Tugas panjang dan monoton sering dijumpai dalam pekerjaan, untuk solusi yang dibutuhkan banyak orang. Misalnya, mendekripsi beberapa ratus rekaman audio, menandai ribuan gambar atau memfilter komentar, yang jumlahnya terus bertambah. Untuk tujuan ini, Anda dapat mempertahankan lusinan karyawan penuh-waktu. Tetapi semuanya harus ditemukan, dipilih, dimotivasi, dikontrol, dipastikan berkembang dan pertumbuhan karier. Dan jika jumlah pekerjaan dikurangi, mereka harus dilatih ulang atau dipecat.
Dalam banyak kasus, terutama jika pelatihan khusus tidak diperlukan, pekerjaan seperti itu dapat dilakukan oleh para pelaksana platform crowdsourcing Yandex. Sistem ini mudah diskalakan: jika ada lebih sedikit tugas dari satu pelanggan, tolokers akan pergi ke yang lain, jika jumlah tugas meningkat, mereka hanya akan senang.
Di bawah potongan adalah contoh bagaimana Toloka membantu Yandex dan perusahaan lain mengembangkan produk mereka. Semua judul dapat diklik - tautan mengarah ke laporan.

MIPT menggunakan Toloka untuk menilai kualitas bot obrolan sebagai bagian dari DeepHack.Chat hackathon. Itu melibatkan 6 tim. Tugasnya adalah mengembangkan chatbot yang dapat berbicara tentang dirinya sendiri berdasarkan profil yang diberikan kepadanya dengan deskripsi singkat tentang karakteristik pribadi.

Toloker dan bot menerima profil dan harus berpura-pura menjadi orang dalam dialog yang uraiannya diberikan di sana, menceritakan tentang diri mereka sendiri dan belajar lebih banyak tentang lawan bicara. Peserta dialog tidak melihat profil masing-masing.
Hanya pengguna yang lulus tes kecakapan berbahasa Inggris diizinkan untuk tugas itu, karena semua bot obrolan dalam hackathon berbicara bahasa Inggris. Mustahil untuk mengatur dialog dengan bot secara langsung melalui Toloka, jadi dalam tugas tersebut tautan diberikan ke saluran Telegram tempat bot obrolan diluncurkan.
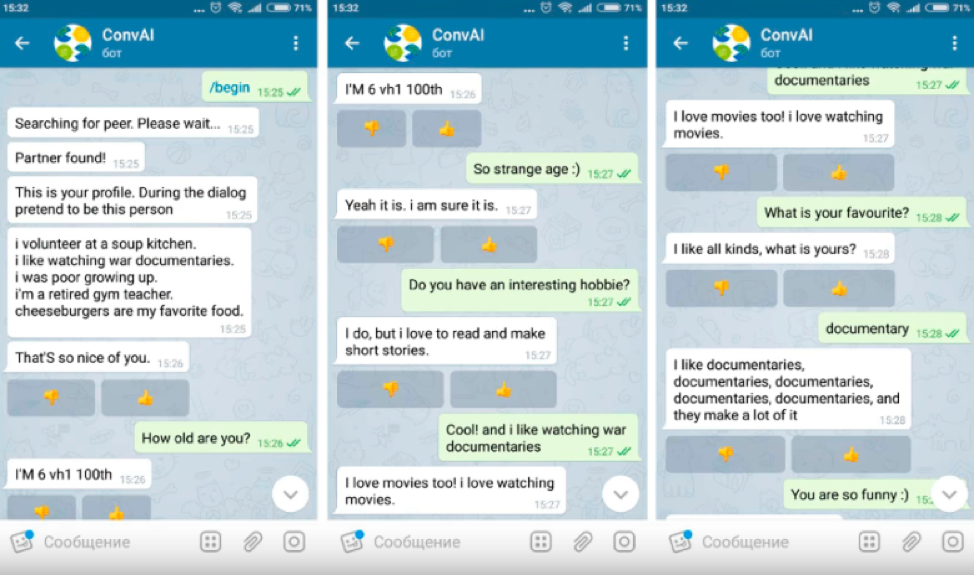
Setelah berbicara dengan bot, pengguna menerima ID dialog, yang, bersama dengan evaluasi dialog, dimasukkan ke dalam Toloka sebagai jawaban.
