Reinforced Learning (RL) adalah salah satu teknik pembelajaran mesin yang paling menjanjikan yang sedang dikembangkan secara aktif. Di sini, agen AI menerima hadiah positif untuk tindakan yang benar, dan hadiah negatif untuk yang salah. Metode
wortel dan tongkat ini sederhana dan universal. Dengan itu, DeepMind mengajarkan algoritma
DQN untuk memainkan video game Atari lama, dan
AlphaGoZero untuk memainkan game Go kuno. Jadi OpenAI mengajarkan algoritma
OpenAI-Five untuk memainkan video game Dota modern, dan Google mengajarkan tangan robot untuk
menangkap objek baru . Terlepas dari keberhasilan RL, masih ada banyak masalah yang mengurangi efektivitas teknik ini.
Algoritma RL
merasa sulit untuk bekerja di lingkungan di mana agen jarang menerima umpan balik. Tapi ini tipikal dari dunia nyata. Sebagai contoh, bayangkan mencari keju favorit Anda di labirin besar, seperti supermarket. Anda mencari dan mencari departemen dengan keju, tetapi Anda tidak dapat menemukannya. Jika pada setiap langkah Anda tidak mendapatkan "tongkat" atau "wortel", maka tidak mungkin untuk mengatakan apakah Anda bergerak ke arah yang benar. Dengan tidak adanya hadiah, apa yang mencegah Anda berkeliaran selamanya? Tidak ada yang lain kecuali mungkin keingintahuan Anda. Itu memotivasi pindah ke departemen kelontong, yang tampak asing.
Karya ilmiah,
"Keingintahuan Episodik melalui Reachability," adalah hasil kolaborasi antara
tim Google Brain ,
DeepMind, dan
Sekolah Tinggi Teknik Swiss Zurich . Kami menawarkan model hadiah RL berbasis memori episodik baru. Dia terlihat seperti keingintahuan yang memungkinkan Anda menjelajahi lingkungan. Karena agen tidak hanya harus mempelajari lingkungan, tetapi juga menyelesaikan masalah awal, model kami menambahkan bonus ke hadiah yang awalnya jarang. Hadiah gabungan tidak lagi jarang, yang memungkinkan algoritma RL standar untuk belajar darinya. Dengan demikian, metode keingintahuan kami memperluas berbagai tugas yang dapat diselesaikan menggunakan RL.
 Rasa ingin tahu sesekali melalui keterjangkauan: data observasi ditambahkan ke memori, hadiah dihitung berdasarkan seberapa jauh pengamatan saat ini dari pengamatan serupa di memori. Agen menerima hadiah yang lebih besar untuk pengamatan yang belum disajikan dalam memori.
Rasa ingin tahu sesekali melalui keterjangkauan: data observasi ditambahkan ke memori, hadiah dihitung berdasarkan seberapa jauh pengamatan saat ini dari pengamatan serupa di memori. Agen menerima hadiah yang lebih besar untuk pengamatan yang belum disajikan dalam memori.Gagasan utama dari metode ini adalah untuk menyimpan pengamatan agen terhadap lingkungan dalam memori episodik, serta menghargai agen untuk melihat pengamatan yang belum disajikan dalam memori. "Kurangnya memori" adalah definisi yang baru dalam metode kami. Pencarian pengamatan seperti itu berarti pencarian orang asing. Keinginan untuk mencari orang asing seperti itu akan membawa agen AI ke lokasi baru, sehingga mencegah berkeliaran dalam lingkaran, dan akhirnya membantunya tersandung pada target. Seperti yang akan kita diskusikan nanti, kata-kata kita dapat menghalangi agen dari perilaku yang tidak diinginkan yang dikenakan oleh beberapa kata lain. Yang mengejutkan kami, perilaku ini memiliki beberapa kesamaan dengan apa yang oleh orang awam disebut "penundaan."
