Pembelajaran mesin memungkinkan Anda untuk membuat layanan ini jauh lebih nyaman bagi pengguna. Tidak begitu sulit untuk mulai menerapkan rekomendasi, hasil pertama dapat diperoleh bahkan tanpa memiliki infrastruktur yang mapan, yang utama adalah memulai. Dan baru kemudian membangun sistem skala besar. Begitulah semuanya dimulai di Booking.com. Dan apa yang dihasilkannya, pendekatan apa yang sekarang digunakan, bagaimana model dimasukkan ke dalam produksi, mana yang harus dipantau, Viktor Bilyk mengatakan kepada HighLoad ++ Siberia. Kemungkinan kesalahan dan masalah tidak tertinggal dari laporan, itu akan membantu seseorang untuk berkeliling dangkal, dan seseorang akan datang dengan ide-ide baru.
 Tentang Pembicara:
Tentang Pembicara: Victor Bilyk memperkenalkan produk pembelajaran mesin ke dalam operasi komersial di Booking.com.
Pertama, mari kita lihat di mana Booking.com menggunakan pembelajaran mesin di produk mana.
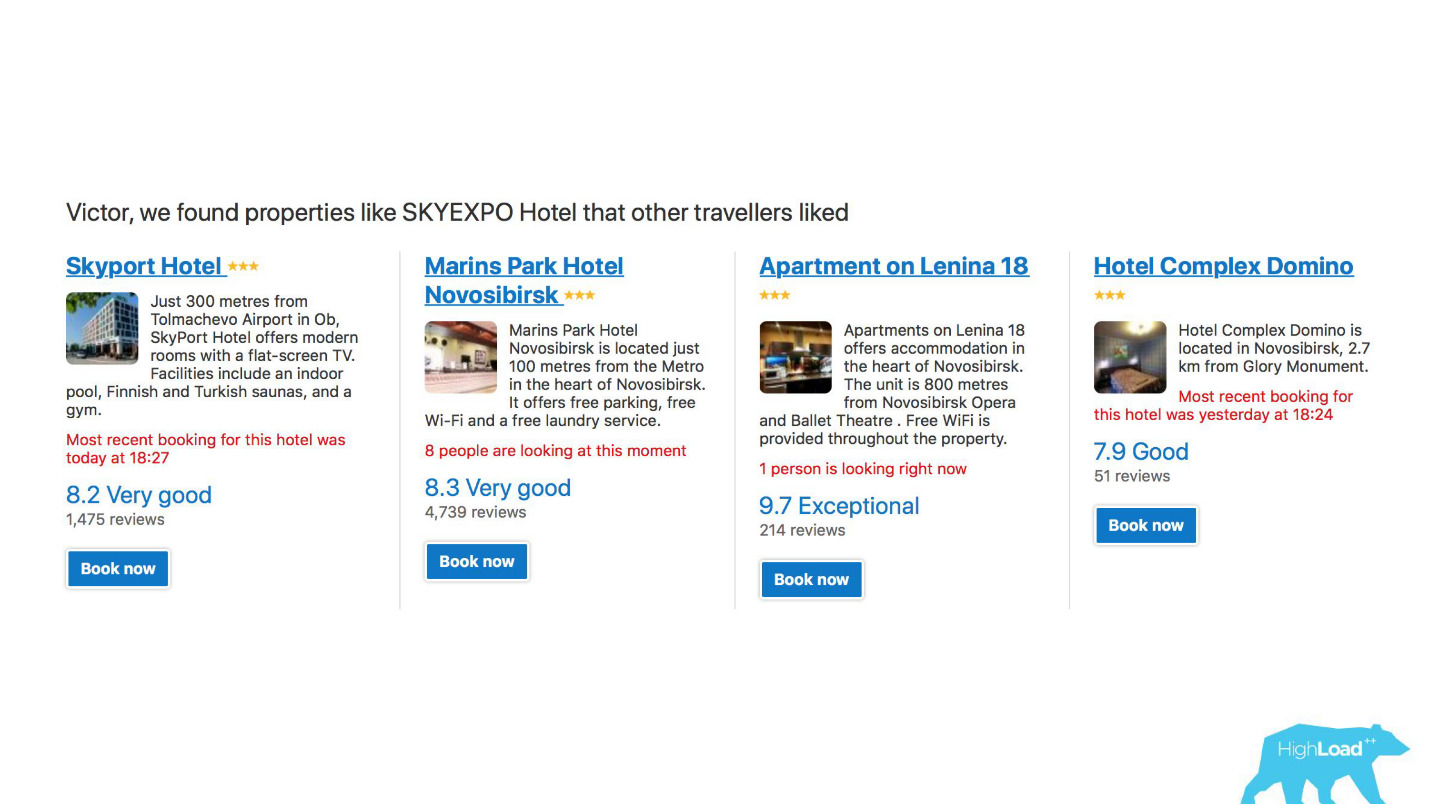
Pertama, ini adalah sejumlah besar sistem rekomendasi untuk hotel, tujuan, tanggal, dan pada titik yang berbeda dalam corong penjualan dan dalam konteks yang berbeda. Misalnya, kami mencoba menebak ke mana Anda akan pergi ketika Anda belum memasukkan apa pun di baris pencarian sama sekali.

Ini adalah tangkapan layar di akun saya, dan saya pasti akan mengunjungi dua area ini tahun ini.
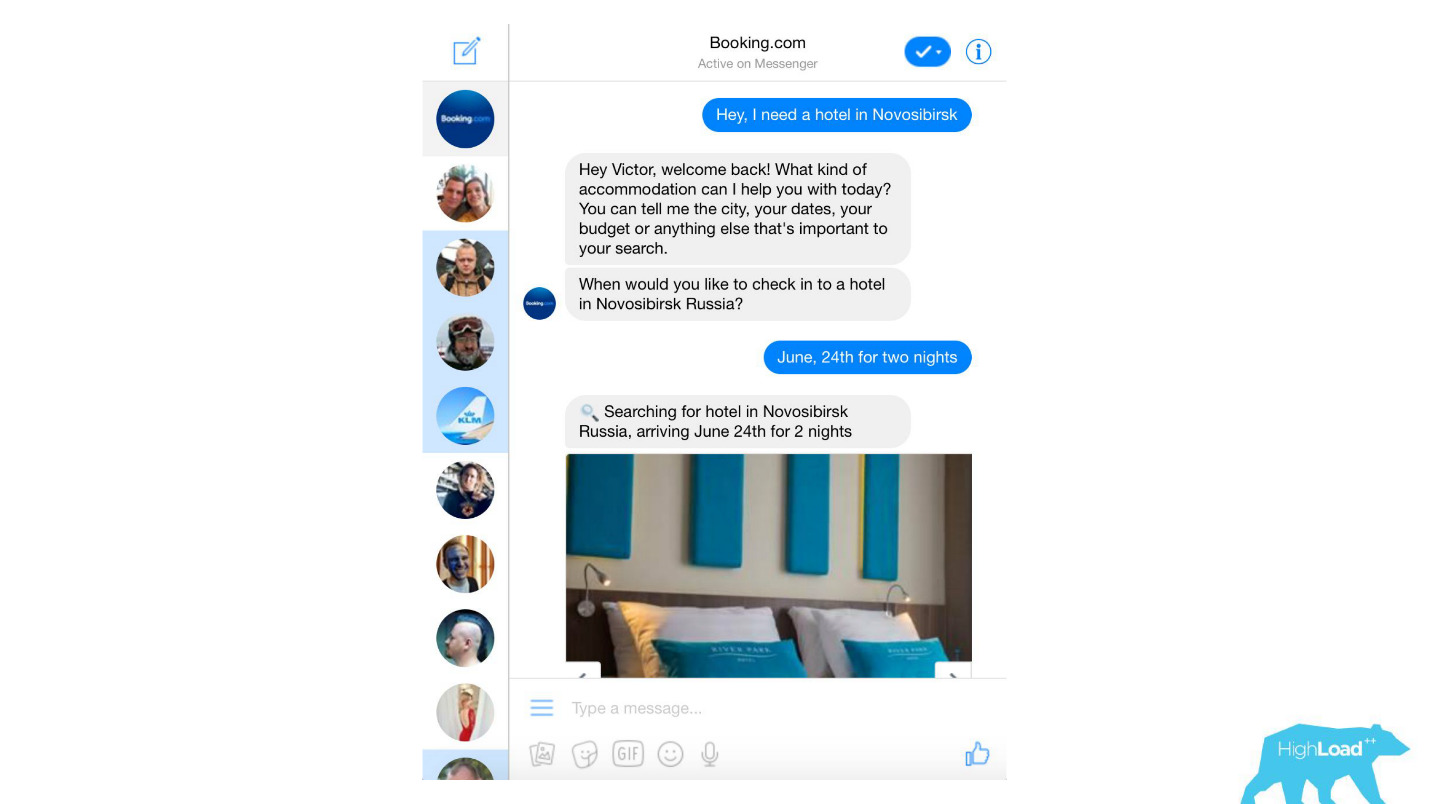
Kami memproses hampir semua pesan teks dari klien, dari filter spam dangkal hingga produk canggih seperti Assistant dan ChatToBook, yang menggunakan model untuk menentukan niat dan mengenali entitas. Selain itu, ada model yang tidak begitu terlihat, misalnya, Deteksi Penipuan.
Kami menganalisis ulasan. Model memberi tahu kita mengapa orang pergi, katakanlah, ke Berlin.
Dengan bantuan model pembelajaran mesin, dianalisis mengapa hotel dipuji sehingga Anda tidak perlu membaca ribuan ulasan sendiri.
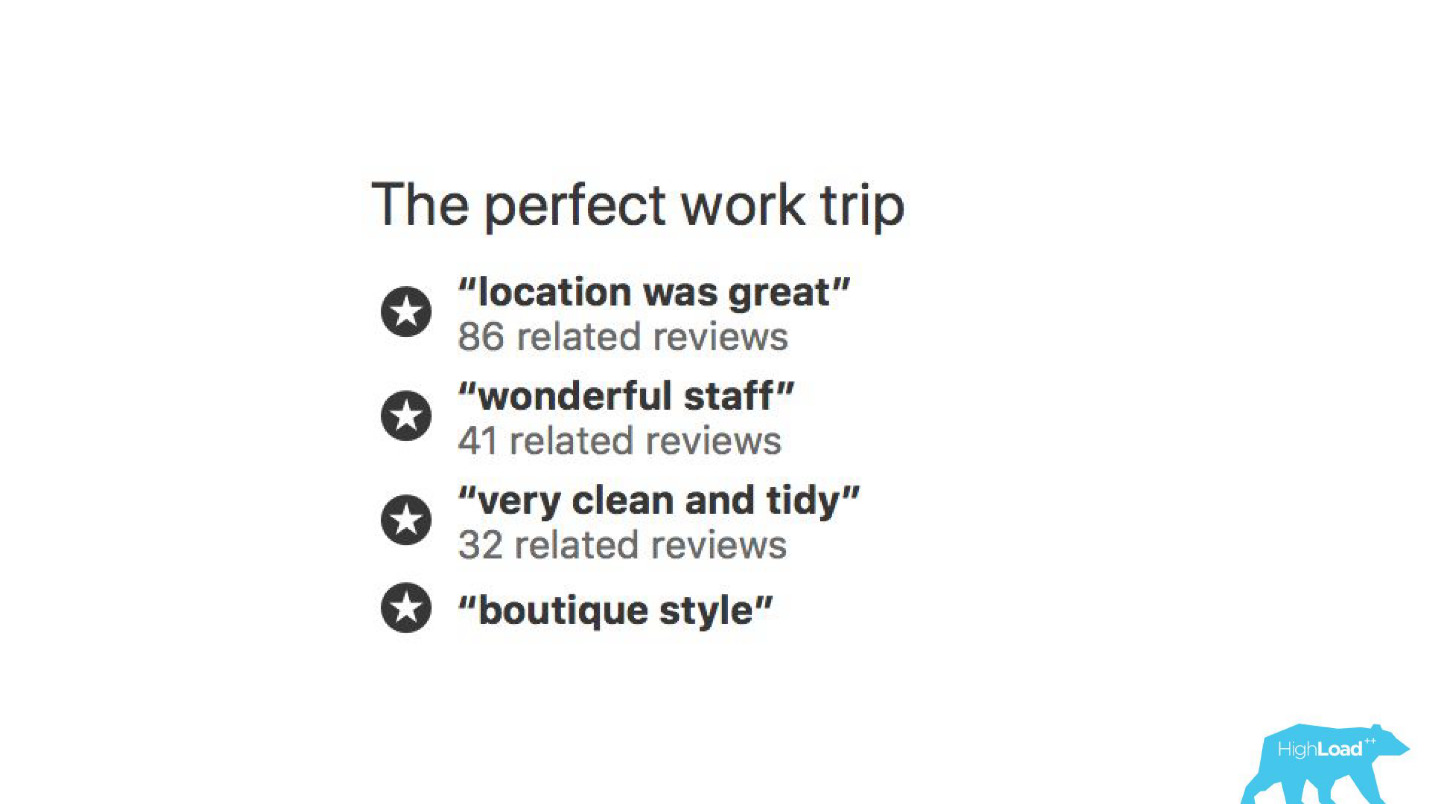
Di beberapa tempat antarmuka kami, hampir setiap bagian terkait dengan prediksi beberapa model. Misalnya, di sini kami mencoba memprediksi kapan hotel akan habis terjual.