Untuk mengecualikan tolokers yang tidak jujur, perlu untuk memeriksa seberapa baik pengguna berbicara dengan bot. Untuk melakukan ini, kami membuat tugas terpisah, di mana pelaku membaca dialog dan mengevaluasi perilaku pengguna, yaitu, penembak dari tugas sebelumnya.
Selama hackathon, tim mengunggah bot obrolan mereka. Pada siang hari, para tolkers menguji mereka, mempertimbangkan kualitas dan memberi tahu tim skor, setelah itu para pengembang mengedit perilaku sistem mereka.
Dalam empat hari, sistem hackathon telah meningkat secara signifikan. Pada hari pertama, bot memiliki jawaban yang tidak sesuai dan duplikat, pada hari keempat, jawaban menjadi lebih memadai dan terperinci. Bot belajar tidak hanya untuk menjawab pertanyaan, tetapi juga untuk bertanya.
Contoh dialog pada hari pertama hackathon:

Di hari keempat:

Statistik: penilaian berlangsung selama 4 hari, sekitar 200 tol berpartisipasi di dalamnya dan 1800 dialog diproses. Mereka menghabiskan $ 180 untuk tugas pertama, dan $ 15 untuk yang kedua. Persentase dialog yang valid ternyata lebih tinggi daripada ketika bekerja dengan sukarelawan.
Tugas penting pencipta drone adalah mengajarinya mengekstrak informasi tentang objek di sekitarnya dari data yang ia terima dari sensor. Selama perjalanan, mobil merekam semua yang dilihatnya. Data ini dituangkan ke dalam cloud, tempat analitik utama dilakukan, dan kemudian menuju post-processing, yang mencakup markup. Data berlabel dikirim ke algoritma pembelajaran mesin, hasilnya dikembalikan ke mesin, dan siklus berulang, meningkatkan kualitas pengenalan objek.
Ada banyak berbagai objek di kota, semuanya harus ditandai. Tugas ini membutuhkan keterampilan tertentu dan membutuhkan banyak waktu, dan puluhan ribu gambar diperlukan untuk melatih jaringan saraf. Mereka dapat diambil dari dataset terbuka, tetapi mereka dikumpulkan di luar negeri, sehingga gambar tidak sesuai dengan kenyataan Rusia. Anda dapat membeli gambar yang ditandai untuk $ 4, tetapi kenaikan harga di Tolok sekitar 10 kali lebih murah.
Karena di Tolok Anda dapat menyematkan antarmuka apa pun dan mentransfer data melalui API, pengembang telah memasukkan editor visual mereka sendiri, yang memiliki lapisan, transparansi, pemilihan, pembesaran, pembagian ke dalam kelas. Ini beberapa kali meningkatkan kecepatan dan kualitas markup.
Selain itu, API memungkinkan Anda untuk secara otomatis membagi tugas menjadi lebih sederhana dan mengumpulkan hasilnya dari bagian-bagian. Misalnya, sebelum menandai gambar, Anda dapat menandai objek mana yang ada di sana. Ini akan memberikan pemahaman tentang apa kelas untuk menandai gambar.
