Suatu kali, dalam sebuah wawancara, seorang musisi Rusia yang terkenal mengatakan: "Kami sedang mengerjakan berbohong dan meludah di langit-langit." Saya tidak bisa tidak setuju dengan pernyataan ini, karena fakta bahwa kemalasan adalah kekuatan pendorong dalam pengembangan teknologi tidak dapat diperdebatkan. Memang, hanya pada abad terakhir kita telah beralih dari mesin uap ke industrialisasi digital, dan sekarang kecerdasan buatan, yang digambarkan oleh penulis fiksi ilmiah dan futurolog abad terakhir, menjadi kenyataan dunia kita yang semakin meningkat setiap hari. Game komputer, perangkat seluler, jam tangan pintar, dan banyak lagi pada dasarnya menggunakan algoritma yang terkait dengan mekanisme pembelajaran mesin.
Saat ini, karena pertumbuhan kemampuan komputasi prosesor grafis dan sejumlah besar data yang telah muncul, jaringan saraf telah mendapatkan popularitas, menggunakan mana mereka memecahkan masalah klasifikasi dan regresi, melatih mereka pada data yang disiapkan. Banyak artikel telah ditulis tentang bagaimana melatih jaringan saraf dan kerangka kerja mana yang digunakan untuk ini. Tetapi ada tugas sebelumnya yang juga harus diselesaikan, dan ini adalah tugas membentuk sebuah array data - dataset, untuk pelatihan lebih lanjut jaringan saraf. Ini akan dibahas dalam artikel ini.
Belum lama ini, ada kebutuhan untuk membangun sebuah pengelompokan akustik dari kebisingan mobil yang mampu mengekstraksi data dari aliran audio yang umum: pecahan kaca, pintu pembuka dan pengoperasian mesin mobil dalam berbagai mode. Pengembangan classifier itu tidak sulit, tetapi di mana mendapatkan dataset sehingga memenuhi semua persyaratan?
Google datang ke penyelamatan (jangan tersinggung Yandex - saya akan berbicara tentang keuntungannya sedikit kemudian), dengan bantuan yang memungkinkan untuk memilih beberapa cluster utama yang berisi data yang diperlukan. Saya ingin mencatat sebelumnya bahwa sumber-sumber yang ditunjukkan dalam artikel ini mencakup sejumlah besar informasi akustik, dengan berbagai kelas, memungkinkan Anda untuk membuat dataset untuk berbagai tugas. Sekarang kita beralih ke ikhtisar sumber-sumber ini.
Freesound.org
Kemungkinan besar,
Freesound.org menyediakan volume terbesar data akustik, menjadi tempat penyimpanan sampel musik berlisensi, yang saat ini memiliki lebih dari 230.000 salinan efek suara. Setiap sampel suara dapat didistribusikan di bawah lisensi yang berbeda, oleh karena itu lebih baik untuk membiasakan diri dengan
perjanjian lisensi terlebih dahulu. Misalnya, lisensi
nol (cc0) memiliki status "Tidak ada hak cipta", dan memungkinkan Anda untuk menyalin, mengubah, dan mendistribusikan, termasuk penggunaan komersial, dan memungkinkan Anda untuk menggunakan data secara mutlak secara hukum.
Untuk kenyamanan menemukan elemen informasi akustik di berbagai freesound.org, pengembang telah menyediakan
API yang dirancang untuk menganalisis, mencari, dan mengunduh data dari repositori. Untuk mengatasinya, Anda perlu mendapatkan akses, untuk ini Anda harus pergi ke
formulir dan mengisi semua bidang yang diperlukan, setelah itu kunci individu akan dihasilkan.

Pengembang Freesound.org menyediakan
API untuk berbagai bahasa pemrograman, sehingga memungkinkan untuk memecahkan masalah yang sama dengan alat yang berbeda. Daftar bahasa dan tautan yang didukung untuk mengaksesnya di GitHub tercantum di bawah ini.
Untuk mencapai tujuan tersebut, python digunakan, karena bahasa pemrograman pengetikan dinamis yang indah ini mendapatkan popularitasnya karena kemudahan penggunaannya, sepenuhnya menghapus mitos kompleksitas pengembangan perangkat lunak.
Modul untuk bekerja dengan freesound.org untuk python dapat diklon dari repositori github.com.
