Hai, nama saya Maxim, saya seorang administrator sistem. Tiga tahun yang lalu, kolega saya dan saya mulai mentransfer produk ke layanan microser, dan memutuskan untuk menggunakan Openstack sebagai platform, dan kami menemukan sejumlah garu yang tidak terlihat saat mengotomatisasi sirkuit uji. Posting ini adalah tentang nuansa pengaturan OpenStack, yang hampir tidak ditemukan di halaman kelima hasil mesin pencari (atau lebih baik, mereka dengan mudah di yang pertama).
Beban pada inti: itu - itu menjadi
NAT
Dalam beberapa kasus kami menggunakan dualstack. Inilah saat mesin virtual menerima dua alamat sekaligus - IPv4 dan IPv6. Pertama, kami memastikan bahwa alamat "mengambang" v4 ditugaskan di jaringan internal melalui NAT, dan mesin menerima v6 melalui BGP, tetapi ada beberapa masalah dengan ini.
NAT - node tambahan dalam jaringan, di mana bahkan tanpa itu Anda perlu memantau distribusi beban normal. Munculnya NAT di jaringan hampir selalu menyebabkan kesulitan dengan debugging - ada satu IP di host, yang lainnya di database, dan menjadi sulit untuk melacak permintaan. Pencarian massal dimulai, dan solusinya masih di dalam OpenStack.
Namun NAT tidak memungkinkan untuk melakukan segmentasi akses yang normal antar proyek. Semua proyek memiliki subnet mereka sendiri, IP mengambang terus bermigrasi, dan dengan NAT jelas tidak mungkin untuk mengelola ini. Dalam beberapa instalasi, mereka berbicara tentang penggunaan NAT 1 in 1 (alamat internal tidak berbeda dari yang eksternal), tetapi ini masih meninggalkan tautan yang tidak perlu dalam rantai interaksi dengan layanan eksternal. Kami sampai pada kesimpulan bahwa bagi kami pilihan terbaik adalah jaringan BGP.
Semakin sederhana semakin baik
Kami mencoba berbagai alat otomatisasi, tetapi memutuskan pada Ansible. Ini adalah alat yang baik, tetapi fungsionalitas standarnya (bahkan dengan mempertimbangkan modul tambahan) mungkin tidak cukup dalam beberapa situasi sulit.
Misalnya, melalui modul Ansible, Anda tidak dapat menentukan dari mana alamat subnet yang akan dialokasikan. Artinya, Anda dapat menentukan jaringan, tetapi Anda tidak dapat menetapkan kumpulan alamat tertentu. Perintah shell yang membuat IP mengambang akan membantu di sini:
openstack floating ip create -c floating_ip_address -f value -project \ {{ project name }} —subnet private-v4 CLOUD_NET
Contoh lain dari fungsionalitas yang hilang: karena dualstack, kami tidak dapat membuat router dengan dua port untuk v4 dan v6. Di sinilah skrip bash berguna:
Script membuat router, menambahkan subnet v4 dan v6 ke dalamnya, dan menetapkan gateway eksternal.
Coba lagi
Dalam situasi apa pun yang tidak bisa dipahami - restart. Coba lagi, buat instance, router atau catatan DNS, karena Anda tidak selalu mengerti dengan cepat apa masalah Anda. Coba lagi dapat menunda penurunan layanan, dan saat ini Anda dapat dengan tenang dan tanpa saraf menyelesaikan masalah.
Semua tips di atas benar-benar berfungsi baik dengan Terraform, Wayang, dan apa pun.
Semuanya ada tempatnya
Layanan besar apa pun (tidak terkecuali OpenStack) menggabungkan banyak layanan kecil yang dapat mengganggu pekerjaan masing-masing. Berikut ini sebuah contoh.
Network Agent Neutron-L2-agent bertanggung jawab untuk konektivitas jaringan di OpenStack. Jika semua agen lain sebagian pada pengendali, maka L2, karena spesifiknya, ada di mana-mana.
