Saya bekerja sebagai pengembang di
hh.ru , dan saya ingin pergi ke dataset, tetapi sejauh ini tidak ada cukup keterampilan. Karena itu, di waktu senggang, saya belajar pembelajaran mesin dan mencoba memecahkan masalah praktis dari bidang ini. Baru-baru ini, mereka memberi saya tugas untuk mengelompokkan resume kami. Posting akan tentang bagaimana saya menyelesaikannya menggunakan pengelompokan hierarkis aglomeratif. Jika Anda tidak ingin membaca, tetapi hasilnya menarik, maka Anda dapat melihat
demo langsung.

Latar belakang
Pasar tenaga kerja terus-menerus dalam dinamika, profesi baru muncul, yang lain menghilang, dan saya ingin memiliki kategorisasi resume yang relevan. Katalog area profesional dan spesialisasi di hh.ru telah lama usang: banyak yang terkait dengannya, jadi mereka tidak melakukan perubahan untuk waktu yang lama. Akan bermanfaat untuk mempelajari cara mengedit kategori-kategori ini tanpa rasa sakit. Saya mencoba mengidentifikasi kategori-kategori ini secara otomatis. Saya berharap bahwa di masa depan ini akan membantu menyelesaikan masalah.
Tentang pendekatan yang dipilih dan tentang pengelompokan
Dengan mengelompokkan, saya akan memahami kombinasi objek dengan fitur paling mirip dalam satu grup. Dalam kasus saya, di bawah objek dianggap resume, dan di bawah tanda-tanda objek adalah data ringkasan: misalnya, frekuensi kata "manajer" di resume atau ukuran gaji. Kesamaan objek ditentukan oleh metrik yang dipilih sebelumnya. Untuk saat ini, Anda dapat menganggapnya sebagai kotak hitam yang menerima dua objek pada input, dan output menghasilkan angka yang mencerminkan, misalnya, jarak antara objek dalam ruang vektor: semakin kecil jarak, semakin mirip objek tersebut.
Pendekatan yang saya gunakan dapat disebut pengelompokan hierarkis aglomeratif ke atas. Hasil pengelompokan adalah pohon biner, di mana di daun ada elemen individu, dan akar pohon adalah kumpulan dari semua elemen. Ini disebut ascendant karena pengelompokan dimulai pada tingkat terendah dari pohon, dengan daun, di mana setiap elemen individu dianggap sebagai sebuah cluster.

Maka Anda perlu menemukan dua cluster terdekat dan menggabungkannya ke dalam cluster baru. Prosedur ini harus diulang sampai hanya ada satu cluster dengan semua objek di dalamnya. Ketika cluster digabungkan, jarak di antara mereka direkam. Di masa depan, jarak ini dapat digunakan untuk menentukan tempat di mana jarak ini cukup besar untuk mempertimbangkan kelompok yang dipilih sebagai terpisah.
Sebagian besar metode pengelompokan mengasumsikan bahwa jumlah cluster diketahui sebelumnya, atau mencoba untuk mengisolasi cluster secara independen, tergantung pada algoritma dan parameter dari algoritma ini. Keuntungan dari pengelompokan hierarkis adalah Anda dapat mencoba menentukan jumlah cluster yang dibutuhkan dengan memeriksa properti dari pohon yang dihasilkan, misalnya, memilih sub pohon dengan jarak yang berbeda antara kelompok yang berbeda. Sangat nyaman untuk bekerja dengan struktur yang dihasilkan untuk mencari cluster di dalamnya. Secara nyaman, struktur seperti itu dibangun sekali dan tidak perlu dibangun kembali ketika mencari jumlah cluster yang diperlukan.
Di antara kekurangannya, saya akan menyebutkan bahwa algoritma ini cukup menuntut pada memori yang dikonsumsi. Dan alih-alih menugaskan kelas tertentu, saya ingin memiliki kemungkinan bahwa resume milik kelas untuk melihat bukan pada spesialisasi terdekat, tetapi pada totalitas.