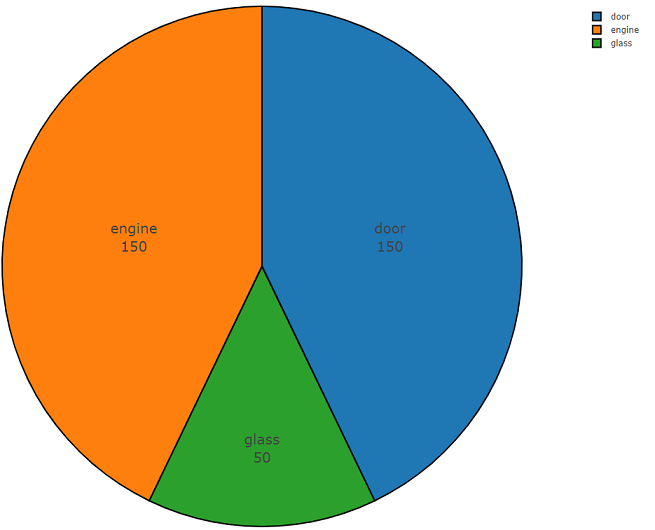
Di bawah ini adalah kode dua bagian yang menunjukkan kemudahan penggunaan API ini. Bagian pertama dari kode program melakukan tugas analisis data, yang hasilnya adalah kepadatan distribusi data untuk setiap kelas yang diminta, dan bagian kedua mengunggah data dari repositori freesound.org untuk kelas yang dipilih. Kepadatan distribusi saat mencari informasi akustik dengan kata kunci
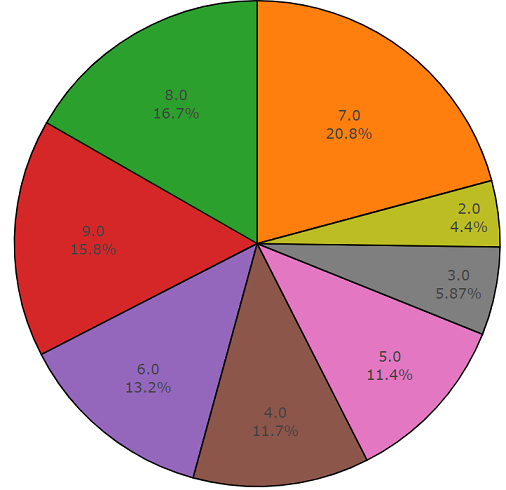
kaca, mesin, pintu disajikan di bawah ini dalam diagram lingkaran sebagai contoh.
Kode sampel analisis data Freesound.org
import plotly import plotly.graph_objs as go import freesound import os import termcolor
Kode contoh untuk mengunduh data freesound.org
Fitur freesound adalah bahwa analisis data audio dapat dilakukan tanpa mengunduh file audio, memungkinkan Anda untuk mendapatkan MFCC, energi spektral, centroid spektral dan koefisien lainnya. Baca lebih lanjut tentang informasi tingkat rendah dalam
dokumentasi freesound.ord .
Menggunakan API freesound.org, waktu yang dihabiskan untuk mengambil dan mengunduh data diminimalkan, memungkinkan Anda untuk menghemat jam kerja mempelajari sumber informasi lain, karena akurasi tinggi pengklasifikasi akustik memerlukan dataset besar dengan variabilitas besar, mewakili data dengan harmonik berbeda pada satu dan kelas acara yang sama.
YouTube-8M dan AudioSet
Saya pikir youtube tidak terlalu diperlukan dalam presentasi, tetapi bagaimanapun, Wikipedia memberi tahu kami bahwa youtube adalah situs hosting video yang menyediakan pengguna dengan layanan tampilan video, lupa untuk mengatakan bahwa youtube adalah database besar, dan sumber ini harus digunakan dalam pembelajaran mesin , dan Google Inc memberi kami proyek yang disebut
YouTube-8M Dataset .
YouTube-8M Dataset adalah kumpulan data yang mencakup lebih dari satu juta file video dari YouTube dalam kualitas tinggi, untuk memberikan informasi yang lebih akurat, pada Mei 2018, ada 6.1M video dengan 3862 kelas. Dataset ini dilisensikan di bawah
Creative Commons Attribution 4.0 International (CC BY 4.0) . Lisensi semacam itu memungkinkan Anda untuk menyalin dan mendistribusikan materi pada media dan format apa pun.
Anda mungkin bertanya-tanya: di mana data video masuk ketika informasi akustik diperlukan untuk tugas tersebut, dan Anda akan sangat benar. Faktanya adalah bahwa Google tidak hanya menyediakan konten video, tetapi juga secara terpisah mengalokasikan sub proyek dengan data audio yang disebut
AudioSet .
 AudioSet
AudioSet - menyediakan kumpulan data yang diperoleh dari video YouTube, di mana banyak data disajikan dalam hierarki kelas menggunakan
file ontologi , representasi grafisnya terletak di bawah.