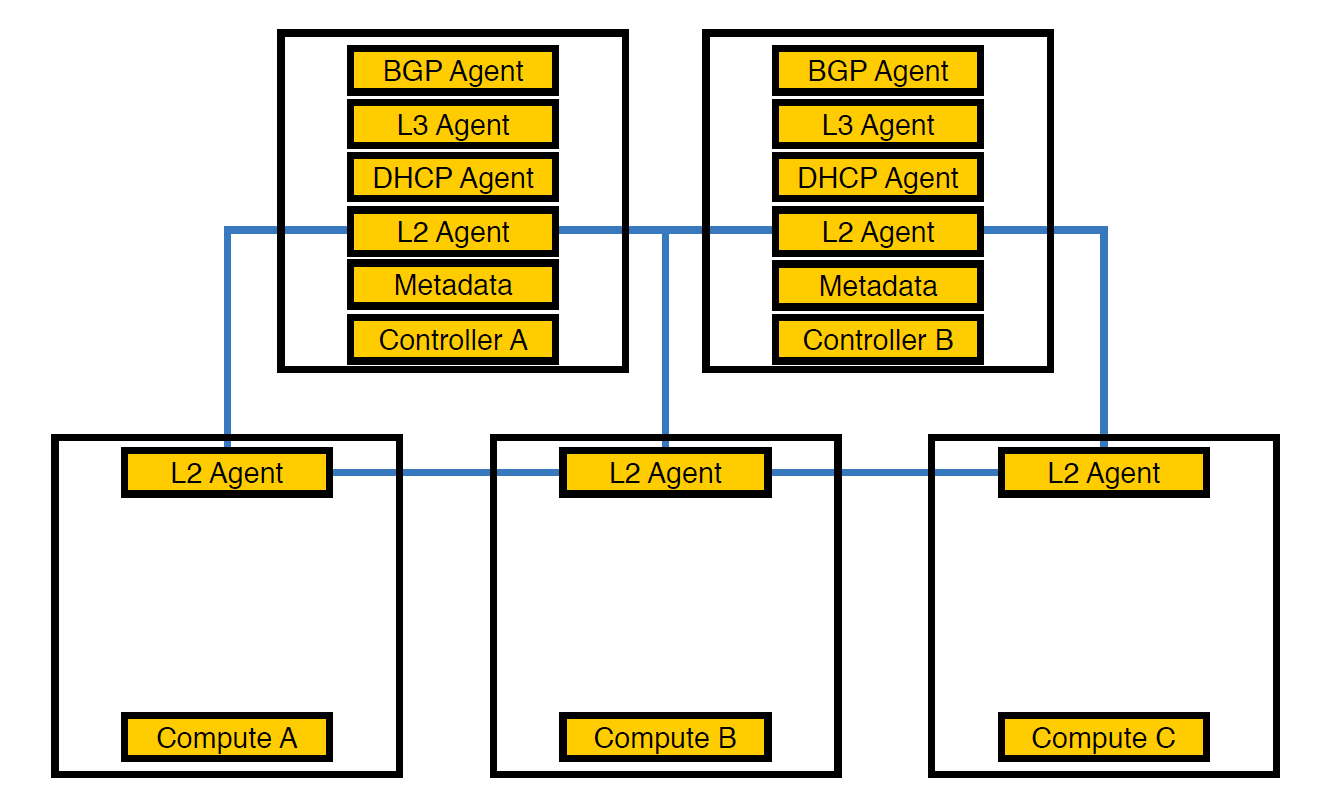
Beginilah infrastruktur kami terlihat sejak awal, hingga jumlah skema melebihi 50
Pada titik ini, kami menyadari bahwa karena pengaturan agen ini, pengendali tidak dapat mengatasi beban, dan mentransfer agen untuk menghitung node. Mereka lebih kuat daripada pengontrol, dan selain itu, pengontrol tidak harus berurusan dengan pemrosesan segalanya - ia harus memberikan tugas kepada node yang mengeksekusi, dan node akan mengeksekusinya.

Agen yang ditransfer untuk menghitung node
Namun, ini tidak cukup, karena pengaturan seperti itu berdampak buruk pada kinerja mesin virtual. Dengan kepadatan 14 inti virtual per fisik, jika satu agen jaringan mulai memuat aliran, ini dapat mempengaruhi beberapa mesin virtual sekaligus.
