
Dengan tes untuk kode, semuanya jelas (well, setidaknya fakta bahwa mereka perlu ditulis). Dengan tes untuk konfigurasi, semuanya menjadi kurang jelas, dimulai dengan keberadaannya. Apakah ada yang menulisnya? Apakah ini penting? Apakah ini sulit? Hasil apa yang bisa dicapai dengan bantuan mereka?
Ternyata ini juga sangat berguna, mulai melakukannya sangat sederhana, dan pada saat yang sama ada banyak nuansa dalam menguji konfigurasi. Yang mana - dilukis di bawah potongan berdasarkan pengalaman praktis.
Materi ini didasarkan pada transkrip laporan oleh Ruslan cheremin Cheremin (pengembang Java di Deutsche Bank). Berikutnya adalah pidato orang pertama.Nama saya Ruslan, saya bekerja untuk Deutsche Bank. Kita mulai dengan ini:

Ada banyak teks, dari kejauhan sepertinya teks itu berbahasa Rusia. Tetapi ini tidak benar. Ini adalah bahasa yang sangat kuno dan berbahaya. Saya menerjemahkan ke dalam bahasa Rusia sederhana:
- Semua karakter dibuat
- Gunakan dengan hati-hati
- Pemakaman dengan biaya sendiri
Saya akan menjelaskan secara singkat apa yang akan saya bicarakan hari ini. Misalkan kita memiliki kode:

Artinya, pada awalnya kami memiliki semacam tugas, kami menulis kode untuk menyelesaikannya, dan itu seharusnya menghasilkan uang bagi kami. Jika karena alasan tertentu kode ini tidak berfungsi dengan benar, ini memecahkan tugas yang salah dan menghasilkan uang yang salah. Bisnis tidak menyukai uang sebanyak itu - mereka terlihat buruk dalam laporan keuangan.
Karena itu, untuk kode penting kami, kami memiliki tes:

Biasanya disana. Sekarang, mungkin, hampir semua orang memilikinya. Tes memverifikasi bahwa kode memecahkan masalah yang tepat dan menghasilkan uang yang tepat. Tetapi layanan tidak terbatas pada kode, dan di samping kode ada juga konfigurasi:

Setidaknya di hampir semua proyek tempat saya berpartisipasi, konfigurasi ini adalah, dalam satu atau lain bentuk. (Saya hanya dapat mengingat beberapa kasus dari tahun-tahun awal UI saya, di mana tidak ada file konfigurasi, tetapi semuanya dikonfigurasi melalui UI) Dalam konfigurasi ini, ada port, alamat, dan parameter algoritma.
Mengapa konfigurasi penting untuk diuji?
Inilah triknya: kesalahan dalam eksekusi program kerusakan tidak kurang dari kesalahan dalam kode. Mereka juga dapat menyebabkan kode melakukan tugas yang salah - dan lihat di atas.
Dan menemukan kesalahan dalam konfigurasi bahkan lebih sulit daripada dalam kode, karena konfigurasi biasanya tidak dikompilasi. Saya mengutip properti-file sebagai contoh, secara umum ada opsi yang berbeda (JSON, XML, seseorang menyimpan di YAML), tetapi penting bahwa tidak ada kompilasi ini dan, karenanya, tidak dicentang. Jika Anda secara tidak sengaja disegel dalam file Java - kemungkinan besar, itu tidak akan lulus kompilasi. Kesalahan ketik acak di properti tidak akan merangsang siapa pun, ini akan berfungsi.
Dan IDE juga tidak menyoroti kesalahan dalam konfigurasi, karena hanya mengetahui yang paling primitif tentang format (misalnya) file properti: bahwa harus ada kunci dan nilai, dan "sama dengan", titik dua atau spasi di antara keduanya. Tetapi fakta bahwa nilainya harus berupa angka, port jaringan atau alamat - IDE tidak tahu apa-apa.
Dan bahkan jika Anda menguji aplikasi dalam UAT atau dalam lingkungan Pementasan, ini juga tidak menjamin apa pun. Karena konfigurasi, sebagai suatu peraturan, di setiap lingkungan berbeda, dan di UAT Anda hanya menguji konfigurasi UAT.
Kehalusan lain adalah bahwa bahkan dalam produksi, kesalahan konfigurasi terkadang tidak segera muncul. Layanan mungkin tidak memulai sama sekali - dan ini adalah skenario yang bagus. Tapi itu bisa mulai, dan bekerja untuk waktu yang sangat lama - sampai saat X, ketika akan diperlukan parameter di mana kesalahan terjadi. Dan di sini Anda menemukan bahwa layanan yang bahkan belum berubah banyak baru-baru ini tiba-tiba berhenti berfungsi.
Setelah semua yang saya katakan - tampaknya pengujian konfigurasi harus menjadi topik hangat. Tetapi dalam praktiknya terlihat seperti ini:
Setidaknya itulah yang terjadi dengan kami - sampai titik tertentu. Dan salah satu tugas laporan saya adalah untuk berhenti terlihat seperti ini untuk Anda juga. Saya harap saya bisa mendorong Anda untuk ini.
Tiga tahun lalu di Deutsche Bank kami, di tim saya, Andrei Satarin bekerja sebagai pemimpin QA. Dialah yang membawa ide pengujian konfigurasi - yaitu, ia hanya mengambil dan melakukan tes pertama seperti itu. Enam bulan lalu, di Heisenbug sebelumnya, dia memberi
ceramah tentang pengujian konfigurasi saat dia melihatnya. Saya sarankan agar Anda melihat, karena di sana ia memberikan pandangan luas pada masalah: baik dari sisi artikel ilmiah dan dari pengalaman perusahaan besar yang telah mengalami kesalahan konfigurasi dan konsekuensinya.
Laporan saya akan lebih sempit - tentang pengalaman praktis. Saya akan berbicara tentang masalah apa, sebagai pengembang, yang saya temui ketika saya menulis tes konfigurasi, dan bagaimana saya memecahkan masalah ini. Keputusan saya mungkin bukan keputusan terbaik, ini bukan praktik terbaik - ini adalah pengalaman pribadi saya, saya berusaha untuk tidak membuat generalisasi yang luas.
Garis besar umum laporan:
- "Yang Dapat Anda Lakukan Sebelum Senin Sore": Contoh-contoh Sederhana dan Berguna.
- "Senin, dua tahun kemudian": di mana dan bagaimana melakukan lebih baik.
- Dukungan untuk refactoring konfigurasi: bagaimana mencapai cakupan yang padat; model konfigurasi perangkat lunak.
Bagian pertama adalah motivasi: Saya akan menjelaskan tes paling sederhana yang semuanya dimulai dengan kita. Akan ada berbagai macam contoh. Saya harap setidaknya satu dari mereka beresonansi dengan Anda, yaitu, Anda akan melihat beberapa jenis masalah yang serupa dan solusinya.
Tes sendiri pada bagian pertama adalah sederhana, bahkan primitif - dari sudut pandang teknik tidak ada ilmu roket. Tetapi hal itu dapat dilakukan dengan cepat adalah sangat berharga. Ini adalah "entri mudah" ke dalam pengujian konfigurasi, dan ini penting karena ada hambatan psikologis untuk menulis tes ini. Dan saya ingin menunjukkan bahwa "Anda bisa melakukan ini": sekarang, kami berhasil, itu berhasil dengan baik bagi kami, dan sementara tidak ada yang meninggal, kami sudah hidup selama tiga tahun sekarang.
Bagian kedua adalah tentang apa yang harus dilakukan setelahnya. Ketika Anda menulis banyak tes sederhana, pertanyaan tentang dukungan muncul. Beberapa dari mereka mulai jatuh, Anda memahami kesalahan yang seharusnya disorot. Ternyata ini tidak selalu nyaman. Dan muncul pertanyaan untuk menulis tes yang lebih kompleks - lagi pula, Anda sudah membahas kasus-kasus sederhana, saya ingin sesuatu yang lebih menarik. Dan di sini lagi tidak ada praktik terbaik, saya hanya akan menjelaskan beberapa solusi yang bekerja untuk kita.
Bagian ketiga adalah tentang bagaimana pengujian dapat mendukung refactoring dari konfigurasi yang agak rumit dan membingungkan. Lagi studi kasus - bagaimana kami melakukannya. Dari sudut pandang saya, ini adalah contoh bagaimana pengujian konfigurasi dapat ditingkatkan untuk menyelesaikan tugas yang lebih besar, dan bukan hanya untuk menyumbat lubang kecil.
Bagian 1. "Kamu bisa melakukannya seperti itu"
Sekarang sulit untuk memahami apa tes konfigurasi pertama dengan kami. Andrei duduk di aula, dia bisa mengatakan bahwa aku berbohong. Tetapi bagi saya tampaknya semuanya dimulai dengan ini:

Situasinya adalah ini: kami memiliki layanan di host yang sama, masing-masing dari mereka meningkatkan server JMX di port-nya, mengekspor beberapa JMX pemantauan. Port untuk semua layanan dikonfigurasikan dalam file. Tetapi file tersebut menempati beberapa halaman, dan ada banyak properti lainnya - seringkali ternyata port-port dari layanan yang berbeda saling bertentangan. Mudah membuat kesalahan. Maka semuanya sepele: beberapa layanan tidak naik, setelah itu mereka tidak naik untuk mereka yang bergantung padanya - penguji sangat marah.
Masalah ini diselesaikan dalam beberapa baris. Tes ini, yang (menurut saya) adalah yang pertama bagi kami, terlihat seperti ini:

Tidak ada yang rumit: kita pergi melalui folder di mana file konfigurasi berada, memuatnya, mem-parsingnya sebagai properti, menyaring nilai-nilai yang namanya berisi "jmx.port", dan memeriksa bahwa semua nilainya unik. Bahkan tidak perlu mengkonversi nilai menjadi integer. Agaknya, hanya ada porta.
Reaksi pertama saya ketika saya melihat ini beragam:
Kesan pertama: apa yang ada di unit test saya yang cantik? Mengapa kami naik ke sistem file?
Dan kemudian kejutan datang: "Apa, mungkinkah itu?"
Saya membicarakan hal ini karena sepertinya ada semacam penghalang psikologis yang membuatnya sulit untuk menulis tes semacam itu. Tiga tahun telah berlalu sejak itu, proyek ini penuh dengan tes seperti itu, tetapi saya sering melihat bahwa rekan-rekan saya, menabrak kesalahan yang dibuat dalam konfigurasi, jangan menulis tes di atasnya. Untuk kode, semua orang sudah terbiasa menulis tes regresi - sehingga kesalahan yang ditemukan tidak lagi direproduksi. Tetapi mereka tidak melakukannya untuk konfigurasi, ada sesuatu yang mengganggu. Ada semacam penghalang psikologis yang perlu ditangani - itu sebabnya saya menyebutkan reaksi sedemikian rupa sehingga Anda akan mengenalinya dari diri sendiri jika itu muncul.
Contoh berikut hampir sama, tetapi sedikit dimodifikasi - saya menghapus semua "jmx". Kali ini kami memeriksa semua properti yang disebut sesuatu di sana port. Mereka harus berupa nilai integer, dan menjadi port jaringan yang valid. Matcher validNetworkPort () menyembunyikan Pencocokan hamcrest kustom kami, yang memeriksa bahwa nilainya berada di atas kisaran port sistem, di bawah kisaran port fana, yah, kami tahu bahwa beberapa port di server kami sudah dikuasai sebelumnya - inilah daftar keseluruhan dari mereka yang disembunyikan di ini adalah matcher.
Tes ini masih sangat primitif. Perhatikan bahwa tidak ada indikasi di dalamnya properti spesifik apa yang kami periksa - properti ini masif. Satu pengujian semacam itu dapat memeriksa 500 properti dengan nama "... port", dan memverifikasi bahwa semuanya adalah bilangan bulat dalam kisaran yang diinginkan, dengan semua kondisi yang diperlukan. Setelah mereka menulis, selusin baris - dan hanya itu. Ini adalah fitur yang sangat nyaman, ini muncul karena konfigurasi memiliki format sederhana: dua kolom, satu kunci dan satu nilai. Karena itu, bisa jadi diproses secara massal.
Contoh tes lain. Apa yang kita periksa di sini?

Ia memeriksa bahwa kata sandi asli tidak bocor ke dalam produksi. Semua kata sandi akan terlihat seperti ini:

Anda dapat menulis banyak tes untuk file properti. Saya tidak akan memberikan lebih banyak contoh - saya tidak ingin mengulang sendiri, idenya sangat sederhana, maka semuanya harus jelas.
... dan setelah cukup menulis tes ini, sebuah pertanyaan menarik muncul: apa yang kita maksud dengan konfigurasi, di mana perbatasannya? Kami menganggap file properti sebagai konfigurasi, kami menutupinya - dan apa lagi yang bisa dicakup dengan gaya yang sama?
Apa yang harus dipertimbangkan konfigurasi
Ternyata ada banyak file teks dalam proyek yang tidak dikompilasi - setidaknya dalam proses pembangunan normal. Mereka tidak diverifikasi dengan cara apa pun sampai mereka dieksekusi di server, yaitu, kesalahan di dalamnya tampak terlambat. Semua file ini - dengan sedikit peregangan - dapat disebut konfigurasi. Paling tidak, mereka akan diuji kira-kira sama.
Sebagai contoh, kami memiliki sistem tambalan SQL yang digulirkan ke database selama proses penyebaran.