Keingintahuan sebelumnya
Meskipun ada banyak upaya untuk merumuskan keingintahuan di masa lalu
[1] [2] [3] [4] , dalam artikel ini kita akan fokus pada satu pendekatan alami dan sangat populer: keingintahuan melalui kejutan berdasarkan perkiraan. Teknik ini dijelaskan dalam artikel baru-baru ini,
"Investigasi Lingkungan yang Menggunakan Keingintahuan dengan Memprediksi Di Bawah Kendali Sendiri" (biasanya disebut sebagai ICM). Untuk menggambarkan hubungan antara kejutan dan rasa ingin tahu, kami kembali menggunakan analogi menemukan keju di supermarket.
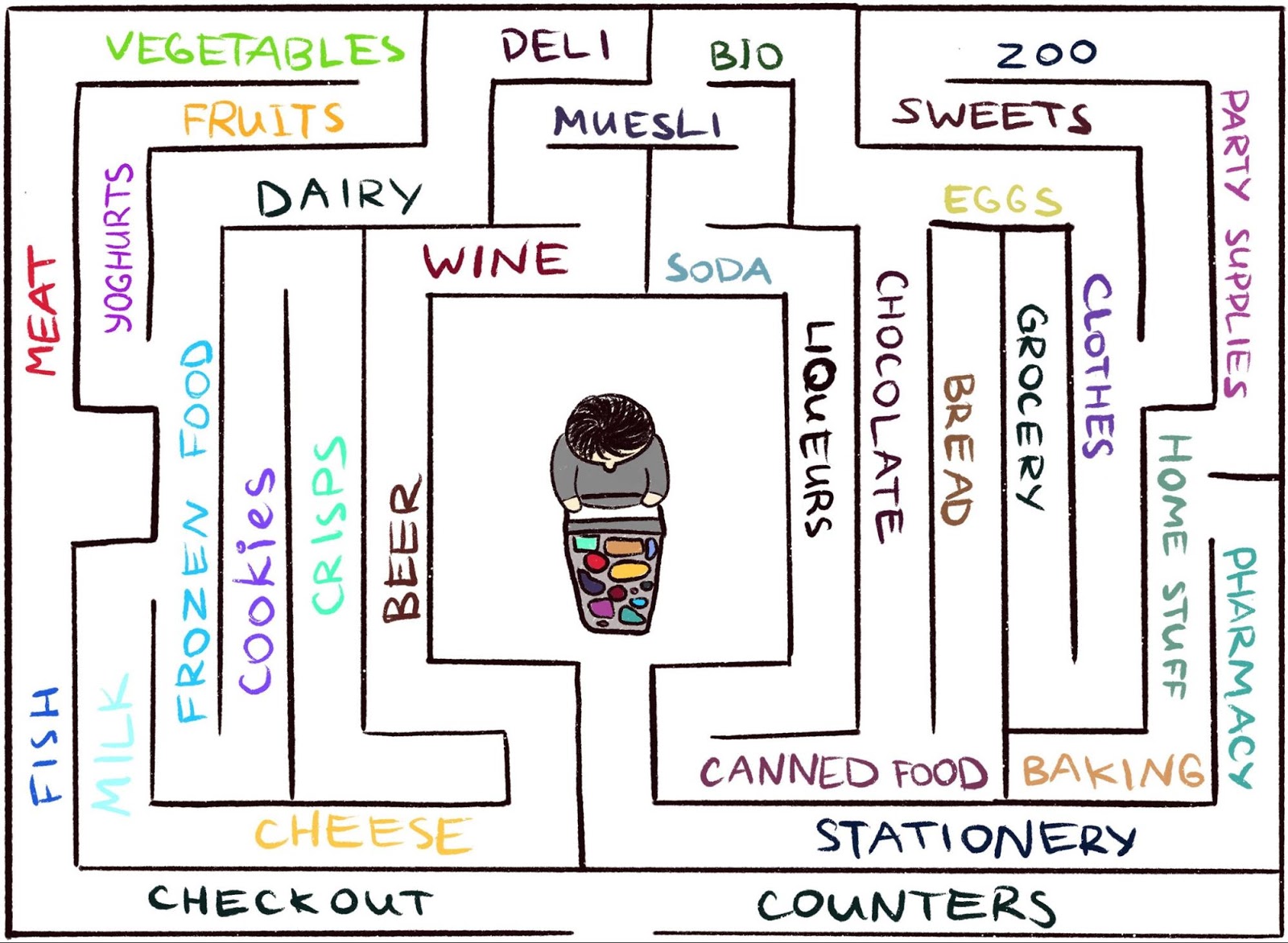 Ilustrasi oleh Indira Pasko , dilisensikan di bawah CC BY-NC-ND 4.0
Ilustrasi oleh Indira Pasko , dilisensikan di bawah CC BY-NC-ND 4.0Berkeliaran di sekitar toko, Anda mencoba untuk memprediksi masa depan (
"Sekarang saya di departemen daging, jadi saya berpikir bahwa departemen di sudut adalah departemen ikan, mereka biasanya di dekatnya dalam rantai supermarket ini" ). Jika ramalannya salah, Anda akan terkejut (
"Sebenarnya, ada departemen sayuran. Saya tidak mengharapkan ini!" ) - dan dengan cara ini Anda mendapatkan hadiah. Ini meningkatkan motivasi di masa depan untuk melihat ke sudut lagi, menjelajahi tempat-tempat baru hanya untuk memverifikasi bahwa harapan Anda benar (dan mungkin tersandung pada keju).
