Standarisasi total
Saya menyiapkan bahan ini untuk pidato saya di konferensi dan bertanya kepada direktur teknis kami apa fitur utama Kubernetes untuk organisasi kami. Dia menjawab:
Para pengembang sendiri tidak mengerti berapa banyak pekerjaan ekstra yang mereka lakukan.
Rupanya, dia terinspirasi oleh buku yang baru-baru ini dibaca "Factfulness" - sulit untuk melihat perubahan kecil dan berkelanjutan menjadi lebih baik, dan kita terus-menerus melupakan kemajuan kita.
Tetapi beralih ke Kubernetes jelas tidak signifikan.

Hampir 30 tim kami menjalankan semua atau sebagian beban kerja pada kluster. Sekitar 70% dari lalu lintas HTTP kami dihasilkan oleh aplikasi pada kluster Kubernetes. Ini mungkin merupakan konvergensi teknologi terbesar sejak saya bergabung dengan perusahaan setelah Forward membeli uSwitch pada tahun 2010, ketika kami beralih dari .NET dan server fisik ke AWS dan dari sistem monolitik ke layanan mikro .
Dan itu semua terjadi dengan sangat cepat. Pada akhir 2017, semua tim menggunakan infrastruktur AWS mereka. Mereka mengatur load balancers, instance EC2, pembaruan cluster ECS, dan hal-hal seperti itu. Sedikit lebih dari setahun berlalu, dan semuanya berubah.
Kami menghabiskan sedikit waktu untuk berkumpul, dan sebagai hasilnya, Kubernetes membantu kami memecahkan masalah yang mendesak - cloud kami tumbuh, organisasi menjadi lebih rumit, dan kami berjuang untuk menyesuaikan orang-orang baru ke dalam tim. Kami tidak mengubah organisasi untuk menggunakan Kubernetes. Sebaliknya - kami menggunakan Kubernetes untuk mengubah organisasi.
Pengembang mungkin tidak memperhatikan perubahan besar, tetapi datanya berbicara sendiri. Lebih lanjut tentang ini nanti.
Beberapa tahun yang lalu saya berada di sebuah konferensi Clojure dan mendengar ceramah oleh Michael Nygard tentang arsitektur yang tidak dapat dibawa ke keadaan akhirnya . Dia membuka mata saya. Sistem yang rapi dan tertata terlihat karikatur ketika membandingkan toko-toko TV dengan produk dapur dan arsitektur perangkat lunak berskala besar - sistem yang ada terlihat seperti pisau bisu, dan beberapa jenis bubur keluar bukannya irisan. Tanpa pisau baru, tidak ada yang perlu dipikirkan tentang salad.
Ini tentang bagaimana organisasi memuja proyek tiga tahun: tahun pertama adalah pengembangan dan persiapan, tahun kedua implementasi, yang ketiga kembali. Dalam sebuah ceramah, ia mengatakan bahwa proyek seperti itu biasanya dilakukan terus menerus dan jarang sampai pada akhir tahun kedua (seringkali karena akuisisi oleh perusahaan lain dan perubahan arah dan strategi), sehingga arsitektur yang biasa adalah
stratifikasi perubahan dalam beberapa kemiripan stabilitas.
Dan uSwitch adalah contoh yang bagus.
Kami beralih ke AWS karena berbagai alasan - sistem kami tidak dapat mengatasi beban puncak, dan organisasi terhalang oleh sistem yang terlalu kaku dan tim yang terkait erat yang dibentuk untuk proyek tertentu dan dibagi dengan spesialisasi.
Kami tidak akan berhenti semuanya, mentransfer semua sistem dan memulai dari awal. Kami menciptakan layanan baru dengan proxy melalui load balancer yang ada dan secara bertahap mencekik aplikasi lama . Kami ingin segera menunjukkan pengembalian dan pada minggu pertama kami melakukan pengujian A / B versi pertama dari layanan baru dalam produksi. Sebagai hasilnya, kami mengambil produk jangka panjang dan mulai membentuk tim untuk mereka dari pengembang, desainer, analis, dll. Dan kami segera melihat hasilnya. Pada 2010, ini tampak seperti revolusi nyata.