Mereka ditulis untuk SQL * Plus. SQL * Plus adalah alat dari tahun 60-an, dan itu membutuhkan segala macam hal aneh: misalnya, untuk memastikan akhir file berada pada baris baru. Tentu saja, orang secara teratur lupa untuk meletakkan ujung garis di sana, karena mereka tidak dilahirkan di tahun 60an.
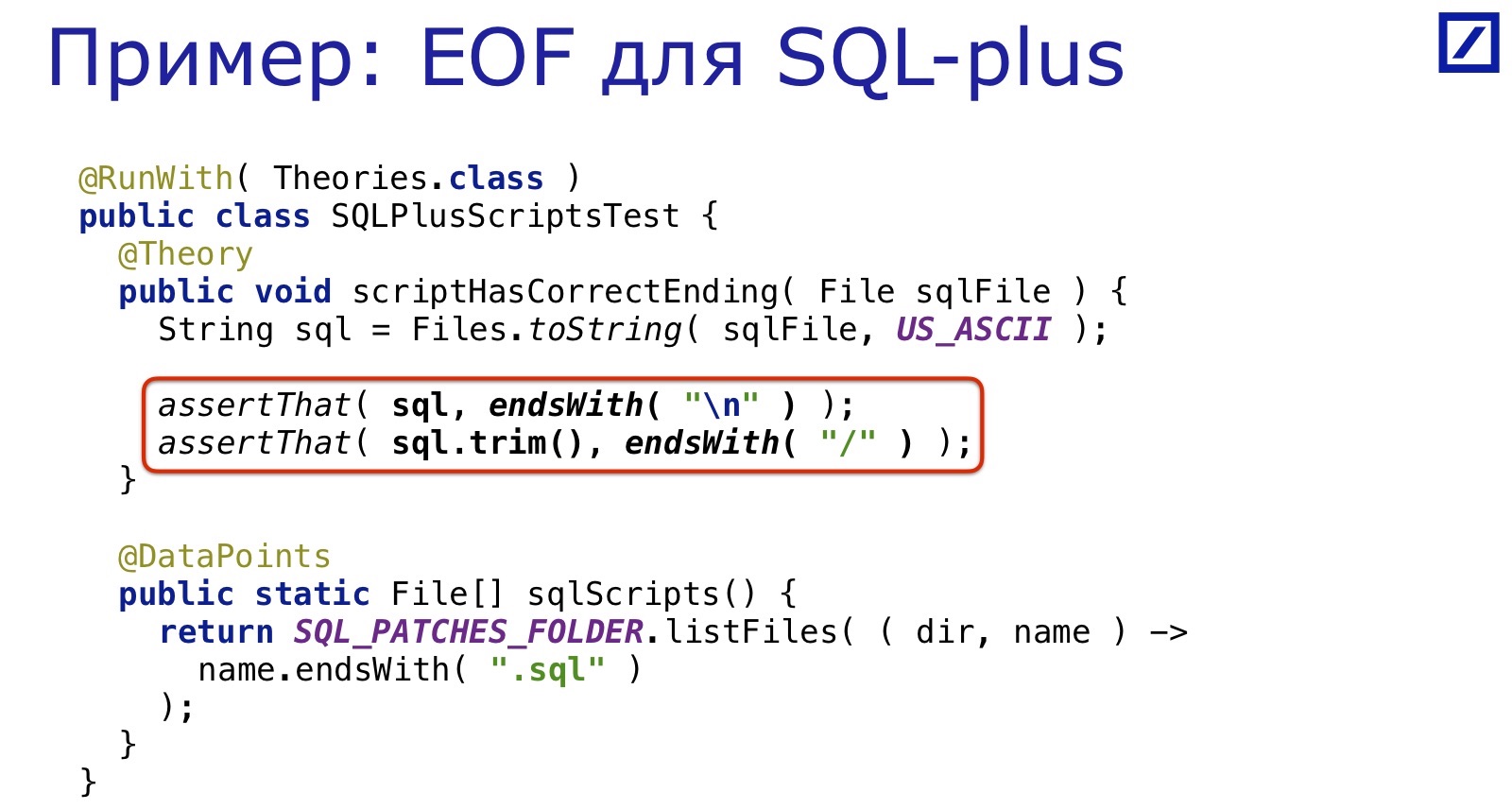
Dan lagi itu dipecahkan oleh selusin baris yang sama: kita memilih semua file SQL, periksa apakah ada garis miring di akhir. Sederhana, mudah, cepat.
Contoh lain dari “like a text file” adalah crontab. Layanan crontab kami mulai dan berhenti. Mereka paling sering menyebabkan dua kesalahan:
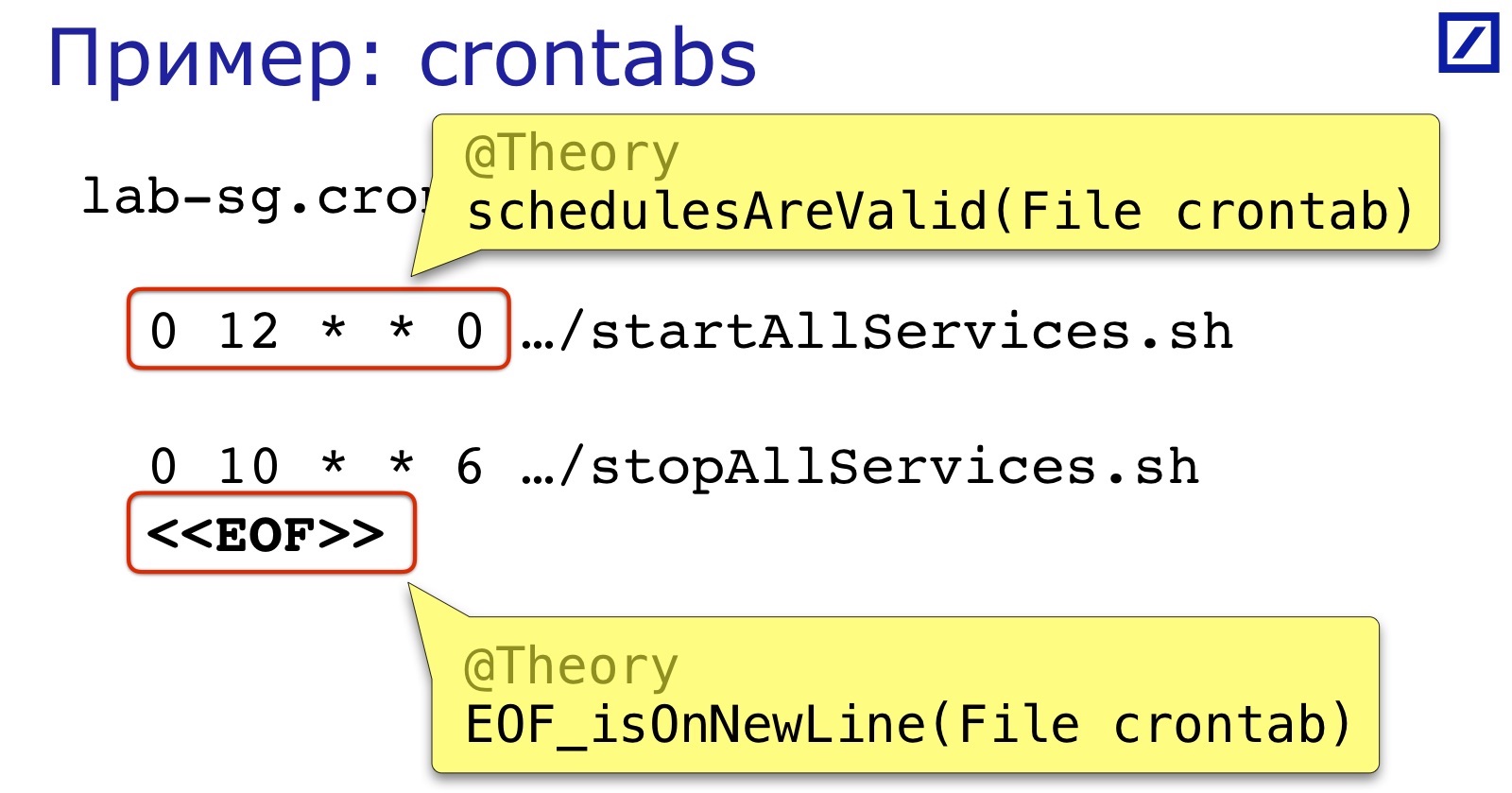
Pertama, format ekspresi jadwal. Ini tidak rumit, tetapi tidak ada yang memeriksanya sebelum diluncurkan, jadi mudah untuk menempatkan ruang ekstra, koma, dan sejenisnya.
Kedua, seperti pada contoh sebelumnya, akhir file juga harus berada pada baris baru.
Dan semua ini cukup mudah diverifikasi. Akhir file dapat dimengerti, tetapi untuk memeriksa jadwal, Anda dapat menemukan pustaka siap pakai yang menguraikan ekspresi cron. Sebelum laporan, saya mencari di Google: setidaknya ada enam. Saya menemukan enam, tetapi secara umum mungkin ada lebih banyak. Ketika kami menulis, kami mengambil yang paling sederhana dari yang ditemukan, karena kami tidak perlu memeriksa isi ekspresi, tetapi hanya kebenaran sintaksisnya, sehingga cron berhasil memuatnya.
Pada prinsipnya, Anda dapat menyelesaikan lebih banyak cek - periksa apakah Anda memulai pada hari yang tepat dalam seminggu, bahwa Anda tidak menghentikan layanan di tengah hari kerja. Tapi ini ternyata tidak begitu berguna bagi kami, dan kami tidak repot-repot.
Gagasan lain yang bekerja sangat baik adalah skrip shell. Tentu saja, menulis di Jawa parser lengkap dari skrip bash adalah kesenangan bagi yang berani. Tetapi intinya adalah bahwa sejumlah besar skrip ini bukan bash lengkap. Ya, ada skrip bash di mana kode itu langsung, neraka dan neraka, di mana mereka jatuh setahun sekali dan, bersumpah, lari. Tetapi banyak skrip bash yang memiliki konfigurasi yang sama. Ada sejumlah variabel sistem dan variabel lingkungan yang diatur ke nilai yang diinginkan, sehingga mengkonfigurasi skrip lain yang menggunakan variabel-variabel ini. Dan variabel-variabel semacam itu mudah diperoleh dari file bash ini dan memeriksa sesuatu tentangnya.