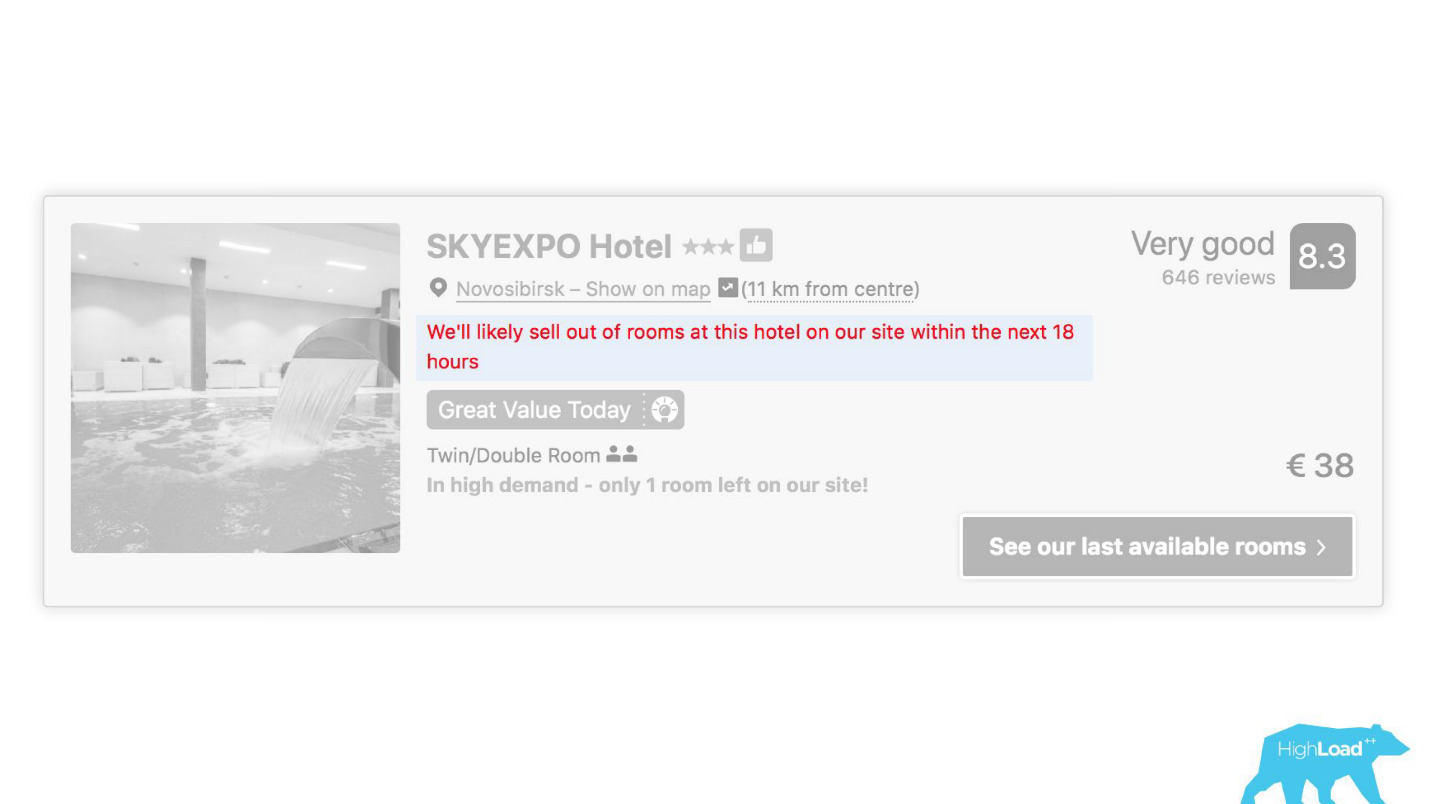
Kita sering menemukan diri kita benar - setelah 19 jam kamar terakhir sudah dipesan.
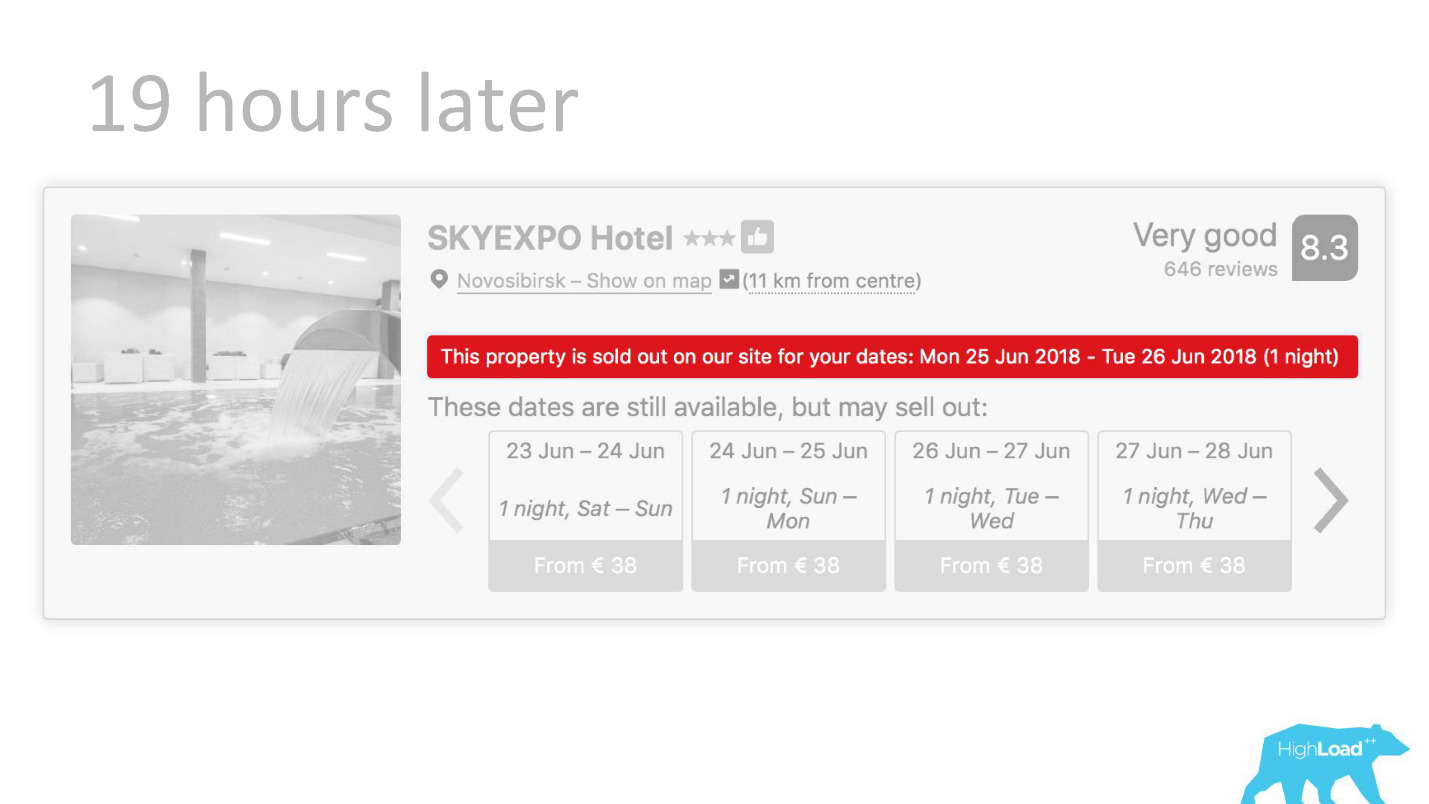
Atau, misalnya, - lencana "Penawaran yang menguntungkan". Di sini kami mencoba memformalkan subyektif: apa yang merupakan tawaran yang menguntungkan. Bagaimana memahami bahwa harga yang ditentukan oleh hotel untuk tanggal ini baik? Lagi pula, ini, di samping harganya, tergantung pada banyak faktor, seperti layanan tambahan, dan seringkali bahkan pada alasan eksternal, jika, misalnya, Piala Dunia atau konferensi teknis besar sedang diadakan di kota ini sekarang.
Mulai dari implementasi
Mari kita mundur beberapa tahun yang lalu, pada tahun 2015. Beberapa produk yang saya bicarakan sudah ada. Terlebih lagi, sistem yang akan saya bicarakan hari ini belum. Bagaimana pelaksanaannya saat itu? Segalanya, jujur saja, tidak terlalu. Faktanya adalah bahwa kami memiliki masalah besar, yang sebagian bersifat teknis, dan sebagian lagi bersifat organisasi.
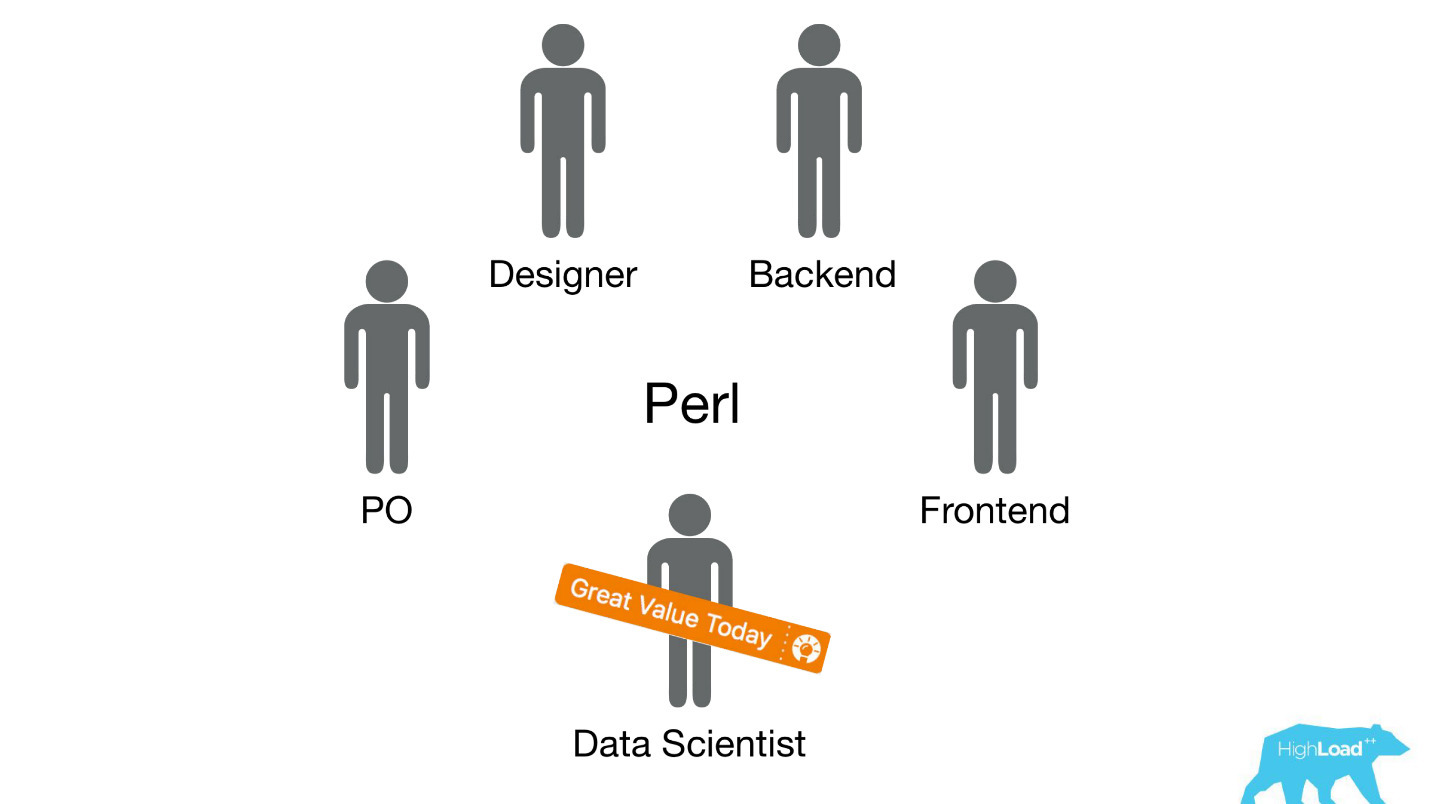
Kami mengirim ilmuwan data ke tim lintas fungsi yang ada yang bekerja pada masalah pengguna tertentu dan berharap mereka untuk meningkatkan produk entah bagaimana.
Paling sering, potongan-potongan produk ini dibangun di atas tumpukan Perl. Ada masalah yang jelas dengan Perl - itu tidak dirancang untuk komputasi intensif, dan backend kami sudah dimuat dengan hal-hal lain. Selain itu, pengembangan sistem serius yang akan menyelesaikan masalah ini tidak dapat diprioritaskan dalam tim, karena fokus tim adalah pada pemecahan masalah pengguna, dan bukan pada pemecahan masalah pengguna menggunakan pembelajaran mesin. Oleh karena itu, Pemilik Produk (PO) akan sangat menentang ini.
Mari kita lihat bagaimana itu terjadi.
Hanya ada dua pilihan - saya tahu ini pasti, karena pada saat itu saya hanya bekerja di tim seperti itu dan membantu para Ilmuwan Data membawa model pertama mereka ke dalam pertempuran.
Opsi pertama adalah
materialisasi prediksi . Misalkan ada model yang sangat sederhana dengan hanya dua fitur:
- negara tempat pengunjung berada;
- kota tempat ia mencari hotel.
Kita perlu memprediksi kemungkinan suatu peristiwa. Kami baru saja meledakkan semua vektor input: katakanlah, 100.000 kota, 200 negara - total 20 juta baris di MySQL. Kedengarannya seperti opsi yang berfungsi penuh untuk menghasilkan beberapa sistem peringkat kecil atau model sederhana lainnya untuk produksi.

Pilihan lain adalah
menanamkan prediksi secara langsung dalam kode backend . Ada batasan besar - ratusan, mungkin ribuan koefisien - itulah yang kami mampu.

Jelas, tidak ada satu atau pun cara lain yang memungkinkan Anda mengeluarkan setidaknya beberapa jenis model rumit dalam produksi. Ini membatasi pusat data dan keberhasilan yang dapat mereka raih dengan meningkatkan produk. Jelas, masalah ini harus dipecahkan entah bagaimana.
Layanan Prediksi
Hal pertama yang kami lakukan adalah layanan prediksi. Mungkin, arsitektur paling sederhana yang pernah ditampilkan di Habré dan HighLoad ++ lebih rendah.