Pengumpulan dan persiapan data
Bagian terpenting dalam bekerja dengan data adalah persiapan, pemilihan, dan pengambilan atribut. Itu adalah berdasarkan tanda-tanda apa yang akan diperoleh pada akhirnya, itu akan tergantung pada apakah ada pola di dalamnya, apakah pola-pola ini sesuai dengan hasil yang diharapkan dan apakah "hasil yang diharapkan" itu mungkin sama sekali. Sebelum mengumpankan data ke beberapa jenis algoritma pembelajaran mesin, Anda perlu memiliki gagasan untuk setiap tanda, apakah ada celah, apa jenis tanda itu, properti apa yang dimiliki jenis tanda ini, dan apa distribusi nilai dalam tanda ini. Juga sangat penting untuk memilih algoritma yang tepat dengan mana data yang tersedia akan diproses.
Saya mengambil resume yang diperbarui selama enam bulan terakhir. Ternyata 2,7 juta. Dari data pada resume saya memilih tanda-tanda paling sederhana, di mana, menurut saya, keanggotaan resume harus bergantung pada satu atau kelompok lain. Ke depan, saya akan mengatakan bahwa hasil pengelompokan semua resume sekaligus tidak memuaskan saya. Oleh karena itu, kami harus terlebih dahulu membagi resume dengan 28 bidang profesional yang ada.
Untuk setiap karakteristik, saya merencanakan distribusi untuk memiliki gagasan tentang bagaimana data terlihat. Mungkin mereka harus bertobat atau ditinggalkan sama sekali.
Wilayah Agar nilai-nilai fitur ini dapat dibandingkan satu sama lain, saya menetapkan jumlah total resume yang termasuk dalam wilayah ini untuk setiap wilayah dan mengambil logaritma dari nomor ini untuk memperlancar perbedaan antara kota-kota yang sangat besar dan kecil.
Paul Dikonversi menjadi tanda biner.
Tanggal lahir . Dihitung dalam jumlah bulan. Tidak semua orang berulang tahun. Saya mengisi kekosongan dengan nilai rata-rata usia dari spesialisasi yang menjadi milik resume ini.
Tingkat pendidikan . Ini adalah tanda kategoris. Saya menyandikannya dengan
LabelBinarizer .
Nama item baris . Saya melewati
TfidfVectorizer dengan ngram_range = (1,2), menggunakan
stemmer .
Gaji Diterjemahkan semua nilai dalam rubel. Saya mengisi kekosongan dengan cara yang sama seperti di usia saya. Mengambil logaritma dari nilai.
Jadwal kerja . LabelBinarizer yang dikodekan.
Tingkat pekerjaan . Saya membuatnya menjadi biner, membaginya menjadi dua bagian: penuh waktu dan sisanya.
Kemahiran bahasa . Saya memilih yang paling banyak digunakan. Setiap bahasa diatur sebagai fitur terpisah. Tingkat kepemilikan dicocokkan dengan angka dari 0 hingga 5.
Keterampilan kunci . Saya melewati TfidfVectorizer. Sebagai kata penutup, saya menyusun kamus kecil keterampilan umum dan kata-kata yang, menurut saya, tidak memengaruhi spesialisasi. Semua kata disampaikan melalui stemmer. Setiap keterampilan kunci tidak hanya terdiri dari satu kata, tetapi juga beberapa. Dalam kasus beberapa kata dalam keterampilan utama, saya mengurutkan kata-kata, dan juga menggunakan setiap kata sebagai atribut terpisah. Fitur ini hanya berjalan dengan baik di bidang profesional "Teknologi Informasi, Internet, Telekomunikasi," karena orang sering menunjukkan keterampilan yang relevan dengan spesialisasi mereka. Di bidang profesional lain, saya tidak menggunakannya karena banyaknya keterampilan kata-kata umum.
Spesialisasi Saya menetapkan masing-masing spesialisasi yang ditentukan pengguna sebagai atribut biner.
Pengalaman kerja . Mengambil logaritma jumlah bulan +1, karena ada orang tanpa pengalaman kerja.
Standarisasi
Akibatnya, setiap resume mulai menjadi vektor tanda-angka. Algoritma pengelompokan yang dipilih didasarkan pada perhitungan jarak antara objek. Bagaimana cara menentukan bagaimana setiap fitur berkontribusi pada jarak ini? Misalnya, ada tanda biner - 0 dan 1, dan tanda lain dapat mengambil banyak nilai dari 0 hingga 1000.
