Sebelum klien dapat melakukan transfer uang dalam pembayaran elektronik, ia harus melalui verifikasi. Dia memberi kami data pribadinya dan mengunggah dokumen untuk memverifikasi identitas dan alamatnya. Dan kami memeriksa apakah mereka memenuhi persyaratan regulator kami. Alur aplikasi untuk verifikasi semakin lama semakin sulit bagi kami untuk memproses aliran dokumen. Kami takut prosedur itu akan memakan banyak waktu dan melebihi semua persyaratan yang masuk akal bagi pelanggan. Kemudian kami memutuskan untuk membuat sistem verifikasi berdasarkan pembelajaran yang mendalam.

Program pendidikan tentang regulator dan persyaratannya
Untuk mengeluarkan uang elektronik, Anda perlu mendapatkan lisensi regulator. Jika Anda membuka sistem pembayaran, misalnya, di Rusia, Bank Sentral Federasi Rusia akan menjadi regulator Anda. ePayments adalah sistem pembayaran bahasa Inggris, regulator kami adalah Financial Conduct Authority (FCA), otoritas yang melapor ke Perbendaharaan Inggris. FCA memastikan bahwa kami mematuhi kebijakan Anti Pencucian Uang (AML), yang mencakup serangkaian prosedur Know Your Customer (KYC).
Menurut KYC, kami berkomitmen untuk memeriksa siapa klien kami dan apakah ia terkait dengan kelompok yang berbahaya secara sosial. Karena itu, kami memiliki dua kewajiban:
- Identifikasi dan konfirmasi identitas pelanggan.
- Rekonsiliasi datanya dengan berbagai daftar: teroris, orang-orang di bawah sanksi, anggota pemerintah dan banyak lainnya.
Setiap tahun, persyaratan KYC menjadi lebih ketat dan lebih rinci. Pada awal 2017, pelanggan ePayments masih dapat menerima pembayaran atau melakukan transfer tanpa verifikasi. Sekarang ini tidak mungkin sampai mereka mengkonfirmasi identitas mereka.
Verifikasi Manual
Beberapa tahun yang lalu, kami berupaya sendiri. Rusia mengirim pemindaian halaman-halaman paspor tertentu untuk mengkonfirmasi identitas mereka, dan pemindaian perjanjian sewa, tanda terima untuk pembayaran perumahan dan layanan komunal untuk mengonfirmasi alamat. Ingat game Papers, tolong? Di dalamnya, bermain sebagai petugas bea cukai, Anda memeriksa dokumen terhadap persyaratan yang semakin kompleks dari pemerintah. Departemen pelanggan kami memainkannya di tempat kerja setiap hari.

Klien diverifikasi dari jarak jauh, tanpa kunjungan ke kantor. Untuk mempercepat prosedur, kami merekrut karyawan baru, tetapi ini jalan buntu. Kemudian muncul ide untuk mempercayakan sebagian pekerjaan jaringan saraf. Jika dia mengatasi dengan baik pengenalan wajah, maka dia mengatasi tugas kita. Dari perspektif bisnis, sistem verifikasi cepat harus dapat:
- Klasifikasi dokumen. Kami dikirim kartu identitas dan konfirmasi alamat tempat tinggal. Sistem harus menjawab apa yang diterimanya di pintu masuk: paspor warga negara Federasi Rusia, perjanjian sewa, atau yang lainnya.
- Bandingkan wajah di foto dan dokumen. Kami meminta pelanggan untuk mengirim narsis dengan kartu identitas untuk memastikan bahwa mereka sendiri terdaftar dalam sistem pembayaran.
- Ekstrak teks. Mengisi lusinan bidang dari telepon pintar tidaklah mudah. Jauh lebih mudah jika aplikasi melakukan segalanya untuk Anda.
- Periksa file gambar untuk montase foto. Kita tidak boleh lupa tentang scammer yang ingin masuk ke sistem dengan curang.
Pada output, sistem harus menunjukkan tingkat kepercayaan tertentu pada klien: tinggi, sedang atau rendah. Berfokus pada gradasi seperti itu, kami akan dengan cepat memverifikasi dan tidak membuat marah pelanggan dengan periode yang lama.