Tahun demi tahun, kami menambahkan tim, layanan, dan aplikasi baru dan secara bertahap "mencekik" sistem monolitik. Tim berkembang dengan cepat - sekarang mereka bekerja secara independen satu sama lain dan terdiri dari spesialis di semua bidang yang diperlukan. Kami meminimalkan interaksi tim untuk rilis produk. Kami telah mengalokasikan beberapa perintah hanya untuk konfigurasi penyeimbang beban.
Tim sendiri memilih metode pengembangan, alat dan bahasa. Kami menetapkan tugas untuk mereka, dan mereka sendiri menemukan solusi, karena mereka adalah yang terbaik dalam hal ini. Dengan AWS, perubahan ini menjadi lebih mudah.
Kami secara intuitif mengikuti prinsip pemrograman - tim yang terhubung secara longgar satu sama lain akan lebih kecil kemungkinannya untuk berkomunikasi, dan kami tidak perlu menghabiskan sumber daya berharga untuk mengoordinasikan pekerjaan mereka. Semua ini dijelaskan dalam buku Accelerate yang baru diterbitkan.
Hasilnya, seperti dijelaskan oleh Michael Nygard, kami mendapat sistem banyak lapisan perubahan - beberapa sistem diotomatisasi dengan Wayang, beberapa dengan Terraform, di suatu tempat kami menggunakan ECS, di suatu tempat EC2.
Pada tahun 2012, kami bangga dengan arsitektur kami, yang dapat dengan mudah diubah menjadi percobaan , menemukan solusi yang sukses dan mengembangkannya.
Tetapi pada tahun 2017, kami menyadari bahwa banyak yang telah berubah.
AWS sekarang jauh lebih kompleks daripada tahun 2010. Ini menawarkan banyak pilihan dan fitur - tetapi bukan tanpa konsekuensi. Hari ini, tim mana pun yang bekerja dengan EC2 harus memilih VPC, konfigurasi jaringan, dan banyak lagi.
Kami mengalaminya sendiri - tim mulai mengeluh bahwa mereka menghabiskan lebih banyak waktu untuk memelihara infrastruktur, misalnya memperbarui contoh dalam kluster AWS ECS , mesin EC2, beralih dari penyeimbang ELB ke ALB, dll.
Pada pertengahan 2017, di sebuah acara perusahaan, saya mendesak semua orang untuk membakukan pekerjaan mereka untuk meningkatkan kualitas sistem secara keseluruhan. Saya menggunakan metafora gunung es untuk menunjukkan bagaimana kami membuat dan memelihara perangkat lunak:

Saya mengatakan bahwa sebagian besar tim di perusahaan kami harus membuat layanan atau produk dan fokus pada pemecahan masalah, kode aplikasi, platform dan perpustakaan, dll. Dalam urutan itu. Banyak pekerjaan yang masih ada di bawah air - integrasi kayu bulat, meningkatkan daya pengamatan, mengelola rahasia, dll.
Pada saat itu, setiap tim pengembang aplikasi menangani hampir seluruh gunung es dan membuat semua keputusan dengan sendirinya - memilih bahasa, lingkungan pengembangan, alat perpustakaan dan metrik, sistem operasi, tipe instance, penyimpanan.
Di dasar piramida, kami memiliki infrastruktur Amazon Web Services. Tetapi tidak semua layanan AWS sama. Mereka memiliki Backend-as-a-Service (BaaS) , misalnya untuk otentikasi dan penyimpanan data. Dan ada layanan lain yang relatif rendah, seperti EC2. Saya ingin mempelajari data dan memahami bahwa tim memiliki alasan untuk mengeluh dan mereka benar-benar menghabiskan lebih banyak waktu bekerja dengan layanan tingkat rendah dan membuat banyak keputusan yang tidak penting.