Demikian pula, metode ICM membangun model prediksi dinamika dunia dan memberikan agen hadiah jika model gagal membuat prediksi yang baik - penanda kejutan atau hal baru. Harap dicatat bahwa menjelajahi tempat-tempat baru tidak secara langsung diartikulasikan dalam keingintahuan ICM. Untuk metode ICM, menghadiri mereka hanyalah cara untuk mendapatkan lebih banyak "kejutan" dan dengan demikian memaksimalkan hadiah keseluruhan Anda. Ternyata, di beberapa lingkungan mungkin ada cara lain untuk mengejutkan diri sendiri, yang mengarah pada hasil yang tidak terduga.
Seorang agen dengan sistem rasa ingin tahu berdasarkan kejutan membeku ketika bertemu dengan TV. Animasi dari video Deepak Patak , dilisensikan di bawah CC BY 2.0Bahaya penundaan
Dalam artikel tersebut,
"Studi Skala Besar Pembelajaran Berbasis Curiosity," penulis metode ICM, bersama dengan para peneliti OpenAI, menunjukkan bahaya tersembunyi untuk memaksimalkan kejutan: agen dapat belajar untuk melakukan penundaan daripada melakukan sesuatu yang berguna untuk tugas tersebut. Untuk memahami mengapa ini terjadi, pertimbangkan eksperimen pikiran yang oleh penulis disebut sebagai "masalah kebisingan televisi." Di sini agen ditempatkan di labirin dengan tugas menemukan barang yang sangat berguna (seperti "keju" dalam contoh kita). Lingkungan memiliki TV, dan agen memiliki remote control. Ada sejumlah saluran yang terbatas (setiap saluran memiliki transmisi terpisah), dan setiap tekan pada remote control mengalihkan TV ke saluran acak. Bagaimana agen bertindak dalam lingkungan seperti itu?