Klasifikasi Dokumen
Tugas modul ini adalah memastikan bahwa pengguna mengirim dokumen yang valid dan memberikan jawaban apa yang sebenarnya dia unggah: paspor warga negara Kazakhstan, perjanjian sewa atau tanda terima untuk pembayaran perumahan dan layanan komunal.
Pengklasifikasi menerima data input:
- Foto atau pindai dokumen
- Negara tempat tinggal
- Jenis dokumen yang ditunjukkan oleh klien (kartu identitas atau bukti alamat)
- Teks yang diekstraksi (lebih lanjut tentang itu di bawah)
Di bagian output, classifier melaporkan apa yang dia terima (paspor, SIM, dan sebagainya) dan seberapa yakin dia akan jawaban yang benar.

Solusinya sekarang berjalan pada arsitektur Wide Residual Network. Kami tidak segera datang kepadanya. Versi pertama dari sistem verifikasi cepat bekerja berdasarkan arsitektur yang diinspirasikan oleh VGG kepada kami. Dia memiliki 2 masalah yang jelas: sejumlah besar parameter (sekitar 130 juta) dan ketidakstabilan pada posisi dokumen. Semakin banyak parameter, semakin sulit untuk melatih jaringan saraf seperti itu - itu membuat generalisasi pengetahuan menjadi buruk. Dokumen dalam foto harus dipusatkan, jika tidak, pengklasifikasi harus dilatih pada sampel di mana ia berada di berbagai bagian foto. Akibatnya, kami meninggalkan VGG dan memutuskan untuk beralih ke arsitektur yang berbeda.
Residual Network (ResNet) lebih keren daripada VGG. Berkat
melompati koneksi, Anda dapat membuat sejumlah besar lapisan dan mencapai akurasi tinggi. ResNet hanya memiliki sekitar 1 juta parameter, dan dia acuh tak acuh pada posisi dokumen. Tidak masalah di mana ia berada dalam gambar, solusi pada arsitektur ini menangani klasifikasi.
Sementara kami menyelesaikan solusi dengan file, modifikasi arsitektur baru, Wide Residual Network (WRN), dirilis. Perbedaan utama dari ResNet adalah langkah mundur dalam hal kedalaman. WRN memiliki lebih sedikit lapisan, tetapi lebih banyak filter konvolusional. Sekarang ini adalah arsitektur jaringan saraf terbaik untuk sebagian besar tugas dan solusi kami bekerja di atasnya.
Beberapa solusi bermanfaat
Masalah nomor 1. Pengklasifikasi perlu dilatih. Kami harus mengunduh banyak paspor dan SIM Rusia, Kazakh dan Belarusia. Tetapi, tentu saja, Anda tidak dapat mengambil dokumen pelanggan. Jaringan berisi sampel, tetapi ada terlalu sedikit dari mereka untuk pelatihan jaringan saraf yang berhasil.
Solusi Departemen teknis kami menghasilkan sampel 8000+ sampel dari setiap jenis. Kami membuat templat dokumen dan mengalikannya dengan banyak sampel acak. Kemudian kami menghasilkan posisi acak dokumen di ruang relatif terhadap kamera, dengan mempertimbangkan model dan karakteristik matematisnya: panjang fokus, resolusi matriks, dan sebagainya. Saat membuat foto buatan, gambar acak dari kumpulan data yang sudah selesai dipilih sebagai latar belakang. Setelah itu, dokumen dengan distorsi perspektif ditempatkan pada gambar secara acak. Pada sampel seperti itu, jaringan saraf kami terlatih dengan baik dan dengan sempurna mendefinisikan dokumen "dalam pertempuran". Hasilnya ada di akhir artikel.
Masalah nomor 2. Pembatasan dangkal pada sumber daya komputasi dan memori. Tidak masuk akal untuk mengirimkan jaringan saraf yang mendalam ke input gambar besar. Dan foto-foto dari smartphone modern hanyalah itu.
Solusi Sebelum menerapkan input, foto dikompresi hingga ukuran sekitar 300x300 piksel. Dari gambar izin ini, seseorang dapat dengan mudah membedakan satu dokumen identifikasi dari yang lainnya. Untuk mengatasi masalah ini, kita dapat menggunakan arsitektur Wide ResNet standar.
