Pernah saya sudah menulis di sini tentang pindah dari Asia ke Eropa , dan sekarang saya ingin menulis apa yang saya lakukan di Eropa ini. Ada profesi seperti itu - DevOps , atau lebih tepatnya tidak, tetapi kebetulan inilah yang saya lakukan sekarang. Sekarang untuk mengatur semua yang berjalan di buruh pelabuhan, kami menggunakan seorang pemilik peternakan , yang juga saya tulis . Tetapi kemudian hal yang mengerikan terjadi, Rancher 2.0 keluar dan pindah ke kubernetes (selanjutnya hanya k8) dan karena k8s sekarang benar-benar standar untuk mengelola cluster, ada keinginan untuk membangun seluruh infrastruktur lagi dengan blackjack dan pustakawan. Apa yang menambah kesedihan pada hal ini adalah bahwa perusahaan terus-menerus mempekerjakan spesialis yang berbeda dari berbagai negara dan dengan tradisi yang berbeda, dan seseorang membawa puppet , seseorang ansible daripada yang ansible , dan seseorang umumnya percaya bahwa Makefile + bash adalah segalanya bagi kita. Karena itu, tidak ada pendapat tegas tentang bagaimana segala sesuatu harus bekerja, tetapi saya benar-benar ingin.
Kebun binatang teknologi dan alat seperti itu sebelumnya dirakit:

Manajemen infrastruktur
- Minikube
- Rke
- Bentuk Terra
- Kops
- Kubespray
- Mungkin
Manajemen aplikasi
- Kubernetes
- Peternak
- Kubectl
- Helm
- Confd
- Kompose
- Jenkins
Penebangan dan Pemantauan
- Pencarian Elastics
- Kibana
- Lancar sedikit
- Telegraf
- Influxdb
- Zabbix
- Prometheus
- Grafana
- Kapasitor
Selanjutnya, saya akan mencoba menjelaskan secara singkat setiap titik di kebun binatang ini, menjelaskan mengapa perlu dan mengapa solusi ini dipilih. Bahkan, hampir semua barang bisa diganti dengan selusin analog dan kami masih belum sepenuhnya yakin akan pilihannya, jadi jika ada yang punya pendapat atau rekomendasi, saya akan membacanya di komentar dengan senang hati.
Kubernetes akan menjadi pusat dari segalanya karena sekarang ini benar-benar merupakan solusi yang sama sekali tidak memiliki alternatif, yang didukung oleh semua penyedia dari Amazon dan Microsoft ke mail.ru. Bagaimana alternatif dipertimbangkan
Swarm - yang tidak pernah lepas landasNomad - yang tampaknya ditulis oleh orang asing untuk predatorCattle adalah mesin dari ranger 1.x, di mana kita sekarang hidup, pada prinsipnya, semuanya baik-baik saja, tetapi peternak telah meninggalkannya demi k8 sehingga tidak akan ada pengembangan.
Pembangunan infrastruktur
Pertama, kita perlu membuat infrastruktur, dan menggunakan cluster K8 di atasnya. Ada beberapa opsi, semuanya bekerja dan karenanya sulit untuk memilih yang terbaik.
Minikube adalah opsi yang bagus untuk memulai cluster di mesin pengembang, untuk tujuan pengujian.
Rke - Rancher kubernetes engine, sesederhana sebuah pintu, konfigurasi minimal untuk membuat tampilan cluster
nodes: - address: localhost role: [controlplane,worker,etcd]
Dan itu saja, ini cukup untuk memulai cluster pada mesin lokal, sementara itu memungkinkan Anda untuk membuat cluster HA siap produksi, mengubah konfigurasi, meng-upgrade cluster, membuang database etcd dan banyak lagi.
Kops - tidak hanya memungkinkan Anda untuk membuat cluster, tetapi juga membuat pra-instans di aws atau gce. Ini juga memungkinkan Anda untuk membuat konfigurasi untuk terraform. Alat yang menarik, tetapi kami belum mengambil root. Itu sepenuhnya diganti oleh terraform + rke sementara itu lebih sederhana dan lebih fleksibel.