Saya membagi layanan menjadi beberapa kategori, menggunakan CloudTrail. Saya mengumpulkan semua statistik yang tersedia, dan kemudian menggunakan BigQuery , Athena , dan ggplot2 untuk melihat bagaimana situasi untuk pengembang telah berubah belakangan ini. Pertumbuhan untuk layanan seperti RDS, Redshift, dll., Kami anggap diinginkan (dan diharapkan), dan pertumbuhan untuk EC2, CloudFormation, dll. - sebaliknya.

Setiap titik pada diagram menunjukkan persentil ke-90 (merah), ke-80 (hijau) dan ke-50 (biru) untuk jumlah layanan tingkat rendah yang digunakan orang-orang kita setiap minggu selama periode tertentu. Saya menambahkan garis smoothing untuk menunjukkan tren.
Meskipun kami bertujuan untuk abstraksi tingkat tinggi ketika menggunakan perangkat lunak, misalnya, menggunakan kontainer dan Amazon ECS , pengembang kami secara teratur menggunakan lebih banyak layanan AWS dan tidak cukup mengabaikan kesulitan dalam mengelola sistem. Dalam dua tahun, jumlah layanan meningkat dua kali lipat untuk 50% karyawan dan hampir tiga kali lipat untuk 20%.
Ini membatasi pertumbuhan perusahaan kami. Tim mencari otonomi, tetapi bagaimana cara merekrut orang baru? Kami membutuhkan pengembang aplikasi dan produk yang kuat serta pengetahuan tentang sistem AWS yang semakin canggih.
Kami ingin memperluas tim kami dan pada saat yang sama menjaga prinsip-prinsip keberhasilan kami: otonomi, koordinasi minimal, dan infrastruktur swalayan.
Dengan Kubernetes, kami menyelesaikan ini dengan abstraksi yang berfokus pada aplikasi dan kemampuan untuk mempertahankan dan mengkonfigurasi cluster dengan koordinasi tim yang minimal.
Abstraksi yang berfokus pada aplikasi
Konsep Kubernet mudah dicocokkan dengan bahasa yang digunakan pengembang aplikasi. Misalkan Anda mengelola versi aplikasi sebagai penyebaran . Anda dapat menjalankan beberapa replika di belakang layanan dan memetakannya ke HTTP melalui Ingress . Dan melalui sumber daya pengguna, Anda dapat memperluas dan mengkhususkan bahasa ini tergantung pada apa yang Anda butuhkan.
Tim bekerja lebih efisien dengan abstraksi ini. Pada dasarnya, contoh ini memiliki semua yang Anda butuhkan untuk menggunakan dan menjalankan aplikasi web. Sisanya adalah Kubernet.
Dalam gambar dengan gunung es, konsep-konsep ini berada di permukaan air dan menggabungkan tugas-tugas pengembang dari atas dengan platform di bawah ini. Tim manajemen kluster dapat membuat keputusan tingkat rendah dan tidak penting (tentang mengelola metrik, penebangan, dll.) Dan pada saat yang sama berbicara bahasa yang sama dengan pengembang di atas air.
Pada 2010, uSwitch memiliki tim tradisional untuk melakukan servis sistem monolitik, dan baru-baru ini kami memiliki departemen TI yang mengelola sebagian akun AWS kami. Tampak bagi saya bahwa kurangnya konsep umum secara serius menghambat pekerjaan tim ini.
Cobalah mengatakan sesuatu yang berguna jika Anda hanya memiliki instance EC2 dalam kosakata, load balancers, dan subnet Anda. Sulit atau bahkan tidak mungkin untuk menggambarkan esensi aplikasi. Itu bisa berupa paket Debian, penyebaran melalui Capistrano, dan sebagainya. Kami tidak dapat mendeskripsikan aplikasi dalam bahasa yang umum untuk semua.
