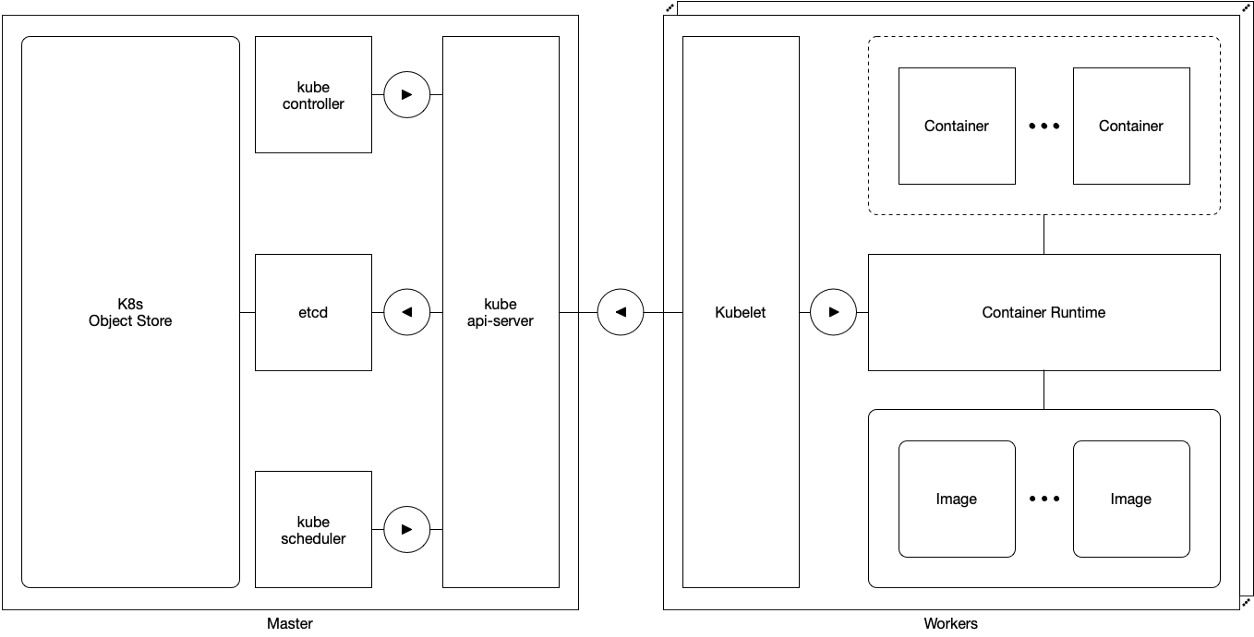
 Skema 1. Tuan dan pekerja
Skema 1. Tuan dan pekerjaPada tingkat konseptual, komponen Kubernetes dikelompokkan ke dalam dua kelas yang berbeda: Komponen
master dan Komponen
pekerja .
Master bertanggung jawab untuk mengelola segalanya kecuali eksekusi perapian. Komponen wizard meliputi:
Pekerja bertanggung jawab untuk mengelola pelaksanaan perapian. Mereka memiliki satu komponen:
Pekerja sepele dapat diandalkan: kegagalan sementara atau permanen dari setiap pekerja dalam sebuah cluster tidak mempengaruhi master atau pekerja cluster lainnya. Jika aplikasi dikerahkan dengan tepat, Kubernetes (kembali) merencanakan dan (kembali) meluncurkan salah satu yang terkena dampak kegagalan pekerja.
Konfigurasi wizard tunggal
 Skema 2. Konfigurasi dengan master tunggal
Skema 2. Konfigurasi dengan master tunggalDalam konfigurasi master tunggal, kluster Kubernetes terdiri dari satu master dan banyak pekerja. Yang terakhir terhubung langsung ke wizard kube-apiserver dan berinteraksi dengannya.
Dalam konfigurasi ini, daya tanggap Kubernetes tergantung pada:
- satu-satunya tuan
- menghubungkan pekerja ke master tunggal.
Karena satu-satunya master adalah satu titik kegagalan, konfigurasi ini tidak termasuk dalam kategori ketersediaan tinggi.
Konfigurasi multi-penyihir
 Skema 3. Konfigurasi dengan banyak master
Skema 3. Konfigurasi dengan banyak masterDalam konfigurasi multi-master, kluster Kubernetes terdiri dari banyak master dan banyak pekerja. Pekerja terhubung ke apiserver kubus master apa pun dan berinteraksi dengannya melalui penyeimbang beban yang sangat mudah diakses.
Dalam konfigurasi ini, Kubernet
tidak tergantung pada:
- satu-satunya tuan
- menghubungkan pekerja ke master tunggal .