Masalah nomor 3. Dengan dokumen yang mengkonfirmasi alamat tempat tinggal, semuanya menjadi lebih rumit. Perjanjian sewa atau pernyataan bank hanya dapat dibedakan dengan teks pada lembar. Setelah memperkecil ukuran gambar menjadi 300x300 piksel yang sama, semua dokumen ini terlihat sama - seperti lembar A4 dengan teks yang tidak terbaca.
Solusi Untuk mengklasifikasikan dokumen sewenang-wenang, kami membuat perubahan pada arsitektur jaringan saraf itu sendiri. Lapisan input tambahan neuron muncul di dalamnya, yang terhubung dengan lapisan output. Neuron pada lapisan input ini menerima input vektor yang menggambarkan teks yang sebelumnya dikenali menggunakan model
Bag-of-Words .
Pertama, kami melatih jaringan saraf untuk mengklasifikasikan dokumen identitas. Kami menggunakan bobot jaringan terlatih ketika menginisialisasi jaringan lain dengan lapisan tambahan untuk mengklasifikasikan dokumen sewenang-wenang. Solusi ini memiliki akurasi tinggi, tetapi pengenalan teks membutuhkan waktu. Perbedaan dalam kecepatan pemrosesan antara modul yang berbeda dan akurasi klasifikasi dapat dilihat pada tabel No. 2.
Pengenalan wajah
Bagaimana cara mengelabui sistem pembayaran yang memeriksa dokumen? Anda dapat meminjam paspor orang lain dan mendaftar menggunakannya. Untuk memastikan bahwa klien mendaftarkan dirinya, kami meminta Anda untuk berfoto selfie dengan kartu identitas. Dan modul pengenalan harus membandingkan wajah pada dokumen dan wajah pada selfie dan menjawab, ini satu atau dua orang berbeda.
Bagaimana membandingkan 2 wajah jika Anda seorang mobil dan berpikir seperti mobil? Ubah foto menjadi seperangkat parameter dan bandingkan nilainya satu sama lain. Beginilah cara kerja jaringan saraf yang mengenali wajah. Mereka mengambil gambar dan mengubahnya menjadi vektor 128 dimensi (misalnya). Ketika Anda mengirimkan gambar wajah lain ke input dan meminta mereka untuk membandingkan, jaringan saraf akan mengubah wajah kedua menjadi vektor dan menghitung jarak di antara mereka.
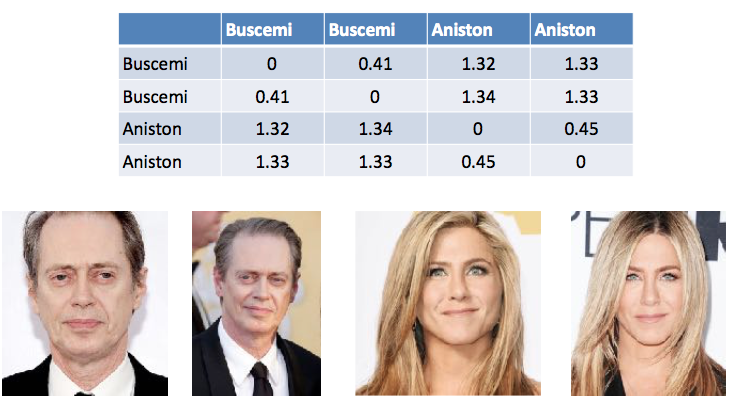 Tabel 1. Contoh menghitung perbedaan antara vektor dalam pengenalan wajah. Steve Buscemi berbeda dari dirinya sendiri di foto yang berbeda dengan 0,44. Dan dari Jennifer Aniston - rata-rata 1,33.
Tabel 1. Contoh menghitung perbedaan antara vektor dalam pengenalan wajah. Steve Buscemi berbeda dari dirinya sendiri di foto yang berbeda dengan 0,44. Dan dari Jennifer Aniston - rata-rata 1,33.Tentu saja, ada perbedaan antara penampilan seseorang dalam kehidupan dan paspor. Kami juga memilih jarak antara vektor dan diuji pada orang sungguhan untuk mencapai hasil. Bagaimanapun, keputusan akhir sekarang akan dibuat oleh orang tersebut, dan komentar dari sistem hanya akan menjadi rekomendasi.
