Hai habr.
Dalam satu proyek di mana perlu untuk menyimpan dan memproses daftar dinamis yang agak besar, penguji mulai mengeluh tentang kurangnya memori. Cara sederhana untuk memperbaiki masalah dengan "darah kecil" dengan menambahkan hanya satu baris kode dijelaskan di bawah ini. Hasilnya dalam gambar:
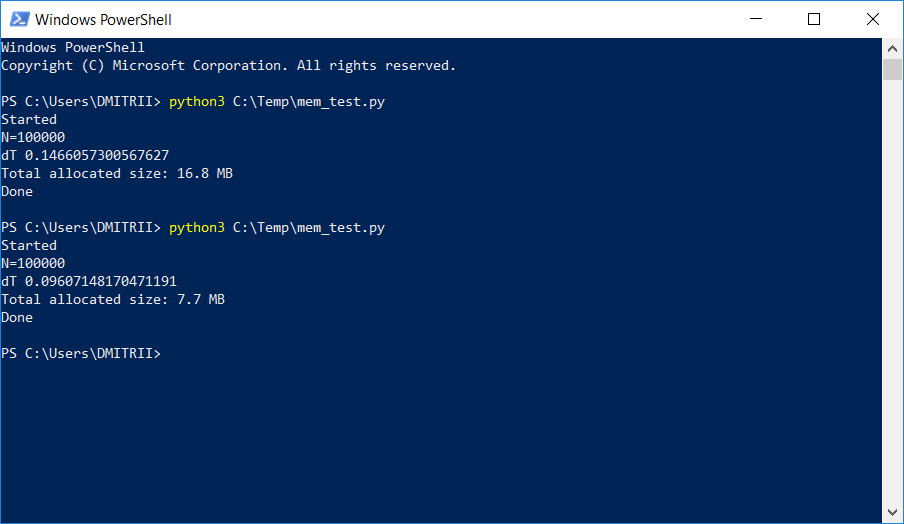
Cara kerjanya, dilanjutkan di bawah luka.
Pertimbangkan contoh "pelatihan" sederhana - buat kelas DataItem yang berisi data
pribadi tentang seseorang, misalnya, nama, usia, dan alamat.
class DataItem(object): def __init__(self, name, age, address): self.name = name self.age = age self.address = address
Pertanyaan "anak-anak" adalah berapa banyak benda seperti itu mengingat?
Mari kita coba solusinya di dahi:
d1 = DataItem("Alex", 42, "-") print ("sys.getsizeof(d1):", sys.getsizeof(d1))
Kami mendapat respons 56 byte. Sepertinya sedikit, cukup puas.
Namun, kami memeriksa objek lain di mana ada lebih banyak data:
d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("sys.getsizeof(d2):", sys.getsizeof(d2))
Jawabannya adalah lagi 56. Pada titik ini, kami memahami bahwa ada sesuatu yang tidak beres di sini, dan tidak semuanya sesederhana seperti yang terlihat pada pandangan pertama.
Intuisi tidak mengecewakan kita, dan semuanya benar-benar tidak begitu sederhana. Python adalah bahasa yang sangat fleksibel dengan pengetikan dinamis, dan untuk pekerjaannya, Python menyimpan banyak data tambahan. Yang dengan sendirinya membutuhkan banyak. Sama seperti contoh, sys.getsizeof ("") akan mengembalikan 33 - ya, sebanyak 33 byte per baris kosong! Dan sys.getsizeof (1) akan mengembalikan 24 - 24 byte untuk integer (saya meminta programmer C untuk menjauh dari layar dan tidak membaca lebih lanjut, agar tidak kehilangan kepercayaan pada yang indah). Untuk elemen yang lebih kompleks, seperti kamus, sys.getsizeof (dict ()) akan mengembalikan 272 byte - dan ini untuk kamus
kosong . Saya tidak akan melanjutkan, saya berharap prinsipnya jelas,
dan produsen RAM juga perlu menjual chip mereka .