Karena tidak ada titik kegagalan tunggal dalam konfigurasi ini, itu dianggap sangat mudah diakses.
Pemimpin dan pengikut di Kubernetes
Dalam konfigurasi multi-wizard, banyak manajer-kubus-pengendali dan penjadwal-kubus terlibat. Jika dua komponen memodifikasi objek yang sama, konflik dapat muncul.
Untuk menghindari kemungkinan konflik, untuk Kubernetes kube-controller-manager dan kube-scheduler mengimplementasikan pola "
master-slave "
(leader / follower) . Setiap kelompok memilih satu pemimpin
(atau pemimpin) , dan anggota kelompok yang tersisa mengambil peran sebagai pengikut. Pada saat tertentu, hanya satu pemimpin yang aktif, dan para pengikut pasif.
 Gambar 4. Wisaya Komponen Penempatan Redundan secara Detail
Gambar 4. Wisaya Komponen Penempatan Redundan secara DetailIlustrasi ini menunjukkan contoh terperinci di mana kube-controller-1 dan kube-scheduler-2 memimpin di antara kube-controller-manager dan kube-schedulers. Karena masing-masing kelompok memilih pemimpinnya sendiri, mereka tidak harus memiliki pemimpin yang sama sekali.
Pemilihan pemimpin
Seorang pemimpin baru dipilih oleh anggota grup pada saat peluncuran atau dalam hal pemimpin jatuh.
Pimpinan - seorang anggota dengan apa yang disebut
pemimpin sewa (saat ini "disewakan" status pemimpin).
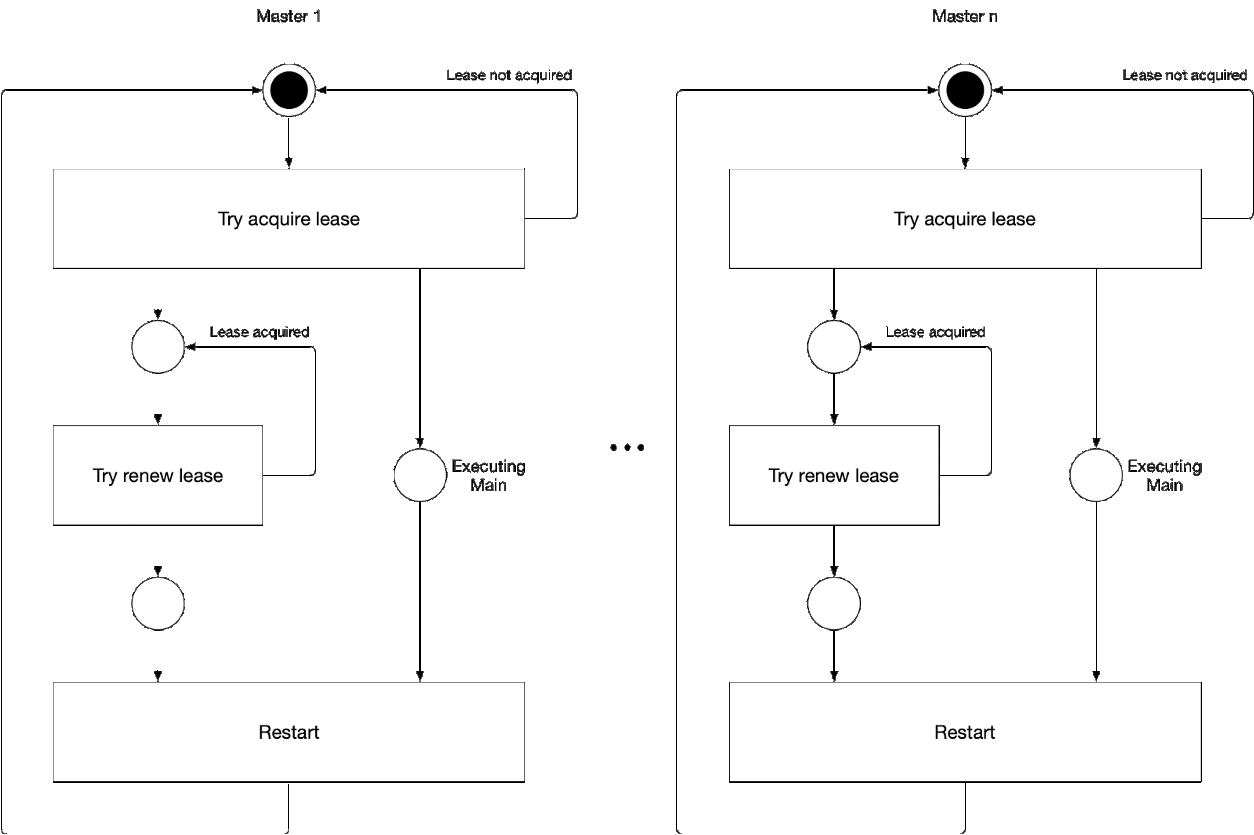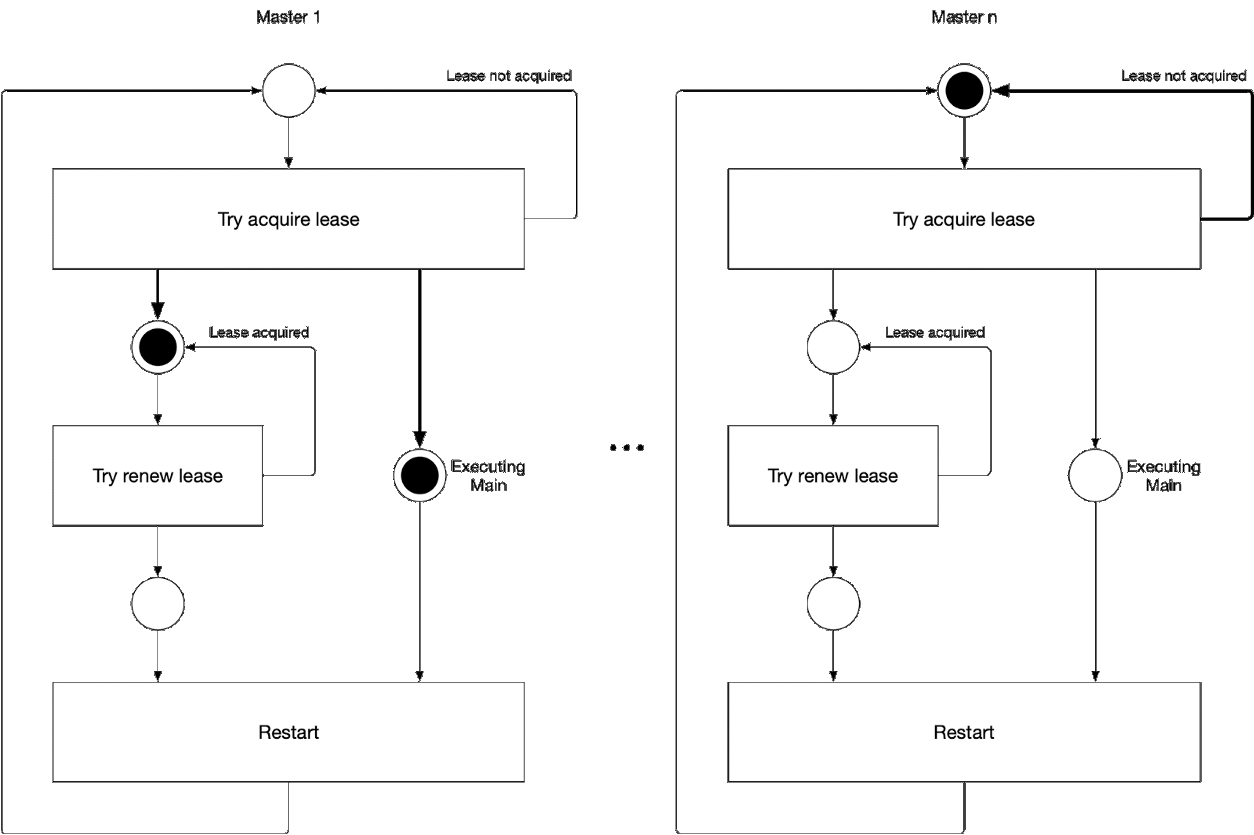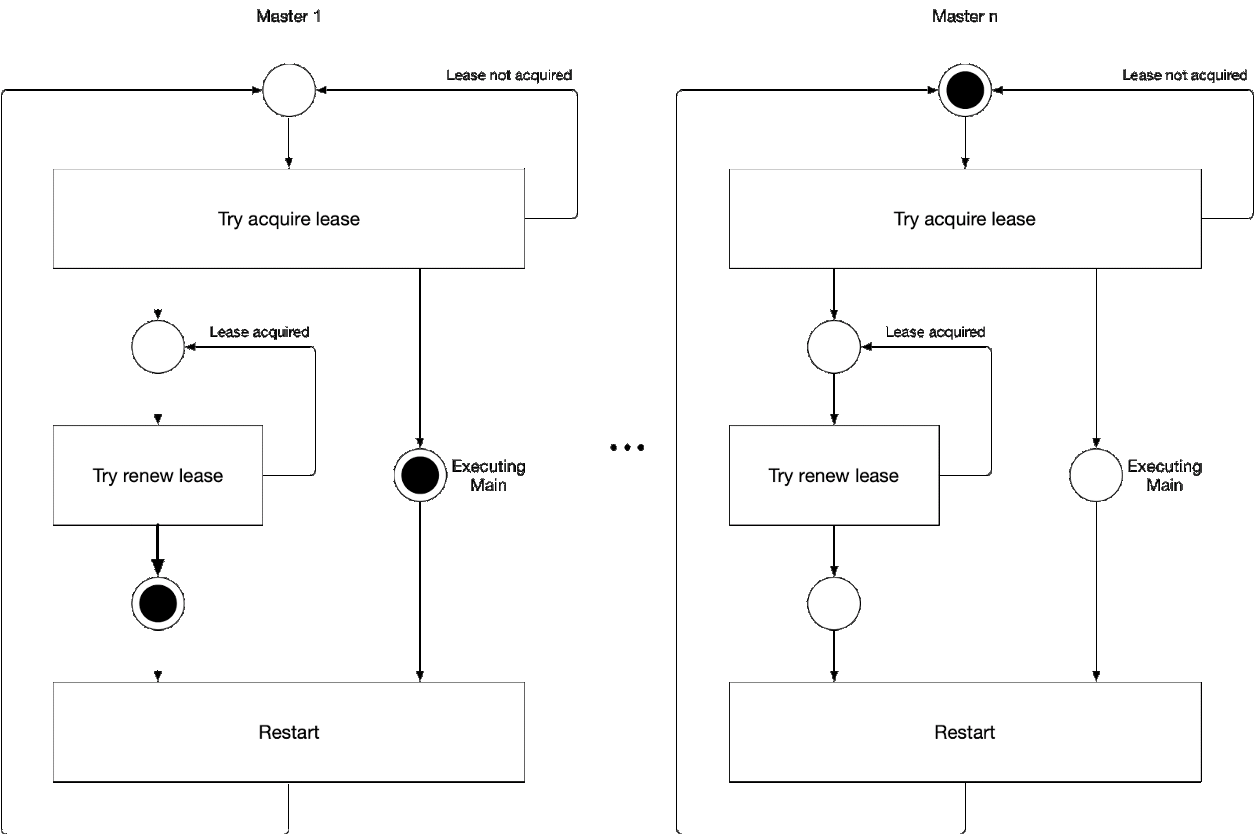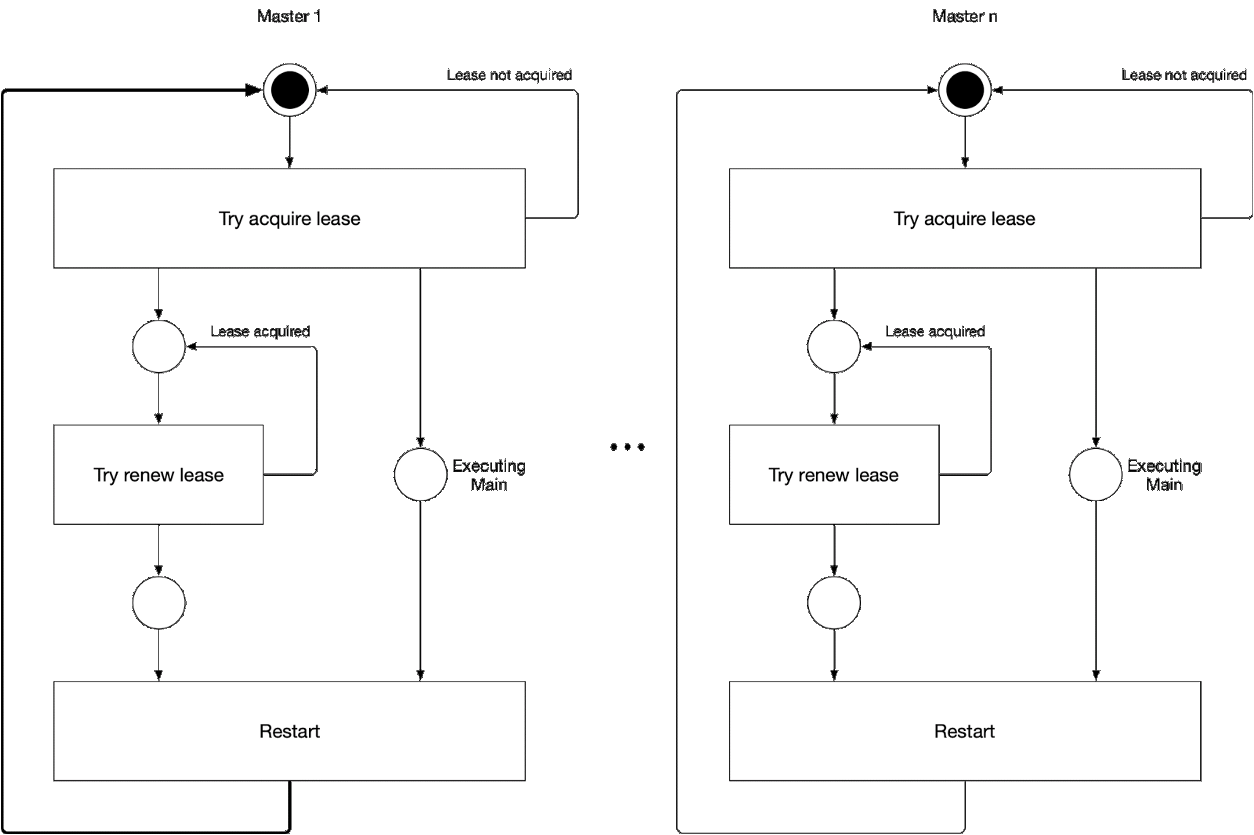 Diagram 5. Proses memilih komponen master wizard
Diagram 5. Proses memilih komponen master wizardIlustrasi ini menunjukkan proses pemilihan master untuk kube-controller-manager dan kube-scheduler. Logika dari proses ini adalah sebagai berikut:
' ' , :
-
-
' ' , :
- leader lease
-
- holderIdentity 'self'Pelacakan Terkemuka
Status pemimpin saat ini untuk kube-controller-manager dan kube-scheduler disimpan secara permanen di penyimpanan objek Kubernetes sebagai
objek endpoint di namespace
kube-system . Karena dua objek Kubernetes tidak dapat memiliki nama, tipe
(jenis) dan namespace yang sama pada saat yang sama, hanya ada satu