Kubespray - pada kenyataannya, itu hanya peran yang memungkinkan yang menciptakan cluster K8, sangat kuat, fleksibel, dapat dikonfigurasi. Ini praktis merupakan solusi default untuk menggunakan k8.
Terraform adalah alat untuk membangun infrastruktur di aws, biru tua atau banyak tempat lain. Fleksibel, stabil - Saya sarankan.
Ansible sebenarnya bukan tentang k8s tetapi kami juga menggunakannya di mana-mana dan di sini: tweak konfigurasi, instal / perbarui perangkat lunak, distribusikan sertifikat. Murah dan ceria.
Manajemen aplikasi
Jadi, kami memiliki sebuah kluster, sekarang kami perlu memulai sesuatu yang bermanfaat di dalamnya, yang tersisa adalah pertanyaan tentang bagaimana melakukan ini.
Opsi satu: gunakan bare k8s semua deploy menggunakan kubectl . Pada prinsipnya, opsi ini memiliki hak untuk hidup. Kubectl adalah alat yang cukup kuat yang memungkinkan kita melakukan semua yang kita butuhkan, termasuk penyebaran, peningkatan, pemantauan keadaan saat ini, mengubah konfigurasi dengan cepat, melihat log, dan menghubungkan ke wadah tertentu. Tetapi kadang-kadang saya ingin semuanya menjadi sedikit lebih nyaman, jadi kami melanjutkan.
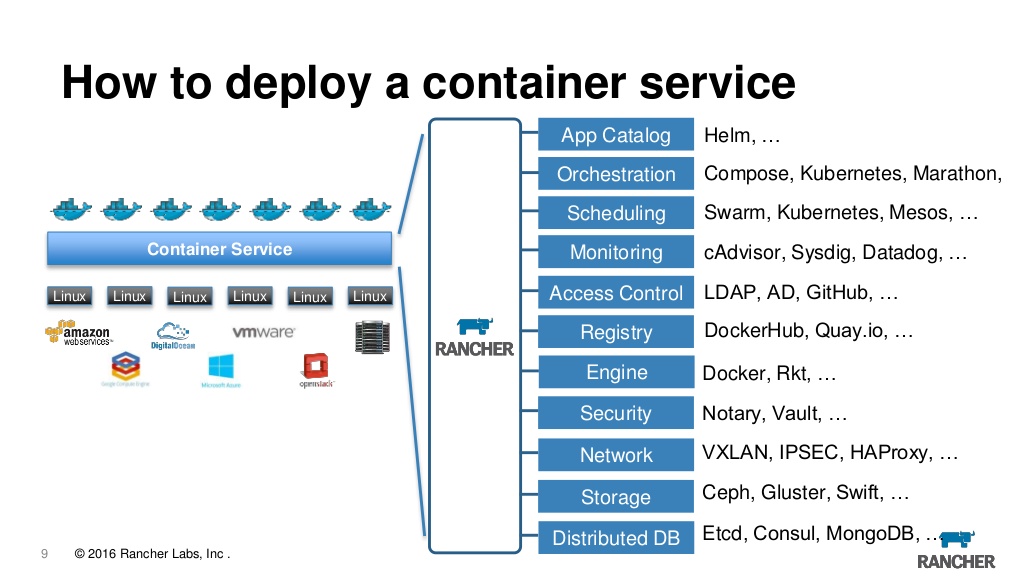
Bahkan, sekarang peternak adalah moncong web untuk mengelola K8 dan pada saat yang sama banyak roti kecil yang menambah kenyamanan. Di sini Anda dapat melihat log, akses ke konsol dan mengonfigurasi dan memutakhirkan aplikasi dan kontrol akses berbasis peran dan server metadata internal, alarm, pengalihan log, manajemen rahasia, dan banyak lagi. Kami telah menggunakan rancher versi pertama selama beberapa tahun sekarang dan benar-benar puas dengannya, walaupun kita harus mengakui bahwa ketika beralih ke k8 pertanyaan muncul apakah kita benar-benar membutuhkannya. Sangat menyenangkan bahwa Anda dapat mengimpor gugus yang sebelumnya dibuat ke peternak, dan dari penyedia apa pun, yaitu, Anda dapat mengimpor gugus dari EKS dari biru dan dibuat secara lokal dan mengarahkan mereka dari satu tempat ke satu server. Selain itu, jika Anda tiba-tiba bosan, Anda bisa menghancurkan server dan terus menggunakan cluster secara langsung melalui kubeclt atau alat lainnya.
