Jadi, komunitas, saya meminta Anda untuk memberi saya kesempatan untuk mengejutkan Anda ketiga kalinya, dalam keputusan sebelumnya saya menggunakan python, saya pikir saya akan menarik perhatian para ahli di sini dan mereka akan segera memberi tahu saya mengapa melakukan ini, secara umum ada ekspresi reguler - Saya melakukannya dan semuanya pasti akan berhasil, ini python kami dapat memberikan dan lebih banyak kecepatan.
Topik artikel selanjutnya adalah tugas lain, tetapi tidak, yang pertama tidak meninggalkan saya, apa yang dapat dilakukan untuk mendapatkan solusi yang lebih cepat, karena kemenangan di situs dimahkotai dengan kompetisi lain.
Saya menulis implementasi yang, rata-rata, dengan kecepatan seperti ini, itu berarti masih ada 90 persen solusi yang saya tidak perhatikan bahwa seseorang tahu bagaimana menyelesaikannya lebih cepat dan dia diam , dan setelah melihat dua artikel sebelumnya saya tidak mengatakan: oh, jika itu masalah kinerja, maka semuanya jelas - di sini prolog tidak cocok. Tetapi sekarang semuanya normal dengan kinerja, tidak mungkin untuk membayangkan sebuah program yang akan berjalan pada perangkat keras yang lemah, "pada akhirnya, mengapa memikirkannya?"
Tantangan
Untuk memecahkan masalah lebih cepat, ada python dan ada waktu, dan apakah ada solusi yang lebih cepat pada python?
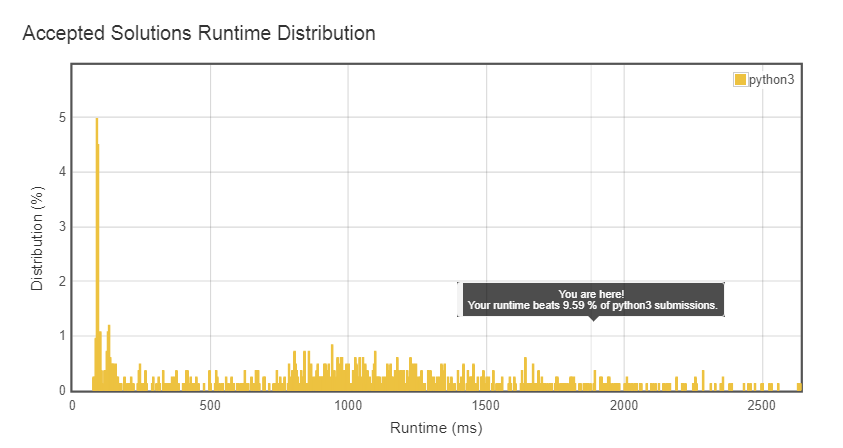
Saya diberi tahu "Runtime: 2504 ms, lebih cepat dari 1,55% dari pengiriman online Python3 untuk Pencocokan Wildcard."
Saya memperingatkan Anda, lebih lanjut ada aliran pemikiran online.
1 Reguler?
Mungkin di sini ada opsi untuk menulis program yang lebih cepat hanya dengan menggunakan ekspresi reguler.
Jelas, python dapat membuat objek ekspresi reguler yang akan memeriksa baris input dan ternyata akan berjalan di sana, di kotak pasir di situs untuk program pengujian.
Cukup impor ulang , saya dapat mengimpor modul seperti itu, menarik, saya harus mencoba.
Tidak mudah untuk memahami bahwa menciptakan solusi cepat tidaklah mudah. Kami harus mencari, mencoba, dan membuat implementasi yang mirip dengan ini:
1. membuat objek keteraturan ini,
2. membuka padanya templat yang dikoreksi oleh aturan perpustakaan reguler dari perpustakaan yang dipilih,
3. Bandingkan dan jawabannya sudah siap
Voila:
import re def isMatch(s,p): return re.match(s,pat_format(p))!=None def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" if ch=='?':res+="." else: res+=ch return res
di sini adalah solusi yang sangat singkat, seakan benar.
Saya mencoba menjalankan, tetapi tidak ada di sini, itu tidak sepenuhnya benar, beberapa opsi tidak cocok, Anda perlu menguji konversi ke templat.