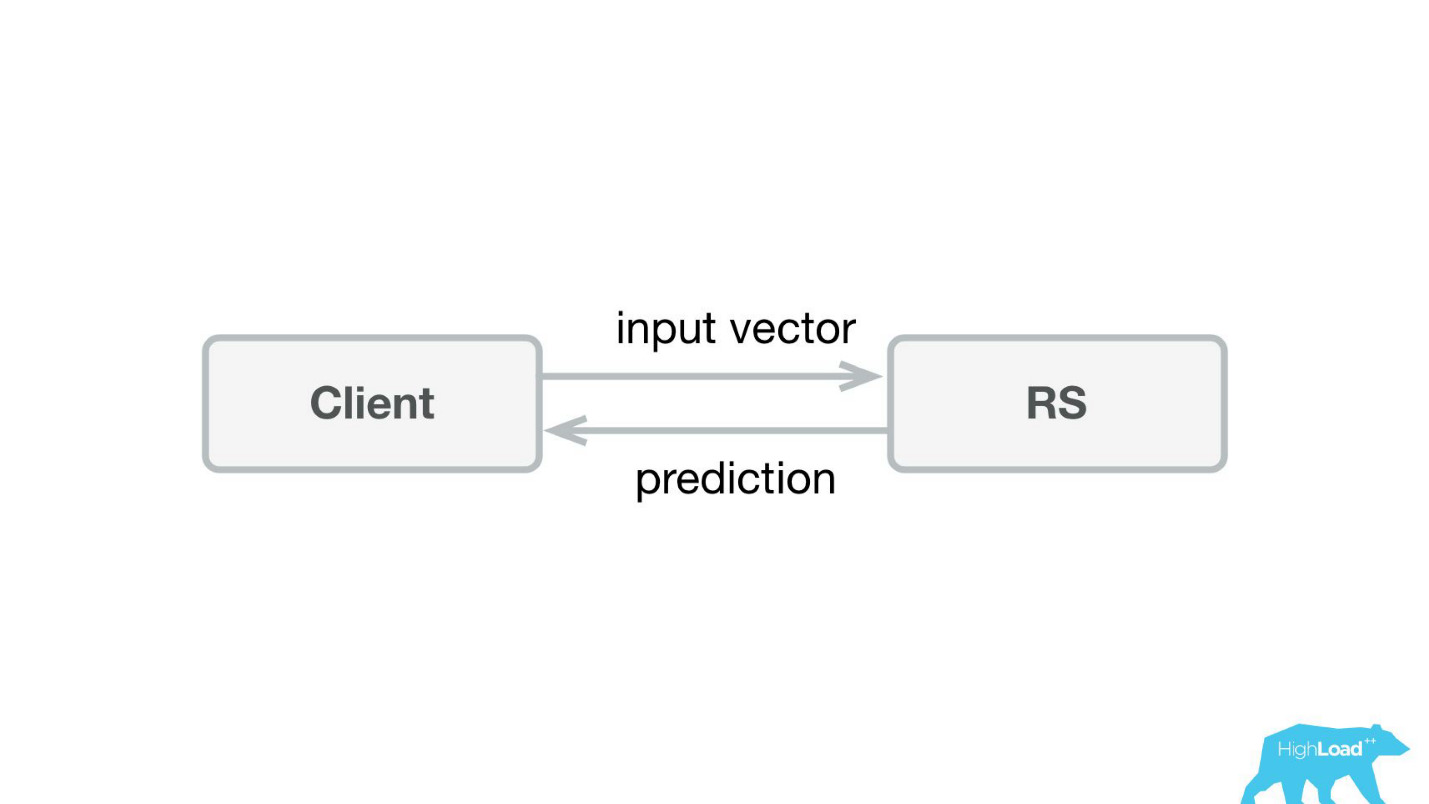
Kami menulis aplikasi kecil di Scala + Akka + Spray yang hanya mengambil vektor yang masuk dan mengembalikan prediksi. Faktanya, saya sedikit cerdik - sistemnya sedikit lebih rumit, karena kami perlu memonitor dan menjalankannya. Pada kenyataannya, semuanya tampak seperti ini:
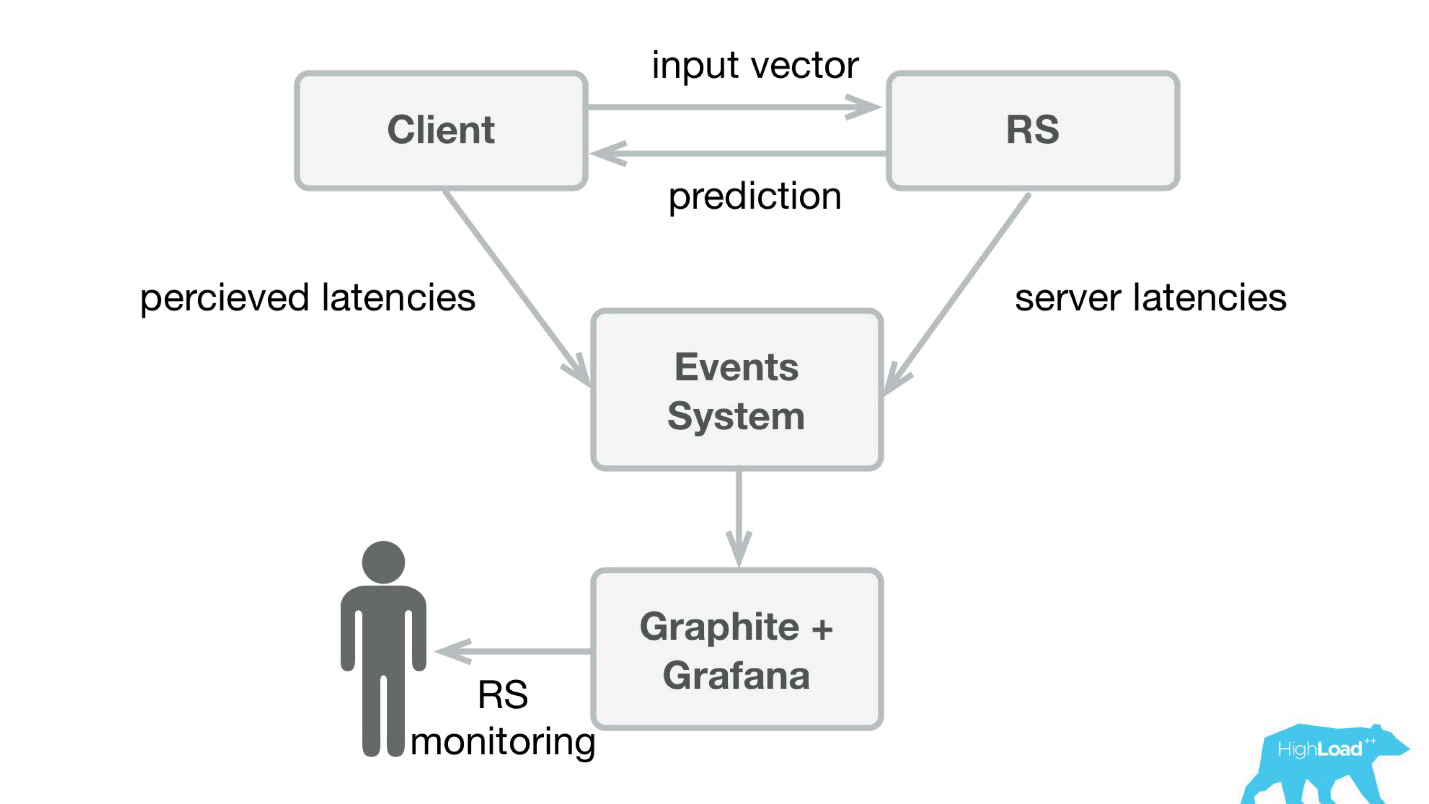
Booking.com memiliki sistem acara - sesuatu seperti majalah untuk semua sistem. Sangat mudah untuk menulis di sana, dan aliran ini sangat mudah untuk dialihkan. Pada awalnya, kami perlu mengirim telemetri klien ke Graphite dan Grafana dengan persepsi latensi dan informasi detail dari sisi server.

Kami membuat pustaka klien sederhana untuk Perl - sembunyikan seluruh RPC dalam panggilan lokal, meletakkan beberapa model di sana, dan layanan mulai berjalan. Untuk menjual produk seperti itu cukup sederhana, karena kami mendapat kesempatan
untuk memperkenalkan model yang lebih kompleks dan menghabiskan lebih sedikit waktu .
Para ilmuwan data mulai bekerja dengan pembatasan yang jauh lebih sedikit, dan dalam beberapa kasus pekerjaan back -ders dikurangi menjadi satu baris.
Prediksi Produk
Tapi mari kita kembali ke bagaimana kita menggunakan prediksi ini dalam produk.
Ada model yang membuat prediksi berdasarkan fakta yang diketahui. Berdasarkan prediksi ini, kami mengubah antarmuka pengguna. Ini, tentu saja, bukan satu-satunya skenario untuk penggunaan pembelajaran mesin di perusahaan kami, tetapi cukup umum.
Apa masalah meluncurkan fitur seperti itu? Masalahnya adalah ini adalah dua hal dalam satu botol: model dan perubahan dalam antarmuka pengguna. Sangat sulit untuk memisahkan efek dari keduanya.
Bayangkan meluncurkan lencana "Penawaran yang Menguntungkan" sebagai bagian dari percobaan AB. Jika tidak lepas landas - tidak ada perubahan signifikan secara statistik dalam metrik target - tidak diketahui apa masalahnya: lencana yang tidak dapat dipahami, kecil, tidak mencolok, atau model yang buruk.
Selain itu, model dapat menurun, dan ada banyak alasan untuk ini. Apa yang berhasil kemarin tidak selalu berhasil hari ini. Selain itu, kami selalu dalam mode mulai dingin, terus-menerus menghubungkan kota dan hotel baru, orang-orang dari kota baru datang kepada kami. Kita perlu entah bagaimana memahami bahwa model masih menggeneralisasi dengan baik di bagian ruang masuk ini.

Kasus degradasi model yang paling baru diketahui adalah kisah dengan Alex. Kemungkinan besar, sebagai hasil dari pelatihan ulang, dia mulai memahami suara-suara acak, sebagai permintaan untuk tertawa, dan mulai tertawa di malam hari, menakuti para pemilik.
Pemantauan Prediksi
Untuk memantau prediksi, kami sedikit memodifikasi sistem kami (diagram di bawah). Dengan cara yang sama, dari sistem acara, kami mengalihkan aliran ke Hadoop dan mulai menyimpan, selain semua yang kami simpan sebelumnya, juga semua vektor input dan semua prediksi yang dibuat oleh sistem kami. Kemudian, menggunakan Oozie, kami mengumpulkannya di MySQL dan dari sana menunjukkannya dengan aplikasi web kecil untuk mereka yang tertarik pada beberapa jenis karakteristik kualitatif dari model.
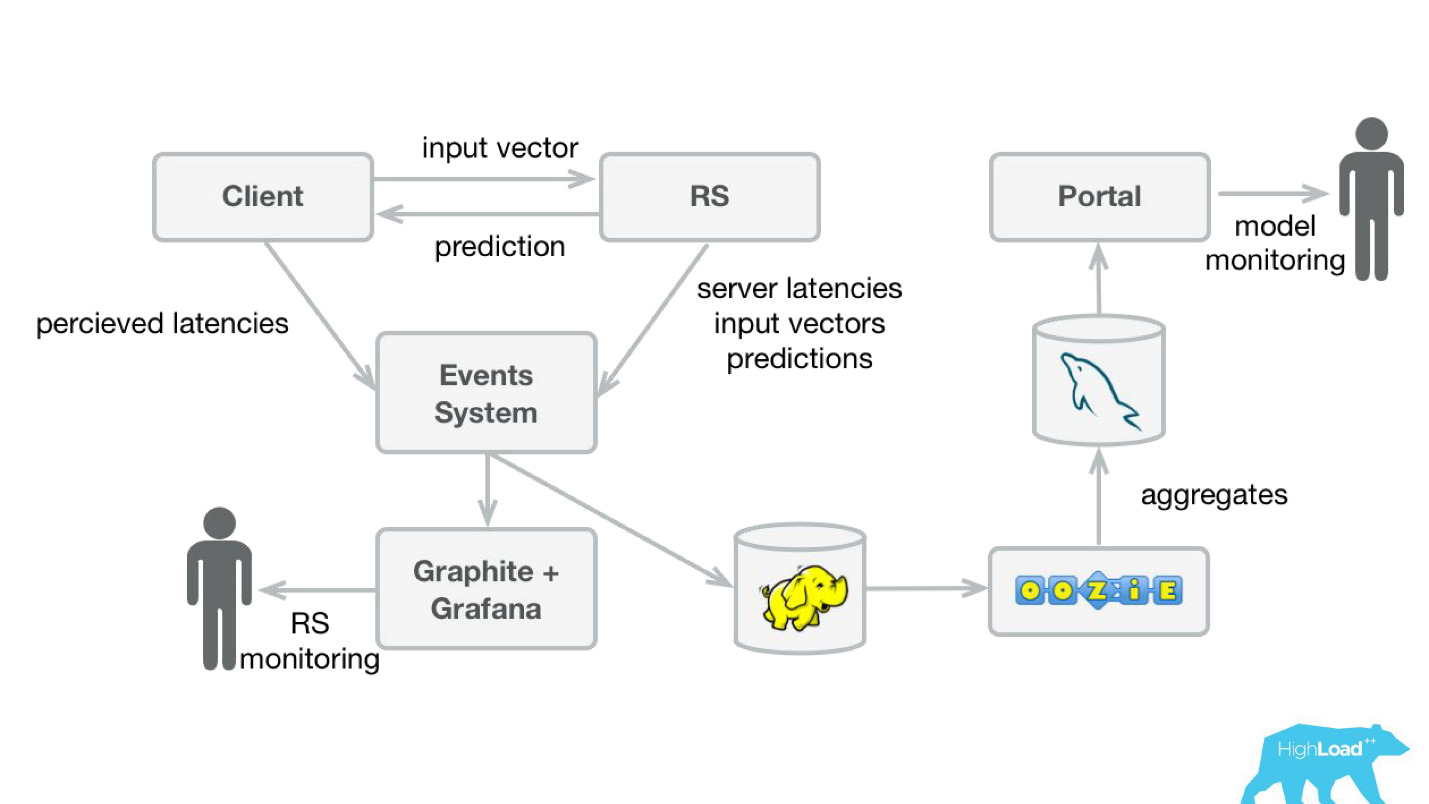
Namun, penting untuk mengetahui apa yang harus ditampilkan di sana. Masalahnya adalah bahwa dalam kasus kami, sangat sulit untuk menghitung metrik yang biasa digunakan dalam pelatihan model, karena seringkali kami mengalami keterlambatan besar pada label.
Anggap ini sebagai contoh. Kami ingin memprediksi apakah pengguna pergi berlibur sendirian atau bersama keluarga. Kita perlu prediksi ini ketika seseorang memilih hotel, tetapi kita hanya bisa mengetahui kebenarannya dalam setahun. Baru saja pergi berlibur, pengguna akan menerima undangan untuk meninggalkan ulasan, di mana antara lain akan ada pertanyaan apakah ia ada di sana sendirian atau bersama keluarganya.
Artinya, Anda perlu menyimpan di suatu tempat semua prediksi yang dibuat sepanjang tahun, dan bahkan agar Anda dapat dengan cepat menemukan kecocokan dengan label yang masuk. Kedengarannya sangat serius, bahkan mungkin investasi besar. Oleh karena itu, sampai kami mengatasi masalah ini, kami memutuskan untuk melakukan sesuatu yang lebih sederhana.
Ini "sederhana" ternyata hanya
histogram prediksi yang dibuat oleh model.