Standardisasi datang untuk menyelamatkan. Saya menggunakan
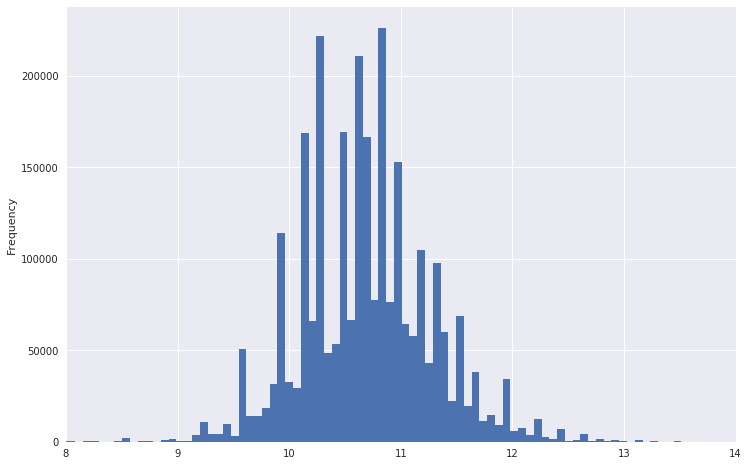
StandardScaler . Dia mengubah setiap sifat sedemikian rupa sehingga nilai rata-rata adalah nol dan standar deviasi dari rata-rata adalah satu. Jadi, kami mencoba untuk membawa semua data ke distribusi yang sama - standar normal. Tentu saja, jauh dari kenyataan bahwa data itu sendiri memiliki sifat distribusi normal. Ini hanyalah salah satu alasan untuk membangun grafik distribusi parameter mereka dan senang bahwa mereka terlihat seperti Gaussian.
Jadi, misalnya, bagan distribusi gaji terlihat seperti.

Dapat dilihat bahwa ia memiliki ekor yang sangat berat. Untuk membuat distribusi lebih seperti biasa, Anda dapat mengambil logaritma dari data ini. Pada saat yang sama, emisi tidak akan sekuat itu.
Turunkan peringkat
Sekarang masuk akal untuk mentransfer data ke ruang dimensi yang lebih kecil, sehingga di masa depan algoritma pengelompokan dapat mencernanya dalam waktu dan memori yang dapat diterima. Saya menggunakan
TruncatedSVD ,
karena ia tahu cara bekerja dengan matriks jarang dan pada outputnya memberikan matriks padat biasa, yang akan kita perlukan untuk pekerjaan lebih lanjut. Omong-omong, TruncatedSVD juga perlu mengirimkan data terstandarisasi.
Pada tahap yang sama, ada baiknya mencoba memvisualisasikan dataset yang dihasilkan, menerjemahkannya ke dalam ruang dua dimensi menggunakan
t-SNE . Ini adalah langkah yang sangat penting. Jika tidak ada struktur yang terlihat pada gambar yang dihasilkan atau, sebaliknya, struktur ini terlihat sangat aneh, maka data Anda tidak memiliki keteraturan yang diperlukan, atau kesalahan telah terjadi di suatu tempat.
Saya mendapat banyak gambar yang sangat mencurigakan sebelum semuanya berjalan dengan baik. Misalnya, pernah ada gambar yang begitu indah:

Alasan untuk cacing yang dihasilkan adalah mendapatkan pengidentifikasi resume dalam dataset. Dan di sini ada sesuatu yang lebih mirip dengan kebenaran:

Clustering
Jika semuanya tampak sesuai dengan data, maka Anda dapat mulai mengelompokkan. Saya menggunakan paket
pengelompokan hierarki dari SciPy. Ini memungkinkan pengelompokan menggunakan
metode tautan . Saya mencoba semua metrik jarak cluster yang disarankan dalam algoritma. Hasil terbaik diberikan oleh
metode Ward .