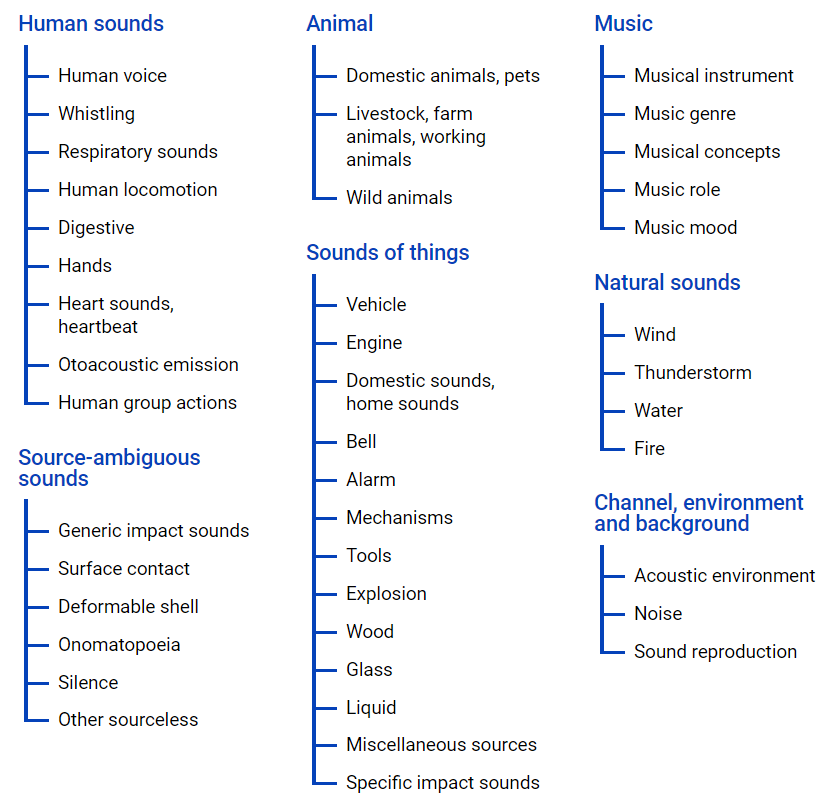
File ini memungkinkan Anda untuk mendapatkan gagasan tentang penyatuan kelas, serta akses ke video youtube. Untuk mengunggah data dari ruang Internet, Anda dapat menggunakan modul python - youtube-dl, yang memungkinkan Anda mengunduh konten audio atau video, tergantung pada tugas yang diperlukan.
AudioSet mewakili sebuah cluster yang dibagi menjadi tiga set: tes, pelatihan (seimbang) dan pelatihan (tidak seimbang)
dataset .
Mari kita lihat cluster ini dan menganalisis masing-masing set ini secara terpisah untuk memiliki gagasan tentang kelas yang terkandung.
