Halo, Habr! Nama saya Nikolai Izhikov, saya bekerja untuk Sberbank Technologies di Tim Pengembangan Solusi Sumber Terbuka. Di belakang 15 tahun pengembangan komersial di Jawa. Saya seorang komiter Apache Ignite dan kontributor Apache Kafka.
Di bawah kucing, Anda akan menemukan versi video dan teks dari laporan saya tentang Apache Ignite Meetup tentang cara menggunakan Apache Ignite dengan Apache Spark dan fitur apa yang telah kami terapkan untuk ini.
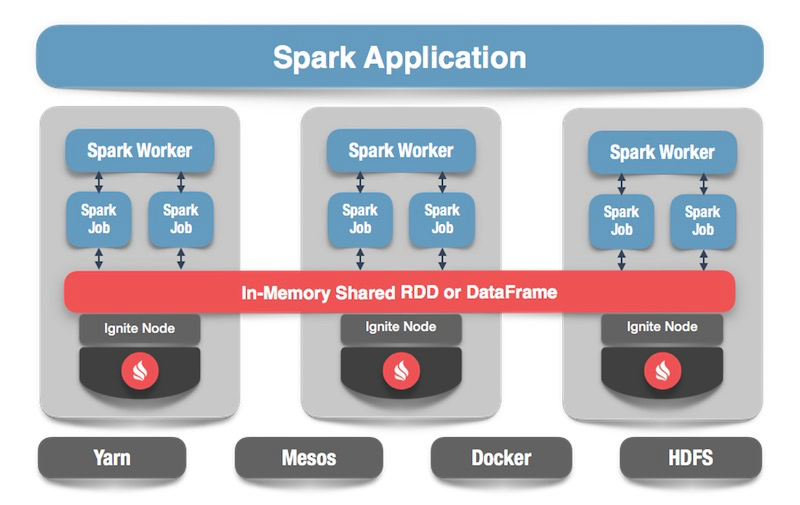
Apa yang bisa dilakukan Apache Spark
Apa itu Apache Spark? Ini adalah produk yang memungkinkan Anda untuk dengan cepat melakukan komputasi terdistribusi dan pertanyaan analitis. Pada dasarnya, Apache Spark ditulis dalam Scala.
Apache Spark memiliki API yang kaya untuk menghubungkan ke berbagai sistem penyimpanan atau menerima data. Salah satu fitur dari produk ini adalah mesin query universal seperti-SQL untuk data yang diterima dari berbagai sumber. Jika Anda memiliki beberapa sumber informasi, Anda ingin menggabungkannya dan mendapatkan beberapa hasil, Apache Spark adalah yang Anda butuhkan.
Salah satu abstraksi kunci yang disediakan Spark adalah Data Frame, DataSet. Dalam hal database relasional, ini adalah tabel, sumber yang menyediakan data dengan cara terstruktur. Struktur, jenis setiap kolom, namanya, dll., Diketahui. Frame Data dapat dibuat dari berbagai sumber. Contohnya termasuk file json, database relasional, berbagai sistem hadoop, dan Apache Ignite.
Spark mendukung penggabungan dalam query SQL. Anda dapat menggabungkan data dari berbagai sumber dan mendapatkan hasil, melakukan kueri analitik. Selain itu, ada API untuk menyimpan data. Ketika Anda telah menyelesaikan pertanyaan, melakukan penelitian, Spark menyediakan kemampuan untuk menyimpan hasil ke penerima yang mendukung fitur ini, dan, dengan demikian, menyelesaikan masalah pemrosesan data.
Fitur apa yang telah kami terapkan untuk mengintegrasikan Apache Spark dengan Apache Ignite
- Membaca data dari tabel Apache Ignite SQL.
- Menulis data ke Apache Ignite tabel SQL.
- IgniteCatalog di dalam IgniteSparkSession - kemampuan untuk menggunakan semua tabel SQL Ignite yang ada tanpa mendaftar "dengan tangan".
- Optimasi SQL - kemampuan untuk mengeksekusi pernyataan SQL di dalam Ignite.
Apache Spark dapat membaca data dari tabel Apache Ignite SQL dan menulisnya dalam bentuk tabel seperti itu. DataFrame apa pun yang dibentuk di Spark dapat disimpan sebagai tabel SQL Ignite SQL.