Pada awal 2000-an, saya bekerja di ThoughtWorks di London. Pada wawancara itu, saya disarankan untuk membaca Problem-Oriented Designing Eric Evans. Saya membeli buku dalam perjalanan pulang dan mulai membaca di kereta. Sejak itu, saya mengingatnya di hampir setiap proyek dan sistem.
Salah satu konsep utama buku ini adalah bahasa tunggal di mana berbagai tim berkomunikasi. Kubernetes hanya menyediakan bahasa yang disatukan untuk pengembang dan tim pemeliharaan infrastruktur, dan ini adalah salah satu keunggulan utamanya. Plus itu dapat diperluas dan ditambah dengan bidang subjek lain dan lini bisnis.
Komunikasi dalam bahasa yang umum lebih produktif, tetapi kita masih perlu membatasi interaksi antar tim sebanyak mungkin.
Diperlukan interaksi minimum
Para penulis Accelerate menyoroti karakteristik arsitektur yang digabungkan secara longgar dengan tim TI yang bekerja lebih efisien:
Pada 2017, keberhasilan pengiriman berkelanjutan bergantung pada apakah tim dapat:
Serius mengubah struktur sistem Anda tanpa izin manajemen.
Serius mengubah struktur sistem Anda, tanpa menunggu tim lain untuk mengubah mereka, dan tanpa membuat banyak pekerjaan yang tidak perlu untuk tim lain.
Lakukan tugas mereka tanpa berkomunikasi atau mengoordinasikan pekerjaan mereka dengan tim lain.
Menyebarkan dan merilis produk atau layanan sesuai permintaan, terlepas dari layanan lain yang terkait dengannya.
Lakukan sebagian besar tes sesuai permintaan, tanpa lingkungan uji terintegrasi.
Kami membutuhkan perangkat lunak multi-tenant cluster terpusat untuk semua tim, tetapi pada saat yang sama kami ingin mempertahankan karakteristik ini. Kami belum mencapai yang ideal, tetapi kami berusaha sebaik mungkin:
- Kami memiliki beberapa kelompok kerja, dan tim sendiri memilih tempat untuk menjalankan aplikasi. Kami belum menggunakan federasi (kami sedang menunggu dukungan AWS), tetapi kami memiliki Utusan untuk load balancing pada penyeimbang Ingress di berbagai kluster. Kami mengotomatiskan sebagian besar tugas ini menggunakan pipa pengiriman kontinu (kami memiliki Drone ) dan layanan AWS lainnya.
- Semua cluster memiliki namespace yang sama. Sekitar satu untuk setiap tim.
- Kami mengontrol akses ke ruang nama melalui RBAC (kontrol akses berbasis peran). Untuk otentikasi dan otorisasi, kami menggunakan identitas perusahaan di Active Directory.
- Skala cluster secara otomatis , dan kami melakukan yang terbaik untuk mengoptimalkan waktu mulai dari node. Masih membutuhkan beberapa menit, tetapi, secara umum, bahkan dengan beban kerja yang besar, kami melakukannya tanpa koordinasi.
- Skala aplikasi secara otomatis berdasarkan metrik level aplikasi dari Prometheus. Tim pengembang mengontrol penskalaan otomatis aplikasi mereka dengan metrik kueri per detik, operasi per detik, dll. Berkat penskalaan otomatis kluster, sistem menyiapkan node ketika permintaan melebihi kemampuan cluster saat ini.
- Kami menulis Go dengan alat baris perintah bernama u yang membakukan otentikasi perintah di Kubernetes, menggunakan Vault , permintaan kredensial AWS sementara, dan sebagainya.
Saya tidak yakin bahwa dengan Kubernetes kami memiliki lebih banyak otonomi, tapi itu pasti tetap pada tingkat tinggi, dan pada saat yang sama kami menyingkirkan beberapa masalah.