Pelatihan (seimbang)Menurut dokumentasi,
set data ini terdiri dari
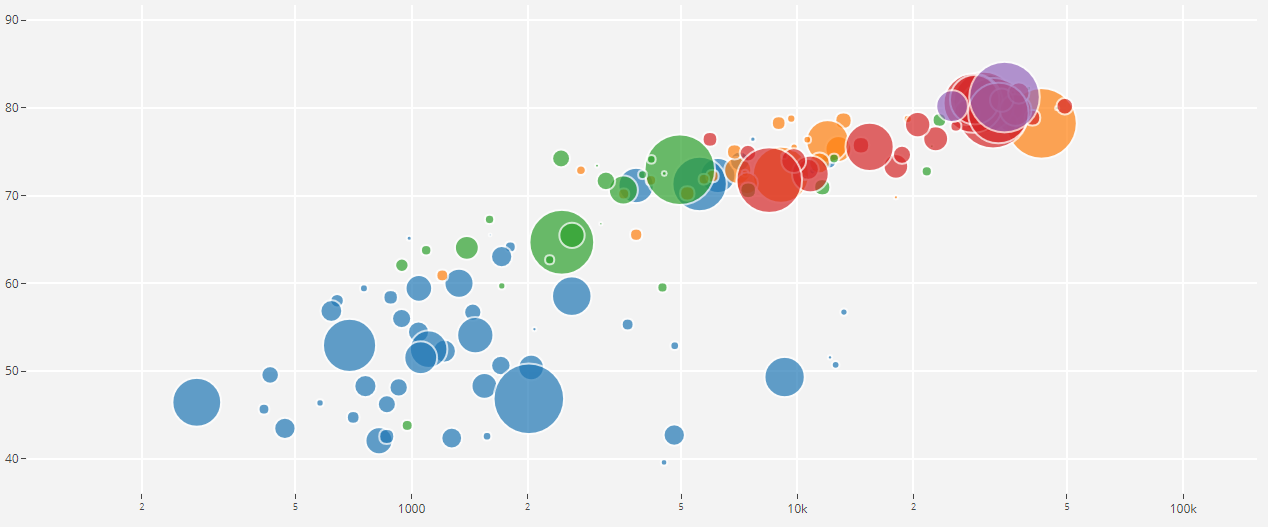
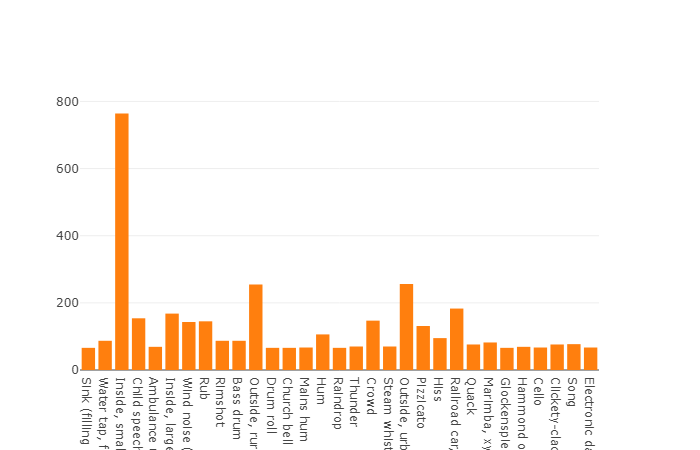
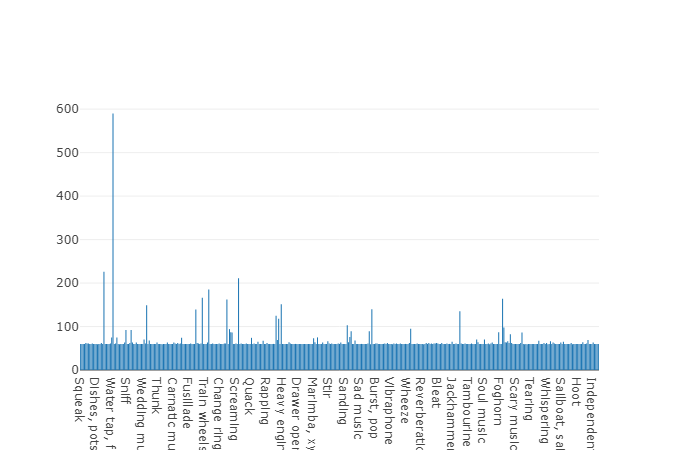
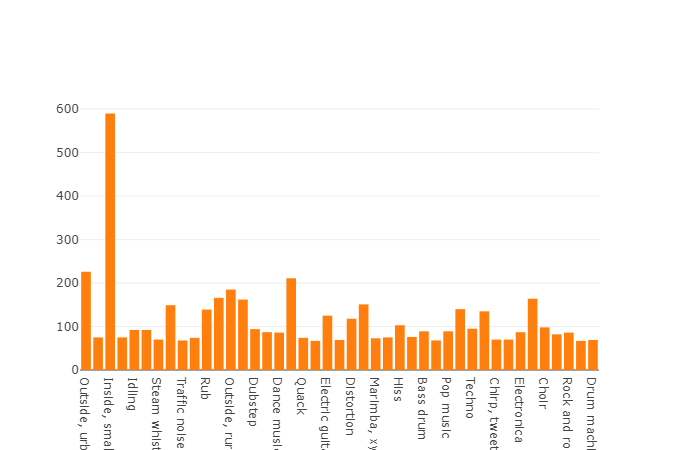
22.176 segmen yang diperoleh dari berbagai video yang dipilih oleh kata kunci, yang menyediakan setidaknya 59 salinan untuk setiap kelas. Jika kita melihat kepadatan distribusi kelas root dalam hierarki set, kita akan melihat bahwa kelas Musik adalah grup terbesar file audio.