Tetapi kembali ke kelas DataItem kami dan pertanyaan "anak". Berapa lama kelas seperti itu mengingat? Untuk mulai dengan, kami menampilkan seluruh konten kelas di tingkat yang lebih rendah:
def dump(obj): for attr in dir(obj): print(" obj.%s = %r" % (attr, getattr(obj, attr)))
Fungsi ini akan menunjukkan apa yang disembunyikan "di bawah tenda" sehingga semua fungsi Python (mengetik, warisan, dan barang lainnya) dapat berfungsi.
Hasilnya mengesankan:
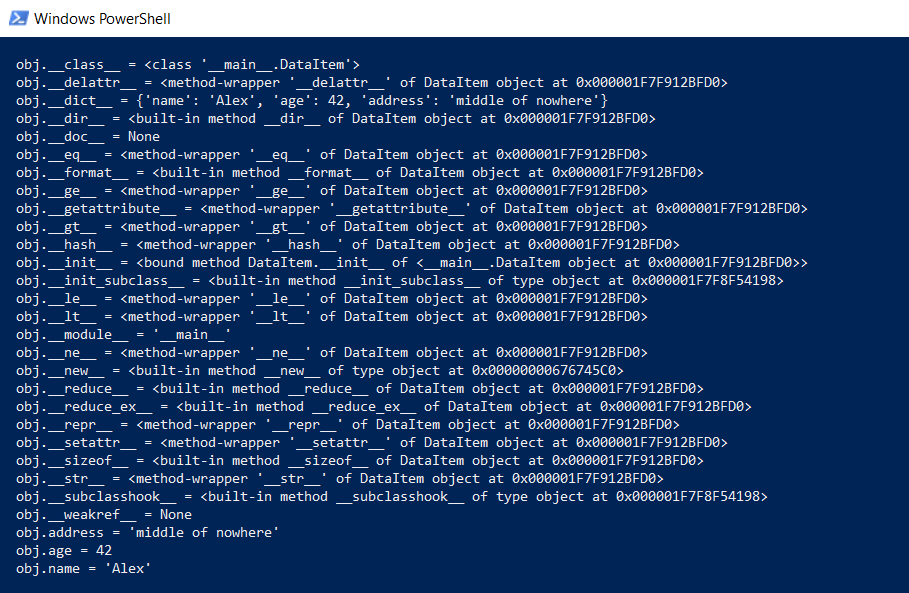
Berapa semua ini? Di github ada fungsi yang menghitung jumlah data aktual, secara rekursif memanggil getsize untuk semua objek.
def get_size(obj, seen=None):
Kami mencobanya:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("get_size(d2):", get_size(d2))
Kami mendapatkan masing-masing 460 dan 484 byte, yang lebih mirip kebenaran.
Memiliki fungsi ini, sejumlah percobaan dapat dilakukan. Sebagai contoh, saya bertanya-tanya berapa banyak data yang akan diambil jika Anda meletakkan struktur DataItem dalam daftar. Fungsi get_size ([d1]) mengembalikan 532 byte - rupanya ini adalah "sama" 460 + beberapa overhead. Tetapi get_size ([d1, d2]) akan mengembalikan 863 byte - kurang dari 460 + 484 secara terpisah. Yang lebih menarik adalah hasilnya untuk get_size ([d1, d2, d1]) - kami mendapatkan 871 byte, hanya sedikit lagi, yaitu. Python cukup pintar untuk tidak mengalokasikan memori untuk objek yang sama untuk kedua kalinya.