Apache Ignite memungkinkan Anda untuk menggunakan semua tabel SQL Ignite yang ada di Spark Session tanpa mendaftar "dengan tangan" - menggunakan IgniteCatalog di dalam ekstensi SparkSession standar - IgniteSparkSession.
Di sini Anda perlu masuk lebih dalam ke perangkat Spark. Dalam hal database reguler, direktori adalah tempat penyimpanan informasi meta: tabel mana yang tersedia, kolom mana di dalamnya, dll. Ketika permintaan datang, informasi meta ditarik dari katalog dan mesin SQL melakukan sesuatu dengan tabel dan data. Secara default, di Spark, semua tabel baca (tidak masalah, dari database relasional, Ignite, Hadoop) harus didaftarkan secara manual dalam sesi. Sebagai hasilnya, Anda mendapatkan kesempatan untuk membuat kueri SQL pada tabel ini. Spark mencari tahu tentang mereka.
Untuk bekerja dengan data yang kami unggah ke Ignite, kami perlu mendaftarkan tabel. Tetapi alih-alih mendaftarkan setiap tabel dengan tangan kami, kami menerapkan kemampuan untuk secara otomatis mengakses semua tabel Ignite.
Apa fitur di sini? Untuk beberapa alasan saya tidak tahu, direktori di Spark adalah API internal, mis. orang luar tidak bisa datang dan membuat implementasi katalognya sendiri. Dan, sejak Spark keluar dari Hadoop, itu hanya mendukung Hive. Dan Anda harus mendaftarkan yang lainnya dengan tangan Anda. Pengguna sering bertanya bagaimana Anda bisa menyiasatinya dan segera membuat pertanyaan SQL. Saya menerapkan direktori yang memungkinkan Anda untuk menelusuri dan mengakses tabel Ignite tanpa mendaftar ~ dan sms ~, dan awalnya mengusulkan tambalan ini di komunitas Spark, yang saya terima jawabannya: tambalan semacam itu tidak menarik karena beberapa alasan internal. Dan mereka tidak memberikan API internal.
Sekarang katalog Ignite adalah fitur menarik yang diimplementasikan menggunakan API internal Spark. Untuk menggunakan direktori ini, kami memiliki implementasi sesi kami sendiri. Ini adalah SparkSession biasa, di mana Anda dapat membuat permintaan, memproses data. Perbedaannya adalah bahwa kami mengintegrasikan ExternalCatalog ke dalamnya untuk bekerja dengan tabel Ignite, serta IgniteOptimization, yang akan dijelaskan di bawah ini.
Optimasi SQL - kemampuan untuk mengeksekusi pernyataan SQL di dalam Ignite. Secara default, saat melakukan penggabungan, pengelompokan, penghitungan agregat, dan kueri SQL kompleks lainnya, Spark membaca data dalam mode baris demi baris. Satu-satunya sumber data dapat lakukan adalah menyaring baris secara efisien.
Jika Anda menggunakan bergabung atau mengelompokkan, Spark menarik semua data dari tabel ke dalam memorinya ke pekerja, menggunakan filter yang ditentukan, dan hanya kemudian mengelompokkan mereka atau melakukan operasi SQL lainnya. Dalam kasus Ignite, ini tidak optimal, karena Ignite sendiri memiliki arsitektur terdistribusi dan memiliki pengetahuan tentang data yang disimpan di dalamnya. Oleh karena itu, Ignite sendiri dapat secara efisien menghitung agregat dan melakukan pengelompokan. Selain itu, mungkin ada banyak data, dan untuk mengelompokkannya, Anda perlu mengurangi segalanya, mengumpulkan semua data dalam Spark, yang cukup mahal.
Spark menyediakan API yang dengannya Anda dapat mengubah rencana awal kueri SQL, melakukan optimasi, dan meneruskan bagian dari kueri SQL yang dapat dieksekusi di sana menjadi Ignite. Ini akan efektif dalam hal kecepatan maupun konsumsi memori, karena kami tidak akan menggunakannya untuk mengeluarkan data yang akan segera dikelompokkan.