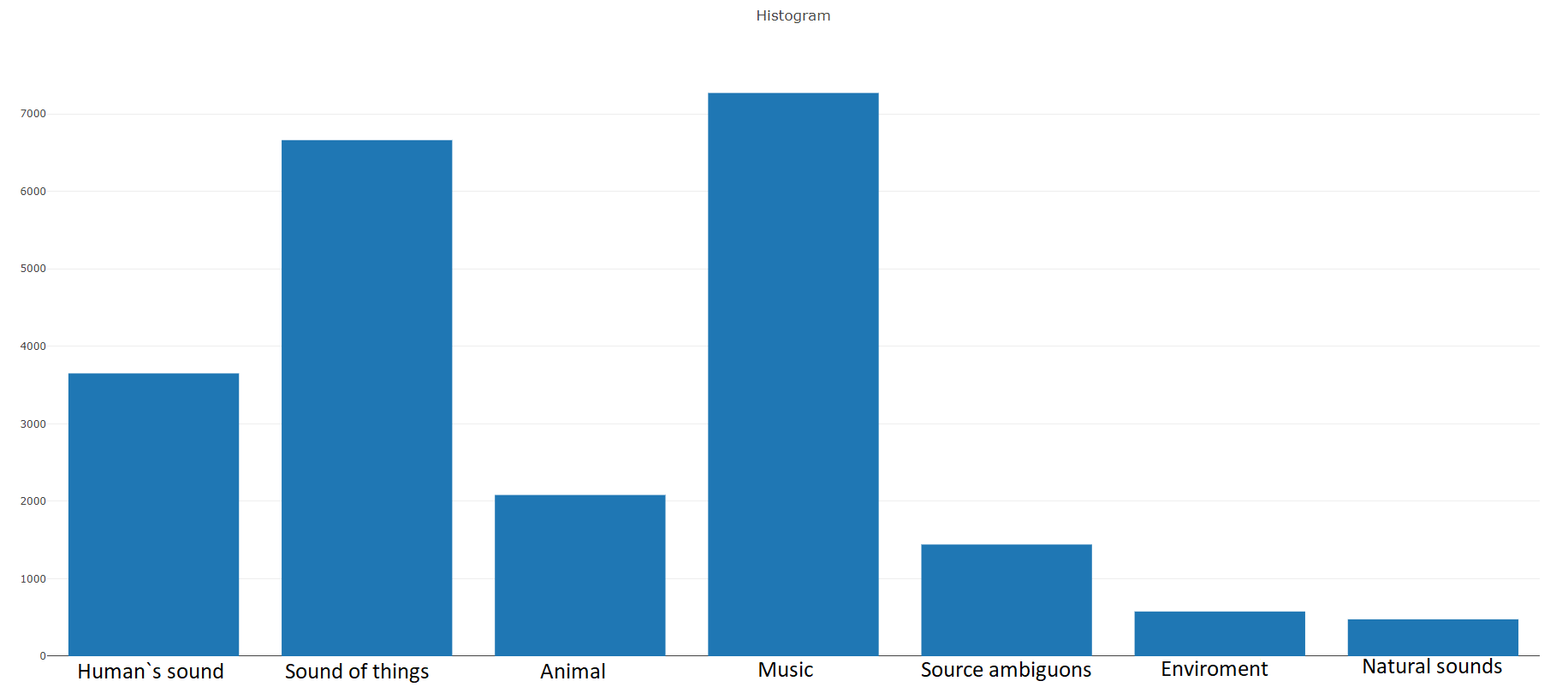
Kelas terorganisir didekomposisi menjadi himpunan bagian kelas, memungkinkan Anda untuk mendapatkan informasi lebih rinci saat menggunakannya. Set pelatihan yang seimbang ini memiliki kepadatan distribusi yang jelas bahwa keseimbangan ada, tetapi juga kelas-kelas individual sangat berbeda dari pandangan umum.
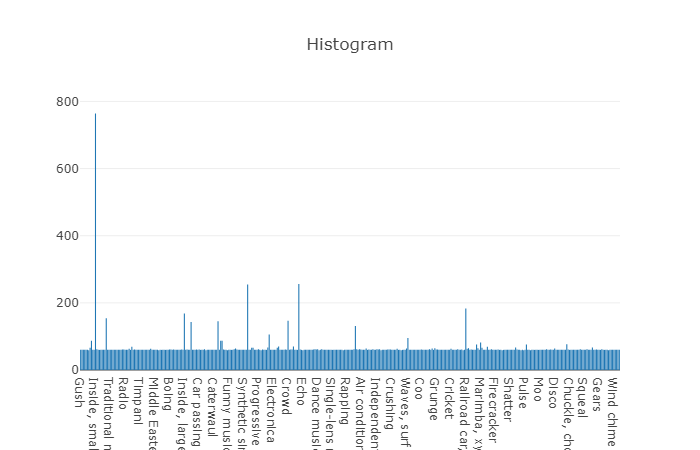
Distribusi kelas yang jumlah elemennya melebihi nilai rata-rata
Durasi rata-rata dari masing-masing file audio adalah 10 detik, informasi lebih rinci disajikan oleh diagram disk, yang menunjukkan bahwa durasi beberapa file berbeda dari set utama. Bagan ini juga disajikan.