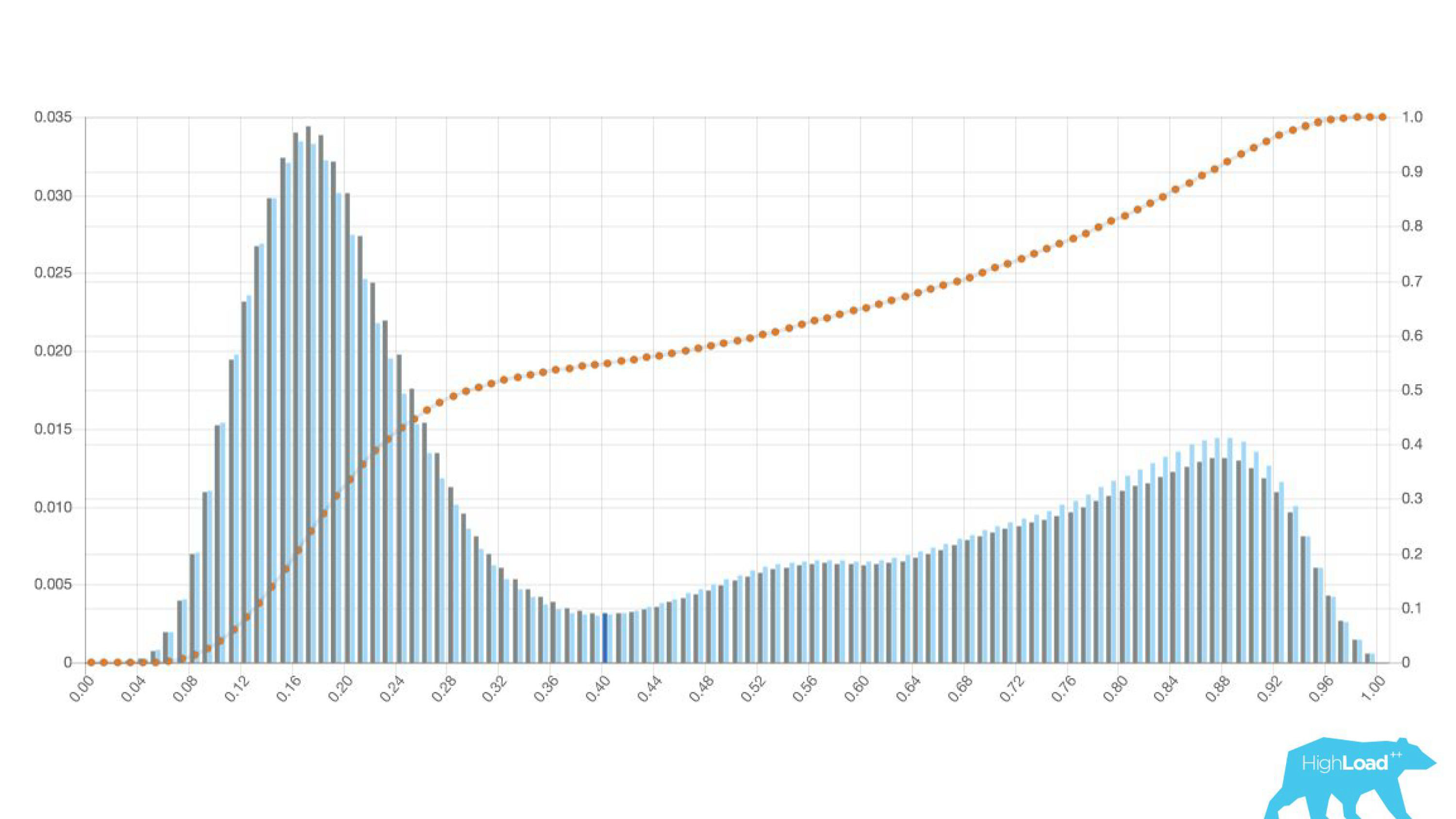
Di atas grafik adalah regresi logistik yang memprediksi apakah pengguna akan mengubah tanggal perjalanannya atau tidak. Dapat dilihat bahwa ia membagi pengguna menjadi dua kelas: di sebelah kiri, bukit adalah mereka yang tidak akan melakukan ini; bukit di sebelah kanan adalah mereka yang melakukannya.
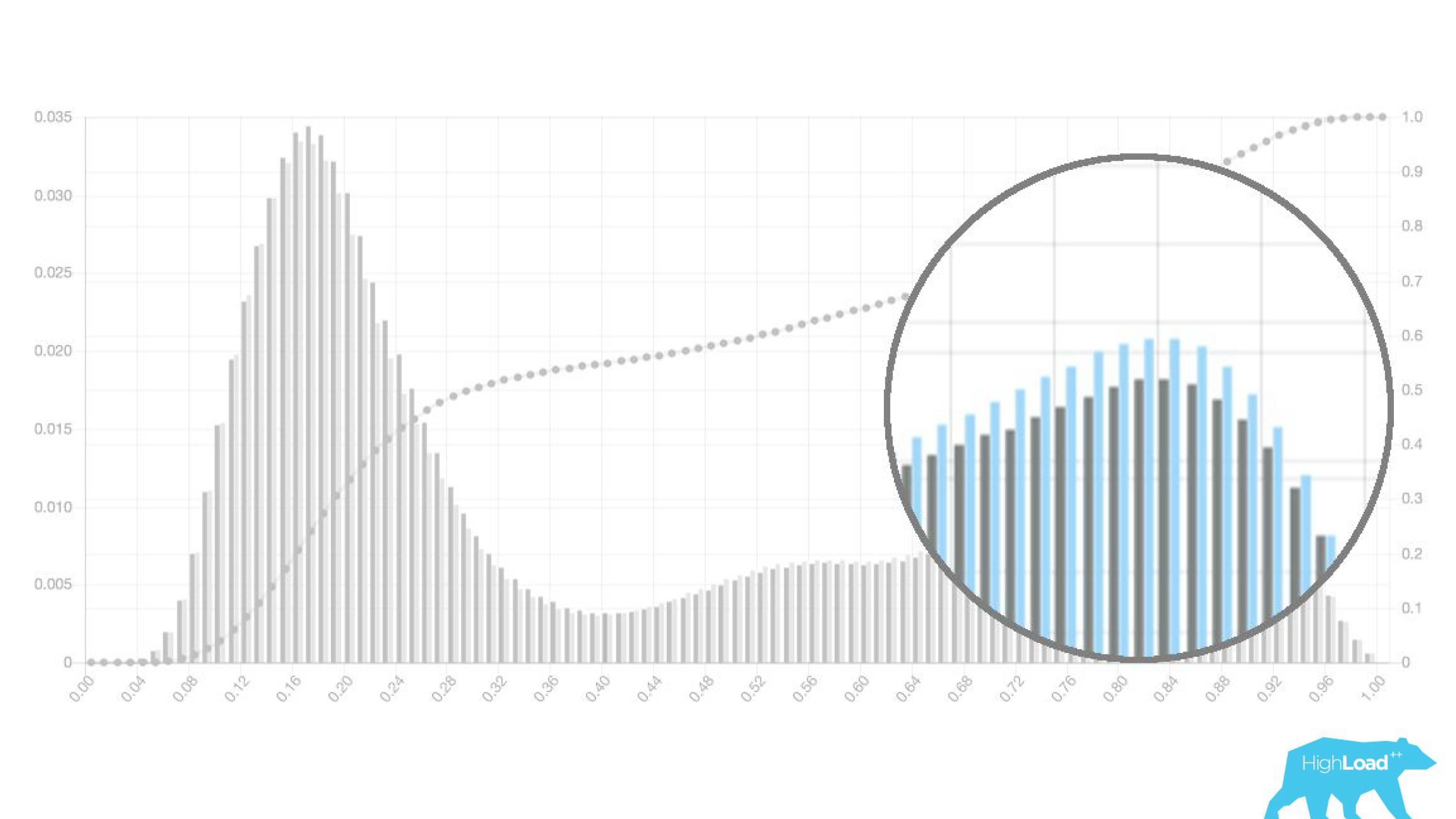
Bahkan, kami bahkan menunjukkan dua grafik: satu untuk periode saat ini, dan yang lain untuk yang sebelumnya. Terlihat jelas bahwa minggu ini (ini adalah grafik mingguan) model tersebut memprediksi perubahan tanggal sedikit lebih sering. Sulit untuk mengatakan dengan pasti apakah itu musiman, atau degradasi yang sama dari waktu ke waktu.
Hal ini menyebabkan perubahan dalam karya datacientes, yang berhenti melibatkan orang lain dan mulai beralih model mereka lebih cepat. Mereka mengirim model ke produksi dalam jangka-kering bersama dengan para insinyur backend. Yaitu, vektor dikumpulkan, model membuat prediksi, tetapi prediksi ini tidak digunakan dengan cara apa pun.
Dalam kasus lencana, kami sama sekali tidak menunjukkan apa pun, seperti sebelumnya, tetapi mengumpulkan statistik. Ini memungkinkan kami untuk tidak membuang waktu untuk proyek yang gagal sebelumnya. Kami meluangkan waktu untuk front-end dan desainer untuk eksperimen lainnya.
Selama datacenter tidak yakin bahwa model bekerja seperti yang diinginkannya, ia tidak melibatkan orang lain dalam proses ini.Sangat menarik untuk melihat bagaimana grafik berubah di berbagai bagian.
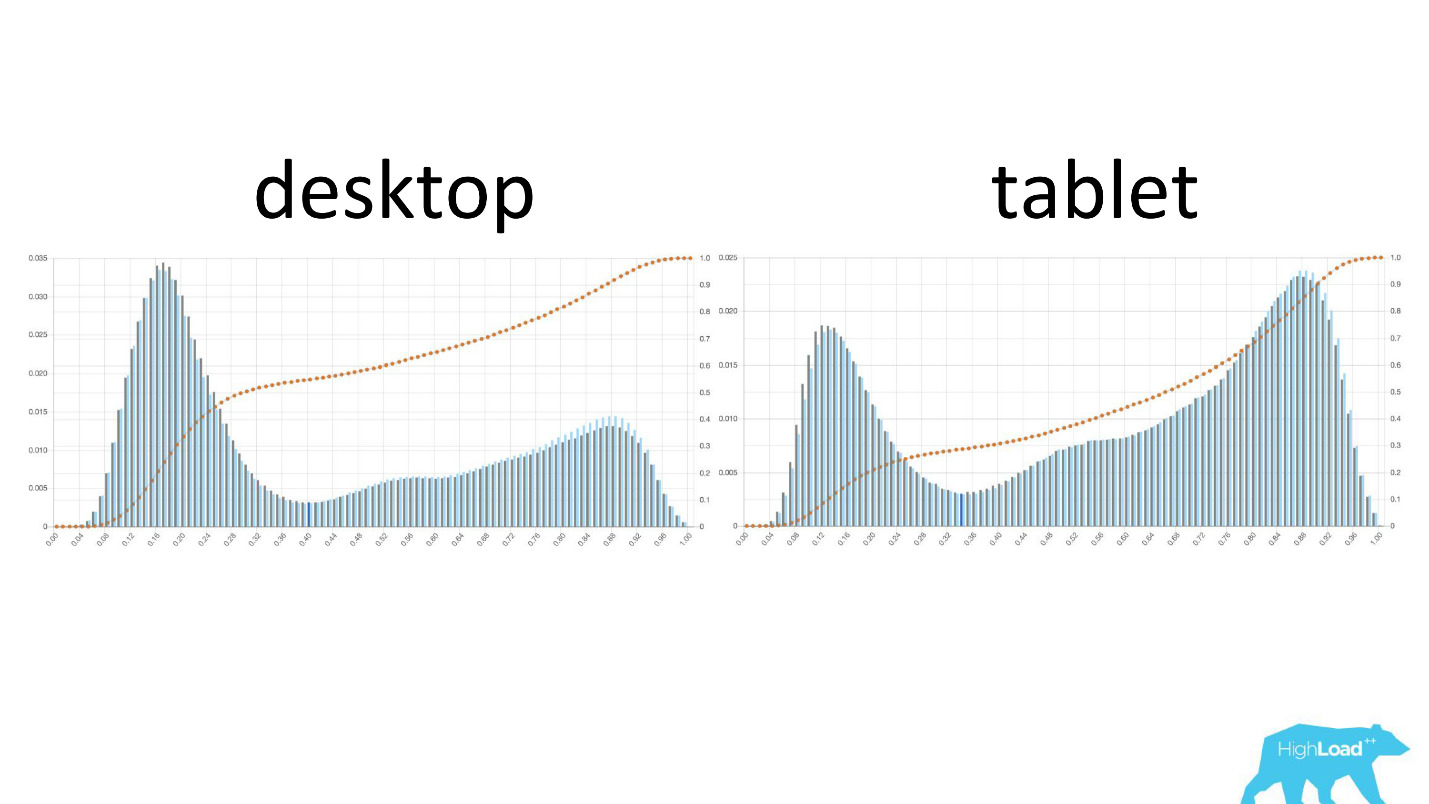
Di sebelah kiri adalah kemungkinan mengubah tanggal di desktop, di sebelah kanan ada di tablet. Terlihat jelas bahwa pada tablet model memprediksi kemungkinan perubahan tanggal. Ini kemungkinan besar disebabkan oleh fakta bahwa tablet sering digunakan untuk perencanaan perjalanan dan lebih jarang untuk pemesanan.
Menarik juga untuk melihat bagaimana grafik ini berubah ketika pengguna bergerak melalui corong penjualan.
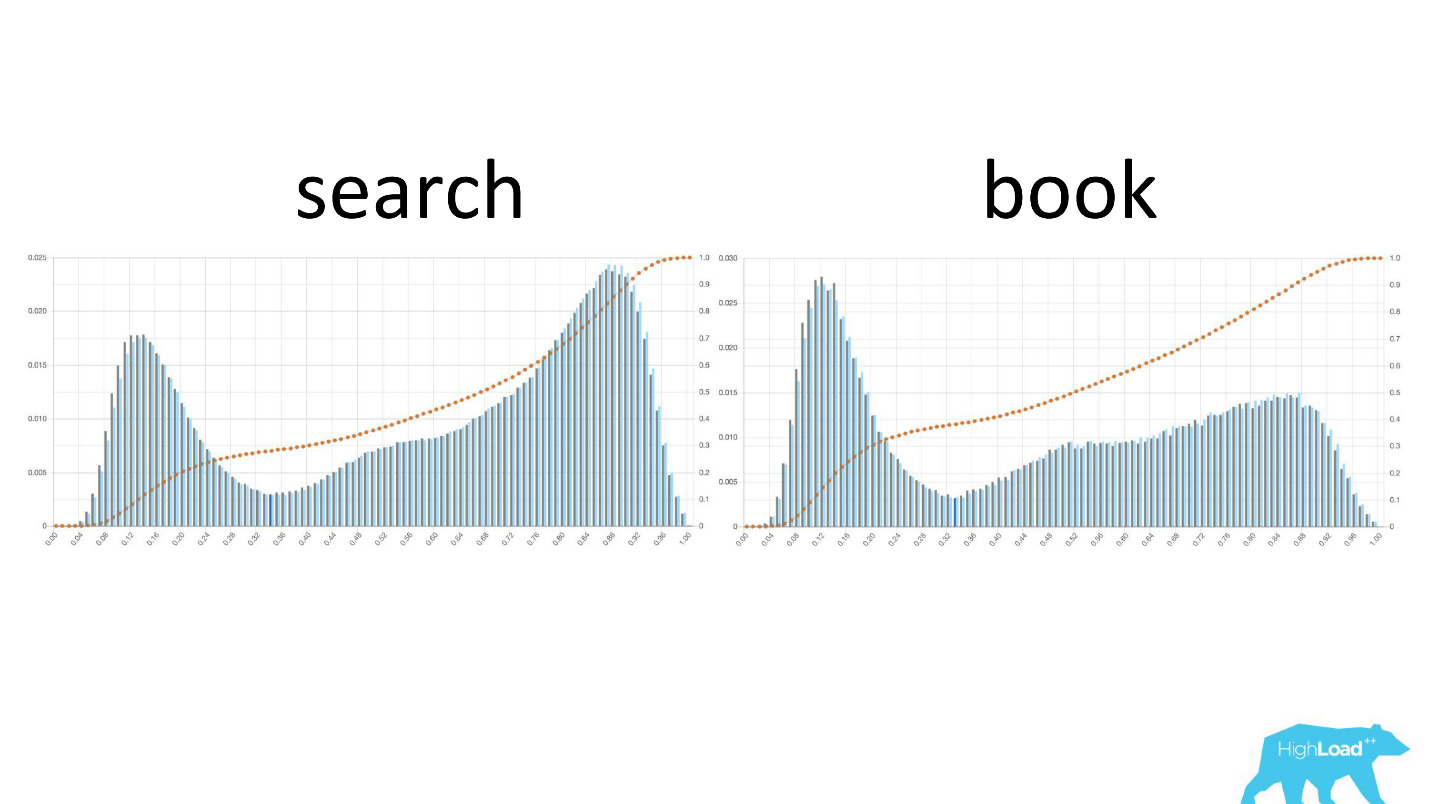
Di sebelah kiri adalah kemungkinan mengubah tanggal pada halaman pencarian, di sebelah kanan adalah pada halaman pemesanan pertama. Dapat dilihat bahwa sejumlah besar orang yang telah memutuskan tanggalnya dapat mengunjungi halaman pemesanan.