Bagaimana cara kerjanya
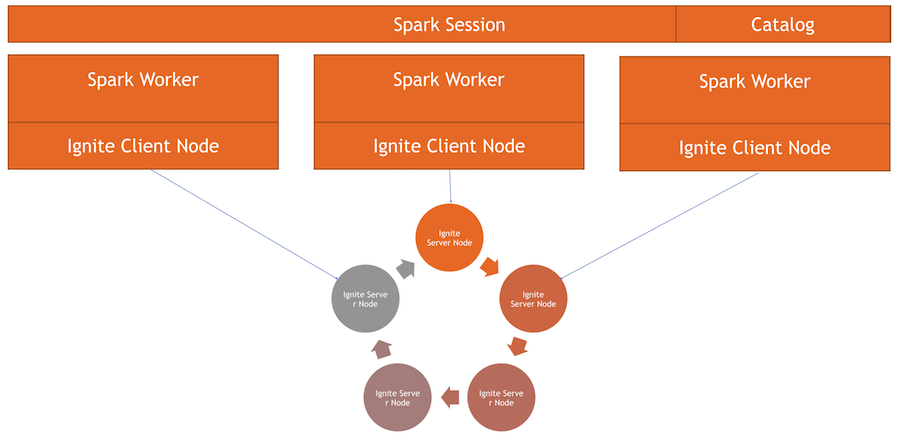
Kami memiliki gugus Ignite - ini adalah bagian bawah gambar. Tidak ada Zookeeper, karena hanya ada lima node. Ada pekerja percikan, di dalam setiap pekerja simpul klien Ignite dinaikkan. Melalui itu, kita dapat membuat permintaan dan membaca data, berinteraksi dengan cluster. Juga, simpul klien naik di dalam IgniteSparkSession agar direktori berfungsi.
Nyalakan bingkai data
Kita beralih ke kode: bagaimana membaca data dari tabel SQL? Dalam kasus Spark, semuanya cukup sederhana dan baik: kami mengatakan bahwa kami ingin menghitung beberapa data, menunjukkan format - ini adalah konstanta tertentu. Selanjutnya, kami memiliki beberapa opsi - jalur ke file konfigurasi untuk node klien, yang dimulai saat membaca data. Kami menunjukkan tabel mana yang ingin kami baca dan beri tahu Spark untuk memuat. Kami mendapatkan data dan kami dapat melakukan apa yang kami inginkan dengannya.
spark.read .format(FORMAT_IGNITE) .option(OPTION_CONFIG_FILE, TEST_CONFIG_FILE) .option(OPTION_TABLE, "person") .load()
Setelah kami menghasilkan data - opsional dari Ignite, dari sumber apa pun - kami dapat dengan mudah menyimpan semuanya dengan menentukan format dan tabel terkait. Kami memerintahkan Spark untuk menulis, kami menentukan format. Dalam konfigurasi, kami meresepkan kluster mana yang akan dihubungkan. Tentukan tabel tempat kami ingin menyimpan. Selain itu, kami dapat meresepkan opsi utilitas - tentukan kunci utama yang kami buat di tabel ini. Jika data hanya mengecewakan tanpa membuat tabel, maka parameter ini tidak diperlukan. Pada akhirnya, klik simpan dan data ditulis.
tbl.write. format(FORMAT_IGNITE). option(OPTION_CONFIG_FILE, CFG_PATH). option(OPTION_TABLE, tableName). option(OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS, pk). save
Sekarang mari kita lihat bagaimana semuanya bekerja.
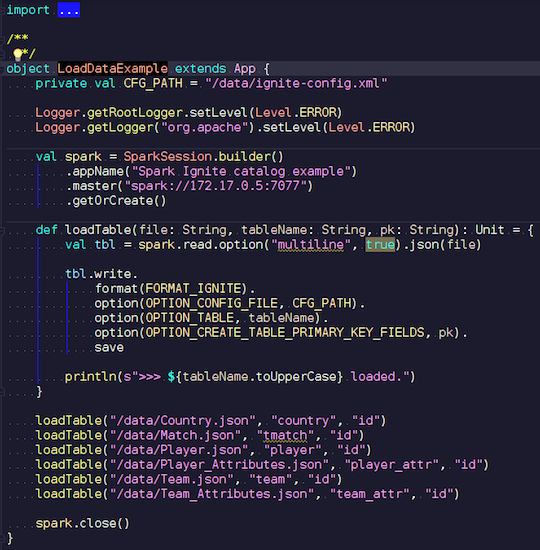 LoadDataExample.scala
LoadDataExample.scalaAplikasi yang jelas ini pertama-tama akan menunjukkan kemampuan merekam. Misalnya, saya memilih data pada pertandingan sepak bola, statistik yang diunduh dari sumber yang terkenal. Ini berisi informasi tentang turnamen: liga, pertandingan, pemain, tim, atribut pemain, atribut tim - data yang menggambarkan pertandingan sepak bola di liga negara-negara Eropa (Inggris, Perancis, Spanyol, dll.).