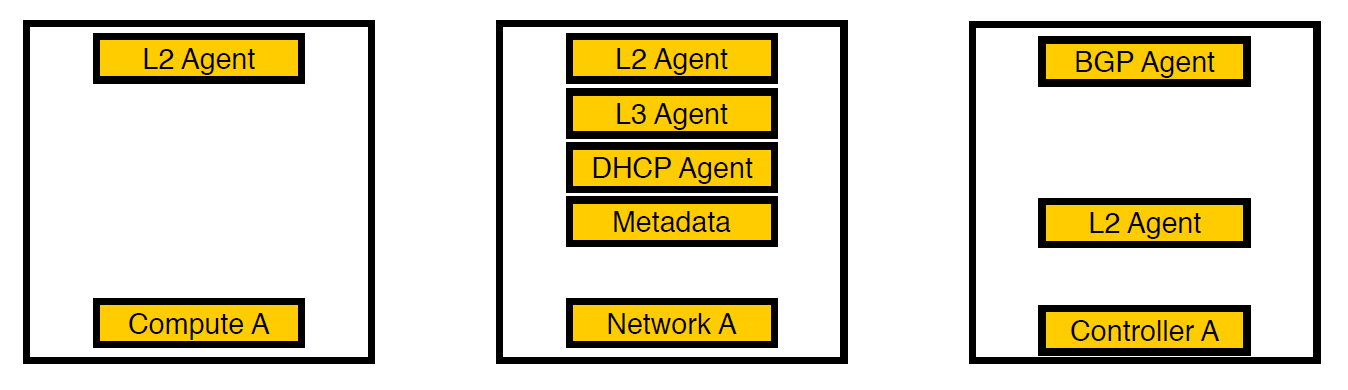
Iterasi ketiga. Node yang dipilih muncul.
Kami berpikir dan memindahkan agen ke node jaringan yang terpisah. Sekarang hanya layanan untuk mesin virtual tetap pada node komputasi, semua agen bekerja pada node jaringan, dan hanya agen bgp yang berhubungan dengan jaringan v6 tetap pada pengendali (karena satu agen bgp hanya dapat melayani satu jenis jaringan). L2 tetap ada di mana-mana, karena tanpa itu, seperti yang kami tulis di atas, tidak akan ada konektivitas di jaringan.
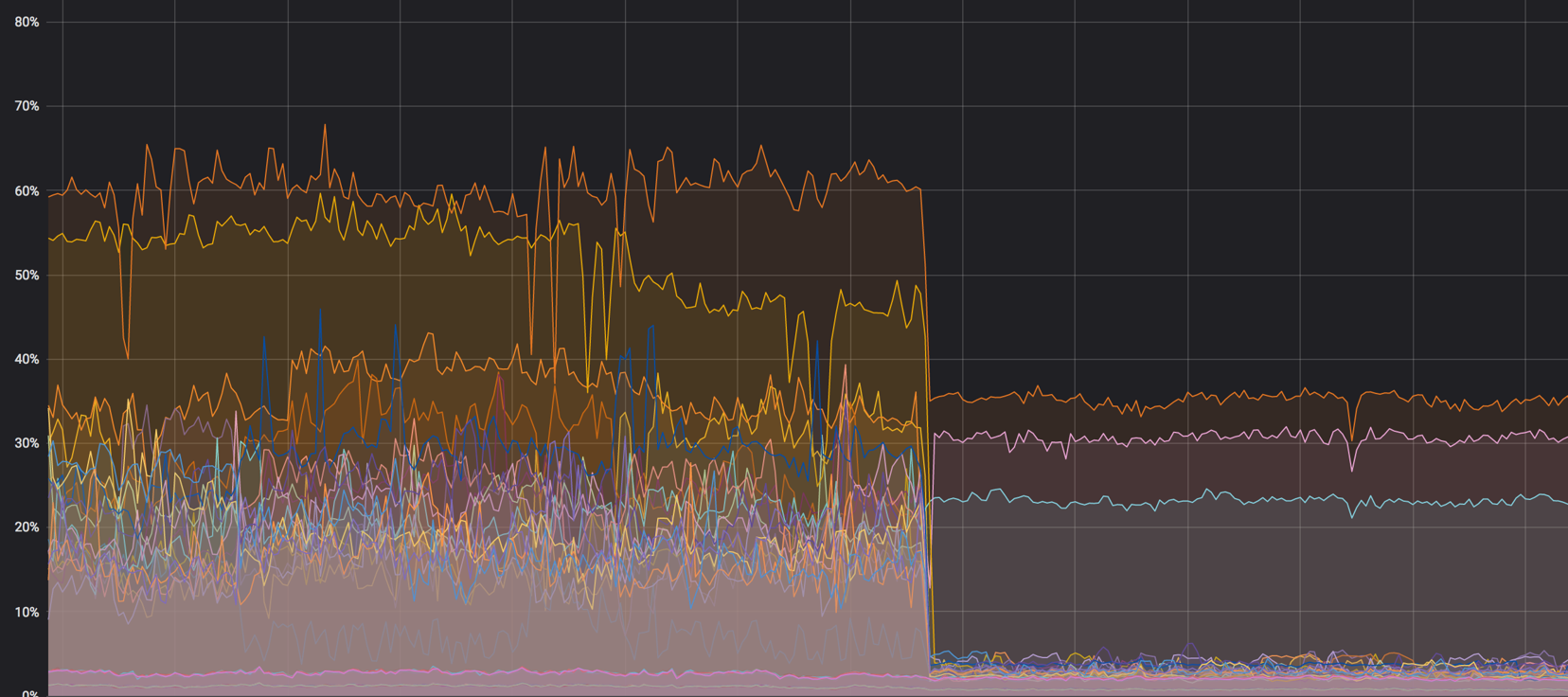
Muat grafik dari node komputasi sebelum semuanya dicampur. Itu sekitar 60%, tetapi bebannya turun tidak signifikan

Beban pada softirq sebelum agen jaringan menghapus node komputasi. 3 core tetap dimuat. Pada saat itu, kami pikir itu normal
Kode sebagai Dokumentasi
Terkadang kode tersebut adalah dokumentasi, terutama dalam layanan besar seperti OpenStack. Dengan siklus rilis enam bulan, pengembang lupa atau tidak punya waktu untuk mendokumentasikan beberapa hal, dan ternyata seperti pada contoh di bawah ini.
Tentang batas waktu
Setelah kami melihat bahwa panggilan Neutron ke Open vSwitch tidak cocok dalam lima detik dan jatuh dalam batas waktu.