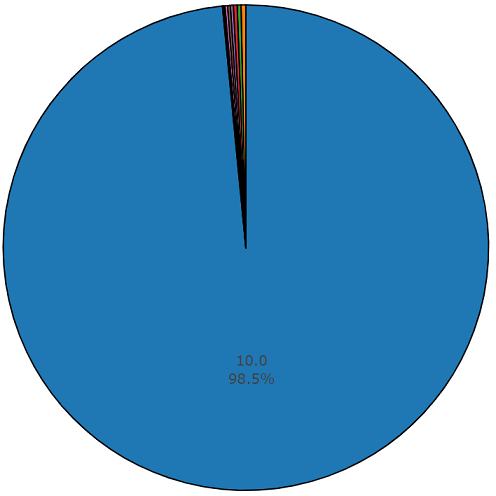
Diagram satu setengah persen durasi non-rata-rata dari set audio seimbang
 Pelatihan (tidak seimbang)
Pelatihan (tidak seimbang)Keuntungan dari dataset ini adalah ukurannya. Bayangkan saja, menurut dokumentasi, set ini mencakup 2.042.985 segmen dan, dibandingkan dengan dataset seimbang, mewakili variabilitas yang hebat, tetapi entropi set ini jauh lebih tinggi.
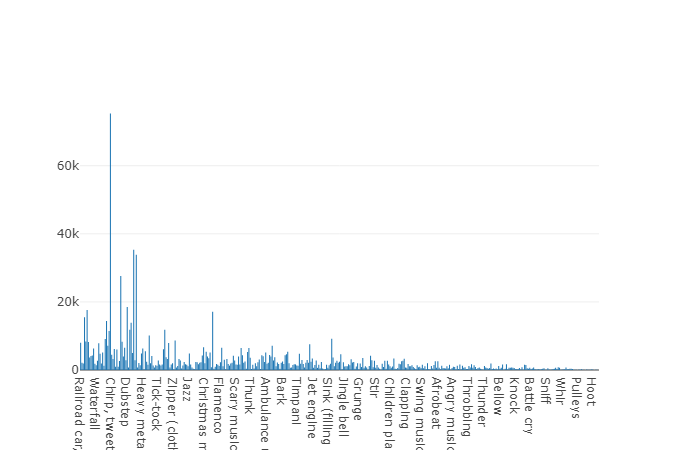
Dalam set ini, durasi rata-rata dari masing-masing file audio juga sama dengan 10 detik, diagram disk untuk dataset ini disajikan di bawah ini.
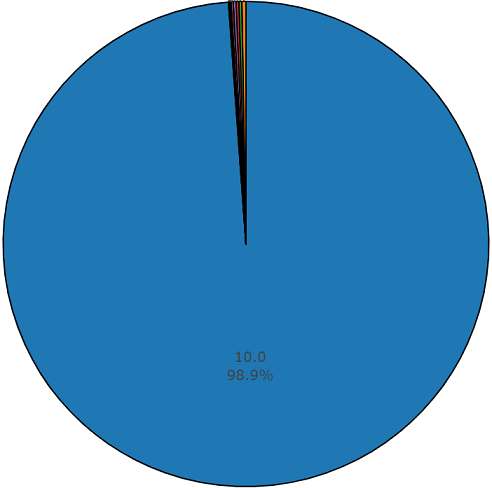
Bagan durasi non-rata-rata dari set audioset yang tidak seimbang
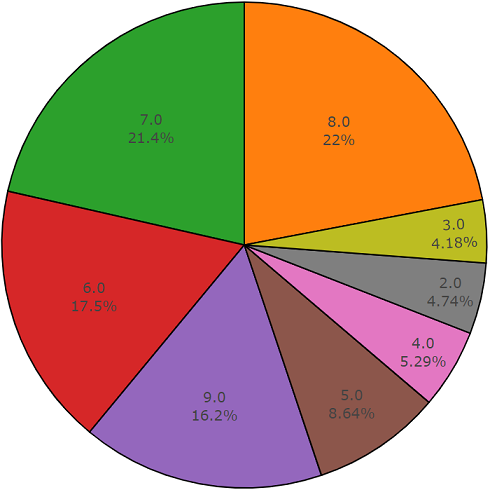
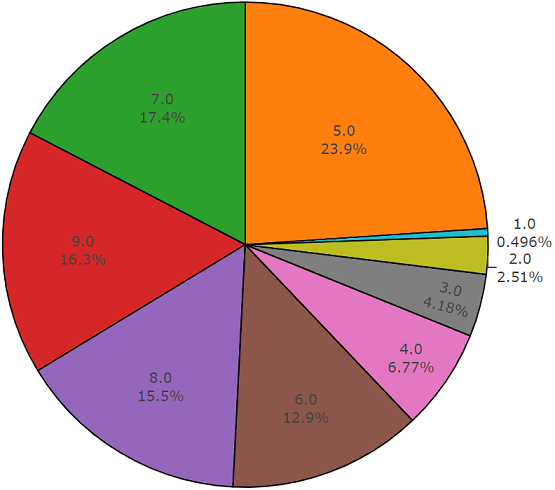 Set tes
Set tesSet ini sangat mirip dengan set seimbang dengan keuntungan bahwa elemen-elemen set ini tidak berpotongan. Distribusi mereka disajikan di bawah ini.