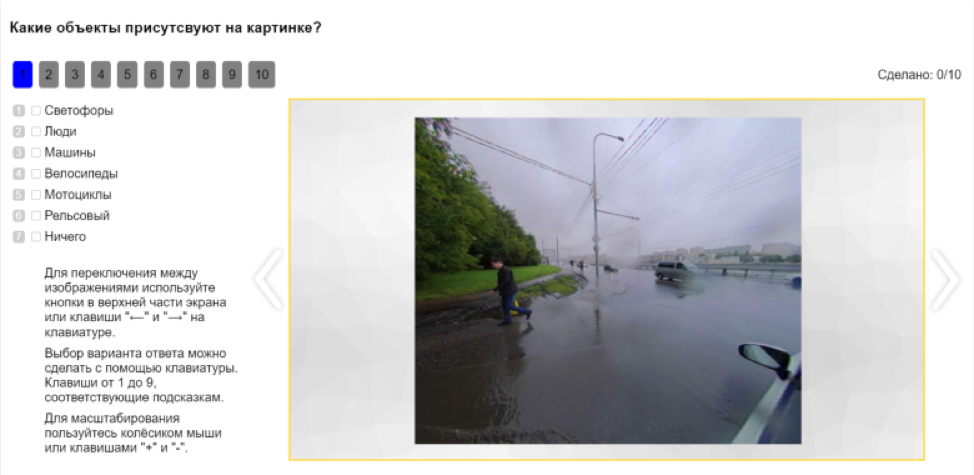
Setelah itu, objek dalam gambar dapat diklasifikasikan. Misalnya, untuk menawarkan kepada para penembak gambar pilihan di mana ada orang, dan minta mereka untuk menjelaskan apakah ini pejalan kaki, pengendara sepeda, pengendara sepeda motor atau orang lain.

Ketika tolker telah menyelesaikan markup, itu perlu diperiksa. Untuk melakukan ini, tugas pengujian dibuat yang ditawarkan ke pemain lain.

Tidak hanya tolokers, tetapi juga jaringan saraf terlibat dalam penandaan. Beberapa dari mereka sudah belajar untuk mengatasi tugas ini tidak lebih buruk daripada orang. Tetapi kualitas pekerjaan mereka juga perlu dievaluasi. Oleh karena itu, dalam tugas, selain gambar yang ditandai dengan tolokers, ada juga yang ditandai dengan jaringan saraf.
Jadi Toloka terintegrasi langsung ke dalam proses pembelajaran jaringan saraf dan menjadi bagian dari pipa semua pembelajaran mesin.
Ozon menggunakan Toloka untuk membuat sampel referensi. Ini untuk beberapa tujuan.
• Penilaian kualitas mesin pencari baru.
• Menentukan model peringkat yang paling efektif.
• Meningkatkan kualitas algoritma pencarian menggunakan pembelajaran mesin.
Sampel uji pertama dibuat secara manual - kami menerima 100 permintaan dan menandainya sendiri. Bahkan sampel sekecil itu membantu mengidentifikasi masalah pencarian dan menentukan kriteria evaluasi. Perusahaan ingin membuat alat mereka sendiri untuk menilai kualitas pencarian, merekrut penilai dan melatih mereka, tetapi itu akan memakan waktu terlalu banyak, jadi kami memutuskan untuk memilih platform crowdsourcing yang sudah jadi.
Tahap paling sulit dalam mempersiapkan tugas untuk tolokers adalah pelatihan - bahkan karyawan perusahaan tidak dapat melakukan tugas tes pertama. Setelah menerima umpan balik dari tim, kami mengembangkan tes baru: kami membangun pelatihan dari tugas yang sederhana hingga rumit dan disusun dengan mempertimbangkan kualitas-kualitas penting pemain untuk perusahaan.
Untuk menghilangkan kesalahan, Ozon melakukan uji coba. Tugas terdiri dari tiga blok - pelatihan, kontrol dengan ambang batas 60% dari jawaban yang benar dan tugas utama dengan ambang batas 80% dari jawaban yang benar. Untuk meningkatkan kualitas sampel, satu tugas ditawarkan kepada lima pemain.
Statistik uji coba: 350 tugas dalam 40 menit. Anggarannya adalah $ 12. Tahap pertama dihadiri oleh 147 pemain, 77 dilatih, 12 mendapatkan keterampilan dan melakukan tugas utama.
Skenario peluncuran utama menjadi lebih rumit: tidak hanya pelanggan baru, tetapi juga mereka yang menerima keterampilan yang diperlukan pada tahap pengujian, berpartisipasi di dalamnya. Yang pertama berjalan di sepanjang rantai standar, yang kedua segera dimasukkan ke tugas utama. Dalam peluncuran utama, keterampilan tambahan ditambahkan - persentase jawaban yang benar dalam sampel utama dan pendapat mayoritas. Tugas itu masih ditawarkan kepada lima pemain.