127.0.0.1:29696: no response to inactivity probe after 10 seconds, disconnecting neutron.agent.ovsdb.native.commands TimeoutException: Commands [DbSetCommand(table=Port, col_values=(('tag', 11),), record=qtoq69a81c6-e2)] exceeded timeout 5 seconds
Tentu saja, kami berasumsi bahwa di suatu tempat dalam pengaturan ini sudah diperbaiki. Kami mencari di paket konfigurasi, dokumentasi dan deb, tetapi pada awalnya mereka tidak menemukan apa pun. Akibatnya, deskripsi pengaturan yang diinginkan ditemukan di halaman kelima hasil pencarian - kami melihat kode lagi dan menemukan tempat yang tepat. Pengaturannya adalah ini:
ovs_vsctl_timeout = 30
Kami mengaturnya selama 30 detik (itu 5), dan semuanya mulai bekerja sedikit lebih baik.
Berikut ini hal lain yang tidak terlihat - ketika Anda mem-boot ulang komponen jaringan, beberapa pengaturan Open vSwitch mungkin diatur ulang. Ini, misalnya, terjadi dengan ovs-vsctl inactivity_probe. Ini juga merupakan batas waktu, tetapi memengaruhi panggilan ovs-vsctl sendiri ke basis datanya. Kami menambahkannya ke systemd init, yang memungkinkan kami memulai semua sakelar dengan parameter yang kami butuhkan saat startup.
ovs-vsctl set Controller "br-int" inactivity_probe=30000
Tentang pengaturan tumpukan jaringan
Kami juga harus pindah sedikit dari pengaturan yang diterima secara umum di tumpukan jaringan, yang kami gunakan di server kami yang lain.