Tapi ini grafik yang bagus. Seperti apa penampilan yang buruk? Dengan cara yang sangat berbeda. Terkadang itu hanya noise, terkadang itu adalah bukit besar, yang berarti bahwa model tersebut tidak dapat secara efektif memisahkan dua kelas prediksi.

Terkadang ini adalah puncak besar.
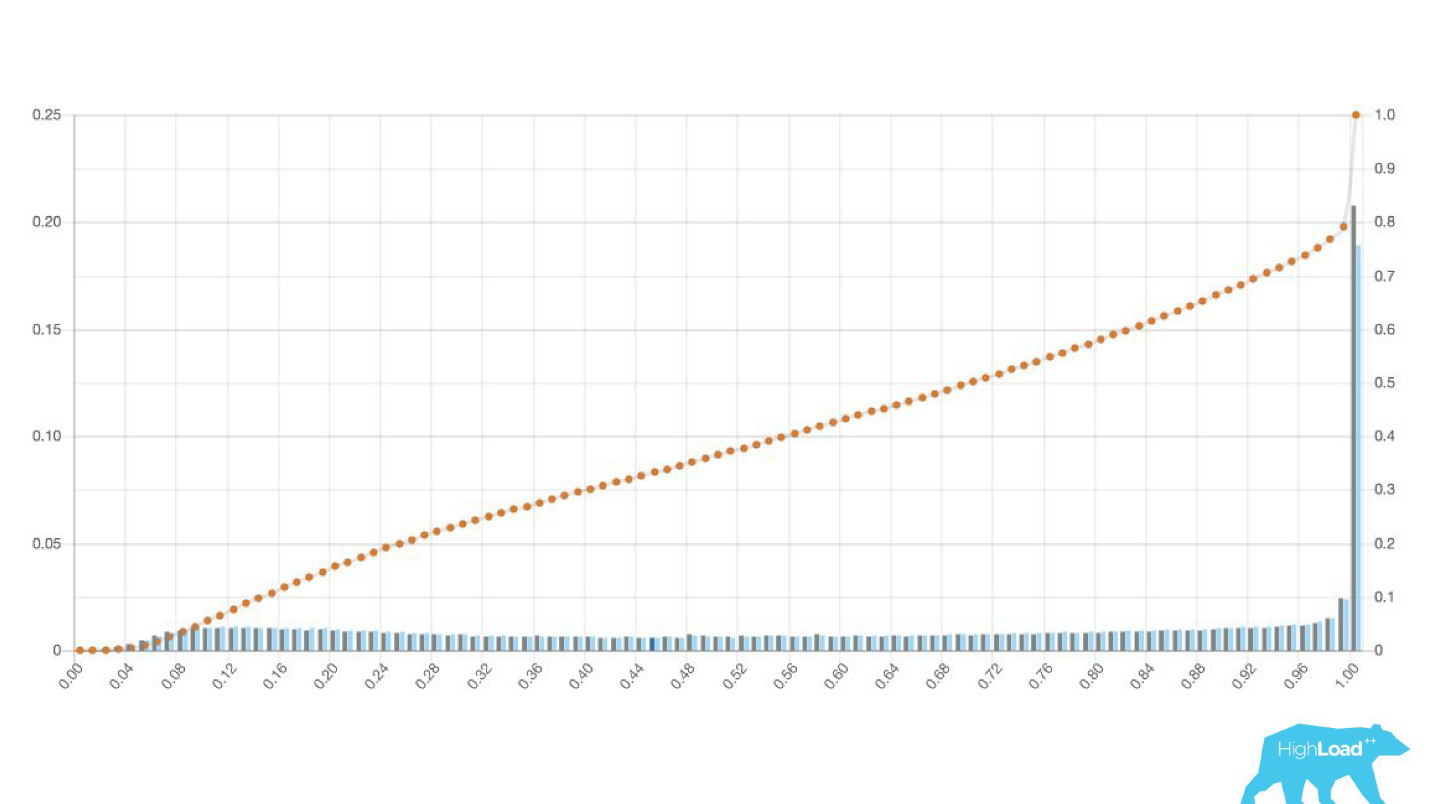
Ini juga merupakan regresi logistik, dan sampai titik tertentu itu menunjukkan gambar yang indah dengan dua bukit, tetapi suatu pagi menjadi seperti itu.
Untuk memahami apa yang terjadi di dalam, Anda perlu memahami bagaimana regresi logistik dihitung.
Referensi cepat
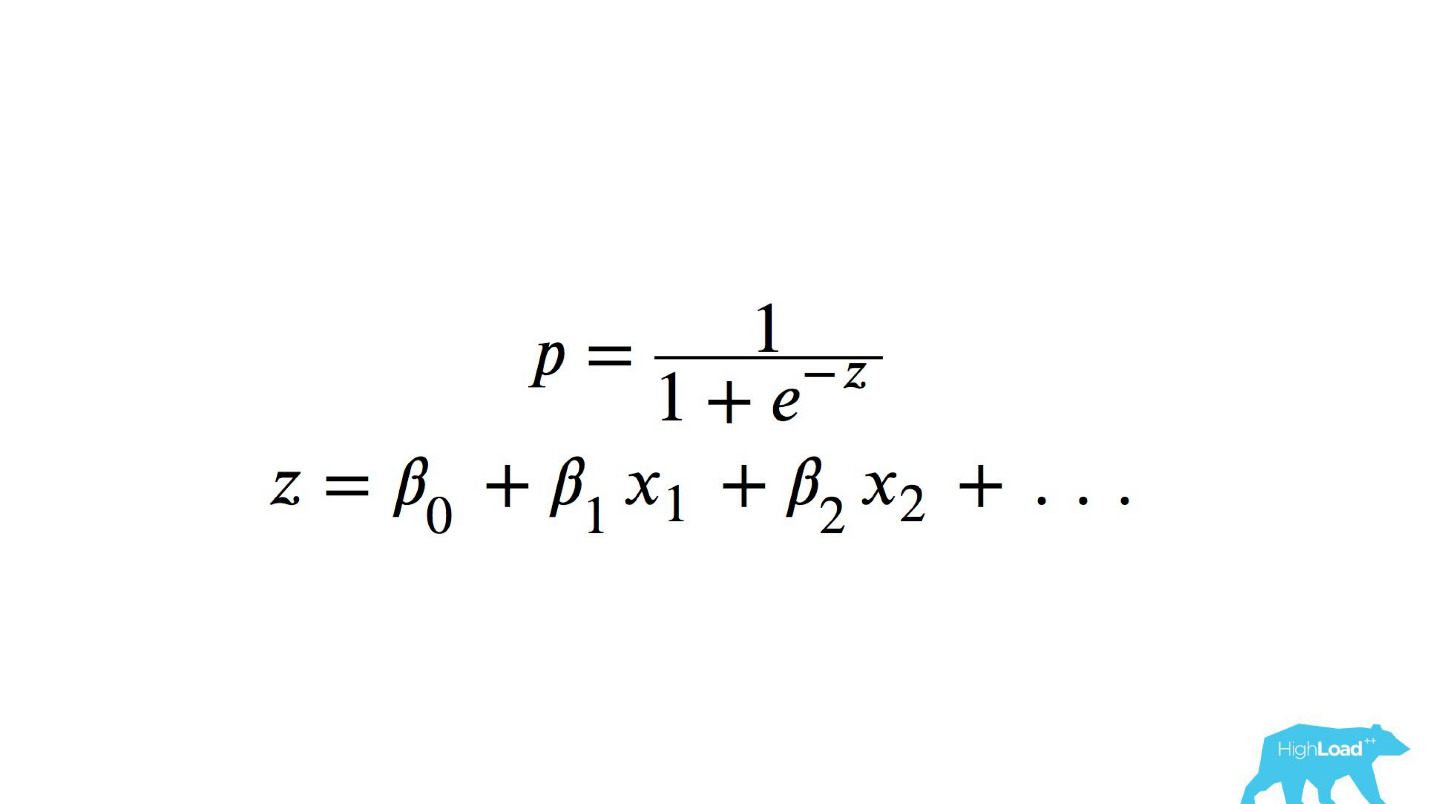
Ini adalah fungsi logistik dari produk skalar, di mana x
n adalah beberapa fitur. Salah satu fitur ini adalah harga malam di hotel (dalam euro).
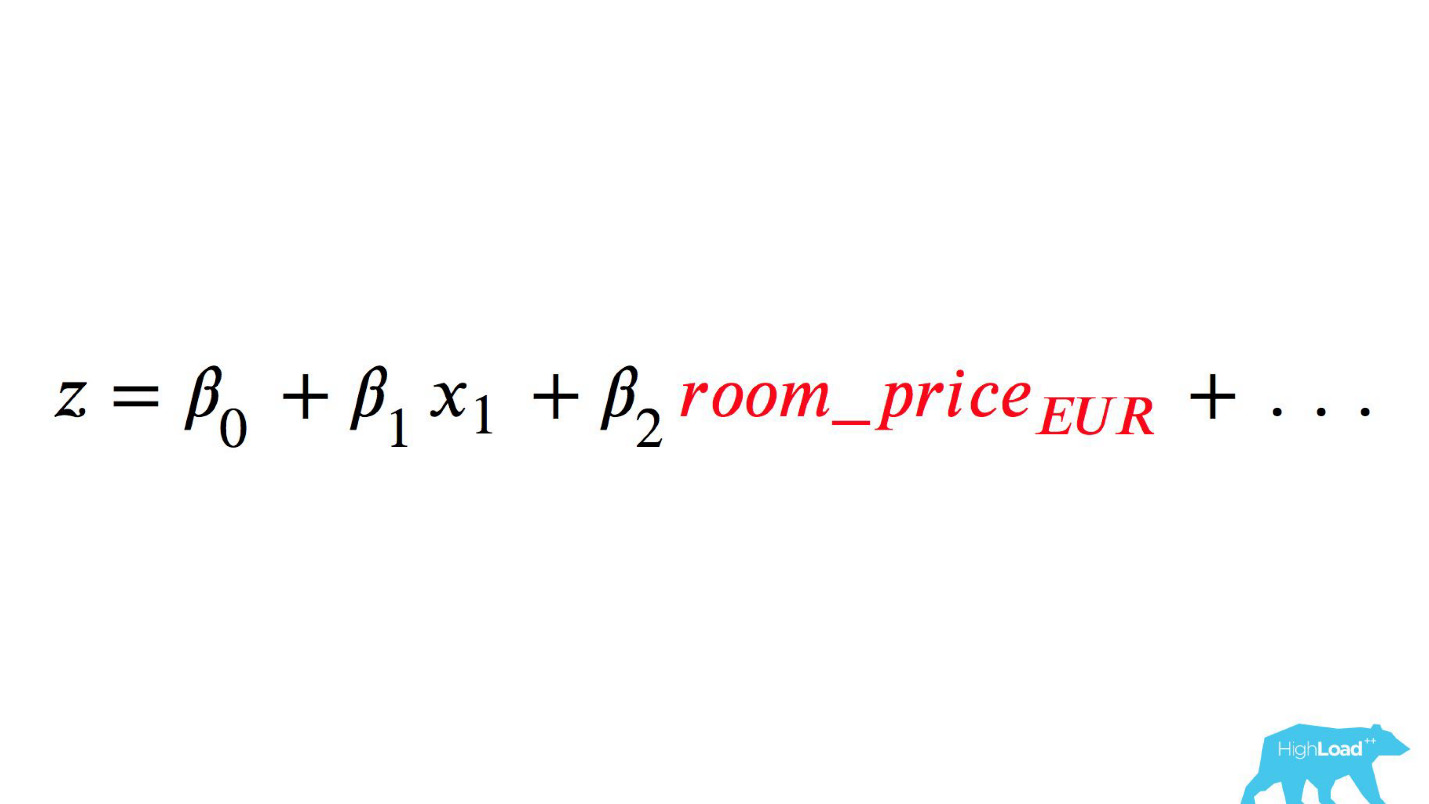
Untuk memanggil model ini akan menjadi sesuatu seperti ini:
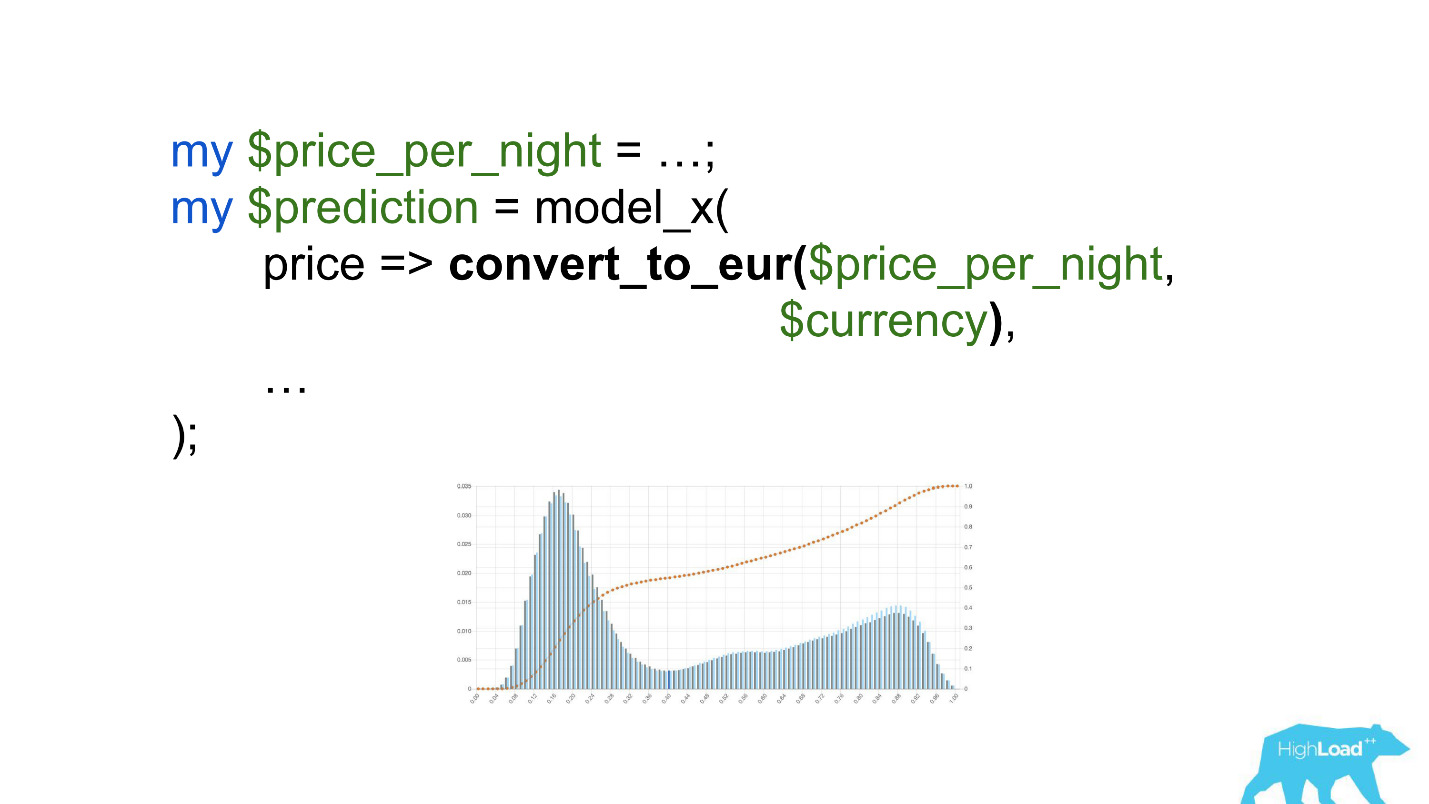
Perhatikan seleksi. Itu perlu untuk mengkonversi harga ke euro, tetapi pengembang lupa melakukannya.