Sekarang kita beralih ke bagian kedua dari pertanyaan - apakah mungkin untuk mengurangi konsumsi memori? Ya kamu bisa. Python adalah penerjemah, dan kami dapat memperluas kelas kami kapan saja, misalnya, menambahkan bidang baru:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d1.weight = 66 print ("get_size(d1):", get_size(d1))
Ini bagus, tetapi jika kita
tidak membutuhkan fungsi ini, kita bisa memaksa penerjemah untuk membuat daftar objek kelas menggunakan arahan __slots__:
class DataItem(object): __slots__ = ['name', 'age', 'address'] def __init__(self, name, age, address): self.name = name self.age = age self.address = address
Anda dapat membaca lebih lanjut di dokumentasi (
RTFM ), yang mengatakan bahwa "__slots__ memungkinkan kami untuk secara eksplisit mendeklarasikan anggota data (seperti properti) dan menolak pembuatan __dict__ dan __weakref__. Ruang yang dihemat saat menggunakan __dict__
dapat menjadi signifikan ".
Periksa: ya, sangat signifikan, get_size (d1) mengembalikan ... 64 byte, bukan 460, yaitu 7 kali lebih sedikit. Sebagai bonus, objek dibuat sekitar 20% lebih cepat (lihat tangkapan layar pertama artikel).
Sayangnya, dengan penggunaan nyata, keuntungan besar dalam memori tidak akan disebabkan oleh biaya overhead lainnya. Mari kita buat array untuk 100.000 hanya dengan menambahkan elemen, dan lihat konsumsi memori:
data = [] for p in range(100000): data.append(DataItem("Alex", 42, "middle of nowhere")) snapshot = tracemalloc.take_snapshot() top_stats = snapshot.statistics('lineno') total = sum(stat.size for stat in top_stats) print("Total allocated size: %.1f MB" % (total / (1024*1024)))
Kami memiliki 16,8 MB tanpa __slots__ dan 6,9 MB dengan itu. Tentu saja tidak 7 kali, tetapi meskipun demikian, mengingat bahwa perubahan kodenya minimal.
Sekarang tentang kekurangannya. Mengaktifkan __slots__ melarang pembuatan semua elemen, termasuk __dict__, yang berarti, misalnya, kode untuk menerjemahkan struktur ke json tidak akan berfungsi:
def toJSON(self): return json.dumps(self.__dict__)
Tapi itu mudah diperbaiki, cukup buat dict Anda secara terprogram, pilah-pilah semua elemen dalam loop:
def toJSON(self): data = dict() for var in self.__slots__: data[var] = getattr(self, var) return json.dumps(data)
Juga tidak mungkin untuk menambahkan variabel baru secara dinamis ke kelas, tetapi dalam kasus saya ini tidak diperlukan.
Dan tes terakhir untuk hari ini. Sangat menarik untuk melihat berapa banyak memori seluruh program. Tambahkan loop tanpa akhir di akhir program sehingga tidak menutup, dan lihat konsumsi memori pada task manager Windows.
Tanpa __slots__:
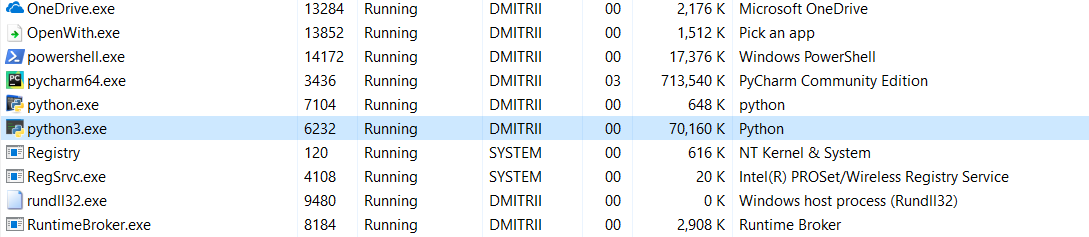
16,8MB oleh beberapa keajaiban diubah (mengedit - penjelasan tentang keajaiban di bawah ini) menjadi 70MB (programmer C mudah-mudahan belum kembali ke layar?).