Berikut adalah pengaturan untuk berapa lama waktu yang diperlukan untuk menyimpan catatan ARP dalam tabel:
net.ipv4.neigh.default.base_reachable_time = 60 net.ipv4.neigh.default.gc_stale_time=60
Nilai default adalah 1 hari. Secara umum, satu skema dapat hidup selama beberapa minggu, tetapi untuk satu hari, skema dapat dibuat kembali 4-6 kali, sementara korespondensi alamat MAC dan alamat IP terus berubah. Agar sampah tidak menumpuk, kami mengatur waktu ke satu menit.
net.ipv4.conf.default.arp_notify = 1 net.nf_conntrack_max = 1000000 (default 262144) net.netfilter.nf_conntrack_max = 1000000 (default 262144)
Selain itu, kami memaksa pengiriman pemberitahuan ARP ketika meningkatkan antarmuka jaringan. Kami juga meningkatkan tabel conntrack, karena ketika menggunakan NAT dan ip mengambang, kami tidak memiliki nilai default. Meningkat menjadi satu juta (dengan default pada 262 144), semuanya menjadi lebih baik.
Kami memperbaiki ukuran tabel MAC Open vSwitch itu sendiri:
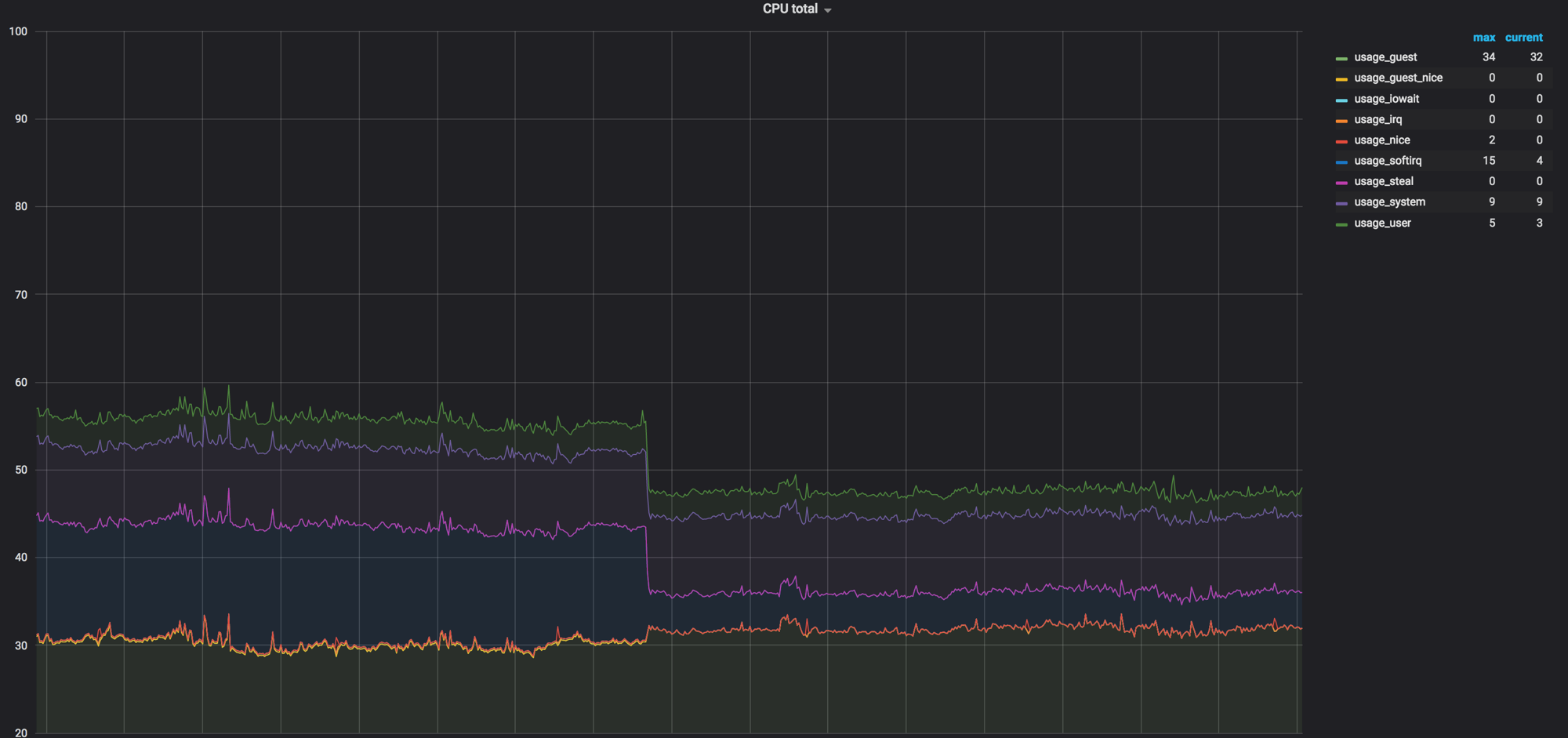
ovs-vsctl set bridge bt-int other-config:mac-table-size=50000 (default 2048)

Setelah semua pengaturan, 40% dari beban berubah menjadi hampir nol
rx-flow-hash
Untuk mendistribusikan pemrosesan lalu lintas udp di antara semua antrian dan utas prosesor, kami menyertakan rx-flow-hash. Pada kartu jaringan Intel, yaitu pada driver i40e, opsi ini dinonaktifkan secara default. Kami memiliki hypervisor dengan 72 core di infrastruktur kami, dan jika hanya satu yang sibuk, maka ini tidak terlalu optimal.
Ini dilakukan seperti ini:
ethtool -N eno50 rx-flow-hash udp4 sdfn

Kesimpulan penting: Anda dapat mengonfigurasi semuanya sama sekali. Konfigurasi default akan cocok di beberapa titik (seperti yang kami lakukan), tetapi masalah dengan timeout membuatnya perlu untuk mencari. Dan ini normal.