Saya ingin mengunggahnya ke Ignite. Kami membuat sesi Spark, menentukan alamat wizard dan memanggil pemuatan tabel ini, melewati parameter. Contohnya adalah dalam Scala, bukan Java, karena Scala kurang verbose dan jadi lebih baik misalnya.
Kami mentransfer nama file, membacanya, menunjukkan bahwa itu multiline, ini adalah file json standar. Kemudian kami menulis di Ignite. Struktur file kita tidak dapat dijelaskan - Spark sendiri menentukan data apa yang kita miliki dan apa strukturnya. Jika semuanya berjalan lancar, sebuah tabel dibuat dengan semua bidang yang diperlukan dari tipe data yang diperlukan. Ini adalah bagaimana kita dapat memuat semua yang ada di dalam Ignite.
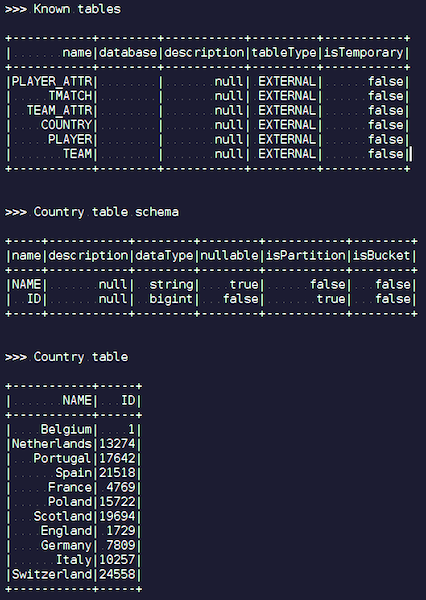
Ketika data dimuat, kita bisa melihatnya di Ignite dan langsung menggunakannya. Sebagai contoh sederhana, kueri yang memungkinkan Anda mengetahui tim mana yang paling banyak memainkan pertandingan. Kami memiliki dua kolom: hometeam dan awayteam, host dan tamu. Kami memilih, mengelompokkan, menghitung, menjumlahkan, dan bergabung dengan data pada perintah - untuk memasukkan nama perintah. Ta-dam - dan data dari json-chiks kami dapatkan di Ignite. Kami melihat Paris Saint-Germain, Toulouse - kami memiliki banyak data tentang tim-tim Prancis.
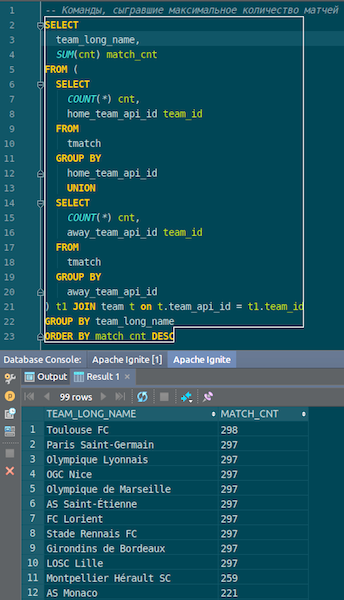
Kami meringkas. Kami sekarang telah mengunggah data dari sumber, file json, ke Ignite, dan cukup cepat. Mungkin, dari sudut pandang data besar, ini tidak terlalu besar, tetapi layak untuk komputer lokal. Skema tabel diambil dari file json dalam bentuk aslinya. Tabel dibuat, nama kolom disalin dari file sumber, kunci utama dibuat. ID ada di mana-mana, dan kunci utama adalah ID. Data ini masuk ke Ignite, kita bisa menggunakannya.
IgniteSparkSession dan IgniteCatalog
Mari kita lihat cara kerjanya.