Dengan __slots__ diaktifkan:

6.9MB berubah menjadi 27MB ... yah, setelah semua, kami menghemat memori, 27MB bukannya 70 tidak begitu buruk untuk hasil penambahan satu baris kode.
Sunting : di komentar (terima kasih kepada robert_ayrapetyan untuk pengujian), mereka menyarankan agar pustaka debug tracemalloc memakan banyak memori tambahan. Rupanya, ia menambahkan elemen tambahan untuk
setiap objek yang dibuat. Jika Anda menonaktifkannya, total konsumsi memori akan jauh lebih sedikit, tangkapan layar menunjukkan 2 opsi:
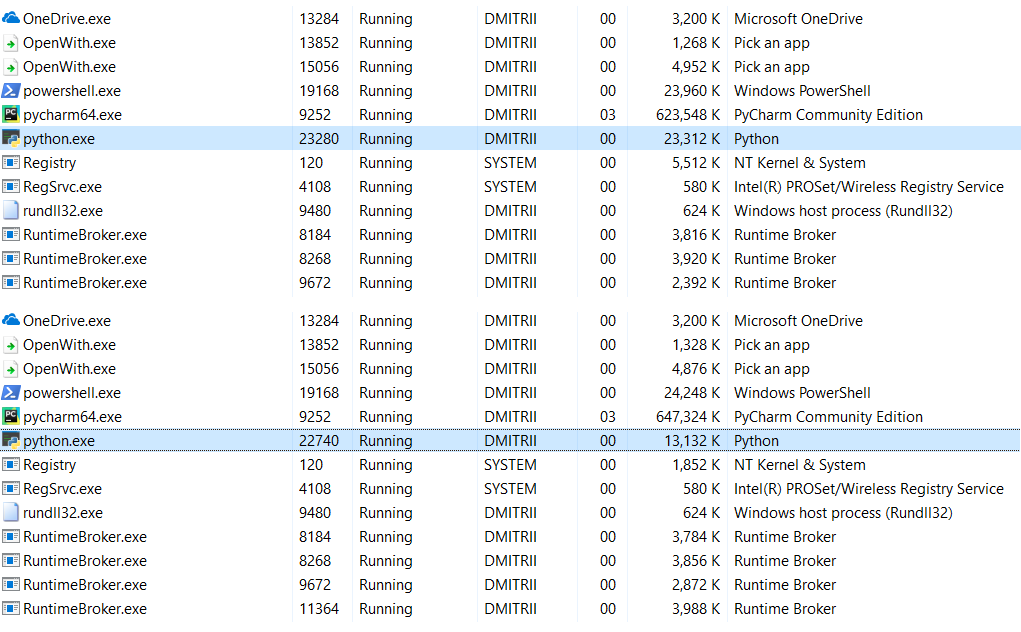
Apa yang harus dilakukan jika Anda perlu menghemat lebih banyak memori? Ini dimungkinkan menggunakan perpustakaan
numpy , yang memungkinkan Anda membuat struktur gaya-C, tetapi dalam kasus saya ini akan membutuhkan penyempurnaan yang lebih dalam dari kode, dan metode pertama ternyata cukup cukup.
Sungguh aneh bahwa penggunaan __slots__ belum pernah diperiksa secara rinci tentang Habré, saya harap artikel ini akan mengisi celah ini sedikit.
Alih-alih sebuah kesimpulan.
Artikel ini mungkin tampak seperti anti-iklan Python, tetapi sama sekali tidak. Python sangat andal (Anda harus berusaha
sangat keras untuk menjatuhkan program Python), bahasa yang mudah dibaca dan mudah untuk menulis kode. Keuntungan ini lebih besar daripada yang kontra dalam banyak kasus, tetapi jika Anda membutuhkan kinerja dan efisiensi maksimum, Anda dapat menggunakan perpustakaan seperti numpy yang ditulis dalam C ++ yang bekerja dengan data cukup cepat dan efisien.
Terima kasih atas perhatian Anda, dan kode yang baik :)