Masalah utama yang saya temui adalah algoritma pengelompokan menghitung matriks jarak antara semua elemen, yang berarti ketergantungan memori kuadrat dari jumlah elemen. Untuk 2,7 juta resume, saya tidak berhasil, karena Jumlah memori yang dibutuhkan adalah terabyte. Semua perhitungan dilakukan pada komputer biasa. Saya tidak punya banyak RAM. Oleh karena itu, tampak masuk akal bagi saya bahwa Anda dapat terlebih dahulu menggabungkan resume yang ada di dekatnya, mengambil pusat dari kelompok yang dihasilkan, dan sudah mengelompokkannya dengan algoritma yang diinginkan. Saya mengambil
MiniBatchKMeans , membentuk 30.000 cluster dengan itu dan mengirim mereka ke pengelompokan hierarkis. Itu berhasil, tetapi hasilnya begitu-begitu. Banyak grup resume yang paling menonjol, tetapi perinciannya tidak cukup untuk menemukan spesialisasi pada level yang baik.
Untuk meningkatkan kualitas spesialisasi yang diperoleh, saya memecah data menjadi bidang profesional. Ternyata dataset dari 400 000 resume dan kurang. Pada saat itu, terpikir oleh saya bahwa pengelompokan sampel data lebih baik daripada menggunakan dua algoritma berturut-turut. Jadi saya menyerah MiniBatchKMeans dan mengambil hingga 100.000 resume untuk setiap spesialisasi sehingga metode tautan bisa mencerna mereka. RAM 32 Gb tidak cukup, jadi saya mengalokasikan tambahan 100 Gb untuk swap. Sebagai hasilnya, hubungan menyediakan matriks dengan jarak antara cluster yang dikombinasikan pada setiap langkah dan jumlah elemen dalam cluster yang dihasilkan.
Sebagai metrik kontrol kualitas untuk membandingkan versi dataset yang berbeda dan metode yang berbeda untuk menghitung jarak antar cluster, algoritma ini menggunakan koefisien korelasi cophenetic yang diperoleh dari
cophenet . Koefisien ini menunjukkan seberapa baik dendrogram yang dihasilkan mencerminkan ketidaksamaan objek satu sama lain. Semakin dekat nilainya dengan persatuan, semakin baik.
Visualisasi
Cara terbaik untuk memvalidasi kualitas pengelompokan adalah visualisasi. Metode
dendrogram menarik dendrogram yang dihasilkan di mana Anda dapat memilih cluster berdasarkan jarak atau berdasarkan level di pohon:

Grafik berikut menunjukkan ketergantungan jarak antara kluster pada nomor langkah iterasi, di mana dua klaster terdekat digabungkan menjadi yang baru. Garis hijau menunjukkan bagaimana akselerasi berubah - kecepatan jarak antara kluster yang disatukan.
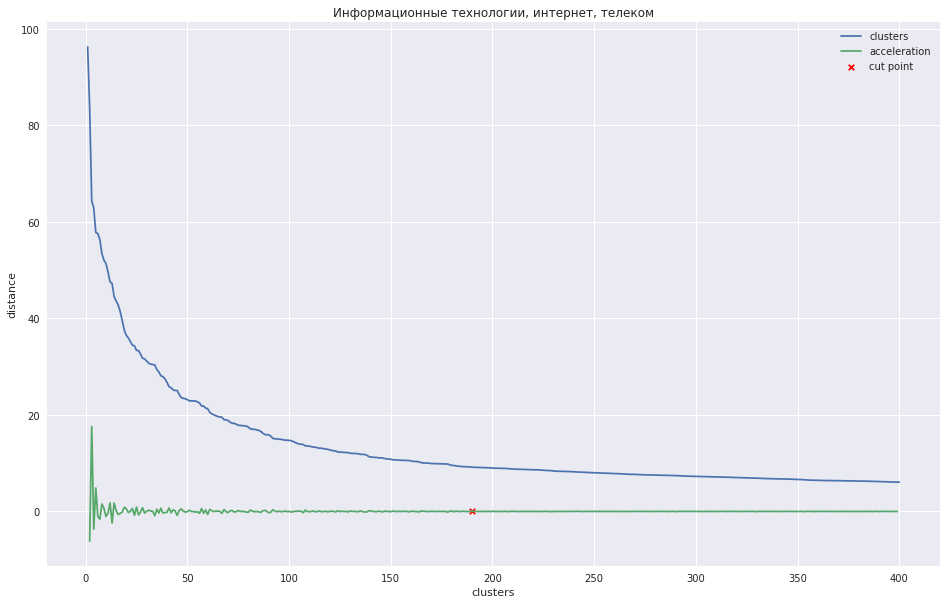
Dalam kasus sejumlah kecil cluster, seseorang dapat mencoba memangkas pohon pada titik di mana akselerasi maksimum, yaitu, jarak pada saat itu ketika dua cluster digabungkan bahkan lebih besar, dan sudah lebih kecil pada langkah berikutnya. Dalam kasus saya, semuanya berbeda - saya memiliki banyak cluster, dan saya menyarankan agar lebih baik memotong dendrogram pada titik di mana akselerasi mulai berkurang secara lebih monoton, mis., Jarak antara cluster pada level ini tidak lagi menunjukkan kelompok yang terpisah. Pada grafik, tempat ini kira-kira pada titik di mana garis hijau berhenti menari.