Beralih ke Kubernetes cepat. Diagram menunjukkan jumlah total ruang nama (kira-kira sama dengan jumlah perintah) dalam kelompok kerja kami. Yang pertama muncul pada Februari 2017.
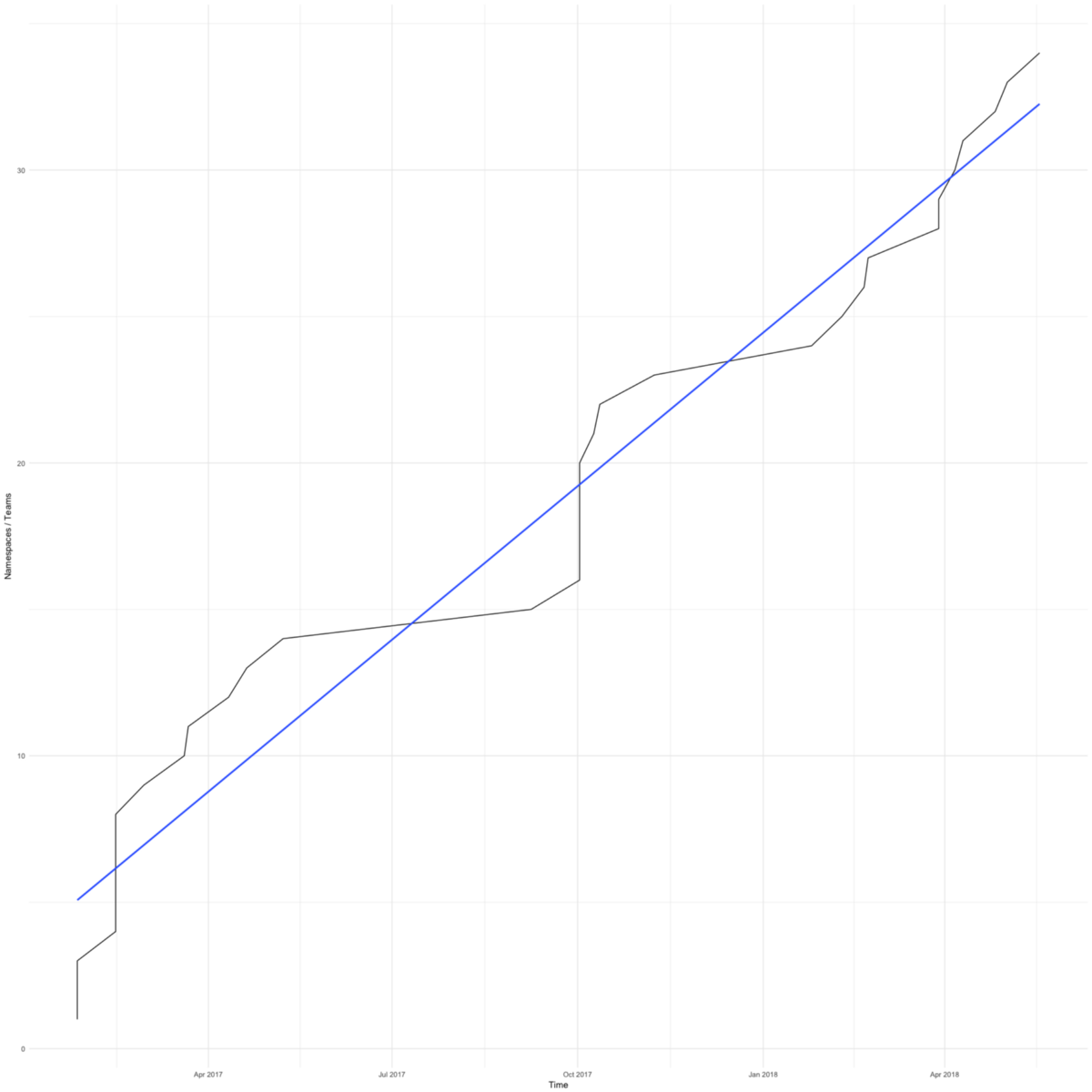
Kami punya alasan untuk terburu-buru - kami ingin menyelamatkan tim kecil yang fokus pada produk mereka dari kekhawatiran tentang infrastruktur.