Jika rasa ingin tahu terbentuk berdasarkan kejutan, maka perubahan saluran akan memberikan lebih banyak hadiah, karena setiap perubahan tidak dapat diprediksi dan tidak terduga. Penting untuk dicatat bahwa bahkan setelah pemindaian siklus semua saluran yang tersedia, pemilihan acak saluran memastikan bahwa setiap perubahan baru akan tetap tidak terduga - agen membuat prediksi bahwa ia akan menampilkan TV setelah mengganti saluran, dan kemungkinan besar ramalan itu akan berubah menjadi tidak benar, yang akan menyebabkan kejutan. Penting untuk dicatat bahwa meskipun agen sudah melihat setiap transmisi pada setiap saluran, perubahannya masih tidak dapat diprediksi. Karena itu, agen, bukannya mencari barang yang sangat berguna, pada akhirnya akan tetap berada di depan TV - mirip dengan penundaan. Bagaimana mengubah kata-kata ingin tahu untuk mencegah perilaku ini?
Keingintahuan episodik
Dalam artikel
"Keingintahuan Episodik melalui Reachability", kami memeriksa model rasa ingin tahu berbasis memori episodik yang kurang rentan terhadap kesenangan instan. Kenapa begitu Jika kita mengambil contoh di atas, maka setelah beberapa waktu berpindah saluran, semua transmisi pada akhirnya akan berakhir di memori. Dengan demikian, TV akan kehilangan daya tariknya: bahkan jika urutan program muncul di layar adalah acak dan tidak dapat diprediksi, semuanya ada dalam memori! Ini adalah perbedaan utama dari metode berdasarkan kejutan: metode kami bahkan tidak mencoba untuk memprediksi masa depan, sulit untuk diprediksi (atau bahkan tidak mungkin). Sebaliknya, agen memeriksa masa lalu dan memeriksa untuk melihat apakah ada pengamatan dalam memori
seperti yang sekarang. Dengan demikian, agen kami tidak rentan terhadap kesenangan instan, yang memberikan "suara televisi". Agen harus pergi dan menjelajahi dunia di luar TV untuk mendapatkan hadiah lebih banyak.
Tetapi bagaimana kita memutuskan apakah agen melihat hal yang sama yang disimpan dalam memori? Pemeriksaan kecocokan yang tepat tidak ada gunanya: dalam lingkungan nyata, agen jarang melihat hal yang sama dua kali. Misalnya, bahkan jika agen kembali ke ruangan yang sama, dia masih akan melihat ruangan ini dari sudut yang berbeda.
Alih-alih memeriksa kecocokan yang tepat, kami menggunakan
jaringan saraf yang dalam yang dilatih untuk mengukur seberapa mirip dua pengalaman itu. Untuk melatih jaringan ini, kita harus menebak seberapa dekat pengamatan terjadi dalam waktu. Kedekatan waktu adalah indikator yang baik apakah dua pengamatan harus dianggap bagian dari yang sama. Pembelajaran semacam itu mengarah pada konsep umum kebaruan melalui jangkauan, yang diilustrasikan di bawah ini.
 Grafik reachability mendefinisikan kebaruan. Dalam praktiknya, grafik ini tidak tersedia - oleh karena itu, kami melatih aproksimasi jaringan saraf untuk memperkirakan jumlah langkah di antara pengamatan
Grafik reachability mendefinisikan kebaruan. Dalam praktiknya, grafik ini tidak tersedia - oleh karena itu, kami melatih aproksimasi jaringan saraf untuk memperkirakan jumlah langkah di antara pengamatanHasil percobaan
Untuk membandingkan kinerja berbagai pendekatan dalam menggambarkan keingintahuan, kami mengujinya dalam dua lingkungan 3D yang kaya visual:
ViZDoom dan
DMLab . Dalam kondisi ini, agen diberi berbagai tugas, seperti menemukan target di labirin, mengumpulkan benda-benda baik dan menghindari yang buruk. Di lingkungan DMLab, agen dilengkapi secara default dengan gadget fantastis seperti laser, tetapi jika gadget tidak diperlukan untuk tugas tertentu, agen tidak dapat menggunakannya secara bebas. Menariknya, berdasarkan kejutan, agen ICM benar-benar menggunakan laser sangat sering, bahkan jika itu sia-sia untuk menyelesaikan tugas! Seperti halnya TV, daripada mencari barang berharga di labirin, ia lebih suka menghabiskan waktu memotret di dinding, karena memberi banyak hadiah dalam bentuk kejutan. Secara teoritis, hasil dari tembakan dinding harus dapat diprediksi, tetapi dalam praktiknya terlalu sulit untuk diprediksi. Ini mungkin membutuhkan pengetahuan fisika yang lebih dalam daripada yang tersedia untuk agen AI standar.