Misalnya, periksa apakah JAVA_HOME diinstal pada setiap lingkungan, atau bahwa beberapa perpustakaan jni yang kami gunakan terletak di LD_LIBRARY_PATH. Entah bagaimana kami pindah dari satu versi Java ke yang lain, dan memperluas tes: kami memeriksa bahwa JAVA_HOME berisi "1.8" pada lingkungan yang sangat kecil itu, yang secara bertahap kami transfer ke versi yang baru.
Berikut ini beberapa contohnya. Biarkan saya meringkas bagian pertama dari kesimpulan:
- Tes konfigurasi pada awalnya membingungkan, ada hambatan psikologis. Tetapi setelah mengatasinya, ada banyak tempat dalam aplikasi yang tidak tercakup oleh cek dan dapat ditanggung.
- Kemudian mereka ditulis dengan mudah dan riang : ada banyak "buah tergantung rendah" yang dengan cepat memberi manfaat besar).
- Mengurangi biaya untuk mendeteksi dan memperbaiki kesalahan konfigurasi. Karena ini, pada kenyataannya, pengujian unit, Anda dapat menjalankannya di komputer Anda, bahkan sebelum melakukan - ini sangat mengurangi Loop Umpan Balik. Banyak dari mereka, tentu saja, akan diuji pada tahap penerapan uji, misalnya. Dan banyak yang tidak akan diuji - jika ini adalah konfigurasi produksi. Dan mereka diperiksa langsung di komputer lokal.
- Mereka memberi pemuda kedua. Dalam arti ada perasaan bahwa Anda masih bisa menguji banyak hal menarik. Memang, dalam kode itu tidak lagi begitu mudah untuk menemukan apa yang dapat Anda uji.
Bagian 2. Kasus yang lebih kompleks
Mari kita beralih ke tes yang lebih kompleks. Setelah membahas sebagian besar pemeriksaan sepele, seperti yang ditunjukkan di sini, muncul pertanyaan: apakah mungkin untuk memeriksa sesuatu yang lebih rumit?
Apa artinya "lebih keras"? Tes yang baru saja saya jelaskan memiliki sekitar struktur berikut:

Mereka memeriksa sesuatu terhadap satu file tertentu. Yaitu, kita pergi melalui file, menerapkan pemeriksaan kondisi tertentu untuk masing-masing. Dengan demikian, banyak yang dapat diverifikasi, tetapi ada skenario yang lebih berguna:
- Aplikasi UI terhubung ke server lingkungannya.
- Semua layanan dari lingkungan yang sama terhubung ke server manajemen yang sama .
- Semua layanan di lingkungan yang sama menggunakan database yang sama .
Misalnya, aplikasi UI terhubung ke server lingkungannya. Kemungkinan besar, UI dan server adalah modul yang berbeda, jika bukan proyek sama sekali, dan mereka memiliki konfigurasi yang berbeda, mereka tidak mungkin menggunakan file konfigurasi yang sama. Oleh karena itu, Anda harus menautkannya sehingga semua layanan dari satu lingkungan terhubung ke satu server manajemen utama yang melaluinya perintah didistribusikan. Sekali lagi, kemungkinan besar, ini adalah modul yang berbeda, layanan yang berbeda dan umumnya tim yang berbeda mengembangkannya.
Atau semua layanan menggunakan database yang sama, hal yang sama - layanan dalam modul yang berbeda.
Bahkan, ada gambar seperti itu: banyak layanan, masing-masing memiliki struktur konfigurasi sendiri, Anda perlu mengurangi beberapa dari mereka dan memeriksa sesuatu di persimpangan:

Tentu saja, Anda dapat melakukan hal itu: muat satu, yang kedua, tarik sesuatu di suatu tempat, rekatkan dalam kode uji. Tapi Anda bisa bayangkan seberapa besar kodenya dan seberapa mudah dibaca. Kami mulai dari ini, tetapi kemudian kami menyadari betapa sulitnya itu. Bagaimana melakukan yang lebih baik?
Jika Anda bermimpi, itu akan lebih mudah, maka saya bermimpi bahwa ujian akan terlihat seperti saya jelaskan dalam bahasa manusia:
@Theory public void eachEnvironmentIsXXX( Environment environment ) { for( Server server : environment.servers() ) { for( Service service : server.services() ) { Properties config = buildConfigFor( environment, server, service );
Untuk setiap lingkungan, suatu kondisi terpenuhi. Untuk memeriksanya, Anda perlu dari lingkungan untuk menemukan daftar server, daftar layanan. Kemudian muat konfigurasi dan periksa sesuatu di persimpangan. Karena itu, saya memerlukan hal seperti itu, saya menyebutnya Layout Penempatan.
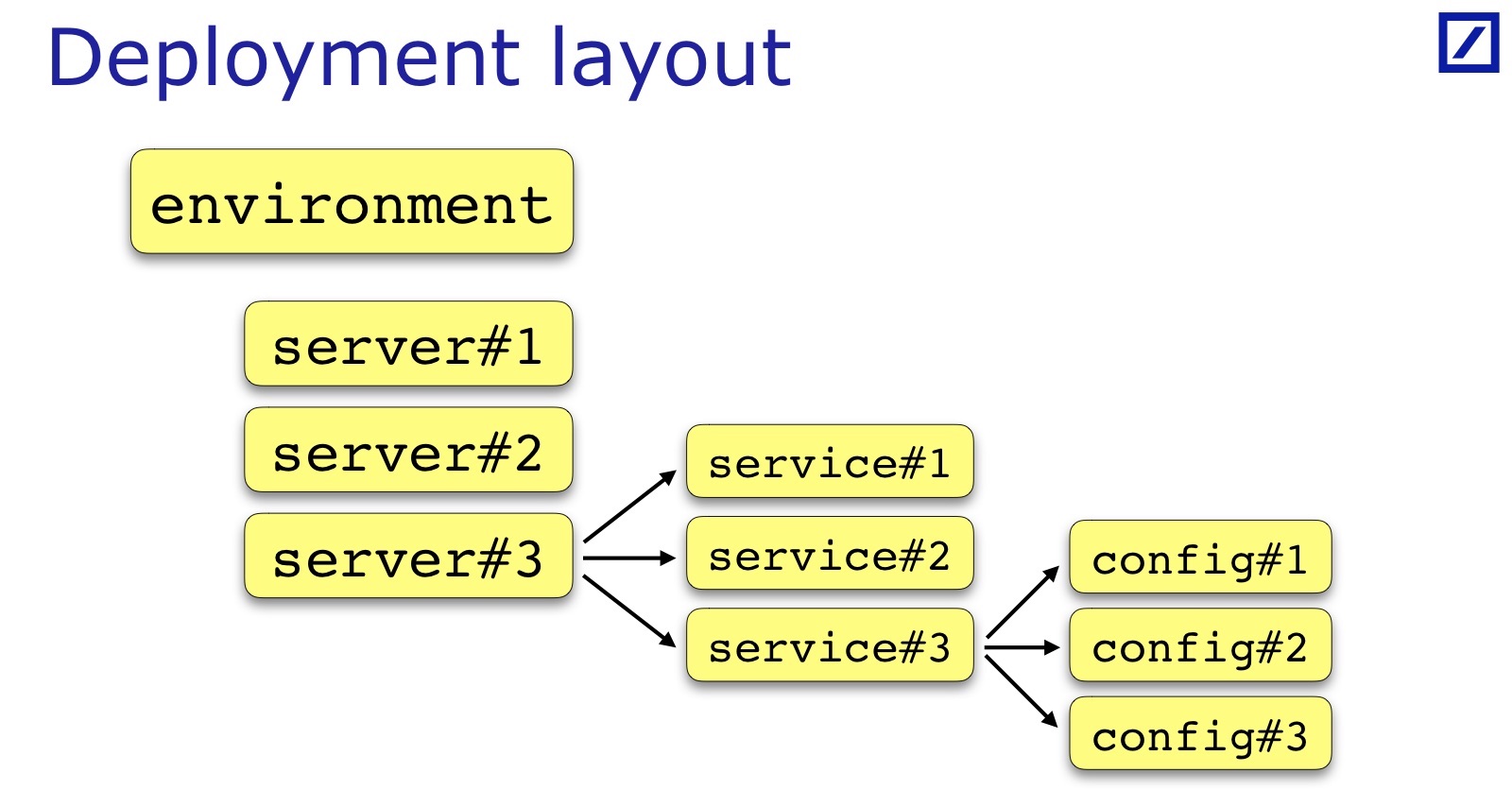
Kami membutuhkan peluang dari kode untuk mendapatkan akses ke bagaimana aplikasi dikerahkan: di server mana layanan ditempatkan, di mana Lingkungan - untuk mendapatkan struktur data ini. Dan mulai dari itu, saya mulai memuat konfigurasi dan memprosesnya.
Layout Penerapan khusus untuk setiap tim dan setiap proyek. Saya telah menggambar - ini adalah kasus umum: biasanya ada beberapa set server, layanan, layanan kadang-kadang memiliki satu set file konfigurasi, dan bukan hanya satu. Terkadang diperlukan parameter tambahan yang berguna untuk pengujian, mereka harus ditambahkan. Misalnya, rak tempat server berada mungkin penting. Andrey dalam laporannya memberikan contoh ketika penting bagi layanan mereka bahwa layanan Cadangan / Utama harus berada di rak yang berbeda - untuk kasusnya, dia perlu menyimpan indikasi rak dalam tata letak penempatan:
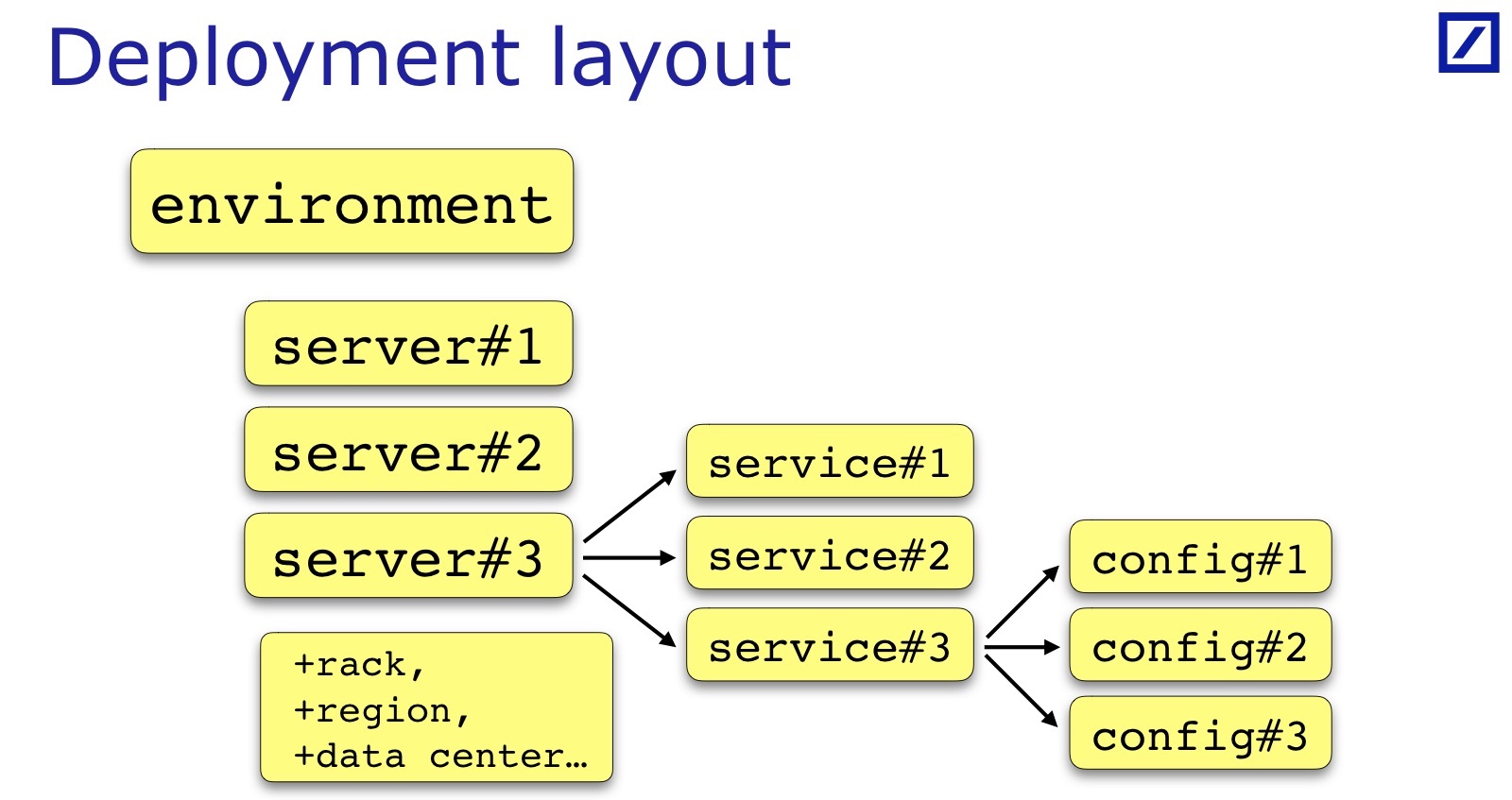
Untuk tujuan kami, wilayah server penting, pusat data spesifik, pada prinsipnya, juga, sehingga Cadangan / Utama berada di pusat data yang berbeda. Ini semua adalah properti server tambahan, khusus untuk proyek tersebut, tetapi pada slide itu adalah penyebut yang umum.
Di mana mendapatkan tata letak penempatan? Tampaknya di perusahaan besar mana pun ada sistem Manajemen Infrastruktur, semuanya dijelaskan di sana, dapat diandalkan, andal, dan semua yang ... sebenarnya tidak.
Paling tidak, praktik saya di dua proyek telah menunjukkan bahwa lebih mudah untuk melakukan hardcode terlebih dahulu, dan kemudian, setelah tiga tahun ... pergi berkulit keras.
Kami telah hidup dengan proyek ini selama tiga tahun sekarang. Yang kedua, sepertinya, kami masih berintegrasi dengan Manajemen Infrastruktur dalam setahun, tetapi selama ini kami hidup seperti ini. Dari pengalaman, masuk akal untuk menunda tugas integrasi dengan IM untuk mendapatkan tes siap pakai sesegera mungkin, yang akan menunjukkan bahwa mereka bekerja dan bermanfaat. Dan kemudian mungkin ternyata integrasi ini mungkin tidak begitu diperlukan, karena distribusi layanan di seluruh server tidak begitu sering diubah.
Hardcode secara harfiah dapat seperti ini:
public enum Environment { PROD( PROD_UK_PRIMARY, PROD_UK_BACKUP, PROD_US_PRIMARY, PROD_US_BACKUP, PROD_SG_PRIMARY, PROD_SG_BACKUP ) … public Server[] servers() {…} } public enum Server { PROD_UK_PRIMARY(“rflx-ldn-1"), PROD_UK_BACKUP("rflx-ldn-2"), PROD_US_PRIMARY(“rflx-nyc-1"), PROD_US_BACKUP("rflx-nyc-2"), PROD_SG_PRIMARY(“rflx-sng-1"), PROD_SG_BACKUP("rflx-sng-2"), public Service[] services() {…} }
Cara termudah yang kami gunakan dalam proyek pertama kami adalah menghitung Lingkungan dengan daftar server di masing-masing. Ada daftar server dan, tampaknya, harus ada daftar layanan, tetapi kami curang: kami telah memulai skrip (yang juga merupakan bagian dari konfigurasi).