Konsep yang sangat benar dari semuanya sebagai kode sekarang populer. Misalnya, infrastruktur sebagai kode diimplementasikan menggunakan terraform , perakitan sebagai kode diimplementasikan melalui jenkins pipeline . Sekarang giliran telah datang ke aplikasi. Instalasi dan konfigurasi aplikasi juga harus dijelaskan dalam beberapa manifes dan disimpan di git. Versi Rancher 1.x menggunakan docker-compose.yml standar dan semuanya baik-baik saja, tetapi ketika mereka pindah ke k8 mereka beralih ke helm charts . Helm adalah berbagi yang sangat mengerikan dengan logika dan arsitektur yang aneh. Ini adalah salah satu proyek dari mana perasaan itu tetap ditulis oleh predator untuk orang asing atau sebaliknya. Satu-satunya masalah adalah bahwa di dunia helm k8s tidak ada alternatif dan ini adalah standar. Karena itu, kita akan ditusuk untuk menangis, tetapi terus menggunakan helm. Dalam versi 3.x, pengembang berjanji untuk menulis ulang dari awal, membuang semua keanehan dan menyederhanakan arsitektur. Saat itulah kita akan menyembuhkan, tetapi untuk sekarang kita akan makan apa yang ada.
Kita juga perlu setidaknya menyebutkan jenkins sini, itu tidak berhubungan langsung dengan topik kubernetis, tetapi dengan bantuannya aplikasi dikerahkan ke cluster. Dia, dia bekerja dan dia adalah topik untuk artikel terpisah.
Pemantauan
Sekarang kami memiliki sebuah cluster dan bahkan memutar beberapa jenis aplikasi, tampaknya Anda dapat menghembuskan napas, tetapi pada kenyataannya, semuanya baru saja dimulai. Seberapa stabil aplikasi kita? Seberapa cepat Apakah dia memiliki sumber daya yang cukup? Apa yang umumnya terjadi di cluster?
Ya, topik selanjutnya adalah pemantauan dan pencatatan. Hanya ada tiga jawaban yang pasti. Simpan log di elasticsearch , tonton melalui kibana draw graphics di grafana . Untuk semua pertanyaan lain, ada selusin jawaban yang benar.
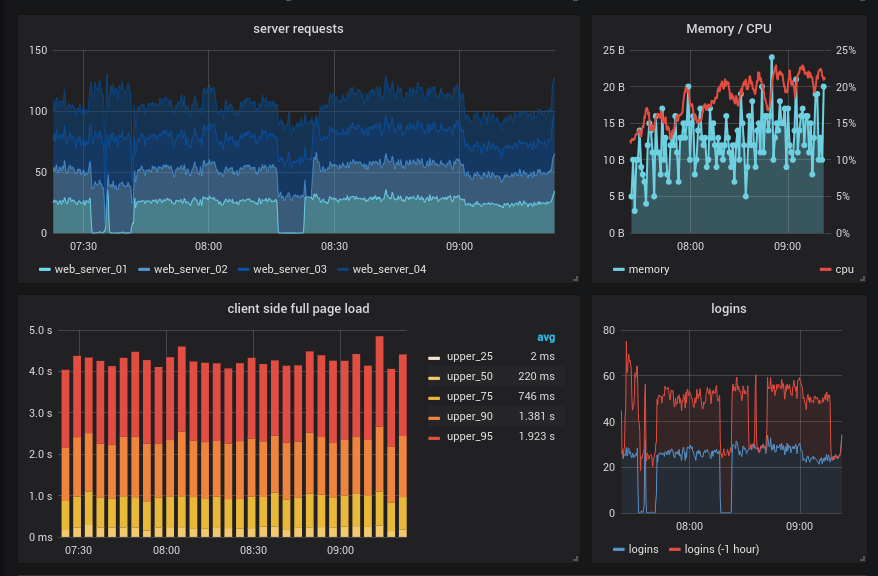
Di sini kita mulai dengan grafana sendiri, tidak praktis apa-apa, tetapi dapat diikat seperti wajah cantik ke salah satu sistem yang dijelaskan di bawah ini dan dapatkan grafik yang indah dan terkadang kosong, selain itu, Anda dapat segera memasang alarm, tetapi lebih baik menggunakan solusi lain untuk ini, misalnya prometheus alertmanager dan ElastAlert .