Agen ICM yang terkejut terus-menerus menembak ke dinding bukannya menjelajahi labirinTidak seperti dia, agen kami telah menguasai perilaku yang masuk akal untuk mempelajari lingkungan. Ini terjadi karena dia tidak mencoba untuk memprediksi hasil dari tindakannya, tetapi lebih mencari pengamatan yang "lebih jauh" dari yang ada dalam memori episodik. Dengan kata lain, agen secara implisit mengejar tujuan yang membutuhkan lebih banyak upaya daripada tembakan sederhana di dinding.
Metode kami menunjukkan perilaku eksplorasi lingkungan yang cerdas.Sangat menarik untuk mengamati bagaimana pendekatan kami untuk hadiah menghukum agen yang berjalan dalam lingkaran, karena setelah menyelesaikan lingkaran pertama, agen tidak menemukan pengamatan baru dan, dengan demikian, tidak menerima hadiah apa pun:
Visualisasi hadiah: merah sesuai dengan hadiah negatif, Hijau ke positif. Dari kiri ke kanan: kartu penghargaan, peta dengan lokasi dalam memori, tampilan orang pertamaPada saat yang sama, metode kami berkontribusi pada studi lingkungan yang baik:
Visualisasi hadiah: merah sesuai dengan hadiah negatif, Hijau ke positif. Dari kiri ke kanan: kartu penghargaan, peta dengan lokasi dalam memori, tampilan orang pertamaKami berharap bahwa pekerjaan kami berkontribusi pada gelombang penelitian baru yang melampaui lingkup teknik kejutan untuk mendidik agen tentang perilaku yang lebih cerdas. Untuk analisis mendalam tentang metode kami, silakan lihat
pracetak karya ilmiah .
Ucapan Terima Kasih:
Proyek ini adalah hasil kolaborasi antara tim Google Brain, DeepMind, dan Sekolah Tinggi Teknik Swiss di Zurich. Kelompok penelitian utama: Nikolay Savinov, Anton Raichuk, Rafael Marinier, Damien Vincent, Mark Pollefeys, Timothy Lillirap dan Sylvain Zheli. Kami ingin mengucapkan terima kasih kepada Olivier Pietkin, Carlos Riquelme, Charles Blundell dan Sergey Levine karena telah membahas dokumen ini. Kami berterima kasih kepada Indira Pasco untuk bantuan dengan ilustrasinya.
Referensi literatur:
[1]
“Studi lingkungan berdasarkan penghitungan dengan model kepadatan saraf” , Georg Ostrovsky, Mark G. Bellemar, Aaron Van den Oord, Remy Munoz
[2]
“ Menghitung
lingkungan belajar berbasis pembelajaran dalam dengan penguatan” , Khaoran Tan, Rain Huthuft, Davis Foot, Adam Knock, Xi Chen, Yan Duan, John Schulman, Philip de Turk, Peter de Bel, Peter Abbel
[3]
“Belajar tanpa guru untuk menemukan sasaran untuk penelitian yang bermotivasi internal,” Alexander Pere, Sebastien Forestier, Olivier Sigot, Pierre-Yves Udaye
[4]
"VIME: Kecerdasan untuk Memaksimalkan Perubahan Informasi," Rein Huthuft, Xi Chen, Yan Duan, John Schulman, Philippe de Turk, Peter Abbel