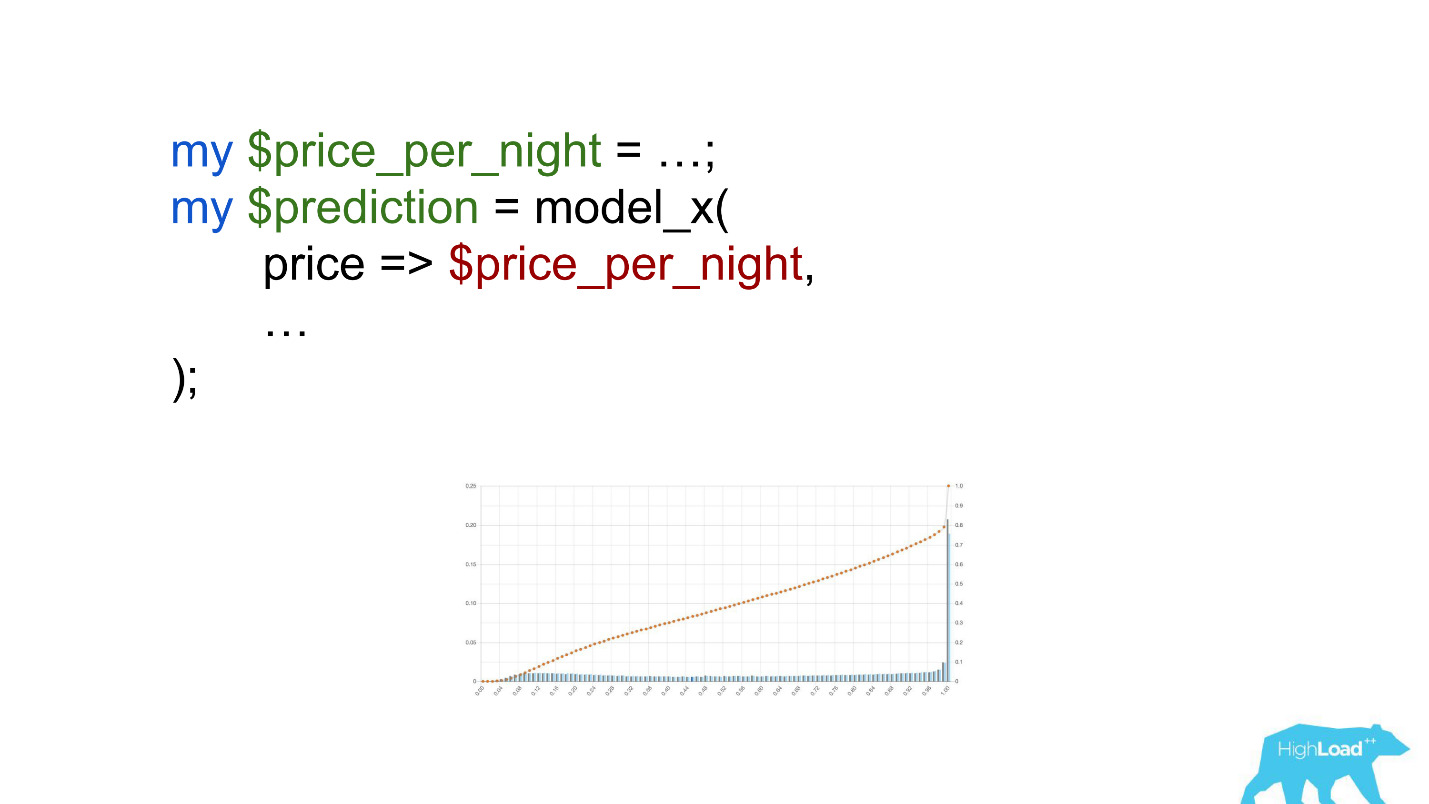
Mata uang seperti rupee atau rubel meningkatkan produk skalar berkali-kali, dan, karenanya, memaksa model ini untuk menghasilkan nilai mendekati persatuan, lebih sering, yang kita lihat pada grafik.
Nilai ambang batas
Fitur lain yang berguna dari histogram ini adalah kemungkinan pilihan nilai ambang batas yang disadari dan optimal.
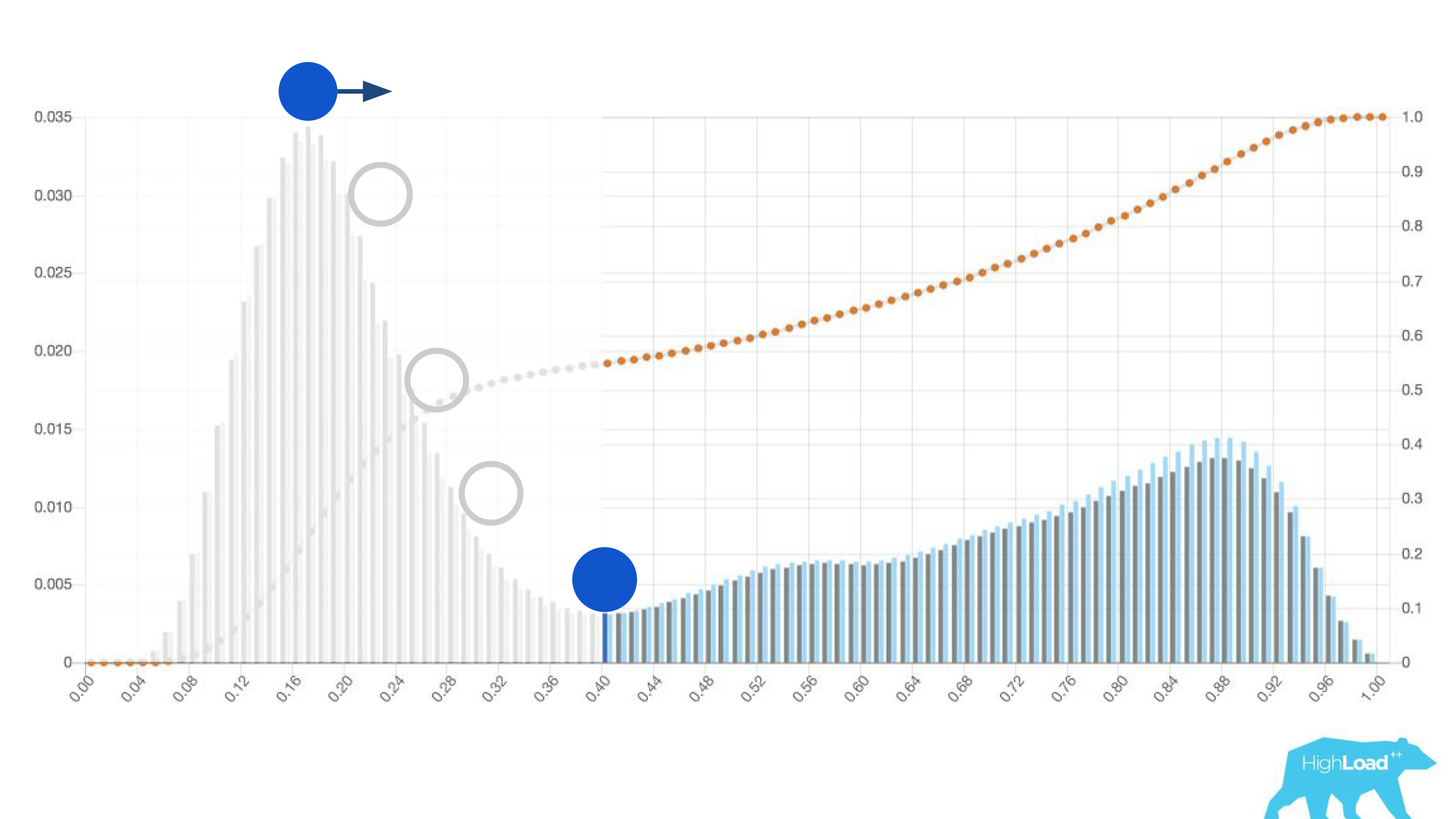
Jika Anda menempatkan bola di bukit tertinggi dalam histogram ini, dorong dan bayangkan di mana ia akan berhenti, ini akan menjadi titik yang optimal untuk pemisahan kelas. Segala sesuatu di kanan adalah satu kelas, semua di sebelah kiri adalah kelas lain.
Namun, jika Anda mulai menggerakkan titik ini, Anda dapat mencapai efek yang sangat menarik. Misalkan kita ingin menjalankan percobaan itu, jika model mengatakan ya, entah bagaimana mengubah antarmuka pengguna. Jika Anda memindahkan titik ini ke kanan, audiens percobaan kami berkurang. Bagaimanapun, jumlah orang yang menerima prediksi ini adalah area di bawah kurva. Namun, dalam praktiknya, akurasi prediksi jauh lebih tinggi. Demikian pula, jika tidak ada daya statis yang cukup, Anda dapat meningkatkan audiens percobaan Anda, tetapi menurunkan akurasi prediksi.
Selain prediksi itu sendiri, kami mulai memantau nilai input dalam vektor.
Satu pengkodean panas
Sebagian besar fitur dalam model kami yang paling sederhana bersifat kategorikal. Ini berarti bahwa ini bukan angka, tetapi kategori tertentu: kota tempat pengguna berada, atau kota tempat ia mencari hotel. Kami menggunakan One Hot Encoding dan mengubah masing-masing nilai yang mungkin menjadi unit dalam vektor biner. Karena pada awalnya kami hanya menggunakan inti komputasi kami sendiri, mudah untuk mengidentifikasi situasi di mana tidak ada tempat untuk kategori yang masuk dalam vektor yang masuk, yaitu, model tidak melihat data ini selama pelatihan.
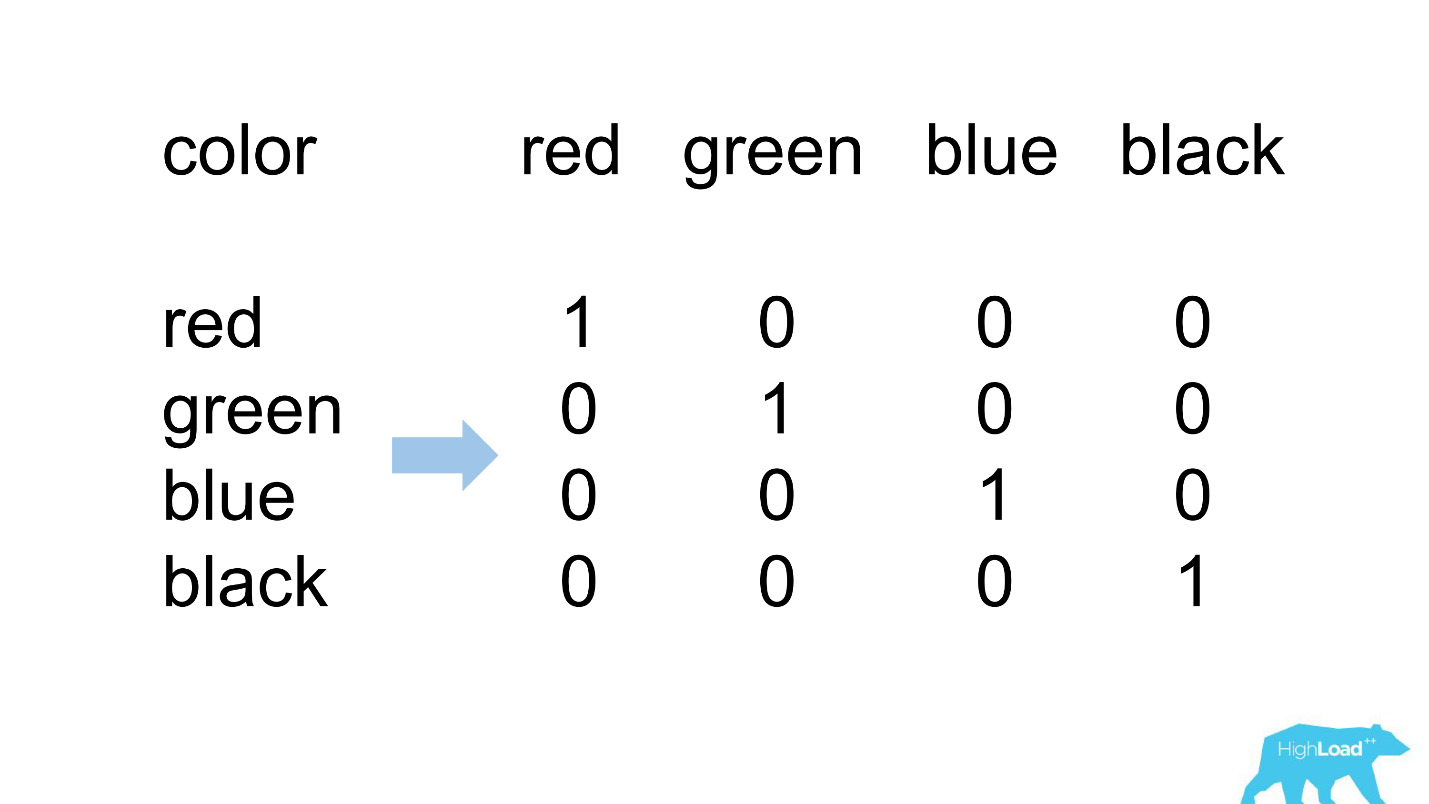
Seperti inilah biasanya.