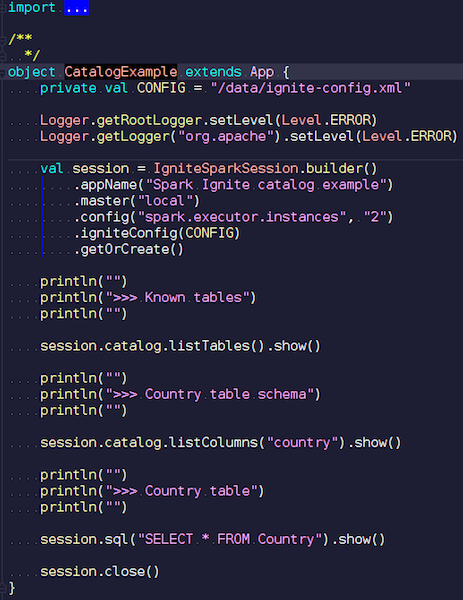 KatalogExample.scala
KatalogExample.scalaDengan cara yang cukup sederhana, Anda dapat mengakses dan menanyakan semua data Anda. Pada contoh terakhir, kami memulai sesi percikan standar. Dan tidak ada spesifisitas Ignite di sana - kecuali bahwa Anda harus meletakkan jar dengan sumber data yang tepat - benar-benar pekerjaan standar melalui API publik. Tetapi, jika Anda ingin mengakses tabel Ignite secara otomatis, Anda dapat menggunakan ekstensi kami. Perbedaannya adalah bahwa alih-alih SparkSession kita menulis IgniteSparkSession.
Segera setelah Anda membuat objek IgniteSparkSession, Anda melihat di direktori semua tabel yang baru saja dimuat ke dalam Ignite. Anda dapat melihat diagram mereka dan semua informasi. Spark sudah tahu tentang tabel yang dimiliki Ignite, dan Anda dapat dengan mudah mendapatkan semua data.
Optimalisasi penyalaan
Saat Anda membuat kueri kompleks di Ignite menggunakan JOIN, Spark menarik datanya terlebih dahulu, dan baru kemudian GABUNG mengelompokkannya. Untuk mengoptimalkan proses, kami membuat fitur IgniteOptimization - ini mengoptimalkan rencana permintaan Spark dan memungkinkan Anda untuk meneruskan bagian-bagian dari permintaan yang dapat dieksekusi di dalam Ignite di dalam Ignite. Kami menampilkan pengoptimalan berdasarkan permintaan tertentu.
SQL Query: SELECT city_id, count(*) FROM person p GROUP BY city_id HAVING count(*) > 1
Kami memenuhi permintaan itu. Kami memiliki meja orang - beberapa karyawan, orang-orang. Setiap karyawan tahu ID kota tempat dia tinggal. Kami ingin tahu berapa banyak orang yang tinggal di setiap kota. Kami memfilter - di kota mana lebih dari satu orang tinggal. Berikut adalah rencana awal yang dibangun Spark:
== Analyzed Logical Plan == city_id: bigint, count(1): bigint Project [city_id#19L, count(1)#52L] +- Filter (count(1)#54L > cast(1 as bigint)) +- Aggregate [city_id#19L], [city_id#19L, count(1) AS count(1)#52L, count(1) AS count(1)#54L] +- SubqueryAlias p +- SubqueryAlias person +- Relation[NAME#11,BIRTH_DATE#12,IS_RESIDENT#13,SALARY#14,PENSION#15,ACCOUNT#16,AGE#17,ID#18L,CITY_ID#19L] IgniteSQLRelation[table=PERSON]
Relasi hanyalah tabel Ignite. Tidak ada filter - kami hanya memompa semua data dari tabel Person melalui jaringan dari cluster. Kemudian Spark mengumpulkan semua ini - sesuai dengan permintaan dan mengembalikan hasil permintaan.
Sangat mudah untuk melihat bahwa semua subtree ini dengan filter dan agregasi dapat dieksekusi di dalam Ignite. Ini akan jauh lebih efisien daripada menarik semua data dari tabel berpotensi besar di Spark - inilah yang dilakukan fitur IgniteOptimization kami. Setelah menganalisis dan mengoptimalkan pohon, kami mendapatkan rencana berikut:
== Optimized Logical Plan == Relation[CITY_ID#19L,COUNT(1)#52L] IgniteSQLAccumulatorRelation( columns=[CITY_ID, COUNT(1)], qry=SELECT CITY_ID, COUNT(1) FROM PERSON GROUP BY city_id HAVING count(1) > 1)
Akibatnya, kami hanya mendapatkan satu relasi, karena kami mengoptimalkan seluruh pohon. Dan di dalam Anda sudah dapat melihat bahwa Ignite akan mengirim permintaan yang cukup dekat dengan permintaan asli.