Aturan keamanan
Menurut persyaratan layanan keamanan, semua proyek dalam perusahaan memiliki aturan pribadi dan global - ada cukup banyak. Ketika kami pindah ke luar negeri dari 300 mesin virtual ke satu hypervisor, semua ini mengalir ke 80 ribu aturan untuk iptables. Untuk iptables sendiri, ini bukan masalah, tetapi Neutron memuat aturan-aturan ini dari RabbitMQ ke dalam satu aliran (karena ditulis dengan Python, dan semuanya sedih dengan multithreading di sana). Agen Neutron membeku, kehilangan koneksi dengan RabbitMQ dan reaksi berantai dari timeout, dan setelah pemulihan, Neutron meminta kembali semua aturan, memulai sinkronisasi, dan semuanya dimulai dari awal lagi.
Seiring dengan ini, waktu untuk membuat dudukan meningkat dari 20-40 menit menjadi, paling lama, satu jam.
Pada awalnya, kami hanya membungkus semuanya dengan mengambil (sudah pada tahap ini kami menyadari bahwa masalahnya tidak dapat diselesaikan dengan cepat), dan kemudian kami mulai menggunakan FWaaS . Dengan itu, kami mengeluarkan aturan keamanan dengan menghitung node untuk memisahkan node jaringan di mana router itu sendiri berada.

Sumber - docs.openstack.org
Dengan demikian, di dalam proyek ada akses penuh ke semua yang diperlukan, dan aturan keamanan diterapkan untuk koneksi eksternal. Jadi kami mengurangi beban pada Neutron dan kembali ke 20-30 menit untuk menciptakan lingkungan pengujian.
Ringkasan
OpenStack adalah hal yang keren di mana Anda dapat mendaur ulang besi, membuat cloud internal dan membuat sesuatu yang lain berdasarkan itu. Selain itu, ada komunitas besar dan grup aktif di Telegram , di mana mereka meminta kami tentang timeout.
Itu saja. Ajukan pertanyaan, kolega saya dan saya siap menjawab dan berbagi pengalaman kami.