destination_id - kota tempat pengguna mencari hotel. Secara alami, model tidak melihat sekitar 5% dari nilai, karena kami terus-menerus menghubungkan kota-kota baru. visitor_cty_id = 23,32%, karena datacientists terkadang secara sadar menghilangkan kota yang kurang umum.
Dalam kasus yang buruk, mungkin terlihat seperti ini:

Segera 3 properti, 100% dari nilai yang modelnya belum pernah lihat. Paling sering ini terjadi karena penggunaan format selain yang digunakan dalam pelatihan, atau hanya kesalahan ketik dangkal.
Sekarang dengan bantuan dasbor, kami mendeteksi dan memperbaiki situasi seperti itu dengan sangat cepat.
Showcase Pembelajaran Mesin
Mari kita bicara tentang masalah lain yang telah kita selesaikan. Setelah kami membuat perpustakaan dan pemantauan klien, layanan mulai mendapatkan momentum dengan sangat cepat. Kami benar-benar kewalahan dengan aplikasi dari berbagai bagian perusahaan: “Mari sambungkan model ini juga! Mari perbarui yang lama! " Kami baru saja menjahit, pada kenyataannya, setiap perkembangan baru telah berhenti.
Kami keluar dari situasi tersebut dengan membuat
kios swalayan untuk para ilmuwan data . Sekarang Anda bisa pergi ke portal kami, yang sama yang kami gunakan pada awalnya hanya untuk pemantauan, dan secara harfiah dengan mengklik tombol memuat model ke dalam produksi. Dalam beberapa menit dia akan bekerja dan memberikan prediksi.
Ada satu masalah lagi.
Booking.com memiliki sekitar 200 tim TI. Bagaimana cara memberi tahu tim di beberapa bagian perusahaan yang sama sekali berbeda bahwa ada model yang dapat membantu mereka? Anda mungkin tidak tahu bahwa tim seperti itu ada. Bagaimana cara mengetahui model apa yang ada dan bagaimana menggunakannya? Secara tradisional, komunikasi eksternal dalam tim kami terlibat dalam PO (Pemilik Produk). Ini tidak berarti bahwa kita tidak memiliki koneksi horisontal lain, hanya PO yang melakukan ini lebih dari yang lain. Tetapi jelas bahwa pada skala seperti itu, komunikasi satu lawan satu tidak berskala. Anda perlu melakukan sesuatu tentang itu.
Bagaimana komunikasi dapat difasilitasi?Kami tiba-tiba menyadari bahwa portal, yang kami buat khusus untuk pemantauan, secara bertahap mulai berubah menjadi sebuah karya pembelajaran mesin di perusahaan kami.
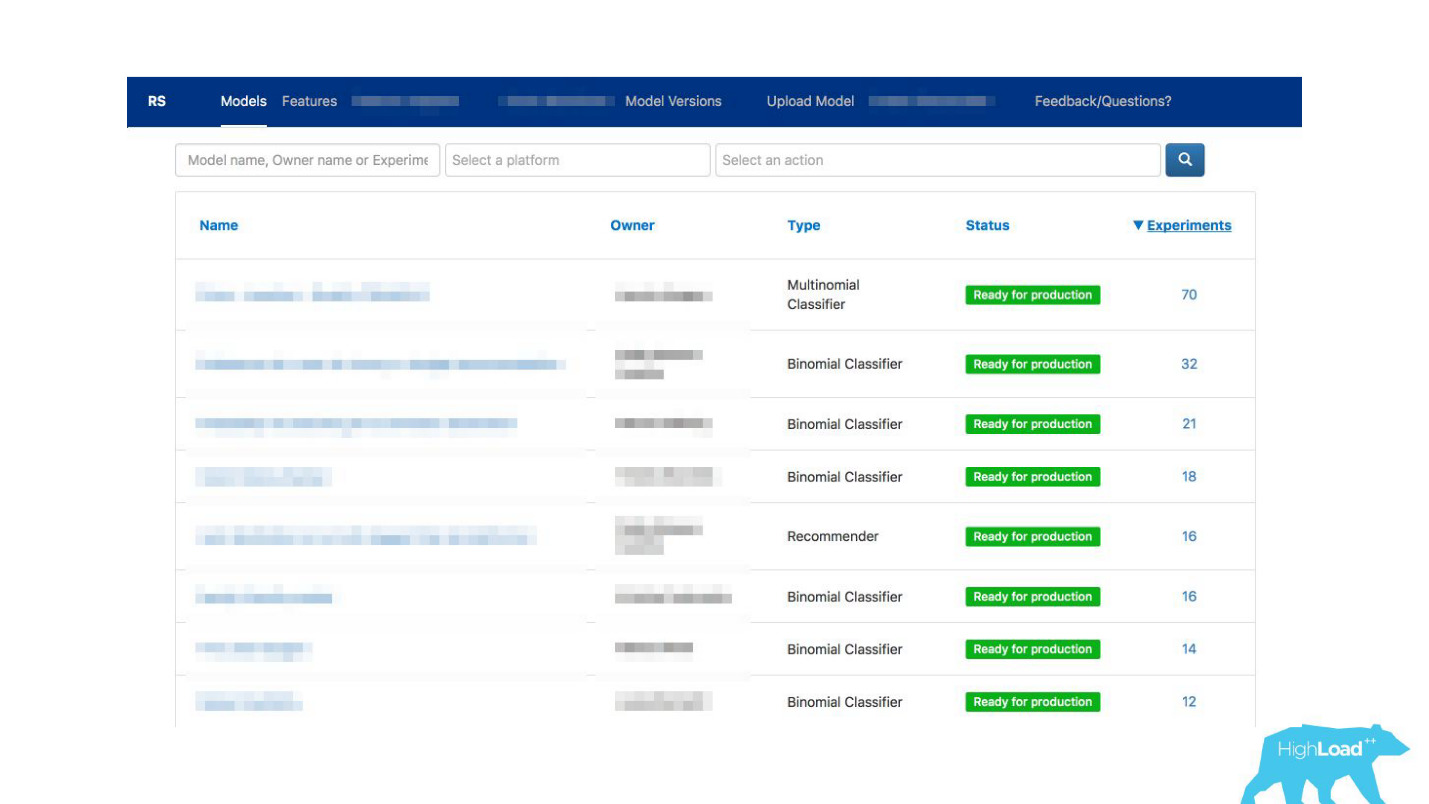
Kami telah memungkinkan para datacientists untuk menggambarkan model mereka secara rinci. Ketika ada banyak model, kami menambahkan label topik dan area untuk pengelompokan yang nyaman.
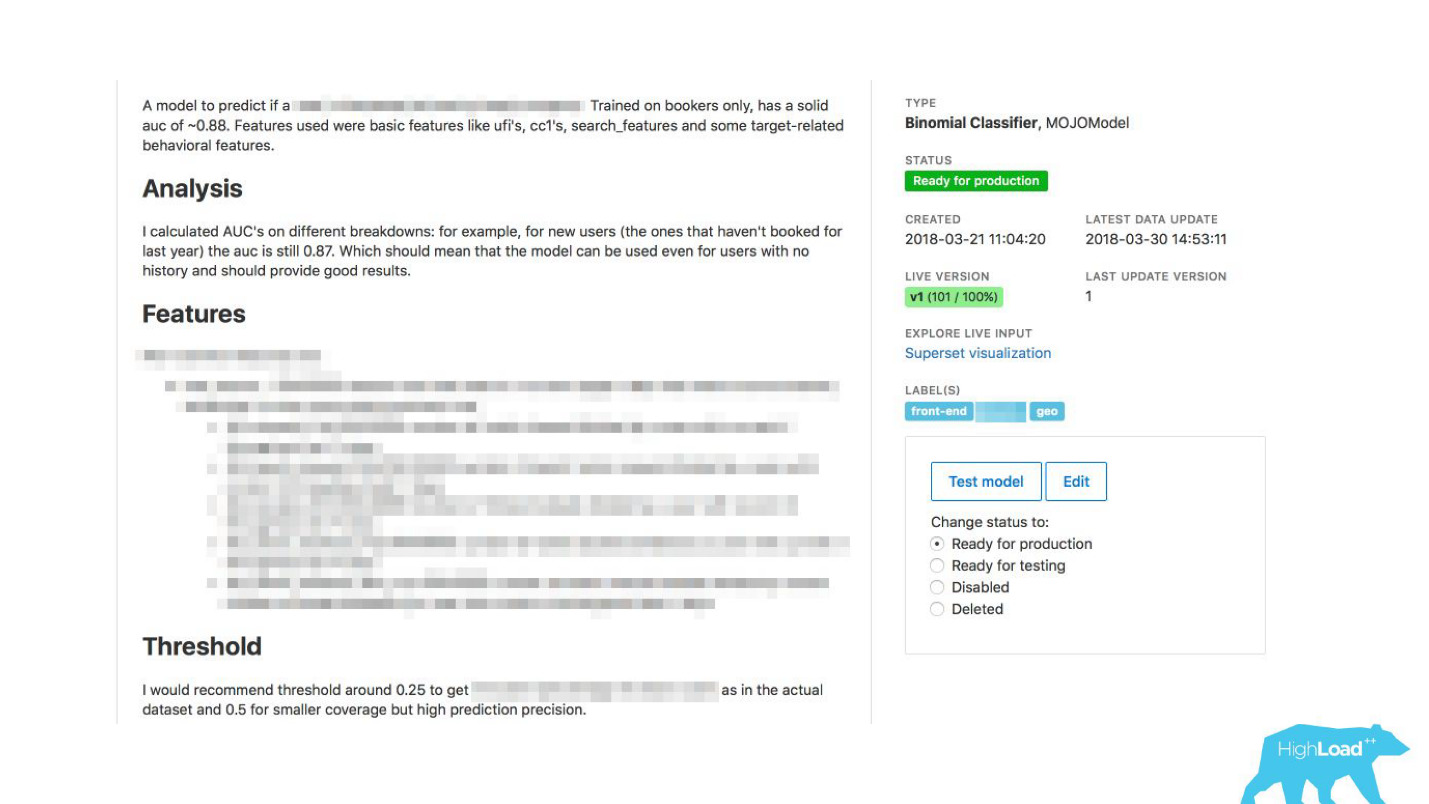
Kami menautkan alat kami dengan ExperimentTool. Ini adalah produk di dalam perusahaan kami yang menyediakan eksperimen A / B dan menyimpan seluruh sejarah eksperimen.

Sekarang, bersama dengan deskripsi model, Anda juga dapat melihat apa yang telah dilakukan tim lain dengan model ini sebelumnya dan seberapa suksesnya. Itu telah mengubah segalanya.
Serius, ini telah mengubah cara kerja TI, karena bahkan dalam situasi di mana tidak ada ilmuwan data dalam tim, Anda dapat menggunakan pembelajaran mesin.
Sebagai contoh, banyak tim menggunakan ini selama sesi curah pendapat. Ketika mereka datang dengan beberapa ide produk baru, mereka cukup memilih model yang sesuai dengan mereka dan menggunakannya. Tidak ada yang rumit diperlukan untuk ini.
Apa yang tumpah bagi kita? Saat ini, pada puncaknya, kami memberikan sekitar 200 ribu prediksi per detik, dengan latensi kurang dari 20-30 ms, termasuk round trip HTTP, dan penempatan lebih dari 200 model.
Kelihatannya sangat mudah berjalan-jalan di taman: kami melakukan pekerjaan yang luar biasa, semuanya bekerja, semua orang senang!