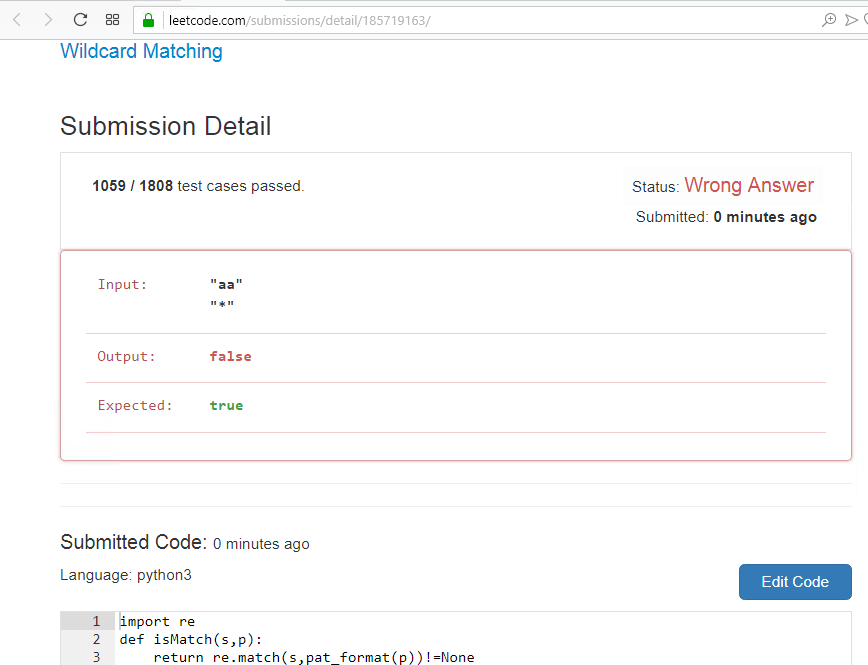
Sebenarnya lucu, saya mencampuradukkan template dan string, tetapi solusinya datang bersama, saya melewati 1058 tes dan gagal, hanya di sini.
Saya ulangi sekali lagi, di situs ini mereka bekerja dengan hati-hati pada tes, seperti yang terjadi, semua yang sebelumnya baik, tapi di sini dua parameter utama digabungkan dan ini muncul, berikut adalah keunggulan TDD ...
Dan pada teks yang begitu indah, saya masih mendapatkan kesalahan
import re def isMatch(s,p): return re.match(pat_format(p),s)==None def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" else: if ch=='?':res+="." else:res+=ch return res
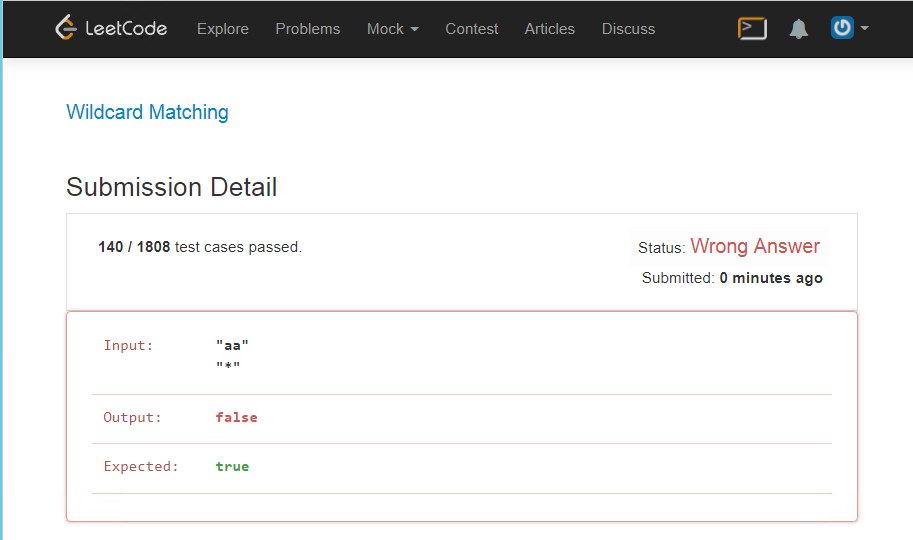
Sulit
Tampaknya tugas ini secara khusus dilapis dengan tes sehingga mereka yang ingin menggunakan ekspresi reguler mendapat lebih banyak kesulitan, saya punya sebelum solusi ini, tidak ada kesalahan logis dalam program, tetapi di sini kita harus memperhitungkan begitu banyak hal.
Jadi, persamaan reguler cocok dan hasil pertama harus sama dengan baris kami.
Kemenangan
Tidak mudah membuatnya menggunakan ekspresi reguler, tetapi usahanya gagal, itu bukan keputusan sederhana untuk memoles para pelanggan tetap. Solusi pencarian luas pertama bekerja lebih cepat.