Pengenalan teks
Ada bidang teks pada dokumen yang membantu classifier memahami apa yang ada di depannya. Ini akan nyaman bagi pengguna jika teks dari paspor yang sama ditransfer secara otomatis dan tidak harus diketik secara manual, oleh siapa dan kapan dikeluarkan. Untuk melakukan ini, kami membuat modul berikut - pengenalan dan ekstraksi teks.
Pada beberapa dokumen, misalnya, paspor baru dari Federasi Rusia ada zona Machine-readable (MRZ). Dengan bantuannya, mudah untuk mengambil informasi - mudah untuk membaca teks hitam dengan latar belakang putih, yang mudah dikenali. Selain itu, MRZ memiliki format yang terkenal, karena itu lebih mudah untuk mendapatkan data yang diperlukan.

Jika tugas memiliki dokumen dengan MRZ, maka itu menjadi lebih mudah bagi kami. Seluruh proses terletak di bidang visi komputer. Jika zona ini tidak ada, maka setelah mengenali teks yang Anda butuhkan untuk menyelesaikan satu masalah yang menarik - untuk memahami, dan informasi apa yang kami kenali? Misalnya, "15 Mei 1999" adalah tanggal lahir atau tanggal penerbitan? Pada tahap ini, Anda juga bisa melakukan kesalahan. MRZ bagus karena diterjemahkan secara unik. Kami selalu tahu informasi apa dan di bagian mana MRZ harus dicari. Sangat nyaman bagi kami. Tetapi MRZ bukan pada dokumen paling populer yang dengannya jaringan akan bekerja - paspor Federasi Rusia.
Untuk pengenalan teks, kami membutuhkan solusi yang sangat efektif. Teks harus dihapus dari gambar yang diambil oleh kamera ponsel dan bukan oleh fotografer paling profesional. Kami menguji Google Tesseract dan beberapa solusi berbayar. Tidak ada yang muncul - apakah itu bekerja dengan buruk, atau itu terlalu mahal. Sebagai hasilnya, kami mulai mengembangkan solusi kami sendiri. Sekarang kami sedang menyelesaikan pengujiannya. Solusinya menunjukkan hasil yang layak - Anda dapat membacanya di bawah ini. Kita akan berbicara tentang modul untuk memeriksa montase foto beberapa saat kemudian, ketika akan ada hasil penelitian yang akurat pada sampel uji dan pada "pertempuran".
Hasil
Sistem saat ini sedang diuji pada segmen aplikasi untuk verifikasi dari Rusia. Segmen ditentukan dengan pengambilan sampel acak, hasilnya disimpan dan diperiksa terhadap keputusan operator departemen klien untuk klien tertentu.
| Negara | Jenis Klasifikasi | Akurasi | Waktu kerja, s |
| Rusia | Kartu identitas | 99,96% | 0,41 |
| Rusia | Dokumen khusus | 98,62% | 6.89 |
| Kazakhstan | Kartu identitas | 99,51% | 0,47 |
| Kazakhstan | Dokumen khusus | 97,25% | 7.66 |
| Belarus | Kartu identitas | 98,63% | 0,46 |
| Belarus | Dokumen khusus | 98,63% | 9.66 |
Tabel 2. Keakuratan classifier dokumen (klasifikasi dokumen yang benar dibandingkan dengan penilaian operator).Salah satu keuntungan besar dari pembelajaran mesin adalah bahwa jaringan saraf benar-benar belajar dan membuat lebih sedikit kesalahan. Segera kami akan menyelesaikan pengujian pada segmen tersebut dan meluncurkan sistem verifikasi dalam mode "pertempuran". 30% aplikasi untuk verifikasi datang ke ePayments dari Rusia, Kazakhstan, dan Belarus. Menurut perkiraan kami, peluncuran ini akan membantu mengurangi beban pada departemen klien sebesar 20-25%. Di masa depan, solusinya dapat ditingkatkan ke negara-negara Eropa.
Mencari pekerjaan?
Kami mencari karyawan untuk bekerja di kantor di St. Petersburg. Jika Anda tertarik pada proyek internasional dengan banyak tugas ambisius, kami menunggu Anda. Kami tidak memiliki cukup banyak orang yang tidak takut untuk menyadarinya. Di bawah ini Anda akan menemukan tautan ke lowongan di hh.ru.