Tim pertama setuju untuk beralih ke Kubernetes ketika server aplikasi mereka kehabisan ruang karena pengaturan logrotate yang tidak tepat. Transisi hanya memakan waktu beberapa hari, dan mereka kembali ke bisnis.
Baru-baru ini, tim telah beralih ke Kubetnetes untuk alat yang ditingkatkan. Cluster Kubernetes menyederhanakan integrasi dengan Hashicorp Vault , Google Cloud Trace, dan alat serupa kami. Semua tim kami mendapatkan fitur yang lebih efektif.
Saya sudah menunjukkan grafik dengan persentil jumlah layanan yang digunakan karyawan kami setiap minggu dari akhir 2014 hingga 2017. Dan ini adalah kelanjutan dari diagram ini hingga hari ini.
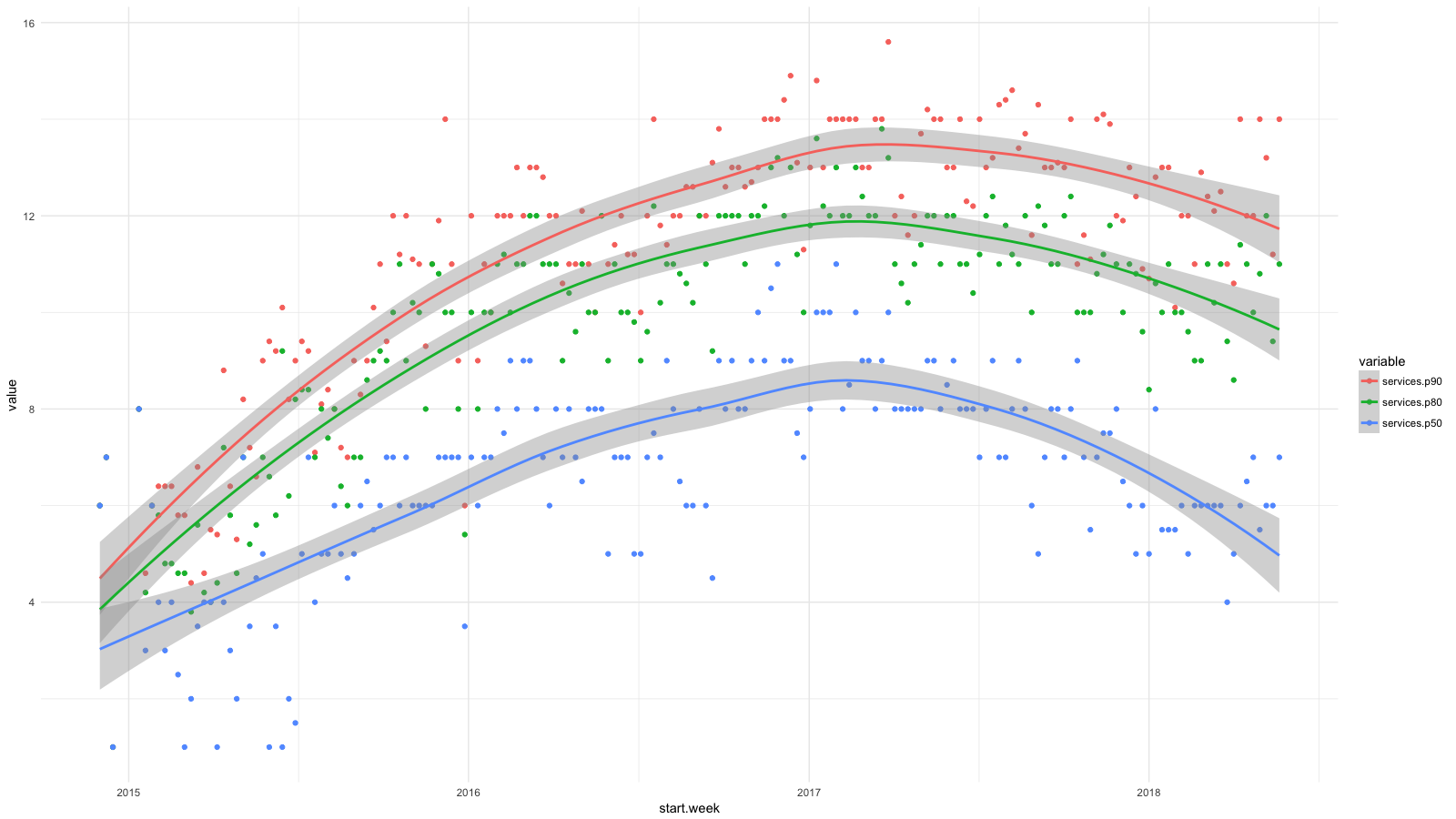
Kami telah membuat kemajuan dalam mengelola kerangka kerja AWS yang kompleks. Saya senang bahwa sekarang setengah dari karyawan melakukan hal yang sama seperti pada awal 2015. Kami memiliki 4-6 karyawan di tim komputasi awan, sekitar 10% dari jumlah total - tidak mengherankan bahwa persentil ke-90 hampir tidak bergerak. Tetapi saya juga berharap untuk kemajuan di sini.
Akhirnya, saya akan berbicara tentang bagaimana siklus pengembangan kami telah berubah, dan kembali mengingat buku Accelerate yang baru dibaca.