Inilah implementasi seperti itu,
import re def isMatch(s,p): res=re.match(pat_format(p),s) if res is None: return False else: return res.group(0)==s def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" else: if ch=='?':res+="." else:res+=ch return res
mengarah ke ini:
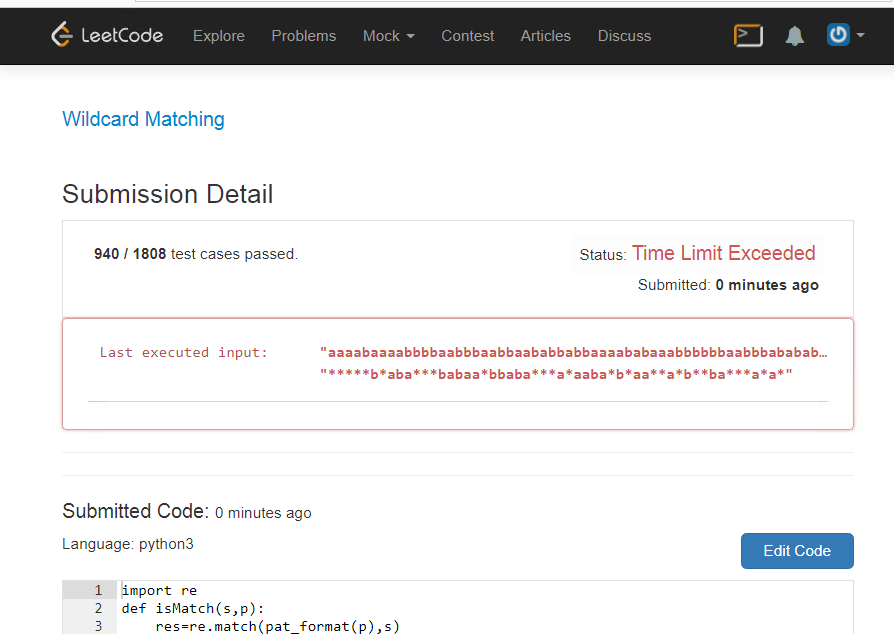
Banding
Penduduk yang terhormat, coba periksa ini, dan itu membuat python tiga , ia tidak dapat dengan cepat menyelesaikan tugas ini:
import re def isMatch(s,p): res=re.match(pat_format(p),s) if res is None: return False else: return res[0]==s def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" else: if ch=='?':res+="." else:res+=ch return res "***** b * aba *** babaa * bbaba *** a * Aaba * b * aa ** a * b ** ba *** a * a *") import re def isMatch(s,p): res=re.match(pat_format(p),s) if res is None: return False else: return res[0]==s def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" else: if ch=='?':res+="." else:res+=ch return res
Anda bisa mencobanya di rumah. Mukjizat, itu tidak hanya butuh waktu lama untuk diselesaikan, itu membeku, oooh.
Apakah ekspresi reguler merupakan bagian dari tampilan deklaratif yang timpang dalam kinerja?
Pernyataan itu aneh, mereka hadir dalam semua bahasa yang modis, jadi produktivitas harus wow, tapi di sini sama sekali tidak realistis bahwa tidak ada mesin negara yang terbatas di dalamnya?, Apa yang terjadi di sana dalam siklus tanpa akhir ??
Pergi
Saya membaca dalam satu buku, tetapi sudah lama sekali ... Bahasa Go terbaru bekerja dengan sangat cepat, tetapi bagaimana dengan ekspresi reguler?
Saya akan mengujinya:
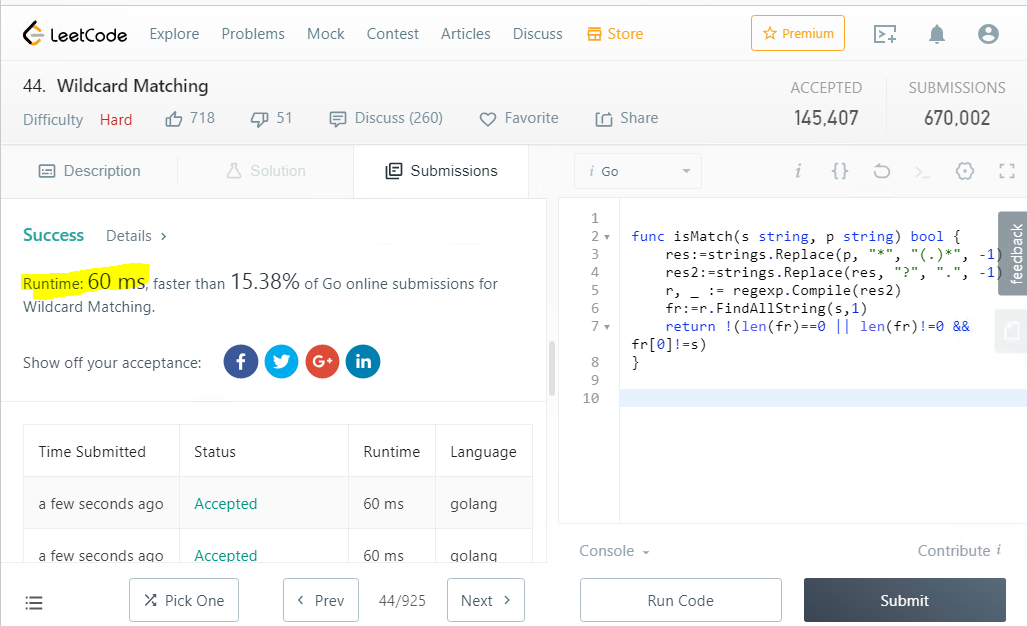
func isMatch(s string, p string) bool { res:=strings.Replace(p, "*", "(.)*", -1) res2:=strings.Replace(res, "?", ".", -1) r, _ := regexp.Compile(res2) fr:=r.FindAllString(s,1) return !(len(fr)==0 || len(fr)!=0 && fr[0]!=s) }
Saya akui, itu tidak mudah untuk mendapatkan teks yang ringkas, di sana sintaksinya tidak sepele, bahkan dengan pengetahuan si, tidak mudah untuk mengetahuinya ...