Distribusi kelas yang jumlah elemennya melebihi nilai rata-rata
Durasi rata-rata satu segmen dari dataset ini juga sama dengan 10 detik
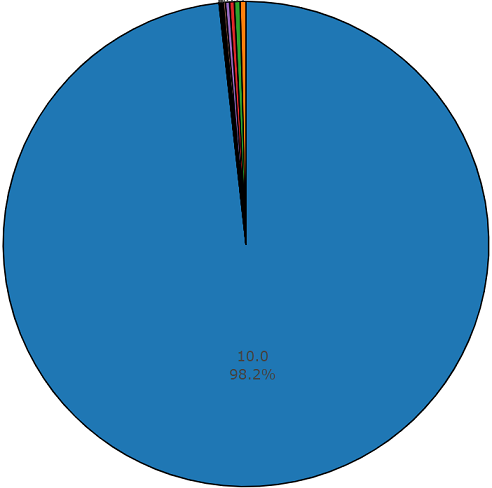
dan sisanya memiliki durasi yang ditunjukkan pada diagram disk
Contoh kode untuk menganalisis dan mengunduh data akustik sesuai dengan dataset yang dipilih:
import plotly import plotly.graph_objs as go from collections import Counter import numpy as np import os import termcolor import csv import json import youtube_dl import subprocess
Untuk memperoleh informasi lebih rinci tentang analisis data audioset, atau mengunggah data ini dari ruang yotube sesuai dengan
file ontologi dan
set audioset yang dipilih, kode program tersedia secara bebas ke
repositori GitHub .
urbansound
Urbansound adalah salah satu set data terbesar dengan peristiwa suara yang ditandai, yang kelasnya termasuk lingkungan perkotaan. Set ini disebut taksonomi (kategorikal), yaitu setiap kelas dibagi ke dalam subkelasnya. Orang banyak seperti itu dapat direpresentasikan dalam bentuk pohon.
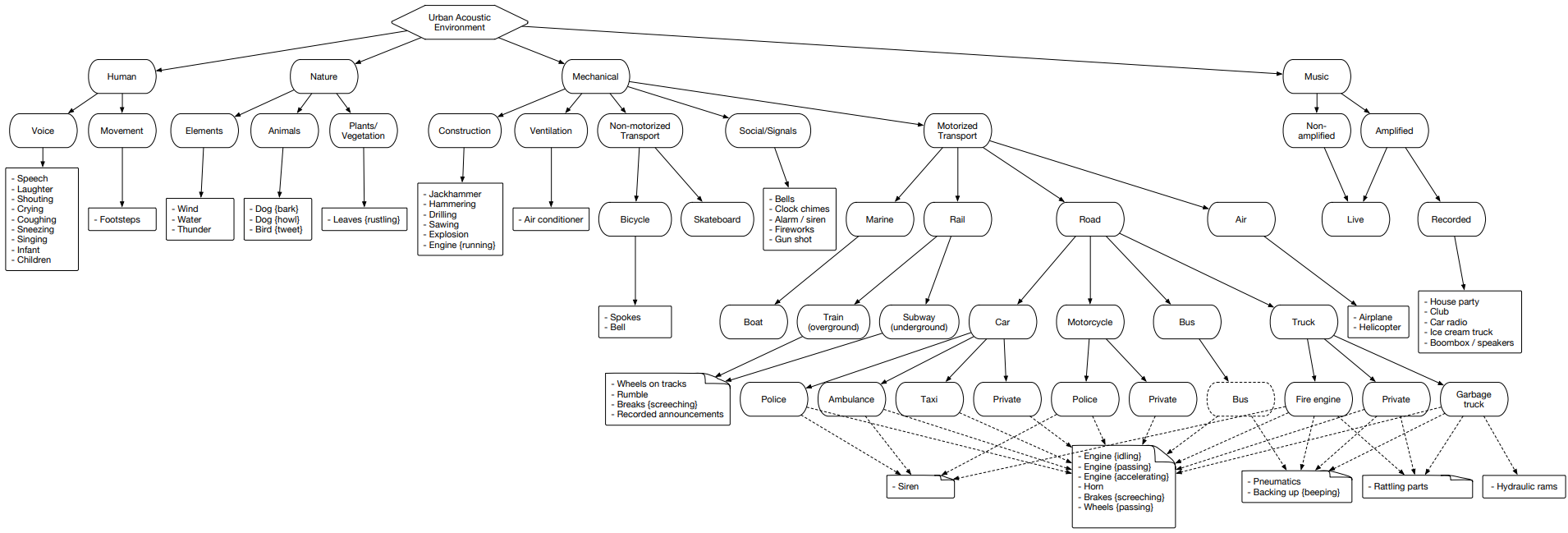
Untuk mengunggah data urbansound untuk digunakan nanti, buka saja halaman itu dan klik
unduh .