Dari sudut pandang saya, saat ini adalah agregator dan router terbaik dari log, selain itu, langsung dari kotak, ia memiliki dukungan k8. Ada juga Fluentd tetapi ditulis dalam rubel dan menarik terlalu banyak kode warisan, yang membuatnya jauh lebih tidak menarik. Jadi, jika Anda memerlukan modul tertentu dari fluentd yang belum di-porting ke fluent-bit, gunakanlah, secara keseluruhan - bit adalah pilihan terbaik. Lebih cepat, lebih stabil, mengkonsumsi lebih sedikit memori. Memungkinkan Anda mengumpulkan log dari semua atau dari wadah yang dipilih, memfilternya, memperkayanya dengan menambahkan data spesifik ke kubernetis dan mengirimkan semuanya ke elasticsearch atau ke banyak repositori lainnya. Jika Anda membandingkannya dengan logstash + docker-bit + file-bit tradisional logstash + docker-bit + file-bit solusi ini pasti lebih baik dalam segala hal. Secara historis, kami masih menggunakan logspout + logstash tetapi lancar-sedikit pasti menang.
Sistem pemantauan yang ditulis khusus untuk arsitektur layanan mikro. Standar de facto di industri, apalagi, ada juga proyek yang disebut Prometheus Operator , yang ditulis khusus untuk k8. Semua orang memutuskan apa yang harus dipilih, tetapi lebih baik memulainya dengan telanjang hati, hanya untuk memahami logika karyanya, itu sangat berbeda dari sistem yang biasa. Kami juga perlu menyebutkan node-exporter yang memungkinkan Anda mengumpulkan metrik level mesin dan eksportir-rometer prometheus yang memungkinkan Anda mengumpulkan metrik melalui api pemilik peternakan. Secara umum, jika Anda memiliki cluster di kubernetes, maka prometheus harus dimiliki.
Seseorang dapat berhenti di sini, tetapi secara historis, kami memiliki beberapa sistem pemantauan lagi. Pertama, sangat nyaman bagi zabbix untuk melihat semua masalah dari seluruh infrastruktur pada satu panel. Kehadiran penemuan otomatis memungkinkan Anda untuk dengan cepat menemukan dan menambahkan jaringan baru, node, layanan, dan umumnya hampir semua hal untuk pemantauan, ini membuatnya lebih dari alat yang nyaman untuk memantau infrastruktur yang dinamis. Selain itu, dalam versi 4.0, kumpulan metrik dari eksportir prometheus ditambahkan ke zabbix dan ternyata semua ini dapat diintegrasikan dengan sangat indah ke dalam satu sistem. Meskipun masih belum ada jawaban pasti apakah perlu menyeret zabbix ke dalam cluster k8s, pasti menarik untuk dicoba.
Sama seperti alternatif, Anda dapat menggunakan TIG (telegraf + influxdb + grafana) mudah dikonfigurasikan, ini berfungsi secara stabil, memungkinkan Anda untuk menggabungkan metrik dengan wadah, aplikasi, simpul, dll. Tetapi pada dasarnya menduplikasi fungsi prometheus, dan hanya ada satu yang tersisa.
Dan ternyata sebelum Anda memulai sesuatu yang berguna, Anda perlu menginstal dan mengkonfigurasi pengikatan dari beberapa lusin layanan dan alat bantu. Pada saat yang sama, artikel itu tidak mengangkat masalah mengelola data yang persisten, rahasia, dan hal-hal aneh lainnya, yang masing-masing dapat ditarik ke publikasi terpisah.
Dan bagaimana Anda melihat infrastruktur yang ideal?
Jika Anda memiliki pendapat, silakan tulis di komentar, atau mungkin bahkan bergabung dengan tim kami dan bantu kumpulkan semuanya.