Mereka menjalankan layanan untuk setiap Lingkungan. Dan metode services () hanya mengambil semua layanan dari file servernya. Ini dilakukan karena tidak begitu banyak Lingkungan, dan server juga jarang ditambahkan atau dihapus - tetapi ada banyak layanan, dan mereka sering dikocok. Masuk akal untuk memuat tata letak layanan yang sebenarnya dari skrip agar tidak mengubah tata letak hardcode terlalu sering.
Setelah membuat model konfigurasi perangkat lunak seperti itu, bonus yang menyenangkan muncul. Misalnya, Anda dapat menulis tes seperti ini:

Tesnya adalah bahwa pada setiap Lingkungan semua layanan utama hadir. Misalkan ada empat layanan utama, dan sisanya mungkin atau mungkin tidak, tetapi tanpa keempat ini tidak masuk akal. Anda dapat memverifikasi bahwa Anda tidak melupakannya di mana pun, bahwa mereka semua memiliki cadangan dalam Lingkungan yang sama. Paling sering, kesalahan seperti itu terjadi ketika mengkonfigurasi UAT dari contoh ini, tetapi juga bisa bocor ke PROD. Pada akhirnya, kesalahan dalam UAT juga membuang-buang waktu dan saraf penguji.
Muncul pertanyaan tentang mempertahankan relevansi model konfigurasi. Anda juga dapat menulis tes untuk ini.
public class HardCodedLayoutConsistencyTest { @Theory eachHardCodedEnvironmentHasConfigFiles(Environment env){ … } @Theory eachConfigFileHasHardCodedEnvironment(File configFile){ … } }
Ada file konfigurasi, dan ada tata letak penyebaran dalam kode. Dan Anda dapat memverifikasi itu untuk setiap Lingkungan / server / dll. ada file konfigurasi yang sesuai, dan untuk setiap file format yang diperlukan - Lingkungan yang sesuai. Segera setelah Anda lupa menambahkan sesuatu ke satu tempat, tes akan jatuh.
Intinya adalah tata letak penempatan:
- Menyederhanakan penulisan tes kompleks yang menyatukan konfigurasi dari berbagai bagian aplikasi.
- Membuatnya lebih jelas dan lebih mudah dibaca. Mereka melihat cara Anda berpikir tentang mereka pada tingkat tinggi, dan bukan cara mereka melalui konfigurasi.
- Selama pembuatannya, ketika orang mengajukan pertanyaan, ternyata banyak hal menarik tentang penyebaran. Keterbatasan, pengetahuan suci implisit, muncul, misalnya, mengenai kemungkinan hosting dua Lingkungan pada satu server. Ternyata para pengembang berpikir secara berbeda dan menulis layanan mereka sesuai. Dan momen seperti itu berguna untuk diselesaikan di antara para pengembang.
- Nah melengkapi dokumentasi (terutama jika tidak). Bahkan jika ada, lebih menyenangkan bagi saya, sebagai pengembang, untuk melihat ini dalam kode. Selain itu, di sana Anda dapat menulis komentar yang penting bagi saya, dan bukan kepada orang lain. Dan Anda juga bisa hardcode. Artinya, jika Anda memutuskan bahwa tidak ada dua Lingkungan di server yang sama, Anda dapat memasukkan cek, dan sekarang tidak akan. Setidaknya Anda akan mengetahui jika seseorang mencoba. Artinya, ini adalah dokumentasi dengan kemampuan untuk menegakkannya. Ini sangat membantu.
Mari kita lanjutkan. Setelah tes ditulis, mereka "menetap" selama satu tahun, beberapa mulai jatuh. Beberapa mulai jatuh lebih awal, tetapi tidak begitu menakutkan. Menakutkan ketika tes yang ditulis setahun yang lalu jatuh, Anda melihat pesan kesalahannya, dan Anda tidak mengerti.

Misalkan saya mengerti dan setuju bahwa ini adalah port jaringan yang tidak valid - tetapi di mana itu? Sebelum ceramah, saya melihat fakta bahwa kami memiliki 1.200 file properti di proyek, yang tersebar di 90 modul, dengan total 24.000 baris di dalamnya. (Meskipun saya terkejut, tetapi jika Anda menghitung, maka ini bukan jumlah yang besar - untuk satu layanan untuk 4 file.) Di mana port ini?
Jelas bahwa assertThat () memiliki argumen pesan, Anda dapat memasukkan sesuatu di dalamnya yang akan membantu mengidentifikasi tempat. Tetapi ketika Anda menulis tes, Anda tidak memikirkannya. Dan bahkan jika Anda berpikir, Anda masih harus menebak deskripsi mana yang akan cukup rinci untuk dipahami dalam setahun. Saya ingin mengotomatisasi momen ini, sehingga ada cara untuk menulis tes dengan generasi otomatis dengan deskripsi yang kurang lebih jelas, yang dengannya Anda dapat menemukan kesalahan.
Sekali lagi, saya bermimpi dan memimpikan sesuatu seperti ini:
SELECT environment, server, component, configLocation, propertyName, propertyValue FROM configuration(environment, server, component) WHERE propertyName like “%.port%” and propertyValue is not validNetworkPort()
Ini seperti pseudo-SQL - well, saya hanya tahu SQL, dan otak mengeluarkan solusi dari apa yang sudah dikenal. Idenya adalah bahwa sebagian besar tes konfigurasi terdiri dari beberapa bagian dari tipe yang sama. Pertama, subset parameter dipilih oleh kondisi:

Kemudian, mengenai subset ini, kami memeriksa sesuatu sehubungan dengan nilainya:

Dan kemudian, jika ada properti yang nilainya tidak memuaskan keinginan, ini adalah "lembar" yang ingin kita terima dalam pesan kesalahan:

Pada suatu waktu saya bahkan berpikir jika saya bisa menulis parser seperti SQL, karena sekarang tidak sulit. Tapi kemudian saya menyadari bahwa IDE tidak akan mendukungnya dan menyarankannya, jadi orang harus menulis secara membabi buta tentang "SQL" buatan sendiri ini, tanpa dorongan IDE, tanpa kompilasi, tanpa memeriksa - ini tidak terlalu nyaman. Karena itu, saya harus mencari solusi yang didukung oleh bahasa pemrograman kami. Jika kita punya .NET, LINQ akan membantu, itu hampir seperti SQL.
Tidak ada LINQ di Jawa, sedekat mungkin adalah stream. Beginilah tes ini akan terlihat di aliran:
ValueWithContext[] incorrectPorts = flattenedProperties( environment ) .filter( propertyNameContains( ".port" ) ) .filter( !isInteger( propertyValue ) || !isValidNetworkPort( propertyValue ) ) .toArray(); assertThat( incorrectPorts, emptyArray() );
flattenedProperties () mengambil semua konfigurasi lingkungan ini, semua file untuk semua server, layanan dan memperluasnya ke tabel besar. Ini pada dasarnya adalah tabel seperti SQL, tetapi dalam bentuk seperangkat objek Java. Dan flattenedProperties () mengembalikan rangkaian string ini sebagai aliran.

Kemudian Anda menambahkan beberapa kondisi pada set objek Java ini. Dalam contoh ini: kami memilih yang mengandung "port" di propertyName dan memfilter nilai yang tidak dikonversi ke Integer, atau tidak dari rentang yang valid. Ini adalah nilai-nilai yang salah, dan secara teori, itu harus menjadi set kosong.

Jika itu bukan set kosong, kami membuat kesalahan yang akan terlihat seperti ini:

Bagian 3. Pengujian sebagai dukungan untuk refactoring
Biasanya, pengujian kode adalah salah satu dukungan refactoring paling kuat. Refactoring adalah proses berbahaya, banyak pengulangan, dan saya ingin memastikan bahwa setelah itu aplikasi masih layak. Salah satu cara untuk memastikan ini adalah pertama-tama overlay semuanya dengan tes di semua sisi, dan kemudian refactor dengannya.
Dan sekarang, sebelum saya adalah tugas refactoring konfigurasi. Ada aplikasi yang ditulis tujuh tahun lalu oleh satu orang pintar. Konfigurasi aplikasi ini terlihat seperti ini:

Ini adalah contoh, masih banyak lagi. Permutasi bertiga tripel, dan ini digunakan di seluruh konfigurasi:

Ada beberapa file dalam konfigurasi itu sendiri, tetapi mereka disertakan satu sama lain. Ia menggunakan ekstensi kecil Properti iu - Konfigurasi Apache Commons, yang hanya mendukung inklusi dan izin dalam kawat gigi.
Dan penulis melakukan pekerjaan yang fantastis hanya dengan menggunakan dua hal ini. Saya pikir dia membangun mesin Turing di sana. Di beberapa tempat, sepertinya dia mencoba melakukan perhitungan menggunakan inklusi dan substitusi. Saya tidak tahu apakah sistem Turing ini selesai, tetapi dia, menurut saya, mencoba membuktikan bahwa memang demikian.
Dan pria itu pergi. Menulis, aplikasi berfungsi, dan dia meninggalkan bank. Semuanya berfungsi, hanya tidak ada yang sepenuhnya memahami konfigurasi.
Jika kita mengambil layanan terpisah, maka ternyata 10 inklusi, menjadi tiga kedalaman, dan secara total, jika semuanya diperluas, 450 parameter. Bahkan, layanan ini menggunakan 10-15% dari mereka, sisanya parameter untuk layanan lain, karena file tersebut dibagikan, mereka digunakan oleh beberapa layanan. Tapi apa yang tepatnya 10-15% menggunakan layanan khusus ini tidak begitu mudah dimengerti. Penulis tampaknya mengerti. Orang yang sangat pintar, sangat.
Tugasnya masing-masing adalah menyederhanakan konfigurasi, yaitu refactoring. Pada saat yang sama, saya ingin aplikasi tetap berfungsi, karena dalam situasi ini kemungkinannya rendah. Saya ingin:
- Sederhanakan konfigurasinya.
- Sehingga setelah refactoring, setiap layanan masih memiliki semua parameter yang diperlukan.
- Sehingga dia tidak memiliki parameter tambahan. 85% dari mereka yang tidak terkait dengannya tidak boleh mengacaukan halaman.
- Layanan itu masih berhasil terkoneksi dalam cluster dan melakukan kolaborasi.
Masalahnya adalah tidak diketahui seberapa baik mereka terhubung sekarang, karena sistemnya sangat redundan. Sebagai contoh, melihat ke depan: selama refactoring, ternyata di salah satu konfigurasi produksi harus ada empat server di klip cadangan, tetapi sebenarnya ada dua. Karena tingginya tingkat redundansi, tidak ada yang memperhatikan ini - kesalahan muncul secara tidak sengaja, tetapi sebenarnya tingkat redundansi untuk waktu yang lama lebih rendah dari yang kami harapkan. Intinya adalah bahwa kita tidak dapat mengandalkan kenyataan bahwa konfigurasi saat ini benar di mana-mana.
Saya mengarah pada fakta bahwa Anda tidak bisa hanya membandingkan konfigurasi baru dengan yang lama. Ini mungkin setara, tetapi tetap pada saat yang sama di tempat yang salah. Diperlukan untuk memeriksa konten logis.
Program minimum: mengisolasi setiap parameter terpisah dari setiap layanan yang dibutuhkan dan memeriksa kebenarannya, bahwa port adalah port, alamat adalah alamat, TTL adalah angka positif, dll. Dan periksa hubungan kunci bahwa layanan pada dasarnya terhubung pada titik akhir utama. Saya ingin mencapai ini, setidaknya. Artinya, tidak seperti contoh sebelumnya, tugas di sini bukan untuk memverifikasi parameter individual, tetapi untuk mencakup seluruh konfigurasi dengan jaringan pemeriksaan lengkap.
Bagaimana cara mengujinya?
public class SimpleComponent { … public void configure( final Configuration conf ) { int port = conf.getInt( "Port", -1 ); if( port < 0 ) throw new ConfigurationException(); String ip = conf.getString( "Address", null ); if( ip == null ) throw new ConfigurationException(); … } … }
Bagaimana saya mengatasi masalah ini? Ada beberapa komponen sederhana, dalam contoh ini disederhanakan secara maksimal. (Bagi mereka yang belum menemukan Konfigurasi Apache Commons: objek Konfigurasi seperti Properti, hanya saja ia masih memiliki metode yang diketik getInt (), getLong (), dll.; Kita dapat berasumsi bahwa ini adalah juProperties pada steroid kecil.) Misalkan komponen membutuhkan dua parameter: misalnya, alamat TCP dan port TCP. Kami menarik mereka dan memeriksa. Apa empat bagian umum di sini?

Ini adalah nama parameter, tipe, nilai default (di sini sepele: nol dan -1, kadang-kadang ada nilai waras) dan beberapa validasi. Port di sini divalidasi terlalu sederhana, tidak lengkap - Anda dapat menentukan port yang akan melewatinya, tetapi tidak akan menjadi port jaringan yang valid. Karena itu, saya ingin meningkatkan momen ini juga. Tetapi pertama-tama, saya ingin mengubah keempat hal ini menjadi satu hal. Sebagai contoh, ini:
IProperty<Integer> PORT_PROPERTY = intProperty( "Port" ) .withDefaultValue( -1 ) .matchedWith( validNetworkPort() ); IProperty<String> ADDRESS_PROPERTY = stringProperty( "Address" ) .withDefaultValue( null ) .matchedWith( validIPAddress() );
Objek komposit semacam itu adalah deskripsi properti yang mengetahui namanya, nilai default, dapat melakukan validasi (di sini saya menggunakan pencocokan hamcrest lagi). Dan objek ini memiliki sesuatu seperti antarmuka ini:
interface IProperty<T> { FetchedValue<T> fetch( final Configuration config ) } class FetchedValue<T> { public final String propertyName; public final T propertyValue; … }
Artinya, setelah membuat objek spesifik untuk implementasi tertentu, Anda dapat memintanya untuk mengekstrak parameter yang diwakilinya dari konfigurasi. Dan dia akan mengeluarkan parameter ini, memeriksa prosesnya, jika tidak ada parameter, dia akan memberikan nilai default, mengarahkan ke tipe yang diinginkan, dan mengembalikannya segera dengan namanya.
Artinya, di sini adalah nama parameter dan nilai aktual sehingga layanan akan melihat apakah permintaan dari konfigurasi ini. Ini memungkinkan Anda untuk membungkus beberapa baris kode dalam satu entitas, ini adalah penyederhanaan pertama yang saya butuhkan.
Penyederhanaan kedua yang saya butuhkan untuk menyelesaikan masalah adalah memperkenalkan komponen yang membutuhkan beberapa properti untuk konfigurasinya. Model konfigurasi komponen:

Kami memiliki komponen yang menggunakan dua properti ini, ada model untuk konfigurasinya - antarmuka IConfigurationModel, yang diterapkan oleh kelas ini. IConfigurationModel melakukan semua yang dilakukan komponen, tetapi hanya bagian yang berhubungan dengan konfigurasi. Jika komponen memerlukan parameter dalam urutan tertentu dengan nilai default tertentu - IConfigurationModel menggabungkan informasi ini dengan sendirinya, merangkumnya. Semua tindakan lain dari komponen tidak penting baginya. Ini adalah model komponen dalam hal akses konfigurasi.

Trik dari pandangan ini adalah bahwa model dapat dikombinasikan. Jika ada komponen yang menggunakan komponen lain, dan mereka digabungkan di sana, maka dengan cara yang sama model komponen kompleks ini dapat menggabungkan hasil panggilan dari dua subkomponen.
Artinya, dimungkinkan untuk membangun hierarki model konfigurasi yang sejajar dengan hierarki komponen itu sendiri. Pada model atas, panggil fetch (), yang akan mengembalikan lembar dari parameter yang ia tarik dari konfigurasi dengan nama mereka - persis yang dibutuhkan komponen terkait secara real time. Jika kami menulis semua model dengan benar, tentu saja.
Artinya, tugasnya adalah menulis model seperti itu untuk setiap komponen dalam aplikasi yang memiliki akses ke konfigurasi. Dalam aplikasi saya, ada beberapa komponen seperti itu: aplikasi itu sendiri cukup banyak, tetapi aktif menggunakan kembali kode, sehingga hanya 70 kelas utama yang dikonfigurasi. Bagi mereka, saya harus menulis 70 model.
Berapa biayanya:
- 12 layanan
- 70 kelas yang dapat dikonfigurasi
- => 70 ConfigurationModels (~ 60 adalah sepele);
- 1-2 orang minggu.
Saya hanya membuka layar dengan kode komponen yang mengkonfigurasi sendiri, dan pada layar berikutnya saya menulis kode untuk ConfigurationModel yang sesuai. Kebanyakan dari mereka sepele, seperti contoh yang ditunjukkan. Dalam beberapa kasus, ada cabang dan transisi kondisional - ada kode menjadi lebih bercabang, tetapi semuanya juga diselesaikan. Dalam satu setengah hingga dua minggu saya memecahkan masalah ini, untuk semua 70 komponen saya menggambarkan model.
Alhasil, ketika kami menggabungkan semuanya, kami mendapatkan kode berikut:

Untuk setiap layanan / lingkungan / dll. kami mengambil model konfigurasi, yaitu, simpul teratas dari pohon ini, dan meminta untuk mendapatkan semuanya dari konfigurasi. Pada titik ini, semua validasi masuk ke dalam, masing-masing properti, ketika menarik diri dari konfigurasi, memeriksa nilainya untuk kebenaran. Jika setidaknya satu tidak lulus, pengecualian akan terbang keluar. Semua kode diperoleh dengan memeriksa bahwa semua nilai valid dalam isolasi.
Saling Ketergantungan Layanan
Kami masih memiliki pertanyaan bagaimana cara memeriksa saling ketergantungan layanan. Ini sedikit lebih rumit, Anda perlu melihat saling ketergantungan seperti apa. Ternyata bagi saya bahwa saling ketergantungan bermuara pada kenyataan bahwa layanan harus "bertemu" pada titik akhir jaringan. Layanan A harus mendengarkan dengan tepat alamat tempat layanan B mengirim paket, dan sebaliknya. Dalam contoh saya, semua dependensi antara konfigurasi berbagai layanan datang ke ini. Dimungkinkan untuk menyelesaikan masalah ini dengan cara yang sangat mudah: dapatkan port dan alamat dari berbagai layanan dan periksa. Akan ada banyak tes, mereka akan menjadi besar. Saya orang yang malas dan saya tidak menginginkan ini. Karena itu, saya melakukan sebaliknya.
Pertama, saya ingin mengabstraksi titik akhir jaringan ini sendiri. Misalnya, untuk koneksi TCP Anda hanya perlu dua parameter: alamat dan port. Untuk koneksi multicast, empat parameter. Saya ingin memecahnya menjadi semacam objek. Saya melakukan ini pada objek Endpoint, yang di dalamnya menyembunyikan semua yang Anda butuhkan. Slide adalah contoh dari OutcomingTCPEndpoint, koneksi jaringan TCP keluar.
IProperty<IEndpoint> TCP_REQUEST = outcomingTCP(
Di luar, antarmuka Endpoint dikeluarkan oleh metode satunya pertandingan (), di mana Anda dapat memberikan Endpoint lain, dan mencari tahu apakah pasangan ini mirip dengan bagian server dan klien dari satu koneksi.Mengapa "seperti"? Karena kami tidak tahu apa yang akan terjadi dalam kenyataan: mungkin, secara formal, itu harus terhubung ke alamat port, tetapi pada jaringan nyata ada firewall di antara node-node ini - kami tidak dapat memeriksanya hanya dengan konfigurasi. Tapi kita bisa mencari tahu apakah mereka sudah secara resmi tidak cocok dengan port / alamat. Kemudian, kemungkinan besar, dan pada kenyataannya mereka juga tidak akan terhubung satu sama lain.Dengan demikian, alih-alih nilai properti primitif, grup port-address-multicast, kami sekarang memiliki properti kompleks yang mengembalikan Endpoint. Dan di semua ConfigurationModels, alih-alih properti terpisah, ada yang kompleks. Apa yang ini berikan pada kita? Ini memberi kami semacam ini pemeriksaan konektivitas cluster: ValueWithContext[] allEndpoints = flattenedConfigurationValues(environment) .filter( valueIsEndpoint() ) .toArray(); ValueWithContext[] unpairedEndpoints = Arrays.stream( allEndpoints ) .filter( e -> !hasMatchedEndpoint(e, allEndpoints) ) .toArray(); assertThat( unpairedEndpoints, emptyArray() );
Dari semua properti dari lingkungan ini, kami memilih titik akhir, dan kemudian kami hanya menentukan apakah ada yang tidak terhubung dengan siapa pun dan tidak terhubung dengan siapa pun. Semua mesin sebelumnya memungkinkan Anda melakukan pemeriksaan ini dalam beberapa baris. Di sini, khususnya, kompleksitas memeriksa "semua orang dengan semua orang" akan menjadi O (n ^ 2), tetapi ini tidak begitu penting, karena ada sekitar seratus titik akhir, Anda bahkan tidak dapat mengoptimalkannya.Yaitu, untuk setiap Titik Akhir, kami melewati semua hal lain dan mencari tahu, jika setidaknya satu, yang terhubung dengannya. Jika tidak ada yang ditemukan, kemungkinan besar dia seharusnya ada di sana, tetapi karena kesalahan dia pergi.Secara umum, mungkin layanan memiliki lubang yang menonjol "keluar" - yaitu, untuk layanan eksternal, di luar aplikasi saat ini. Lubang seperti itu perlu disaring secara eksplisit. Saya beruntung, dalam kasus saya, klien eksternal terhubung melalui lubang yang sama yang digunakan oleh layanan itu sendiri. Ini sangat tertutup dan ekonomis dalam arti koneksi jaringan.Ini adalah solusi untuk masalah pengujian. Dan saya ingat, tugas utama adalah refactoring. Dan saya siap untuk melakukan refactoring dengan tangan saya, tetapi ketika saya melakukan semua tes ini dan mereka mulai bekerja, saya menyadari bahwa saya dapat melakukan refactoring secara otomatis untuk perubahan.Semua hierarki ConfigurationModel ini memungkinkan Anda untuk:- Konversikan ke format lain
- Lakukan permintaan konfigurasi ("semua port udp digunakan oleh layanan di server ini")
- .
Saya dapat menyeret seluruh konfigurasi ke dalam memori sedemikian rupa sehingga setiap properti melacak asalnya. Setelah itu, saya dapat mengubah konfigurasi ini dalam memori, dan menuangkannya ke file lain, dalam urutan berbeda, dalam format yang berbeda - seperti yang cocok untuk saya. Jadi saya lakukan: Saya menulis kode kecil untuk mengubah lembar itu ke dalam bentuk di mana saya ingin mengubahnya. Sebenarnya, saya harus melakukan ini beberapa kali, karena pada awalnya tidak jelas format mana yang nyaman dan mudah dimengerti, dan saya harus melakukan beberapa kunjungan untuk mencobanya.Tetapi ini tidak cukup. Dengan konstruksi ini, menggunakan ConfigurationModels, saya dapat menjalankan permintaan konfigurasi. Angkat ke dalam memori dan cari tahu port UDP spesifik apa yang digunakan pada server ini oleh layanan yang berbeda, mintalah daftar port yang digunakan, dengan instruksi layanan.Selain itu, saya dapat menghubungkan layanan pada titik akhir dan menampilkannya dalam bentuk diagram, ekspor ke .dot. Dan permintaan serupa lainnya mudah dibuat. Hasilnya adalah pisau Swiss - biaya konstruksi terbayar dengan cukup baik.Di sinilah saya berakhir. Kesimpulan:
- Menurut pendapat saya, dalam pengalaman saya, menguji konfigurasi itu penting dan menyenangkan.
- Ada banyak buah yang menggantung rendah, ambang entri untuk memulai rendah. Anda dapat memecahkan masalah yang rumit, tetapi ada juga banyak masalah sederhana.
- Jika Anda menggunakan sedikit otak, Anda bisa mendapatkan alat canggih yang memungkinkan Anda untuk tidak hanya menguji, tetapi masih ada banyak hubungannya dengan konfigurasi.
Jika Anda menyukai laporan ini dari Heisenbug 2018 Piter, harap dicatat: pada 6-7 Desember, Heisenbug berikutnya akan diadakan di Moskow . Sebagian besar deskripsi laporan baru sudah tersedia di situs web konferensi . Dan mulai 1 November, harga tiket naik - jadi masuk akal untuk mengambil keputusan sekarang.