titik akhir untuk penjadwal kube dan untuk kube-controller-manager.
Demo menggunakan utilitas konsol
kubectl :
$ kubectl get endpoints -n kube-system NAME ENDPOINTS AGE kube-scheduler <none> 30m kube-controller-manager <none> 30m
Penjadwal kube-scheduler dan informasi pemimpin toko kube-controller-manager di anotasi
control-plane.alpha.kubernetes.io/leader :
$ kubectl describe endpoints kube-scheduler -n kube-system Name: kube-scheduler Annotations: control-plane.alpha.kubernetes.io/leader= { "holderIdentity": "scheduler-2", "leaseDurationSeconds": 15, "acquireTime": "2018-01-01T08:00:00Z" "renewTime": "2018-01-01T08:00:30Z" }
Meskipun Kubernetes menjamin bahwa akan ada satu master pada satu waktu, Kubernetes tidak menjamin bahwa dua atau lebih komponen wizard tidak akan
secara keliru percaya bahwa mereka saat ini memimpin - keadaan ini dikenal sebagai
otak terbelah .
Sebuah diskusi instruktif tentang topik otak terbelah dan solusi yang mungkin dapat ditemukan dalam artikel
Bagaimana cara melakukan penguncian didistribusikan Martin Kleppmann
Kubernetes tidak menggunakan tindakan penanggulangan otak terpisah. Sebaliknya, ia bergantung pada kemampuannya untuk berjuang untuk negara yang diinginkan dari waktu ke waktu, yang mengurangi konsekuensi dari keputusan konflik.
Kesimpulan
Dalam konfigurasi multi-master, Kubernetes adalah mesin orkestrasi kontainer yang dapat diskalakan dan andal. Dalam konfigurasi ini, Kubernetes menyediakan keandalan menggunakan berbagai penyihir dan banyak pekerja. Banyak master bekerja pada pola master / slave, dan para pekerja bekerja secara paralel. Kubernetes memiliki proses pemilihan host sendiri, di mana informasi host disimpan sebagai
objek endpoint .
Untuk informasi tentang cara menyiapkan kluster ketersediaan tinggi Kubernet untuk operasi, lihat
dokumentasi resmi .
Tentang publikasi
Posting ini adalah bagian dari inisiatif bersama oleh CNCF, Google, dan SAP untuk meningkatkan pemahaman tentang Kubernet dan konsep-konsep yang mendasarinya.PS dari penerjemah
Baca juga di blog kami: