
Mungkin tidak banyak pengguna di Habr yang belum pernah mendengar tentang
" Internet Archive", layanan yang mencari dan menyimpan data digital yang penting bagi semua umat manusia, baik itu halaman web, buku, video atau jenis informasi lainnya. .
Siapa yang menjalankan arsip online ketika muncul dan apa misinya? Baca tentang hal ini dalam Bantuan hari ini.
Mengapa kita membutuhkan "Arsip"?
Ini jauh dari sekadar hiburan. Misi organisasi adalah akses universal ke semua informasi. Arsip Internet berupaya melawan monopoli dalam penyediaan informasi dari kedua perusahaan telekomunikasi (Google, Facebook, dll.) Dan negara-negara bagian.
Selain itu, "Arsip" adalah organisasi yang taat hukum. Jika hukum AS mengharuskan informasi apa pun dihapus, organisasi akan melakukannya.
Internet Archive juga berfungsi sebagai alat bagi para ilmuwan, agen intelijen, sejarawan (seperti arkeografer), dan perwakilan dari banyak bidang lainnya, belum lagi pengguna perorangan.
Kapan "Internet Archive" muncul?
Pencipta Arsip adalah American Brewster Cale, yang menciptakan Alexa Internet. Kedua layanannya telah menjadi sangat populer, keduanya berkembang sekarang.
Internet Archive mulai mengarsipkan informasi dari situs dan menyimpan salinan halaman web sejak 1996. Markas organisasi nirlaba ini berlokasi di San Francisco, AS.
Benar, selama lima tahun data tidak tersedia untuk akses publik - data disimpan di server Archive, dan itu saja, hanya administrasi layanan yang dapat melihat salinan situs lama. Sejak 2001, administrasi layanan memutuskan untuk menyediakan akses ke data yang disimpan untuk semua orang.
Pada awalnya, "arsip Internet" hanya arsip web, tetapi kemudian organisasi mulai menyimpan buku, audio, gambar bergerak, dan perangkat lunak. Sekarang "Internet Archive" bertindak sebagai gudang untuk foto dan gambar NASA lainnya, teks Open Library, dll.
Untuk apa sebuah organisasi ada?
"Arsip" ada atas sumbangan sukarela - baik organisasi maupun individu. Anda dapat memberikan dukungan dalam bitcoin, dompet 1Archive1n2C579dMsAu3iC6tWzuQJz8dN. Dompet ini, omong-omong, telah menerima 357.47245492 BTC untuk seluruh keberadaannya, yaitu sekitar $ 2,25 juta dengan nilai tukar saat ini.
Bagaimana cara kerja Arsip?
Sebagian besar karyawan dipekerjakan di pusat pemindaian buku, melakukan pekerjaan rutin tetapi melelahkan. Organisasi ini memiliki tiga pusat data yang berlokasi di California, AS. Satu di San Francisco, yang kedua adalah Redwood City, yang ketiga adalah Richmond. Untuk menghindari bahaya kehilangan data jika terjadi bencana alam atau bencana lainnya, Arsip memiliki kapasitas cadangan di Mesir dan Amsterdam.
“Jutaan orang telah menghabiskan banyak waktu dan upaya untuk berbagi dengan orang lain apa yang kita ketahui dalam bentuk Internet. Kami ingin membuat perpustakaan untuk platform penerbitan baru ini, ”kata Brewster Kahle, pendiri Internet Archive
Seberapa besar arsip sekarang?
"Arsip Internet" memiliki beberapa divisi, dan yang mengumpulkan informasi dari situs memiliki namanya sendiri - Wayback Machine. Pada saat penulisan "Permintaan", arsip menyimpan 339 miliar halaman web yang disimpan. Pada 2017, "Archive"
menyimpan 30 petabyte informasi, yaitu sekitar 300 miliar halaman web, 12 juta buku, 4 juta rekaman audio, 3,3 juta video, 1,5 juta foto, dan 170 ribu distribusi perangkat lunak berbeda. Hanya dalam satu tahun, layanan ini terasa "bertambah berat", sekarang "Archive" menyimpan 339 miliar halaman web, 19 juta buku, 4,5 juta file video, 4,7 juta file audio, 3,2 juta gambar dari berbagai jenis, 381 ribu distribusi Perangkat lunak.
Bagaimana cara mengatur penyimpanan data?
Informasi disimpan pada hard drive dalam apa yang disebut "data node". Ini adalah server, yang masing-masing berisi 36 hard disk (ditambah dua disk dengan sistem operasi). Node data dikelompokkan ke dalam array 10 mesin dan merupakan repositori cluster. Pada 2016, "Archive" menggunakan HDD 8-terabyte, sekarang situasinya hampir sama. Ternyata satu node menampung sekitar 288 terabyte data. Secara umum, hard drive ukuran lain juga digunakan: 2, 3 dan 4 TB.
Pada 2016, ada sekitar 20.000 hard drive. Pusat data arsip dilengkapi dengan sistem iklim untuk mempertahankan iklim mikro dengan karakteristik konstan. Satu penyimpanan cluster 10 node mengkonsumsi sekitar 5 kW energi.
Struktur Internet Archive adalah "perpustakaan" virtual, yang dibagi menjadi beberapa bagian seperti buku, film, musik, dll. Untuk setiap elemen ada deskripsi yang dimasukkan dalam katalog - biasanya ini adalah nama, nama penulis dan informasi tambahan. Dari sudut pandang teknis, elemen-elemen terstruktur dan berada di direktori Linux.
Jumlah total data yang disimpan oleh "Archive" adalah 22 PB, sementara sekarang masih ada ruang untuk 22 PB. “Karena kami paranoid,” kata perwakilan layanan.

Lihatlah screenshot dari isi direktori - ada file dengan nama yang berakhiran "_files.xml". Ini adalah direktori dengan informasi tentang semua file dalam direktori.
Apa yang akan terjadi pada data jika satu atau beberapa server gagal?
Tidak ada hal buruk yang akan terjadi -
datanya diduplikasi . Segera setelah elemen baru muncul di perpustakaan Archive, itu segera direplikasi dan ditempatkan pada berbagai hard drive di server yang berbeda. Proses "mirroring" konten membantu untuk mengatasi masalah seperti pemadaman listrik dan crash di sistem file.
Jika hard drive gagal, itu diganti dengan yang baru. Berkat struktur data yang dicerminkan dan direduplikasi, pemula segera diisi dengan data yang ada di HDD lama yang gagal.
"Archive" memiliki sistem khusus yang memantau status HDD. Pada hari itu Anda harus mengganti 6-7 drive yang gagal.
Apa itu Mesin Wayback?
Ini hanyalah salah satu layanan dari "arsip Internet", yang berspesialisasi dalam pelestarian halaman web. Layanan ini memiliki "laba-laba" sendiri, yang secara teratur memeriksa semua situs yang tersedia di jaringan dan menyimpannya di server khusus. Semakin populer situs web, semakin sering robot menyalin isinya. Jika administrator sumber daya tidak ingin informasi situs disalin oleh bot, cukup menulis larangan di file robots.txt.
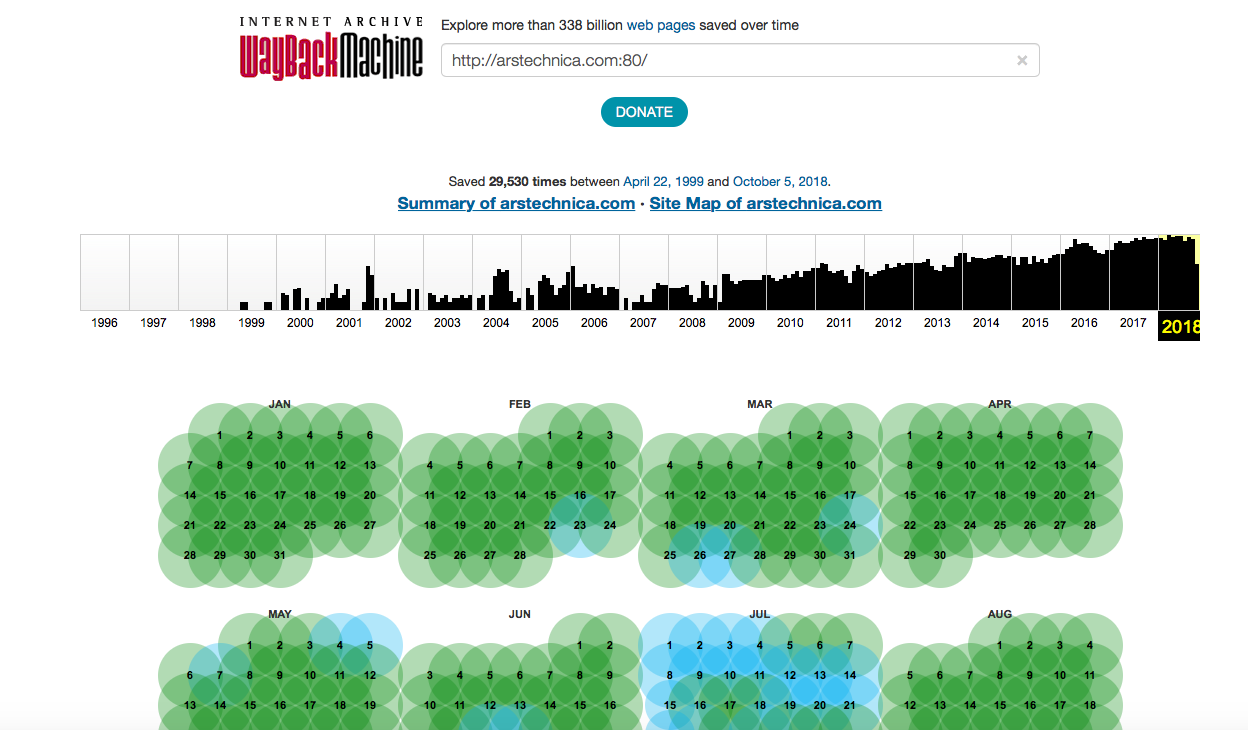 Sumber daya populer sering disalin - hampir setiap hari. Wayback Machine bahkan mengindeks jejaring sosial, termasuk Twitter, Facebook
Sumber daya populer sering disalin - hampir setiap hari. Wayback Machine bahkan mengindeks jejaring sosial, termasuk Twitter, Facebook
Pada 2017, Archive
meluncurkan layanan Wayback Machine yang diperbarui , menjanjikan akses yang lebih nyaman ke halaman web yang disimpan. Layanan ini ditulis jika bukan dari awal, kemudian dirancang ulang keren. Sekarang mendukung sejumlah format file yang sebelumnya tidak disimpan. Pada tahun 2017 yang sama, organisasi mengumumkan bahwa sekitar 1 miliar halaman web disimpan di servernya setiap minggu.
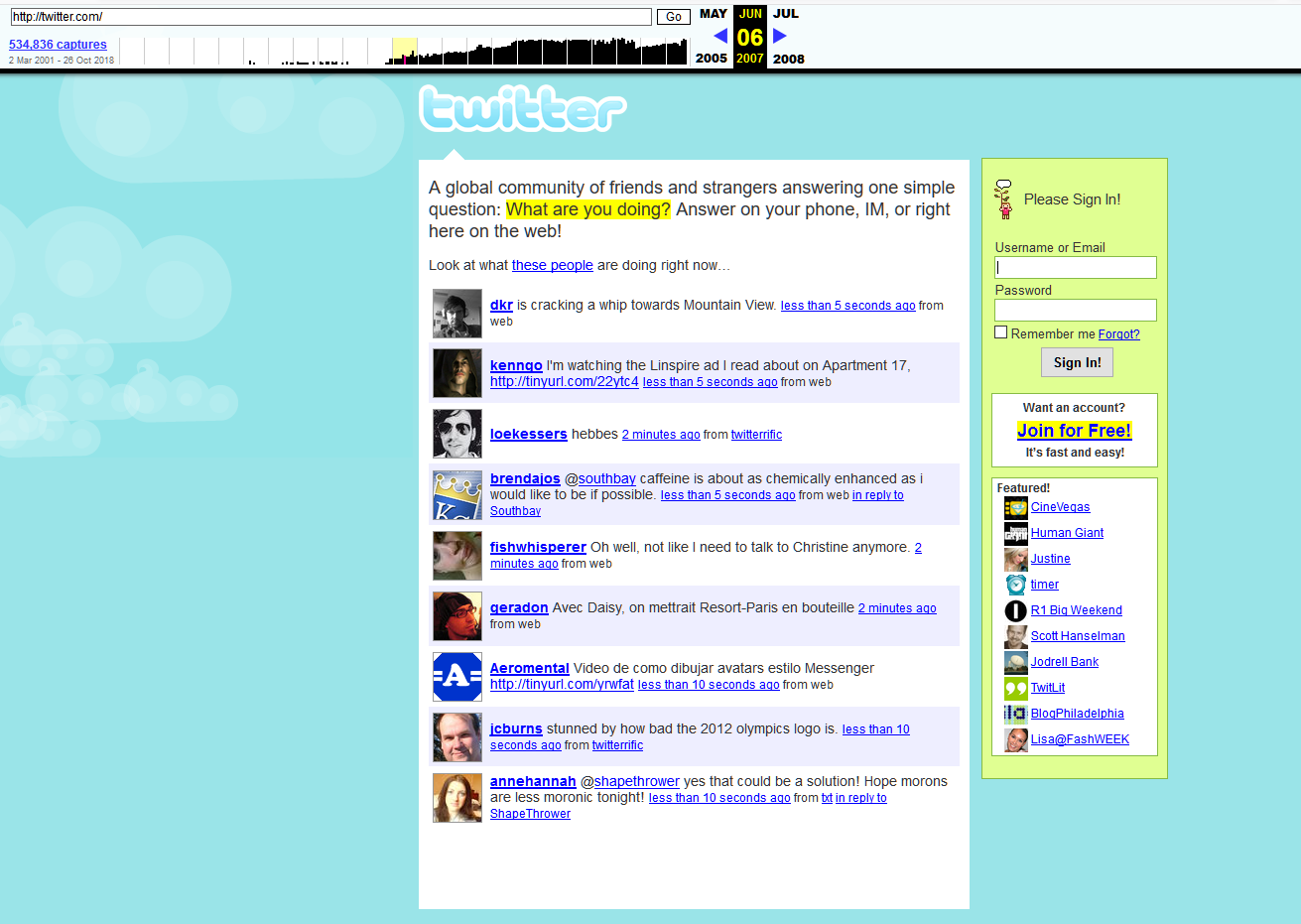 Seperti itulah Twitter pada 2007
Seperti itulah Twitter pada 2007Apa lagi yang bisa ditemukan di database "Internet Archive"?
Buku. Koleksi organisasi sangat besar, termasuk buku-buku digital, edisi umum dan sangat langka. Buku disimpan tidak hanya dalam bahasa Inggris, tetapi juga dalam banyak bahasa lainnya. Arsip memiliki pusat-pusat khusus untuk memindai buku, ada 33 pusat seperti itu secara total, mereka berada di lima negara di seluruh dunia.
Staf pusat memindai sekitar 1.000 buku per hari. Basis data layanan berisi jutaan publikasi, pekerjaan digitalisasi mereka didanai oleh orang biasa dan berbagai organisasi, termasuk perpustakaan dan dana.
Sejak 2007, Internet Archive telah mengelola buku-buku yang dapat diakses publik dari Google Book Search dalam basis datanya. Setelah peluncuran, basis buku dengan cepat meluas - pada 2013, sudah ada lebih dari 900 ribu buku yang disimpan dari layanan Google.
Salah satu layanan dari "Archive" juga menyediakan akses ke buku-buku yang sepenuhnya terbuka, sudah ada lebih dari satu juta di antaranya. Layanan ini disebut Open Library.
Video Layanan ini menyimpan 4,5 juta klip. Mereka dibagi berdasarkan subjek dan memiliki fokus yang sangat berbeda. Server “Archive” menyimpan film, dokumenter, rekaman acara olahraga, acara TV, dan banyak materi lainnya.
Pada 2015, "Archive" memunculkan proyek skala besar -
digitalisasi kaset video . Pada awalnya itu sekitar 40 ribu kaset dari arsip Marion Stokes, seorang wanita yang selama beberapa dekade merekam berita di kaset. Kemudian, kaset video lainnya ditambahkan, yang dikirim ke "Archive" oleh para penggemar gagasan digitalisasi data yang penting bagi umat manusia.
Audio Mirip dengan video, "Archive" juga menyimpan file audio, yang juga dibagi berdasarkan subjek. Tahun lalu, "Archive" mulai mengimplementasikan proyek barunya - mendekodekan catatan shellac, format rekaman audio tertua. Suara itu diawetkan di piring lak, resin alami yang dikeluarkan oleh cacing betina. Secara total, arsip
Great 78 Project memiliki beberapa
ratus ribu catatan .
Perangkat lunak. Tentu saja, tidak mungkin untuk menyimpan semua perangkat lunak yang dibuat oleh manusia, bahkan untuk Arsip. Server menyimpan vintage - misalnya, program untuk Macintosh, perangkat lunak untuk DOS dan perangkat lunak lainnya. Pada 2016, karyawan Archive memposting
1.500+ program untuk Windows 3.1 , Anda dapat bekerja secara langsung di browser. Pada tahun 2017, Internet Archive merilis
arsip perangkat lunak untuk Macintosh pertama .
Game Ya, Arsip menyediakan akses ke sejumlah besar permainan. Beberapa di antaranya dapat dimainkan di lingkungan emulator browser. Game disimpan sangat berbeda, termasuk dari
konsol analog-ke-digital portabel . Ada game untuk
MS-DOS dan
game konsol untuk Atari dan ColecoVision.

Organisasi ini pertama kali
memposting arsip game lama pada tahun 2013. Kami berbicara tentang judul 30-40 tahun yang lalu, yang dapat diputar langsung di browser. Ini adalah game untuk konsol Atari 2600 (1977), Atari 7800 (1986), ColecoVision (1982), Philips Videopac G7000 (1978) dan Astrocade (1983). Yang paling menarik adalah Internet Archive memungkinkan untuk bermain secara legal. Sekarang koleksinya memiliki
lebih dari 3400 game dan terus diisi ulang.