Ini adalah hasil yang luar biasa, kecepatannya benar-benar berputar, total ~ 60 milidetik, tetapi mengejutkan bahwa solusi ini lebih cepat daripada hanya 15% dari tanggapan di situs yang sama.
Dan di mana prolognya
Saya menemukan bahwa bahasa yang terlupakan ini untuk bekerja dengan ekspresi reguler memberi kami perpustakaan berdasarkan Ekspresi Reguler yang Kompatibel Perl.
Ini adalah bagaimana itu dapat diimplementasikan, tetapi pra-proses string template dengan predikat terpisah.
pat([],[]). pat(['*'|T],['.*'|Tpat]):-pat(T,Tpat),!. pat(['?'|T],['.'|Tpat]):-pat(T,Tpat),!. pat([Ch|T],[Ch|Tpat]):-pat(T,Tpat). isMatch(S,P):- atom_chars(P,Pstr),pat(Pstr,PatStr),!, atomics_to_string(PatStr,Pat), term_string(S,Str), re_matchsub(Pat, Str, re_match{0:Str},[bol(true),anchored(true)]).
Dan runtime baik-baik saja:
isMatch(aa,a)->ok:0.08794403076171875/sec isMatch(aa,*)->ok:0.0/sec isMatch(cb,?a)->ok:0.0/sec isMatch(adceb,*a*b)->ok:0.0/sec isMatch(acdcb,a*c?b)->ok:0.0/sec isMatch(aab,c*a*b)->ok:0.0/sec isMatch(mississippi,m??*ss*?i*pi)->ok:0.0/sec isMatch(abefcdgiescdfimde,ab*cd?i*de)->ok:0.0/sec isMatch(zacabz,*a?b*)->ok:0.0/sec isMatch(leetcode,*e*t?d*)->ok:0.0009980201721191406/sec isMatch(aaaa,***a)->ok:0.0/sec isMatch(b,*?*?*)->ok:0.0/sec isMatch(aaabababaaabaababbbaaaabbbbbbabbbbabbbabbaabbababab,*ab***ba**b*b*aaab*b)->ok:0.26383304595947266/sec isMatch(abbbbbbbaabbabaabaa,*****a*ab)->ok:0.0009961128234863281/sec isMatch(babaaababaabababbbbbbaabaabbabababbaababbaaabbbaaab,***bba**a*bbba**aab**b)->ok:0.20287489891052246/sec
NAMUN, ada beberapa keterbatasan, tes berikutnya dibawa:
Not enough resources: match_limit Goal (directive) failed: user:assert_are_equal(isMatch(aaaabaaaabbbbaabbbaabbaababbabbaaaababaaabbbbbbaabbbabababbaaabaabaaaaaabbaabbbbaababbababaabbbaababbbba,'*****b*aba***babaa*bbaba***a*aaba*b*aa**a*b**ba***a*a*'),false)
Sebagai kesimpulan
Hanya pertanyaan yang tersisa. Semuanya bisa diimplementasikan, tetapi kecepatannya lemah.
Solusi transparan tidak efektif?
Seseorang menerapkan ekspresi reguler deklaratif, mekanisme apa yang ada?
Dan bagaimana Anda menyukai tantangan-tantangan ini, apakah ada masalah yang dapat diselesaikan, tetapi di mana solusi yang sempurna?