Buku ini menyebutkan dua metrik pengembangan lean: waktu tunggu dan ukuran paket. Waktu tunggu dipertimbangkan dari permintaan hingga pengiriman solusi yang sudah jadi. Ukuran paket adalah jumlah pekerjaan. Semakin kecil ukuran paket, semakin efisien pekerjaan:
Semakin kecil paket, semakin pendek siklus produksi, semakin sedikit variabilitas proses, lebih sedikit risiko, biaya dan biaya, kami mendapatkan umpan balik lebih cepat, bekerja lebih efisien, kami memiliki lebih banyak motivasi, kami mencoba untuk menyelesaikan lebih cepat dan menunda pengiriman lebih jarang.
Buku ini menyarankan untuk mengukur ukuran paket berdasarkan frekuensi penyebaran - semakin sering penyebarannya, semakin kecil paketnya.
Kami memiliki data untuk beberapa penyebaran. Data tidak sepenuhnya akurat - beberapa tim mengirim rilis langsung ke cabang utama repositori, beberapa menggunakan mekanisme lain. Ini tidak termasuk semua aplikasi, tetapi data selama 12 bulan dapat dianggap indikatif.
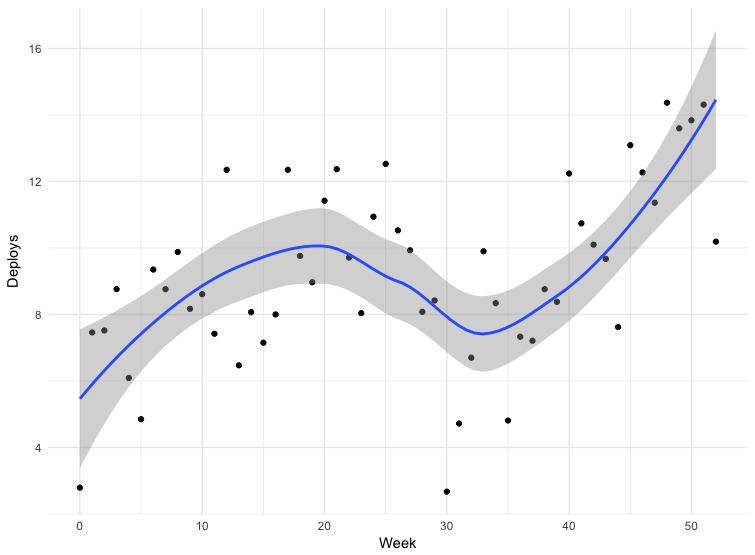
Kegagalan di minggu ketiga puluh adalah Natal. Untuk selebihnya, kita melihat bahwa frekuensi penyebaran meningkat, yang berarti bahwa ukuran paket menurun. Dari Maret hingga Mei 2018, frekuensi rilis hampir dua kali lipat, dan baru-baru ini kami terkadang membuat lebih dari seratus masalah per hari.