Misalkan kita bergabung dengan berbagai sumber data: misalnya, kita memiliki satu DataFrame dari Ignite, yang kedua dari json, yang ketiga lagi dari Ignite, dan yang keempat dari beberapa jenis database relasional. Dalam hal ini, hanya subtree yang akan dioptimalkan dalam rencana. Kami mengoptimalkan apa yang kami bisa, letakkan di Ignite, dan Spark akan melakukan sisanya. Karena ini, kami mendapatkan keuntungan dalam kecepatan.
Contoh lain dengan GABUNG:
SQL Query - SELECT jt1.id as id1, jt1.val1, jt2.id as id2, jt2.val2 FROM jt1 JOIN jt2 ON jt1.val1 = jt2.val2
Kami punya dua meja. Kami tetap bersama berdasarkan nilai dan memilih dari semuanya - ID, nilai. Spark menawarkan rencana seperti itu:
== Analyzed Logical Plan == id1: bigint, val1: string, id2: bigint, val2: string Project [id#4L AS id1#84L, val1#3, id#6L AS id2#85L, val2#5] +- Join Inner, (val1#3 = val2#5) :- SubqueryAlias jt1 : +- Relation[VAL1#3,ID#4L] IgniteSQLRelation[table=JT1] +- SubqueryAlias jt2 +- Relation[VAL2#5,ID#6L] IgniteSQLRelation[table=JT2]
Kita melihat bahwa dia akan mengeluarkan semua data dari satu tabel, semua data dari tabel kedua, bergabung dengan mereka di dalam dirinya sendiri dan memberikan hasilnya. Setelah diproses dan dioptimalkan, kami mendapatkan permintaan yang sama persis dengan Ignite, yang dijalankan dengan relatif cepat.
== Optimized Logical Plan == Relation[ID#84L,VAL1#3,ID#85L,VAL2#5] IgniteSQLAccumulatorRelation(columns=[ID, VAL1, ID, VAL2], qry= SELECT JT1.ID AS id1, JT1.VAL1, JT2.ID AS id2, JT2.VAL2 FROM JT1 JOIN JT2 ON JT1.val1 = JT2.val2 WHERE JT1.val1 IS NOT NULL AND JT2.val2 IS NOT NULL)
Saya akan tunjukkan contoh.
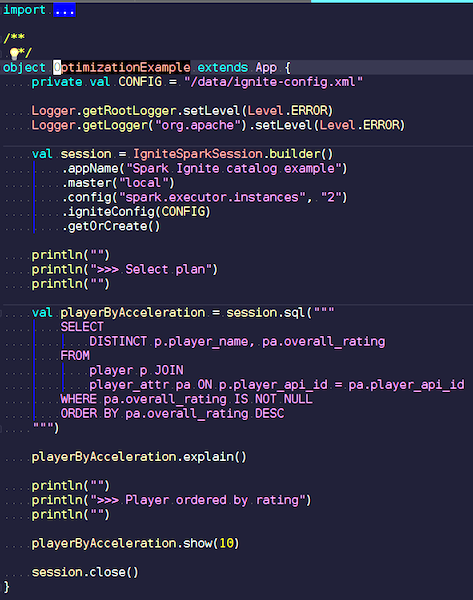 OptimizationExample.scala
OptimizationExample.scalaKami membuat sesi IgniteSpark di mana semua kemampuan optimasi kami sudah termasuk secara otomatis. Di sini permintaannya adalah ini: temukan para pemain dengan peringkat tertinggi dan tampilkan nama mereka. Di tabel pemain, atribut dan datanya. Kami bergabung, memfilter data sampah dan menampilkan pemain dengan peringkat tertinggi. Mari kita lihat jenis rencana apa yang kita dapatkan setelah optimasi, dan tunjukkan hasil dari query ini.