Statistik peluncuran utama: 40.000 pekerjaan dalam satu bulan. Anggaran berjumlah 1150 dolar. 1117 tolkers datang ke proyek, 18 mendapat keterampilan, 6 mendapat akses ke kumpulan utama terbesar dan mengevaluasinya.
Sekarang pekerjaan Tolok Ozon adalah seperti ini:
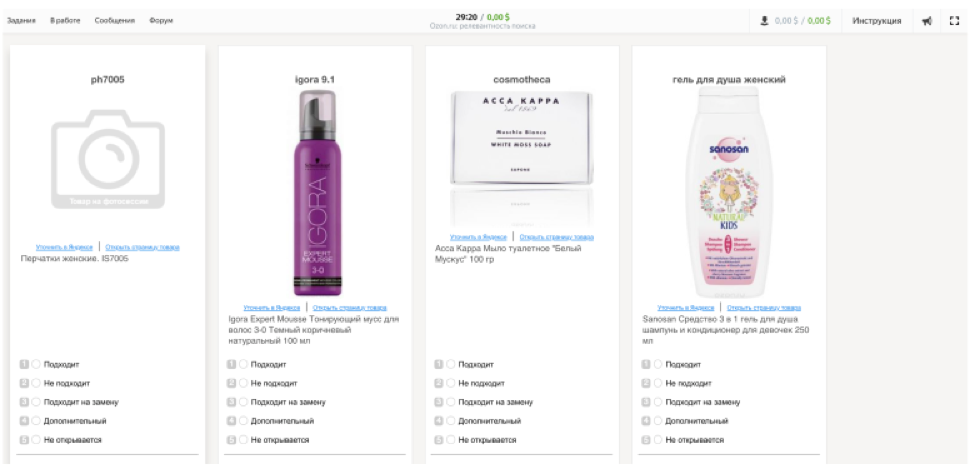
Kontraktor melihat permintaan pencarian dan 9 produk dari hasil pencarian. Tugasnya adalah memilih salah satu peringkat - "cocok", "tidak cocok", "cocok untuk penggantian", "tambahan", "tidak terbuka". Peringkat akhir membantu mengidentifikasi masalah teknis di situs. Untuk mensimulasikan perilaku pengguna seakurat mungkin, pengembang melalui iframe menciptakan kembali antarmuka toko online.
Sejalan dengan peluncuran tugas di Toloka, markup permintaan pencarian dilakukan menggunakan aturan. Penekanannya adalah pada pertanyaan populer untuk meningkatkan penerbitannya.
Markup oleh aturan memungkinkan untuk dengan cepat mendapatkan data pada sejumlah kecil pertanyaan dan menunjukkan hasil yang baik pada kueri teratas. Tetapi ada juga kontra: permintaan ambigu tidak dapat diperkirakan dengan aturan, ada banyak situasi kontroversial. Selain itu, dalam jangka panjang, metode ini cukup mahal.
Markup dengan bantuan orang menutupi kekurangan ini. Di Tolok, Anda dapat mengumpulkan opini dari sejumlah besar pemain, penilaiannya lebih lulus, yang memungkinkan Anda untuk bekerja lebih dalam dengan ekstradisi. Setelah pengaturan awal, platform bekerja secara stabil dan memproses sejumlah besar data.
Tenaga kerja manual dan mekanisme kecerdasan buatan tidak saling bertentangan. Semakin banyak kecerdasan buatan berkembang, semakin banyak tenaga kerja manual yang diperlukan untuk pelatihannya. Di sisi lain, jaringan saraf yang lebih terlatih adalah, semakin banyak tugas rutin dapat diotomatisasi, menyelamatkan seseorang dari mereka.
Hampir semua tugas, bahkan banyak, dapat dibagi menjadi banyak tugas kecil dan dibangun berdasarkan crowdsourcing. Sebagian besar tugas yang diselesaikan di
Tolok adalah langkah pertama menuju model pelatihan dan proses otomatisasi pada data yang dikumpulkan oleh orang-orang.
Dalam publikasi berikutnya tentang topik ini, kita akan berbicara tentang bagaimana crowdsourcing digunakan untuk melatih Alice, komentar moderat dan menegakkan aturan di Yandex.Bus.