Karena tugas tidak perlu menggunakan semua subclass, dan hanya satu kelas saja yang diperlukan terkait dengan mobil, pertama-tama perlu untuk menyaring kelas yang diperlukan menggunakan file meta yang terletak di root direktori yang diperoleh saat membuka ritsleting file yang diunduh.
Setelah membongkar semua data yang diperlukan dari sumber yang terdaftar, ternyata membentuk dataset yang berisi lebih dari 15.000 file. Volume data yang sedemikian besar memungkinkan kita untuk beralih ke tugas melatih pengklasifikasi akustik, tetapi masih ada masalah yang belum terselesaikan mengenai “kemurnian” data, mis. set pelatihan mencakup data yang tidak terkait dengan kelas-kelas yang diperlukan dari masalah yang sedang dipecahkan. Misalnya, ketika mendengarkan file dari kelas “pemecahan kaca”, Anda dapat menemukan orang-orang berbicara tentang “betapa tidak baiknya memecahkan kaca”. Oleh karena itu, kita dihadapkan dengan tugas menyaring data dan, sebagai alat untuk memecahkan masalah semacam ini, alat sangat cocok, intinya dikembangkan oleh orang-orang Belarusia dan menerima nama aneh "Yandex.Toloka".
Yandex.Toloka
Yandex.Toloka adalah proyek crowdfunding yang dibuat pada tahun 2014 untuk menandai atau mengumpulkan sejumlah besar data untuk digunakan lebih lanjut dalam pembelajaran mesin. Bahkan, alat ini memungkinkan Anda untuk mengumpulkan, menandai, dan memfilter data menggunakan sumber daya manusia. Ya, proyek ini tidak hanya memungkinkan Anda untuk menyelesaikan masalah, tetapi juga memungkinkan orang lain untuk menghasilkan uang. Beban keuangan dalam kasus ini jatuh di pundak Anda, tetapi karena kenyataan bahwa lebih dari 10.000 tolkers bertindak sebagai bagian dari pemain, hasil pekerjaan akan diterima dalam waktu dekat. Deskripsi yang baik tentang pengoperasian alat ini dapat ditemukan di
blog Yandex .
Secara umum, penggunaan naksir tidak terlalu sulit, karena publikasi tugas hanya memerlukan pendaftaran di
situs , jumlah minimum 10 dolar AS, dan tugas yang dijalankan dengan benar. Cara merumuskan tugas dengan benar, Anda dapat melihat
dokumentasi Yandex.Tolok atau tidak ada
artikel buruk
tentang Habr . Dari saya sendiri hingga artikel ini saya ingin menambahkan bahwa meskipun sebuah templat yang sesuai dengan kebutuhan tugas Anda tidak ada, pengembangannya akan memakan waktu tidak lebih dari beberapa jam kerja, dengan istirahat untuk kopi dan rokok, dan hasil dari para pemain dapat diperoleh pada akhir hari kerja.
KesimpulanDalam pembelajaran mesin, ketika memecahkan masalah klasifikasi atau regresi, salah satu tugas utama adalah mengembangkan set data yang andal - sebuah dataset. Dalam artikel ini, sumber informasi dengan sejumlah besar data akustik dipertimbangkan yang memungkinkan untuk membentuk dan menyeimbangkan set data yang diperlukan untuk tugas tertentu. Kode program yang disajikan memungkinkan kami untuk menyederhanakan operasi mengunggah data ke minimum, sehingga mengurangi waktu untuk menerima data dan menghabiskan sisanya untuk pengembangan sebuah classifier.
Adapun tugas saya, setelah mengumpulkan data dari semua sumber yang disajikan dalam artikel ini dan penyaringan data berikutnya, saya berhasil membentuk dataset yang diperlukan untuk melatih pengklasifikasi akustik, yang didasarkan pada jaringan saraf. Saya harap artikel ini memungkinkan Anda dan tim Anda menghemat waktu dan menghabiskannya untuk pengembangan teknologi baru.
PS Modul perangkat lunak yang dikembangkan dalam python, untuk analisis dan pengunggahan data akustik untuk masing-masing sumber yang disajikan, Anda dapat menemukannya di
repositori github