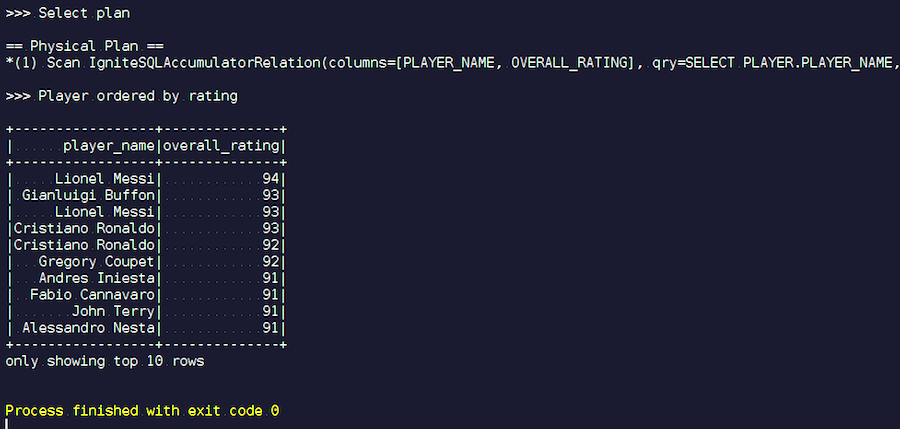
Kita mulai. Kami melihat nama keluarga yang akrab: Messi, Buffon, Ronaldo, dll. Ngomong-ngomong, beberapa karena alasan tertentu bertemu dalam dua samaran - baik Messi dan Ronaldo. Pecinta sepak bola mungkin merasa aneh bahwa pemain tak dikenal muncul di daftar. Ini adalah kiper, pemain dengan karakteristik agak tinggi - dengan latar belakang pemain lain. Sekarang kita melihat rencana permintaan yang dieksekusi. Di Spark, hampir tidak ada yang dilakukan, yaitu, kami mengirim seluruh permintaan lagi ke Ignite.
Pengembangan Apache Apache
Proyek kami adalah produk open source, jadi kami selalu senang dengan tambalan dan umpan balik dari pengembang. Bantuan, umpan balik, tambalan Anda sangat kami harapkan. Kami sedang menunggu mereka. 90% komunitas Ignite berbahasa Rusia. Sebagai contoh, bagi saya, sampai saya mulai bekerja di Apache Ignite, bukan pengetahuan bahasa Inggris terbaik adalah pencegah. Hampir tidak layak menulis dalam bahasa Rusia di daftar dev, tetapi bahkan jika Anda menulis sesuatu yang salah, mereka akan menjawab dan membantu Anda.
Apa yang dapat ditingkatkan pada integrasi ini? Bagaimana saya dapat membantu jika Anda memiliki keinginan seperti itu? Daftar di bawah ini. Tanda bintang menunjukkan kompleksitas.

Untuk menguji pengoptimalan, Anda perlu menulis tes dengan kueri yang kompleks. Di atas, saya menunjukkan beberapa pertanyaan yang jelas. Jelas bahwa jika Anda menulis banyak pengelompokan dan banyak bergabung, maka sesuatu dapat jatuh. Ini adalah tugas yang sangat sederhana - datang dan lakukanlah. Jika kami menemukan bug berdasarkan hasil tes, bug tersebut harus diperbaiki. Akan lebih sulit di sana.
Tugas lain yang jelas dan menarik adalah integrasi Spark dengan klien tipis. Awalnya dapat menentukan beberapa set alamat IP, dan ini cukup untuk bergabung dengan cluster Ignite, yang nyaman dalam kasus integrasi dengan sistem eksternal. Jika Anda tiba-tiba ingin bergabung dengan solusi untuk masalah ini, saya pribadi akan membantu dengannya.
Jika Anda ingin bergabung dengan komunitas Apache Ignite, berikut adalah beberapa tautan bermanfaat:
Kami memiliki daftar pengembang yang responsif, yang akan membantu Anda. Ini masih jauh dari ideal, tetapi dibandingkan dengan proyek lain itu benar-benar hidup.
Jika Anda tahu Java atau C ++, Anda sedang mencari pekerjaan dan ingin mengembangkan Open Source (Apache Ignite, Apache Kafka, Tarantool, dll.) Tulis di sini: join-open-source@sberbank.ru.