Seseorang dapat menemukan semacam metode programatik, tetapi ternyata lebih cepat untuk menandai tempat-tempat ini dengan 28 tangan untuk 28 domain profesional dan
meneruskan jumlah cluster yang diinginkan ke metode
fcluster , yang akan memotong pohon di tempat yang tepat.
Saya menyimpan data yang diperoleh sebelumnya dari t-SNE, dan mencatat cluster yang dihasilkan pada mereka. Itu terlihat cukup bagus:

Sebagai hasilnya, saya membuat antarmuka web di mana Anda dapat melihat ringkasan dari setiap cluster, posisinya di bagan dan memberikan nama yang bermakna. Untuk kenyamanan, saya menyimpulkan judul resume yang paling umum - sering mencirikan nama cluster dengan baik.
Anda dapat melihat hasil pengelompokan di
sini .
Saya menyimpulkan sendiri bahwa sistem ternyata berfungsi. Meskipun pengelompokan menjadi kelompok tidak sempurna dan beberapa kelompok sangat mirip satu sama lain, tetapi beberapa dapat, sebaliknya, dibagi menjadi beberapa bagian, tetapi tren utama pasar khusus terlihat jelas. Anda juga dapat melihat bagaimana grup baru terbentuk. Membongkar resume dilakukan di musim panas, jadi
pembalap, yang ingin bekerja di Piala Dunia , menonjol, misalnya. Jika Anda belajar untuk mencocokkan cluster antara satu sama lain dari peluncuran ke peluncuran, Anda dapat mengamati bagaimana bidang utama spesialisasi berubah seiring waktu. Bahkan, ide untuk meningkatkan kualitas dan pengembangan masih penuh. Jika saya dapat menemukan motivasi yang tepat dalam diri saya, saya akan mengembangkan lebih lanjut.
Bahan tambahan
Video tentang pengelompokan hierarki aglomeratif dari kursus tentang mencari struktur dalam data
Tentang penskalaan dan normalisasi tandaTutorial tentang hierarki hierarki dari perpustakaan SciPy, yang saya ambil sebagai dasar untuk tugas saya
Perbandingan berbagai jenis pengelompokan menggunakan pustaka sklearn sebagai contoh
Bonus kecil. Saya pikir itu menarik bagi orang-orang bagaimana seseorang bekerja pada suatu tugas. Saya ingin mengatakan bahwa dalam beberapa masalah saya memompa dengan baik ketika saya melakukan proyek ini. Saya mencoba berbagai pilihan, mempelajari, merenungkan bagaimana ini atau itu bekerja. Di banyak tempat, kurangnya dasar matematika yang baik diimbangi oleh sumber daya dan sejumlah besar upaya. Dan saya ingin berbagi
lembar evernote yang menderita di mana saya membuat catatan saat mengerjakan tugas. Refleksi di dalamnya dimaksudkan hanya untuk saya, ada banyak bidat dan ketidakpahaman, tetapi saya pikir itu normal.
UPD: Saya memposting laptop dengan
persiapan data dan kode
pengelompokan . Saya tidak berencana untuk mengunggah kodenya, mohon maaf atas kualitasnya.