Beralih ke Kubernetes hanyalah bagian dari strategi kami untuk menstandarkan, mengotomatisasi, dan meningkatkan alat. Kemungkinan besar, semua faktor ini mempengaruhi frekuensi rilis.
Accelerate juga berbicara tentang hubungan antara frekuensi penempatan dan jumlah karyawan, dan seberapa cepat perusahaan dapat bekerja jika staf ditingkatkan. Para penulis menekankan keterbatasan arsitektur dan tim terkait:
Secara tradisional diyakini bahwa memperluas tim akan meningkatkan produktivitas secara keseluruhan, tetapi menurunkan produktivitas pengembang individu.
Jika kita mengambil data yang sama tentang frekuensi penyebaran dan membuat diagram ketergantungan pada jumlah pengguna, kita dapat melihat bahwa kita dapat meningkatkan frekuensi rilis, bahkan jika kita memiliki lebih banyak orang.

Di awal artikel, saya menyebutkan buku Factfulness (yang menginspirasi CTO kami). Transisi ke Kubernetes telah menjadi konvergensi teknologi yang paling signifikan dan cepat bagi pengembang kami. Kami bergerak dalam langkah-langkah kecil, dan mudah untuk tidak melihat seberapa banyak segalanya telah berubah menjadi lebih baik. Adalah baik bahwa kita memiliki data, dan mereka menunjukkan bahwa kita telah mencapai apa yang kita inginkan - orang-orang kita terlibat dalam produk mereka dan membuat keputusan penting di bidang mereka.
Dulu baik untuk kita. Kami memiliki layanan microservice, AWS, tim mapan untuk produk, pengembang yang bertanggung jawab atas layanan mereka dalam produksi, tim dan arsitektur yang digabungkan secara longgar. Saya membicarakan hal ini dalam laporan "Zaman Pencerahan Kita" ("Zaman Pencerahan Kita") di sebuah konferensi pada tahun 2012. Tetapi tidak ada batasan untuk kesempurnaan.
Pada akhirnya, saya ingin mengutip buku lain - Scale . Saya memulainya baru-baru ini, dan ada fragmen yang menarik tentang konsumsi energi dalam sistem yang kompleks:
Untuk menjaga ketertiban dan struktur dalam sistem yang sedang berkembang, dibutuhkan aliran energi yang konstan, dan menciptakan kekacauan. Karena itu, untuk mempertahankan hidup, kita harus makan setiap saat untuk mengalahkan entropi yang tak terhindarkan.
Kami melawan entropi dengan memasok lebih banyak energi untuk pertumbuhan, inovasi, pemeliharaan, dan perbaikan, yang menjadi lebih sulit seiring bertambahnya usia sistem, dan pertempuran ini adalah dasar dari setiap diskusi serius tentang penuaan, kematian, keberlanjutan, dan kemandirian sistem apa pun, baik itu organisme hidup , perusahaan atau masyarakat.
Saya pikir Anda dapat menambahkan sistem TI di sini. Saya berharap bahwa upaya terakhir kami akan tetap entropi untuk sementara waktu.