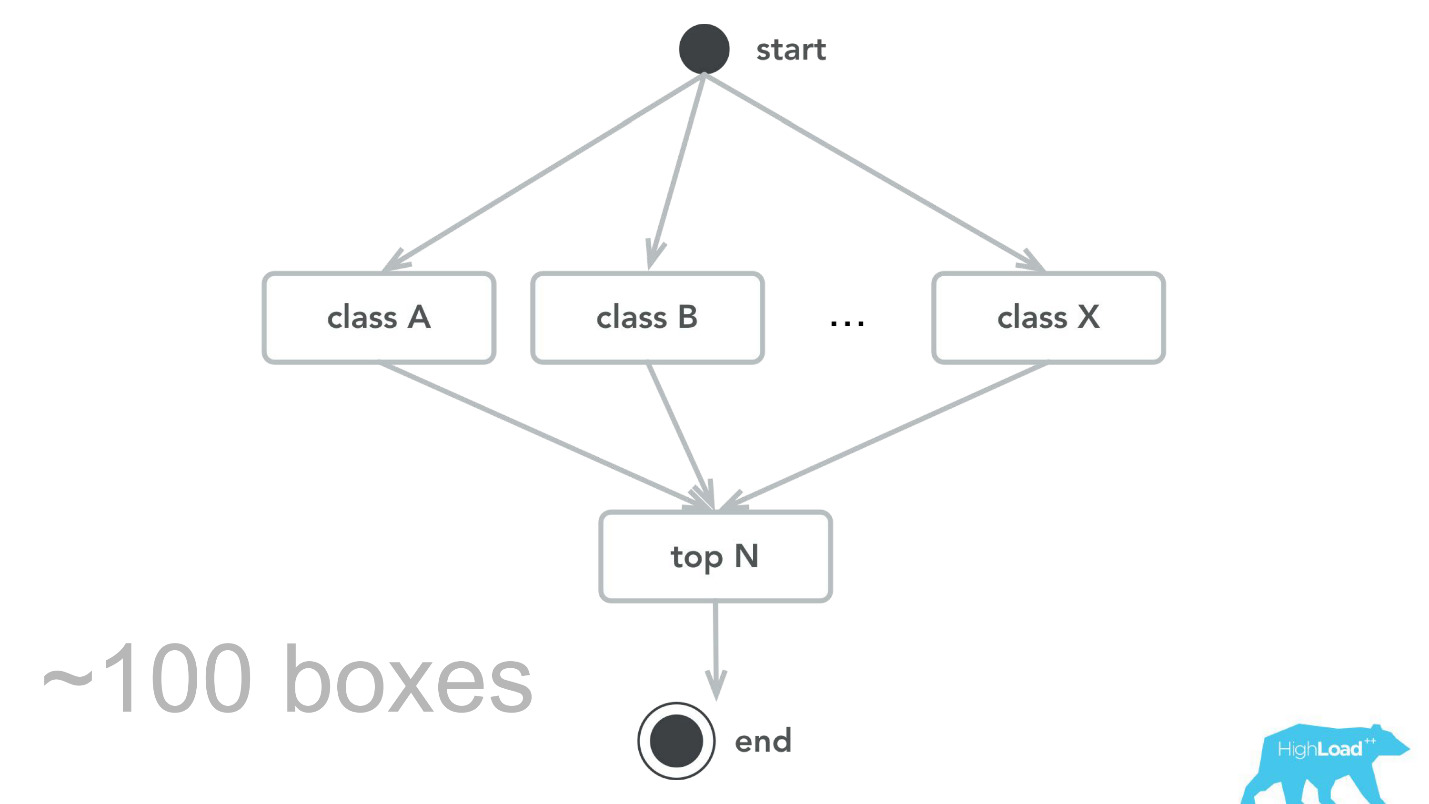
Ini, tentu saja, tidak terjadi. Ada kesalahan. Pada awalnya, misalnya, kami menanam bom waktu kecil. Untuk beberapa alasan, kami berasumsi bahwa sebagian besar model kami akan menjadi sistem rekomendasi dengan vektor input yang berat, dan tumpukan Scala + Akka dipilih dengan tepat karena sangat mudah untuk mengatur perhitungan paralel dengan bantuannya. Namun dalam kenyataannya, overhead untuk semua paralelisasi ini, untuk mengumpulkan bersama, ternyata lebih tinggi dari kemungkinan keuntungan. Pada titik tertentu, 100 mesin kami hanya memproses 100.000 RPS, dan kegagalan terjadi dengan gejala yang cukup khas: Penggunaan CPU rendah, tetapi waktu tunggu habis.
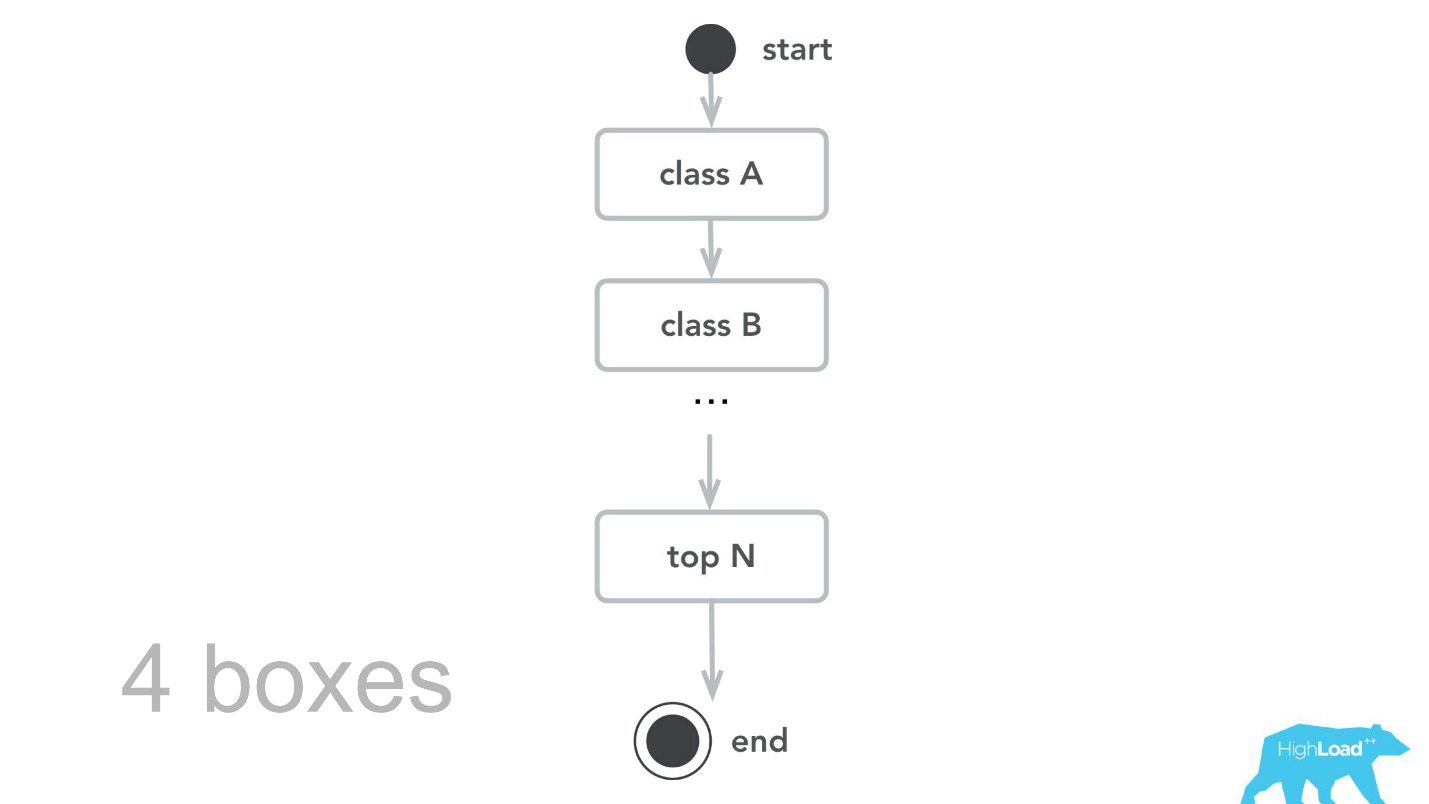
Kemudian kami kembali ke inti komputasi, ditinjau, membuat tolok ukur, dan sebagai hasil dari pengujian kapasitas, kami mengetahui bahwa untuk lalu lintas yang sama, kami hanya membutuhkan 4 mesin. , , -, , , , 100 000 RPS 4 .
- , , . - , , , .
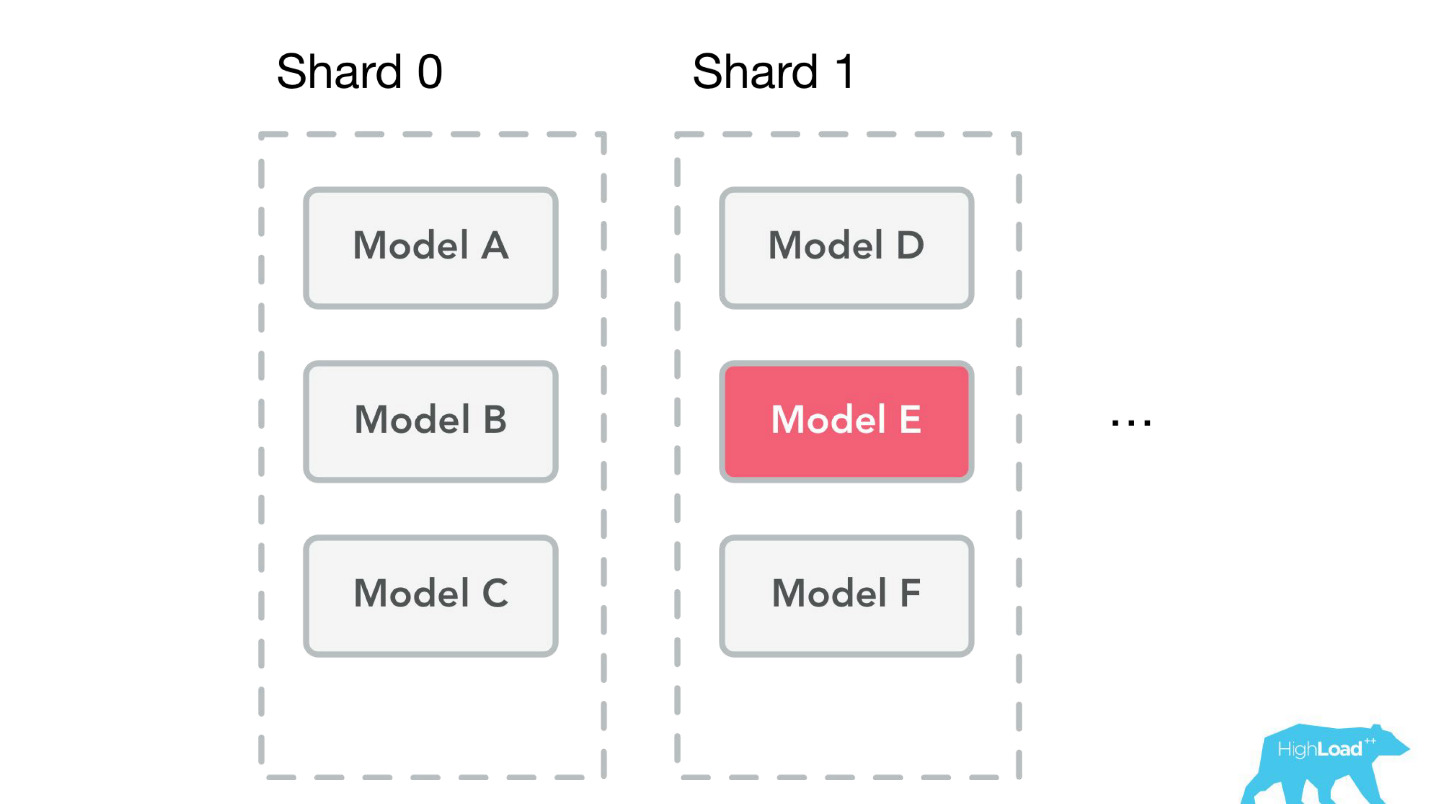
— , . , ID , . , 0.
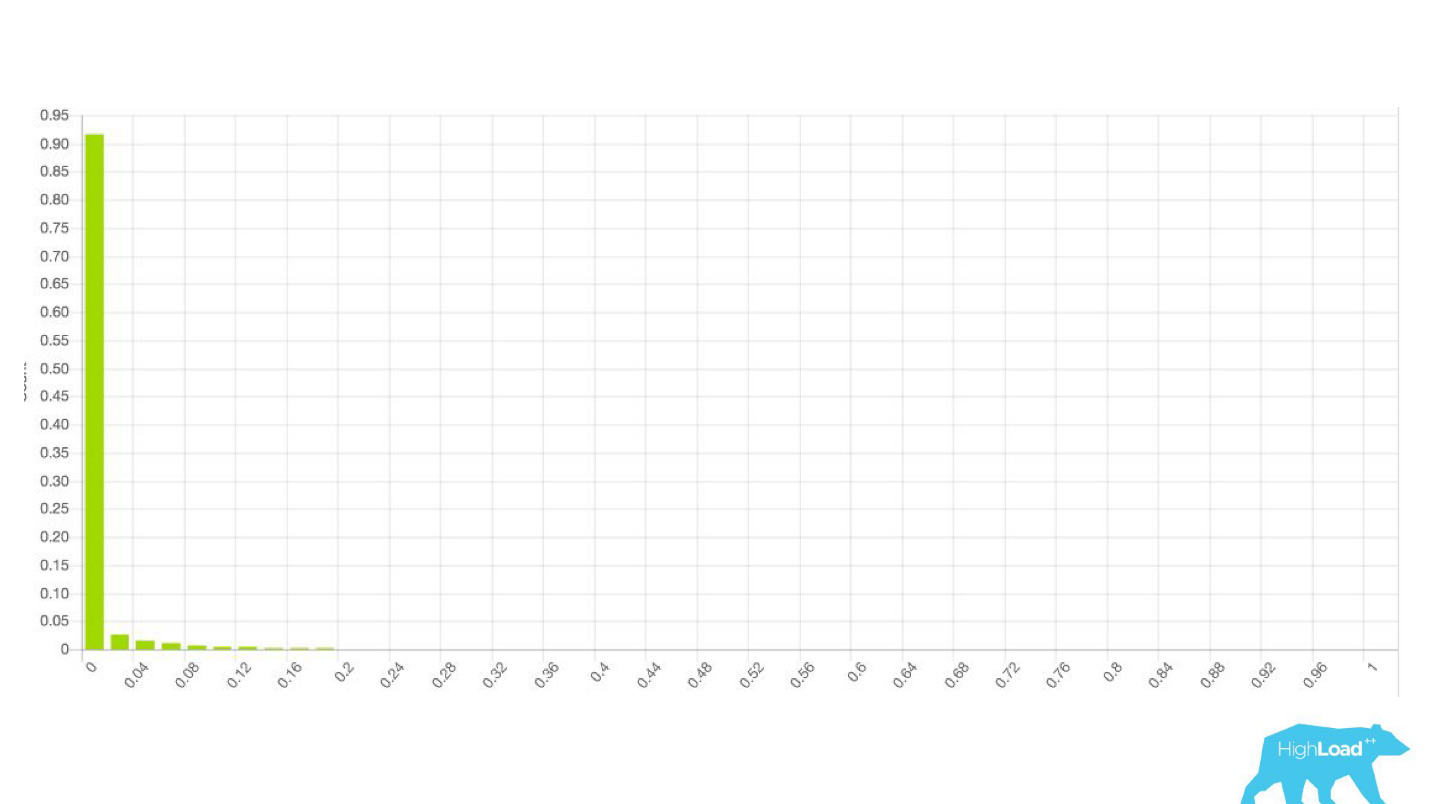
— , — .
, . , . , — , . , , , - .
, — ID . — 49-51%. , . , , . , .
Rencana masa depan
- , . Label based metrics, precision recall .
- More tools & integrations
, . , Perl Java, , , . Spark, .
- Reusable training pipelines
.
, -. , , , , ,
steaming — - , , .
. pipeline, , . , , .
. ,
, 50 , . , . , , .
Start small
, , Booking.com, , , — !
, , MySQL. , , . - . B . , , - — .
, ?
Monitor
— , -, .
— . — , . , , , . : , . , , , — !
Organization footprint
, . , . , .
(Don't) Follow our steps
- , , , . , - , . , . — , , ? , , , ?
, , !HighLoad++ 2018, 8 9 , 135 , . 9 - . , .